STL版本情况
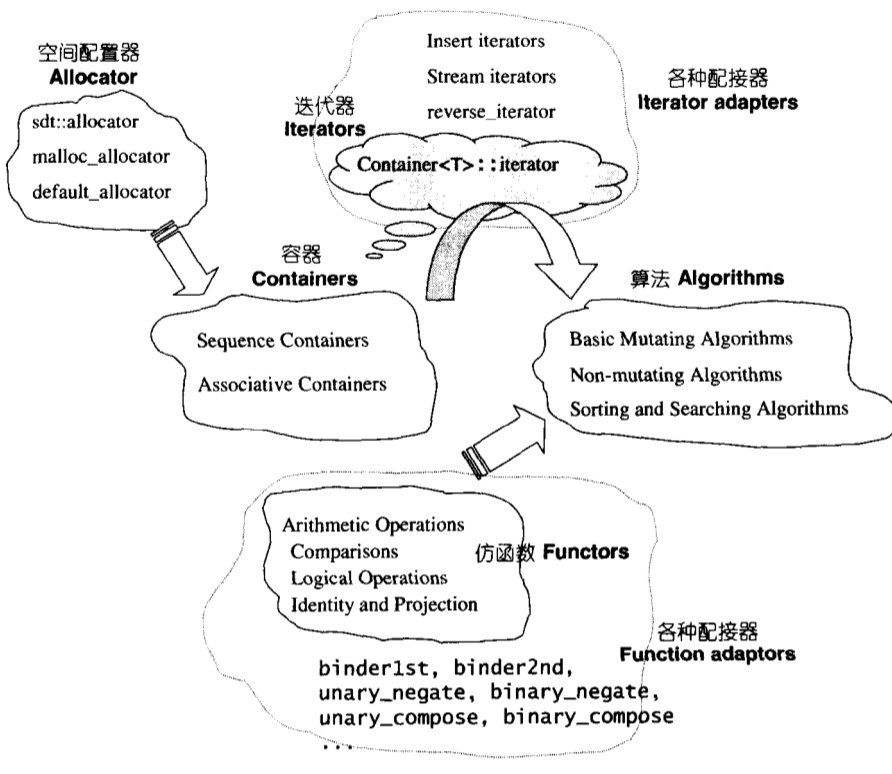
stl是一个框架,将数据结构和算法进一步抽象
容器、迭代器、算法
STL历史
1979年创造C++年代却不支持泛型,第一个支持泛型的是Ada,但Ada在美国国防工业以外未被广泛接受
1987年Alexander开发出Ada Library,接下来看到C++如此火热于是试验了多种架构和算法公式,先以C完成,后再以C++完成
- 1992年Meng Lee加入了Alex的项目成为早期STL另一位主要贡献者
- 1993年贝尔实验室的Andrew Koenig在1993年知道这个研究计划后邀请Alex ander于11月ANSI/ISO c++标准委员会议上展示观念
- 1994年1月25日Alexander完成了提案报告提交到委员会,3月份在圣地亚哥会议,STL活得很好回响,投票结果压倒性给予提案机会
- 1998年STL正式成为9月C++标准规格,原本stream,string以template重写
STL六大组件
容器(containers):各种数据结构(vector,list,deque,set,map)
用以存放数据
算法(algorithms):常用算法如sort,search,copy,erase(抹去)…..
迭代器(iterators):扮演容器和算法之间的胶合剂,所谓的泛型指针
仿函数(functors):行为类似函数,可作为算法的某种策略
配接器(adapter):一种修饰容器或仿函数或迭代器接口的东西
配置器:负责空间配置与管理
GNU开放精神
1 | 全世界所有STL实现版本由Alexander,meng lee完成 |
这种开源精神就是open source
1 | 此开源精神来源于美国人理察.史托曼,他认为私藏源代码是一种违反人性的罪恶行为 |
GNU 代表GNU is Not Unix,Unix是当时计算机界主流操作系统,由AT&T 贝尔实验室创造,原本只是学术型产品,AT&T将它分享给许多研究人员,但是所有研究使得这个产品越来越美好,于是AT&T开始考虑追加投资并要求不得公开或透露UNIX源代码,想从中获利,并赞助伯克利大学继续强化Unix,导致后来发展成BSD以及FreeBSD,OpenBSD,NetBSD
1 | Unix类操作系统:FreeBSD、Solaris、MacOSX这都属于Unix类操作系统。 |
Stallman认为AT&T对大学的赞助只是微薄的施舍,于是进行反奴役计划称之为GNU
GNU早期计划是Gcc和EMacs,一个C/C++编译器,还有一个文本编辑器
GNU计划晚期著名的软件则由1991年芬兰人Linux Torvalds开发的Linux操作系统
GNU以GPL(广泛开放授权)来保护乘员:使用者可以阅读修改GPL软件的源代码,但是使用者要传播借助GPL软件而完成的软件必须遵守GPL规范,这类精神主要强迫人们分享并回馈他们对GPL软件的改善
后期衍生了不同的授权包括:Library GPL,Lesser GPL,Apache License,BSD License等,它们的共同原则就是“开放源代码”
空间配置器(Allocator)
隐藏在一切组件背后,默默工作付出
整个STL操作对象都存放容器,容器需要配置空间存放资源
迭代器(Iterator)
迭代器扮演重要角色,将数据容器和算法分开彼此独立设计,再以胶合剂撮合一起,class template和function templates可分别达成目标
容器(Container)
C++ STL 的实现:
1 | 1.vector 底层数据结构为数组 ,支持快速随机访问 |
序列式容器
- array
- vector
- dequeue
- list
- forward_list
这类都通过数组或者指针链表
关联类容器
- set
- map
- multiset(类似hashset)
- multimap(类似hashmap,第三方库已经起好,为避免冲突不起此类名字)
关联式都是通过二叉树方式实现,set和map默认都是红黑树
无序容器
- unordered_map
- unordered_set
- unordered_multimap
- unordered_multiset
无序容器都是通过hash_table,哈希表
其他重要数据结构:stack,queue,priority_queue
字符串string,也是一个container
如果存入是否布尔值可用位集合:bitset
1 | regex rand |
- 1:容器可以复制(copy)或者搬移(move)(隐含的条件是在拷贝和搬移的过程中没有副作用)
基本数据类型:bool char int double pointer reference function
2:元素可被赋值操作来复制和搬移
3:元素是可销毁的,析构不能使private,而且析构函数不允许抛出异常
对于序列式容器,元素必须有默认的构造函数
对于某些操作,元素需要定义== std::find
对于关联式容器,排序准则默认是<, > std::less
无顺序容器,必须要提供一个hash函数 也需要==符号
1 | > stl容器里面存的是元素的值而不是引用? |
总结
向量(vector)连续存储的元素
列表(list) 由节点组成的双向链表,每个结点包含着一个元素
双队列(deque) 连续存储的指向不同元素的指针所组成的数组
集合(set) 由节点组成的红黑树,每个节点都包含着一个元素,节点之间以某种作用于元素对的谓词排列,没有两个不同的元素能够拥有相同的次序
多重集合(multiset) 允许存在两个次序相等的元素的集合
栈(stack) 后进先出的值的排列
队列(queue) 先进先出的执的排列
优先队列(priority_queue) 元素的次序是由作用于所存储的值对上的某种谓词决定的的一种队列
映射(map) 由{** const 键,值}**对组成的集合,以某种作用于键对上的谓词排列
多重映射(multimap) 允许键对有相等的次序的映射
容器通用接口
类接口编程通过模板或者类派生
1 | tempalte <typename T> |
array
array 是固定大小的顺序容器,它们保存了一个以严格的线性顺序排列的特定数量的元素。
| 方法 | 含义 |
|---|---|
| begin | 返回指向数组容器中第一个元素的迭代器 |
| end | 返回指向数组容器中最后一个元素之后的理论元素的迭代器 |
| rbegin | 返回指向数组容器中最后一个元素的反向迭代器 |
| rend | 返回一个反向迭代器,指向数组中第一个元素之前的理论元素 |
| cbegin | 返回指向数组容器中第一个元素的常量迭代器(const_iterator) |
| cend | 返回指向数组容器中最后一个元素之后的理论元素的常量迭代器(const_iterator) |
| crbegin | 返回指向数组容器中最后一个元素的常量反向迭代器(const_reverse_iterator) |
| crend | 返回指向数组中第一个元素之前的理论元素的常量反向迭代器(const_reverse_iterator) |
| size | 返回数组容器中元素的数量 |
| max_size | 返回数组容器可容纳的最大元素数 |
| empty | 返回一个布尔值,指示数组容器是否为空 |
| operator[] | 返回容器中第 n(参数)个位置的元素的引用 |
| at | 返回容器中第 n(参数)个位置的元素的引用 |
| front | 返回对容器中第一个元素的引用 |
| back | 返回对容器中最后一个元素的引用 |
| data | 返回指向容器中第一个元素的指针 |
| fill | 用 val(参数)填充数组所有元素 |
| swap | 通过 x(参数)的内容交换数组的内容 |
| get(array) | 形如 std::get<0>(myarray);传入一个数组容器,返回指定位置元素的引用 |
| relational operators (array) | 形如 arrayA > arrayB;依此比较数组每个元素的大小关系 |
1 |
|
迭代器
1 | data.begin(); |
元素访问
1 | //直接拿某个元素, array直接取下标 |
array是固定大小,无法进行插入元素操作
vector
vector 是表示可以改变大小的数组的序列容器。
| 方法 | 含义 |
|---|---|
| vector | 构造函数 |
| ~vector | 析构函数,销毁容器对象 |
| operator= | 将新内容分配给容器,替换其当前内容,并相应地修改其大小 |
| begin | 返回指向容器中第一个元素的迭代器 |
| end | 返回指向容器中最后一个元素之后的理论元素的迭代器 |
| rbegin | 返回指向容器中最后一个元素的反向迭代器 |
| rend | 返回一个反向迭代器,指向中第一个元素之前的理论元素 |
| cbegin | 返回指向容器中第一个元素的常量迭代器(const_iterator) |
| cend | 返回指向容器中最后一个元素之后的理论元素的常量迭代器(const_iterator) |
| crbegin | 返回指向容器中最后一个元素的常量反向迭代器(const_reverse_iterator) |
| crend | 返回指向容器中第一个元素之前的理论元素的常量反向迭代器(const_reverse_iterator) |
| size | 返回容器中元素的数量 |
| max_size | 返回容器可容纳的最大元素数 |
| resize | 调整容器的大小,使其包含 n(参数)个元素 |
| capacity | 返回当前为 vector 分配的存储空间(容量)的大小 |
| empty | 返回 vector 是否为空 |
| reserve | 请求 vector 容量至少足以包含 n(参数)个元素 |
| shrink_to_fit | 要求容器减小其 capacity(容量)以适应其 size(元素数量) |
| operator[] | 返回容器中第 n(参数)个位置的元素的引用 |
| at | 返回容器中第 n(参数)个位置的元素的引用 |
| front | 返回对容器中第一个元素的引用 |
| back | 返回对容器中最后一个元素的引用 |
| data | 返回指向容器中第一个元素的指针 |
| assign | 将新内容分配给 vector,替换其当前内容,并相应地修改其 size |
| push_back | 在容器的最后一个元素之后添加一个新元素 |
| pop_back | 删除容器中的最后一个元素,有效地将容器 size 减少一个 |
| insert | 通过在指定位置的元素之前插入新元素来扩展该容器,通过插入元素的数量有效地增加容器大小 |
| erase | 从 vector 中删除单个元素(position)或一系列元素([first,last)),这有效地减少了被去除的元素的数量,从而破坏了容器的大小 |
| swap | 通过 x(参数)的内容交换容器的内容,x 是另一个类型相同、size 可能不同的 vector 对象 |
| clear | 从 vector 中删除所有的元素(被销毁),留下 size 为 0 的容器 |
| emplace | 通过在 position(参数)位置处插入新元素 args(参数)来扩展容器 |
| emplace_back | 在 vector 的末尾插入一个新的元素,紧跟在当前的最后一个元素之后 |
| get_allocator | 返回与vector关联的构造器对象的副本 |
| swap(vector) | 容器 x(参数)的内容与容器 y(参数)的内容交换。两个容器对象都必须是相同的类型(相同的模板参数),尽管大小可能不同 |
| relational operators (vector) | 形如 vectorA > vectorB;依此比较每个元素的大小关系 |
vector是c++98中引入的动态数组
特点随机访问元素,末端添加删除元素效率非常高
但是前端和中间效率低下,当超过容器容量会重新分配
初始化
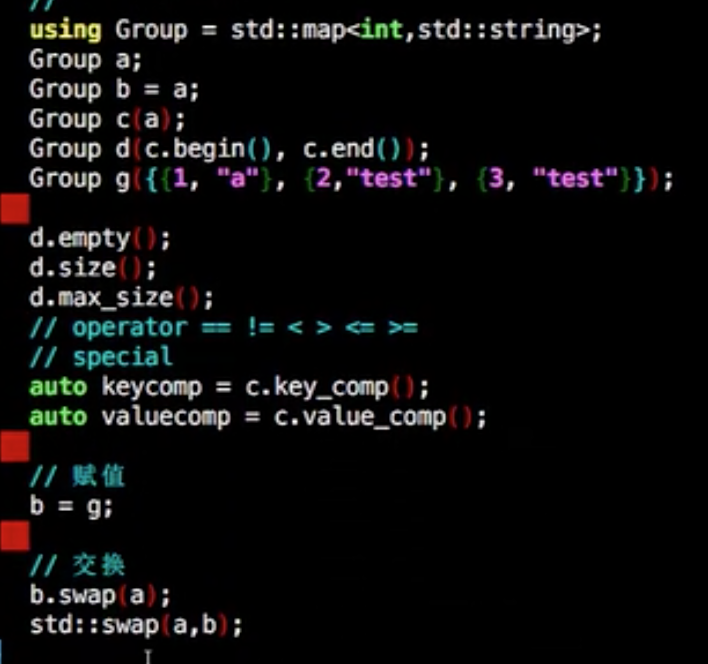
1 | using Group = std::vector<float>; |
通用接口
1 | d.empty(); |
赋值
1 | b = g; |
交换
1 | b.swap(a); //vector 高效且不抛出异常,对于container除了array,其他的交换全都是交换指针,把内容全部交换过来 |
元素访问
1 | b[0]; |
移除新增
1 | //移除 |
迭代器
1 | data.begin(); |
vector异常
- push_back发生异常对vector不会变化
- pop_back绝对不会出现异常
- 元素move/copy没有异常的话, erase insert emplace emplace_back push_back不会有异常
- swap clear 不会有异常
vector不要用bool
deque
deque([‘dek])(双端队列)是double-ended queue 的一个不规则缩写。deque是具有动态大小的序列容器,可以在两端(前端或后端)扩展或收缩。
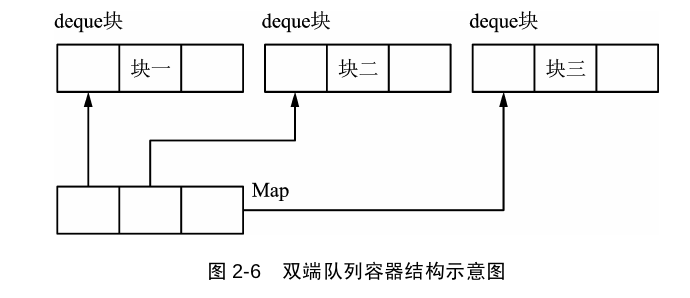
1 | deque和vector一样,采用线性表,与vector唯一不同的是,deque采用的分块的线性存储结构 |
| 方法 | 含义 |
|---|---|
| deque | 构造函数 |
| push_back | 在当前的最后一个元素之后 ,在 deque 容器的末尾添加一个新元素 |
| push_front | 在 deque 容器的开始位置插入一个新的元素,位于当前的第一个元素之前 |
| pop_back | 删除 deque 容器中的最后一个元素,有效地将容器大小减少一个 |
| pop_front | 删除 deque 容器中的第一个元素,有效地减小其大小 |
| emplace_front | 在 deque 的开头插入一个新的元素,就在其当前的第一个元素之前 |
| emplace_back | 在 deque 的末尾插入一个新的元素,紧跟在当前的最后一个元素之后 |
deque是c++98引入的动态数组(dynamic array)
1 | namespaces std{ |
特点随机访问元素
末端和头部添加删除元素效率高,中间删除和添加元素效率低
元素的访问和迭代比vector要慢,迭代器不能使普通的指针
通用接口
1 | d.empty(); |
赋值
1 | b = g; |
交换
1 | b.swap(a); //类似vector |
元素访问
1 | b[0]; |
大多数功能和vector类似
deque的clear是释放空间的
移除新增
1 | //移除 |
迭代器
1 | data.begin(); |
forward_list
forward_list(单向链表)是序列容器,允许在序列中的任何地方进行恒定的时间插入和擦除操作。
| 方法 | 含义 |
|---|---|
| forward_list | 返回指向容器中第一个元素之前的位置的迭代器 |
| cbefore_begin | 返回指向容器中第一个元素之前的位置的 const_iterator |
特点几乎跟list一致,不支持随机访问函数,访问头部速度快
特点不支持随机访问元素,访问头部元素速度快
forward_list和自己手写的C-style singly linked list相比
没有任何时间和空间上的额外开销,任何性质如果和这个目标抵触,我们放弃该特征
任何位置插入删除元素都很快,常量时间完成
插入和删除不会造成迭代器失效
对于异常支持的好,出现异常对于forward_list而言,要不成功,要不什么影响没有
构造函数
1 | using Group = std::forward_list<float>; |
迭代器
1 | data.begin(); |
新增移除
1 | //移除 |
其他函数
1 | auto iterBegin = a.begin(); |
算法
1 | b.remove(1.0f); |
list
list,双向链表,是序列容器,允许在序列中的任何地方进行常数时间插入和擦除操作,并在两个方向上进行迭代。
c++98引入,双向串联
不支持随机访问函数,访问头部和尾部速度快
在任何位置插入删除元素都很快,常量时间完成
插入和删除不会造成迭代器失效
对于异常支持的好,出现异常对于list而言,要不成功,要不什么影响没有
构造函数
1 | using Group = std::list<float>; |
迭代器
1 | data.begin(); |
新增移除
1 | //移除 |
其他函数
1 | auto iterBegin = a.begin(); |
算法
1 | b.remove(1.0f); |
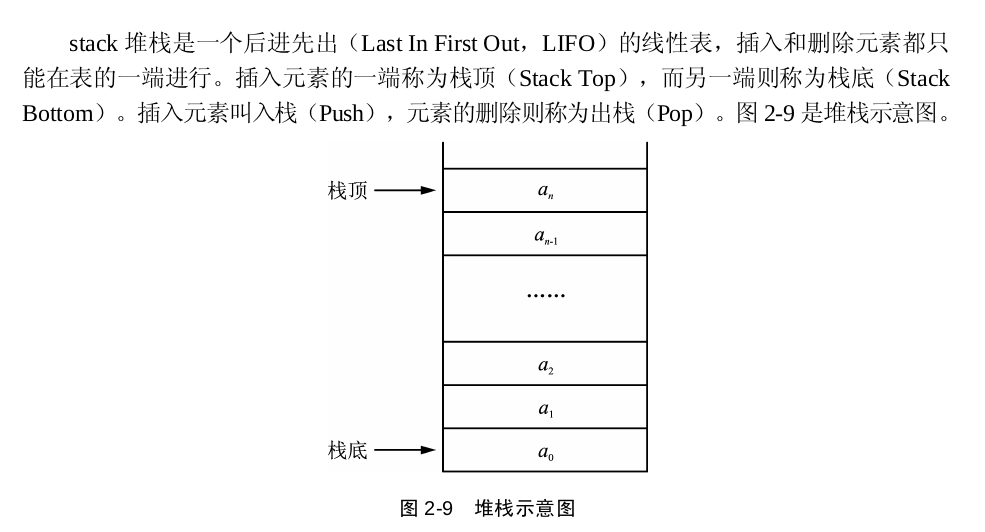
stack
stack 是一种容器适配器,用于在LIFO(后进先出)的操作,其中元素仅从容器的一端插入和提取。
结构
queue
queue 是一种容器适配器,用于在FIFO(先入先出)的操作,其中元素插入到容器的一端并从另一端提取。
结构
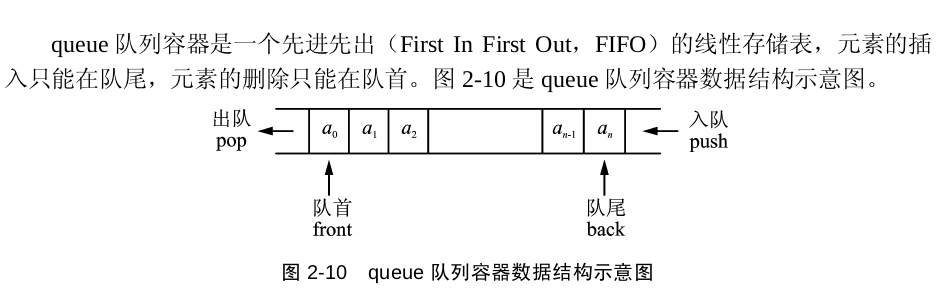
queue有入队push(插入)、出队pop(删除)、读取队首元素front、读取队尾元素back、empty,size这几种方法
priority_queue
示例
1 |
|
set
set 是按照特定顺序存储唯一元素的容器。
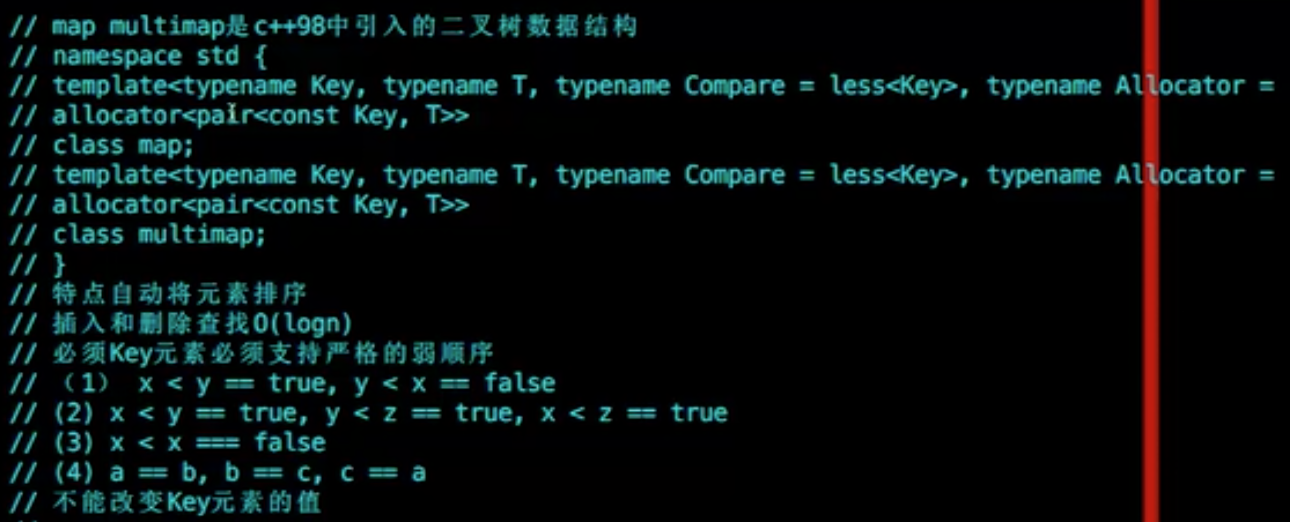
是c++98的二叉树数据结构,红黑树结构
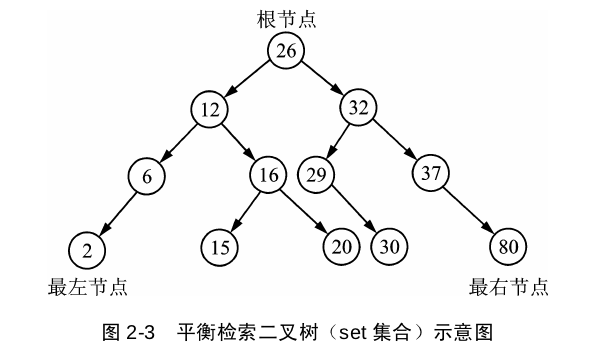
特点
元素自动排序
插入和删除查找,O(logN) 1000次查找只需要20
元素必须支持严格的弱顺序
1
2
3
4
5//1: x < y == true, y < x == false
//2: X < Y == true, y < z ==true, x < z == true
//3: x < x == false
//4: a == b, b == c, c == a
//不能改变元素的值
辅助类
1 | namespace std{ |
构造
1 | using Group = std::set<float>; |
迭代器
1 | // 迭代器 |
算法
1 | //算法 |
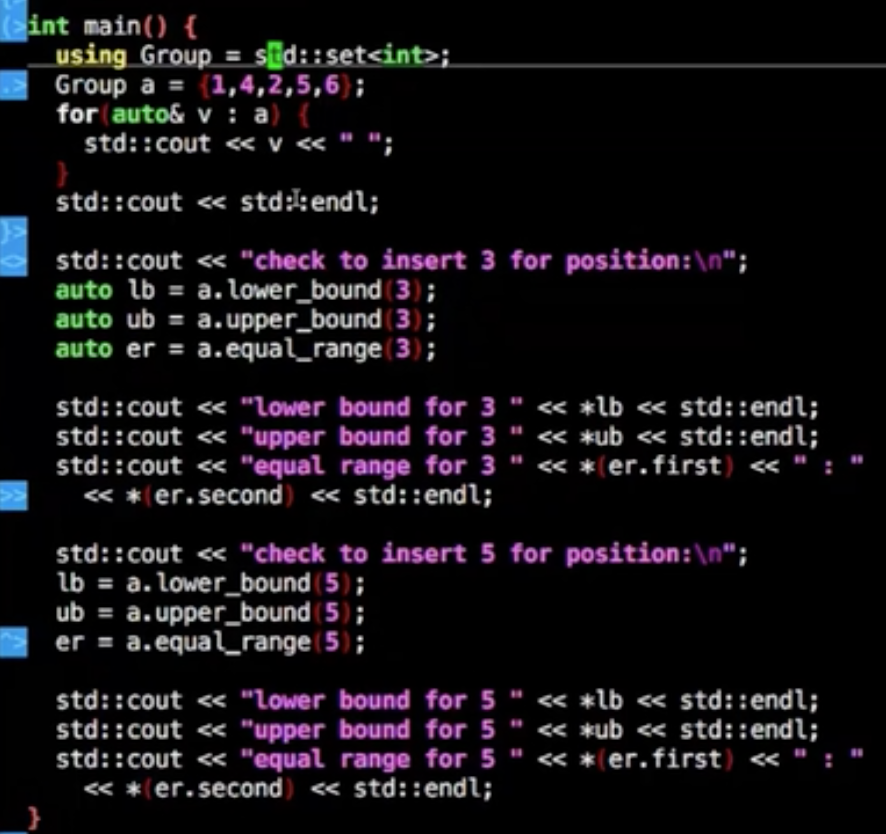
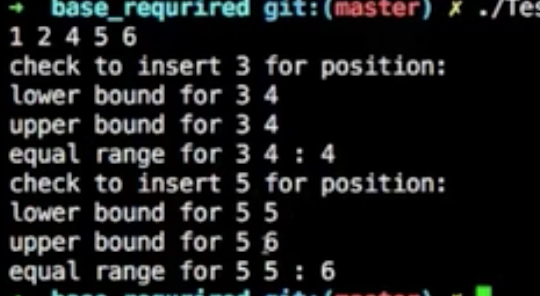
示例
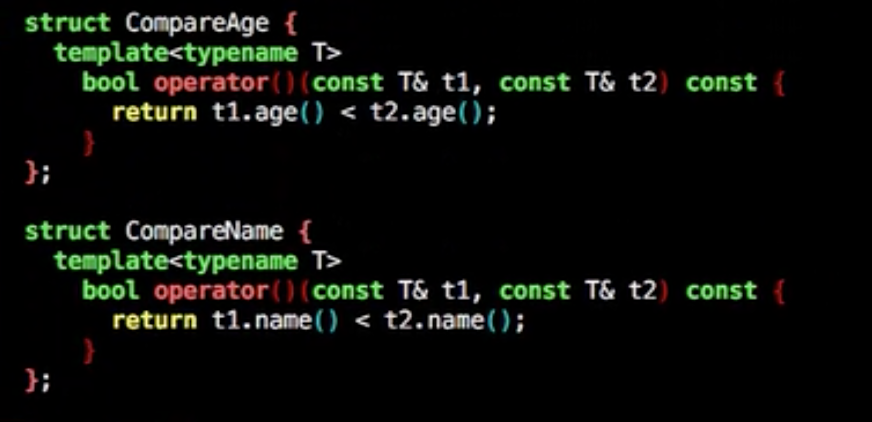
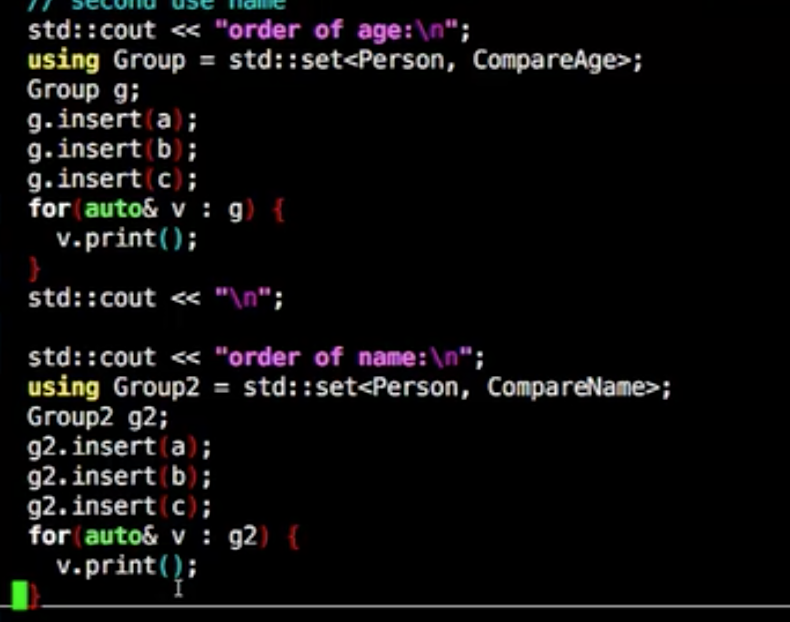
multiset
是c++98的二叉树数据结构
结构
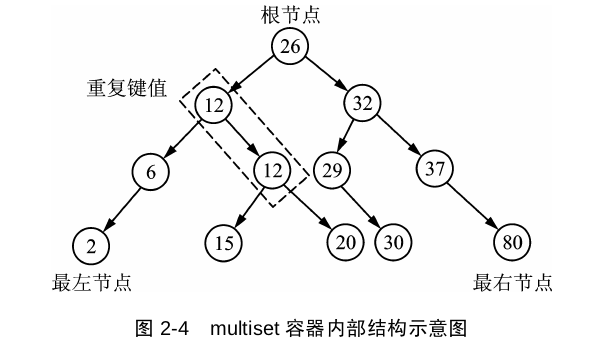
map
map 是关联容器,按照特定顺序存储由 key value (键值) 和 mapped value (映射值) 组合形成的元素。红黑树结构
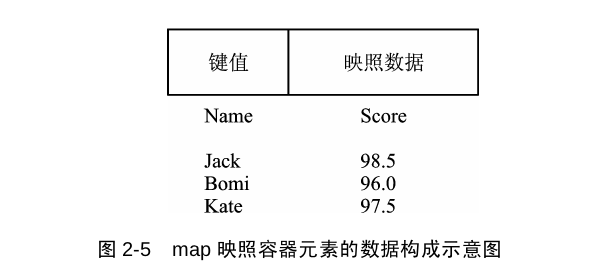
set,multisets,map,multimap使用相同的内部结构,因此可以将set和multiset当成特殊的map和multimap,只不过set的value和key指向的是同一元素
| 方法 | 含义 |
|---|---|
| map | 构造函数 |
| begin | 返回引用容器中第一个元素的迭代器 |
| key_comp | 返回容器用于比较键的比较对象的副本 |
| value_comp | 返回可用于比较两个元素的比较对象,以获取第一个元素的键是否在第二个元素之前 |
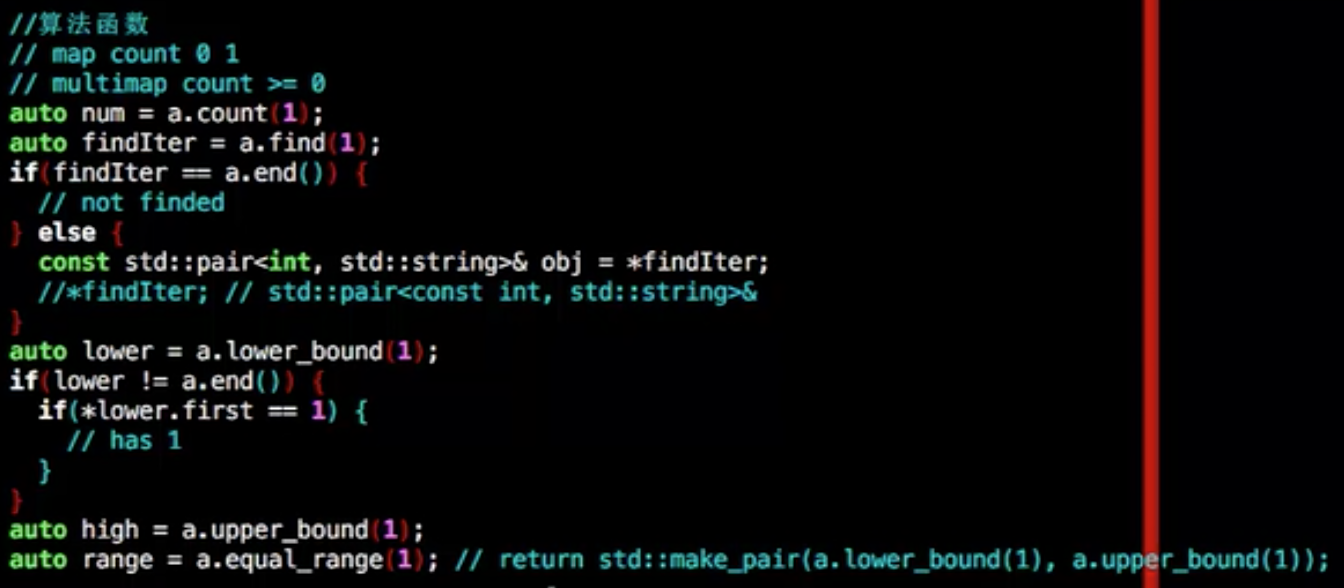
| find | 在容器中搜索具有等于 k(参数)的键的元素,如果找到则返回一个迭代器,否则返回 map::end 的迭代器 |
| count | 在容器中搜索具有等于 k(参数)的键的元素,并返回匹配的数量 |
| lower_bound | 返回一个非递减序列 [first, last)(参数)中的第一个大于等于值 val(参数)的位置的迭代器 |
| upper_bound | 返回一个非递减序列 [first, last)(参数)中第一个大于 val(参数)的位置的迭代器 |
| equal_range | 获取相同元素的范围,返回包含容器中所有具有与 k(参数)等价的键的元素的范围边界(pair< map<char,int>::iterator, map<char,int>::iterator >) |
特点
key是const的key
构造
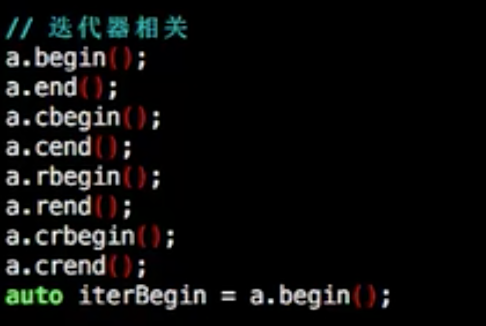
迭代器
算法
示例
1 | // cont/mapl.cpp |
1 | stock: BASF price: 369.5 |
multimap
简介
C++ stl Multimap 和C++ stl map 很相似,但是MultiMap允许重复的元素。
map和multimap会根据key对元素进行自动排序,所以根据key值搜寻某个元素具有良好的性能,但是如果根据value来搜寻效率就很低了。
同样,自动排序使得你不能直接改变元素的key,因为这样会破坏正确次序,要修改元素的key,必须先移除拥有key的元素,然后插入拥有新的key/value的元素,从迭代器的观点来看,元素的key是常数,元素的value是可以直接修改的。
C++ stl Multimap的基本操作类成员函数列表介绍如下:
1 | begin()返回指向第一个元素的迭代器 |
示例
1 | // cont/mmap1.cpp |
输出
1 | english german |
unordered_set
unordered_set与与unordered_map相似
unordered_set它的实现基于hashtable,它的结构图仍然可以用下图表示,这时的空白格不在是单个value,而是set中的key与value的数据包
有unordered_set就一定有unordered_multiset.跟set和multiset一样,一个key可以重复一个不可以
结构
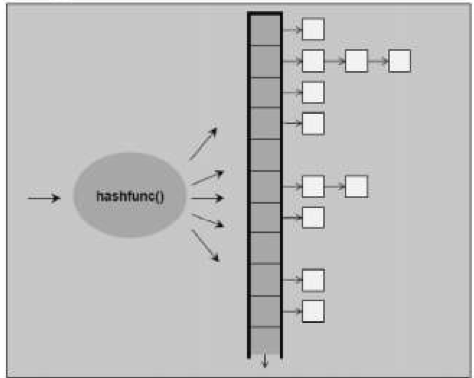
unordered_set是一种无序集合,既然跟底层实现基于hashtable那么它一定拥有快速的查找和删除,添加的优点.基于hashtable当然就失去了基于rb_tree的自动排序功能
unordered_set无序,所以在迭代器的使用上,set的效率会高于unordered_set
基本操作
1 | //定义 |
示例
1 |
|
unordered_multiset
简介
不排序的关联容器类,key和value为相同值,key不需要唯一。支持forward迭代器。
unordered_map
简介
unordered_set、unodered_multiset、unordered_map、unodered_multimap都是无序容器,都是以哈希表实现的。
因为用了hashtable所以查找,插入,删除时间复杂为1
效率惊人
元素是无序的,如果是要按照一定顺序遍历则不能提供
可能空间使用上会比红黑树之前的map用的多一点
元素在一千万以下set的性能不能unordered_set,但是基于一千万以上
unordered_set性能却不如set,因为key会用重复,所以要调整
一般存玩家信息和玩家物品能达到百万级已经不得了,如果得顺序不需要建议还是用上unordered无序容器
1 | using Group = std::unordered_map<int std::string>; |
带上hash算法
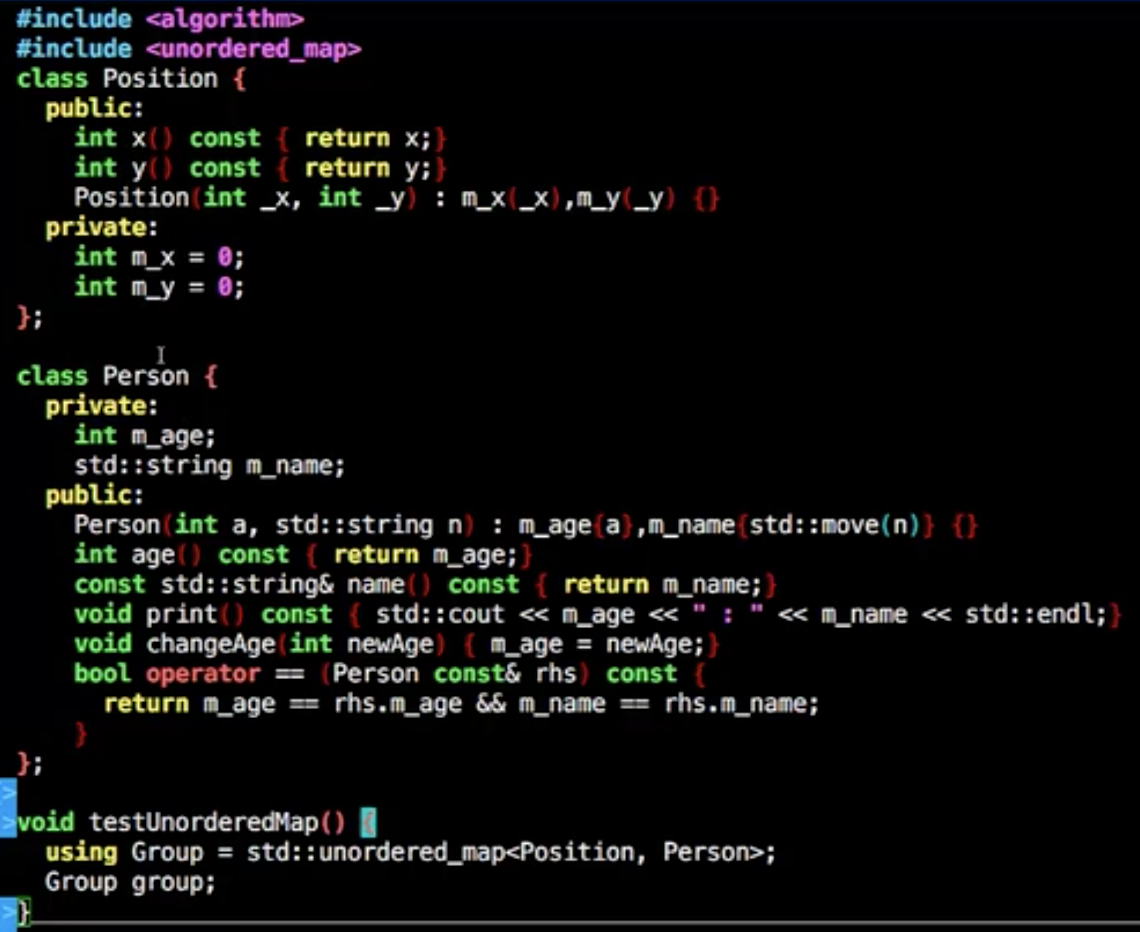
需要做个模板特化
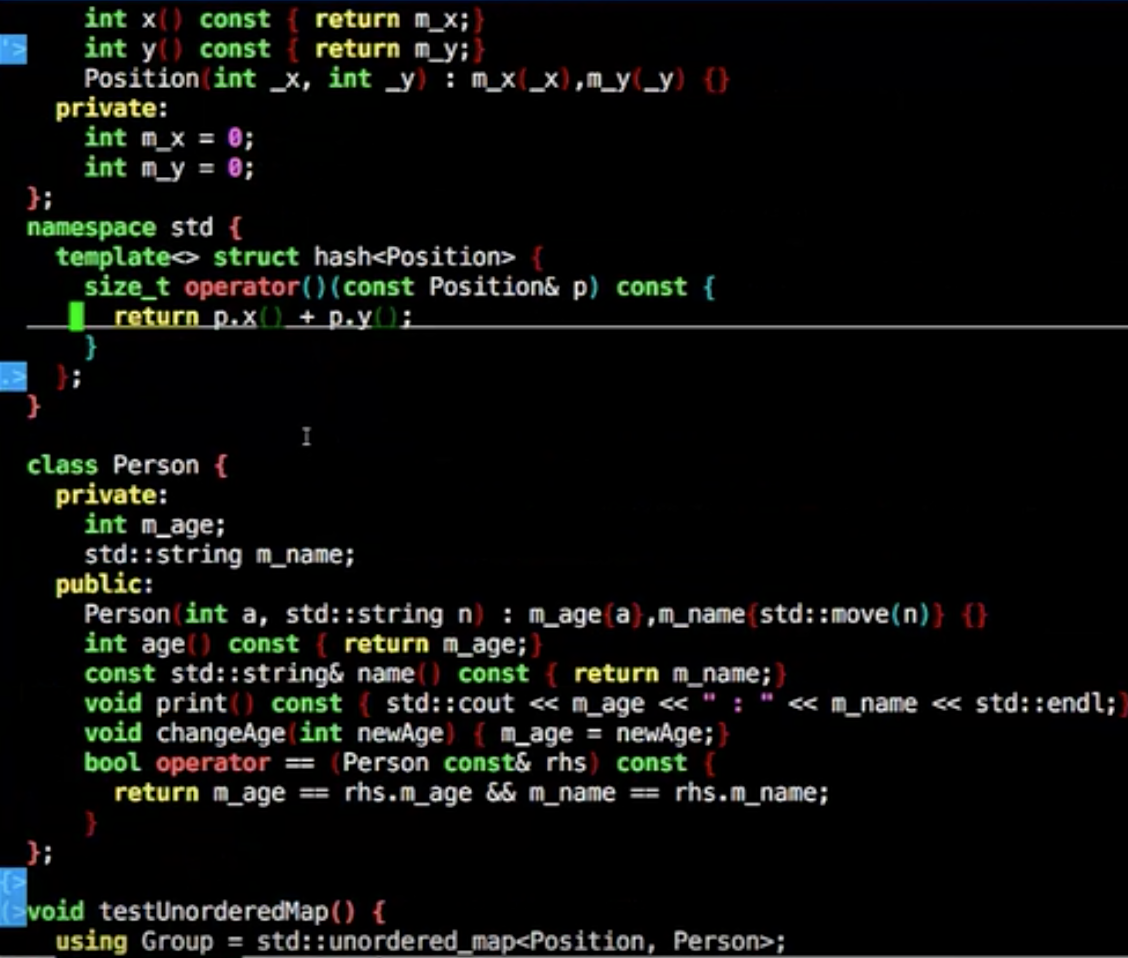
要带上这个hash
1 | namespace std{ |
unordered_multimap
简介
unordered_set、unodered_multiset、unordered_map、unodered_multimap都是无序容器,都是以哈希表实现的。
tuple
元组是一个能够容纳元素集合的对象。每个元素可以是不同的类型。
算法(Algorithms)
1 | // 简单查找算法,要求输入迭代器(input iterator) |
国内查看评论需要代理~