简介
Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核。
Mesos最初是由加州大学伯克利分校的AMPLab开发的,后在Twitter得到广泛使用。
组件
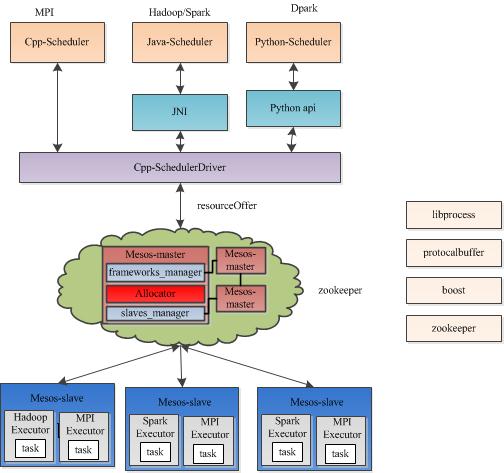
Mesos-master
Mesos master,主要负责管理各个framework和slave,并将slave上的资源分配给各个framework
Mesos-master是整个系统的核心,负责管理接入mesos的各个framework(由frameworks_manager管理)和slave(由slaves_manager管理),并将slave上的资源按照某种策略分配给framework(由独立插拔模块Allocator管理)。
Mesos-slave
Mesos slave,负责管理本节点上的各个mesos-task,比如:为各个executor分配资源
Mesos-slave负责接收并执行来自mesos-master的命令、管理节点上的mesos-task,并为各个task分配资源。
mesos-slave将自己的资源量发送给mesos-master,由mesos-master中的Allocator模块决定将资源分配给哪个framework
当前考虑的资源有CPU和内存两种,也就是说,mesos-slave会将CPU个数和内存量发送给mesos-master
而用户提交作业时,需要指定每个任务需要的CPU个数和内存量,这样,当任务运行时,mesos-slave会将任务放到包含固定资源的linux container中运行,以达到资源隔离的效果。
很明显,master存在单点故障问题,为此,mesos采用了zookeeper解决该问题。
Framework
计算框架,如:Hadoop,Spark等,通过MesosSchedulerDiver接入Mesos
Framework是指外部的计算框架,如Hadoop,Mesos等,这些计算框架可通过注册的方式接入Mesos,以便mesos进行统一管理和资源分配。
Mesos要求可接入的框架必须有一个调度器模块,该调度器负责框架内部的任务调度。
当一个Framework想要接入Mesos时,需要修改自己的调度器,以便向mesos注册,并获取Mesos分配给自己的资源。
这样再由自己的调度器将这些资源分配给框架中的任务,也就是说,整个mesos系统采用了双层调度框架:第一层,由mesos将资源分配给框架;第二层,框架自己的调度器将资源分配给自己内部的任务。
当前Mesos支持三种语言编写的调度器,分别是C++,java和python,为了向各种调度器提供统一的接入方式,Mesos内部采用C++实现了一个MesosSchedulerDriver(调度器驱动器)
Framework的调度器可调用该driver中的接口与Mesos-master交互,完成一系列功能(如注册,资源分配等)。
Executor
执行器,安装到mesos-slave上,用于启动计算框架中的task。
Executor主要用于启动框架内部的task。
由于不同的框架,启动task的接口或者方式不同,当一个新的框架要接入mesos时,需要编写一个executor,告诉mesos如何启动该框架中的task。
为了向各种框架提供统一的执行器编写方式,Mesos内部采用C++实现了一个MesosExecutorDiver(执行器驱动器),framework可通过该驱动器的相关接口告诉mesos启动task的方法。
当用户试图添加一种新的计算框架到Mesos中时,需要实现一个
Framework scheduler和executor以接入Mesos。
Mesos流程
流程简介
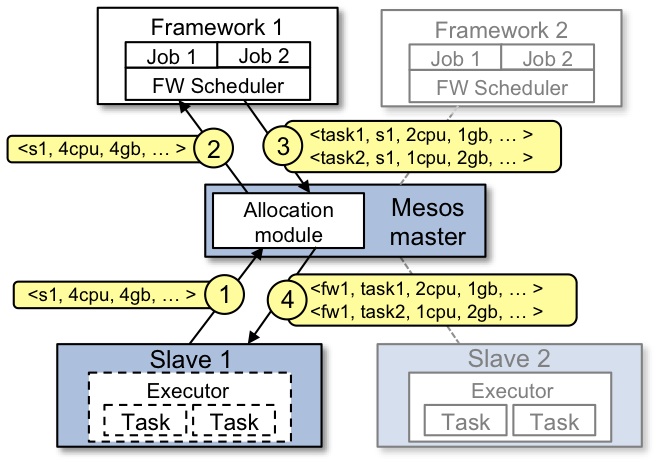
Slave是运行在物理或虚拟服务器上的Mesos守护进程,是Mesos集群的一部分。
Framework由调度器(Scheduler)应用程序和任务执行器(Executor)组成,被注册到Mesos以使用Mesos集群中的资源。
- Slave 1向Master汇报其空闲资源:4个CPU、4GB内存。然后,Master触发分配策略模块,得到的反馈是Framework 1要请求全部可用资源。
- Master向Framework 1发送资源邀约,描述了Slave 1上的可用资源。
- Framework的调度器(Scheduler)响应Master,需要在Slave上运行两个任务,第一个任务分配<2CPUs,1GB-RAM>资源,第二个任务分配<1CPUs,2GB-RAM>资源。
- 最后,Master向Slave下发任务,分配适当的资源给Framework的任务执行器(Executor),接下来由执行器启动这两个任务(如图中虚线框所示)。此时,还有1个CPU和1GB的RAM尚未分配,因此分配模块可以将这些资源供给Framework 2。
资源隔离与分配
资源隔离
为了实现在同一组Slave节点集合上运行多任务这一目标,Mesos使用了隔离模块
Mesos早在2009年就用上了Linux的容器技术,如cgroups和Solaris Zone,时至今日这些仍然是默认的。
然而,Mesos社区增加了Docker作为运行任务的隔离机制。
不管使用哪种隔离模块,为运行特定应用程序的任务,都需要将执行器全部打包,并在已经为该任务分配资源的Slave服务器上启动。
当任务执行完毕后,容器会被“销毁”,资源会被释放,以便可以执行其他任务。
资源分配
因为这对Mesos管理跨多个Framework和应用的资源,是不可或缺的。
我们前面提到资源邀约的概念,即由Master向注册其上的Framework发送资源邀约。
每次资源邀约包含一份Slave节点上可用的CPU、RAM等资源的列表。 Master提供这些资源给它的Framework,是基于分配策略的。
分配策略对所有的Framework普遍适用,同时适用于特定的Framework。
Framework可以拒绝资源邀约,如果它不满足要求,若此,资源邀约随即可以发给其他Framework。
由Mesos管理的应用程序通常运行短周期的任务,因此这样可以快速释放资源,缓解Framework的资源饥饿;
Slave定期向Master报告其可用资源,以便Master能够不断产生新的资源邀约。
另外,还可以使用诸如此类的技术, 每个Fraamework过滤不满足要求的资源邀约、Master主动废除给定周期内一直没有被接受的邀约。
分配策略有助于Mesos Master判断是否应该把当前可用资源提供给特定的Framework,以及应该提供多少资源。
Mesos实现了公平共享和严格优先级(这两个概念我会在资源分配那篇讲)分配模块, 确保大部分用例的最佳资源共享。已经实现的新分配模块可以处理大部分之外的用例。
分配细节
对
Mesos Master代理任务的调度首先从Slave节点收集有关可用资源的信息,然后以资源邀约的形式,将这些资源提供给注册其上的Framework做细节化描述
Framework可以根据是否符合任务对资源的约束,选择接受或拒绝资源邀约。一旦资源邀约被接受,Framework将与Master协作调度任务,并在数据中心的相应Slave节点上运行任务。
如何作出资源邀约的决定是由资源分配模块实现的,该模块存在于Master之中。资源分配模块确定Framework接受资源邀约的顺序,与此同时,确保在本性贪婪的Framework之间公平地共享资源。
在同质环境中,比如Hadoop集群,使用最多的公平份额分配算法之一是最大最小公平算法(max-min fairness)。最大最小公平算法算法将最小的资源分配最大化,并将其提供给用户,确保每个用户都能获得公平的资源份额,以满足其需求所需的资源;
一个简单的例子能够说明其工作原理
如前所述,在同质环境下,这通常能够很好地运行。同质环境下的资源需求几乎没有波动,所涉及的资源类型包括CPU、内存、网络带宽和I/O。
然而,在跨数据中心调度资源并且是异构的资源需求时,资源分配将会更加困难。
例如,当用户A的每个任务需要1核CPU、4GB内存,而用户B的每个任务需要3核CPU、1GB内存时,如何提供合适的公平份额分配策略?
当用户A的任务是内存密集型,而用户B的任务是CPU密集型时,如何公平地为其分配一揽子资源?
因为Mesos是专门管理异构环境中的资源,所以它实现了一个可插拔的资源分配模块架构,将特定部署最适合的分配策略和算法交给用户去实现。
例如,用户可以实现加权的最大最小公平性算法,让指定的Framework相对于其它的Framework获得更多的资源。
默认情况下,Mesos包括一个严格优先级的资源分配模块和一个改良的公平份额资源分配模块。
严格优先级模块实现的算法给定Framework的优先级,使其总是接收并接受足以满足其任务要求的资源邀约。
这保证了关键应用在Mesos中限制动态资源份额上的开销,但是会潜在其他Framework饥饿的情况。
由于这些原因,大多数用户默认使用DRF(主导资源公平算法 Dominant Resource Fairness),这是Mesos中更适合异质环境的改良公平份额算法。
DRF和Mesos一样出自Berkeley AMPLab团队,并且作为Mesos的默认资源分配策略实现编码。
DRF的目标是确保每一个用户,即Mesos中的Framework,在异质环境中能够接收到其最需资源的公平份额。
为了掌握DRF,我们需要了解主导资源(dominant resource)和主导份额(dominant share)的概念。
Framework的主导资源是其最需的资源类型(CPU、内存等),在资源邀约中以可用资源百分比的形式展示。
例如,对于计算密集型的任务,它的Framework的主导资源是CPU,而依赖于在内存中计算的任务,它的Framework的主导资源是内存。
因为资源是分配给Framework的,所以DRF会跟踪每个Framework拥有的资源类型的份额百分比;
Framework拥有的全部资源类型份额中占最高百分比的就是Framework的主导份额。DRF算法会使用所有已注册的Framework来计算主导份额,以确保每个Framework能接收到其主导资源的公平份额。
概念过于抽象了吧?让我们用一个例子来说明。
假设我们有一个资源邀约,包含9核CPU和18GB的内存。Framework 1运行任务需要(1核CPU、4GB内存),Framework 2运行任务需要(3核CPU、1GB内存)
Framework 1的每个任务会消耗CPU总数的1/9、内存总数的2/9,因此Framework 1的主导资源是内存。同样,Framework 2的每个任务会CPU总数的1/3、内存总数的1/18,因此Framework 2的主导资源是CPU。
DRF会尝试为每个Framework提供等量的主导资源,作为他们的主导份额。
在这个例子中,DRF将协同Framework做如下分配:Framework 1有三个任务,总分配为(3核CPU、12GB内存),Framework 2有两个任务,总分配为(6核CPU、2GB内存)。
此时,每个Framework的主导资源(Framework 1的内存和Framework 2的CPU)最终得到相同的主导份额(2/3或67%)
这样提供给两个Framework后,将没有足够的可用资源运行其他任务。
需要注意的是,如果Framework 1中仅有两个任务需要被运行,那么Framework 2以及其他已注册的Framework将收到的所有剩余的资源。

那么DRF是怎样计算而产生上述结果的呢?
如前所述DRF分配模块跟踪分配给每个Framework的资源和每个框架的主导份额。
每次DRF以所有Framework中运行的任务中最低的主导份额作为资源邀约发送给Framework。
如果有足够的可用资源来运行它的任务,Framework将接受这个邀约。
通过前面引述的DRF论文中的示例,我们来贯穿DRF算法的每个步骤。
为了简单起见,示例将不考虑短任务完成后,资源被释放回资源池中这一因素,我们假设每个Framework会有无限数量的任务要运行,并认为每个资源邀约都会被接受。
回顾上述示例,假设有一个资源邀约包含9核CPU和18GB内存。
Framework 1运行的任务需要(1核CPU、4GB内存),Framework 2运行的任务需要(3核CPU、2GB内存)。
Framework 1的任务会消耗CPU总数的1/9、内存总数的2/9,Framework 1的主导资源是内存。同样,Framework 2的每个任务会CPU总数的1/3、内存总数的1/18,Framework 2的主导资源是CPU。

上面表中的每一行提供了以下信息:
- Framework chosen——收到最新资源邀约的Framework。
- Resource Shares——给定时间内Framework接受的资源总数,包括CPU和内存,以占资源总量的比例表示。
- Dominant Share(主导份额)——给定时间内Framework主导资源占总份额的比例,以占资源总量的比例表示。
- Dominant Share %(主导份额百分比)——给定时间内Framework主导资源占总份额的百分比,以占资源总量的百分比表示。
- CPU Total Allocation——给定时间内接受的所有Framework的总CPU资源。
- RAM Total Allocation——给定时间内接受的所有Framework的总内存资源。
注意,每个行中的最低主导份额以粗体字显示,以便查找。
最初,两个Framework的主导份额是0%,我们假设DRF首先选择的是Framework 2,当然我们也可以假设Framework 1,但是最终的结果是一样的。
Framework 2接收份额并运行任务,使其主导资源成为CPU,主导份额增加至33%。
由于Framework 1的主导份额维持在0%,它接收共享并运行任务,主导份额的主导资源(内存)增加至22%。
由于Framework 1仍具有较低的主导份额,它接收下一个共享并运行任务,增加其主导份额至44%。
然后DRF将资源邀约发送给Framework 2,因为它现在拥有更低的主导份额。
该过程继续进行,直到由于缺乏可用资源,不能运行新的任务。在这种情况下,CPU资源已经饱和。
然后该过程将使用一组新的资源邀约重复进行。
需要注意的是,可以创建一个资源分配模块,使用加权的DRF使其偏向某个Framework或某组Framework。
如前面所提到的,也可以创建一些自定义模块来提供组织特定的分配策略。
一般情况下,现在大多数的任务是短暂的,Mesos能够等待任务完成并重新分配资源。然而,集群上也可以跑长时间运行的任务,这些任务用于处理挂起作业或行为不当的Framework。
值得注意的是,在当资源释放的速度不够快的情况下,资源分配模块具有撤销任务的能力。
Mesos尝试如此撤销任务:向执行器发送请求结束指定的任务,并给出一个宽限期让执行器清理该任务。如果执行器不响应请求,分配模块就结束该执行器及其上的所有任务。
分配策略可以实现为,通过提供与Framework相关的保证配置,来阻止对指定任务的撤销。如果Framework低于保证配置,Mesos将不能结束该Framework的任务。
持久化
存储
Mesos的主要好处是可以在同一组计算节点集合上运行多种类型的应用程序(调度以及通过Framework初始化任务)。
这些任务使用隔离模块(目前是某些类型的容器技术)从实际节点中抽象出来,以便它们可以根据需要在不同的节点上移动和重新启动
如果我在运行一个数据库作业,Mesos如何确保当任务被调度时,分配的节点可以访问其所需的数据?如图所示,在Hindman的示例中,使用Hadoop文件系统(HDFS)作为Mesos的持久层
这是HDFS常见的使用方式,也是Mesos的执行器传递分配指定任务的配置数据给Slave经常使用的方式。
实际上,Mesos的持久化存储可以使用多种类型的文件系统,HDFS只是其中之一,但也是Mesos最经常使用的,它使得Mesos具备了与高性能计算的亲缘关系。其实Mesos可以有多种选择来处理持久化存储的问题:
分布式文件系统。如上所述,Mesos可以使用DFS(比如HDFS或者Lustre)来保证数据可以被Mesos集群中的每个节点访问。这种方式的缺点是会有网络延迟,对于某些应用程序来说,这样的网络文件系统或许并不适合。
使用数据存储复制的本地文件系统。另一种方法是利用应用程序级别的复制来确保数据可被多个节点访问。
提供数据存储复制的应用程序可以是NoSQL数据库,比如Cassandra和MongoDB。
这种方式的优点是不再需要考虑网络延迟问题。缺点是必须配置Mesos,使特定的任务只运行在持有复制数据的节点上,因为你不会希望数据中心的所有节点都复制相同的数据。为此,可以使用一个Framework,静态地为其预留特定的节点作为复制数据的存储。
- 不使用复制的本地文件系统。也可以将持久化数据存储在指定节点的文件系统上,并且将该节点预留给指定的应用程序。和前面的选择一样,可以静态地为指定应用程序预留节点,但此时只能预留给单个节点而不是节点集合。后面两种显然不是理想的选择,因为实质上都需要创建静态分区。然而,在不允许延时或者应用程序不能复制它的数据存储等特殊情况下,我们需要这样的选择。
Mesos项目还在发展中,它会定期增加新功能。现在我已经发现了两个可以帮助解决持久化存储问题的新特性:
动态预留。Framework可以使用这个功能框架保留指定的资源,比如持久化存储,以便在需要启动另一个任务时,资源邀约只会发送给那个Framework。这可以在单节点和节点集合中结合使用Framework配置,访问永久化数据存储。关于这个建议的功能的更多信息可以从此处获得。
持久化卷。该功能可以创建一个卷,作为Slave节点上任务的一部分被启动,即使在任务完成后其持久化依然存在。Mesos为需要访问相同的数据后续任务,提供在可以访问该持久化卷的节点集合上相同的Framework来初始化。关于这个建议的功能的更多信息可以从此处获得。
容错
Mesos的优势之一便是将容错设计到架构之中,并以可扩展的分布式系统的方式来实现。
Master。
故障处理机制和特定的架构设计实现了Master的容错。
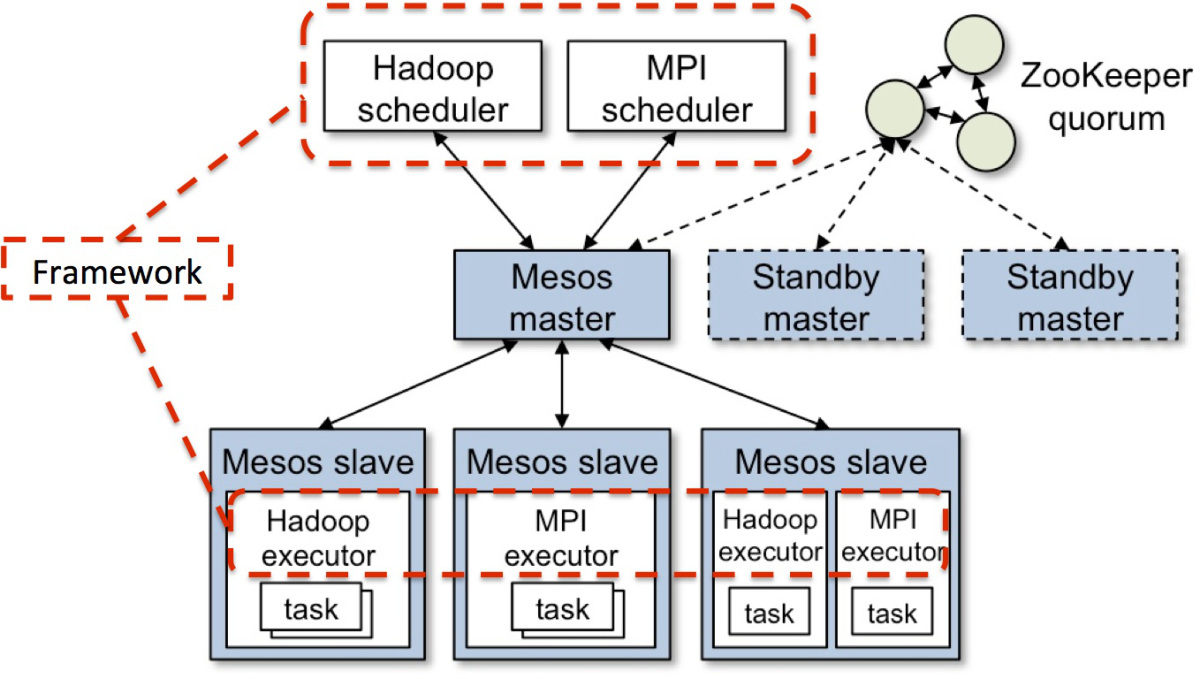
首先,Mesos决定使用热备份(hot-standby)设计来实现Master节点集合。
正如Tomas Barton对上图的说明,一个Master节点与多个备用(standby)节点运行在同一集群中,并由开源软件Zookeeper来监控。
Zookeeper会监控Master集群中所有的节点,并在Master节点发生故障时管理新Master的选举。
建议的节点总数是5个,实际上,生产环境至少需要3个Master节点。
Mesos决定将Master设计为持有软件状态,这意味着当Master节点发生故障时,其状态可以很快地在新选举的Master节点上重建。
Mesos的状态信息实际上驻留在Framework调度器和Slave节点集合之中。
当一个新的Master当选后,Zookeeper会通知Framework和选举后的Slave节点集合,以便使其在新的Master上注册。
彼时新的 Master可以根据Framework和Slave节点集合发送过来的信息,重建内部状态。
Framework调度器。
Framework调度器的容错是通过Framework将调度器注册2份或者更多份到Master来实现。
当一个调度器发生故障时,Master会通知另一个调度来接管。需要注意的是Framework自身负责实现调度器之间共享状态的机制。
Slave。
Mesos实现了Slave的恢复功能,当Slave节点上的进程失败时,可以让执行器/任务继续运行,并为那个Slave进程重新连接那台Slave节点上运行的执行器/任务。
当任务执行时,Slave会将任务的监测点元数据存入本地磁盘。如果Slave进程失败,任务会继续运行
当Master重新启动Slave进程后,因为此时没有可以响应的消息,所以重新启动的Slave进程会使用检查点数据来恢复状态,并重新与执行器/任务连接。
如下情况则截然不同,计算节点上Slave正常运行而任务执行失败。在此,Master负责监控所有Slave节点的状态。
当计算节点/Slave节点无法响应多个连续的消息后,Master会从可用资源的列表中删除该节点,并会尝试关闭该节点。
然后,Master会向分配任务的Framework调度器汇报执行器/任务失败,并允许调度器根据其配置策略做任务失败处理。通常情况下,Framework会重新启动任务到新的Slave节点,假设它接收并接受来自Master的相应的资源邀约。
执行器/任务。与计算节点/Slave节点故障类似,Master会向分配任务的Framework调度器汇报执行器/任务失败,并允许调度器根据其配置策略在任务失败时做出相应的处理。通常情况下,Framework在接收并接受来自Master的相应的资源邀约后,会在新的Slave节点上重新启动任务。
国内查看评论需要代理~