主流的编译器gcc,用c语言写的,后期由Google,从6.0把gcc用c++重新写了一套
苹果公司开发的编译器主流的是llvm,前端是clang
关键字
alignas(c++11起)
字节对齐方式,alignas都是2的倍数,除了0之外,默认都是0,1,2,4,8,16,32,64…….这跟c++寻找方式有关
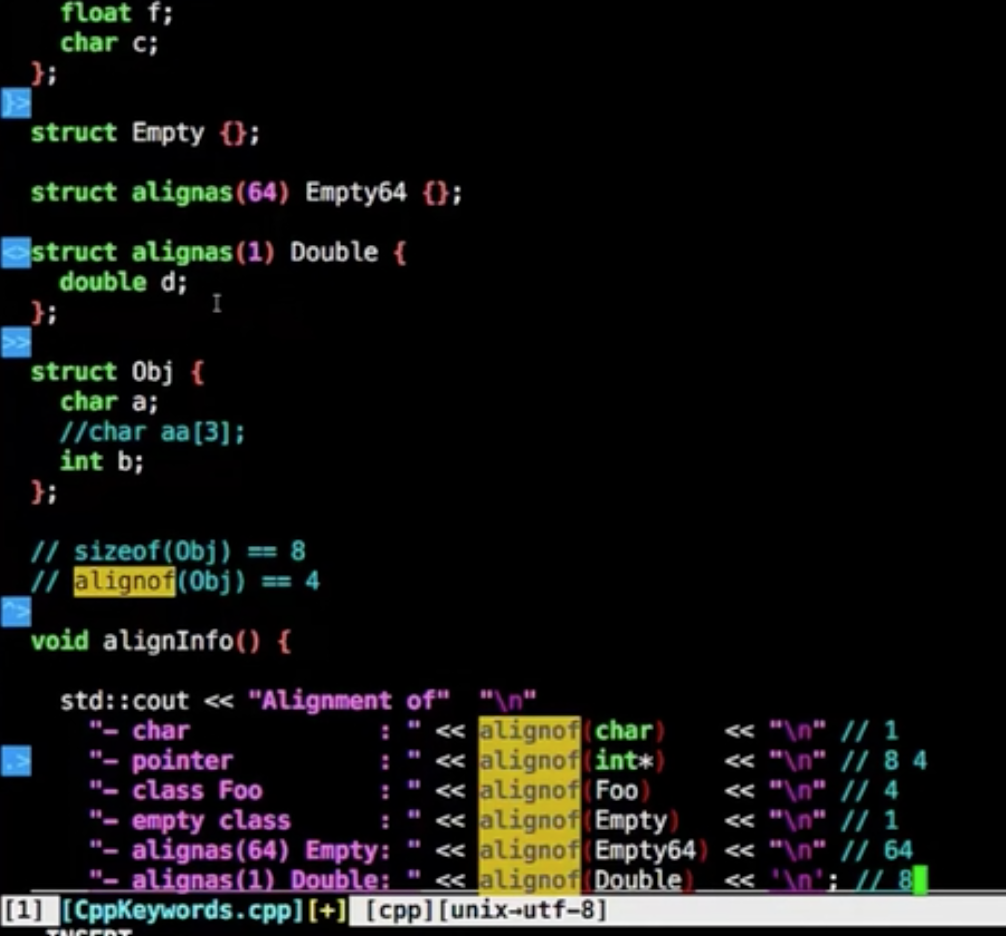
alignof(C++11起)
实际占有字节大小,obj中虽然是1个字节的char+4个字节的int,但是内存中为了查找方便采用了对齐,直接新增3个字节在char后面,所以sizeof为8,但是alignof能够显示最原始的大小
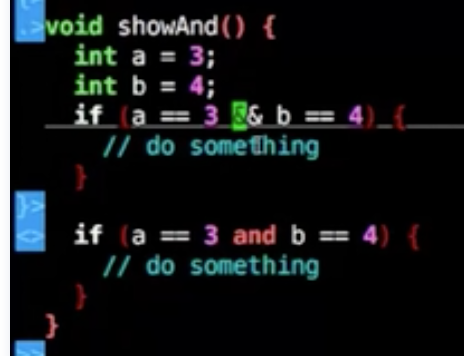
and
and等价于==
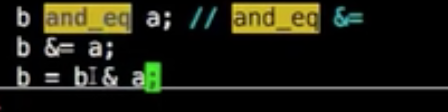
and_eq
a and_eq b 等价于 a = a & b
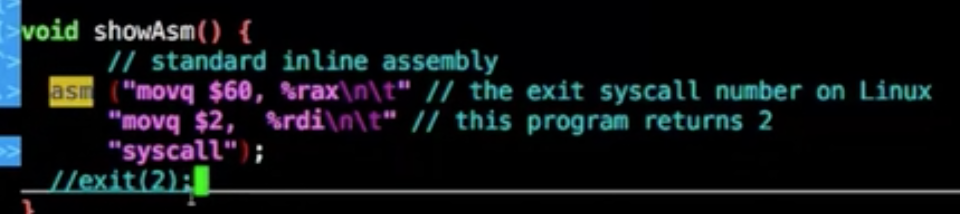
asm
内嵌汇编语言
auto
自动类型,让编译器去自动选择类型
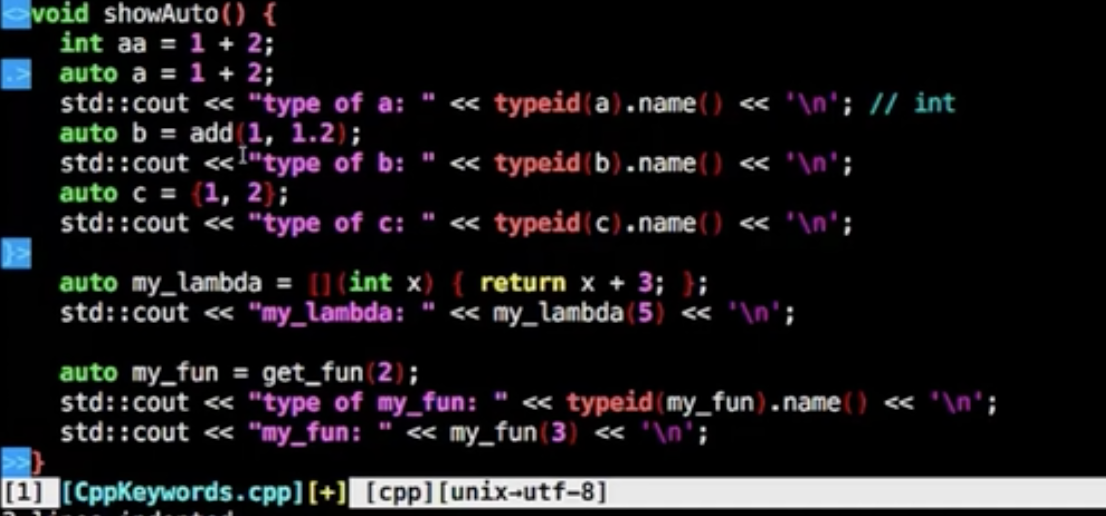
bitand,bitor
按位于,按位或
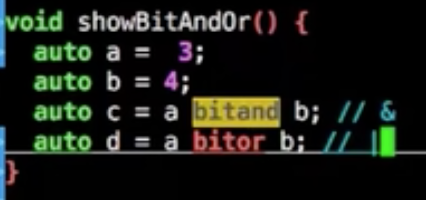
bool
布尔值,只有一个字节,但是强转char变成范围0~255
以下结果为True,有的编译器也会跑出what的结果
所以对布尔值的写法应该写成if(a)不要if(a == true)
break
用来跳出循环,switch,while,for三个地方
case
配合switch使用
catch
捕捉异常
char
char按照语言规范至少能够表示255个值就行了,用1个字节8个位就行了
在linux平台下char和unsigned char 等价
windows平台下则char和signed char等价
char16_t,char_32_t
像中文韩文日文,256个字符可能不够用,所以有2个字节,4个字节的char长度
很多平台都用Unicode,像中文就用UTF-8
compl等价符号~
照顾某些国家键盘没有这个字符
concept
概念TS,当出错的时候,错误信息冗长不清晰,对模板编程很模糊,能够有错误码
const
不变性引入,区别于其他语言的关键,如果能用const尽量用const
与multithread多线程编程密不可分
const最早c++引入,c语言看c++引入的东西不错也引入const概念
constexpr
从代码到程序,编译+链接
拓展c++在编译器的功能,当在编译器产生足够多的信息,把值就产生出来

如果在编译器就能确定的话,直接把值求出来
const_cast
将const语义转非const语义的功能
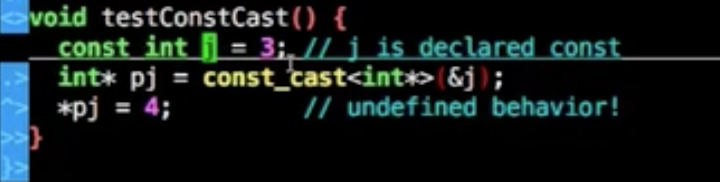
1 | const int j = 3; |
continue
继续循环,与break对应
decltype(c++11起)
与auto差不多类型,等价于
1 | auto aa = a->x; |
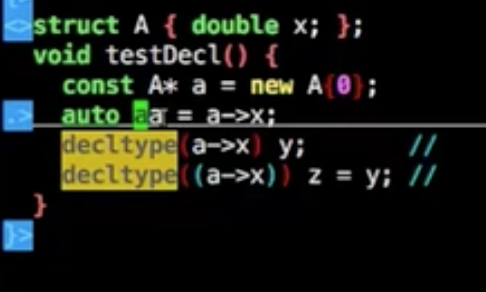
与auto不同得用途范围,推到表达式类型
default
switch case中默认选项
delete
delete等价于执行析构+free
dynamic_cast
将父类制作转换子类指针
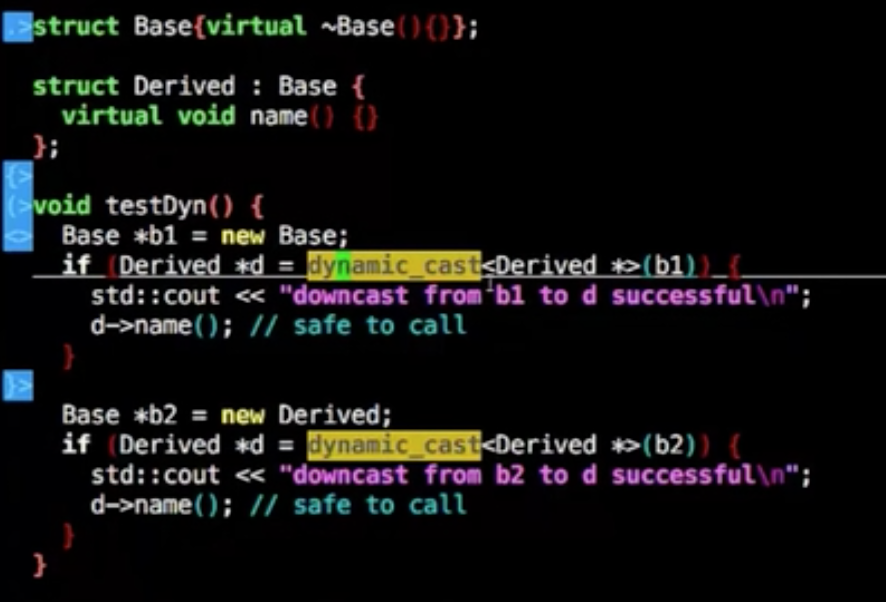
大致常用三种cast,dynamic_cast,const_cast,static_cast
1 | Base bb; |
enum
c++为防止作用于复用不到,加了enum class
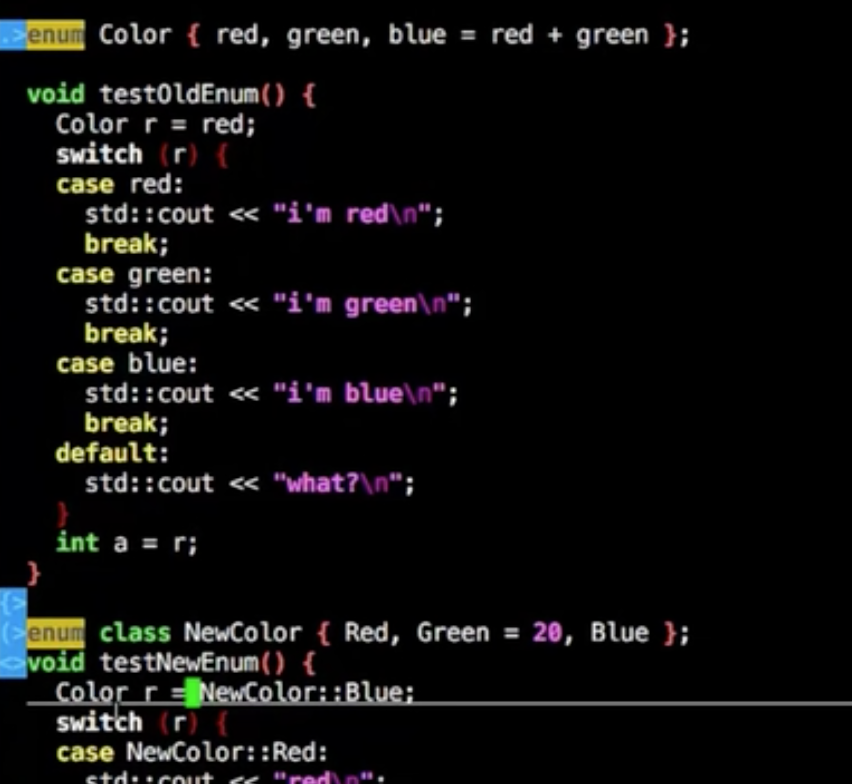
传统老Enum的sizeof不明确,根据enum里面的value来决定它的sizeof可能是char 可能是unsigned char
1 | //所以可以限定char大小,默认不写会等价Int类型 |
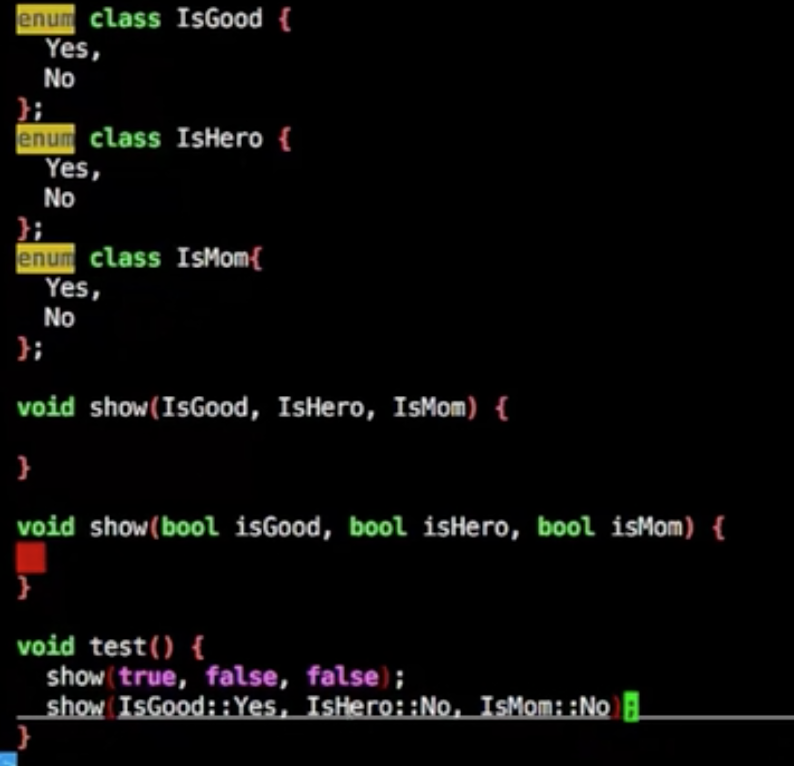
用enum替代bool传参
explicit
明确告诉编译器要做什么类型,阻止隐式转换,阻止类似Java自动拆装箱
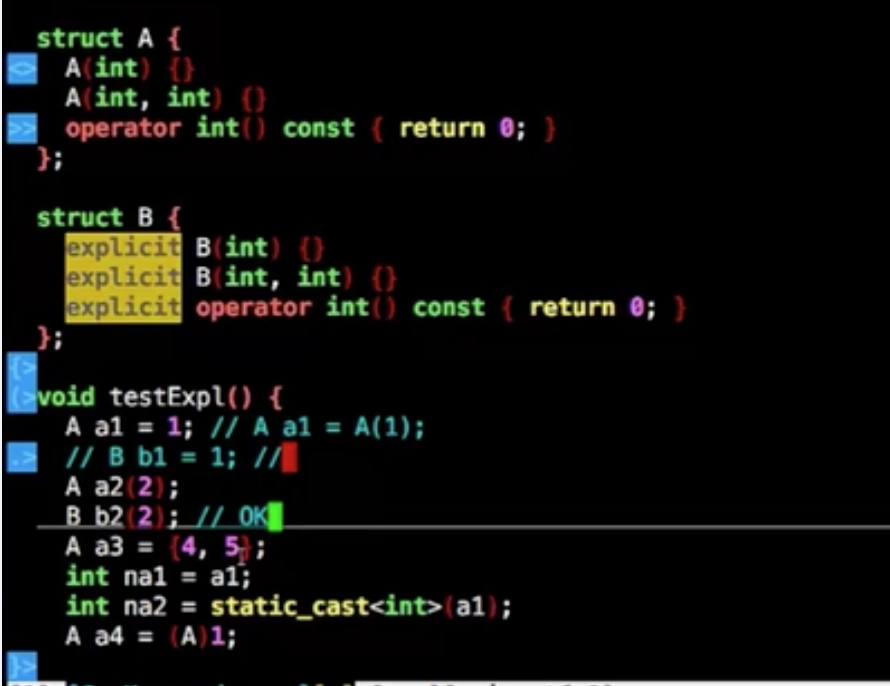
1 | A a2(2);//允许 |
这样写的好处,在函数传参的时候可以默认减少很多Bug
export
之前运用模板都是在头文件,后期能有这个在cpp文件里实现
因为没有编译器支持,后期就c++11废弃不用
extern
对于C语言和C++没有什么变化
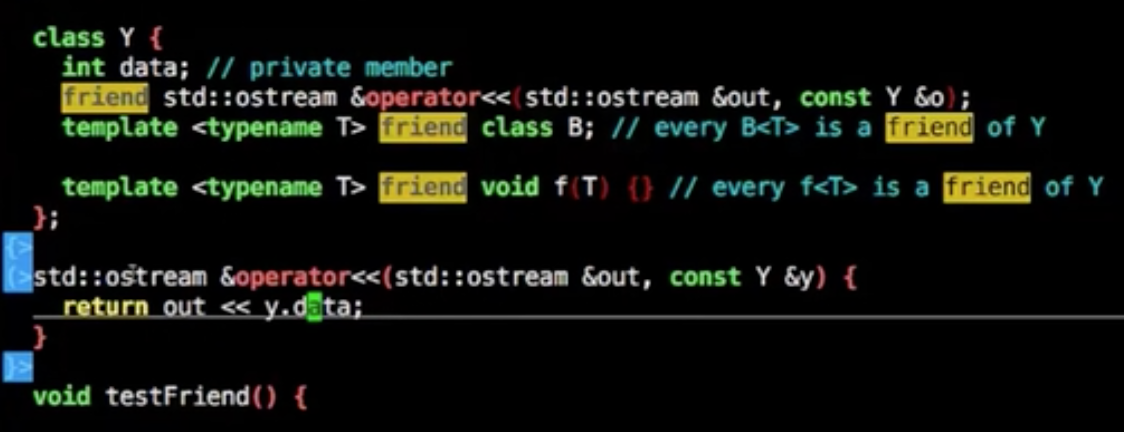
friend
使用的场景比较少,比较特殊
友元函数是可以直接访问类的私有成员的非成员函数。它是定义在类外的普通函数,它不属于任何类,但需要在类的定义中加以声明,声明时只需在友元的名称前加上关键字friend。
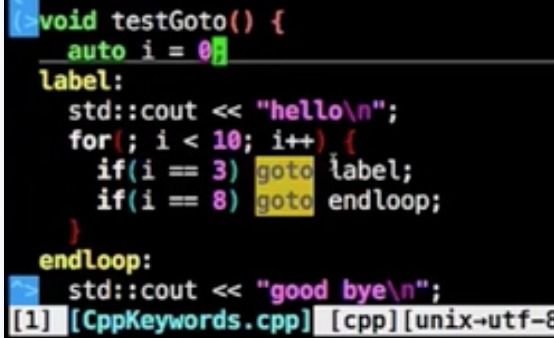
goto
为了兼容性的高级语言,goto很容易出错,但是像break只能跳出一层,goto可以随意跳
inline
普通执行函数给对应函数开堆栈空间,如果函数非常小,开堆栈反而时间比函数调用多,所以拿空间换时间,inline会让空间变大,但是不需要开堆栈空间
加inline会把代码直接展开函数内部的表达式
inline函数会不会坏也不一定,现在的cpu对内存有关,当代码内存过大,运行代码会找不到,则重新加载你的代码信息
inline到底会不会展开还是看编译器,这只是标识告诉编译器我需要展开
mutable
在类定义成员的时候用到
namespace
命名空间
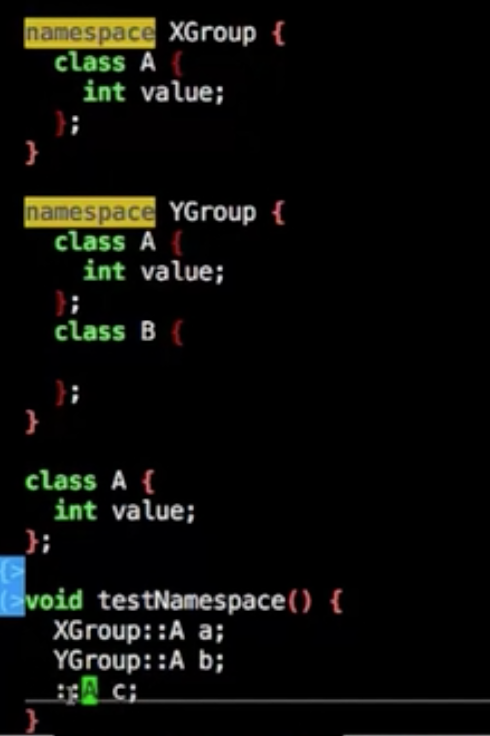
以及命名空间的指示
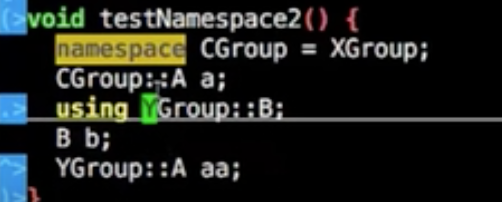
命名空间也可不写名字
noexcept(c++11起)
明确告诉编译器不抛出异常,编译器则采用相关优化方法

如果抛出了异常则调用如下
1 | std::terminate(); |
not
代表键盘!
not_eq
等价于!=
or
等价于||
or_eq
等价于|=
nullptr(c++11起)
用来专门代表空指针
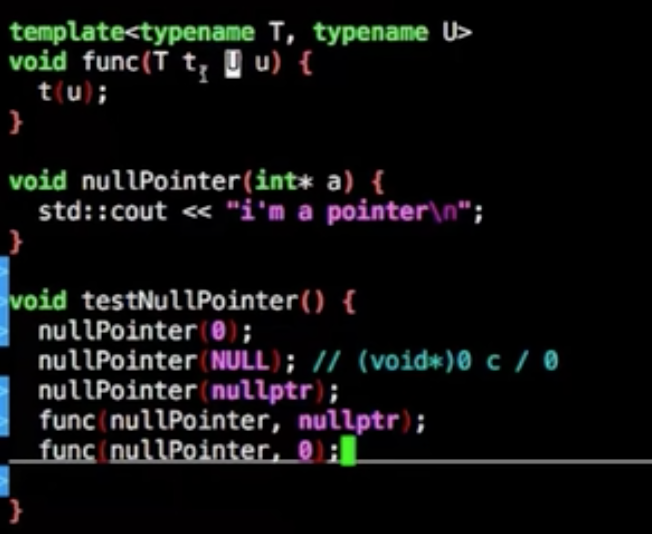
1 | 如果传0无法推到,必须转换成(int*)0的参数 |
operator
定义类的时候重载之时改变一些+,-,||等符号的重载,对于库的编辑者非常方便,但是对应用开发几乎不怎么使用
应用开发使用operator带来的坏处可能还多点
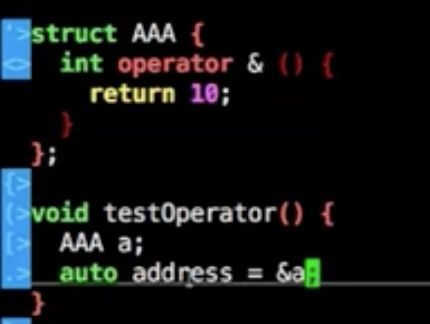
这类重载就会带来一些问题
但是如果使用下面的方式将考虑重载=号
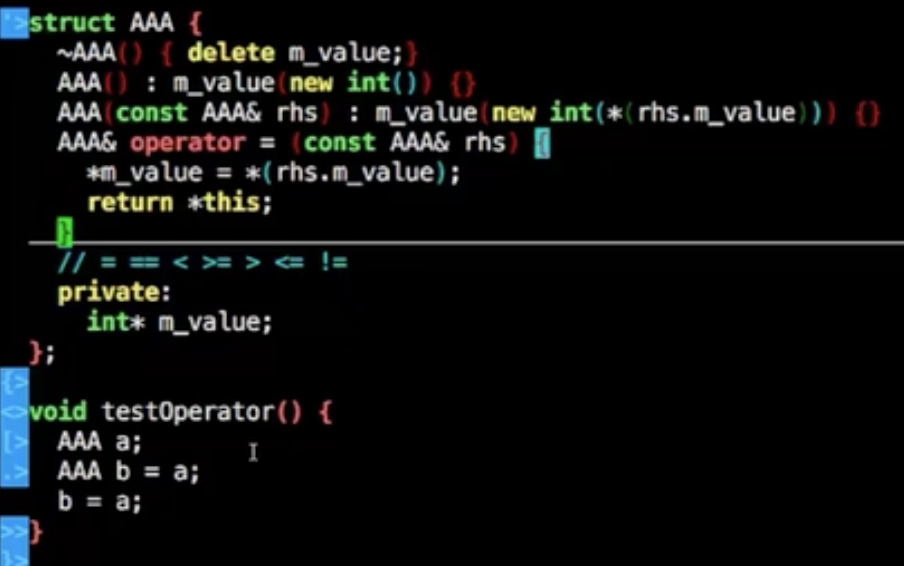
如果重载了”+”号,那“+=”符号没重载就很奇怪,也一并去重载掉
register
希望数据放入寄存器中,编码基本不用
reinterpret_cast
意图长的就少用,转换类型的一种
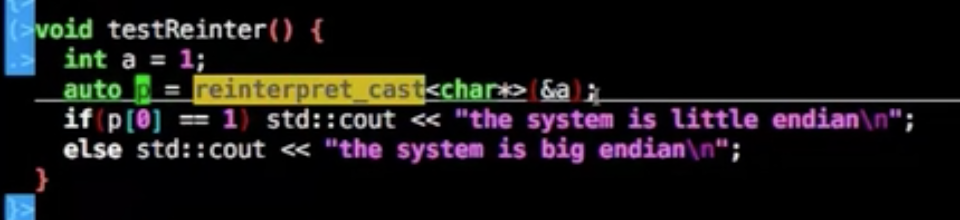
static_cast 类型转换 //float转int等
const_cast 破坏const语义
dynamic_cast 父子指针转换,并且转换失败会返回0
reinterpret_cast 指针转换
c_like_cast
1
2
3
4//万能转换
//直接转换比如
int c = 10;
char a = (char)c;
c++希望在合适的场景运用合适的cast做类型转换,而不是直接用c_like_cast
requires
c++17中会引用
sizeof
- sizeof 对数组,得到整个数组所占空间大小。
- sizeof 对指针,得到指针本身所占空间大小。
1 | sizeof(void);//不允许 |
static
修饰普通变量,修改变量的存储区域和生命周期,使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
修饰普通函数,表明函数的作用范围,仅在定义该函数的文件内才能使用。在多人开发项目时,为了防止与他人命令函数重名,可以将函数定位为 static。
- 修饰成员变量,修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。
- 修饰成员函数,修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员。
static_assert(c++11起)
assert断言,用的多是对自己的代码严格
当assert不满足值就终止掉,但static_assert区别会在编译器的时候就抛出问题来,而且处理的问题也是编译器中

而不允许在运行期间使用
static_cast
四种cast的方式,同等类型转换,int转long 转char,之类的转换
thread_local(c++11起)
方便多线程编程的时候,多线程的数据不一致类似java的thread_local
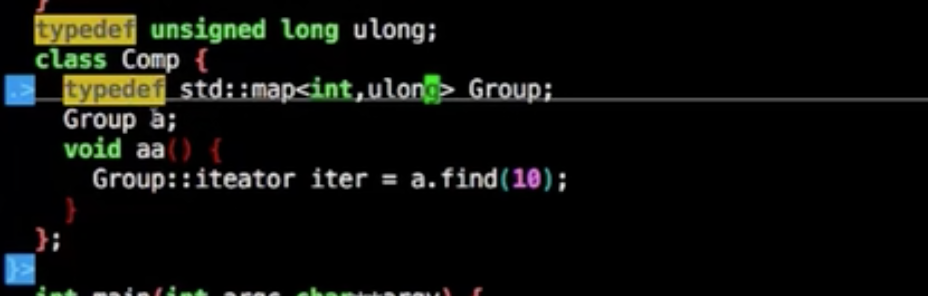
typedef
把一个很长的类型换个短名字
typeid
为了增加运行期的查看类型引入的关键词
typename
union
using
类似typedef的功能
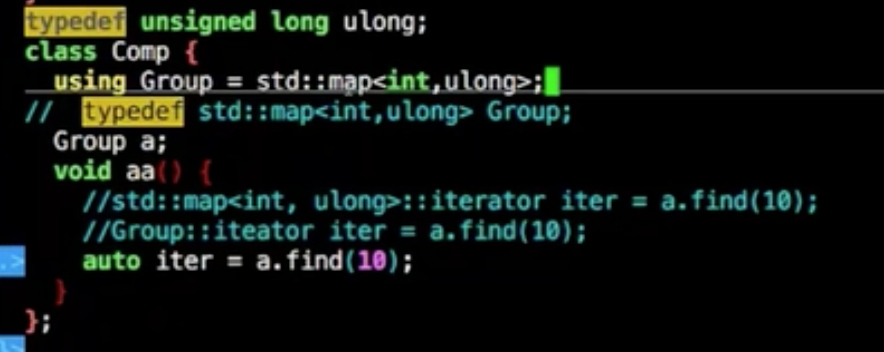
volatile
不要内存优化,存取直接拿主内存,类似Java的volatile
重点领域
前置申明
前置声明的对象最好用指针赋值,因为不知道具体的数据大小
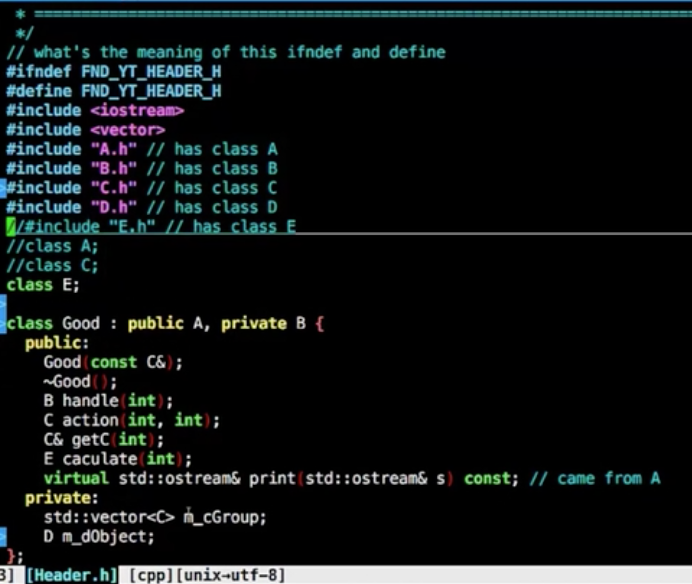
上面的情况只有E可作为前置声明省略头文件引入
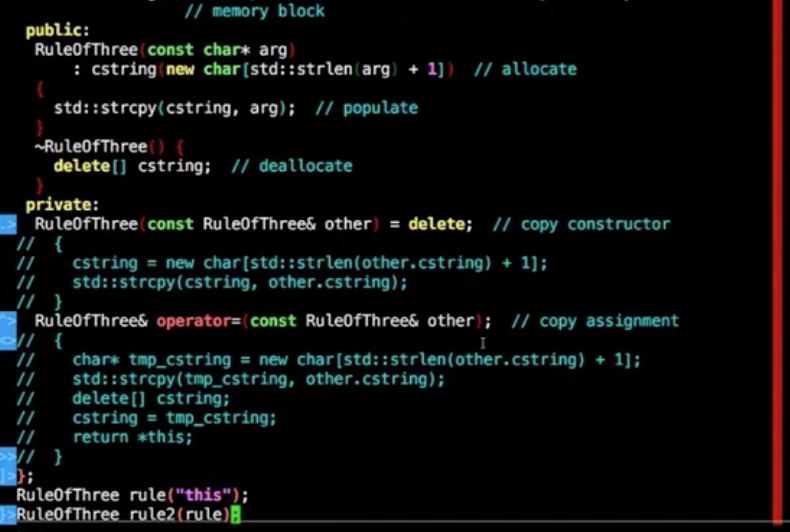
三个基本原则
- 析构函数函数重写
- 拷贝构造函数重写
- =号拷贝函数重写
c++中有析构函数用来回收资源
析构函数
系统默认的析构函数,默认的调用类成员的析构函数,如果类成员是派生,则使用派生成员的析构函数
但是如果是类成员是内置类型的,则类成员的析构函数是什么都没做
所以还是得通过代码手动delete 资源掉
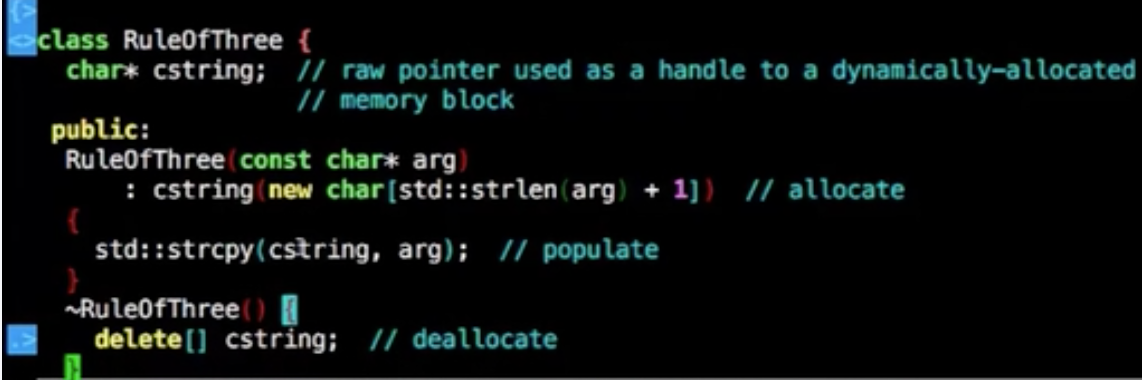
构造拷贝,等号拷贝
如果提供了=号拷贝,构造拷贝功能,那也要明确的写出拷贝的构造函数
默认的拷贝只是浅拷贝,使用析构的时候内存会重复释放
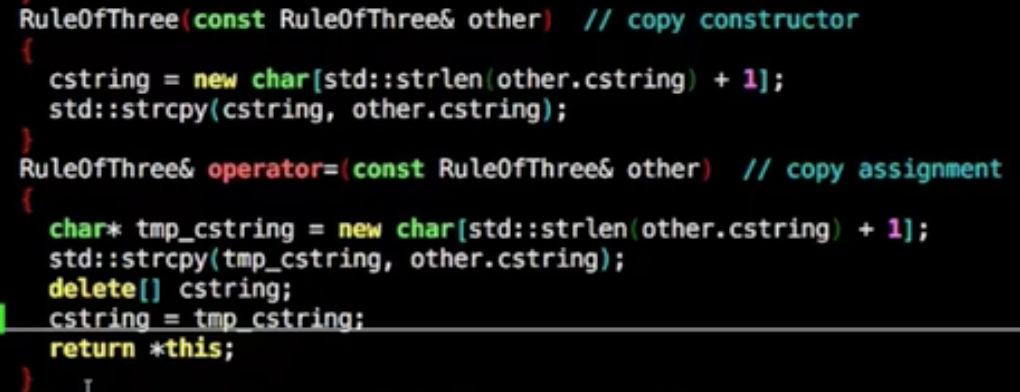
当程序不想要等号拷贝和构造拷贝,那就单纯的声明出来即可,不需要写实现代码进去
或者c++11的写法后面追加delete关键字
左右值引用
在函数处理传参的时候都是值拷贝,如果普通的数据变量进去都无法修改原先的数据
要修改原先的数据则需要放入指针,而指针也是开辟内存空间浪费
所以c++引出了右值引用,直接将数据的引用传参过去,既能改变数据又能不开辟指针空间
1 | // 在函数处理传参的时候都是值拷贝,如果普通的数据变量进去都无法修改原先的数据 |
右值引用
1 | int a = 0; |
std::move会让构造拷贝右键引用显得不一样
1 | //构造函数的T&& rhs |
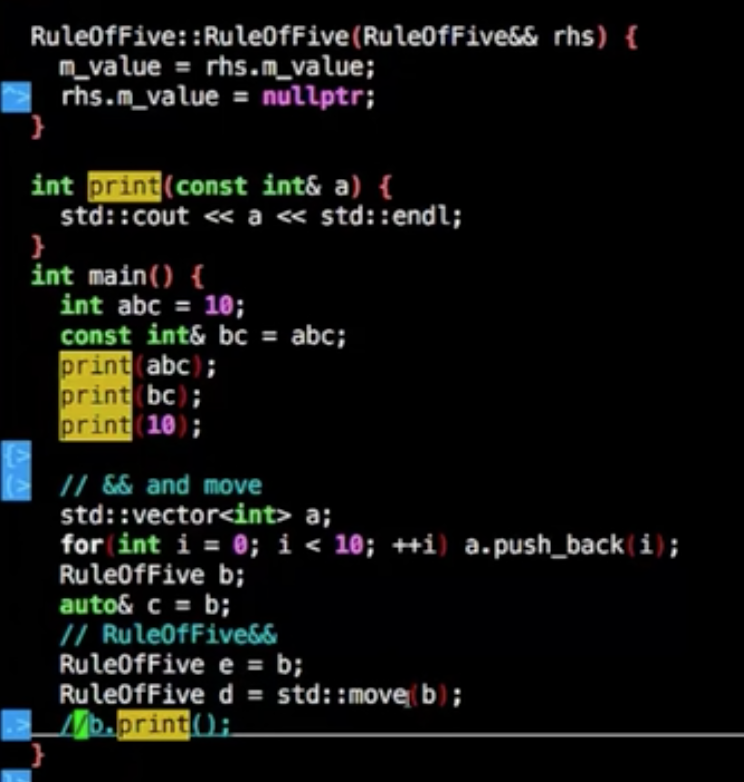
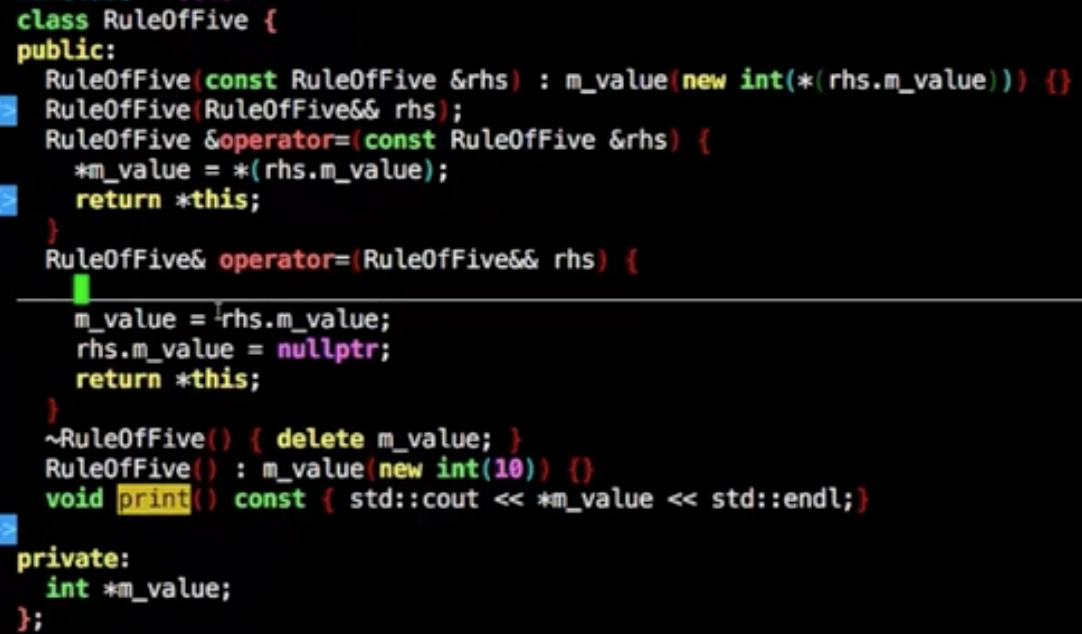
构造抛异常
析构函数不要抛出异常,默认的时候也加了noexcept
如果要捕获析构函数异常那就加false选项
1 | class EvilB{ |
但是如果是派生类情况就复杂了
1 | class A{ |
所以希望析构函数的时候别抛出异常,程序处理不了这样的情况
但是普通的函数调用一旦抛出异常的情况下,会捕捉异常然后catch后继续往后走,析构则不会
虚析构
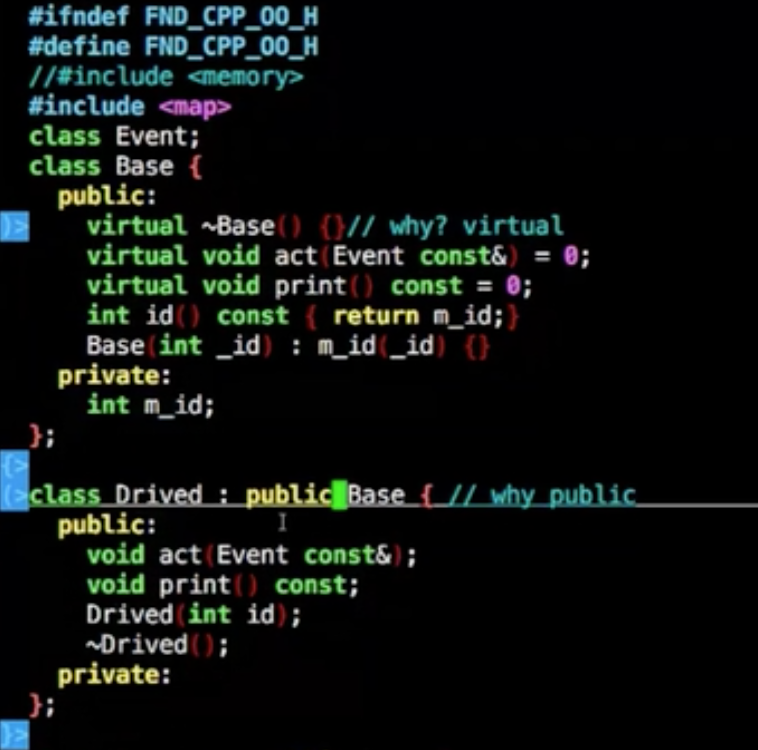
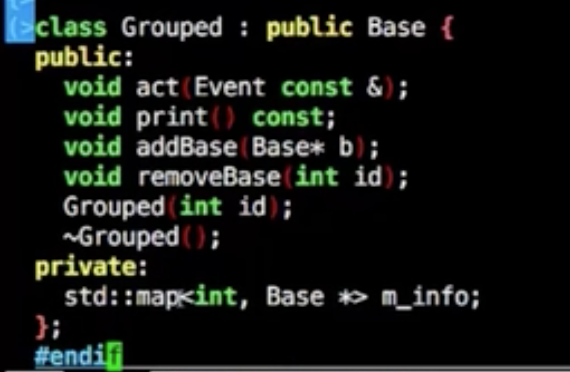
1 | Base *info = new Drived(1); |
如果不是虚析构函数,那么这里析构执行的只是Base的析构函数
而不执行Group的析构函数
不使用派生类的function的方法
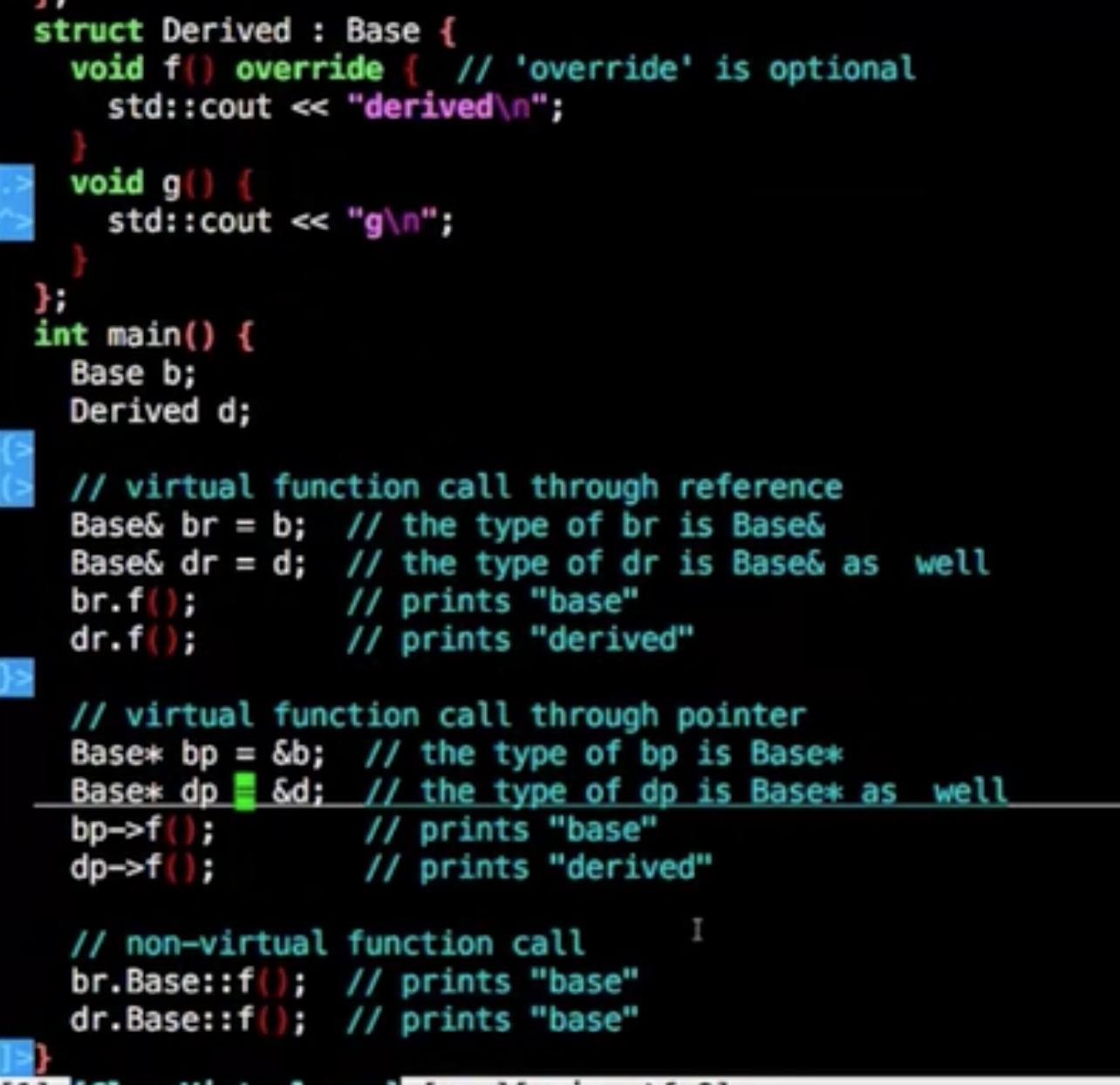
或者自身内部调用
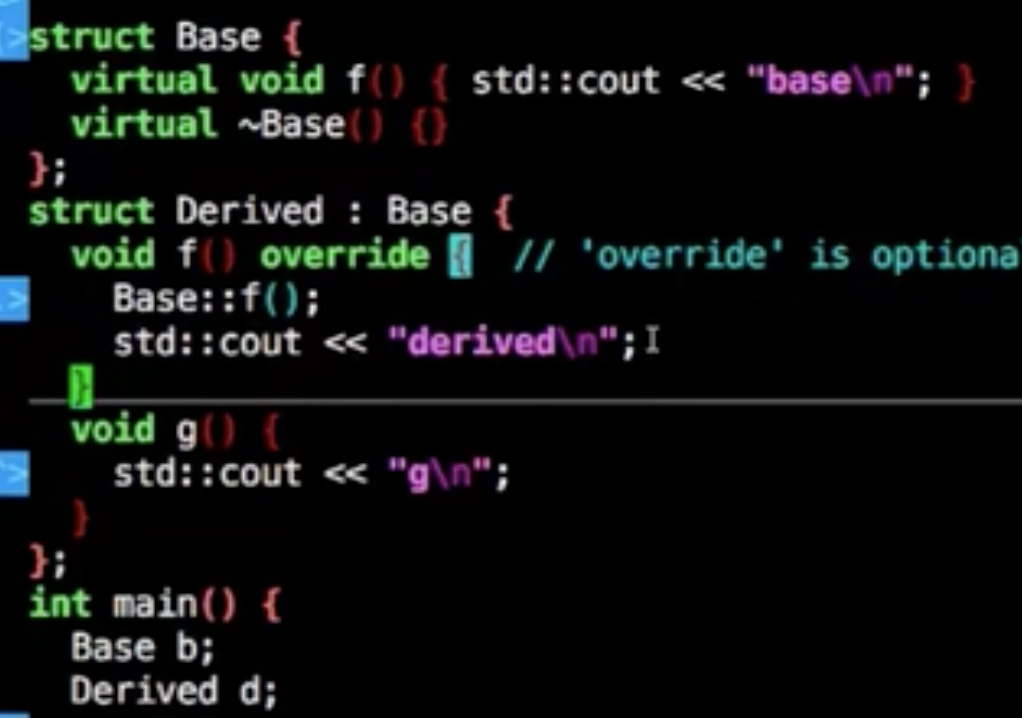
在构造函数和析构函数调用虚函数,会调用自身的虚函数
这个很好理解,构造和析构函数调用虚函数,不会调用派生类上的虚函数而是调用自身的虚函数上,以析构来举例,基类的析构调用虚函数,派生类之前就调用过析构已经删除了资源,没有意义再去调用派生类的虚函数了
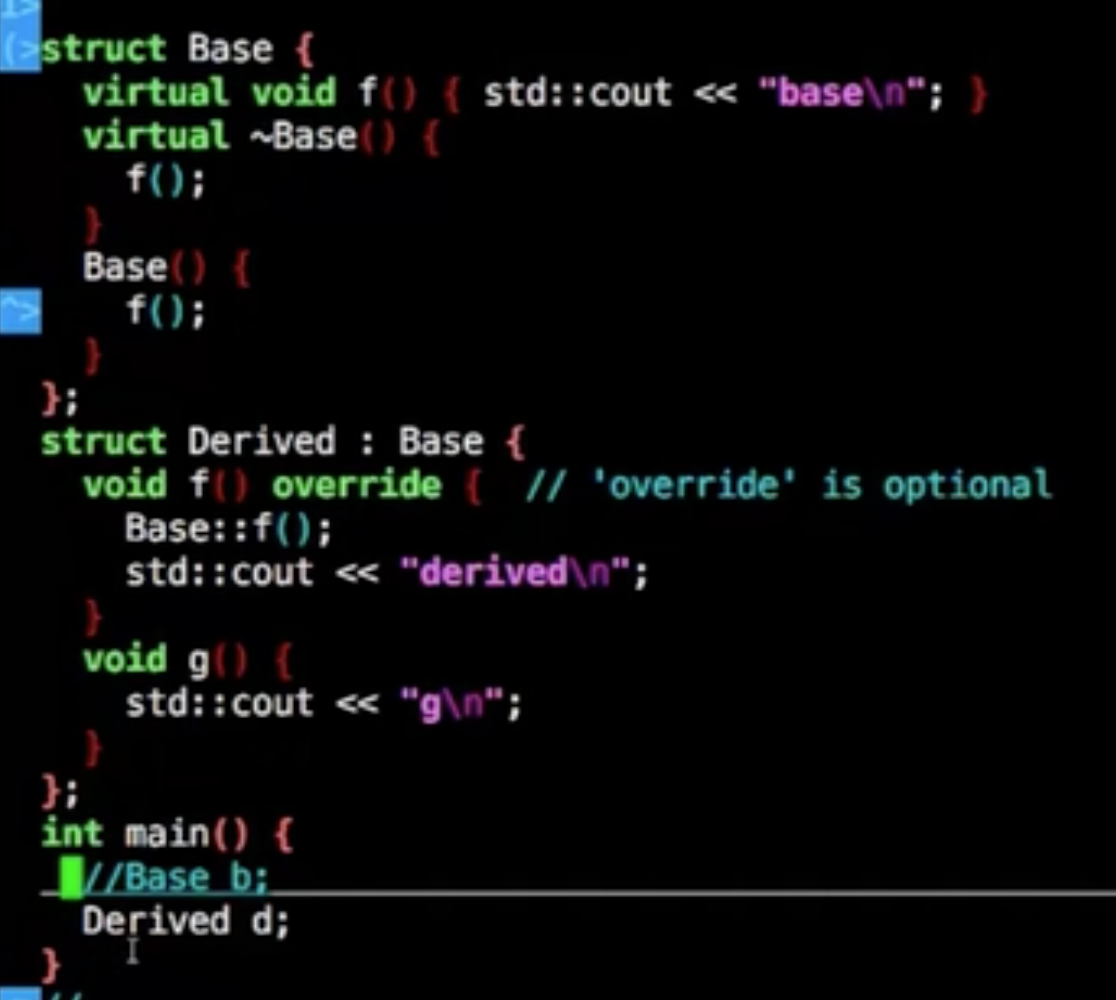
如果你的成员里有虚函数或者纯虚函数,则需要将public的析构函数置为虚函数
又或者把你的虚构函数隐藏起来
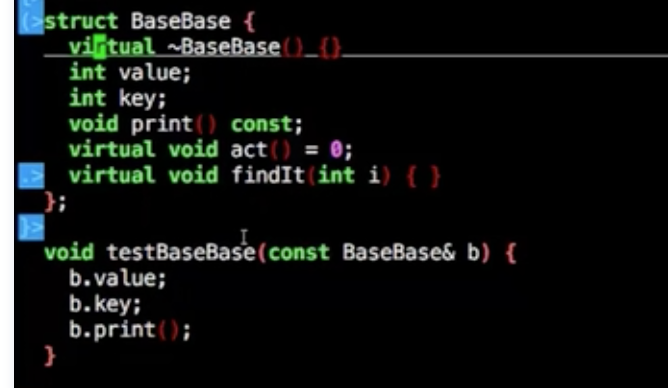
你如果把析构函数隐藏的话,不能使用如下
1 | Base b;//这样的语句是非法的 |
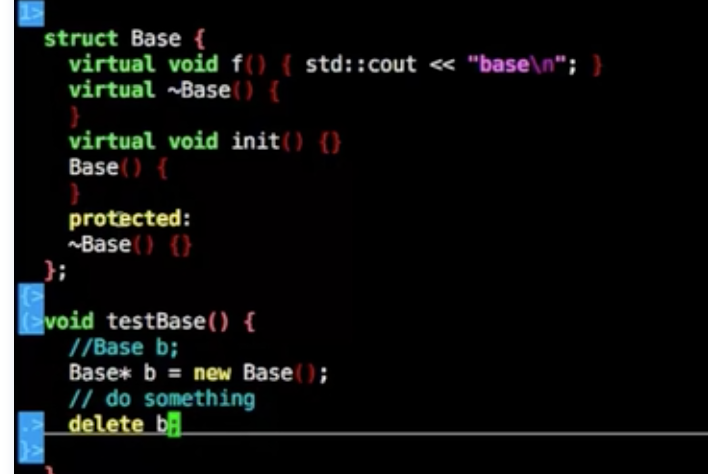
虽然析构函数protected,但是可以在派生类去操作
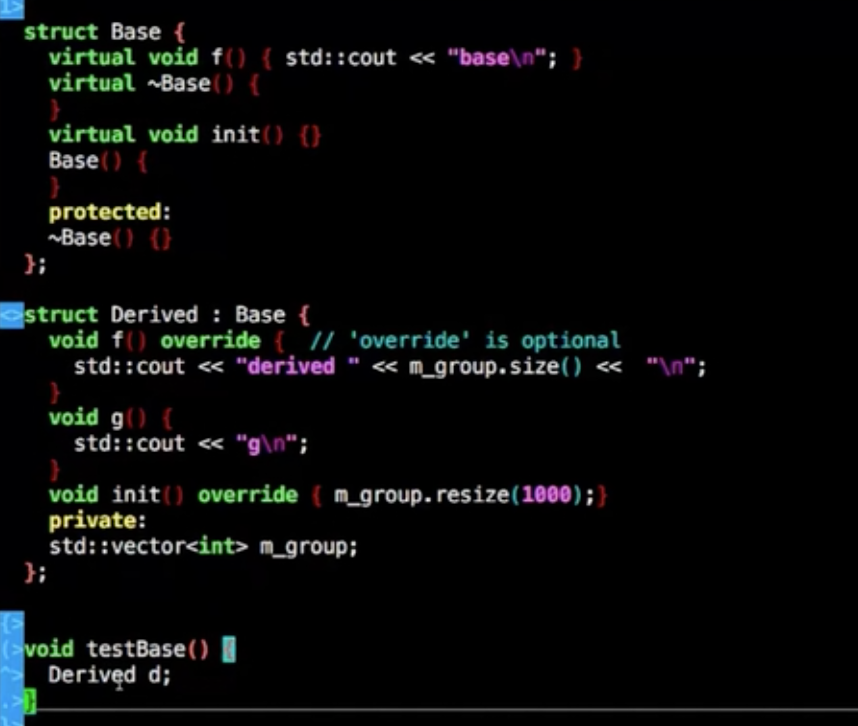
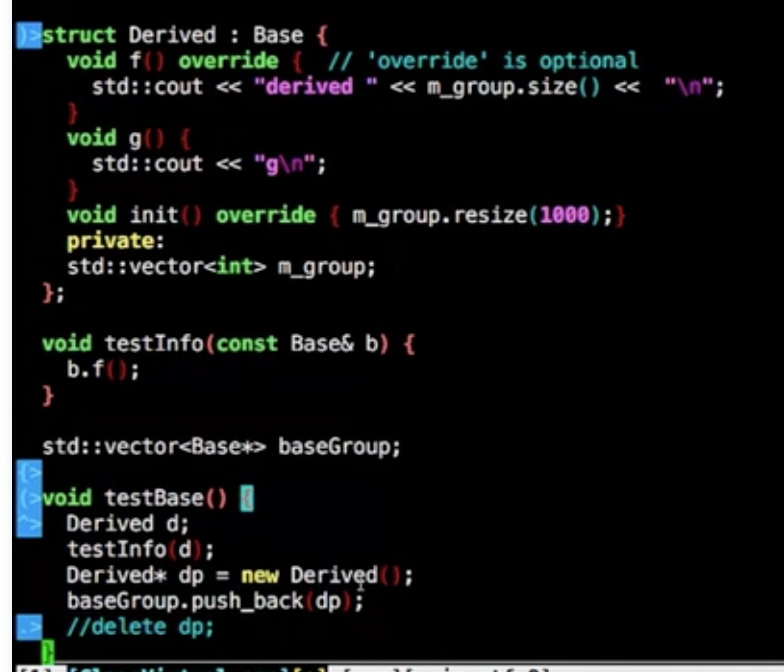
如下的操作将会导致无法释放相关的资源,因为是Base的指针
auto关键字
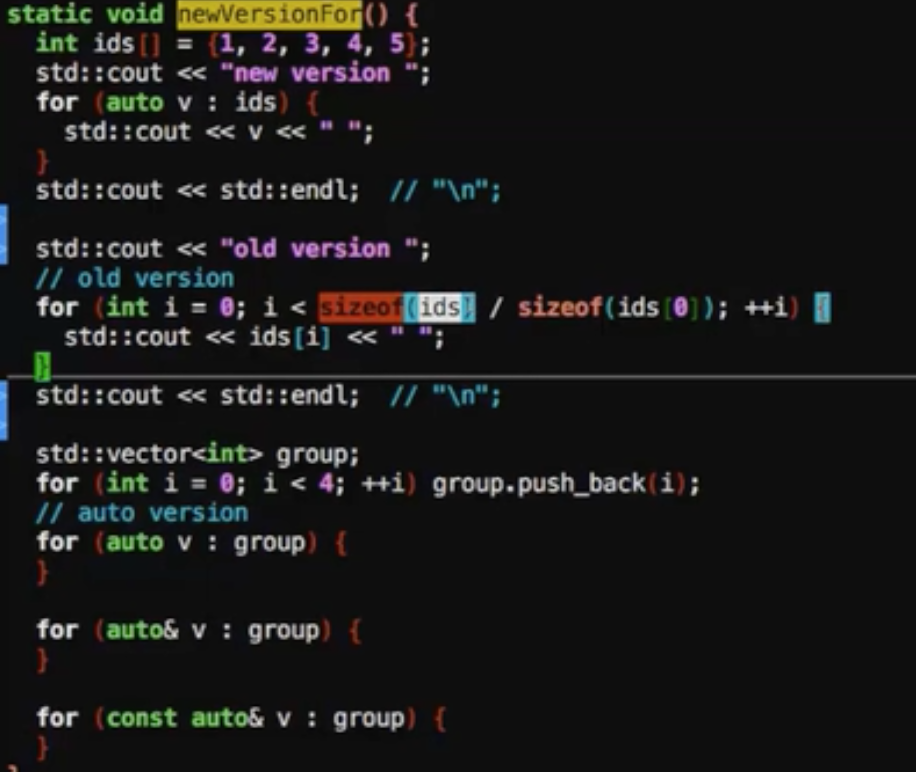
1 | for(auto v:ids){ |
提前将bean和end取出来
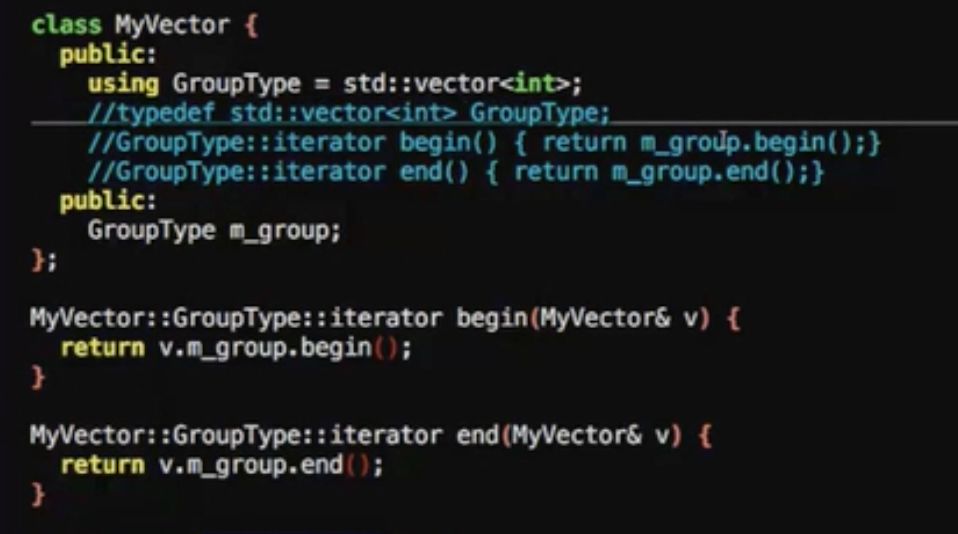
构造
构造相关
1 | class A{ |
默认参数
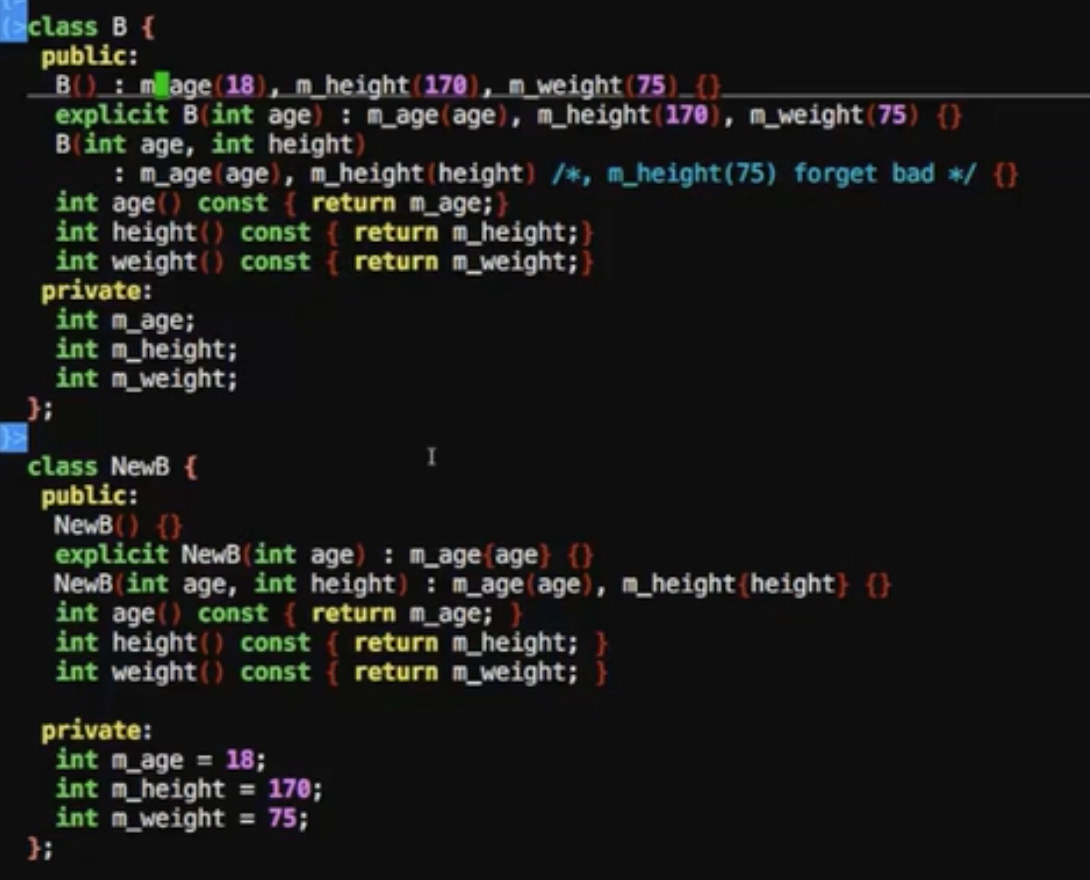
NewB在默认值的直接写到private上,做了这么个优化
在老版本上m_weight就会出现65535的错误值
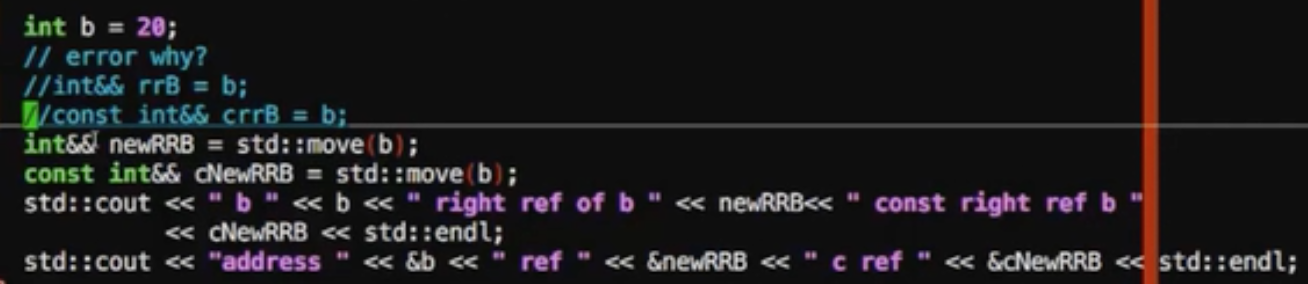
左值引用,右值引用
引用和指针稍微像,但是引用不可能是空的,像给其他变量起了别名,引用还不用开辟指针需要的内存空间
1 | int a = 10; |
内存管理知识
malloc,传入参数需要多大内存,返回值是void*,可以指向任何东西
free,释放对应的指针内存
但是在C++强类型的,malloc返回的是void*,不符合c++规则,而且返回的只是开辟内存空间未经过初始化的构造函数
所以对应c++得有直接的分配内存和资源的方法
new 分配资源调用构造函数
delete 调用析构 释放内存
但是最大的弊端,new忘了delete很容易犯错,设计上就有这个缺陷,程序员很难做出是否要释放的需要
1 | const char* getName(){ |
引入了异常流之后,对内存的管控就更加乱,也很容易出现泄露
为解决内存泄漏,科学家想到的版本
1 | class SafeIntPointer{ |
通过简单的构造和析构,把new和delete给解决掉
SaleIntPointer在单线程虽然正确但是在多线程就出现了问题
因为多线程的情况下,没有同步会多重执行delete m_value
到了c++11的情况下
就有了智能指针std::shared_ptr来管理这个情况了,就不会有这个问题了
shared_ptr常规使用
c++98的auto_ptr不推荐使用,未来的标准还可能要去掉这个
- shared_ptr:每增加一次引用加一,做到指针共享
- unique_ptr:独占,一个指针必须只有一个使用者来使用,不能拥有两个使用者
- weaked_ptr:与shared_ptr搭配使用
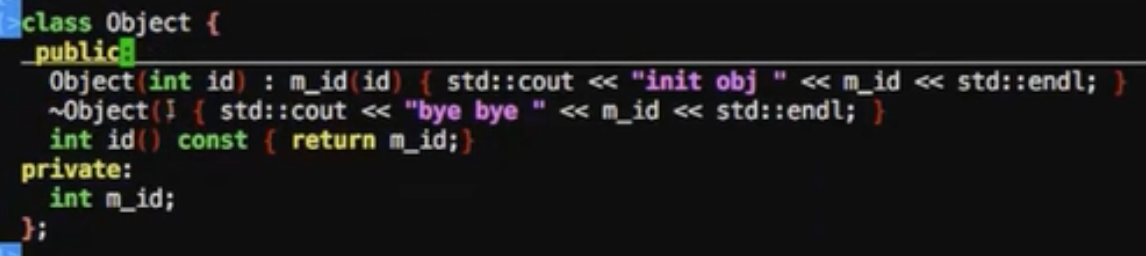
构建一个Object类型的类
1 | typedef std::shared_ptr<Object> ObjectPtr; |
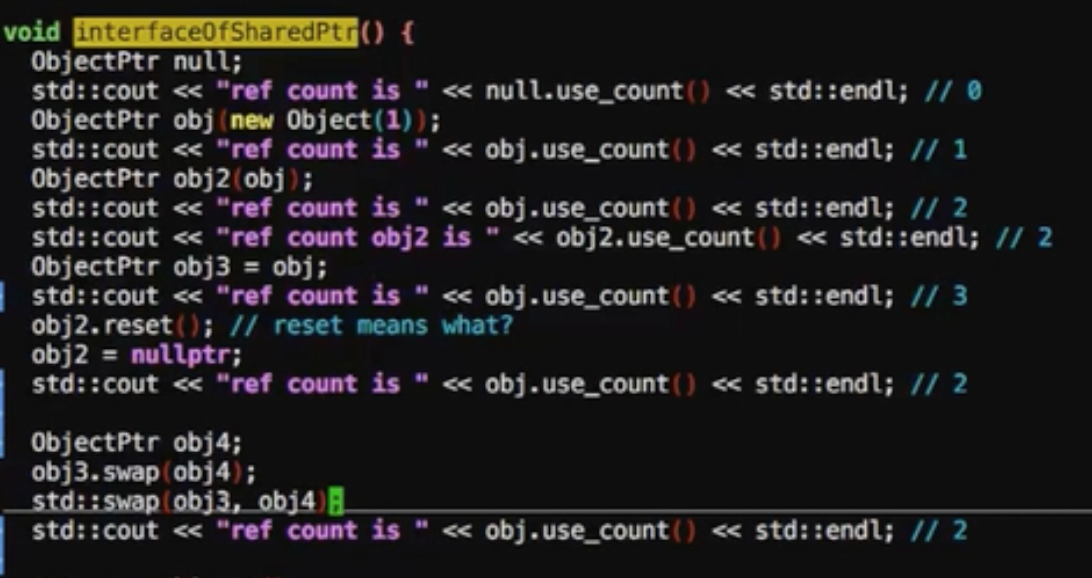
obj3.swap(obj4)//obj3与obj4交换管理的资源或者std::swap(obj3, obj4)
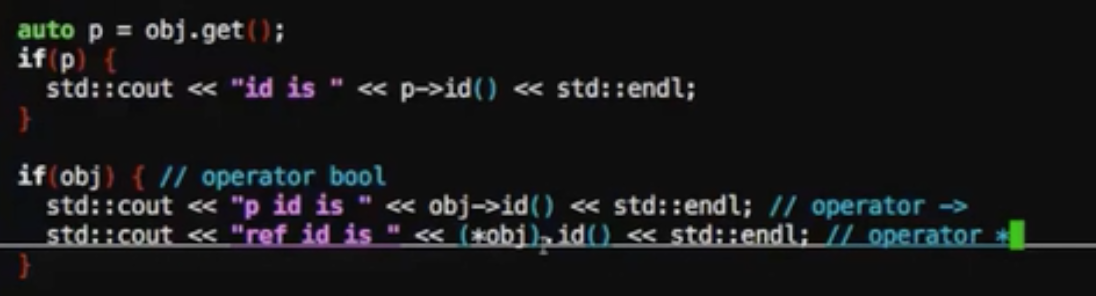
智能指针后期直接用get拿取真实对应的指针资源进行操作
也可以直接拿裸指针用,因为指针指针重载->,*
可通过以下方式减小引用计数
- reset
- obj2 = nullptr
以下可以查询指针是否单独一个调用方使用

如果对智能指针当做函数参数值传入,那么也会对引用+1

所以采用const 引用的方式传入
1 | void printRef(const ObjectPtr& obj){ |
智能指针也可进行专门放入析构的时候清理函数

weak_ptr常规使用
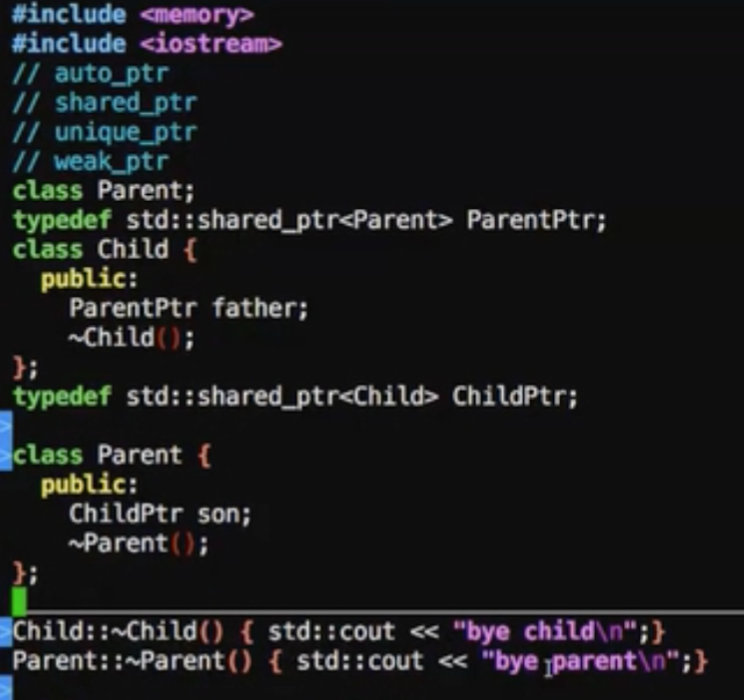
1 | //测试代码 |
输出结果是什么都没输出
该两个析构函数无法调用到
在这里有严重明显的内存泄漏
这时候构造函数再输出一下
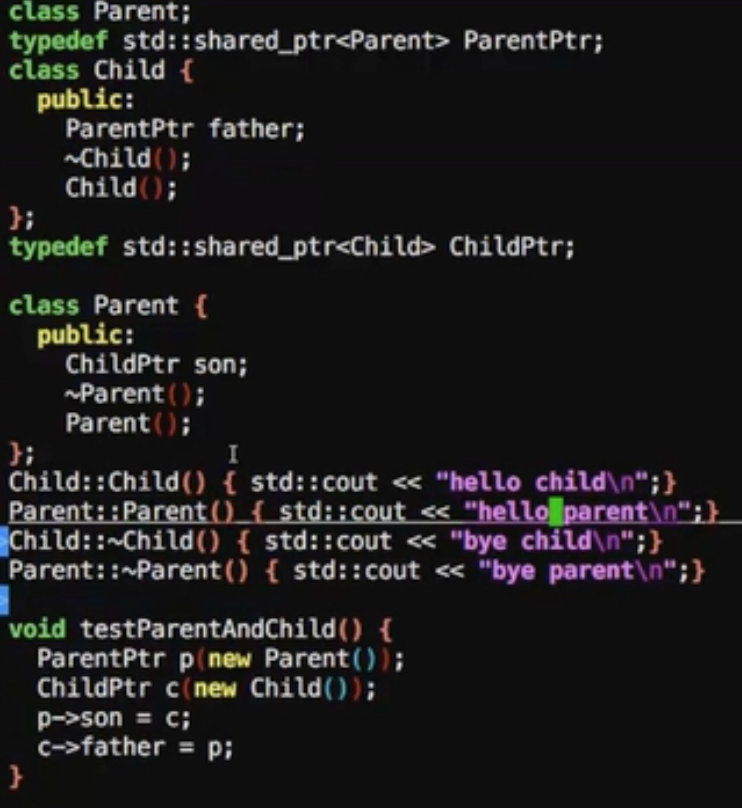
1 | //输出结果,构造函数调用到了 |
通过weak_ptr可以打破这种关系
1 | typedef std::weak_ptr<Object> WeakobjectPtr; |
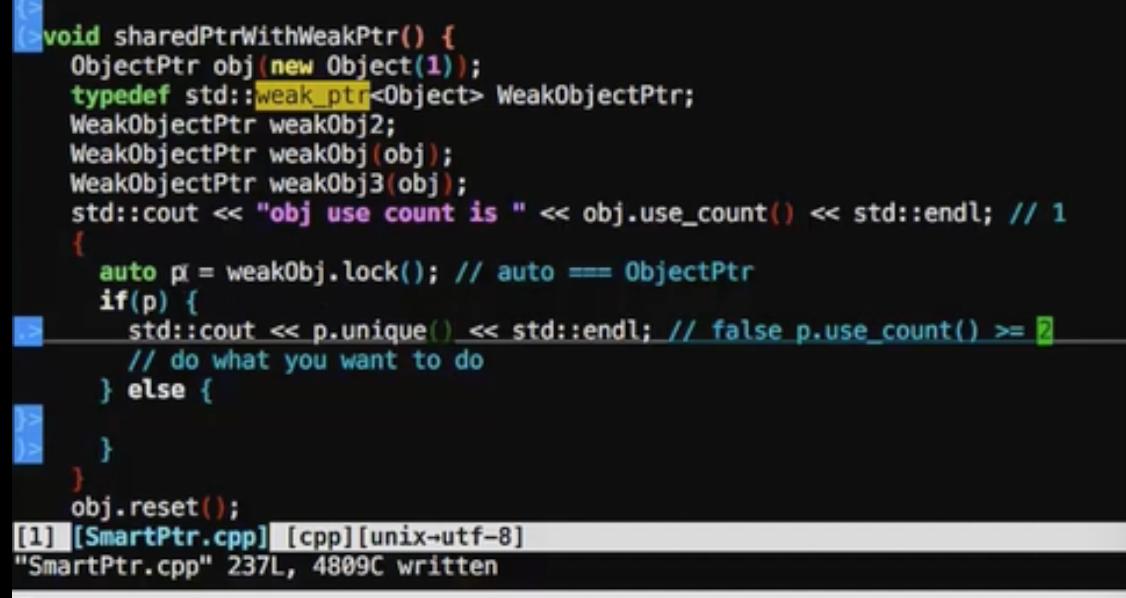
当obj调用reset,所有的调用都直接返回空指针
expired
查询是否过期
查询外部有没有管理一份资源
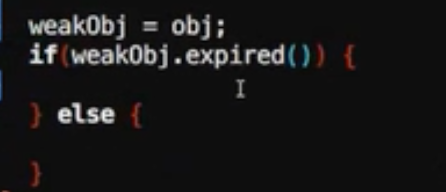
之前的内存泄漏代码就修改如下
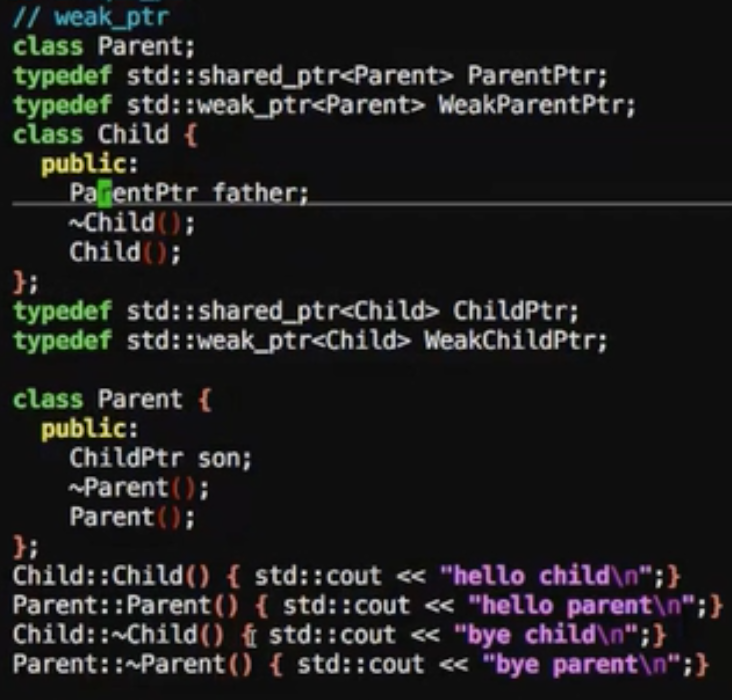
1 |
|
enable_shared_from_this CRTP 奇异递归模板模式
enable_shared_from_this CRTP
bye parent调用了两次析构函数
1 | ParentPtr p(this); |
对象成员属性里有智能指针管理的类型,要传出或者调用的时候
要将对象从enable_shared_from_this派生
从而将
1 | //ParentPtr p(this); |
但是希望不要直接Parent pp;使用出来,因为此类本就派生了enable_shared_from_this是给智能指针来使用的
unique_ptr
1 | typedef std::unique_ptr<Object> UniqueObjectPtr; |
release
unique_ptr的release并不是释放资源,而是将指针的控制权转移给其他智能指针了
reset
1 | ptr1.reset();// 不带任何参数,把以前管理的资源调用析构然后delete |
C++11引入了右值和右值引用
1 | //unique_ptr,在同一时刻只能由一个指针管理资源 |
所以要将unique_ptr进行转移
通过普通传参然后release并且delete
或者std::move()传参
c++11大多数来源于在boost库也方法,还有一个scoped_ptr,类似于unique_ptr
智能指针注意的坑
1 | //不要自己手动管理资源,即不要出现new和delete关键字,malloc&free关键字 |
lambda
1 | void printInfo(int a, int b, int c){ |
lambda c++11,将一个inner函数的定义作为参数或者local对象
1 | inline void print(int a, int b, int c){ |
国内查看评论需要代理~