Docker Kubernetes ServiceMesher 云原生
Docker基础设施
NameSpaces资源隔离
Linux的命名空间机制提供了以下七种不同的命名空间
| Namespace | 系统调用参数 | 隔离内容 |
|---|---|---|
| UTS | CLONE_NEWUTS | 主机名与域名 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等等 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
| User | CLONE_NEWUSER | 用户和用户组 |
通过这七个选项我们能在创建新的进程时设置新进程,应该在哪些资源上与宿主机器进行隔离。
ps命令打印出当前操作系统中正在执行的进程,一个是pid为1的init 进程
另一个是pid为2的kthreadd进程
这两个进程都是被Linux中的上帝进程idle创建出来的
- 前者负责执行内核的一部分初始化工作和系统配置
- 后者负责管理和调度其他的内核进程
1 | root 1 0 0 Jun08 ? 00:00:13 /usr/lib/systemd/systemd --system --deserialize 15 |
而docker容器中却是如下
1 | root@helloworld-v2-646d4bbdcd-gwdh2:/opt/microservices# ps -ef |
容器是创建新进程时传入CLONE_NEWPID实现的,从而达到了Linux的命名空间实现进程的隔离,Docker容器内部的任意进程都对宿主机器的进程一无所知。
如下是容器设置命名空间的方式
1 | containerRouter.postContainersStart |
在setNamespaces方法中不仅会设置进程相关的命名空间,还会设置与用户、网络、IPC 以及 UTS 相关的命名空间
网络
Docker的容器通过Linux的命名空间完成了与宿主机进程的网络隔离,但是Docker中的服务仍然需要与外界相连才能发挥作用
libnetwork
整个网络部分的功能都是通过Docker拆分出来的libnetwork实现的,它提供了一个连接不同容器的实现,同时也能够为应用给出一个能够提供一致的编程接口和网络层抽象的容器网络模型。
1 | libnetwork中最重要的概念,容器网络模型由以下的几个主要组件组成,分别是 Sandbox、Endpoint 和 Network |
网络模式
Docker为我们提供了四种不同的网络模式:Host、Container、None 和 Bridge 模式
主机模式
1 | 众所周知,Docker使用了Linux的Namespaces技术来进行资源隔离, |
容器模式
1 | 在理解了host模式后,这个模式也就好理解了。 |
None模式
1 | 这个模式和前两个不同。在这种模式下,Docker容器拥有自己的Network Namespace, |
网桥模式
1 | bridge模式是Docker默认的网络设置, |
VMware三种网络模式
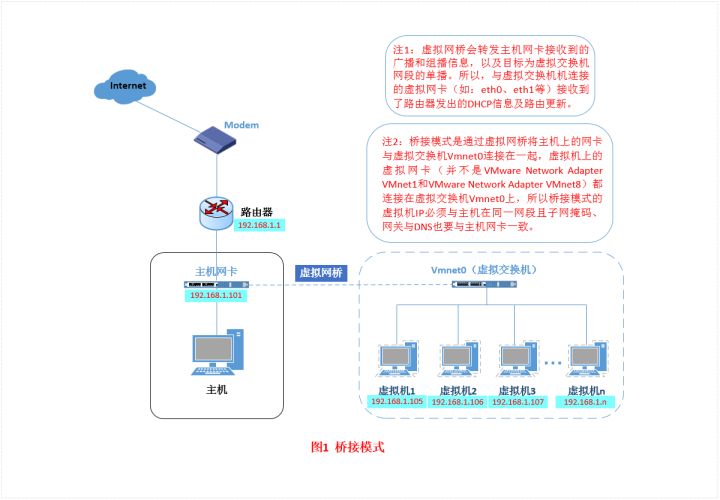
Bridged(桥接模式)
特点
虚拟机和主机是处于同等地位的机器,所以网络功能也无异于主机。并且和主机处于同一网段。
虚拟机配置
1 | DEVICE="eth0" |
大致原理
1 | 在这种模式下,VMWare虚拟出来的操作系统就像是局域网中的一台独立的主机 |
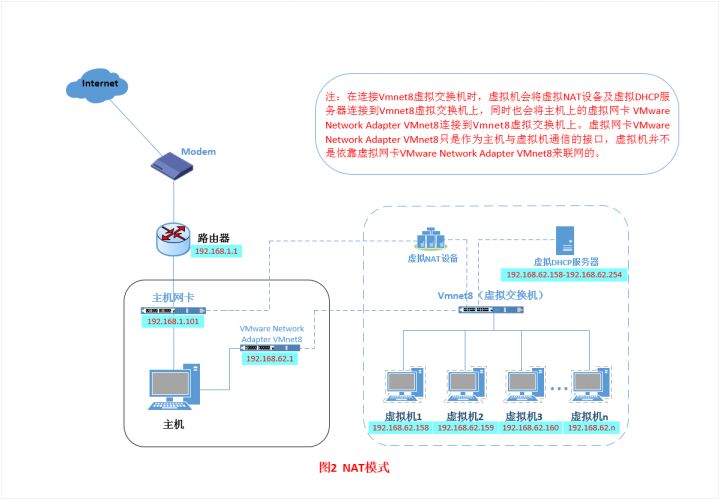
NAT(网络地址转换模式)
特点
- 主机ping不通虚拟机(包括宿主)
- 同一宿主的虚拟机可以相互ping通
- 宿主能够联网,虚拟机也能联网(其他主机)。宿主没有联网,虚拟机也不能联网
- 虚拟机能够ping通主机其他主机不能访问虚拟机
虚拟机配置
1 | DEVICE="eth0" |
大致原理
1 | 使用NAT模式,就是让虚拟系统借助NAT的功能,通过宿主机所在的网络来访问公网。 |
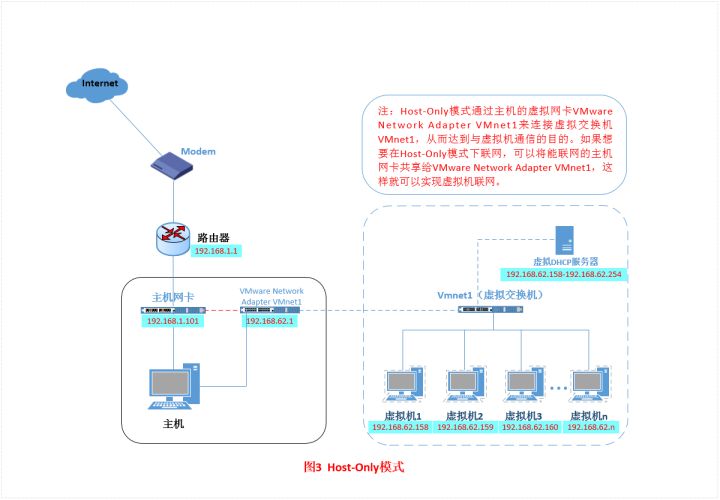
Host-Only模式
特点
只能和主机相互通信,不能上网,也不能访问其他主机,用于建立与外部隔离的网络环境
虚拟机配置
1 | DEVICE="eth0" |
大致原理
1 | 在Host-Only模式下,虚拟网络是一个全封闭的网络 |
CGroups 资源限制
目前越来越火的轻量级容器
Docker就使用了cgroups提供的资源限制能力来完成cpu,内存等部分的资源控制。
每一个CGroup都是一组被相同的标准和参数限制的进程,不同的CGroup之间是有层级关系的
也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
cgroups 的全称是control groups,cgroups为每种可以控制的资源定义了一个子系统。典型的子系统介绍如下:
cpu 子系统,主要限制进程的 cpu 使用率。
cpuacct子系统,可以统计 cgroups 中的进程的 cpu 使用报告。cpuset子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。memory子系统,可以限制进程的 memory 使用量。blkio子系统,可以限制进程的块设备 io。devices子系统,可以控制进程能够访问某些设备。net_cls子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。freezer子系统,可以挂起或者恢复 cgroups 中的进程。ns子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
task_struct->css_set->cgroup_subsys_state->cgroup
AUFS && overlay2 文件存储
UnionFS其实是一种为Linux操作系统设计的用于把多个文件系统『联合』到同一个挂载点的文件系统服务。而AUFS即 Advanced UnionFS 其实就是 UnionFS 的升级版,它能够提供更优秀的性能和效率。
AUFS作为联合文件系统,它能够将不同文件夹中的层联合Union到了同一个文件夹中,这些文件夹在AUFS中称作分支
1 | 每一个镜像层都是建立在另一个镜像层之上的,同时所有的镜像层都是只读的 |
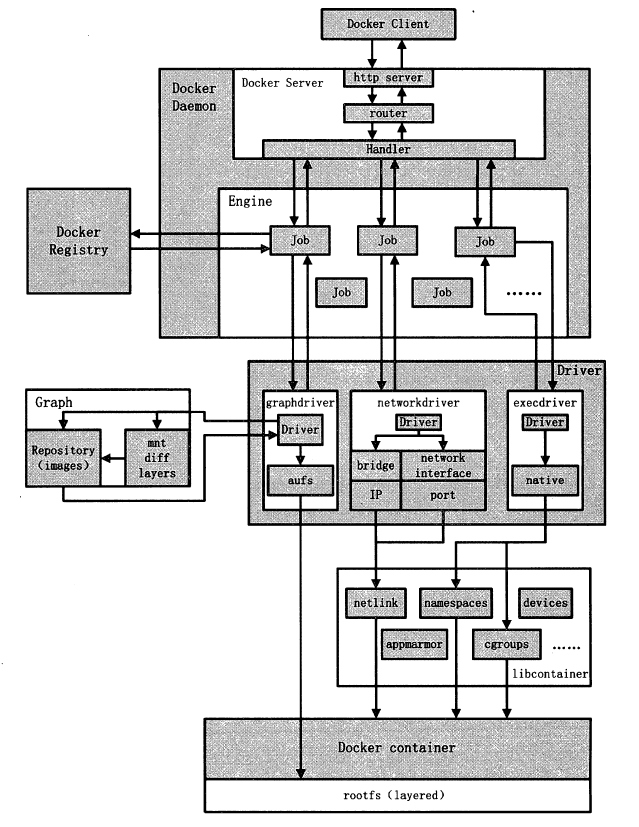
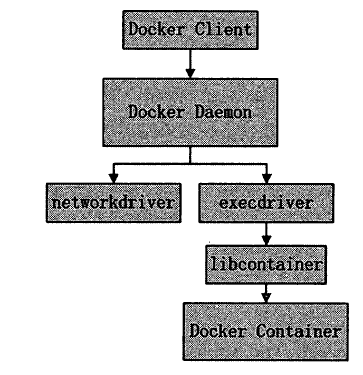
Docker内核
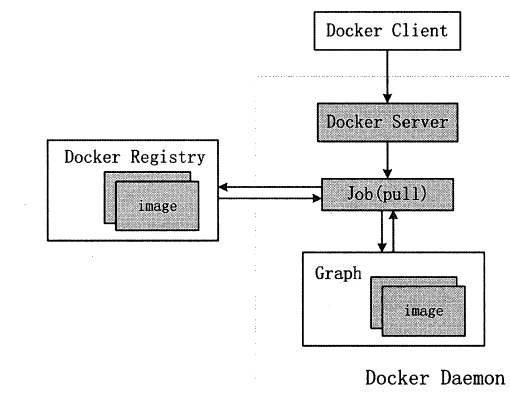
架构中主要的模块有:DockerClient、DockerDaemon、DockerRegistry、Graph、Driver、libcontainer以及Docker Container。
Docker Client是与Docker Daemon建立通信的最佳途径。用户通过Docker Client发起容器的管理请求,请求最终发往Docker Daemon。
Docker Daemon需要完成的任务很多,因此Job的种类也很多。
- 若用户需要下载容器镜像,DockerDaemon则会创建一个名为“pull”的Job,运行时从Docker Registry中下载镜像,并通过镜像管理驱动graphdriver将下载的镜像存储在graph中
- 若用户需要为Docker容器创建网络环境,DockerDaemon则会创建一个名“allocate_interface”的Job,通过网络驱动networkdriver分配网络接口的资源……
libcontainer是一套独立的容器管理解决方案,这套解决方案涉及了大量Linux内核方面的特性,如:namespaces、cgroups以及capabilities等。libcontainer很好地抽象了Linux的内核特性,并提供完整、明确的接口给Docker Daemon。
当用户执行运行容器这个命令之后,一个Docker容器就处于运行状态,该容器拥有隔离的运行环境、独立的网络栈资源以及受限的资源等。
Docker各模块功能与实现分析
Docker Client
Docker Client可以通过以下三种方式和Docker Daemon建立通信,分别为:tcp://host:port、unix://path_to_socket和fd://socketfd。
Docker Client发送容器管理请求后,请求由Docker Daemon接收并处理,当Docker Client接收到返回的请求响应并做简单处理后,Docker Client一次完整的生命周期就此结束。
若需要继续发送容器管理请求,用户必须再次通过可执行文件docker创建Docker Client,并走完以上相同的流程。
Docker Daemon
DockerDaemon的作用主要有以下两方面:
- 接收并处理Docker Client发送的请求。
- 管理所有的Docker容器。
Docker Daemon运行时,会在后台启动一个Server,Server负责接收Docker Client发送的请求;接收请求后,Server通过路由与分发调度,找到相应的Handler来处理请求。
启动Docker Daemon所使用的可执行文件同样是docker,与Docker Client启动所使用的可执行文件docker相同。
既然Docker Client与Docker Daemon都可以通过docker二进制文件创建,那么如何辨别两者就变得非常重要。
实际上执行docker命令时,通过传入的参数可以辨别Docker Daemon与Docker Client,如docker–d代表Docker Daemon的启动,dockerps则代表创建Docker Client,并发送ps请求。
Docker Daemon 的架构大致可以分为三部分: Docker Server 、Engine 和Job o Daemon 的架构如图所示。
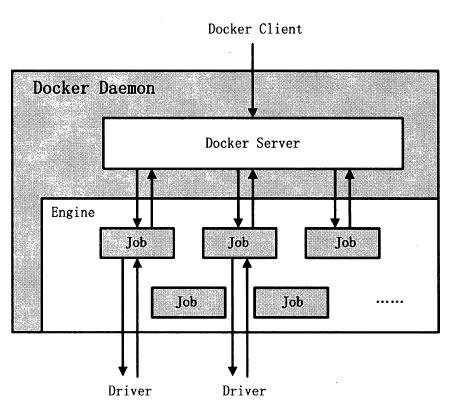
Docker Server
Docker Server 在Docker 架构中专门服务于Docker Client ,它的功能是接收并调度分发
Docker Client 发送的请求。
Docker Server 的架构如图
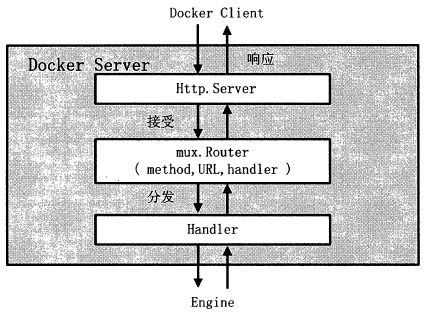
在服务过程中, Docker Server 在listener 上接收Docker Client 的访问请求。对于每一个Docker Client 请求, DockerServer 均会创建一个全新的goroutine 来服务。
在goroutine 中,Docker Server 首先读取请求内容,然后做请求解析工作,接着匹配相应的路由项,随后调用相应的Handler 来处理,最后Handler 处理完请求之后给Docker Client 回复响应。
需要注意的是: Docker Server 在Docker 的启动过程中运行,通过一个名为” serveapi”的Job 来实现。理论上, Docker Server 的运行只是众多Job 中的一个,但是为了强调Docker Server 的重要性以及它为后续Job 服务的重要特性
将serveapi的Job单独抽离出来分析,理解为Docker Server。
Engine
Engine 是Docker 架构中的运行引擎,同时也是Docker 运行的核心模块。Engine 存储着大量的容器信息,同时管理着Docker 大部分Job 的执行。
换言之, Docker 中大部分任务的执行都需要Engine 协助,并通过Engine 匹配相应的Job 完成Job 的执行。
在Docker 源码中,有关Engine 的数据结构定义中含有一个名为handlers 的对象。
该 handlers 对象存储的是关于众多特定Job 各自的处理方式handler。
举例说明, Engine 的 handlers 对象中有一项为: {“create”: daemon.ContainerCreate,},则说明当执行名为” create”的Job 时,执行的是daemon.ContainerCreate 这个handler。
除了容器管理之外, Engine 还接管Docker Daemon 的某些特定任务。当Docker Daemon 遭遇到自身进程需要退出的情况时, Engine 还负责完成DockerDaemon 退出前的所有善后工作。
Job
Job 可以认为是Docker 架构中Engine 内部最基本的工作执行单元。DockerDaemon 可以完成的每一项工作都会呈现为一个Job 。
- 在Docker 容器内部运行一个进程,这是一个Job;
- 创建一个新的容器,这是一个Job;
- 在网络上下载一个文档,这是一个Job;
- 包括之前在Docker Server 部分谈及的,创建Server 服务于HTTP 协议的API ,这也是一个Job ,等等。
有关Job 接口的设计,与UNIX 进程非常相仿。
比如说 Job 有一个名称,有运行时参数,有环境变量,有标准输入与标准输出,有标准错误,还有返回状态等。
对于Job 而言,定义完毕之后,运行才能完成Job 自身真正的使命。Job 的运行函数Run()则用以执行Job 本身。
Docker Registry
Docker Regisry叩是一个存储容器镜像( Docker Image) 的仓库。容器镜像( Docker Image)是容器创建时用来初始化容器rootfs 的文件系统内容。
Docker Registry 将大量的容器镜像汇集在一起,并为分散的Docker Daemon 提供镜像服务。
Docker 的运行过程中,有三种情况可能与Docker Regist可通信,分别为搜索镜像、下载镜像、上传镜像。
这三种情况所对应的Job 名称分别为search 、pull 和push 。
不同场景下, Docker Daemon 可以使用不同的Docker Registry。公有Registry 与私有Registry可就是两种场景模式不同的Docker Registry。
其中大家熟知的Docker Hub ,就是全球范围内最大的公有Registry Docker 可以通过互联网访问DockerHub ,并下载容器镜像;
同时Docker 也允许用户构建本地私有Registry ,使容器镜像的获取在内网完成。
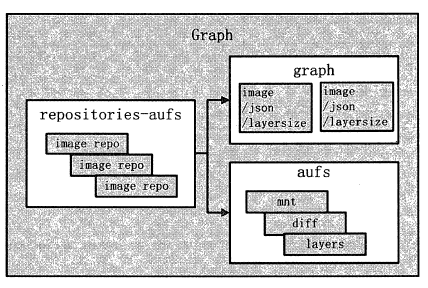
Graph
Graph 在Docker 架构中扮演的角色是容器镜像的保管者。不论是Docker 下载的镜像,还是Docker 构建的镜像,均由Graph 统一化管理。
由于Docker 支持多种不同的镜像存储方式,如aufs 、devicemapper 、Btrfs 等,故Graph 对镜像的存储也会因以上种类而存在一些差异。
对Docker 而言,同一种类型的镜像被称为一个repository ,如名称为ubuntu 的镜像都同属一个repository ;
而同一个repository 下的镜像则会因tag 存在差异而不同,如ubuntu这个reposit。
可下有tag 为12.04 的镜像,也有tag 为14.04 的镜像。
Docker 中Graph 的架构如图
Driver
Driver 是Docker 架构中的驱动模块。通过Driver 驱动, Docker 可以实现对Docker 容器运行环境的定制,定制的维度主要有网络环境、存储方式以及容器执行方式。
需要注意的是, Docker 运行的生命周期中,并非用户所有的操作都是针对Docker 容器的管理,同时包括用户对Docker 运行信息的获取,还包括Docker 对Graph 的存储与记录等。
因此为了将仅与Docker 容器有关的管理从Docker Daemon 的所有逻辑中区分开来, Docker 的创造者设
计了Driver 层来抽象不同类别各自的功能范畴。
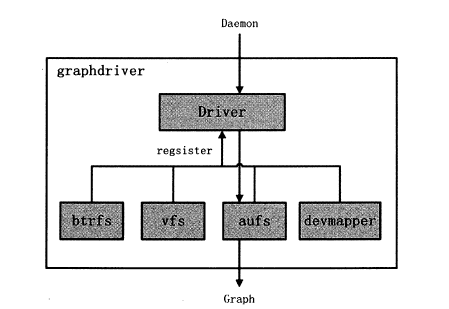
Docker Driver 的实现可以分为以下三类驱动: graphdriver 、networkdriver 和execdriver。
graphdriver
graphdriver 主要用于完成容器镜像的管理
包括从远程Docker Registry 上下载镜像并进行存储,也包括本地构建完镜像后的存储。
当用户下载指定的容器镜像时, graphdriver将容器镜像分层存储在本地的指定目录下;
同时当用户需要使用指定的容器镜像来创建容器时, graphdriver 从本地镜像存储目录中获取指定的容器镜像,并按特定规则为容器准备rootfs ;
另外,当用户需要通过指定Dockerfi1e 构建全新镜像时, graphdriver 会负责新镜像
的存储管理。
在graphdriver 的初始化过程之前,有4 种文件系统或类文件系统的驱动Driver 在
DockerDaemon 内部注册,它们分别是aufs 、btrfs 、vfs 和devmapper。其中aufs 、b位fs 以
及devmapper 用于容器镜像的管理, vfs 用于容器vo1ume 的管理。
Docker 在初始化之时,优先通过获取系统环境变量”DOCKER D阳VER” 来提取所使用driver 的指定类型。因此之后所有的Graph 操作,都使用该driver 来执行。
Docker 镜像是Docker 技术中非常关键的。2014 年12 月,在Linux 3.18-rc2 版本中Over1ayFS 被合并至Linux 内核主线,在Docker1 .4 .0 版本发布时, Docker 官方宣布支持over1ay 这一类graphdriver ,即用户在启动Docker Daemon 时可以选择制定graphdriver 的类型为overlay 0 graphdriver 的架构如图
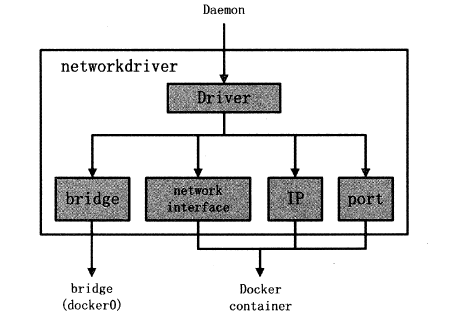
networkdriver
networkdriver 的作用是完成Docker 容器网络环境的配置,其中包括Docker Daemon启动时为Docker 环境创建网桥;
Docker 容器创建前为其分配相应的网络接口资源;以及为Docker 容器分配IP 、端口并与宿主机做NAT 端口映射,设置容器防火墙策略等。
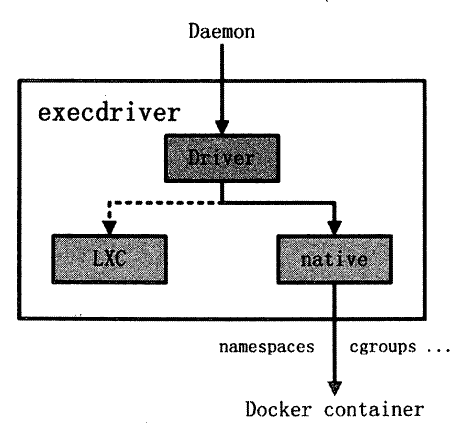
execdriver
execdriver 作为Docker 容器的执行驱动,负责创建容器运行时的命名空间,负责容器资源使用的统计与限制,负责容器内部进程的真正运行等。
在Docker 0.9.0 版本之前,execdriver 只能通过LXC 驱动来实现容器的启动管理。实际上,当时Docker 通过LXC 驱动
调用Linux 下的LXC 工具管理容器的创建,并控制管理容器的生命周期。
从Docker 0.9.0 开始,在继续支持LXC 的情况下, Docker 的execdriver 默认使用native 驱动, native 驱动完全独立于LXC ,属于Docker 项目下第一个全新的子项目,用于容器的创建与管理。
Docker 默认使用native 驱动的具体体现为: Docker Daemon 启动过程中加载的ExecDriverflag 参数在
配置文件中已经被设为native
native 这个execdriver 的存在,使得Docker 对Linux 容器的创建与管理有了自己的解决方案。
execdriver 架构如图
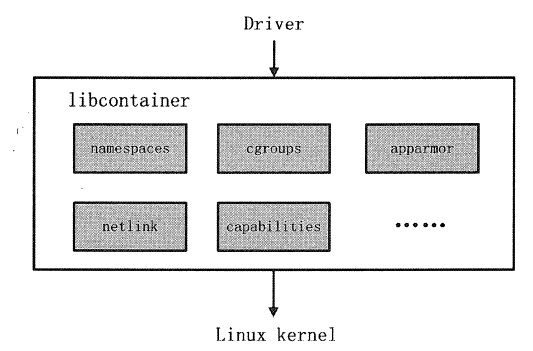
libcontainer
libcontainer 是Docker 架构中一个使用Go语言设计实现的库,设计初衷是希望该库可以不依靠任何依赖,直接访问内核中与容器相关的系统调用。
正是由于libcontainer 的存在, Docker 可以直接调用libcontainer ,而最终操作容器的namespaces 、cgroups 、apparmor 、网络设备以及防火墙规则等。
这一系列操作的完成都不需要依赖LXC 或者其他包。libcontainer 架构如图
另外, libcontainer 提供了一整套标准的接口来满足上层对容器管理的需求。或者说,
libcontainer 屏蔽了Docker 上层对容器的直接管理。
又由于libcontainer 使用Go 这种跨平台的语言开发实现,且本身又可以被上层多种不同的编程语言访问因此,很难说未来的Docker一定会与Linux 平台紧紧捆绑在一起。Docker Daemon 的逻辑完全有可能位于其他非Linux 操作系统的平台上,仅仅通过libcontainer 的远程调用来实现对Docker 容器的管理。
另一方面,libcontainer 与Docker Daemon 的松耦合设计,似乎让用户感受到了除Linux Container 之外其他的容器技术接入Docker Daemon 的可能性。
libcontainer 承接Linux 内核与Docker Daemon的同时,也让Docker 的生态在跨平台方面充满生机。
与此同时Microsoft 在其著名云计算平台Azure 中,也添加了对Docker 的支持,可见Docker 的开放程度与业界的火热度。
暂不谈Docker ,由于本身完善的功能以及与应用系统的松搞合特性, libcontainer 很有可能会在众多其他以容器为原型的平台出现,同时也很有可能催生出云计算领域全新的项目。
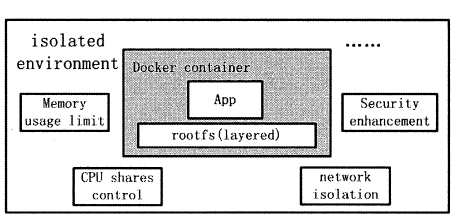
Docker Container
Docker Container (Docker 容器)是Docker 架构中服务交付的最终体现形式。Docker 通过DockerDaemon 的管理, libcontainer 的执行,最终创建Docker 容器。Docker 容器作为一个交付单位,功能类似于传统意义上的虚拟机( Virtual Machine) ,具备资源受限、环境与外界隔离的特点。
然而,实现手段却与KVM 、Xen 等传统虚拟化技术大相径庭。
Docker 容器的从无到有,涉及Docker 利用到的很多技术。总而言之,用户可以根据自己的需求,通过Docker Client 向Docker Daemon 发送容器的创建与启动请求,请求中将携带容器的配置信息,从而达到定制相应Docker 容器的目的。
用户对Docker 容器的配置有以下4 个基本方面:
- 通过指定容器镜像,使得Docker 容器可以自定义rootfs 等文件系统。
- 通过指定物理资源的配额,如CPU、内存等,使得Docker 容器使用受限的物理资源。
- 通过配置容器网络及其安全策略,使得Docker 容器拥有独立且安全的网络环境。
- 通过指定容器的运行命令,使得Docker 容器执行指定的任务。
Docker 容器示意图如图所示。
Docker 运行案例分析
分析原型为Docker 中的docker pull 与docker run 两个命令。
docker pull
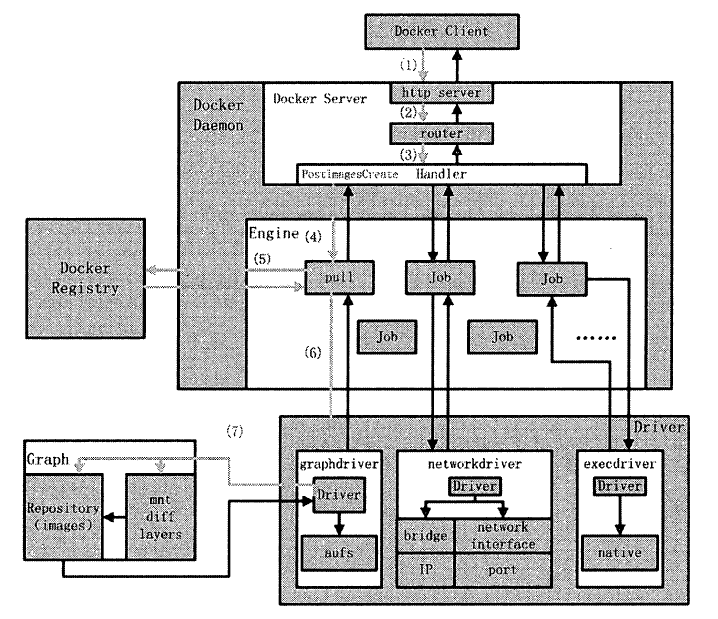
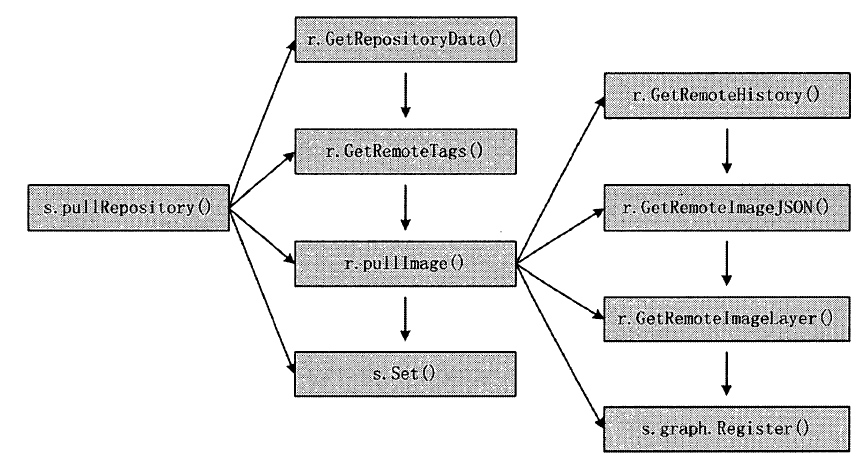
docker pull 命令的作用是: Docker Daemon 从Docker Registry 下载指定的容器镜像,并将镜像存储在本地的Graph 中,以备后续创建Docker 容器时使用
- Docker Client 处理用户发起的docker pull 命令,解析完请求以及参数之后,发送一个HTTP 请求给Docker Server, HTTP 请求方法为POST ,请求URL 为”/images/create?”+”xxx” ,实际意义为下载相应的镜像。
- Docker Server 接收以上HTTP 请求,并交给mux.Router , mux.Router 通过URL 以及请求方法类型来确定执行该请求的具体handler。
- mux.Router 将请求路由分发至相应的handler ,具体为PostImagesCreate 。
- 在PostImageCreate 这个handler 之中,创建并初始化一个名为”pull” 的Job ,之后触发执行该Job 。
- 名为”pull” 的Job 在执行过程中执行pullRepository。可操作,即从Docker Registry 中下载相应的一个或者多个Docker 镜像。
- 名为”pull” 的Job 将下载的Docker 镜像交给graphdriver 管理。
- graphdriver 负责存储Docker 镜像,一方面将实际镜像存储至本地文件系统中,另一方面为镜像创建对象,由Docker Daemon 统一管理。
docker run
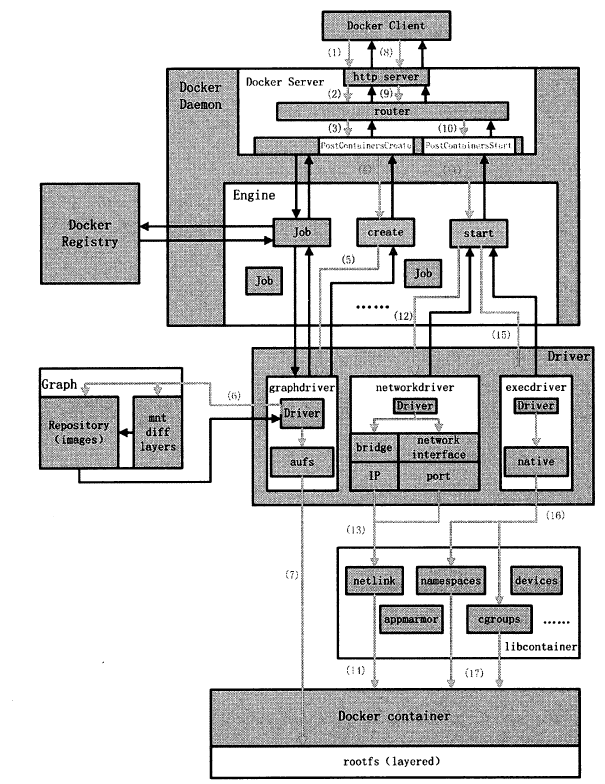
docker run 命令的作用是创建一个全新的Docker 容器,并在容器内部运行指定命令。
Docker Daemon 处理用户发起的这条命令时,所做工作可以分为两部分:
- 第一,创建Docker容器对象,并为容器准备所需的rootfs;
- 第二,创建容器的运行环境,如网络环境、资源限制等,最终真正运行用户指令。
因此在dockerrun 命令的完整执行流程中, Docker Client给Docker Server 发送了两次HTTP 请求,第二次请求的发起取决于第一次请求的返回状态。
docker run 命令执行流程如图
下面我们逐一分析这些步骤:
- Docker Client 处理用户发起的docker run 命令,解析完请求与参数之后,向 Docker Server 发送一个HTTP 请求, HTTP 请求方法为POST ,请求URL 为”/containers/create?”+”xxx” ,实际意义为创建一个容器对象,即Docker Daemon 程序逻辑中的容器对象,并非实际运行的容器。
- Docker Server 接收以上HTTP 请求,并交给mux.Router , mux.Router 通过URL 以及请求方法来确定执行该请求的具体handler。
- mux.Router 将请求路由分发至相应的handler ,具体为PostContainersCreate 。
- 在PostContainersCreate 这个handler 之中,创建并初始化一个名为”create” 的Job ,之后触发执行该Job 。
- 名为”create” 的Job 在运行过程中执行Container.Create 操作,该操作需要获取容器镜像来为Docker 容器准备rootfs ,通过graphdriver 完成。
- graphdriver 从Graph 中获取创建Docker 容器rootfs 所需要的所有镜像。
- graphdriver 将rootfs 的所有镜像通过某种联合文件系统的方式加载至Docker 容器指定的文件目录下。
- 若以上操作全部正常执行,没有返回错误或异常,则Docker Client 收到Docker Server 返回状态之后,发起第二次HTTP 请求。请求方法为”POST” ,请求URL 为”/containers/“+container ID+”/start” ,实际意义为启动时才创建完毕的容器对象,实现物理容器 的真正运行。
- Docker Server 接收以上HTTP 请求,并交给mux.Router , mux.Router 通过URL 以及请求方法来确定执行该请求的具体handler。
- mux.Router 将请求路由分发至相应的handler ,具体为PostContainersStart 。
- 在PostContainersStart 这个handler 之中,创建并初始化名为”start” 的Job ,之后触发执行该Job 。
- 名为”start” 的Job 执行需要完成一系列与Docker 容器相关的配置工作,其中之一是为Docker 容器网络环境分配网络资源,如IP 资源等,通过调用networkdriver 完成。
- networkdriver 为指定的Docker 容器分配网络资源,其中有IP 、po此等,另外为容器设置防火墙规则。
- 返回名为”start” 的Job ,执行完一些辅助性操作后, Job 开始执行用户指令,调用execdriver。
- execdriver 被调用,开始初始化Docker 容器内部的运行环境,如命名空间、资源控制与隔离,以及用户命令的执行,相应的操作转交至libcontainer 来完成。
- libcontainer 被调用完成Docker 容器内部的运行环境初始化,并最终执行用户要求启动的命令。
Docker 镜像
Docker 另外采用了神奇的”镜像”技术作为Docker 管理文件系统以及运行环境强有力的补充。
Docker 灵活的”镜像”技术,在笔者看来,也是其大红大紫最重要的因素之一。
Docker 镜像介绍
镜像是一种文件存储形式,文件管理员可以通过技术手段将很多文件制作成一个镜像。
对于虚拟机而言,镜像文件中存储着操作系统、文件系统内容、设备文件等。
可以说 Docker 镜像与虚拟机镜像有很大的相似度,然而也有着本质的区别。
相似的是,两者存储内容大致相同,都会含有文件系统内容;
不同的是, Docker 镜像不含操作系统内容,同时Docker 镜像由多个镜像组成。
根据Docker 官方网站上的技术文档描述, image (镜像)是Docker 术语的一种,对于容器而言,它代表一个只读的layer。
而layer 则具体代表Docker 容器文件系统中可叠加的一部分。
如此介绍Docker 镜像,相信众多Docker 爱好者理解起来仍然是云里雾里。
那么理解之前,先让我们来认识一下与Docker 镜像相关的4 个概念: rootfs 、union mount 、image 以及layer。
rootfs
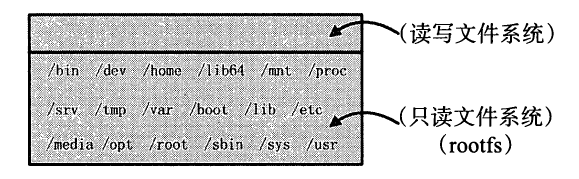
rootfs 代表一个Docker 容器在启动时(而非运行后)其内部进程可见的文件系统视角,或者Docker 容器的根目录。
当然该目录下含有Docker 容器所需要的系统文件、工具、容器文件等。
传统上, Linux 操作系统内核启动时,内核首先会挂载一个只读( read-only) 的rootfs ,当系统检测其完整性之后,决定是否将其切换为读写( read-write) 模式,或者最后在rootfs之上另行挂载一种文件系统并忽略rootfs, Docker 架构下依然沿用Linux 中rootfs 的思想。
当Docker Daemon 为Docker 容器挂载rootfs 的时候,与传统Linux 内核类似,将其设定为只读模式。
在rootfs 挂载完毕之后,和Linux 内核不一样的是, Docker Daemon 没有将Docker容器的文件系统设为读写模式,而是利用Union Mount 的技术,在这个只读的rootfs 之上再挂载一个读写的文件系统,挂载时该读写文件系统内空无一物。
在这里,我们暂且把Docker容器的文件系统这么理解:只含只读的rootfs 和可读写的文件系统。
举一个Ubuntu 容器启动的例子。假设用户已经通过Docker Registry 下拉了Ubuntu:14.04的镜像,并通过命令docker run -it ubuntu:14.04 /bin/bash 将其启动并运行,则Docker Daemon为其创建的rootfs 以及容器可读写的文件系统如图所示。
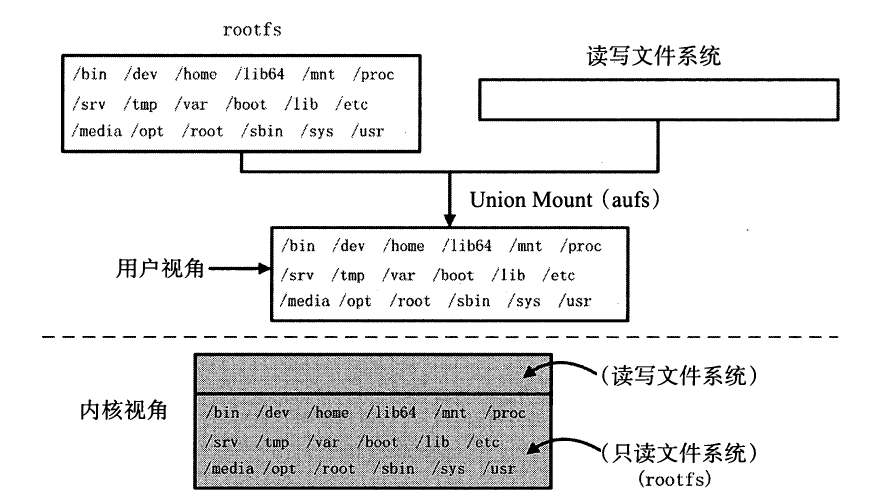
那么Union Mount 又是一种怎样的技术?
Union Mount
Union Mount 代表一种文件系统挂载方式,允许同一时刻多种文件系统叠加挂载在一起,并以一种文件系统的形式,呈现多种文件系统内容合并后的目录。
一般情况下,若通过某种文件系统挂载内容至挂载点,挂载点目录中原先的内容将会被隐藏。
而Union Mount 则不会将挂载点目录中的内容隐藏反而是将挂载点目录中的内容和被挂载的内容合并,并为合并后的内容提供一个统一独立的文件系统视角。
通常来讲,被合并的文件系统中只有一个会以读写( read-write) 模式挂载,其他文件系统的挂载模式均为只读( read-only) 。
实现这种Union Mount 技术的文件系统一般称为联合文件系统( Union Filesystem) ,较为常见的有UnionFS 、aufs 、OverlayFS 等。
Docker 实现容器文件系统Union Mount 时,提供多种具体的文件系统解决方案,如Docker 早期版本沿用至今的AUFS ,还有在Docker 1 .4 .0 版本中开始支持的OverlayFS 等。
为了更深入地了解Union Mount ,可以使用aufs 文件系统来进一步阐述本章前面 Ubuntu:14.04 容器文件系统的例子,挂载Ubuntu 14.04 文件系统的示意图如图所示。
aufs 等文件系统的COW (copy-on-write) 特性。
COW 文件系统和其他文件系统最大的区别就是:前者从不覆写已有文件系统中已有的内容。
通过COW 文件系统将两个文件系统( rootfs 和读写文件系统)合井,最终用户视角为合并后含有所有内容的文件系统
然而在Linux 内核逻辑上依然可以区别两者,那就是用户对原先rootfs 中的内容拥有只读权限,而对读写文件系统中的内容拥有读写权限。
既然对用户而言,全然不知哪些内容只读,哪些内容可读写,这些信息只有内核在接管
那么假设用户需要更新其视角下的文件/etc/bash. bashrc ,而该文件又恰巧是rootfs 只读文件系统中的内容,内核是否会抛出异常或者驳回用户请求呢?
答案是否定的。
当此情形发生时, COW 文件系统首先不会覆写只读文件系统中的文件,即不会覆写rootfs 中的/etc/bash.bashrc
其次反而会将该文件复制至读写文件系统中,即将/etc/bash. bashrc 复制至读写文件系统中的/etc/bash.bashrc (此时 rootfs 文件系统和读写文件系统中各含有一份/etc/bash.bashrc)
最后再对后者进行更新操作。如此一来纵使rootfs 与读写文件系统中均有/etc/bash.bashrc
诸如aufs 类型的COW 文件系统也能保证用户视角中只能看到读写文件系统中的/etc/bash.bashrc ,即更新后的内容。
当然这样的特性同样支持rootfs 中文件的删除等其他操作。
例如:用户通过apt-get 软件包管理工具安装Golang ,所有与Golang 相关的内容都会安装在读写文件系统中,而不会安装在rootfs 中。
此时用户又希望通过apt-get 软件包管理工具删除所有关于MySQL 的内容,恰巧这部分内容又都存在于rootfs 中,删除操作执行时同样不会删除rootfs 实际存在的MySQL ,而是在读写文件系统中删除该部分内容,导致最终rootfs 中的MySQL 对容器用户
不可见,也不可访。由于读写文件系统中根本不存在MySQL 的相关内容,因此似乎在读写
文件系统中找不到需要删除的对象。此时, aufs 保障在读写文件系统中对这些文件内容做相
关的标记( whiteout),确保用户在查看文件系统内容时,读写文件系统中的whiteout 将遮盖
第8 章Docker 镜像127
住rootfs 中的相应内容,导致这些内容不可见,以达到与删除这部分内容相类似的效果。
掌握Docker 中rootfs 以及Union Mount 的概念之后,再来理解Docker 镜像,就会有水
到渠成的感觉。
image
Docker 中rootfs 的概念,起到容器文件系统中基石的作用。对于容器而言,其只读的特性也是不难理解。
神奇的是,实际情况下Docker 架构中rootfs 的设计与实现比前面的描述还要精妙得多。
继续以Ubuntu 14.04 为例,虽然通过aufs 可以实现rootfs 与读写文件系统的合井,但是考虑到rootfs 自身接近200MB 的磁盘大小如果以这个rootfs 的粒度来实现容器的创建与迁移等,是否会稍显笨重?
同时也会大大降低镜像的灵活性?
而且若用户希望拥有一个Ubuntu 14.10 的rootfs ,那么是否有必要创建一个全新的rootfs ,毕竟Ubuntu 14.10 和Ubuntu14.04 的rootfs 中有很多一致的内容。
Docker 中image 的概念,非常巧妙地解决了以上问题。
最为简单地解释image ,它就是Docker 容器中只读文件系统rootfs 的一部分。
换言之实际上Docker 容器的rootfs 可以由多个image 来构成。多个image 构成rootfs 的方式依然沿用Union Mount 技术。
多个image 构成的rootfs 如图所示(其中 rootfs 中每一层image 中的内容划分只为了阐述清楚rootfs 由多个image 构成,并不代表实际情况下rootfs 中的内容划分)
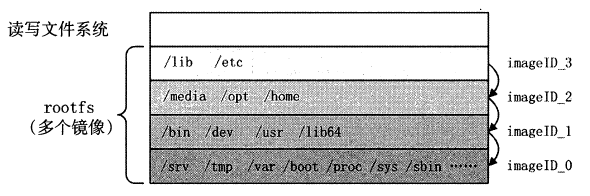
容器rootfs 包含4 个image ,其中每个image 中都有一些用户视角文件系统中的一部分内容。
4 个image 处于层叠的关系,除了最底层的image ,每一层的 image 都叠加在另一个image 之上。
另外每一个image 均含有一个image ID ,用于唯一地标记该image 。
基于以上概念, Docker Image 中又抽象出两种概念:父镜像以及基础镜像。除了容器 rootfs 最底层的镜像,其余镜像都依赖于其底下的一个或多个镜像。
这种情况下, Docker 将下一层的镜像称为上一层镜像的父镜像。
imageID_0 是imageID_1 的父镜像,imageID_2 是imageID_3 的父镜像,而imageID_O 没有父镜像。
对于最下层的镜像,即没有父镜像的镜像,在Docker 中我们习惯称之为基础镜像。
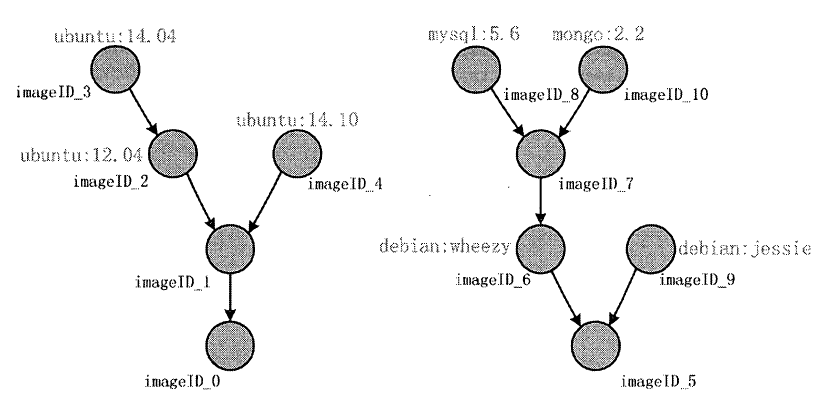
通过Image 的形式,原先较为臃肿的rootfs 被逐渐打散成轻便的多层。
除了轻便的特性之外, image 同时还有前面提到的只读特性,如此一来,在不同的容器、不同的rootfs 中image 完全可以用来复用。
多image 组织关系与复用关系如图
layer
在Docker 中,术语layer 是一个与image 含义较为相近的词。容器镜像的rootfs 是容器只读的文件系统, rootfs 又由多个只读的Image 构成。
于是rootfs 中每个只读的image 都可以称为一个layer。
除了只读的Image 之外, Docker Daemon 在创建容器时会在容器的rootfs 之上,再挂载一层读写文件系统,而这一层文件系统也称为容器的一个layer ,常被称为top layer。
实际情况下, Docker 还会在rootfs 和top layer 之间再挂载一个layer ,这一个layer 中主要包含的内容是/etc/hosts 、/etc/hostname 以及/etc/resolv.conf,一般这一个layer 称为init layer。
为了简化阐述流程,我们暂不提init layer。
因此总之, Docker 容器中每一层只读的image 以及最上层可读写的文件系统,均称为layer。
如此一来, layer 的范畴比image 多了一层,即多包含了最上层的读写文件系统。
有了layer 的概念,大家可以思考这样一个问题:容器文件系统分为只读的rootfs ,以及可读写的top layer ,那么容器运行时若在top layer 中写入了内容,这些内容是否可以持久化,并且也被其他容器复用?
答案是肯定的。
Docker 的设计理念中, top layer 转变为image 的行为( Docker 中称为 commit 操作)进一步释放了容器rootfs 的灵活性。
Docker 的开发者完全可以基于某个镜像创建容器做开发工作,并且无论在开发周期的哪个时间点,都可以对容器进行commit ,将所有top layer 中的内容打包为一个image ,构成一个新的镜像。
commit 完毕之后,用户完全可以基于新的镜像,进行开发、分发、测试、部署等。
不仅Docker commit 的原理如此,基于Dockerfile 的docker build 最为核心的思想,也是不断将容器的top layer 转化为image
Docker镜像下载
大家肯定对两条命令不陌生: docker pull 和docker run。这两条命令中,正是前者实现了Docker Image 的下载。
Docker Daemon 在执行这条命令时,会将Docker Image 从Docker Registry 下载至本地,并保存在本地 Docker Daemon 管理的Graph 中。
Docker 下载Docker Image 的过程。分析内容主要包括以下4 部分:
- 概述Docker 镜像下载的流程,涉及Docker Client 、Docker Server 以及Docker
Daemon; - Docker Client 处理并发送docker pull 请求;
- Docker Server 接收docker pull 请求,创建镜像下载任务并触发执行;
- Docker Daemon 执行镜像下载任务,并存储镜像至Graph 。
Docker 镜像下载流程
如图所示, Docker Image 的下载流程可以归纳为以下3 个步骤:
- 用户通过Docker Client 发送pull 请求,用于让Docker Daemon 下载指定名称的镜像;
- Docker Server 接收Docker 镜像的pull 请求,创建下载镜像任务并触发执行;
- Docker Daemon 执行镜像下载任务,从Docker Registry 中下载指定镜像,并将其存储于本地的Graph 中。
Docker Client
Docker 架构中, Docker 用户的角色绝大多数由Docker Client 来扮演。
因此用户对Docker 的管理请求全部由Docker Client 来发送, Docker 镜像下载请求自然也不例外。
为了更清晰地描述Docker 镜像下载,本节结合具体的命令进行分析,命令如下:docker pull ubuntu:14.04
此命令的含义是:通过docker 二进制可执行文件,执行镜像下载的pull 命令,镜像参数为ubuntu:14.04 ,镜像名称为ubuntu ,镜像标签( tag) 为14.04。
此命令一经发起,第一个接受并处理的Docker 组件为Docker Client ,执行内容包括以下三个步骤:
- 解析命令中与Docker 镜像相关的参数;
- 配置Docker 下载镜像时所需的认证信息;
- 发送RESTful 请求至Docker Daemon 。
解析镜像参数
Docker Client 执行pull 请求相应的处理函数,源码位于./docker/api/client/command.go#L1183-L1244
另外纵观以上源码,可以发现Docker Client 解析的镜像参数无外乎4 个: tag 、remote 、v 以及hostname ,四者各自的作用如下。
- tag: 带有Docker 镜像的标签(已弃用);
- remote: 带有Docker 镜像的名称与标签;
- v: 类型为url.Values ,实质是一个map 类型,用于配置请求中URL 的查询参数;
- hostname: Docker Registry 的地址,代表用户希望从指定的Docker Registry 下载 Docker 镜像。
配置认证信息
用户下载Docker 镜像时Docker 同样支持用户信息的认证。用户认证信息由Docker Client 配置;
Docker Client 发送请求至Docker Server 时,用户认证信息也被一并发送;
随后Docker Daemon 处理下载Docker 镜像的请求时,用户认证信息将在Docker Registry 中验证。
发送API 请求
解析完所有的Docker 镜像参数,并且配置完毕用户的认证信息之后, Docker Client 需要使用这些信息正式发送镜像下载的请求至Docker Server。
Docker Client 定义了pull 函数来实现发送镜像下载请求至Docker Server ,源码位于./docker/apνclienνcommands.go#L1217-L1229
Docker Server
Docker Server 作为Docker Daemon 的入口,所有Docker Client 发送请求都由Docker Server 接收。
Docker Server 通过解析请求的URL 与请求方法,最终路由分发至相应的处理方法来处理。
Docker Server 接收到镜像下载请求之后通过路由分发最终由具体的处理方法一postImagesCreate来处理。postImagesCreate 的源码实现位于docker/api/server/server.go#L466-L524 ,其执行流程主要分为3 部分
- 解析HTTP 请求中包含的请求参数,包括URL 中的查询参数、HTTP Header 中的认证信息等;
- 创建镜像下载Job ,并为该Job 配置环境变量;
- 触发执行镜像下载Job 。
解析请求参数
Docker Server 接收到Docker Client 发送的镜像下载请求之后,首先解析请求参数,并为后续Job 的创建与运行提供参数依据。
Docker Server 解析的请求参数主要有HTTP 请求URL 中的查询参数”fromImage” 、”repo” 以及”tag” ,还有HTTP 请求Header 中的”X-Registry-Auth” 。
1 | 需要特别说明的是,通过" fromImage" 解析出的image 变量包含镜像repository 名称与镜像tag 信息。 |
创建并配置Job
Docker Server 只负责接收Docker Client 发送的请求,并将其路由分发至相应的处理方法来处理,最终的请求执行还需要Docker Daemon 来协作完成。
Docker Server 在处理方法中,通过创建Job 并触发job 执行的形式,把控制权交给Docker Daemon 。
触发执行Job
Docker Server 创建完Docker 镜像下载Job 之后,需要触发该Job 执行,实现将控制权交给Docker Daemon
由于Docker Daemon 在启动时,已经配置了名为” pull” 的Job 所对应的处理方法,实际为graph 包中的CmdPull 函数,故一旦该Job 被触发执行,控制权将直接交给Docker Daemon 的CmdPull 函数。
Docker Daemon
Docker Daemon 是完成Job 执行的主要载体。
Docker Server 为镜像下载Job 准备好所有的参数配置之后,只等Docker Daemon 来完成执行,并返回相应的信息
Docker Server 再将响应信息返回至Docker Client
Docker Daemon 对于镜像下载Job 的执行涉及的内容较多:
- 首先解析Job 参数,获取Docker 镜像的repository、tag 以及Docker Registry 信息等;
- 随后与 Docker Registry 建立会话(session) ;
- 然后通过会话下载Docker 镜像;
- 接着将Docker 镜像下载至本地并存储于Graph 中;
- 最后在TagStore 中标记该镜像。
Docker Daemon 对于镜像下载Job 的执行主要依靠CmdPull 函数。
这个CmdPull 函数与Docker Client 的CmdPull 函数完全不同,前者是为了代替用户发送镜像下载的请求至Docker Daemon ,而Docker Daemon 的CmdPull 函数则实现代替用户真正完成镜像下载的任务。
调用CmdPull 函数的对象类型为TagStore ,其源码实现位于./docker/graph/pull.go 。
解析Job 参数

创建session 对象
为了下载Docker 镜像, Docker Daemon 与Docker Regist可需要建立通信。为了保障两者之间通信的可靠性, Docker Daemon 采用了sesslOn 机制。
Docker Daemon 每收到一个Docker Client 的镜像下载请求,都会创建一个与之相应的Docker Registry 的session ,之后所有的网络数据传输都在该session 上完成。
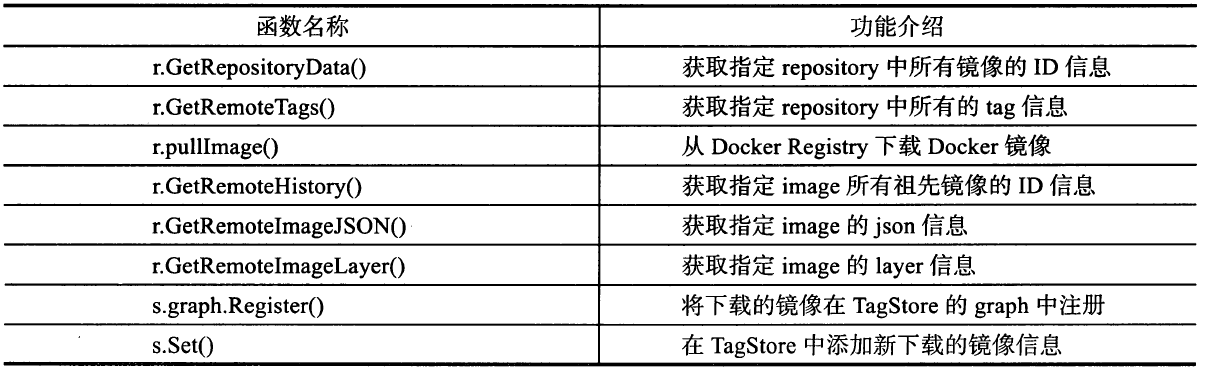
执行镜像下载
pullRepository可函数包含了镜像下载整个流程的林林总总, 如图
Docker存储管理
镜像分层、写时复制机制以及内容寻址存储(content-addressable storage),为了支持这些特性,Docker设计了一套镜像元数据管理机制来管理镜像元数据。另外,为了能够让Docker容器适应不同平台不同应用场景对存储的要求,Docker提供了各种基于不同文件系统实现的存储驱动来管理实际镜像文件。
Docker镜像元数据管理
Docker镜像管理相关的概念,包括repository、image、layer。
Docker在管理镜像层元数据时,采用的也正是从上至下repository、image、layer三个层次。
由于Docker以分层的形式存储镜像,所以repository与image这两类元数据并无物理上的镜像文件与之对应,而layer这种元数据则存在物理上的镜像层文件与之对应
repository元数据
repository即由具有某个功能的Docker镜像的所有迭代版本构成的镜像库。
repository在本地的持久化文件存放于/var/lib/docker/image/some_graph_driver/repositories.json中
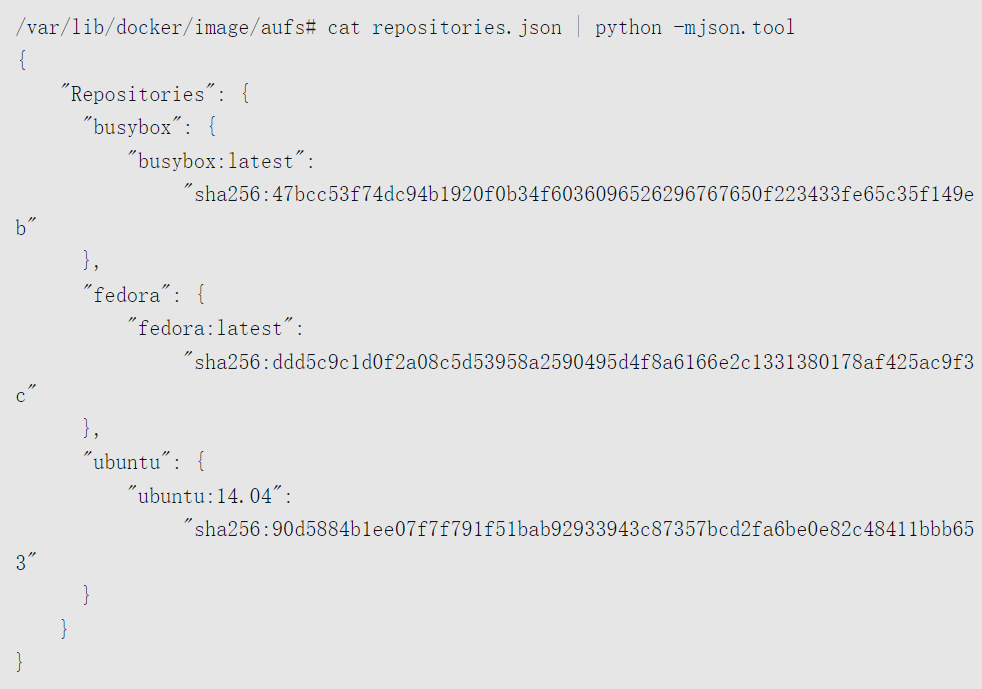
文件中存储了所有repository的名字(如busybox),每个repository下所有版本镜像的名字和tag(如busybox:latest)以及对应的镜像ID。
而referenceStore的作用便是解析不同格式的repository名字,并管理repository与镜像ID的映射关系。
image元数据
image元数据包括了镜像架构(如amd64)、操作系统(如Linux)、镜像默认配置、构建该镜像的容器ID和配置、创建时间、创建该镜像的Docker版本、构建镜像的历史信息以及rootfs组成。
其中构建镜像的历史信息和rootfs组成部分除了具有描述镜像的作用外,还将镜像和构成该镜像的镜像层关联了起来。
Docker会根据历史信息和rootfs中的diff_ids计算出构成该镜像的镜像层的存储索引chainID,这也是Docker 1.10镜像存储中基于内容寻址的核心技术,详细计算方式将在稍后叙述。
imageStore则管理镜像ID与镜像元数据之间的映射关系以及元数据的持久化操作,持久化文件位于/var/lib/docker/image/[graph_driver]/imagedb/content/sha256/[image_id]中。
layer元数据
layer对应镜像层的概念,在Docker 1.10版本以前,镜像通过一个graph结构管理,每一个镜像层都拥有元数据,记录了该层的构建信息以及父镜像层ID,而最上面的镜像层会多记录一些信息作为整个镜像的元数据。
graph则根据镜像ID(即最上层的镜像层ID)和每个镜像层记录的父镜像层ID维护了一个树状的镜像层结构。
Docker存储驱动
上面介绍了镜像分层与写时复制机制,为了支持这些特性,Docker提供了存储驱动的接口。
存储驱动根据操作系统底层的支持提供了针对某种文件系统的初始化操作以及对镜像层的增、删、改、查和差异比较等操作。
目前存储系统的接口已经有aufs、btrfs、devicemapper、vfs、overlay、zfs这6种具体实现,其中vfs不支持写时复制,是为使用volume(Docker提供的文件管理方式,后面节将会具体介绍)提供的存储驱动,仅仅做了简单的文件挂载操作;剩下5种存储驱动支持写时复制,它们的实现有一定的相似之处。
并以aufs、overlay和devicemapper为例介绍存储驱动的具体实现
存储驱动的功能与管理
Docker中管理文件系统的驱动为graphdriver。
其中定义了统一的接口对不同的文件系统进行管理,在Docker daemon启动时就会根据不同的文件系统选择合适的驱动
本节将针对GraphDriver中的功能进行详细的介绍
存储驱动接口定义
GraphDriver中主要定义了Driver和ProtoDriver两个接口,所有的存储驱动通过实现Driver接口提供相应的功能,而ProtoDriver接口则负责定义其中的基本功能。这些基本功能包括如下8种。
- String()返回一个代表这个驱动的字符串,通常是这个驱动的名字。
- Create()创建一个新的镜像层,需要调用者传进一个唯一的ID和所需的父镜像的ID。
- Remove()尝试根据指定的ID删除一个层。
- Get()返回指定ID的层的挂载点的绝对路径。
- Put()释放一个层使用的资源,比如卸载一个已经挂载的层。
- Exists()查询指定的ID对应的层是否存在。
- Status()返回这个驱动的状态,这个状态用一些键值对表示。
- Cleanup()释放由这个驱动管理的所有资源,比如卸载所有的层。
而正常的Driver接口实现则通过包含一个ProtoDriver的匿名对象实现上述8个基本功能
除此之外Driver还定义了其他4个方法,用于对数据层之间的差异(diff)进行管理。
- Diff()将指定ID的层相对父镜像层改动的文件打包并返回。
- Changes()返回指定镜像层与父镜像层之间的差异列表。
- ApplyDiff()从差异文件包中提取差异列表,并应用到指定ID的层与父镜像层,返回新镜像层的大小。
- DiffSize()计算指定ID层与其父镜像层的差异,并返回差异相对于基础文件系统的大小。
GraphDriver还提供了naiveDiffDriver结构,这个结构就包含了一个ProtoDriver对象并实现了Driver接口中与差异有关的方法,可以看作Driver接口的一个实现。
综上所述Docker中的任何存储驱动都需要实现上述Driver接口。当我们在Docker中添加一个新的存储驱动的时候,可以实现Driver的全部12个方法,或是实现ProtoDriver的8个方法再使用naiveDiffDriver进一步封装。
不管那种做法,只要集成了基本存储操作和差异操作的实现,一个存储驱动就算开发完成了。
存储驱动的创建过程
首先,前面提到的各类存储驱动都需要定义一个属于自己的初始化过程,并且在初始化过程中向GraphDriver注册自己。
GraphDriver维护了一个drivers列表,提供从驱动名到驱动初始化方法的映射,这用于将来根据驱动名称查找对应驱动的初始化方法。
而所谓的注册过程,则是存储驱动通过调用GraphDriver提供自己的名字和对应的初始化函数,这样GraphDriver就可以将驱动名和这个初始化方法保存到drivers。
当需要创建一个存储驱动时(比如aufs的驱动), GraphDriver会根据名字从drivers中查找到这个驱动对应的初始化方法,然后调用这个初始化函数得到对应的Driver对象。
这个创建过程如下所示
- 依次检查环境变量DOCKER_DRIVER和变量DefaultDriver是否提供了合法的驱动名字(比如aufs),其中DefaultDriver是从Docker daemon启动时的——storage-driver或者-s参数中读出的。获知了驱动名称后,GraphDriver就调用对应的初始化方法,创建一个对应的Driver对象实体。
- 若环境变量和配置默认是空的,则GraphDriver会从驱动的优先级列表中查找一个可用的驱动。“可用”包含两个意思:第一,这个驱动曾经注册过自己;第二,这个驱动对应的文件系统被操作系统支持(这个支持性检查会在该驱动的初始化过程中执行)。在Linux平台下,目前优先级列表依次包含了这些驱动:aufs、btrfs、zfs、devicemapper、overlay和vfs。
- 如果在上述6种驱动中查找不到可用的,则GrapthDriver会查找所用注册过的驱动,找到第一个注册过的、可用的驱动并返回。不过这一设计只是为了将来的可扩展性而存在,用于查找自定义的存储驱动插件,现在有且仅有的上述6种驱动一定会注册自己。
常用存储驱动分析
aufs
首先,让我们来简单认识一下aufs。aufs(advanced multi layered unification filesystem)是一种支持联合挂载的文件系统,简单来说就是支持将不同目录挂载到同一个目录下,这些挂载操作对用户来说是透明的,用户在操作该目录时并不会觉得与其他目录有什么不同。这些目录的挂载是分层次的,通常来说最上层是可读写层,下层是只读层。所以,aufs的每一层都是一个普通文件系统。
当需要读取一个文件A时,会从最顶层的读写层开始向下寻找,本层没有,则根据层之间的关系到下一层开始找,直到找到第一个文件A并打开它。
当需要写入一个文件A时,如果这个文件不存在,则在读写层新建一个;否则像上面的过程一样从顶层开始查找,直到找到最近的文件A, aufs会把这个文件复制到读写层进行修改。
由此可以看出,在第一次修改某个已有文件时,如果这个文件很大,即使只要修改几个字节,也会产生巨大的磁盘开销。当需要删除一个文件时,如果这个文件仅仅存在于读写层中,则可以直接删除这个文件;否则就需要先删除它在读写层中的备份,再在读写层中创建一个whiteout文件来标志这个文件不存在,而不是真正删除底层的文件。
当新建一个文件时,如果这个文件在读写层存在对应的whiteout文件,则先将whiteout文件删除再新建。否则直接在读写层新建即可。
那么镜像文件在本地存放在哪里呢?
我们知道Docker的工作目录是/var/lib/docker,查看该目录下的内容可以看到如下文件。

如果你正在使用或者曾经使用过aufs作为存储驱动,就会在Docker工作目录和image下发现aufs目录。关于image/aufs目录下的内容,本书在前面已经比较详细地介绍过了,是用于存储镜像相关的元数据的,存储逻辑上的镜像和镜像层。
下面一起探究/var/lib/docker下另一个aufs文件夹。

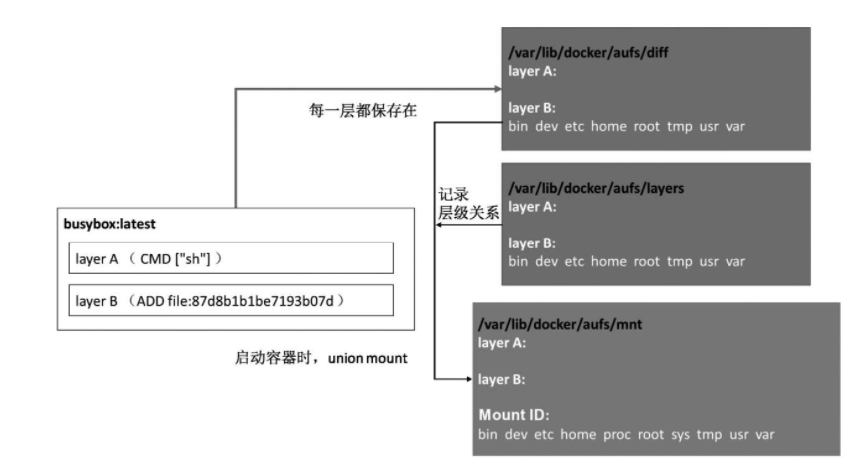
进入其中可以看到3个目录,其中mnt为aufs的挂载目录,diff为实际的数据来源,包括只读层和可读写层,所有这些层最终一起被挂载在mnt上的目录,layers下为与每层依赖有关的层描述文件。
最初mnt和layers都是空目录,文件数据都在diff目录下。一个Docker容器创建与启动的过程中,会在/var/lib/docker/aufs下面新建出对应的文件和目录。
由于改版后,Docker镜像管理部分与存储驱动在设计上完全分离了,镜像层或者容器层在存储驱动中拥有一个新的标示ID,在镜像层(roLayer)中称为cacheID,容器层(mountedLayer)中为mountID。
在Unix环境下,mountID是随机生成的并保存在mountedLayer的元数据mountID中,持久化在image/aufs/layerdb/mounts/[container_id]/mount-id中。
由于讲解的是容器创建过程中新创建的读写层,下面以mountID为例。
创建一个新镜像层的步骤如下
- 分别在mnt和diff目录下创建与该层的mountID同名的子文件夹。
- 在layers目录下创建与该层的mountID同名的文件,用来记录该层所依赖的所有的其他层。
- 如果参数中的parent项不为空(这里由于是创建容器,parent就是镜像的最上层),说明该层依赖于其他的层。GraphDriver就需要将parent的mountID写入到该层在layers下对应mountID的文件里。然后GraphDriver还需要在layers目录下读取与上述parent同mountID的文件,将parent层的所有依赖层也复制到这个新创建层对应的层描述文件中,这样这个文件才记录了该层的所有依赖。创建成功后,这个新创建的层的描述文件如下:
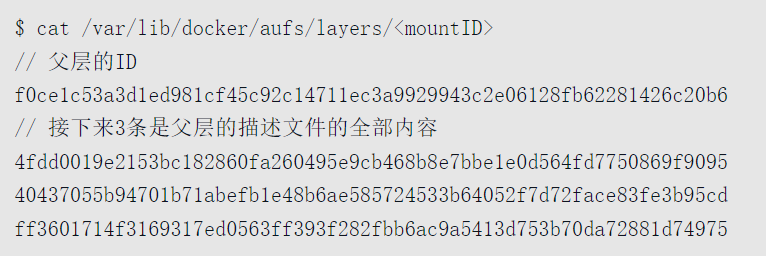
随后GraphDriver会将diff中属于容器镜像的所有层目录以只读方式挂载到mnt下,然后在diff中生成一个以当前容器对应的

可以看到这些文件与这个容器内的环境息息相关,但并不适合被打包作为镜像的文件内容(毕竟文件里的内容是属于这个容器特有的),同时这些内容又不应该直接修改在宿主机文件上,所以Docker容器文件存储中设计了mountID-init这么一层单独处理这些文件。
这一层只在容器启动时添加,并会根据系统环境和用户配置自动生成具体的内容(如DNS配置等),只有当这些文件在运行过程中被改动后并且docker commit了才会持久化这些变化,否则保存镜像时不会包含这一层的内容。
所以严格地说,Docker容器的文件系统有3层:可读写层(将来被commit的内容)、init层和只读层。但是这并不影响我们传统认识上可读写层+只读层组成的容器文件系统:因为init层对于用户来说是完全透明的。
接下来会在diff中生成一个以容器对应mountID为名的可读写目录,也挂载到mnt目录下。所以,将来用户在容器中新建文件就会出现在mnt下以mountID为名的目录下,而该层对应的实际内容则保存在diff目录下。
至此我们需要明确,所有文件的实际内容均保存在diff目录下,包括可读写层也会以mountID命名出现在diff目录下,最终会整合到一起联合挂载到mnt目录下以mountID为名的文件夹下。接下来我们统一观察mnt对应的mountID下的变化。
首先让我们看看要运行的镜像对应的容器ID,其容器短ID为“7e7d365e363e”。

查看容器层对应mountID为“7e2152451105f352a78421a9f78061bdc8c9895002dcd12f71bf49b7057f2b45”。

再来看看该容器运行前对应的mnt目录,看到对应mountID文件夹下是空的。

然后我们启动容器,再次查看对应的mountID文件夹的大小。
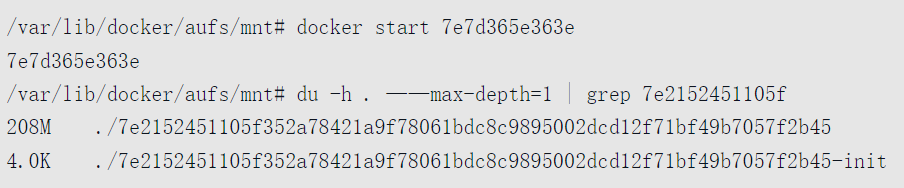
可以看到以mountID命名的文件夹变大了,进入可以看到已经挂载了对应的系统文件。

接下来我们进入容器,查看容器状态,并添加一个1GB左右的文件
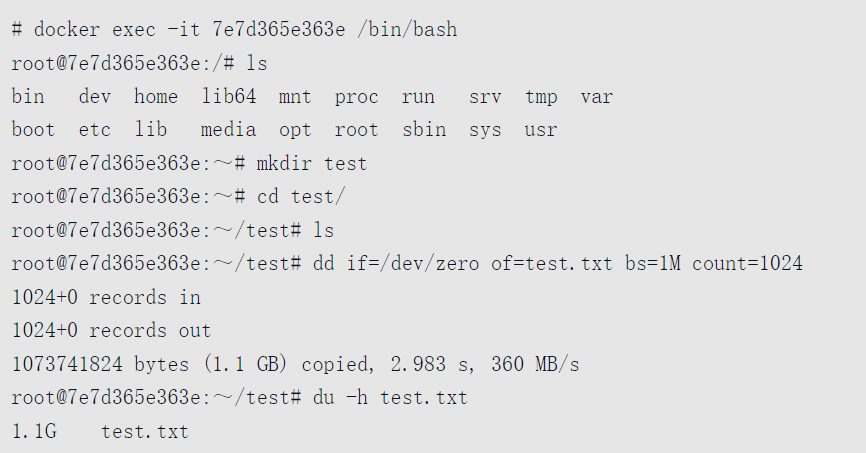
当我们在容器外查看文件变化时可以看到,以mountID命名的文件夹大小出现了变化,如下所示

我们在容器中生成的文件出现在对应容器对应mountID文件夹中的root文件夹内。而当我们停止容器时,mnt下相应mountID的目录被卸载,而diff下相应文件夹中的文件依然存在。
当然这仅限于当前宿主机,当我们需要迁移容器时,需要把这些内容保存成镜像再操作。综上所述,以aufs为例的话,Docker镜像的主要存储目录和作用可以通过图来解释
最后当我们用docker commit把容器提交成镜像后,就会在diff目录下生成一个新的cacheID命名的文件夹,存放了最新的差异变化文件,这时一个新的镜像层就诞生了。
而原来的以mountID为名的文件夹已然存在,直至对应容器被删除。
overlay
OverlayFS是一种新型联合文件系统(union filesystem),它允许用户将一个文件系统与另一个文件系统重叠(overlay),在上层的文件系统中记录更改,而下层的文件系统保持不变。
相比于aufs,OverlayFS在设计上更简单,理论上性能更好,最重要的是,它已经进入Linux 3.18版本以后的内核主线,所以在Docker社区中很多人都将OverlayFS视为aufs的接班人。
Docker的overlay存储驱动便建立在OverlayFS的基础上。
OverlayFS主要使用4类目录来完成工作,被联合挂载的两个目录lower和upper,作为统一视图联合挂载点的merged目录,还有作为辅助功能的work目录。作为upper和lower被联合挂载的统一视图,当同一路径的两个文件分别存在两个目录中时,位于上层目录upper中的文件会屏蔽位于下层lower中的文件,如果是同路径的文件夹,那么下层目录中的文件和文件夹会被合并到上层。
在对可读写的OverlayFS挂载目录中的文件进行读写删等操作的过程与挂载两层的aufs(下层是只读层,上层是可读写层)是类似的。
需要注意的一点是,第一次以write方式打开一个位于下层目录的文件时,OverlayFS会执行一个copy_up将文件从下层复制到上层,与aufs不同的是,这个copy_up的实现不符合POSIX标准[插图]。
OverlayFS在使用上非常简单,首先使用命令lsmod | grep overlay确认内核中是否存在overlay模块,如果不存在,需要升级到3.18以上的内核版本,并使用modprobe overlay加载。然后再创建必要文件夹并执行mount命令即可完成挂载,最后可以通过查看mount命令的输出来确认挂载结果。

在了解了OverlayFS的原理后,下面介绍一下Docker的overlay存储驱动是如何实现的。首先请读者直观感受一下overlay的目录结构。
overlay存储驱动的工作目录是/var/lib/docker/overlay/,在本书的实验环境中,该存储驱动下共存储了两个镜像与一个容器。
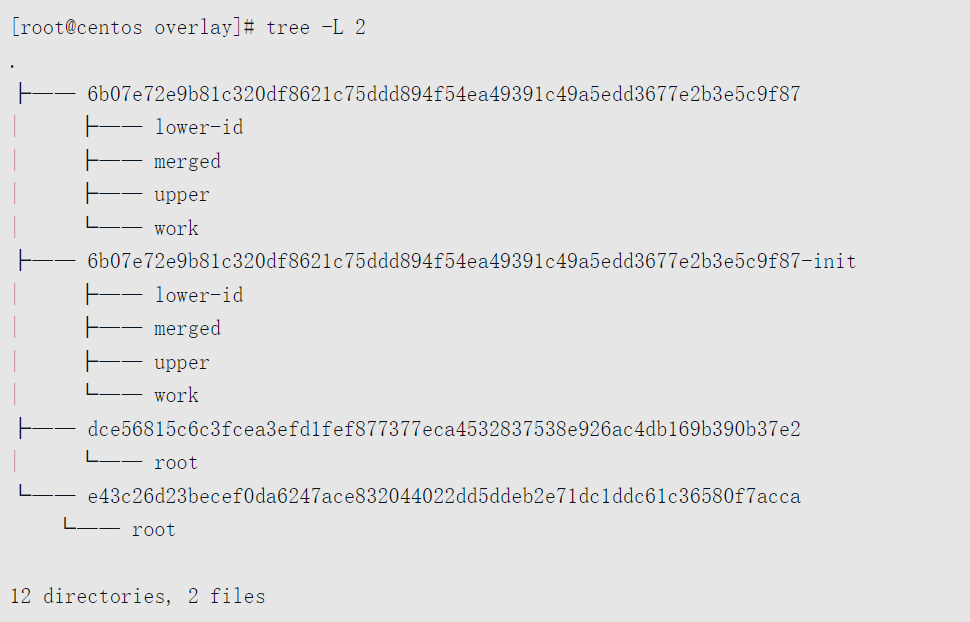
读者可以清楚地看到overlay目录下面以UUID命名的文件夹下的目录结构分为两种,一种是只有root目录的,另一种则有3个文件夹和一个文件lower-id。
根据UUID中是否带-init后缀以及UUID名,很容易能判断出来,前者是镜像层的目录,后者是容器层(包括init层)的目录。
读者可能会觉得比较奇怪,为什么镜像层与容器层要采用不同的目录结构。
前面介绍OverlayFS原理是将一层目录重叠于另一层目录之上,也就是说OverlayFS文件系统只会涉及两个目录,而Docker镜像却可能有许多层[插图]。
为了解决这种不对应的情况,overlay存储驱动在存储镜像层的时候,会把父镜像层的内容“复制”到当前层,然后再写入当前层,为了节省存储空间,在“复制”的过程中,普通文件是采用硬链接的方式链接到父镜像层对应文件,其他类型的文件或文件夹则是按照原来的内容重新创建。
所以上层镜像层拥有其依赖镜像层的所有文件,而最上面的镜像层则拥有了整个镜像的文件系统,这也是为什么镜像层对应的目录中只有一个root文件夹。
至于另一种目录结构,细心的读者可能已经参照上面介绍OverlayFS工作的4种目录找到了对应关系。upper对应上层目录,merged对应挂载点目录,work对应辅助工作(比如copy_up操作需要用到)目录,但lower-id却是一个文件,里面记录了该容器层所属容器的镜像最上面镜像层的cache-id,在本书上面的实验环境中,lower-id内记录的是e43c26d23b<省略部分...>acca, Docker使用该cache-id找到所依赖镜像层的root目录作为下层目录。
在准备最上层可读写容器层的时候,会将init层的lower-id与upper目录中的内容全部复制到容器层中。最后为容器准备rootfs时,将对应的4种文件夹联合挂载即可。下面通过在容器里面新建一个文件,然后在存储驱动对应目录中查看,请读者直观感受一下具体的文件存储位置。

最后需要说明一下,虽然overlay存储驱动曾经一度被提议提升为默认驱动[插图],但其本身仍是一个发展相对初级的存储驱动,用户需要谨慎在生产环境中使用。相对于aufs,除了本节开始提到的优点之外,由于OverlayFS只实现了POSIX标准的子集(例如copy-up等操作不符合POSIX标准),在运行在overlay存储驱动上的容器中直接执行yum命令会出现问题;另外一点就是,在使用overlay存储驱动时会消耗大量的inode,尤其是对于本地镜像和容器比较多的用户,而inode只能在创建文件系统的时候指定[插图]。
本节讨论了Docker对镜像元数据、文件系统的管理方法并介绍了3种典型存储驱动的具体实现。用户在使用Docker的时候,可以根据自己的需求和底层操作系统的支持情况灵活地选择最合适的存储驱动。
Docker Daemon 网络
Docker 自身的网络主要包含两部分: Docker Daemon 的网络配置、Docker 容器的网络配置。
分析Docker Daemon 在启动过程中,为Docker 配置的网络环境,内容安排如下:
- Docker Daemon 网络配置。
- 运行Docker Daemon 网络初始化任务。
- 创建Docker 网桥。
Docker Daemon 网络介绍
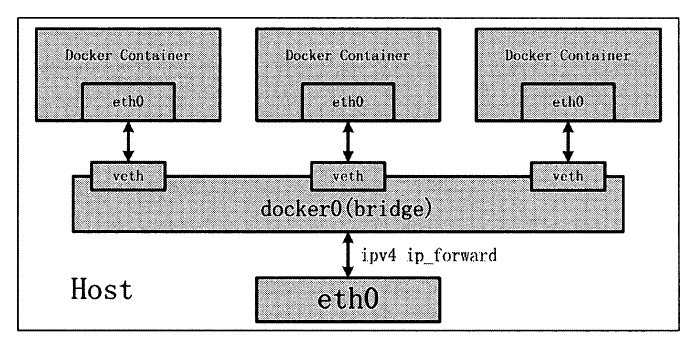
关于Docker 的网络模式,大家最熟知的应该就是”桥接”模式,也被称为bridge 模式。
在桥接模式下, Docker 的网络环境拓扑(包括Docker Daemon 网络环境和Docker Container网络环境)如图
Docker Daemon 网络配置接口
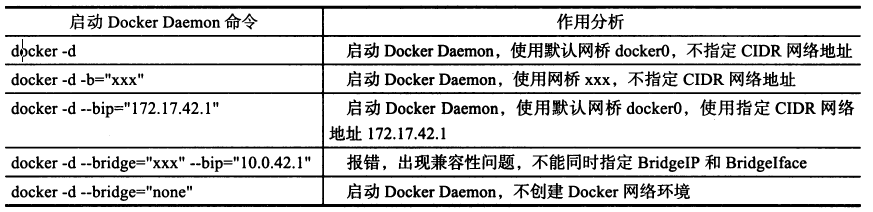
Docker Daemon 每次启动的过程中,都会初始化自身的网络环境。初始化后的网络环境最终为Docker 容器提供网络通信服务。
为了实现Docker Daemon 网络的初始化, Docker 管理员可以在启动Docker Daemon 时,通过参数的形式配置Docker 的网络环境。
配置参数可以通过运行docker 二进制可执行文件来完成,即通过运行docker -d 并添加其他与网络相关的flag 参数来完成。
以下介绍这5 个flag 参数的作用:
- EnableIptables: 确保Docker Daemon 启动时,能对宿主机上的iptables 规则进行修改。
- EnableIpForward :确保net.ipv4中forward 功能开启,使得宿主机在多网络接口模式下,数据包可以在网络接口之间转发。
- BridgeIP: Docker Daemon 为网络环境中的网桥配置的CIDR 网络地址。
- BridgeIface :为Docker 网络环境指定具体的通信网桥,若BridgeIface 的值为none ,则说明不需要为Docker 容器创建网桥服务,关闭Docker 容器的网络能力。
- InterContainerCommunication: 确保Docker 容器之间可以完成通信,通过防火墙完成。
除DockerDaemon 会使用到的5 个flag 参数之外, Docker 在创建网络环境时,还使用一个DefaultIP 变量
Docker Daemon 网络初始化
Docker Daemon 网络初始化流程如图
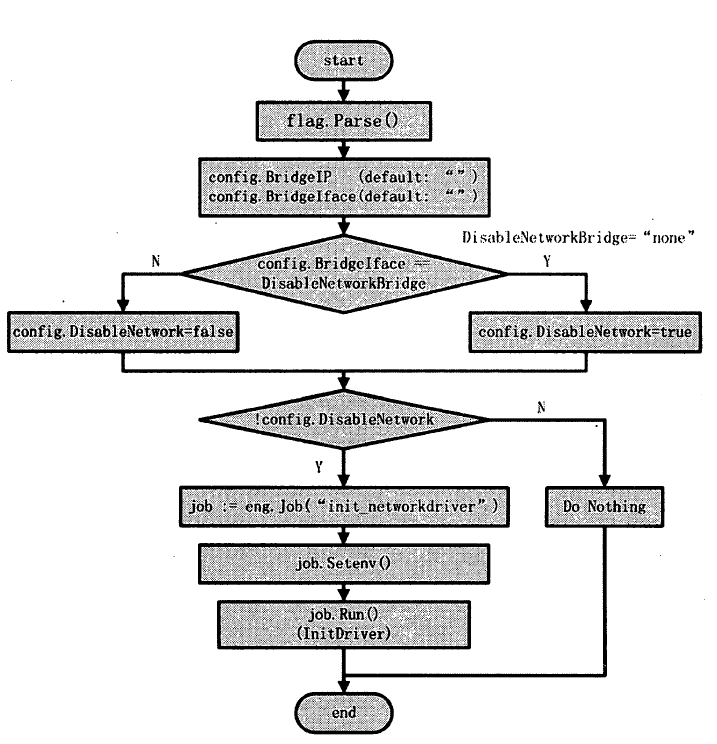
Docker Daemon 网络的初始化流程主要是根据解析 flag 参数来决定到底建立哪种类型的网络环境
- 创建名为init networkdriver 的Job 。
- 为Job 配置环境变量,配置的环境变量有EnableIptables 、InterContainerCommunication 、EnableIpForward 、BridgeIface 、BridgeIP 以及DefaultBindingIP 。
- 触发执行Job 。
刨建Docker 网桥
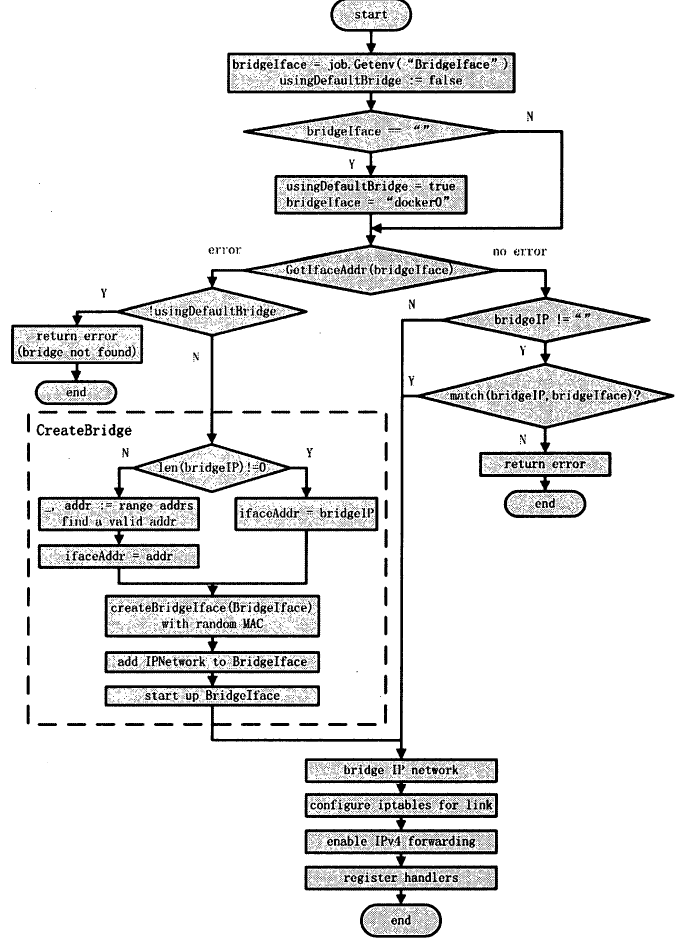
- 提取环境变量
- 确定Docker 网桥设备名
提取Job 的环境变量之后, Docker 随即确定最终使用网桥设备的名称。为此 Docker 首先是否使用默认的网桥设备,默认值为false。
接着若环境变量中bridgelface 的值为空,则说明用户启动Docker 时,没有指定特定的网桥设备名,因此Docker 首先将usingDefaultBridge 置为true ,然后使用默认的网桥设备名DefaultNetworkBridge 赋值于bridgelface ,即dockerO - 查找bridgelface 网桥设备
确定Docker 网桥设备名bridgelface 之后, Docker 首先通过bridgelface 设备名在宿主机上查找该设备是否真实存在。
若存在,则返回该网桥设备的IP 地址,若不存在,则返回nil 。 - bridgelface 己创建
Docker Daemon 所在宿主机上bridgeIface 的网桥设备存在时, Docker Daemon 仍然需要验证用户在配置信息中是否为网桥设备指定了IP 地址。 - bridgelface 未创建
Docker Daemon 所在宿主机上bridgelface 的网桥设备未创建时,上文已经介绍将存在两种情况- 用户指定的bridgelface 未创建。
当用户指定的bridgelface 不存在于宿主机时,即没有使用Docker 的默认网桥设备名dockerO , Docker 打印日志信息”指定网桥设备未找到”,并返回网桥未找到的错误信息。 - 用户未指定bridgelface ,而docker0 暂未创建。
当使用默认网桥设备名,而dockerO 网桥设备还未创建时, Docker Daemon 则立即实现创建网桥的操作,并返回该dockerO 网桥设备的IP 地址
- 用户指定的bridgelface 未创建。
- 获取网桥设备的网络地址
创建完网桥设备之后,网桥设备必然会存在一个网络地址。网桥网络地址的作用为:Docker Daemon 在创建Docker 容器时,使用该网络地址为Docker 容器分配IP 地址。 - 配置Docker Daemon 的iptables
创建完网桥之后, Docker Daemon 为容器以及宿主机配置iptables ,包括为容器之间所需要的link 操作提供支持,为宿主机上所有的对外对内流量制定传输规则等。 - 配置网络设备闰数据报转发功能
默认情况下, Linux 操作系统上的数据包转发功能是禁止的。数据包转发就是当宿主机存在多个网络设备时,如果其中一个接收到数据包,并将其转发给另外的网络设备。
Docker Daemon 通过修改/proc/sys/net/ipv4/ip_ forward的值,将其置为1 ,则可以保证系统内数据包可以实现转发功能 - 注册网络Handler
创建Docker Daemon 网络环境的最后一个步骤是:注册4 个与网络相关的Handler。
这 4 个处理方法分别是allocate interface 、release interface 、allocate__port 和link ,作用分别是为Docker 容器分配IP 网络地址,释放Docker 容器网络设备,为Docker 容器分配端口资源,以及在Docker 容器之间执行link 操作。
至此Docker Daemon 的网络环境初始化工作全部完成。
Docker 容器网络
说到运行环境的”隔离”,相信大家肯定对Linux 内核中的namespaces 和cgroups 略有耳闻
namespaces 主要负责命名空间的隔离, cgroups 主要负责资源使用的限制。
其实正是这两个神奇的内核特性联合使用,才保证了Docker 容器之间的”隔离”。
那么namespaces和cgroups 又和进程有什么关系呢?
问题的答案可以用以下的次序来表示:
- 父进程通过fork 创建子进程时,使用namespaces 技术,实现子进程与父进程以及其他进程之间命名空间的隔离。
- 子进程创建完毕之后,使用cgroups 技术来处理进程,实现进程的资源限制。
- namespaces 和cgroups 这两种技术都用上之后,进程所处的”隔离”环境才真正建立,此时”容器”真正诞生!
可以说Linux 内核的namespaces 和cgroups 技术,实现了资源的隔离与限制。那么对于资源的隔离,是否还需要为容器准备必需的资源
比如说容器需要使用的网络资源,容器需要使用的文件系统挂载点等。
这回答案是肯定的。
网络资源就是一个很好的例子。当Docker Daemon 为进程创建完隔离的运行环境之后,我们可以发现进程并没有独立的网络技可以使用,如独立的网络接口等。
此时, Docker Daemon 会将Docker 容器内部所需要的资源一一配备齐全。
网络方面即为Docker 容器通过用户指定的网络模式,配置相应的网络资源。
本分析的主要内容有以下5 部分:
- Docker 容器的网络模式
- Docker Client 配置容器网络
- Docker Daemon 创建容器网络流程
- execdriver 网络执行流程
- libcontainer 实现内核态网络配置
Docker 容器网络模式
bridge 桥接模式
bridge 桥接模式的实现步骤如下。
- 利用veth pair 技术,在宿主机上创建两个虚拟网络接口,假设为vethO 和vethl 。而veth pair 技术的特性可以保证无论哪一个veth 接收到网络报文,都会将报文传输给另一方。
- Docker Daemon 将vethO 附加到Docker Daemon 创建的dockerO 网桥上。保证宿主机的网络报文有能力发往vethO o
- Docker Daemon 将vethl 添加到Docker 容器所属的网络命名空间( namespaces) 下,vethl 在Docker 容器看来就是ethO。一方面,保证宿主机的网络报文若发往vethO ,可以立即被veth1 收到,实现宿主机到Docker 容器之间网络的联通性;另一方面,保证Docker 容器单独使用veth1 ,实现容器之间以及容器与宿主机之间网络环境的隔离性。
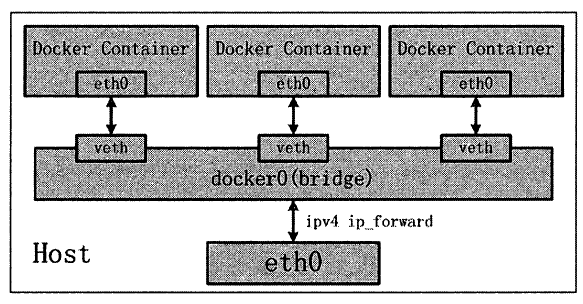
bridge 桥接模式,从原理上实现了Docker 容器到宿主机乃至其他机器的网络联通性。
然而由于宿主机的IP 地址与veth pair 的IP 地址不属于同一个网段,故仅仅依靠veth pair和网络命名空间的技术,还不足以使宿主机以外的网络主动发现Docker 容器的存在。
为使Docker 容器有能力让宿主机以外的世界感受到容器内部暴露的服务, Docker 采用NAT(Network Address Translation ,网络地址转换)的方式让宿主机以外的世界可以将网络报文发送至容器内部。
因此, Docker 使用NAT 方法,将容器内部的服务与宿主机的某一个端口port_l 进行”绑定”。
如此一来,外界访问Docker 容器内部服务的流程为:
- 外界访问宿主机的IP 以及宿主机的端口port_l 。
- 当宿主机接收到这类请求之后,由于存在DNAT 规则,会将该请求的目的IP (宿主机ethO 的IP) 和目的端口port_l 进行替换,替换为容器IP 和容器端口port_O 。
- 由于能够识别容器IP ,故宿主机可以将请求发送给veth pair 。
- veth pair 将请求发送至容器,容器交于内部服务进行处理。
使用DNAT 方法,可以使Docker 宿主机以外的世界主动访问Docker 容器。那么Docker容器如何访问宿主机以外的世界呢?
以下简要分析Docker 容器内部访问宿主机以外世界的流程
- Docker 容器内部进程获悉宿主机外部服务的IP 地址和端口port_2 ,于是Docker 容器发起请求。容器独立的网络环境保证了请求中报文的源IP 地址为容器IP (即容器内部ethO ,veth pair 一方的IP 地址),另外Linux 内核会自动为进程分配一个可用端口(假设为port_3 )。
- 请求通过容器内部ethO 发送至veth pair 的另一端,也就是到达网桥dockerO 处。
- dockerO 网桥开启了数据报转发功能(
/proc/sys/netJipv4/ip forward) ,故dockerO 将请求发送至宿主机的ethO 处。 - 宿主机处理请求时,使用SNAT 对请求进行源地址IP 替换,即将请求中源地址IP( 容器ethO 的IP 地址)替换为宿主机ethO 的IP 地址。
- 宿主机将经过SNAT 处理后的报文通过请求的目的IP 地址(宿主机以外世界的IP 地址)发送至外界。
在这里很多人肯定要问:对于Docker 容器内部主动发起对外的网络请求,请求到达宿主机进行SNAT 处理发给外界之后,当外界响应请求时,响应报文中的目的IP 地址肯定是Docker Daemon 所在宿主机的IP 地址,那响应报文回到宿主机的时候,宿主机又是如何转给Docker 容器的呢?
关于这样的响应,由于没有做相应的DNAT 转换,原则上不会被发送至容器内部。为什么说对于这样的响应,不会做DNAT 转换呢。
原因很简单, DNAT 转换是针对特定容器内部服务监听的特定端口做的,该端口是供服务监听使用,而容器内部发起的请求报文中,源端口号肯定不会占用服务监昕的端口,故容器内部发起请求的响应不会在宿主机上经过DNAT 处理。
其实,这一环节的关键在于iptables ,具体的iptables 规则如下:Iptables -I FORWARD -o dockerO -m conntrack --ctstate RELATED, ESTABLISHED -j ACCEPT
此iptables规则的意思是:在宿主机上发往docker0网桥的网络数据报文,如果该数据报文所处的连接已经建立,则无条件接受,并由Linux 内核将其转至原来的连接上,即回到Docker 容器内部。
host 模式
Docker 容器中的host 模式与bridge 桥接模式是完全不同的模式。最大的区别是: host模式并没有为容器创建一个隔离的网络环境。
之所以称之为host 模式,是因为该模式下的Docker 容器会和host 宿主机使用同一个网络命名空间,故Docker 容器可以和宿主机一样,
使用宿主机的ethO 和外界进行通信。如此一来, Docker 容器的IP 地址自然也是宿主机ethO的IP地址。
Docker 容器的host 网络模式如图所示
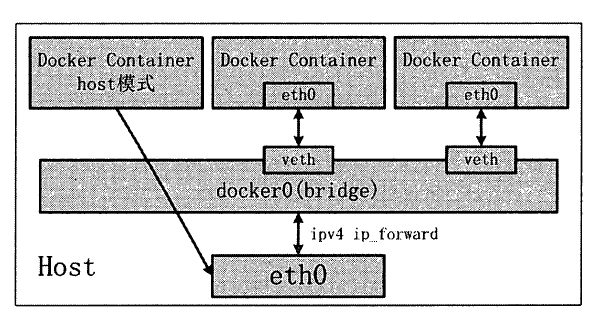
Docker 容器的host 网络模式在实现过程中,由于不需要额外的网桥以及虚拟网卡,故不
会涉及dockerO 以及veth pair。
上文namespace 的介绍中曾经提到:父进程在创建子进程的时候,如果不使用CLONE NEWNET这个参数标志,那么创建出的子进程会与其父进程共享同一个网络命名空间。
Docker 就是采用了这个简单的原理,在创建进程启动容器的过程中,没有传人CLONE NEWNET参数标志,实现Docker 容器与宿主机共享同一个网络环境,网络模式即为host 网络模式。
other container 模式
Docker 容器的other container 网络模式是Docker 中一种较为特别的网络模式。
之所以称为”other container 模式”,是因为这个模式下的Docker 容器,会使用其他容器的网络环境。
之所以称为”特别”,是因为这个模式下容器的网络隔离性会处于bridge 桥接模式与host 模式之间。
Docker 容器共享其他容器的网络环境,则至少这两个容器之间不存在网络隔离,而这两个容器又与宿主机以及除此之外其他的容器存在网络隔离。
在Docker 容器的other container 网络模式实现过程中,不涉及网桥,同样也不需要创建
虚拟网卡veth pair。完成other container 网络的创建只需要两个步骤:
- 查找other container (即需要被共享网络环境的容器)的网络命名空间。
- 新创建的Docker 容器的网络命名空间使用其他容器的网络命名空间。
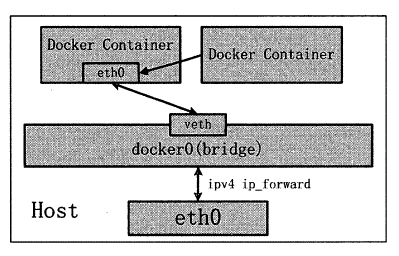
none 模式
Docker 容器的第4 种网络模式是none 模式。顾名思义,网络环境为none ,即不为Docker 容器创建任何的网络环境。一旦Docker 容器采用了none 网络模式,那么容器内部就只能使用loopback 网络接口,不会再有其他的网络资源。
可以说none 模式为Docker 容器做了极少的网络设定,但是俗话说得好”少即是多”,在没有网络配置的情况下,作为Docker 开发者,才能在这种模式下做无限多可能的网络定制开发。这也恰恰体现了Docker 开放的设计理念。
至此Docker 的4 种网络模式的介绍就告一段落,下文带来Docker 网络模式的创建流程分析。
Dockerfile
Dockerfile基本构成
| 四部分 | 指令 |
|---|---|
| 基础镜像信息 | FROM |
| 维护者信息 | MAINTAINER |
| 镜像操作指令 | WORKDIR、RUN、COPY、ADD、EXPOSE等 |
| 容器执行命令 | CMD、ENTRYPOINT |
•ADD
ADD命令有两个参数,源和目标。它的基本作用是从源系统的文件系统上复制文件到目标容器的文件系统。如果源是一个URL,那该URL的内容将被下载并复制到容器中。
•USER
使用哪个用户跑container
•VOLUME
VOLUME [“/data”] 创建一个可以从本地主机或其他容器挂载的挂载点,一般用来存放数据库和需要保持的数据等。
•RUN
安装软件用
•CMD
container启动时执行的命令,但是一个Dockerfile中只能有一条CMD命令,多条则只执行最后一条CMD.
和RUN不同的是,这些命令不是在镜像构建的过程中执行的,而是在用镜像构建容器后被调用。
•ENTRYPOINT
container启动时执行的命令,但是一个Dockerfile中只能有一条ENTRYPOINT命令,如果多条,则只执行最后一条
CMD/ENTRYPOINT两个共同点
1 | 都可以指定shell或exec函数调用的方式执行命令; |
CMD/ENTRYPOINT两个差异点
1 | 差异1:CMD指令指定的容器启动时命令可以被docker run指定的命令覆盖,而ENTRYPOINT指令指定的命令不能被覆盖,而是将docker run指定的参数当做ENTRYPOINT指定命令的参数。 |
Docker镜像基本操作命令
- docker tag
docker tag : 标记本地镜像,将其归入某一仓库。
docker tag ubuntu:15.10 runoob/ubuntu:v3
- docker build
1 | -m :设置内存最大值; |
docker build : 使用Dockerfile创建镜像。
docker build -t runoob/ubuntu:v1 .
- docker commit
1 | -a :提交的镜像作者; |
docker commit :从容器创建一个新的镜像。
docker commit -a “runoob.com” -m “my apache” a404c6c174a2 mymysql:v1
- docker push
docker push yourdomain.com/myproject/myrepo:mytag
- docker login
1 | -u :登陆的用户名 |
docker login yourdomain.com -u 用户名 -p 密码
- docker pull
1 | -a :拉取所有 tagged 镜像 |
docker pull yourdomain.com/myproject/myrepo:mytag
- docker search
docker search -s 10 java
//从Docker Hub查找所有镜像名包含java,并且收藏数大于10的镜像
Docker-Compose
Docker Compose是一个用来定义和运行复杂应用的Docker工具。
一个使用Docker容器的应用,通常由多个容器组成。
使用Docker Compose不再需要使用shell脚本来启动容器。
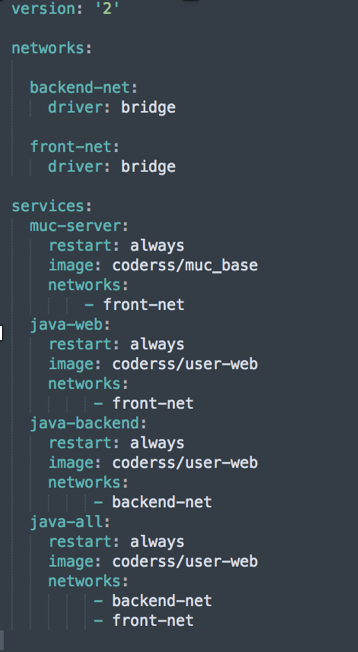
1 | Java-web能够访问同front-net的网络 |
Docker-Compose基本命令
- build
构建项目中的服务容器。
Docker-compose文件有相关build&dockerfile参数指定Dockerfile
并在service中直接用image和tag命名
- down
此命令将会停止 up 命令所启动的容器,并移除网络
- exec
进入指定的容器。
- help
获得一个命令的帮助。
- images
列出 Compose 文件中包含的镜像。
- kill
通过发送 SIGKILL 信号来强制停止服务容器。
支持通过 -s 参数来指定发送的信号,例如通过如下指令发送 SIGINT 信号。
- pause
暂停一个服务容器。
- port
打印某个容器端口所映射的公共端口。
- ps
列出项目中目前的所有容器。
- pull
拉取服务依赖的镜像。
- push
推送服务依赖的镜像到 Docker 镜像仓库。
- start
格式为 docker-compose start [SERVICE…]。
启动已经存在的服务容器。
- stop
停止已经处于运行状态的容器,但不删除它。通过 docker-compose start 可以再次启动这些容器。
- run
在指定服务上执行一个命令。
- restart
重启项目中的服务。rm
删除所有(停止状态的)服务容器。推荐先执行 docker-compose stop 命令来停止容器。
- top
查看各个服务容器内运行的进程。
- unpause
恢复处于暂停状态中的服务。
- up
它将尝试自动完成包括构建镜像,(重新)创建服务,启动服务,并关联服务相关容器的一系列操作。
- scale
设置服务的个数.
Docker容器基本命令
docker ps
1
2
3
4
5
6
7
8
9-a :全部
-l :显示最近创建的容器。
-n :列出最近创建的n个容器。
-a -s :多显示总的文件大小。
-a -q :静默模式,只显示容器编号。
- docker inspect
获取容器/镜像的元数据。
- docker top
docker top :查看容器中运行的进程信息,支持 ps 命令参数。
- docker attach
docker attach :连接到正在运行中的容器。
attach是可以带上–sig-proxy=false来确保CTRL-D或CTRL-C不会关闭容器
- docker exec
•-i: 以交互模式运行容器,通常与 -t 同时使用;
•-t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用;
- docker export
docker export > my_container.tar
docker export : 导出容器export
export命令用于持久化容器(不是镜像)。所以,我们就需要通过以下方法得到容器ID:
sudo docker export > /home/export.tar
Save命令用于持久化镜像(不是容器)。所以,我们就需要通过以下方法得到镜像名称: sudo docker save busybox-1 > /home/save.tar
- docker import
docker import my_ubuntu_v3.tar runoob/ubuntu:v4
docker import : 从归档文件中创建镜像。
- docker run
- docker create
参数同docker run但是与docker run不同的是,docker create创建的容器并未实际启动,还需要执行docker start命令
- docker start
docker start CONTAINER
start 启动一个已经被停止的容器
- docker stop
•-t,–time=10:等待十秒后去停止
- docker kill
•-s :向容器发送一个信号docker kill -s KILL mynginx
- docker rm
删除一个或多少容器
- docker pause/unpause
暂停数据库容器db01提供服务。docker pause db01
恢复数据库容器db01提供服务。docker unpause db01
Kubernetes
基础架构
抽象版
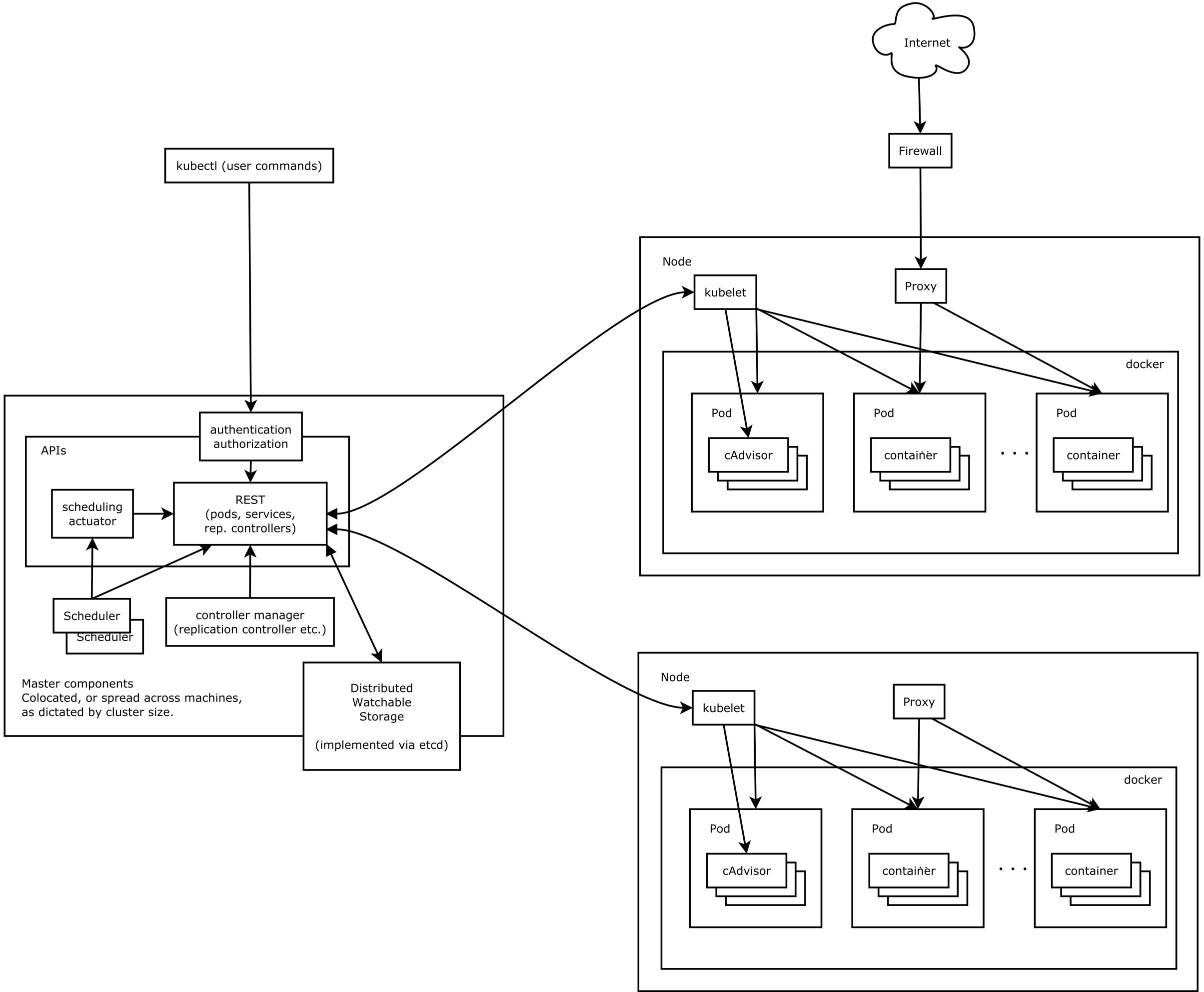
完整版
基本知识
1 | K8s提供了完备的容器集群管理平台 |
基本概念
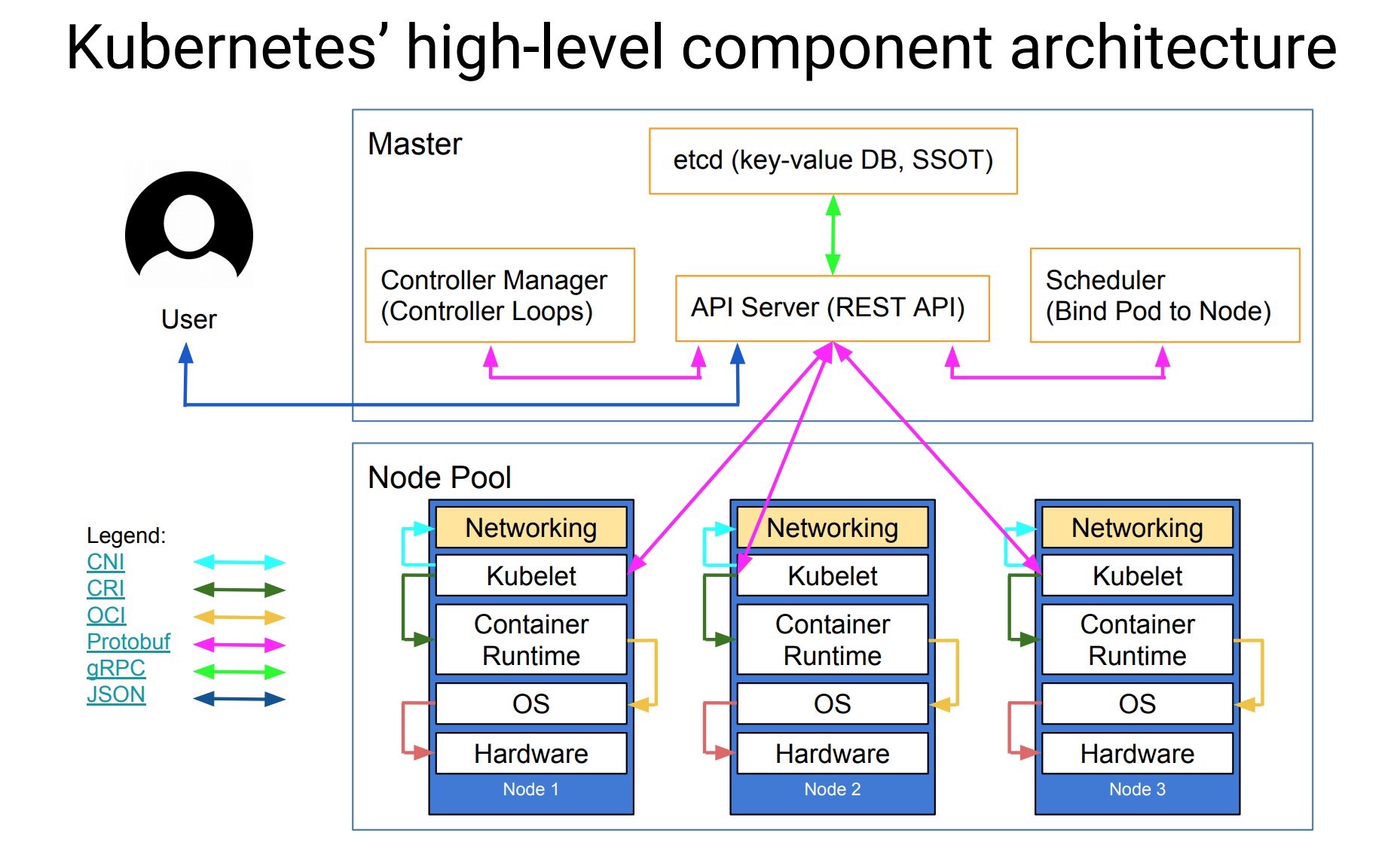
Master节点
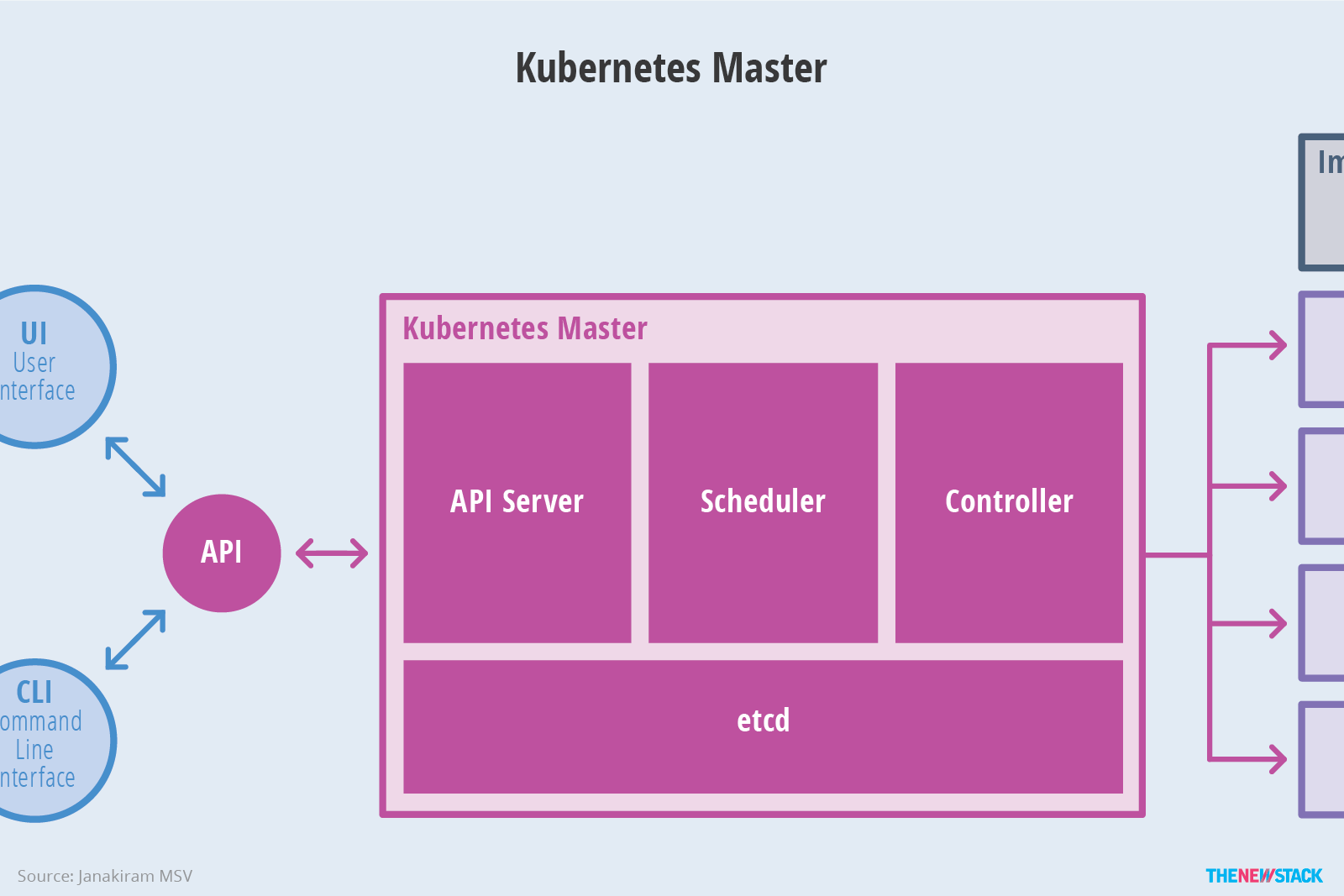
- API服务器
API服务器是一个关键组件 并使用 Kubernetes API 和 JSON over HTTP它提供了Kubernetes的内部和外部接口。API服务器处理和验证 REST请求并更新 API 对象的状态etcd,从而允许客户端在Worker节点之间配置工作负载和容器。
- 调度器
调度程序是可插拔组件,其基于资源可用性来选择未调度的pod(由调度程序管理的基本实体)应该运行哪个节点。调度程序跟踪每个节点上的资源利用率,以确保工作负载不会超过可用资源。为此,调度程序必须知道资源需求,资源可用性以及各种其他用户提供的约束和策略指令,例如服务质量,亲和力,数据位置等。实质上,调度程序的作用是将资源“供应”与工作负载“需求”相匹配。
- 控制器管理
控制器管理器是核心的Kubernetes控制器如DaemonSet控制器和复制控制器的进程。控制器与API服务器通信以创建,更新和删除他们管理的资源(pod,服务端点等)Node节点Node也称为Worker是部署容器(工作负载)的单机器(或虚拟机)集群中的每个节点都必须运行容器runtime(如 Docker)以及下面提到的组件,以便与这些容器的网络配置进行通信。
Node节点
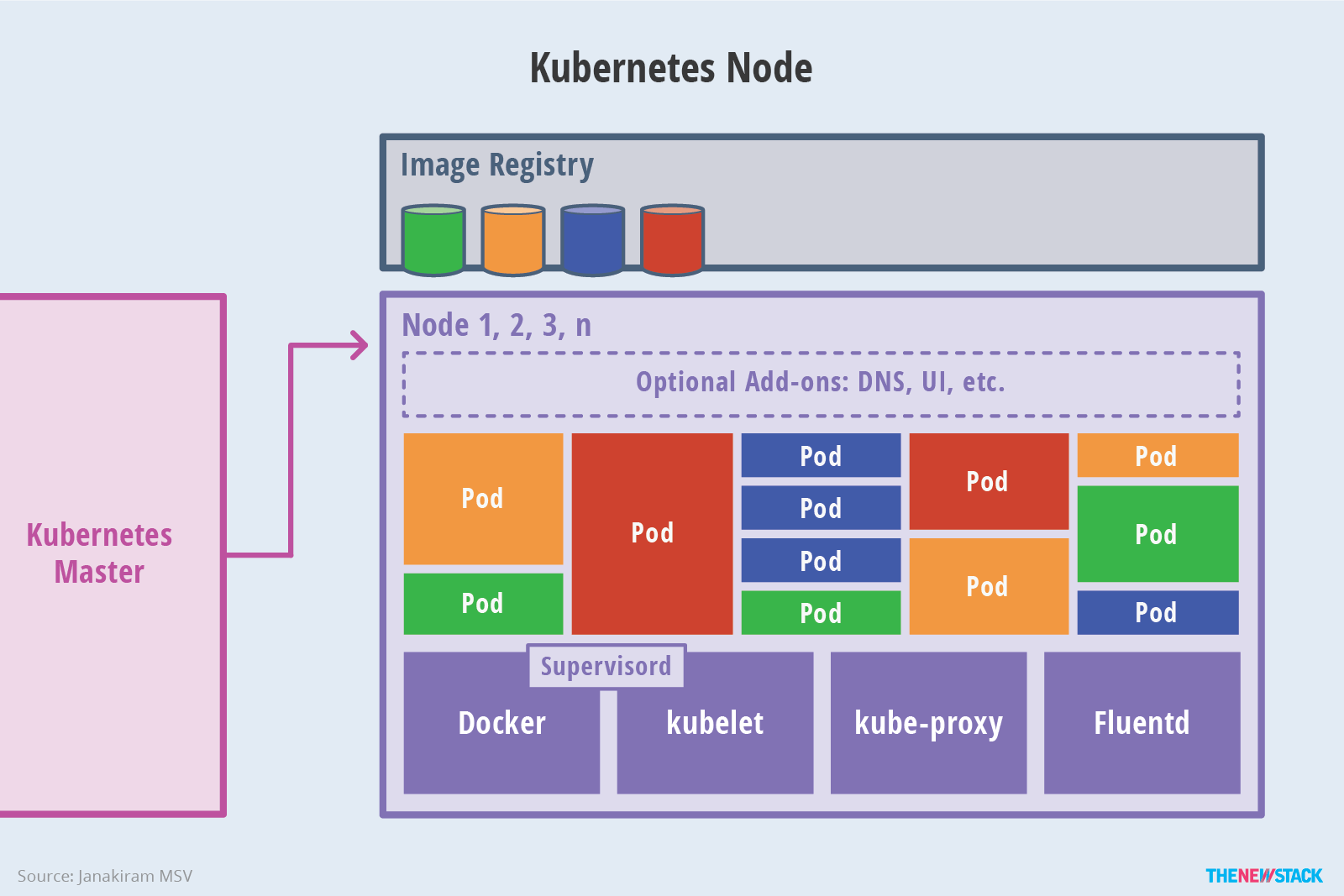
- Kubelet
Kubelet负责每个节点的运行状态(即确保节点上的所有容器都正常运行)。它按照控制面板的指示来处理启动,停止和维护应用程序容器(按组织到pod中)并监视pod的状态如果不处于所需状态则pod将被重新部署到同一个节点。节点状态每隔几秒通过心跳消息中继到主机。主控器检测到节点故障后,复制控制器将观察此状态更改,并在其他健康节点上启动pod。
- Kube代理
kube代理是网络代理和负载平衡器的实现,它支持服务抽象以及其他网络操作。它负责根据传入请求的IP和端口号将流量路由到相应的容器。
Controller-Manager
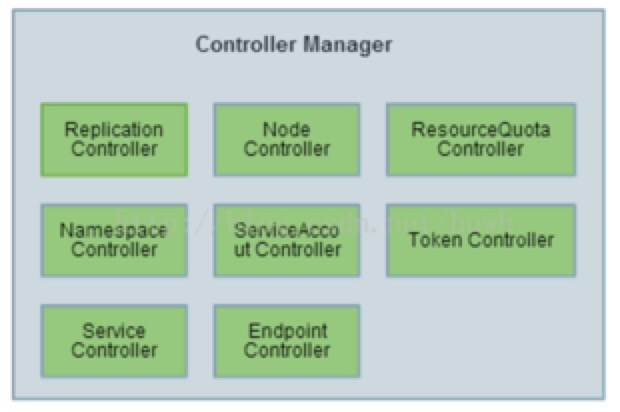
复制(replication)控制器
确保指定pod存在指定数目的实例
端点(endpoint)控制器
负责endpoint对象的创建、更新
节点(node)控制器
负责节点的发现、管理和监控
命名空间(namespaces)控制器
响应对命名空间的操作,并网络隔离
服务(service)控制器
由此控制service,而service是定义一系列Pod以及访问这些Pod的策略的一层抽象。
Service通过Label找到Pod组,在没有selector选择器就会通过对应的endpoint
ApiServer
Kubernetes Pod资源对象创建流程
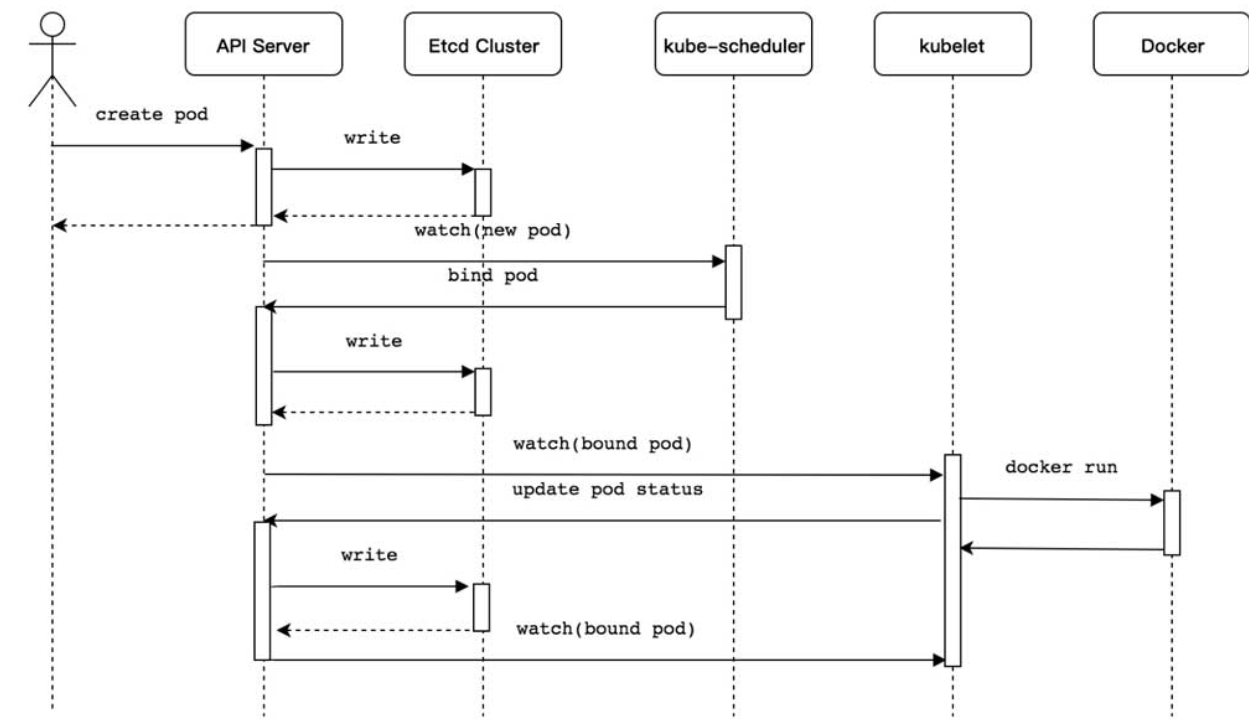
Kubernetes Pod资源对象创建流程介绍如下。
- 使用kubectl工具向Kubernetes API Server发起创建Pod资源对象的请求。
- Kubernetes API Server验证请求并将其持久保存到Etcd集群中。
- Kubernetes API Server基于Watch机制通知kube-scheduler调度器。
- kube-scheduler调度器根据预选和优选调度算法为Pod资源对象选择最优的节点并通知Kubernetes API Server。
- Kubernetes API Server将最优节点持久保存到Etcd集群中。
- Kubernetes API Server通知最优节点上的kubelet组件。
- kubelet组件在所在的节点上通过与容器进程交互创建容器。
- kubelet组件将容器状态上报至Kubernetes API Server。
- Kubernetes API Server将容器状态持久保存到Etcd集群中。
kube-apiserver架构设计详解
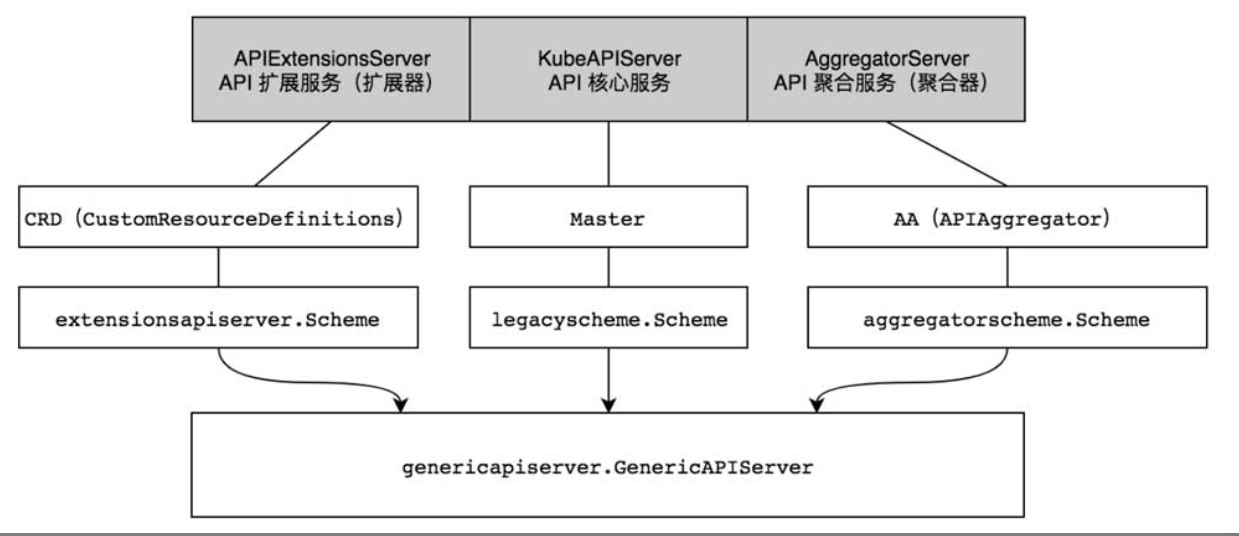
- APIExtensionsServer:API扩展服务(扩展器)。该服务提供了CRD(CustomResourceDefinitions)自定义资源服务,开发者可通过CRD对Kubernetes资源进行扩展,。该服务通过CustomResourceDefinitions对象进行管理,并通过extensionsapiserver.Scheme资源注册表管理CRD相关资源。
AggregatorServer:API聚合服务(聚合器)。该服务提供了AA (APIAggregator)聚合服务,开发者可通过AA对Kubernetes聚合服务进行扩展,例如,metrics-server是Kubernetes系统集群的核心监控数据的聚合器,它是AggregatorServer服务的扩展实现。API聚合服务通过APIAggregator对象进行管理,并通过aggregatorscheme.Scheme资源注册表管理AA相关资源。
KubeAPIServer:API核心服务。该服务提供了Kubernetes内置核心资源服务,不允许开发者随意更改相关资源,例如,Pod、Service等内置核心资源会由Kubernetes官方维护。API核心服务通过Master对象进行管理,并通过legacyscheme.Scheme资源注册表管理Master相关资源。
提示:无论是APIExtensionsServer、KubeAPIServer还是AggregatorServer,它们都在底层依赖于GenericAPIServer。
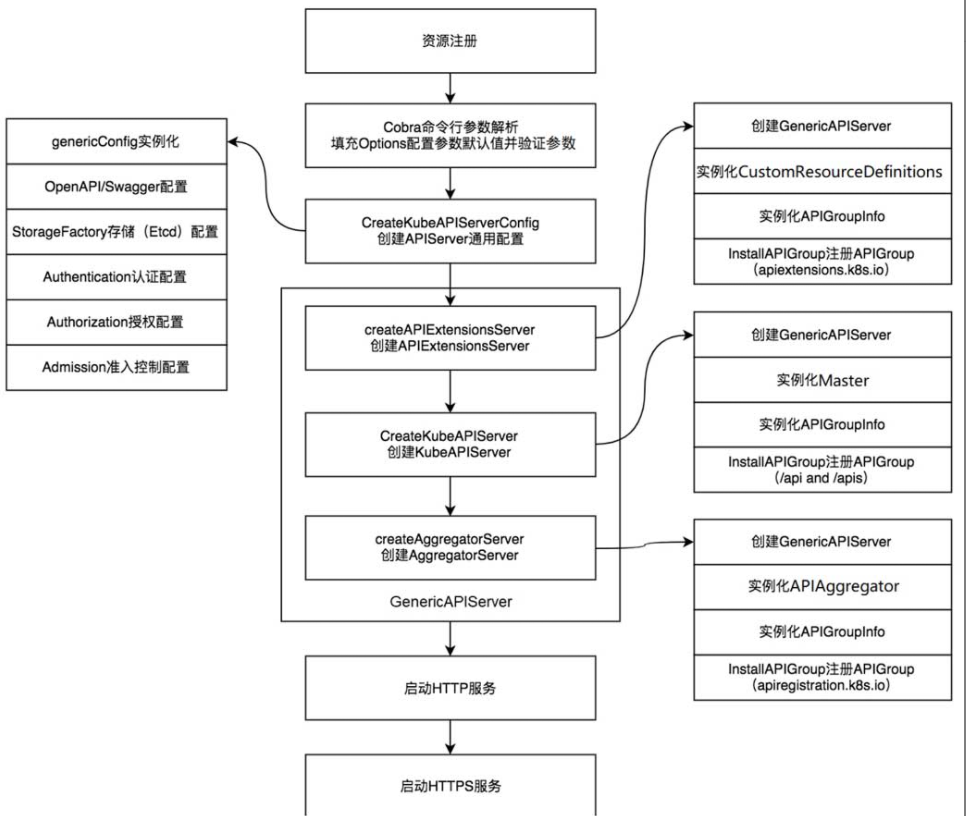
kube-apiserver启动流程
-(1)资源注册。
-(2)Cobra命令行参数解析。
-(3)创建APIServer通用配置。
-(4)创建APIExtensionsServer。
-(5)创建KubeAPIServer。
-(6)创建AggregatorServer。
-(7)创建GenericAPIServer。
-(8)启动HTTP服务。
-(9)启动HTTPS服务。
权限控制
kube-apiserver(Kubernetes API Server)作为Kubernetes集群的请求入口,接收集群中组件与客户端的访问请求
kube-apiserver对接口请求访问,提供了3种安全权限控制,每个请求都需要经过认证、授权及准入控制器才有权限操作资源对象。
- 认证:针对请求的认证,确认是否具有访问Kubernetes集群的权限。
- 授权:针对资源的授权,确认是否对资源具有相关权限。
- 准入控制器:在认证和授权之后,对象被持久化之前,拦截kube-apiserver的请求,拦截后的请求进入准入控制器中处理,对请求的资源对象进行自定义(校验、修改或拒绝)等操作。
认证
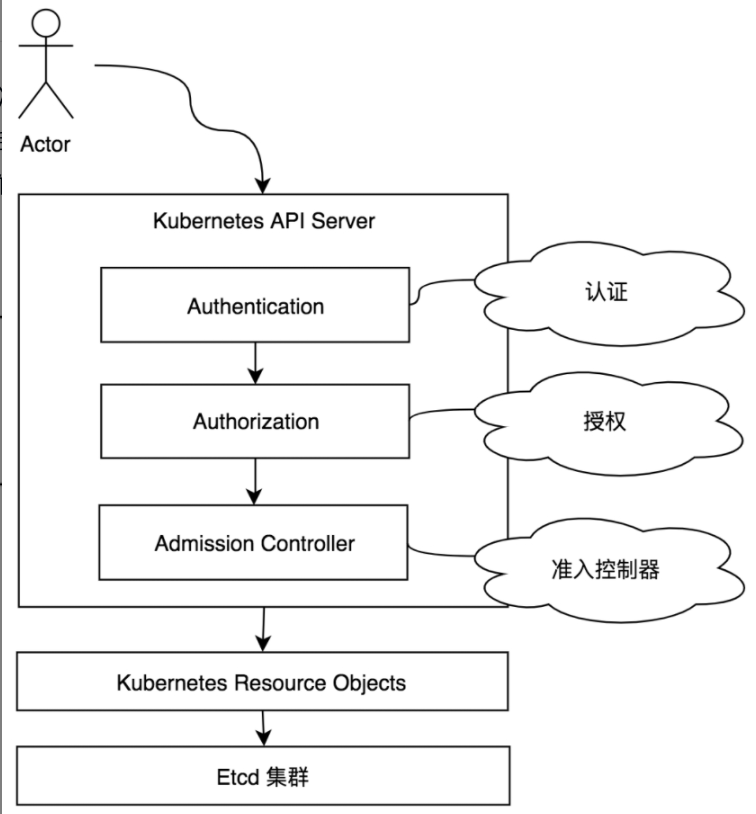
kube-apiserver目前提供了9种认证机制,分别是BasicAuth、ClientCA、TokenAuth、BootstrapToken、RequestHeader、WebhookTokenAuth、Anonymous、OIDC、ServiceAccountAuth。
每一种认证机制被实例化后会成为认证器(Authenticator),每一个认证器都被封装在http.Handler请求处理函数中,它们接收组件或客户端的请求并认证请求。
当客户端请求通过认证器并返回true时,则表示认证通过。
BasicAuth认证
BasicAuth是一种简单的HTTP协议上的认证机制,客户端将用户、密码写入请求头中,HTTP服务端尝试从请求头中验证用户、密码信息,从而实现身份验证。
- 1.启用BasicAuth认证
apiserver通过指定–basic-auth-file,auth_file是一个csv文件 - 2.BasicAuth认证接口定义
代码路径:vendor/k8s.io/apiserver/pkg/authentication/authenticator/interfaces.go - 3.BasicAuth认证实现
代码路径:vendor/k8s.io/apiserver/plugin/pkg/authenticator/request/basicauth/basicauth.go
通过req.BasicAuth函数尝试从请求头中读取Authorization字段,通过Base64解码出用户、密码信息
并通过a.auth.AuthenticatePassword函数进行认证,认证失败会返回false,而认证成功会返回true。
ClientCA认证
ClientCA认证,也被称为TLS双向认证,即服务端与客户端互相验证证书的正确性。
使用ClientCA认证的时候,只要是CA签名过的证书都可以通过验证。
- 1.启用ClientCA认证
apiserver通过指定–client-ca-file参数指定ClientCA认证 - 2.ClientCA认证接口定义
代码路径:vendor/k8s.io/apiserver/pkg/authentication/authenticator/interfaces.go - 3.ClientCA认证实现
代码路径:vendor/k8s.io/apiserver/pkg/authentication/request/x509/x509.go
TokenAuth认证
Token也被称为令牌,服务端为了验证客户端的身份,需要客户端向服务端提供一个可靠的验证信息,这个验证信息就是Token。
- 1.apiserver通过指定–token-auth-file参数启用TokenAuth认证。
TOKEN_FILE是一个CSV文件,每个用户在CSV中的表现形式为token、user、userid、group, - 2.Token认证接口定义
代码路径:vendor/k8s.io/apiserver/pkg/authentication/authenticator/interfaces.go - 3.Token认证实现
代码路径:vendor/k8s.io/apiserver/pkg/authentication/token/tokenfile/tokenfile.go
a.tokens中存储了服务端的Token列表,通过a.tokens查询客户端提供的Token,如果查询不到,则认证失败返回false,反之则认证成功返回true。
BootstrapToken认证
当Kubernetes集群中有非常多的节点时,手动为每个节点配置TLS认证比较烦琐,为此Kubernetes提供了BootstrapToken认证,其也被称为引导Token。
客户端的Token信息与服务端的Token相匹配,则认证通过,自动为节点颁发证书,这是一种引导Token的机制。
- 1.启用BootstrapToken认证
apiserver通过指定–enable-bootstrap-token-auth参数启用BootstrapToken认证。 - 2.BootstrapToken认证接口定义
代码路径:vendor/k8s.io/apiserver/pkg/authentication/authenticator/interfaces.go - 3.BootstrapToken认证实现
代码路径:plugin/pkg/auth/authenticator/token/bootstrap/bootstrap.go
RequestHeader认证
Kubernetes可以设置一个认证代理,客户端发送的认证请求可以通过认证代理将验证信息发送给kube-apiserver组件。
RequestHeader认证使用的就是这种代理方式,它使用请求头将用户名和组信息发送给kube-apiserver。
WebhookTokenAuth认证
Webhook也被称为钩子,是一种基于HTTP协议的回调机制
当客户端发送的认证请求到达kube-apiserver时,kube-apiserver回调钩子方法,将验证信息发送给远程的Webhook服务器进行认证,然后根据Webhook服务器返回的状态码来判断是否认证成功。
Anonymous认证
Anonymous认证就是匿名认证,未被其他认证器拒绝的请求都可视为匿名请求。kube-apiserver默认开启Anonymous(匿名)认证。
OIDC认证
OIDC(OpenID Connect)是一套基于OAuth 2.0协议的轻量级认证规范,其提供了通过API进行身份交互的框架。
OIDC认证除了认证请求外,还会标明请求的用户身份(ID Token)。
其中Toekn被称为ID Token,此ID Token是JSON Web Token (JWT),具有由服务器签名的相关字段。
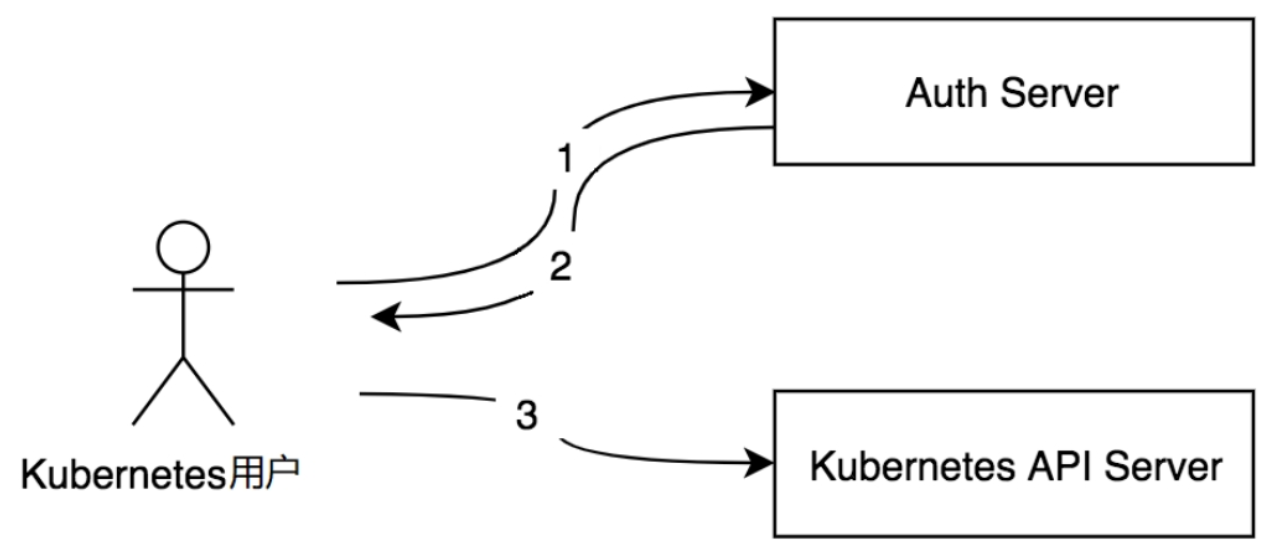
OIDC认证流程介绍如下。
- (1)Kubernetes用户想访问Kubernetes API Server,先通过认证服务(Auth Server,例如GoogleAccounts服务)认证自己,得到access_token、id_token和refresh_token。
- (2)Kubernetes用户把access_token、id_token和refresh_token配置到客户端应用程序(如kubectl或dashboard工具等)中。
- (3)Kubernetes客户端使用Token以用户的身份访问Kubernetes API Server。
下面详细描述Kubernetes Authentication OIDC Token的完整过程
-(1)用户登录到身份提供商(即Auth Server,例如Google Accounts服务)。
-(2)用户的身份提供商将提供access_token、id_token和refresh_token。
-(3)用户使用kubectl工具,通过–token参数指定id_token,或者将id_token写入kubeconfig文件中。
-(4)kubectl工具将id_token设置为Authorization的请求头并发送给Kubernetes API Server。
-(5)Kubernetes API Server将通过检查配置文件中指定的证书来确保JWT签名有效。
-(6)检查并确保id_token未过期。
-(7)检查并确保用户已获得授权。
-(8)获得授权后,Kubernetes API Server会响应kubectl工具。
-(9)kubectl工具向用户提供反馈。
ServiceAccountAuth认证
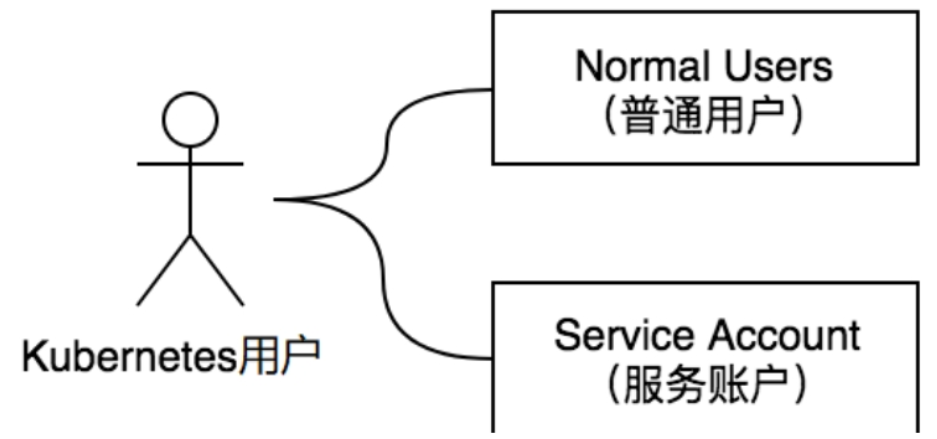
- Normal Users:普通用户,一般由外部独立服务管理,前面介绍的认证机制(如BasicAuth、OIDC认证等)都属于普通用户,Kubernetes没有为这类用户设置用户对象。
- Service Account:服务账户,是由Kubernetes API Server管理的用户,它们被绑定到指定的命名空间,由Kubernetes API Server自动或手动创建。Service Account是为了Pod资源中的进程方便与Kubernetes API Server进行通信而设置的。
授权
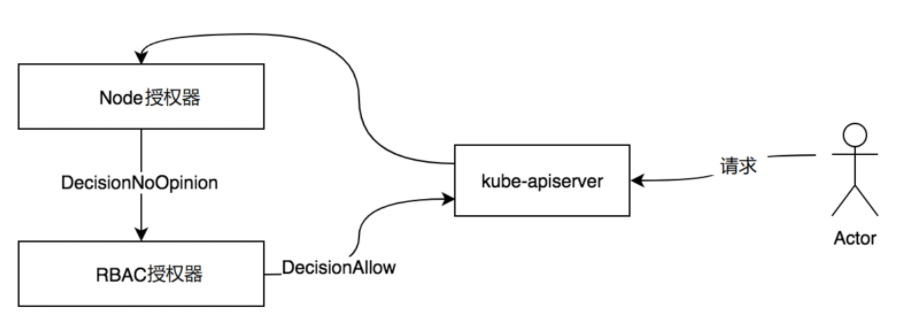
kube-apiserver目前提供了6种授权机制,分别是AlwaysAllow、AlwaysDeny、ABAC、Webhook、RBAC、Node
可通过指定–authorization-mode参数设置授权机制。
- AlwaysAllow:允许所有请求。
- AlwaysDeny:阻止所有请求。
- ABAC:即Attribute-Based Access Control,基于属性的访问控制。
- Webhook:基于Webhook的一种HTTP协议回调,可进行远程授权管理。
- RBAC:即Role-Based Access Control,基于角色的访问控制。
- Node:节点授权,专门授权给kubelet发出的API请求。
在kube-apiserver中,授权有3个概念,分别是Decision决策状态、授权器接口、RuleResolver规则解析器。
Decision决策状态
Decision决策状态类似于认证中的true和false,用于决定是否授权成功。
授权支持3种Decision决策状态,例如授权成功,则返回DecisionAllow决策状态
- DecisionDeny:表示授权器拒绝该操作。
- DecisionAllow:表示授权器允许该操作。
- DecisionNoOpionion:表示授权器对是否允许或拒绝某个操作没有意见,会继续执行下一个授权器。
授权器接口
每一种授权机制都需要实现authorizer.Authorizer授权器接口方法、接口定义
Attributes是决定授权器从HTTP请求中获取授权信息方法的参数,例如GetUser、GetVerb、GetNamespace、GetResource等获取授权信息方法。
- 如果授权成功,Decision决策状态变为DecisionAllow
- 如果授权失败,Decision决策状态变为DecisionDeny
RuleResolver规则解析器
授权器通过RuleResolver规则解析器去解析规则
RuleResolver接口定义了RulesFor方法,每个授权器都需要实现该方法,RulesFor方法通过接收的user用户信息及namespace命名空间参数,解析出规则列表并返回。
规则列表分为如下两种。
- ResourceRuleInfo:资源类型的规则列表,例如/api/v1/pods的资源接口。
- NonResourceRuleInfo:非资源类型的规则列表,例如/api或/health的资源接口。
以ResourceRuleInfo资源类型为例,其中通配符(*)表示匹配所有
Pod资源规则列表表示:该用户对所有资源版本的Pod资源拥有所有操作(即get、list、watch、create、update、patch、delete、deletecollection)权限。
RBAC授权
RBAC授权器现实了基于角色的权限访问控制(Role-Based Access Control),其也是目前使用最为广泛的授权模型。
在RBAC授权器中,权限与角色相关联,形成了用户—角色—权限的授权模型。
用户通过加入某些角色从而得到这些角色的操作权限,这极大地简化了权限管理。

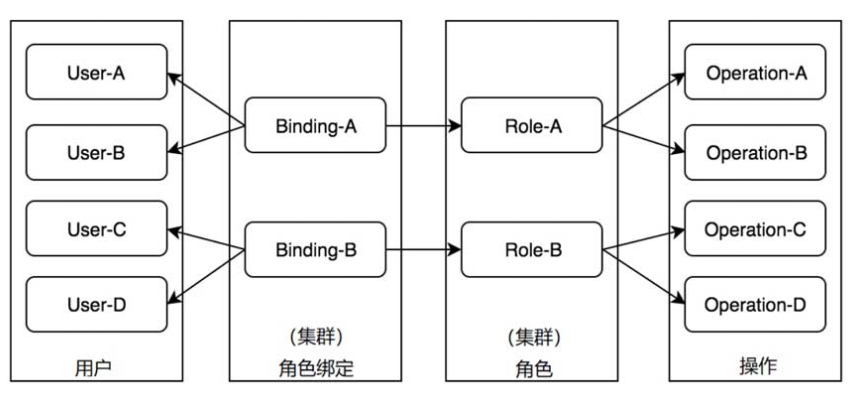
Role-A角色拥有访问/操作Operation-A和Operation-B的权限
将User-A用户与Role-A角色进行绑定,User-A用户就有了访问/操作Operation-A和Operation-B的权限
但User-A用户没有访问/操作Operation-C和Operation-D的权限。
准入控制
准入控制器会在验证和授权请求之后,对象被持久化之前,拦截kube-apiserver的请求
拦截后的请求进入准入控制器中处理,对请求的资源对象执行自定义(校验、修改或拒绝等)操作。
准入控制器以插件的形式运行在kube-apiserver进程中,插件化的好处在于可扩展插件并单独启用/禁用指定插件,也可以将每个准入控制器称为准入控制器插件。
如果开启了多个准入控制器,则按照顺序执行准入控制器。
kube-apiserver目前提供了31种准入控制器
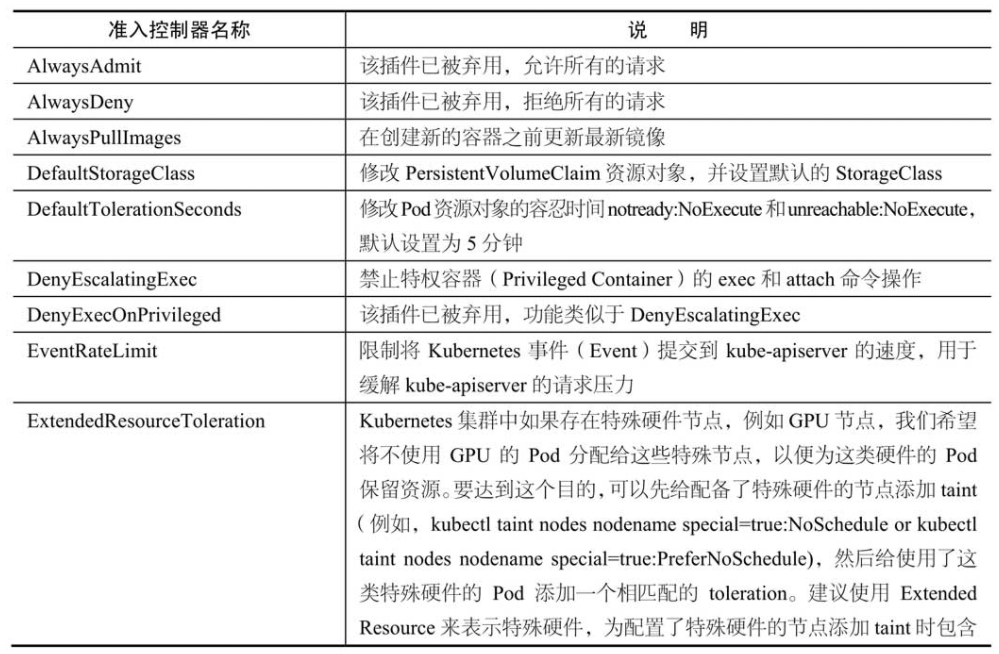
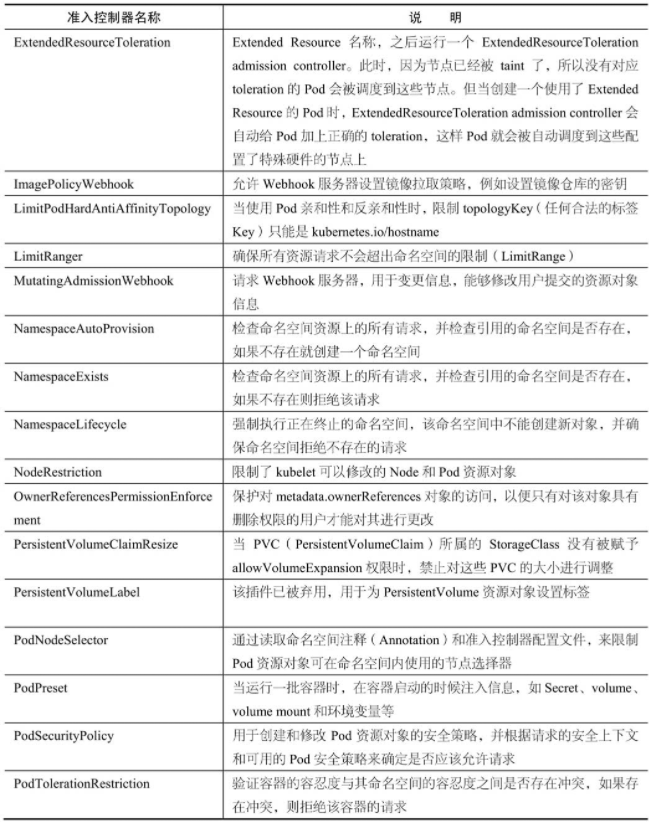
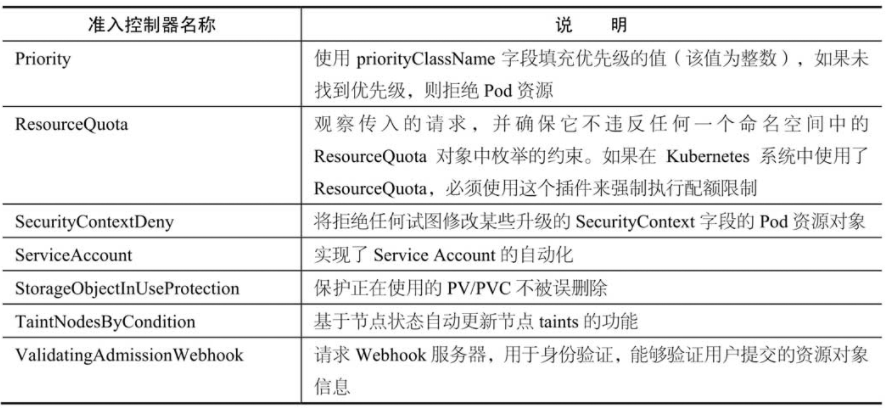
可通过–enable-admission-plugins参数指定启用的准入控制器列表
可通过–disable-admission-plugins参数指定禁用的准入控制器列表。
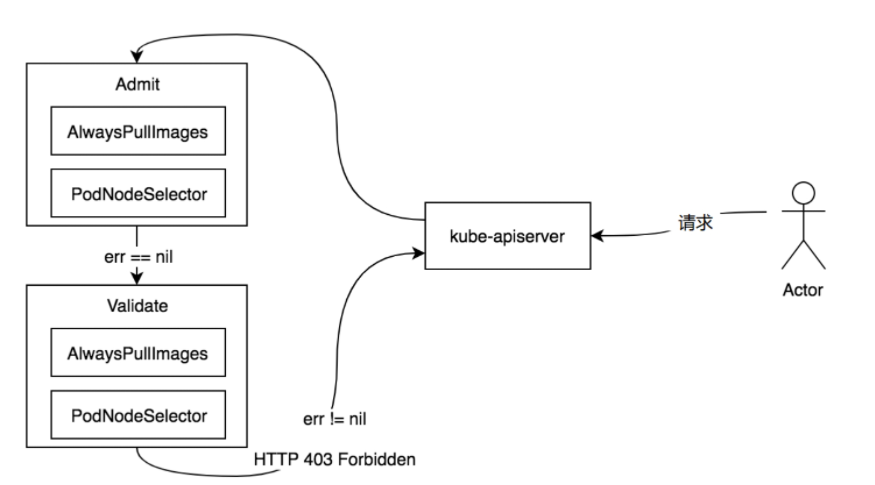
在请求经过准入控制器列表时,只要有一个准入控制器拒绝了该请求,则整个请求被拒绝(HTTP 403 Forbidden)
kube-apiserver目前支持如下两种准入控制器。
- 变更准入控制器(Mutating Admission Controller):用于变更信息,能够修改用户提交的资源对象信息。
- 验证准入控制器(Validating Admission Controller):用于身份验证,能够验证用户提交的资源对象信息。
提示:变更准入控制器运行在验证准入控制器之前。
变更准入控制器和验证准入控制器接口定义分别是MutationInterface和ValidationInterface
1 | 变更准入控制器接口拥有Admit方法,验证准入控制器接口拥有Validate方法。 |
AlwaysPullImages准入控制器
AlwaysPullImages准入控制器在创建新的容器之前更新最新镜像。
对拦截的kube-apiserver请求中的Pod资源对象进行修改,将Pod资源对象的镜像拉取策略改为Always。
PodNodeSelector准入控制器
PodNodeSelector准入控制器通过读取命名空间注释和准入控制器配置文件来限制Pod资源对象可在命名空间内使用的节点选择器。
PodNodeSelector准入控制器会对拦截的kube-apiserver请求中的Pod资源对象进行修改
将节点选择器与Pod资源对象的节点选择器进行合并并赋值给Pod资源对象的节点选择器(即pod.Spec.NodeSelectore)。
- 如果命名空间中具有带键的注释(即scheduler.alpha.kubernetes.io/node-selector),则将其值用作节点选择器。
- 如果命名空间中没有这样的注释(即scheduler.alpha.kubernetes.io/node-selector),则使用准入控制器配置文件中定义的clusterDefaultNodeSelector作为节点选择器。
验证pod.Spec.NodeSelector资源对象的节点选择器是否与准入控制器配置文件中定义的节点选择器存在冲突
则通过errors.NewForbidden函数返回HTTP 403 Forbidden。
Kubelet
在Kubernetes集群中,在每个Node(又称Minion)上都会启动一个kubelet服务进程。该进程用于处理Master下发到本节点的任务,管理Pod及Pod中的容器。
每个kubelet进程都会在API Server上注册节点自身的信息,定期向Master汇报节点资源的使用情况,并通过cAdvisor监控容器和节点资源。
节点管理
当前每个kubelet都被授予创建和修改任何节点的权限。
但是在实践中它仅仅创建和修改自己。
将来计划限制kubelet的权限,仅允许它修改和创建所在节点的权限。
kubelet在启动时通过API Server注册节点信息,并定时向API Server发送节点的新消息,API Server在接收到这些信息后,将这些信息写入etcd。
通过kubelet的启动参数--node-status- update-frequency设置kubelet每隔多长时间向API Server报告节点状态,默认为10s。
Pod管理
kubelet通过以下几种方式获取自身Node上要运行的Pod清单。
- (1)文件:kubelet启动参数
--config指定的配置文件目录下的文件(默认目录为/etc/kubernetes/manifests/)。通过--file-check-frequency设置检查该文件目录的时间间隔,默认为20s。 - (2)HTTP端点(URL):通过
--manifest-url参数设置。通过--http-check-frequency设置检查该HTTP端点数据的时间间隔,默认为20s。 - (3)API Server:kubelet通过API Server监听etcd目录,同步Pod列表。
所有以非API Server方式创建的Pod都叫作Static Pod。
kubelet通过API Server Client使用Watch加List的方式监听/registry/nodes/$当前节点的名称和/registry/pods目录,将获取的信息同步到本地缓存中。
kubelet读取监听到的信息,如果是创建和修改Pod任务,则做如下处理。
- 为该Pod创建一个数据目录。
- 从API Server读取该Pod清单。
- 为该Pod挂载外部卷(External Volume)。
- 下载Pod用到的Secret。
- 检查已经运行在节点上的Pod,如果该Pod没有容器或Pause容器(“kubernetes/pause”镜像创建的容器)没有启动,则先停止Pod里所有容器的进程。如果在Pod中有需要删除的容器,则删除这些容器。
- 用“kubernetes/pause”镜像为每个Pod都创建一个容器。该Pause容器用于接管Pod中所有其他容器的网络。每创建一个新的Pod,kubelet都会先创建一个Pause容器,然后创建其他容器。“kubernetes/pause”镜像大概有200KB,是个非常小的容器镜像。
- 为Pod中的每个容器做如下处理。
- 为容器计算一个Hash值,然后用容器的名称去查询对应Docker容器的Hash值。若查找到容器,且二者的Hash值不同,则停止Docker中容器的进程,并停止与之关联的Pause容器的进程;若二者相同,则不做任何处理。
- 如果容器被终止了,且容器没有指定的restartPolicy(重启策略),则不做任何处理。
- 调用Docker Client下载容器镜像,调用Docker Client运行容器。
容器健康检查
一类是LivenessProbe探针
用于判断容器是否健康并反馈给kubelet。
如果LivenessProbe探针探测到容器不健康,则kubelet将删除该容器,并根据容器的重启策略做相应的处理。
如果一个容器不包含LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success;
另一类是ReadinessProbe探针
用于判断容器是否启动完成,且准备接收请求。
如果ReadinessProbe探针检测到容器启动失败,则Pod的状态将被修改,Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的IP地址的Endpoint条目。
kubelet定期调用容器中的LivenessProbe探针来诊断容器的健康状况。LivenessProbe包含以下3种实现方式。
- ExecAction:在容器内部执行一个命令,如果该命令的退出状态码为0,则表明容器健康。
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果端口能被访问,则表明容器健康。
- HTTPGetAction:通过容器的IP地址和端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于等于400,则认为容器状态健康。
cAdvisor资源监控
cAdvisor是一个开源的分析容器资源使用率和性能特性的代理工具,它是因为容器而产生的,因此自然支持Docker容器
在Kubernetes项目中,cAdvisor被集成到Kubernetes代码中,kubelet则通过cAdvisor获取其所在节点及容器的数据。
cAdvisor自动查找所有在其所在Node上的容器,自动采集CPU、内存、文件系统和网络使用的统计信息。
在大部分Kubernetes集群中,cAdvisor通过它所在Node的4194端口暴露一个简单的UI。
1 | cAdvisor在4194端口提供的UI和API服务从Kubernetes 1.10版本开始进入弃用流程,并于1.12版本完全关闭。 |
Kube-proxy运行机制解析
为了支持集群的水平扩展、高可用性,Kubernetes抽象出了Service的概念。
Service是对一组Pod的抽象,它会根据访问策略(如负载均衡策略)来访问这组Pod。
Service只是一个概念,而真正将Service的作用落实的是它背后的kube-proxy服务进程。
只有理解了kube-proxy的原理和机制,我们才能真正理解Service背后的实现逻辑。
在Kubernetes集群的每个Node上都会运行一个kube-proxy服务进程,我们可以把这个进程看作Service的透明代理兼负载均衡器,其核心功能是将到某个Service的访问请求转发到后端的多个Pod实例上。
Service的Cluster IP与NodePort等概念是kube-proxy服务通过iptables的NAT转换实现的,kube-proxy在运行过程中动态创建与Service相关的iptables规则,这些规则实现了将访问服务(Cluster IP或NodePort)的请求负载分发到后端Pod的功能。
由于iptables机制针对的是本地的kube-proxy端口,所以在每个Node上都要运行kube-proxy组件,这样一来,在Kubernetes集群内部,我们可以在任意Node上发起对Service的访问请求。
综上所述由于kube-proxy的作用,在Service的调用过程中客户端无须关心后端有几个Pod,中间过程的通信、负载均衡及故障恢复都是透明的。
1 | Kubernetes从1.2版本开始,将iptables作为kube-proxy的默认模式。 |
ipvs
iptables与IPVS虽然都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别
iptables是为防火墙而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张,因此被kube-proxy采纳为第三代模式。
与iptables相比,IPVS拥有以下明显优势:
- 为大型集群提供了更好的可扩展性和性能;
- 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等);
- 支持服务器健康检查和连接重试等功能;
- 可以动态修改ipset的集合,即使iptables的规则正在使用这个集合。
由于IPVS无法提供包过滤、airpin-masquerade tricks(地址伪装)、SNAT等功能,因此在某些场景(如NodePort的实现)下还要与iptables搭配使用。
在IPVS模式下,kube-proxy又做了重要的升级,即使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。
1 | iptables规则链是一个线性的数据结构,ipset则引入了带索引的数据结构,因此当规则很多时,也可以很高效地查找和匹配。 |
Schedule
架构设计
kube-scheduler是Kubernetes的默认调度器,其架构设计本身并不复杂,但Kubernetes系统在后期引入了优先级和抢占机制及亲和性调度等功能,kube-scheduler调度器的整体设计略微复杂。
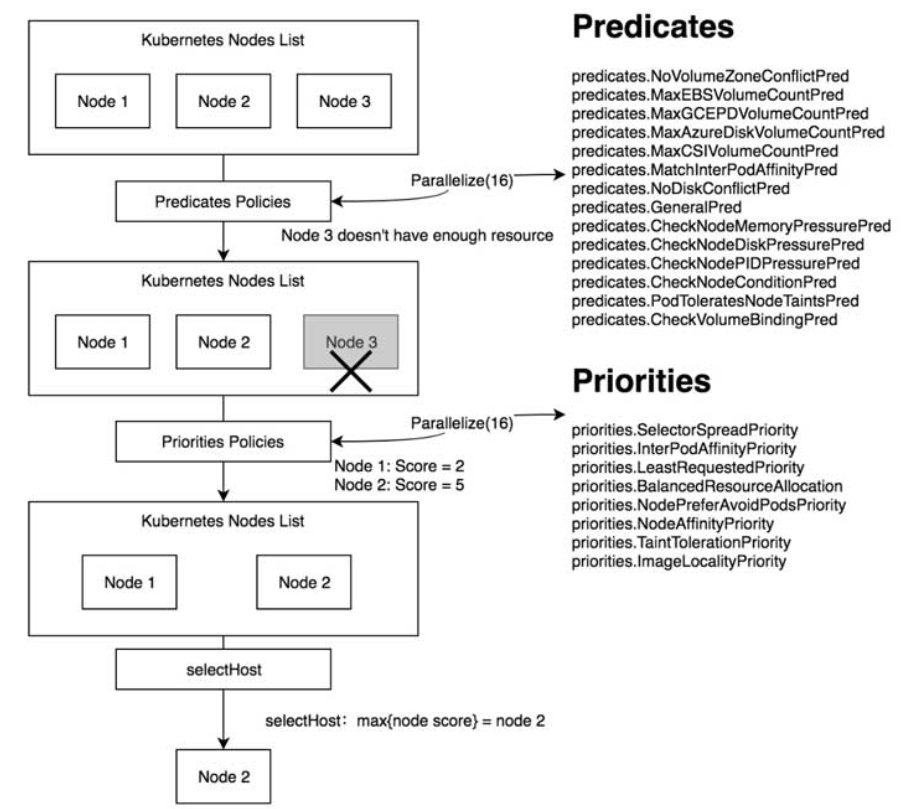
kube-scheduler调度器在为Pod资源对象选择合适节点时,有如下两种最优解。
● 全局最优解:是指每个调度周期都会遍历Kubernetes集群中的所有节点,以便找出全局最优的节点。
● 局部最优解:是指每个调度周期只会遍历部分Kubernetes集群中的节点,找出局部最优的节点。
内置调度算法
● fitPredicateMap:存储所有的预选调度算法。
● priorityFunctionMap:存储所有的优选调度算法。
● algorithmProviderMap:存储所有类型的调度算法。
Predicates预选算法
predicates 算法主要是对集群中的 node 进行过滤,选出符合当前 pod 运行的一组 nodes。
过滤 node 的预选算法有很多,比如:CheckNodeConditionPredicate(检查节点是否可被调度),PodFitsHost(检查pod.spec.nodeName字段是否已经指定),PodFitsHostPorts(检查pod需要的端口node能否提供)等
1 | var ( |
Priorities优先调度算法
LeastRequestedPriority:如果新的pod要分配给一个节点,这个节点的优先级就由节点空闲的那部分与总容量的比值(即(总容量-节点上pod的容量总和-新pod的容量)/总容量)来决定。CPU和memory权重相当,比值最大的节点的得分最高。需要注意的是,这个优先级函数起到了按照资源消耗来跨节点分配pods的作用。
计算公式如下:cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2BalancedResourceAllocation:尽量选择在部署Pod后各项资源更均衡的机器。BalancedResourceAllocation不能单独使用,而且必须和LeastRequestedPriority同时使用,它分别计算主机上的cpu和memory的比重,主机的分值由cpu比重和memory比重的“距离”决定。
计算公式如下:score = 10 – abs(cpuFraction-memoryFraction)*10SelectorSpreadPriority:对于属于同一个service、replication controller的Pod,尽量分散在不同的主机上。如果指定了区域,则会尽量把Pod分散在不同区域的不同主机上。调度一个Pod的时候,先查找Pod对于的service或者replication controller,然后查找service或replication controller中已存在的Pod,主机上运行的已存在的Pod越少,主机的打分越高。
CalculateAntiAffinityPriority:对于属于同一个service的Pod,尽量分散在不同的具有指定标签的主机上。
ImageLocalityPriority:根据主机上是否已具备Pod运行的环境来打分。ImageLocalityPriority会判断主机上是否已存在Pod运行所需的镜像,根据已有镜像的大小返回一个0-10的打分。如果主机上不存在Pod所需的镜像,返回0;如果主机上存在部分所需镜像,则根据这些镜像的大小来决定分值,镜像越大,打分就越高。
NodeAffinityPriority(Kubernetes1.2实验中的新特性):Kubernetes调度中的亲和性机制。Node Selectors(调度时将pod限定在指定节点上),支持多种操作符(In, NotIn, Exists, DoesNotExist, Gt, Lt),而不限于对节点labels的精确匹配。另外,Kubernetes支持两种类型的选择器,一种是“hard(requiredDuringSchedulingIgnoredDuringExecution)”选择器,它保证所选的主机必须满足所有Pod对主机的规则要求。这种选择器更像是之前的nodeselector,在nodeselector的基础上增加了更合适的表现语法。另一种是“soft(preferresDuringSchedulingIgnoredDuringExecution)”选择器,它作为对调度器的提示,调度器会尽量但不保证满足NodeSelector的所有要求。
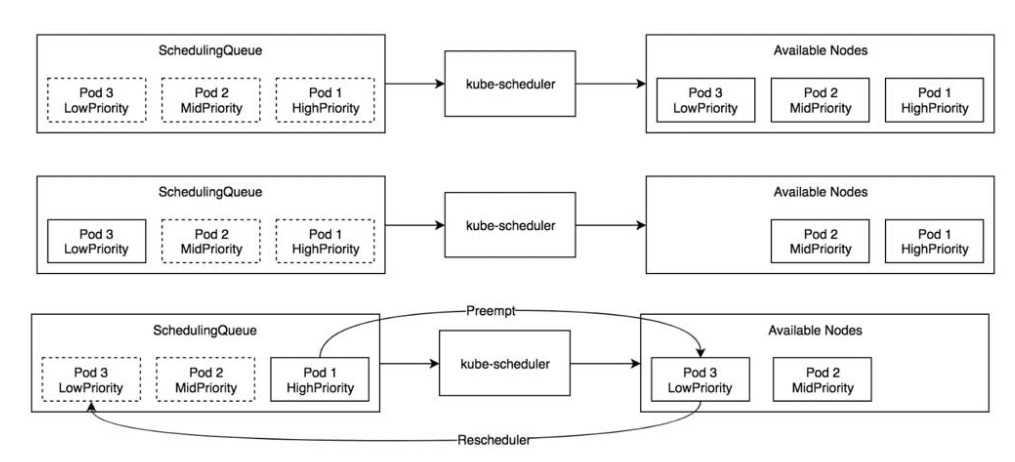
优先级与抢占机制
Pod资源对象支持优先级(Priority)与抢占(Preempt)机制。
优先级
当kube-scheduler调度器运行时,根据Pod资源对象的优先级进行调度,高优先级的Pod资源对象排在调度队列(SchedulingQueue)的前面,优先获得合适的节点(Node),然后为低优先级的Pod资源对象选择合适的节点。
抢占
当高优先级的Pod资源对象没有找到合适的节点时,调度器会尝试抢占低优先级的Pod资源对象的节点,抢占过程是将低优先级的Pod资源对象从所在的节点上驱逐走,使高优先级的Pod资源对象运行在该节点上,被驱逐走的低优先级的Pod资源对象会重新进入调度队列并等待再次选择合适的节点。
SchedulingQueue调度队列中拥有高优先级(HighPriority)、中优先级(MidPriority)、低优先级(LowPriority)3个Pod资源对象,它们等待被调度。调度队列中的Pod资源对象也被称为待调度Pod(Pending Pod)资源对象。
亲和性调度
- 亲和性(Affinity):用于多业务就近部署,例如允许将两个业务的Pod资源对象尽可能地调度到同一个节点上。
- 反亲和性(Anti-Affinity):允许将一个业务的Pod资源对象的多副本实例调度到不同的节点上,以实现高可用性。
- NodeAffinity:节点亲和性,Pod资源对象与节点之间的关系亲和性。
- PodAffinity:Pod资源对象亲和性,Pod资源对象与Pod资源对象的关系亲和性。
- RequiredDuringSchedulingIgnoredDuringExecution:Pod资源对象必须被部署到满足条件的节点上(与另一个Pod资源对象相邻),如果没有满足条件的节点,则Pod资源对象创建失败并不断重试。该策略也被称为硬(Hard)策略。
- PreferredDuringSchedulingIgnoredDuringExecution:Pod资源对象优先被部署到满足条件的节点上(与另一个Pod资源对象相邻),如果没有满足条件的节点,则从其他节点中选择较优的节点。该策略也被称为软(Soft)模式。
- PodAntiAffinity:Pod资源对象反亲和性,Pod资源对象与Pod资源对象的关系反亲和性。
- RequiredDuringSchedulingIgnoredDuringExecution:Pod资源对象必须被部署到满足条件的节点上(与另一个Pod资源对象互斥),如果没有满足条件的节点,则Pod资源对象创建失败并不断重试。该策略也被称为硬(Hard)策略。
- PreferredDuringSchedulingIgnoredDuringExecution:Pod资源对象优先被部署到满足条件的节点上(与另一个Pod资源对象互斥),如果没有满足条件的节点,则从其他节点中选择较优的节点。该策略也被称为软(Soft)模式。
核心实现
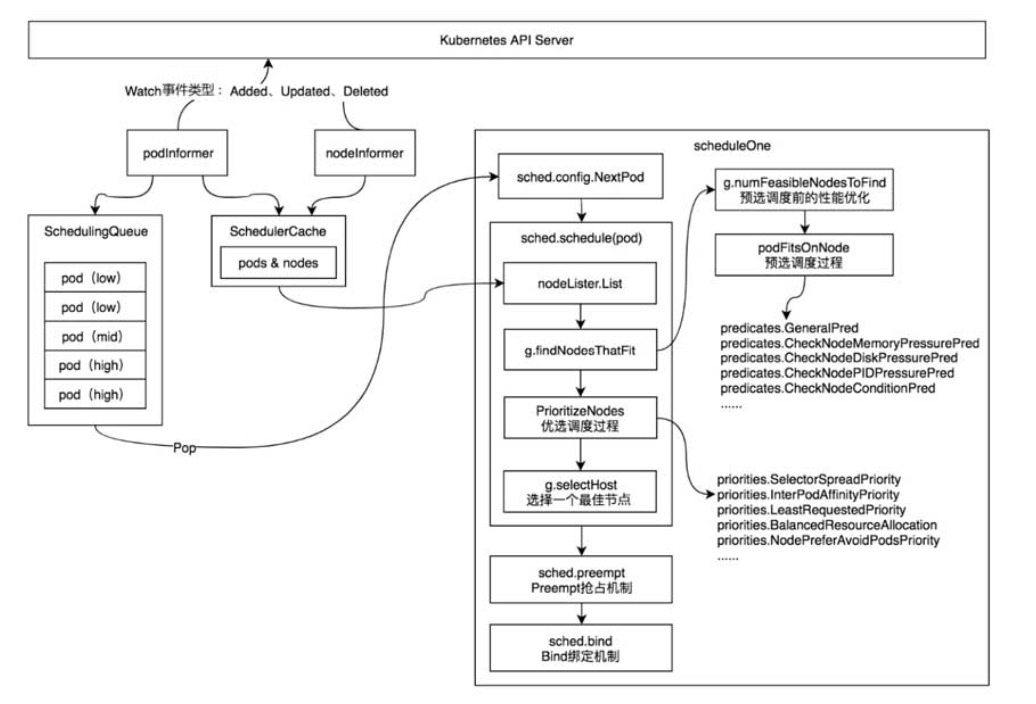
kube-scheduler调度器在启动过程中实例化并运行了多个资源的Informer,其中podInformer和nodeInformer用于同步Kubernetes API Server上的资源数据。
podInformer将监控到的Pod资源事件分别存储至调度队列(SchedulingQueue)和调度缓存(SchedulingCache)中。
nodeInformer将监控到的Node资源事件存储至调度缓存(SchedulingCache)中。
调度队列(SchedulingQueue):存储了待调度Pod资源对象。调度队列的实现有两种方式,分别是FIFO(先进先出队列)和PriorityQueue(优先级队列)。其中优先级队列根据Pod资源对象的优先级进行排序,优先级越高的排得越前。
调度缓存(SchedulingCache):存储了调度过程中使用到的Pod和Node资源信息。
- 第1部分:通过sched.config.NextPod函数从优先级队列中获取一个优先级最高的待调度Pod资源对象,该过程是阻塞模式的,当优先级队列中不存在任何Pod资源对象时,sched.config.NextPod函数处于等待状态。
- 第2部分:通过sched.schedule(pod)调度函数执行预选调度算法和优选调度算法,为Pod资源对象选择一个合适的节点。
- 第3部分:当高优先级的Pod资源对象没有找到合适的节点时,调度器会通过sched.preempt函数尝试抢占低优先级的Pod资源对象的节点。
- 第4部分:当调度器为Pod资源对象选择了一个合适的节点时,通过sched.bind函数将合适的节点与Pod资源对象绑定在一起。
调度过程
- 1.预选调度前的性能优化
1 | kube-scheduler调度器会将Kubernetes集群中所有的可用节点(Available Node)都加载到预选调度过程中 |
- 2.预选调度过程
1 | kube-scheduler调度器通过PercentageOfNodesToScore参数值计算出需要参与预选调度的节点数量,遍历这些节点并执行所有的预选调度算法, |
- 3.优选调度过程
1 | 优选调度算法为每一个可用节点计算出一个最终分数,kube-scheduler调度器会将分数最高的节点作为运行Pod资源对象的节点。 |
- 4.选择一个最佳节点
1 | kube-scheduler调度器会通过selectHost函数将分数最高的节点作为运行Pod资源对象的节点。 |
抢占机制
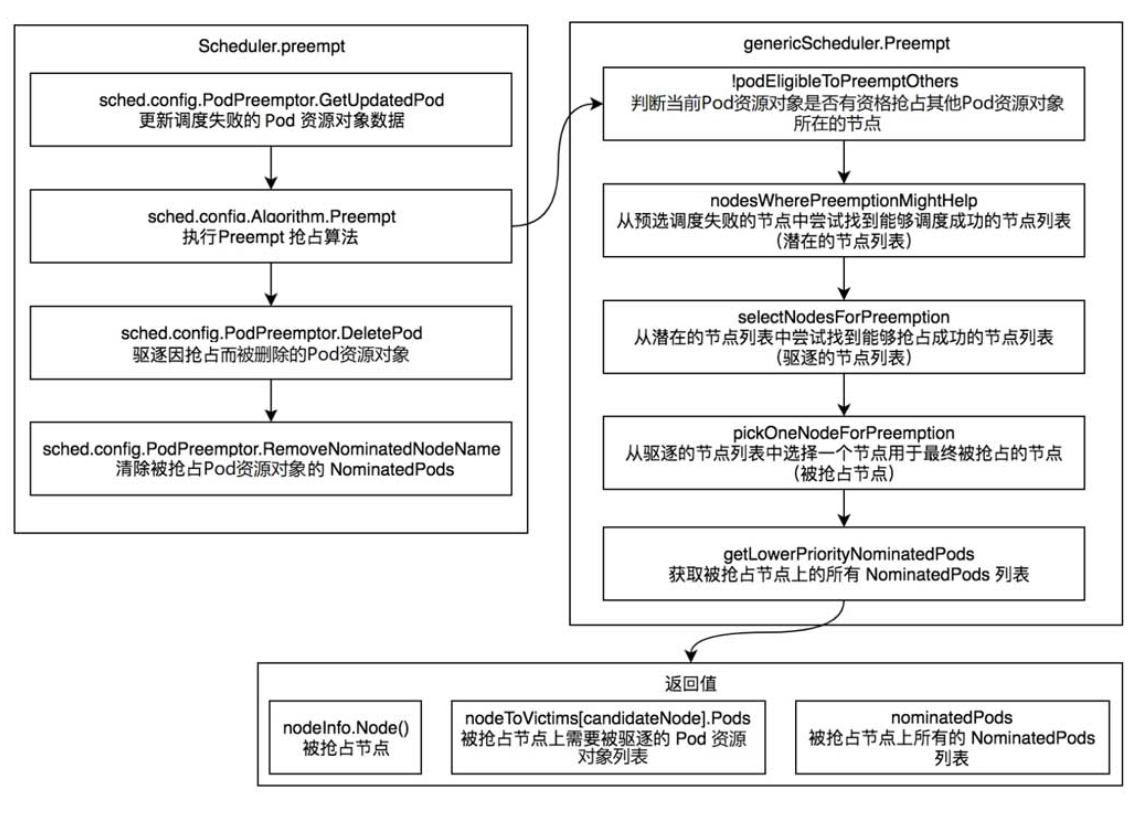
抢占只会发生在Pod资源对象没有调度成功,sched.schedule函数返回FitError错误时。
- sched.config.PodPreemptor.GetUpdatedPod函数通过ClientSet向Kubernetes API Server发起请求,更新调度失败的Pod资源对象数据。
- sched.config.Algorithm.Preempt函数执行Preempt抢占算法,返回值为node(被抢占的节点)、victims (被抢占节点上需要被驱逐的Pod资源对象列表)、nominatedPodsToClear(被抢占节点上所有的NominatedPods列表)。
- sched.config.PodPreemptor.DeletePod函数驱逐victims(被抢占节点上需要被驱逐的Pod资源对象列表)。驱逐过程通过ClientSet向Kubernetes API Server发起删除Pod资源对象的请求。
- sched.config.PodPreemptor.RemoveNominatedNodeName函数清除nominatedPodsToClear (被抢占节点上所有的NominatedPods列表)上的NominatedNodeName字段,因为被抢占的Pod资源对象已经不再适合此节点。
genericScheduler.Preempt
- 1.判断当前Pod资源对象是否有资格抢占其他Pod资源对象所在的节点
遍历节点上的所有Pod资源对象,如果发现节点上有Pod资源对象的优先级小于待调度Pod资源对象并处于终止状态,则返回false,不会发生抢占。 - 2:从预选调度失败的节点中尝试找到能够调度成功的节点列表(潜在的节点列表)
- 3.从潜在的节点列表中尝试找到能够抢占成功的节点列表(驱逐的节点列表)
- 4.从驱逐的节点列表中选择一个节点用于最终被抢占的节点(被抢占节点)
以下标准选择一个节点作为最终被抢占的节点。
-(1)PDB中断次数最少的节点。PDB(PodDisruptionBudget)能够限制同时中断的Pod资源对象的数量,以保证集群的高可用性。
-(2)具有最少高优先级Pod资源对象的节点。
-(3)具有优先级Pod资源对象总数最少的节点。
-(4)具有被驱逐Pod资源对象总数最少的节点。
-(5)最后多个节点具有相同的分数,直接返回第一个节点。 - 5.获取被抢占节点上的所有NominatedPods列表
Client-Go机制
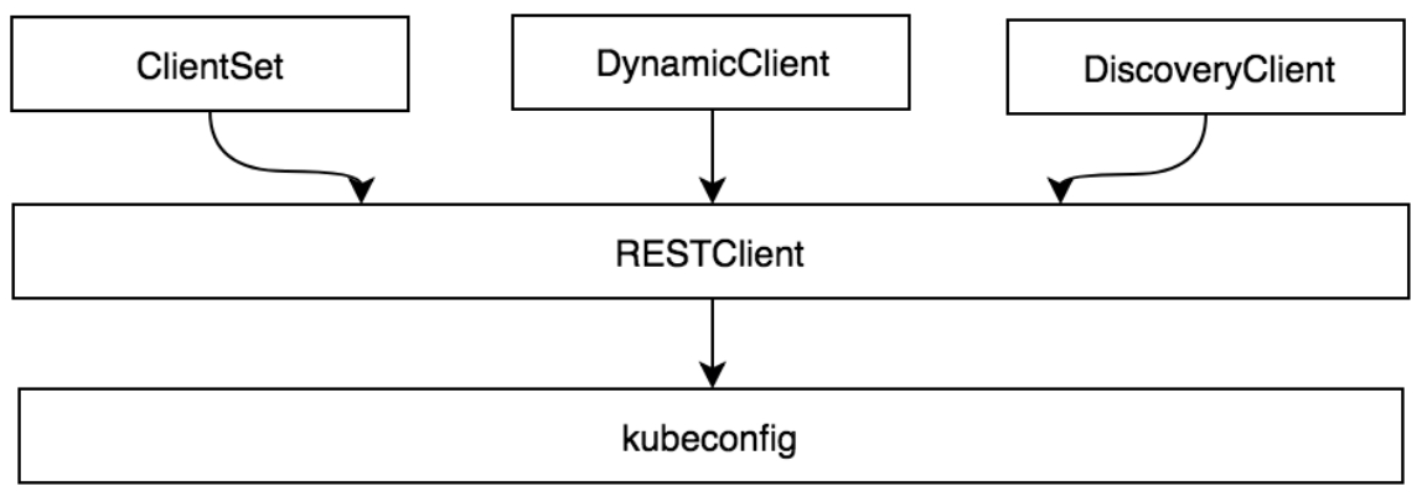
Client客户端对象
RestClient
RESTClient是最基础的客户端。
RESTClient对HTTP Request进行了封装,实现了RESTful风格的API。
ClientSet、DynamicClient及DiscoveryClient客户端都是基于RESTClient实现的。
ClientSet
ClientSet在RESTClient的基础上封装了对Resource和Version的管理方法。
每一个Resource可以理解为一个客户端,而ClientSet则是多个客户端的集合,每一个Resource和Version都以函数的方式暴露给开发者。
ClientSet只能够处理Kubernetes内置资源,它是通过client-gen代码生成器自动生成的。
DynamicClient
DynamicClient与ClientSet最大的不同之处是,ClientSet仅能访问Kubernetes自带的资源(即Client集合内的资源),不能直接访问CRD自定义资源。
DynamicClient能够处理Kubernetes中的所有资源对象,包括Kubernetes内置资源与CRD自定义资源。
kubeconfig配置管理
kubeconfig配置信息通常包含3个部分,分别介绍如下。
- clusters:定义Kubernetes集群信息,例如kube-apiserver的服务地址及集群的证书信息等。
- users:定义Kubernetes集群用户身份验证的客户端凭据,例如client-certificate、client-key、token及username/password等。
- contexts:定义Kubernetes集群用户信息和命名空间等,用于将请求发送到指定的集群。
Informer机制
在Kubernetes系统中,组件之间通过HTTP协议进行通信,在不依赖任何中间件的情况下需要保证消息的实时性、可靠性、顺序性等。
那么Kubernetes是如何做到的呢?
答案就是Informer机制。Kubernetes的其他组件都是通过client-go的Informer机制与Kubernetes API Server进行通信的。
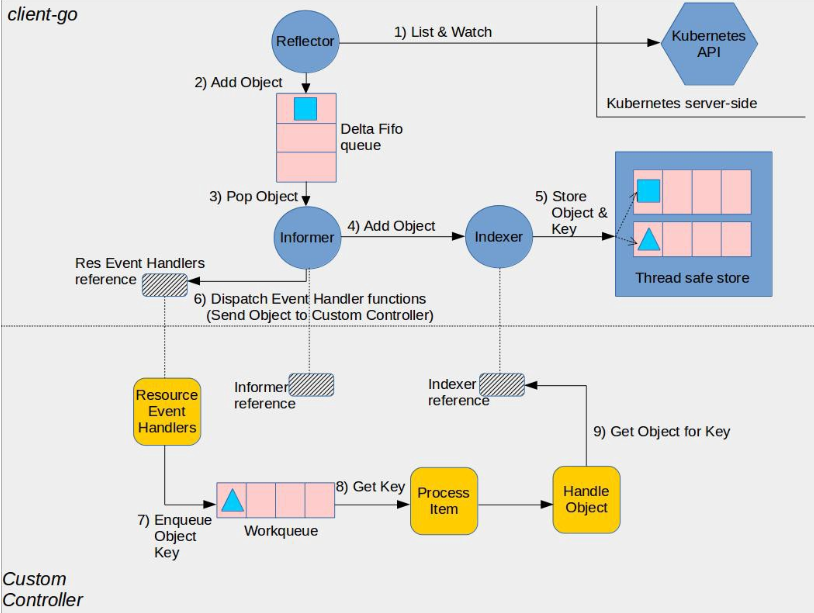
Informer机制架构设计及运行原理如图
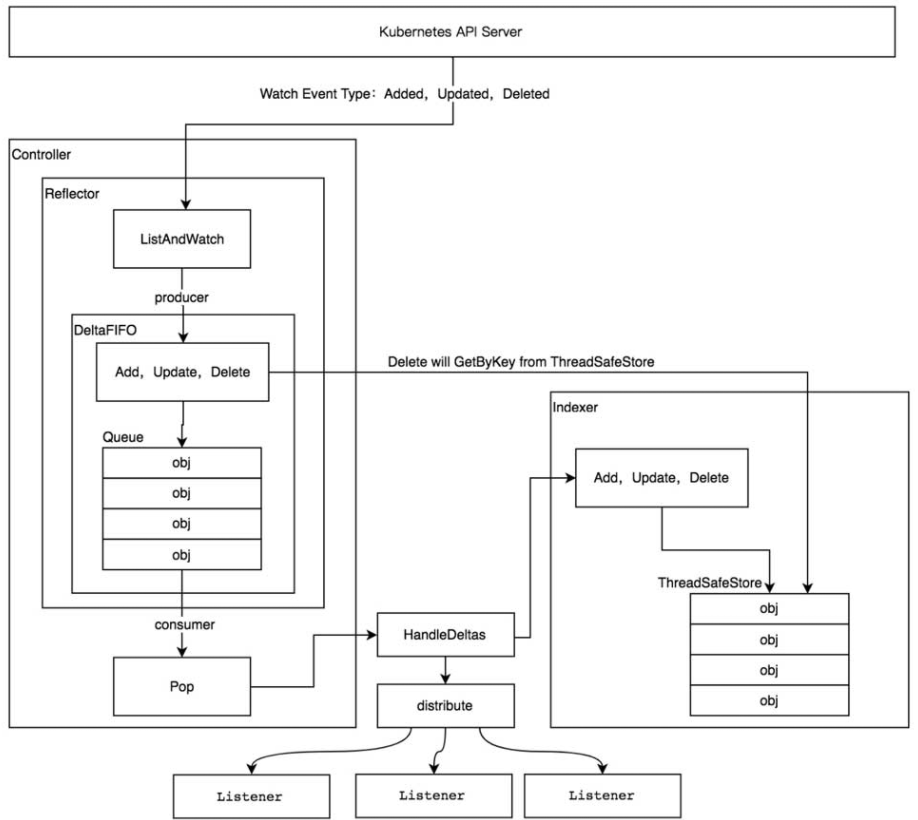
在Informer架构设计中,有多个核心组件,分别介绍如下。
- Reflector用于监控(Watch)指定的Kubernetes资源,当监控的资源发生变化时,触发相应的变更事件
例如Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除)事件,并将其资源对象存放到本地缓存DeltaFIFO中。 - DeltaFIFODeltaFIFO可以分开理解,FIFO是一个先进先出的队列,它拥有队列操作的基本方法
例如Add、Update、Delete、List、Pop、Close等,而Delta是一个资源对象存储,它可以保存资源对象的操作类型
例如Added(添加)操作类型、Updated(更新)操作类型、Deleted(删除)操作类型、Sync(同步)操作类型等。 - IndexerIndexer是client-go用来存储资源对象并自带索引功能的本地存储,Refector从DeltaFIFO中将消费出来的资源对象存储至Indexer。
Indexer与Etcd集群中的数据完全保持一致。
client-go可以很方便地从本地存储中读取相应的资源对象数据,而无须每次从远程Etcd集群中读取,以减轻Kubernetes API Server和Etcd集群的压力。
通过Informer机制可以很容易地监控我们所关心的资源事件,例如,当监控Kubernetes Pod资源时,如果Pod资源发生了Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除)事件,就通知client-go,告知Kubernetes资源事件变更了并且需要进行相应的处理。
Informer类型
资源Informer
每一个Kubernetes资源上都实现了Informer机制。每一个Informer上都会实现Informer和Lister方法,例如PodInformer
Shared Informer共享机制
Informer也被称为Shared Informer,它是可以共享使用的。在用client-go编写代码程序时,若同一资源的Informer被实例化了多次,每个Informer使用一个Refector,那么会运行过多相同的ListAndWatch,太多重复的序列化和反序列化操作会导致Kubernetes API Server负载过重。
Shared Informer可以使同一类资源Informer共享一个Refector,这样可以节约很多资源。
通过map数据结构实现共享的Informer机制。Shared Informer定义了一个map数据结构,用于存放所有Informer的字段
Reflector
Refector源码实现中,其中最主要的是ListAndWatch函数,它负责获取资源列表(List)和监控(Watch)指定的Kubernetes APIServer资源。
ListAndWatch函数实现可分为两部分
- 第1部分获取资源列表数据
- 第2部分监控资源对象。
1 | func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error { |
DeltaFIFO
DeltaFIFO可以分开理解,FIFO是一个先进先出的队列,它拥有队列操作的基本方法
例如Add、Update、Delete、List、Pop、Close等,而Delta是一个资源对象存储,它可以保存资源对象的操作类型
例如Added(添加)操作类型、Updated(更新)操作类型、Deleted(删除)操作类型、Sync(同步)操作类型等
DeltaFIFO存储结构

生产者方法
DeltaFIFO队列中的资源对象在Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除)事件中都调用了queueActionLocked函数,它是DeltaFIFO实现的关键
queueActionLocked代码执行流程如下。
- 通过f.KeyOf函数计算出资源对象的key。
- 如果操作类型为Sync,则标识该数据来源于Indexer(本地存储)。如果Indexer中的资源对象已经被删除,则直接返回。
- 将actionType和资源对象构造成Delta,添加到items中,并通过dedupDeltas函数进行去重操作。
- 更新构造后的Delta并通过cond.Broadcast通知所有消费者解除阻塞。
1 | func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error { |
消费者方法
Pop方法作为消费者方法使用,从DeltaFIFO的头部取出最早进入队列中的资源对象数据。
Pop方法须传入process函数,用于接收并处理对象的回调方法
1 | func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) { |
Indexer
Indexer是client-go用来存储资源对象并自带索引功能的本地存储,Refector从DeltaFIFO中将消费出来的资源对象存储至Indexer。
Indexer中的数据与Etcd集群中的数据保持完全一致。
client-go可以很方便地从本地存储中读取相应的资源对象数据,而无须每次都从远程Etcd集群中读取,这样可以减轻Kubernetes APIServer和Etcd集群的压力。
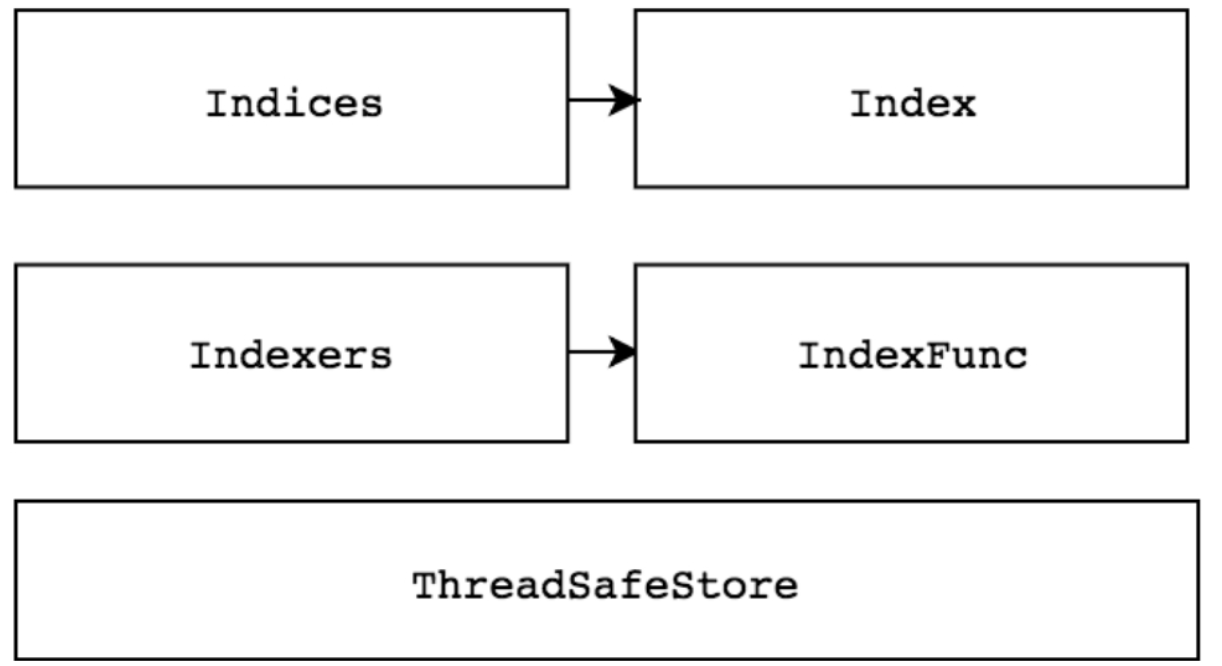
在介绍Indexer之前,先介绍一下ThreadSafeMap。
ThreadSafeMap是实现并发安全的存储。
作为存储,它拥有存储相关的增、删、改、查操作方法,例如Add、Update、Delete、List、Get、Replace、Resync等。Indexer在ThreadSafeMap的基础上进行了封装,它继承了与ThreadSafeMap相关的操作方法并实现了Indexer Func等功能,例如Index、IndexKeys、GetIndexers等方法,这些方法为ThreadSafeMap提供了索引功能
WorkQueue
WorkQueue称为工作队列,Kubernetes的WorkQueue队列与普通FIFO(先进先出,First-In,First-Out)队列相比,实现略显复杂,它的主要功能在于标记和去重,并支持如下特性。
- 有序:按照添加顺序处理元素(item)。
- 去重:相同元素在同一时间不会被重复处理,例如一个元素在处理之前被添加了多次,它只会被处理一次。
- 并发性:多生产者和多消费者。
- 标记机制:支持标记功能,标记一个元素是否被处理,也允许元素在处理时重新排队。
- 通知机制:ShutDown方法通过信号量通知队列不再接收新的元素,并通知metric goroutine退出。
- 延迟:支持延迟队列,延迟一段时间后再将元素存入队列。
- 限速:支持限速队列,元素存入队列时进行速率限制。限制一个元素被重新排队(Reenqueued)的次数。
- Metric:支持metric监控指标,可用于Prometheus监控。
WorkQueue支持3种队列,并提供了3种接口,不同队列实现可应对不同的使用场景,分别介绍如下。
- Interface:FIFO队列接口,先进先出队列,并支持去重机制。
- DelayingInterface:延迟队列接口,基于Interface接口封装,延迟一段时间后再将元素存入队列。
- RateLimitingInterface:限速队列接口,基于DelayingInterface接口封装,支持元素存入队列时进行速率限制。
延迟队列
vendor/k8s.io/client-go/util/workqueue/delaying_queue.go
AddAfter方法会插入一个item(元素)参数,并附带一个duration(延迟时间)参数,该duration参数用于指定元素延迟插入FIFO队列的时间。
如果duration小于或等于0,会直接将元素插入FIFO队列中。
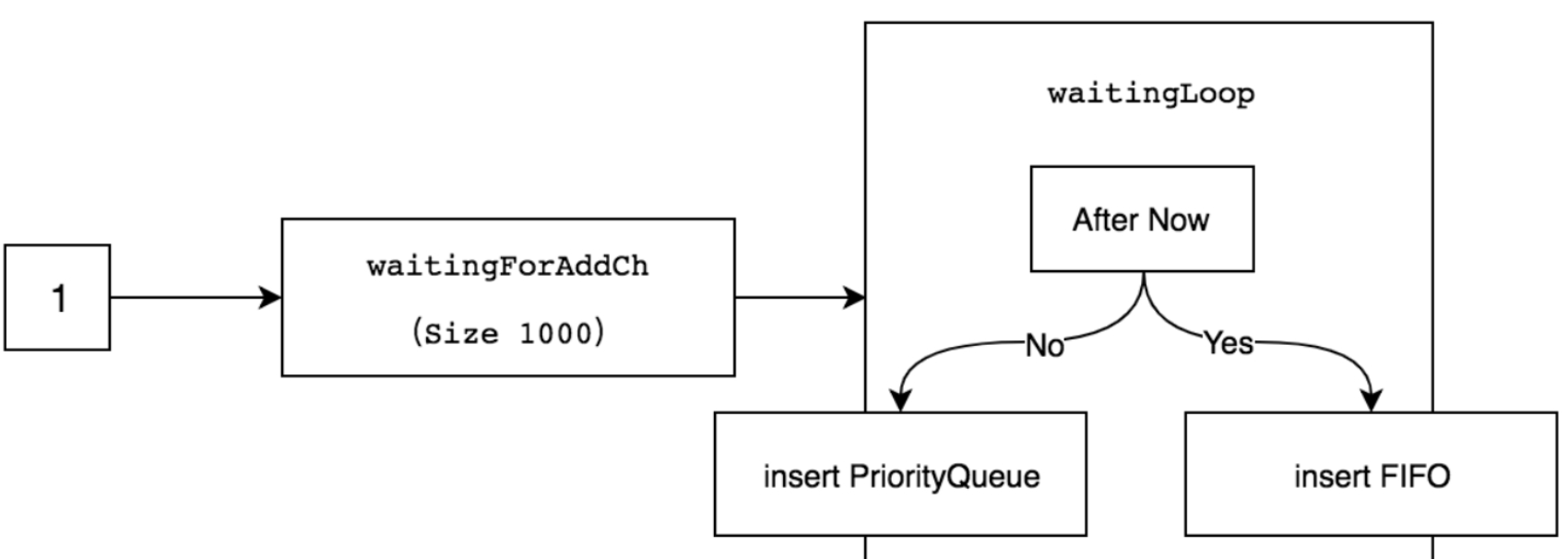
delayingType结构中最主要的字段是waitingForAddCh,其默认初始大小为1000,通过AddAfter方法插入元素时,是非阻塞状态的
只有当插入的元素大于或等于1000时,延迟队列才会处于阻塞状态。
waitingForAddCh字段中的数据通过goroutine运行的waitingLoop函数持久运行。
限速队列
限速队列的重点不在于RateLimitingInterface接口,而在于它提供的4种限速算法接口(RateLimiter)。
其原理是,限速队列利用延迟队列的特性,延迟某个元素的插入时间,达到限速目的
下面会分别详解WorkQueue提供的4种限速算法,应对不同的场景,这4种限速算法分别如下。
- 令牌桶算法(BucketRateLimiter)。
令牌桶算法内部实现了一个存放token(令牌)的“桶”,初始时“桶”是空的,token会以固定速率往“桶”里填充,直到将其填满为止,多余的token会被丢弃。
每个元素都会从令牌桶得到一个token,只有得到token的元素才允许通过(accept),而没有得到token的元素处于等待状态 - 排队指数算法(ItemExponentialFailureRateLimiter)。
排队指数算法将相同元素的排队数作为指数,排队数增大,速率限制呈指数级增长,但其最大值不会超过maxDelay。
元素的排队数统计是有限速周期的,一个限速周期是指从执行AddRateLimited方法到执行完Forget方法之间的时间。
如果该元素被Forget方法处理完,则清空排队数 - 计数器算法(ItemFastSlowRateLimiter)。
计数器算法是限速算法中最简单的一种,其原理是:限制一段时间内允许通过的元素数量
例如在1分钟内只允许通过100个元素,每插入一个元素,计数器自增1,当计数器数到100的阈值且还在限速周期内时,则不允许元素再通过。 - 混合模式(MaxOfRateLimiter),将多种限速算法混合使用。
混合模式是将多种限速算法混合使用,即多种限速算法同时生效。例如,同时使用排队指数算法和令牌桶算法
限速队列接口方法说明如下。
- When:获取指定元素应该等待的时间。
- Forget:释放指定元素,清空该元素的排队数。
- NumRequeues:获取指定元素的排队数。
Operator-sdk
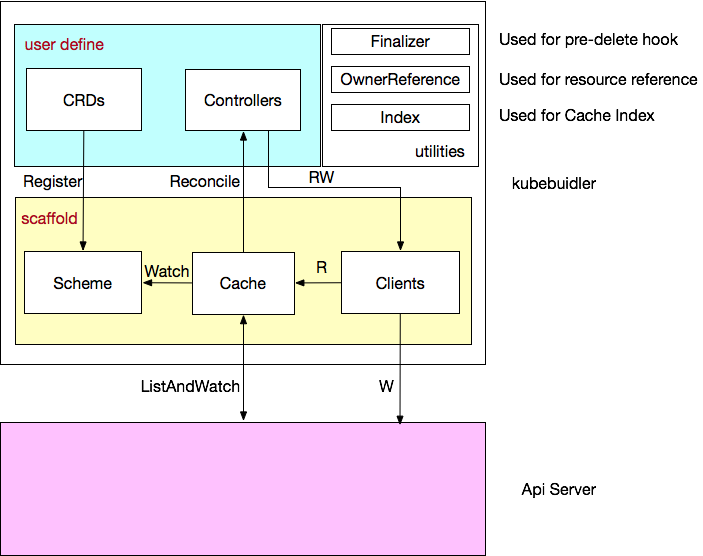
operator sdk与kubebuilder的区别?
operator sdk和kubebuilder都是为了用户方便创建和管理operator而生的脚手架项目。
对于用基于Golang开发的operator项目而言,operator sdk在底层使用了kubebuilder
例如operator sdk的命令行工具底层实际是调用kubebuilder的命令行工具。
所以无论由operator sdk还是kubebuilder创建的operator项目都是调用的controller-runtime接口,而有相同的项目布局。
基本操作命令
为你的项目创建一个项目目录并初始化项目
1 | mkdir memcached-operator |
创建一个简单的 Memcached API:
1 | operator-sdk create api --group cache --version v1alpha1 --kind Memcached --resource --controller |
修改
*_types.go文件后,始终运行以下命令来更新该资源类型的生成代码:
1 | make generate |
使用规范/状态字段和 CRD 验证标记定义 API 后,可以使用以下命令生成和更新 CRD 清单
1 | make manifests |
控制器监视的资源
该SetupWithManager()函数controllers/memcached_controller.go是怎么控制器内置指定观看CR和拥有并通过控制器管理的其他资源。
1 | import ( |
- NewControllerManagedBy()提供了一个控制器助洗剂,其允许各种控制器配置。
- For(&cachev1alpha1.Memcached{})将 Memcached 类型指定为要监视的主要资源。对于每个 Memcached 类型的添加/更新/删除事件,协调循环将发送Request该 Memcached 对象的协调(命名空间/名称键)。
- Owns(&appsv1.Deployment{})将 Deployments 类型指定为要监视的辅助资源。对于每个部署类型的添加/更新/删除事件,事件处理程序会将每个事件映射到Request部署所有者的协调。在这种情况下,这是为其创建部署的 Memcached 对象。
控制器配置
初始化控制器时可以进行许多其他有用的配置。有关这些配置的更多详细信息,请参阅上游构建器和控制器godocs。
1 | func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error { |
- 通过MaxConcurrentReconciles 选项设置控制器的最大并发协调数。默认为 1。
- 使用谓词过滤观察事件
- 选择EventHandler的类型以更改监视事件将如何转换为协调循环的协调请求。对于比主要和次要资源更复杂的运算符关系,EnqueueRequestsFromMapFunc处理程序可用于将监视事件转换为任意一组协调请求。
构建并推送您的镜像:
1 | make docker-build docker-push IMG="example.com/memcached-operator:v0.0.1" |
部署
1 | make deploy IMG="example.com/memcached-operator:v0.0.1" |
创建示例 Memcached 自定义资源:
1 | kubectl apply -f config/samples/cache_v1alpha1_memcached.yaml |
卸载部署
1 | make undeploy |
原理
深入
在使用 Kubebuilder 的过程中有些问题困扰着我:
如何同步自定义资源以及 K8s build-in 资源?
Controller 的 Reconcile 方法是如何被触发的?
Cache 的工作原理是什么?
…
Istio
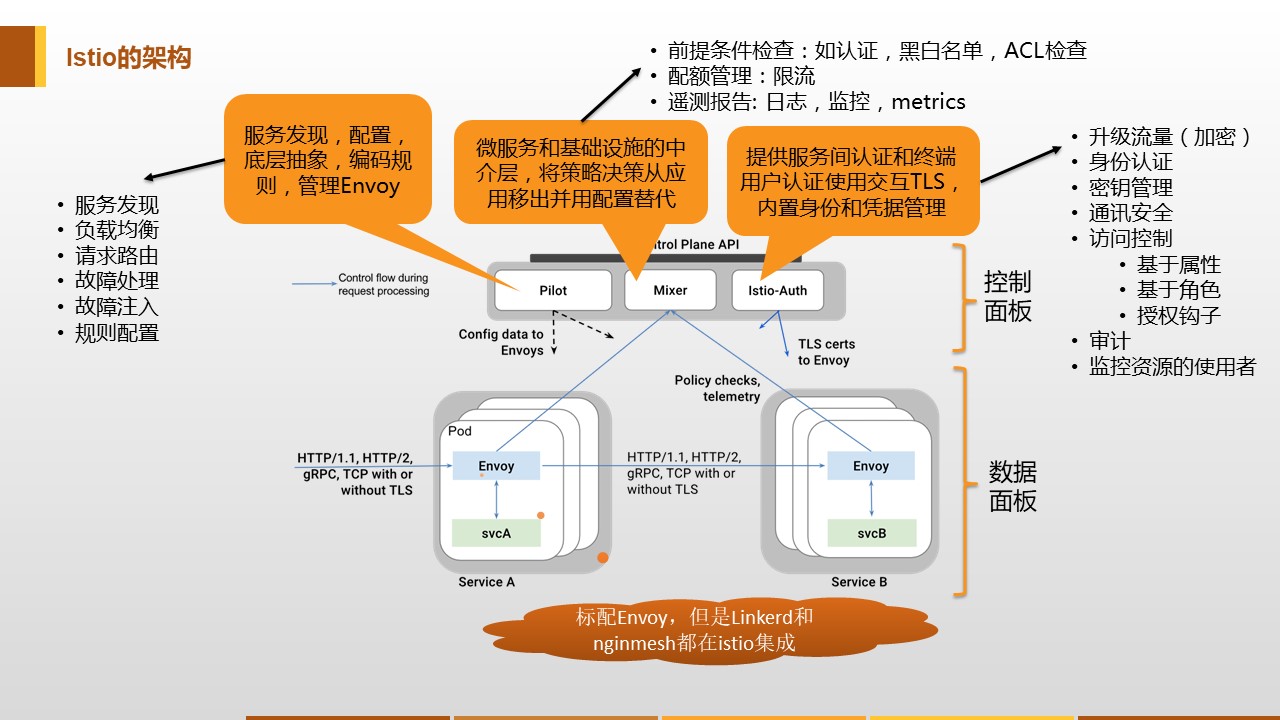
大体分两个结构:数据面板(Envoy)和控制面板(Istio)
- Pilot:提供了服务发现均衡负载以及路由配置还有故障注入,管理Envoy的转发规则
- Mixer:Envoy转发请求前的前提条件检查验证服务是否白名单ACL等以及配额上的资源管理,转发请求后的日志和监控信息上报
- Istio-Auth:服务间的认证
实践篇
对于Sidecar的具体实现有很多选择,比如早期的Linkerd,后来的Envoy或者经典反向代理Nginx衍生出的Nginmesh等。然而Istio选择的却是Envoy,笔者个人认为Nginx作为之前服务架构中广泛使用的网关,却没有得到Istio的青睐,很大程度上是因为没有像Envoy那样优秀的配置扩展API。虽然Nginx也支持Lua扩展脚本,但却是静态级别的,与Envoy的实时配置相差甚远,与Istio的透明配置设计相违背。
xDS-API
可见Envoy的动态转发/代理功能是相当强大的,几乎可以动态配置一切路由、转发及监听规则。
Istio正是利用了这点,对所有注入的Sidecar进行全局管控,将系统管理集中配置的路由及服务信息分发给各节点的Envoy。
- SDS/EDS(Service/Endpoint(v2)Discovery Service)
节点发现服务,针对的就是提供服务的节点,让节点可以以聚合成服务的方式提供给调用方。在Envoy v2 API中,ServiceDiscovery Service已经更名为Endpoint Discovery Service,因此这两个描述本质上是一个概念。
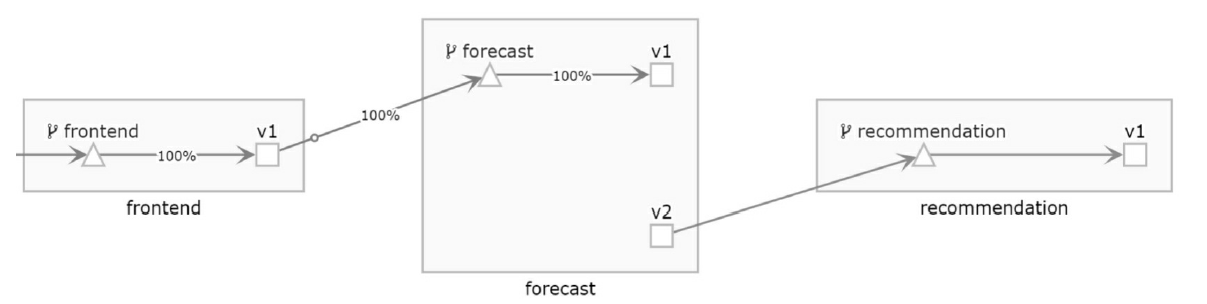
- CDS(Cluster Discovery Service)
集群发现服务,集群指Envoy接管的服务集群,例如三台机器组成了一个服务集群提供reviews服务;Istio可以使用这个接口创建虚拟集群,例如一个应用可以划分出不同版本号的部署结构。
- RDS(Route Discovery Service)
路由规则发现服务,路由规则的作用是动态转发,例如上面BookInfo中的指定流量只流向v3版本的reviews服务,基于此可以实现比如请求漂移、蓝绿发布等功能。
- LDS(Listener Discovery Service)
监听器发现服务,监听器主要作用于Envoy的链接状态,例如像downstream_cx_total(连接总数)、downstream_cx_active(活动的连接总数)等。
流量控制
负载均衡
ROUND_ROBIN模式

RANDOM模式

会话保持

故障应急机制
Envoy之所以会结合主动与被动两种健康检测方式,是为了避免将不可用的服务纳入网格。当与平台提供的健康检测结果相结合时,应用能够最大限度地保证故障节点及时被移除,最大限度地减少因为检测延时而导致的错误调用。
以上功能都是可以通过Istio的配置规则进行动态设置的。这些功能的结合,为Istio中的服务提供了健康保障,能有效避免因过载导致的各类链路故障。
超时机制
在服务请求总时间超过一个阈值时直接返回错误,避免卡死。

断路器支持
同样对服务过载进行保护。
熔断
服务端的Proxy会记录调用发生错误的次数,然后根据配置决定是否继续提供服务或者立刻返回错误。使用熔断机制可以保护服务后端不会过载。
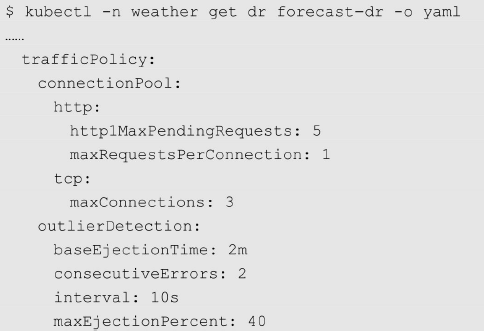
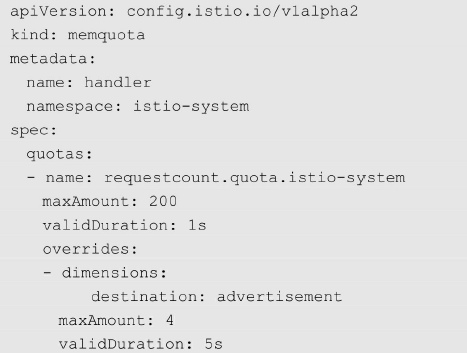
限流
限流是一种预防措施,在发生灾难发生前就对并发访问进行限制。Istio的速率限制特性可以实现常见的限流功能,即防止来自外部服务的过度调用。
衡量指标主要是QPS(每秒请求量),实现方式是计数器方式。
Istio 支持 Memquota 适配器和 Redisquota 适配器。
- 普通方式
首先对目标服务advertisement在上线前进行性能测试,找到此服务最大能承受的性能值,在上线时利用这个性能值设置限流规则,使得在请求达到限制的速率时触发限流。
Istio的限流是直接拒绝多出来的请求,对客户端直接返回“429:RESOURCE_EXHAUSTED”状态码。
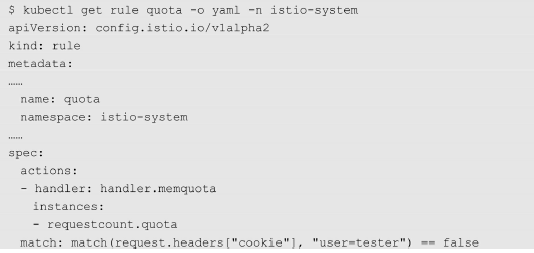
- 条件方式
Istio的速率限制还可以用于另一种场景:普通用户在使用advertisement服务时,只被提供免费的配额,若超过免费配额的请求,则被限制。
对于付费的特殊用户会取消速率限制。
健康检测
对挂载服务进行健康检测,支持主动与被动(即平台提供的健康检测结果)两种方式,以及时剔除不健康的节点,当其恢复时又及时加入。
并行连接控制
对下游的并行连接数量进行控制,以避免过载的情况。
重试机制
采用不确定重试时间间隔,并限制重试次数,最大程度保障服务调用的顺畅性。

服务隔离
Sidecar资源的配置是Istio 1.1新引入的功能,支持定义Sidecar可访问的服务范围,让用户能够更精确地控制Sidecar的行为。
影子测试
查找新代码错误的最佳方法是在实际环境中进行测试。影子测试可以将生产流量复制到目标服务中进行测试,在处理中产生的任何错误都不会对整个系统的性能和可靠性造成影响。
上面配置的策略将全部流量都发送到 forecast 服务的 v1 版本,其中的 mirror 字段指定将流量复制到forecast服务的v2版本。
当流量被复制时,会在请求的HOST或Authority头中添加-shadow后缀(例如forecast-shadow)并将请求发送到forecast服务的v2版本以示它是影子流量。这些被复制的请求引发的响应会被丢弃,不会影响终端客户。

重定向&重写
- 重定向
HTTP重定向(HTTP Redirect)能够让单个页面、表单或者整个Web应用都跳转到新的 URL 下,该操作可以应用于多种场景:网站维护期间的临时跳转,网站架构改变后为了保持外部链接继续可用的永久重定向,上传文件时的进度页面等

- 重写
HTTP 重写(HTTPRewrite)用来在 HTTP 请求被转发到目标之前,对请求的内容进行部分改写。

故障注入
通常来说故障模拟都是通过杀掉服务进程或者发送一个错误的TCP包来模拟的,显然这种方式非常低效。
Istio支持两种形式的错误注入:延时(delays)与丢包(aborts)。
延时,顾名思义就是增加网络的传输延时以模拟服务过载时出现的问题;
丢包则是模拟上行服务故障,这种故障一般是利用HTTP错误码来实现的。
- 延迟注入
为advertisement服务注入3秒的延迟,期望访问advertisement服务的返回时间是3秒
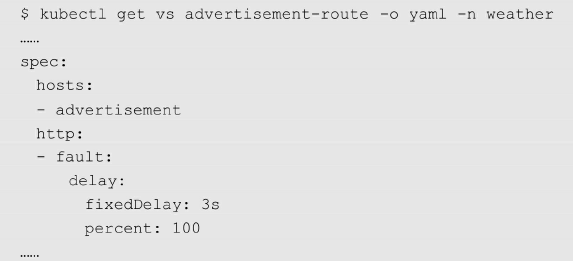
- 中断注入
为 advertisement服务注入 HTTP 500 错误,期望在访问 advertisement服务时始终返回“500”状态码。

Envoy
基础架构图
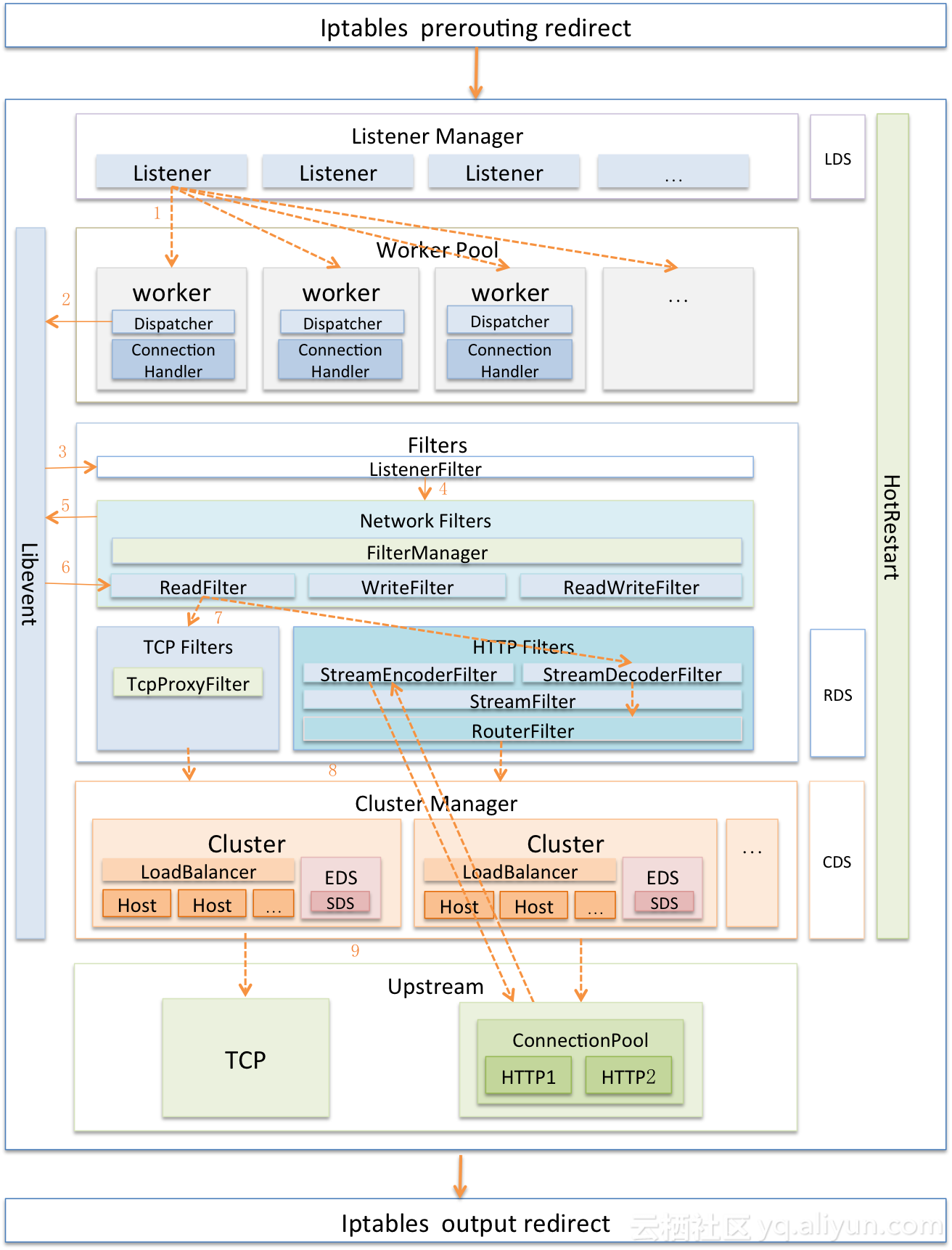
清晰架构图
逻辑架构图
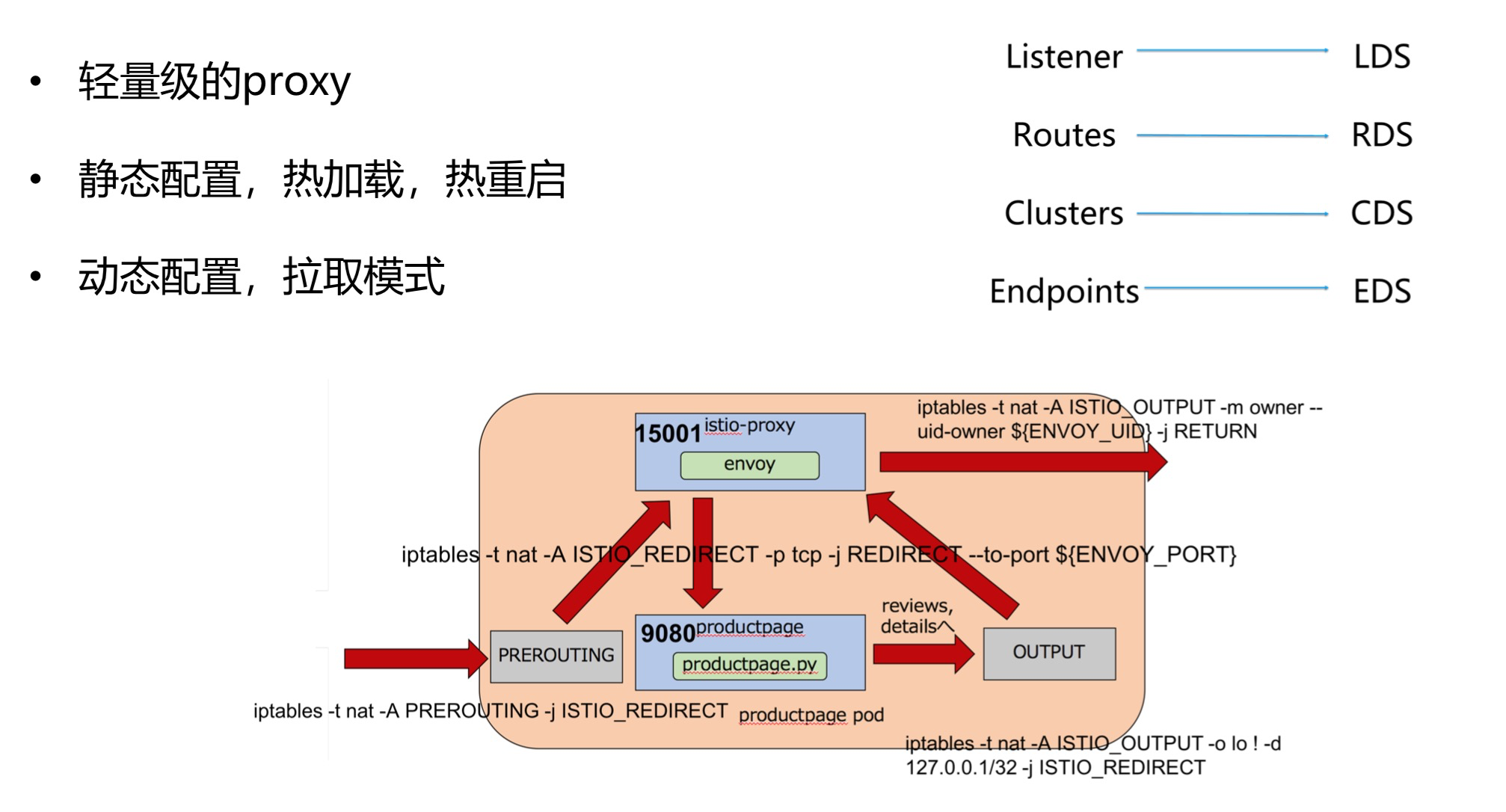
Envoy的另一特点是支持配置信息的热更新,其功能由XDS模块完成,XDS是个统称,具体包括ADS(Aggregated Discovery Service)、SDS(Service Discovery Service)、EDS(Endpoint Discovery Service)、CDS(Cluster Discovery Service)、RDS(Route Discovery Service)、LDS(Listener Discovery Service)。
XDS模块功能是向Istio的Pilot获取动态配置信息,拉取配置方式分为V1与V2版本,V1采用HTTP,V2采用gRPC。
Envoy还支持热重启,即重启时可以做到无缝衔接,其基本实现原理是:
将统计信息与锁放到共享内存中。
新老进程采用基本的RPC协议使用Unix Domain Socket通讯。
新进程启动并完成所有初始化工作后,向老进程请求监听套接字的副本。
新进程接管套接字后,通知老进程关闭套接字。
通知老进程终止自己。
Envoy同样也支持Lua编写的Filter,不过与Nginx一样,都是工作在HTTP层,具体实现原理都一样
基础
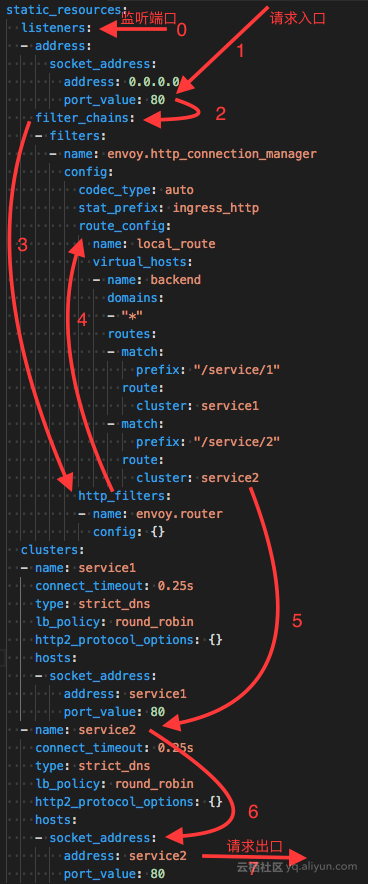
在配置里面往往会配置四个东西。
- Listener->LDS
也即envoy既然是proxy,专门做转发,就得监听一个端口,接入请求然后才能够根据策略转发,这个监听的端口称为listener
- Routes->RDS
有时候多个cluster具有类似的功能,但是是不同的版本号,可以通过route规则,选择将请求路由到某一个版本号,也即某一个cluster。
- Clusters->CDS
一个cluster是具有完全相同行为的多个endpoint,也即如果有三个容器在运行,就会有三个IP和端口,但是部署的是完全相同的三个服务, 他们组成一个Cluster,从cluster到endpoint的过程称为负载均衡,可以轮询等。
- Endpoints->EDS
是目标的ip地址和端口,这个是proxy最终将请求转发到的地方。
Envoy可以通过加装静态配置文件的方式运行,而动态信息需要从Discovery Service去拿。Discovery Service就是部署在控制面的,在istio中是Pilot。
Envoy Mesh
Envoy Mesh指的是由envoy做负载均衡和代理的mesh。该Mesh中会包含两类envoy
- Edge envoy:即流量进出 mesh 时候的 envoy,相当于 kubernetes 中的 ingress。
- Service envoy:服务 envoy 是跟每个 serivce 实例一起运行的,应用程序无感知的进程外工具,在 kubernetes 中会与应用容器以 sidecar 形式运行在同一个 pod 中。
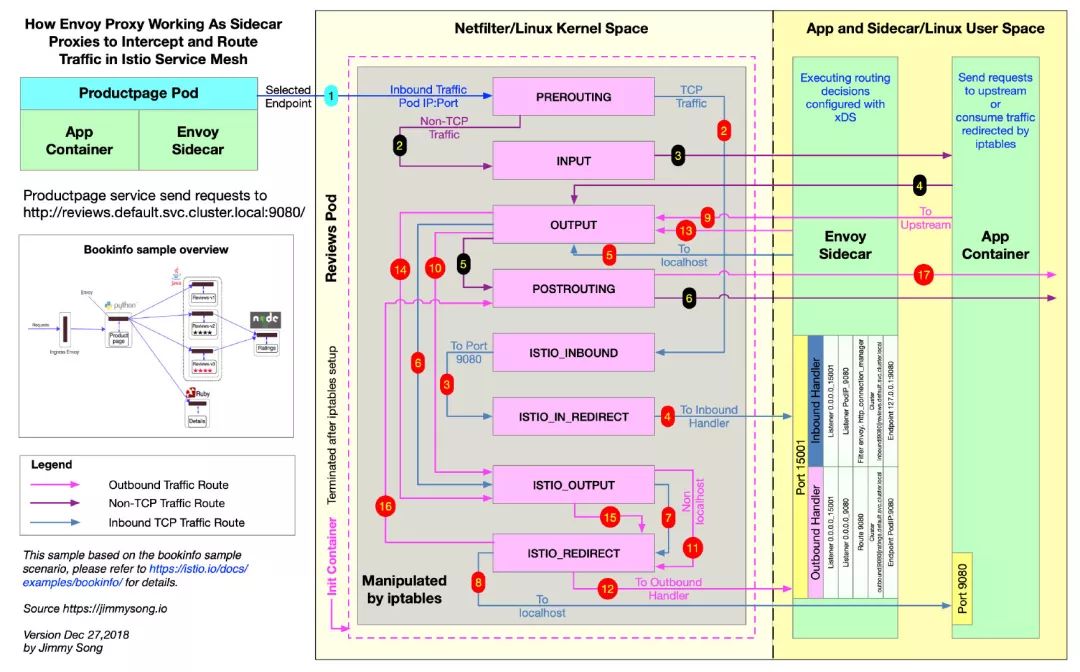
定制化
嵌入proxy_init作为InitContainer
定制化的第一项就是添加了一个initContainer
1 | 在这个InitContainer里面运行了一个shell脚本 |
嵌入proxy容器作为sidecar
嵌入proxy容器作为sidecar
进入容器我们可以看到,启动了两个进程。
1 | 一个是我们熟悉的envoy,他有一个配置文件是/etc/istio/proxy/envoy-rev0.json |
Envoy架构
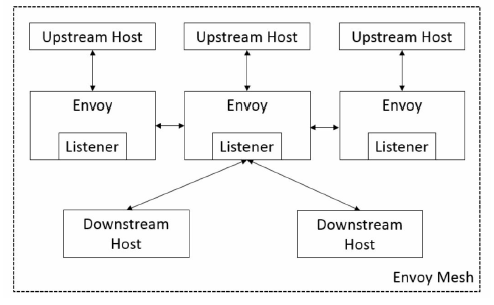
在Envoy模型中有以下基本概念
- Upstream Host:上游主机,接收Envoy的连接和请求并返回响应。一组逻辑相似的主机被称作Cluster,Envoy通过负载均衡规则将请求路由到对应的Cluster成员。
- Downstream Host:下游主机,向Envoy发起请求并接收响应。
- Listener:Envoy 内部的监听器,用来监听下游主机,下游主机通过 Listener 连接Envoy。
- Envoy Mesh:Envoy网格,是由一组Envoy和多个不同的服务或应用平台组成的拓扑。
Envoy特性
部署模式
Envoy作为一个独立的进程,与应用服务相伴运行。这种结构的好处如下。
- 可以兼容多种编程语言如 Java、C++、Go、Python 等的应用服务:在由多种语言编写的应用组成的网格中,Envoy作为桥梁,连接不同编程语言的应用。
- Envoy的使用可以大大提升效率:针对大规模应用服务的架构,传统软件的库更新是非常痛苦的,而Envoy的部署和升级单独完成。
协议支持
Envoy的协议兼容性非常广
- 作为L3/L4网络代理,支持TCP、HTTP代理和TLS认证;
- 作为L7代理,支持Buffer、限流等高级功能;
- 作为L7路由,Envoy支持通过路径、权限、请求内容、运行时间等参数重定向路由请求,并支持L7的MongoDB和DynamoDB;
- 在HTTP模式下同时支持HTTP/1.1和HTTP/2,还支持基于HTTP/2的gRPC请求和响应。
功能及可拓展性
Envoy支持对上游主机的服务发现和健康检查,选定活跃的主机作为负载均衡的目标。
它的负载均衡支持自动重连、熔断、全局限速、流量镜像和异常点检查等多种高级功能。
因为其主要设计目标是使网络透明化,所以针对网络和应用层的问题诊断提供了大量的统计数据,可以通过Admin端口获取,并且可以通过API端口动态下发规则。
拥有上述丰富的功能,Envoy也常被用于边缘代理。
性能
到达应用的数据会经过 Envoy 处理和路由,这会增加一定的时延,但这并不意味着Envoy很慢,Envoy在设计之初就考虑到了模块化和快速路径。Envoy由C++11编写,拥有良好的性能,相较于其他代理或者负载均衡软件自身的时延和内存使用,Envoy并不会额外增加很多系统负担。
Envoy的模块结构
Envoy的模块结构如图所示,包含utils、Network、Network filter、L7 protocol、L7 filter、ServerManager、L7 Connection Manager及Cluster Manager这几个子模块。
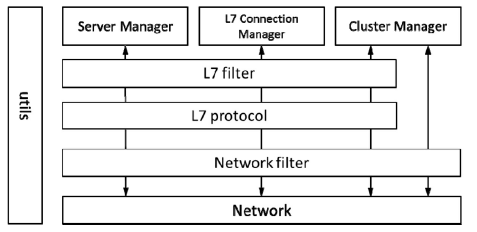
- utils 模块包含各模块都可能用到的公共库,例如压缩、解压缩、访问日志和状态统计等;
- Network 模块是抽象操作系统的 Socket 接口,向上提供统一的数据读写功能,读写数据采用C++的readv接口,将数据读到struct iovec中,之后交给libevent统一管理;
- Network filter 模块在网络层中过滤数据流量,包含 Listener filter、Read filter 和Write filter,目前支持Client TLS authentication、Echo、External Authentication、Mongo proxy、Rate Limit、Redis proxy及TCP proxy;
- L7 protocol模块是L7的一个协议处理层,目前包含HTTP和gRPC。在一般情况下,如果在一个部署场景下只包含一个L7过滤器,那么这一层模块的功能为编码和解码,以实现L7的协议过滤、桥接等功能;
- L7 filter模块是基于 L7的过滤模块,包括 L7的路由规则等功能,目前支持认证鉴权,与 HTTP 路由相关的路由、限流、IP 标签和 Buffer,健康检查及与其相关的故障注入、squash,与gRPC相关的桥接、转码等;
- Server Manager模块是管理整个Envoy功能的核心模块,包括Worker管理、启动管理、配置管理和日志访问管理等功能;
- L7 Connection Manager模块是基于L7协议的连接管理模块,包括建立连接、复用连接等功能;
- Cluster Manager模块是集群管理模块,包括集群内的Host管理、负载均衡、健康检查等。集群管理模块可能会不经过L7层,直接访问L3、L4层实现健康管理等。
Envoy的线程模型
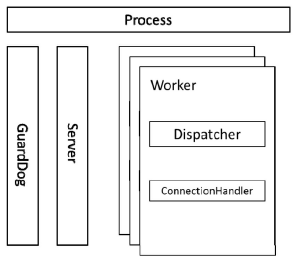
如图所示,一个Envoy进程包含一个Server主线程和一个GuardDog守护线程,这两个线程的功能是固定的,其中Server 线程负责管理 Access Log 及解析上游主机的DNS 等,GuardDog 负责看门狗业务。
一个 Envoy 的进程可以配置多个 Listener(推荐一个进程对应一个 Listener),每个 Listener都独立调度,在每个 Listener下都创建若干条线程(默认值为核心数量),每条线程都对应一个Worker,多个Worker并行处理该Listener的事务
Server线程
Server线程用于处理Access Log和DNS解析。
Access Log根据配置的信息来处理Envoy的访问记录,并且将访问记录刷新到本地文件系统中(如果配置),同时监听 TCP的端口(如果配置),并且根据 TCP的请求处理并返回对应的结果。
DNS解析指统一将在系统中配置的域名(包括集群中的主机域名和外部服务的域名)解析成IP地址列表并缓存在本地DNS缓存中。当Envoy内部的其他模块需要解析域名时,直接从本地缓存中查找。
Envoy中的DNS解析使用Network::DnsResolver实现缓存,使用c-ares这个开源项目为解析器,通过设置定时器定时刷新DNS缓存,定时器的轮询时间由ares_init_options设定。
Worker线程
ListenerManager 根据配置文件中的本地监听端口启动若干 Worker 线程,这些线程通过libevent处理Socket的accept、epoll等相关事件。在一般情况下,多条线程按照libevent配置的策略并行处理事件,但是一旦某个客户端连接进入Envoy的某个线程,则连接断开之前的逻辑都在该线程内处理。
例如根据Client 端的请求处理对应的 TCP filter,解码L7协议并重新编码L7协议,和上游Server主机建立连接并处理上游主机返回的数据等一系列操作的逻辑都在该线程内处理。但是这些逻辑在线程内不是阻塞式串行处理的,而是以I/O为界限,轮流处理多条连接I/O事件。
例如从Client端读取一个L7的数据包,则该包的过滤、解码、编码工作都是串行阻塞处理的,直到这个包需要通过下一个I/O事件发出去,线程才将该I/O事件加入libevent处理队列中,由libevent调度到下一个I/O事件。这样做的好处是将I/O事件剥离出来,防止由于某个I/O事件的堵塞导致线程阻塞。
ListenerManager 中的 Worker 线程数量可以在配置文件中配置,如果在配置文件中没有配置,则默认通过thread:hardware_concurrency获取CPU的内核数量。
在默认情况下,线程数量和CPU内核数量相等。
GuardDog线程
GuardDog 线程处理看门狗的相关业务,代码实现在 Server::GuardDog 类中,这不是主业务,在本书中不做展开。
Envoy的内存管理
Envoy的内存管理分为变量管理和Buffer管理,其中,变量管理针对C++在运行过程中通过new或者make_shared等创造出的类的实例;
Buffer管理指运行时在数据接收、编解码等过程中存储临时数据的Buffer,一般通过malloc分配。
变量管理
Envoy 使用了 C++11 内存管理的新特性,即使用 new、make_shared、make_unique等函数创建实例,其中有的模块是常驻内存的,例如server manager模块、cluster manager模块中的实例,它们在进程启动时就创建了,直到进程销毁才释放;
一些模块是动态创建的,即每条连接都会创建一套完整的实例,在连接终止时释放实例,例如Network、Network filter、L7 filter、L7 protocol、L7 Connection Manager模块中的实例都是动态创建的,其中动态实例不是在连接关闭时实时释放的,而是先加入 deferredDelete,然后 libevent 中的Timer定时检查连接,并通过clearDeferredDeleteList()释放。
当一个新的下游连接建立时,会首先创建 connection 对象;然后在读取数据时创建TransportSocket对象;在数据读取完成后依次创建filter manager和filter chain对象;当有filter匹配到L7时,开始创建L7的connection manager、connection、parse、filter对象,这些对象是在整个连接周期内常驻内存的,直到连接关闭才释放。
Buffer管理
Envoy中所有的Buffer都是通过libevent来管理的,其他Buffer则在各自的模块内管理。例如,HTTP parse 在读取数据之前根据需要读取的数据大小,通过 libevent 的evbuffer_reserve_space函数在libevent中创建I/O的buffer;evbuffer_reserve_space函数的返回值是一个 iovec 结构体,在读取数据时,使用 C++数据读取 readv 函数,直接将数据读取到 iovec结构体中;当数据到达 L7 protocol时,decoder模块在解码数据之后,通过调用evbuffer_drain函数释放该Buffer。
在L7的模块中,有两部分Buffer
- 解码后的Buffer,这部分Buffer是由L7的decoder管理的;
- 数据发出之前 encode之后的 Buffer,这部分 Buffer是直接在libevent中分配的,管理方法和读取数据时相同,在写出时直接将这个Buffer传给writev接口。
Envoy的流量控制
Envoy中的Buffer管理,如果上下游的主机处理速度慢,就有可能出现Buffer的积压。
Envoy中的Buffer统一封装了libevent的Buffer接口,并在Buffer管理上增加了callback和watermark功能,在Buffer中的数据总量超过预设的上水位线时,通过callback 通知数据源终止读写。
当数据量低于下水位线时,通过 callback 回调通知数据源继续开始读写。在一般情况下为了防止数据抖动,将上水位线设置为80%,将下水位线设置为上水位线的 50%,即总 Buffer的 40%。因为这种退避可能是立即终止 Socket读取或逐步停止更新HTTP/2时间窗,因此流量控制是软限制,并不是基于硬件中断的限制。
Envoy 流量控制是以事件为驱动的,例如来自 Server 端的 read 事件触发 Envoy 读取来自Server的数据,并经过一系列的处理将数据存储到Client的Write Buffer中,然后触发write事件,这时函数返回。
libevent在收到write事件时,通过调度线程将Write Buffer中的数据发给Client。因为是异步处理的,所以在遇到Client响应慢时,Write Buffer会非常大。在每次添加数据到Write Buffer时应该先检查上水位线,在没有超过时才可写入,在超出时通过回调函数不响应libevent的read事件。在每次将Write Buffer发给Client端时先检查下水位线,如果低于下水位线,则使能read事件,这样数据又会进入Buffer。
除了对每一条连接请求的Buffer进行限制,Envoy还设置了全局的连接数请求限制,当达到连接数上限时不会再建立新的连接。
Envoy与Istio的配合
部署与交互
Envoy作为转发代理,可以单独在虚拟机上运行,通过YAML配置文件实现代理的功能。
在Istio中Envoy被打包成容器部署在集群中,在 Envoy容器中包含两个执行文件,一个是Envoy本身,一个是Pilotagent,
Envoy的部署模型如图所示
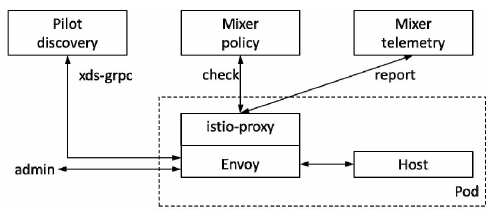
Envoy被部署在proxyv2容器中,以Sidecar的模式和应用容器部署在同一个Pod中,在Pod内通过iptables转发流量。Envoy的执行文件被保存在容器中的/usr/local/bin目录下,由两部分组成:一部分是Envoy的代码;另一部分是istio-proxy项目的代码,用于mixerclient和mixer之间的交互,是Envoy和Mixer之间的桥梁。
Pilot通过在Envoy启动文件中配置的Pilot的地址和端口,向Envoy动态下发xDS的gRPC配置。
Envoy把后端Host的服务发现也会上报给Pilot的discovery容器。Envoy的配置分为两部分:一部分是启动时的bootstrap参数,通过启动时的--config-path参数加载启动配置文件,在 Envoy 运行的容器中的/etc/istio/proxy/目录下;另一部分就是通过Pilot动态下发的xDS配置。
Envoy API
在 Istio 中,Envoy 开放了 admin 端口作为查询的 API,通过在容器内运行 curl 127.0.0.1:15000/help
命令可以查询到相关的路由PATH。
- /certs:包括证书地址、序列号和有效期。
- /clusters:包括所有服务发现的 Cluster 的地址、端口及连接信息(请求统计、最大连接数、最大重连数、是否有金丝雀发布等)。
- /cpuprofiler:通过curl-X POST打开和关闭cpuprofiler。
- /healthcheck/fail&/healthcheck/ok:通过curl-X POST获取健康检查情况。
- /hot_restart_version:查看热重启版本。
- /listeners:显示Envoy中所有Listener的地址。
- /logging:通过curl-X POST修改日志的级别。
- /runtime&/runtime_modify:通过curl-X POST查看和修改运行时。
- /server_info:显示Envoy的版本信息。
- /stats&/stats/Prometheus:打印Envoy中的各类数据统计信息。
- /config_dump:Envoy中的所有配置信息,包括启动时的bootstrap及Pilot通过xDS下发的listener、cluster和route配置。
- /quitquitquit:退出Envoy的API。
Envoy源码解析
1 |
|
从代码实现的角度,讲解 Envoy 从初始化、启动到接收客户端 downstream 的请求,并将请求发送到upstream服务端的过程。
Envoy的初始化
Envoy 的初始化入口在 main_common.cc 文件中,通过 MainCommon()调用base_(options_)进入MainCommonBase(OptionsImpl&options)。
这里首先对libevent进行初始化,然后调用Server::InstanceImpl初始化Server:

Server的初始化在server.cc中通过initialize函数来实现:
启动参数bootstrap的初始化
启动参数的初始化是通过InstanceUtil::loadBootstrapConfig(bootstrap_, options)函数实现的, Envoy在启动时用–config-path来选定启动配置文件, 这里会判断configPath()是否为空,若不为空,则调用loadFromFile()加载配置文件:
1 | void InstanceUtil::loadBootstrapConfig(envoy::config::bootstrap::v3::Bootstrap& bootstrap, |
在fileReadtoEnd中通过file.rdbuf()函数返回文件的后缀类型,因为我们用的配置是JSON格式的,所以这里通过loadFromJson()中的JsonStringToMessage()来解析文件中的每一行配置
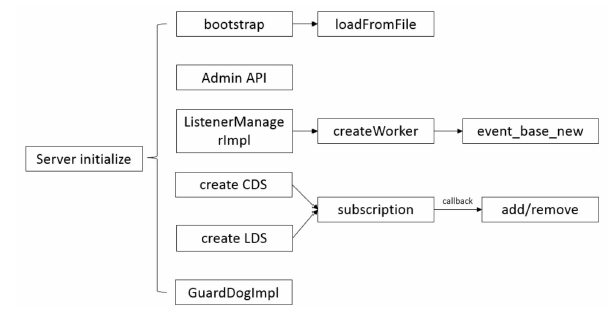
Admin API的初始化
Admin的配置在 bootstrap文件中进行,会配置访问日志的 path及 admin的访问地址等,通过admin_.reset(new AdminImpl(…)来重置加载配置文件中的 admin 字段,这是通过 admin.cc 文件中的AdminImpl:AdminImpl()函数实现的。
这里通过一个结构体的 list (handlers_)来管理admin的prefix,该结构体的定义如下:
1 | struct UrlHandler { |
该list中每一条信息的形式如下
Worker的初始化
初始化Server时的一个重要环节就是初始化Worker,它的入口函数如下
1 | listener_manager_ = std::make_unique<ListenerManagerImpl>(*this, *this, *this, false, quic_stat_names_); |
实现在listener_manager_impl.cc文件中,通过worker_factory来创建新的worker
1 | ListenerManagerImpl::ListenerManagerImpl(Instance& server, |
在worker_impl.cc中通过ProdWorkerFactory:createWorker()创建worker实例:
1 | WorkerPtr ProdWorkerFactory::createWorker(uint32_t index, OverloadManager& overload_manager, |
调用Impl::allocateDispatcher(),进而调用DispatcherImpl函数:
1 | Event::DispatcherPtr Impl::allocateDispatcher(const std::string& name, |
在这个函数中会新创建event_base_new()来处理libevent事件。
CDS的初始化
Cluster服务发现的初始化在MainImpl::initialize中实现
1 |
|
Main_config的initialize在configuration_impl.cc中实现
1 | void MainImpl::initialize(const envoy::config::bootstrap::v3::Bootstrap& bootstrap, |
clusterManagerFromProto 的父类是 ProdClusterManagerFactory,它的返回值是ClusterManagerImpl():
1 | ClusterManagerPtr ProdClusterManagerFactory::clusterManagerFromProto( |
在 ClusterManagerImpl 中,如果在我们的启动文件中配置了 CDS 的配置,那么这里会通过create()函数创建CDS:
1 | cds_api_ = factory_.createCds(dyn_resources.cds_config(), cds_resources_locator.get(), *this); |
createCds的返回值是
1 | CdsApiPtr |
create()函数的返回值是:
1 | CdsApiPtr CdsApiImpl::create(const envoy::config::core::v3::ConfigSource& cds_config, |
创建CDS是通过CdsApiImpl::CdsApiImpl()实现的,这里会注册subscription,每当有事件更新时都通过SubscriptionCallbacks注册回调,执行CdsApiImpl::onConfigUpdate(),通过ClusterManager实现addOrUpdateCluster()或removeCluster(),并且在Envoy的日志中打印cds:add/updatecluster'{…}'或cds:remove cluster'{…}'。
LDS的初始化
LDS的初始化和CDS相似,这一步发生在CDS初始化之后,首先加载启动文件里的LDS配置,调用父类ListenerManagerImpl创建Lds
1 | listener_manager_->createLdsApi(bootstrap_.dynamic_resources().lds_config(), lds_resources_locator.get()); |
在ProdListenerComponentFactory类下创建新的LdsApiImpl
1 | LdsApiPtr createLdsApi(const envoy::config::core::v3::ConfigSource& lds_config, |
在 LdsApiImpl 中注册 subscription,当有事件到来时通过 SubscriptionCallbacks 回调,用LdsApiImpl::onConfigUpdate实现ListenerManager的addOrUpdateListener()或removeListener(),打印日志lds:add/update listener'{…}'或lds:remove listener'{…}'。
TCP Proxy
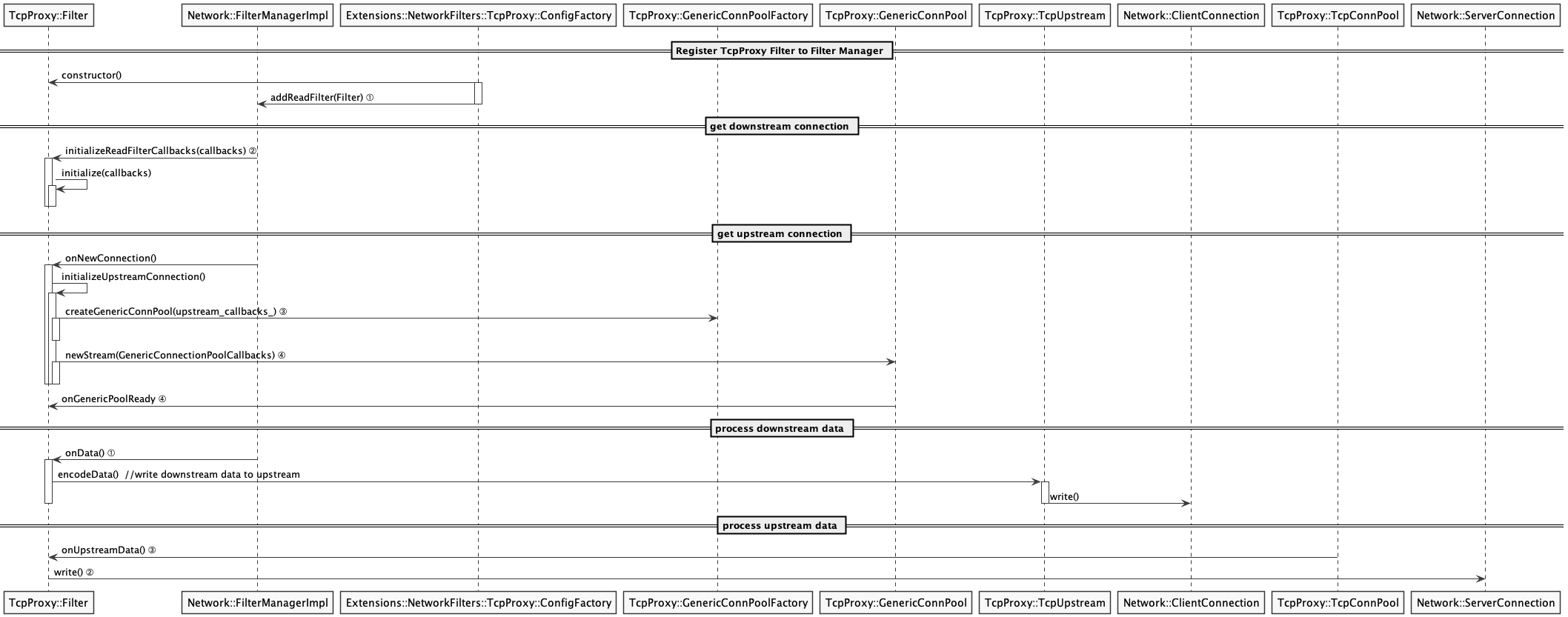
Dubbo Proxy

Envoy的运行和建立新连接
它的入口在MainCommonBase::run()中,在这里Envoy作为Server,执行启动Server的操作
1 | server_->run(); |
图简要梳理了Envoy建立连接的主要流程
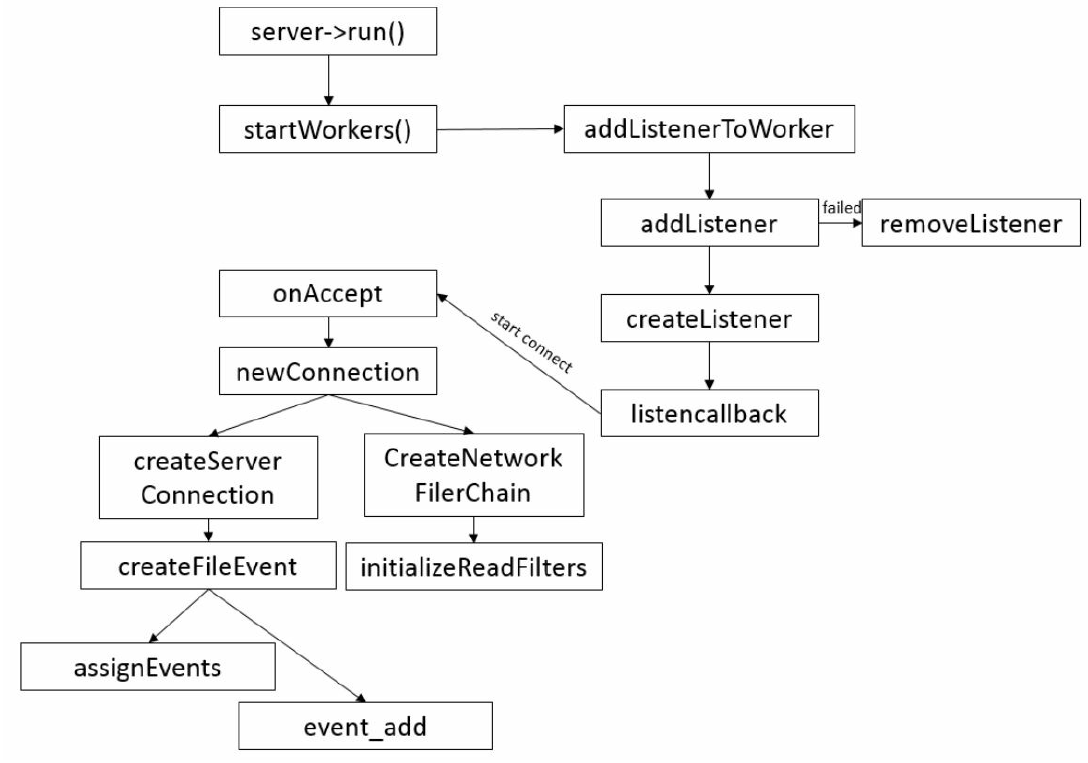
启动worker
在Server中会调用RunHelper来启动InstanceImpl::startWorkers()
1 | const auto run_helper = RunHelper(*this, options_, *dispatcher_, clusterManager(), |
Worker 启动的入口在 ListenerManagerImp 类中,在最外面一层先遍历所有 worker,再将所有 active的 listener 都放到 active_listeners_这个列表中,然后用 for 循环依次执行addListenerToWorker(*worker,*listener),将listener绑到worker上。
addListenerToWorker()会调用WorkerImpl::addListener(),用dispatcher的post方法来给worker添加listener
1 | void ListenerManagerImpl::addListenerToWorker(Worker& worker, |
Listener的加载
Woker的addListener是通过ConnectionHandlerImpl的addListener()实现的,这里会创建新的ActiveListenerDetails
1 | void ConnectionHandlerImpl::addListener(absl::optional<uint64_t> overridden_listener, |
调用parent.dispatcher_.createListener(),它的实现在DispatcherImpl这个类中,会创建新的ListenerImpl(),这里的listener是network的listener
1 |
|
用 libevent 中的 evconnlistener_new 来注册监听 socket 的 fd 的新连接,通过listenerCallback回调:
1 | TcpListenerImpl::TcpListenerImpl(Event::DispatcherImpl& dispatcher, Random::RandomGenerator& random, |
在ListenerImpl::listenCallback中调用onAccept:
1 | protected: |
接收连接
在ActiveListener::onAccept()中会通过createListenerFilterChain()创建listener过滤器的filterChain然后通过continueFilterChain()运行过滤器。
1 | void ActiveTcpListener::onAccept(Network::ConnectionSocketPtr&& socket) { |
这里有两部操作
- createServerConnection()建立请求端和Envoy Server的连接,返回ConnectionImpl,在这里设置buffer的高低水位来进行流量控制,并且创建FileEvent:
在创建FileEvent之后会创建新的FileEventImpl(),然后通过assignEvents()分配事件,再通过event_add()注册事件。
1 | void ActiveTcpSocket::continueFilterChain(bool success) { |
- createNetworkFilterChain()用于建立Network的FilterChain,通过FilterFactory的回调来执行函数 buildFilterChain(),返回 filter_manager 的 initializeReadFilters(),初始化ReadFilter。
如果这里Network的filter_chain为空,则会关闭连接:
在完成上述两步之后,通过onNewConnection()函数给ActiveConnection的相关统计计数增加1。
已经讲解了如何建立新连接,现在回到本节开头的入口server_->run()之处,在运行worker之后进行如下两步操作。
- 启动守护进程看门狗,防止死锁:
运行dispatcher调度器:
1
dispatcher_->run(Event::Dispatcher::RunType::Block);
dispatcher调度器在运行之后会调用libevent的event_base_loop进行监听:当有新的事件到来时触发回调进入处理流程。
1
event_base_loop(libevent_.get(), flag);
Envoy对数据的读取、接收及处理
上面介绍了 Envoy 通过 event_base_loop 监听,downstream 数据在通过 Socket 到达 Envoy 时,首先会被加入 libevent 的 event_process_active 中,通过一个队列event_process_active_single_queue 进行处理。
libevent 通过 assignEvents()来分发事件,在事件分发之后进入ConnectionImpl中,完成onFileEvent()函数。当读和写都就绪时,返回onWriteReady()和onReadReady()。
注意在这里读和写不能同时运行。在写事件发生时,fd会返回-1,这样就不会进入onReadReady()的分支了。
Envoy接收及处理数据的流程如图所示
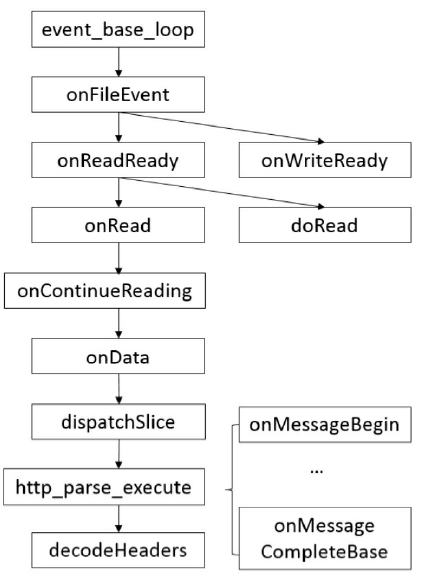
读取数据
connection_impl.cc
1 | void ConnectionImpl::onFileEvent(uint32_t events) { |
现在,进入onReadReady(),通过doRead()从Socket中读取数据,每次读取16KB大小的downstream报文并放入Buffer中
1 | void ConnectionImpl::onReadReady() { |
当读取的数据不为0或读取完成时进入onRead(read_buffer_size)。在完成读取且Buffer不为空时,通过FilterManagerImpl::onRead()判断是否有upstream的filter,当filter不为空时,会执行函数onContinueReading()。
接收数据
在函数onContinueReading()中,首先会遍历一遍所有的upstream_filters_,并在判断它们的onNewConnection()的状态不为StopIteration时,让Filter开始onData(),请求的数据被会转到
ConnectionManagerImpl::onData(),通过 codec_->dispatch(data)在 ConnectionImpl::dispatch中进行处理(这里会区分 HTTP1 和 HTTP2),将 Buffer 中的切片 slice 通过循环交由ConnectionImpl::dispatchSlice()处理
1 | void FilterManagerImpl::onContinueReading(ActiveReadFilter* filter, |
处理数据
在调用parser_->execute时,会设置的回调会执行如下代码:
1 | settings_ = { |
这里有两种类型的回调:
- 不包含数据,只包含 http_parser*parser 状态,包括 onMessageBeginBase、onHeadersCompleteBase和onMessageCompleteBase;
- 包含状态http_parserparser和数据const charat、size_t length,包括onUrl、onHeaderField、onBody和onHeaderValue。
报文会按照 url、header、body 的顺序依次解析之后到达 onMessageCompleteBase()。当message处理完成时返回onMessageComplete()。
onMessageComplete()所属的类是 ServerConnectionImpl,这里会通过 decodeHeaders解码请求的头文件:
1 | active_request.request_decoder_->decodeHeaders(std::move(absl::get<RequestHeaderMapPtr>(headers_or_trailers_)), true) |
通过decodeHeaders解码headermap
1 | void ConnectionManagerImpl::ActiveStream::decodeHeaders(RequestHeaderMapPtr&& headers,bool end_stream); |
Envoy发送数据到服务端
在ActiveStream::decodeHeaders中会遍历所有活跃的stream的DecoderFilter。
这里的主线有两部分,一部分是调用istio-proxy中的Mixer::Filter::decodeHeaders,继而向Mixer发起远程check请求;另一部分是在Router::Filter::decodeHeaders中匹配路由。
1 | void ConnectionManagerImpl::ActiveStream::decodeHeaders(RequestHeaderMapPtr&& headers, |
Envoy发送请求到服务端的流程
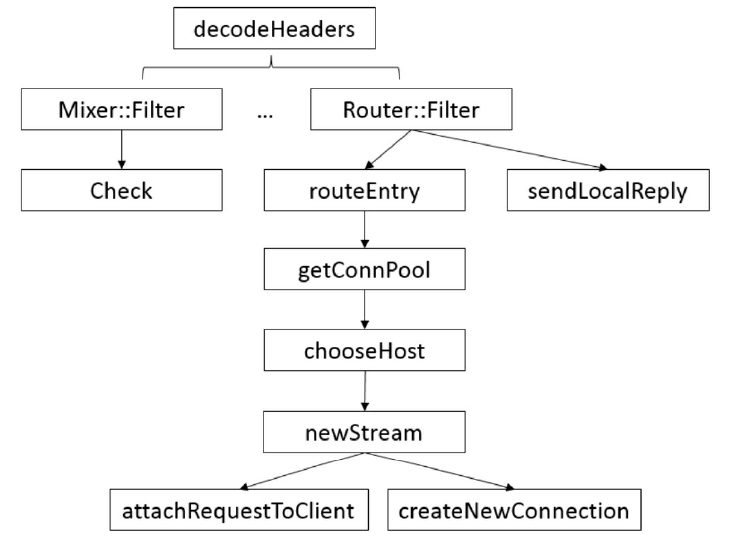
匹配路由
Client端的请求会被区分为如下两种。
1 | Http::FilterHeadersStatus Filter::decodeHeaders(Http::RequestHeaderMap& headers, bool end_stream) { |
- 由Envoy直接direct response:
在这种场景下会通过回调发送本地回复,调用sendLocalReply()函数将direct_response的报文Header中的路径重写,并且终止FilterHeader的遍历。
- 找到匹配的route entry:
在查找route entry时通过route_entry_->clusterName()来查找cluster的名称。
upstream的 cluster 名称也是服务端的名称,会在函数 ClusterManagerImpl::get()中进行查找,调用find方法返回entry->second.get():
获取连接池
在查找到route entry之后通过getConnPool获取upstream cluster的连接池
1 | ```c++ |
选择上游主机
在httpConnPoolForCluster()中通过route entry选择connPool通过loadbalance选择后端的Host:
chooseHost在EdfLoadBalancerBase::chooseHost()中实现,如果在virtualservice中设置了后端流量到不同cluster的weight比重,则会根据scheduler.edf_.pick()选择返回的Host;
如果没有设置cluster的weight比重,则会根据unweightedHostPick()选择active request计数少的Host作为服务端,并建立upstream连接:
这里,UptreamRequest会对Host做健康检查:
encodeHeaders会建立一条新的stream:
如果有ready的Client,则会复用连接否则新建连接
Pilot
架构
Istio的服务模型
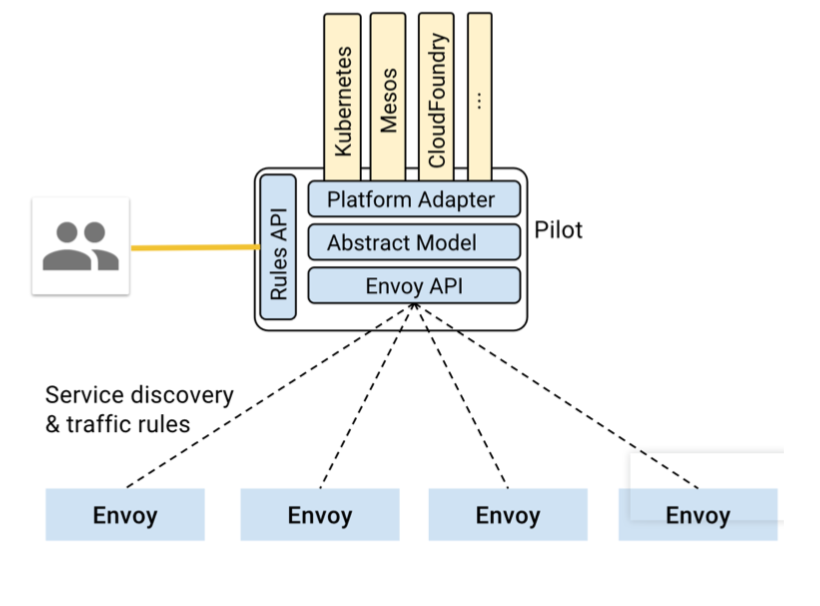
其中新版的Pilot只能搜集Kubernetes的注册中心
Istio通用的服务模型包含Service(服务)和ServiceInstance(服务实例)。
Service
每个服务都有一个完全限定的域名(FQDN)及用于监听连接的一个或多个端口。可选地,服务可以具有与其相关联的单个负载均衡器或虚拟IP地址,使得针对FQDN的DNS查询被解析为虚拟IP地址(负载均衡器IP)。
例如在Kubernetes平台上,一个服务forecast的FQDN可能是forecast.weather.svc.cluster.local,拥有虚拟IP地址10.0.1.1并监听在3002端口
属性如下
- Hostname:服务域名,为FQDN(全限定域名),在Kubernetes环境下,服务的域名形式是<name>.<namespace>.svc.cluster.local。
- Address:服务的虚拟 IP 地址,主要为 HTTP 服务生成 HTTP 路由的虚拟主机Domains。Envoy代理会根据路由中虚拟主机的域名转发请求。
- ClusterVIPs:服务于Kubernetes多集群服务网格,表示集群ID与虚拟IP的关系。Pilot在为 Envoy代理构建 Listener和 Route时,会根据代理所在的集群选用对应集群的虚拟IP。
- ServiceAccounts:是服务的身份标识,遵循SPIFFE规范。例如,在Kubernetes环境下,身份信息的
格式为“spiffe://<domain>/ns/<namespace>/sa/<serviceaccount>”,这使Istio服务能够建立和接收与其他SPIFFE兼容系统的连接。 - Resolution:指示代理如何解析服务实例的地址,在大多数网格内的服务之间访问时使用ClientSideLB,Envoy 会根据负载均衡算法从本地负载均衡池中选择一个Endpoint地址进行转发。还有DNSLB和Passthrough两种解析策略可选,一般用于访问服务网格外部的服务或者Kubernetes Headless(无头)服务。
- Attributes:定义服务的额外属性,主要用于 Mixer 遥测。特别要注意,在属性中还有一个ExportTo字段,用于定义服务的可见范围,表示本服务可被同一命名空间或者集群中的所有工作负载访问。
可见,Istio Service模型完全不同于底层平台服务模型,例如Kubernetes Service API。Istio服务模型记录了Istio生成xDS配置所需要的属性,这些关键属性由Kubernetes Service转换而来。这种抽象的与底层无关的服务模型,在很大程度上解耦了Pilot xDS Server模块与底层平台适配器,并具有很强的可扩展性。
ServiceInstance
ServiceInstance 表示特定版本的服务实例,记录服务与其实例 NetworkEndpoint 的关联关系,定义与服务相关联的标签(版本等信息)。每个服务都有一个或者多个实例,服务实例是服务的实际表现形式,类似于Kubernetes中Service与Endpoint的概念。
服务实例的属性及其作用如下。
- Service:关联的服务,用于维护服务实例与服务的关系。
- Labels:服务实例的标签,可用于路由选择,例如,可以限制只有标签为 app:v1的服务实例才可以访问某个服务。
- ServiceAccount:服务实例的身份信息,与 Service.ServiceAccounts 属性类似,主要用于Istio双向TLS认证。
- Endpoint:NetworkEndpoint 类型,定义了服务实例的网络地址、位置信息、负载均衡权重及所在的网络ID等元数据。
NetworkEndpoint模型的主要属性及其含义如表所示。
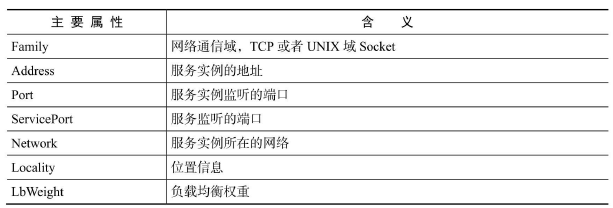
接下来,结合实际的Kubernetes环境解释NetworkEndpoint的主要属性。
- Address:服务实例监听的IP地址,即Pod的IP地址。
- Port:服务实例监听的端口号,实际上等同于服务进程监听的端口号。
- ServicePort:服务端口号,等同于 Service的虚拟 IP或者负载均衡 IP所匹配的服务端口。
- Network:网络标识,支持多网络的服务网格内路由转发。
- Locality:Pod所在的区域、可用域等位置信息,用于基于位置的负载均衡策略。
- LbWeight:负载均衡权重,目前主要用于服务网格外部服务(ServiceEntry定义)的访问权重设置。
NetworkEndpoint模型与在 Istio 1.1中新定义的 IstioEndpoint模型很相似,这给开发者带来很大的阅读挑战和开发负担,Istio社区计划在将来的版本中使用IstioEndpoint代替NetworkEndpoint。
xDS协议
一次完整的xDS流程包含三个步骤:请求、响应、ACK或者NACK,如图所示。
- (1)Envoy主动向Pilot发起DiscoveryRequest类型的请求。
- (2)Pilot根据请求生成相应的DiscoveryResponse类型的响应。
- (3)Envoy 接收 DiscoveryResponse,然后动态加载配置,在配置加载成功后进行ACK,否则进行NACK,ACK或者NACK消息也是以DiscoveryRequest的形式传输的。
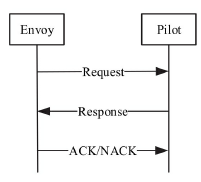
DiscoveryRequest配置的主要属性及其含义如表所示。
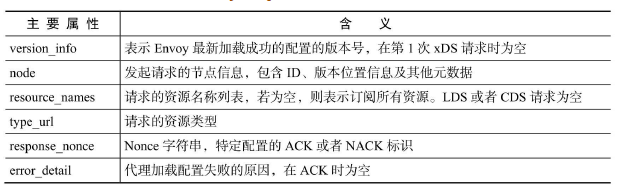
DiscoveryResponse配置的主要属性及其含义如表所示。

ADS的演进
ADS(Aggregated Discovery Service)是在Istio 0.8以后的版本中出现的一种聚合发现服务。ADS基于gRPC协议的同一个流,避免了 CDS、EDS、LDS、RDS更新分别指向不同的Pilot服务端的可能。之所以引入ADS,主要是因为基于REST协议的xDS有以下问题。
- xDS 是一种最终一致性协议,在配置更新的过程中流量容易丢失。
例如,通过CDS或者EDS获得了Cluster X,一条指向Cluster X的RouteConfiguration刚好被更新为指向Cluster Y,但是在CDS、EDS还没来得及分发Cluster Y的配置的情况下,路由到Cluster Y的流量会被全部丢弃,并且返回给客户端“503”状态码。 - 在某些场景下,流量的丢失是不可接受的。
值得庆幸的是,遵循make-before-break的原则,通过调整配置更新的顺序完全可以避免流量的丢失。- CDS的更新必须先进行,请求资源的名称为空。
- EDS 的更新必须在 CDS 的更新之后进行,并且 EDS 的更新需要指定 CDS 获取的相关集群名称。
- LDS的更新必须在CDS或EDS的更新之后进行,请求资源的名称为空。
- RDS 的更新与 LDS 新加的监听器有关,在请求过程中必须指定新的监听器的路由名称,因此RDS的更新必须在LDS的更新之后进行。
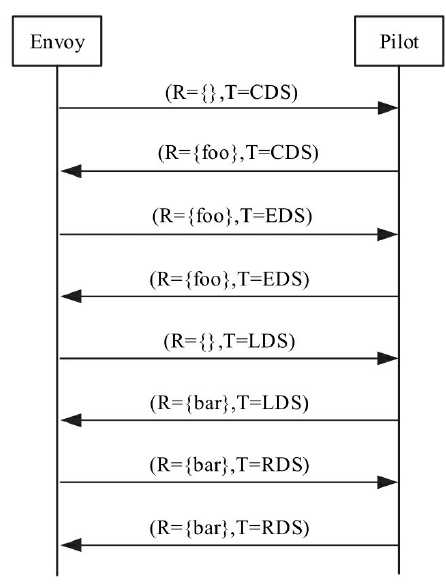
工作流程
Pilot 组件作为 Istio 控制面的核心,主要职责是获取注册中心的配置规则或者服务,服务于所有的Envoy。
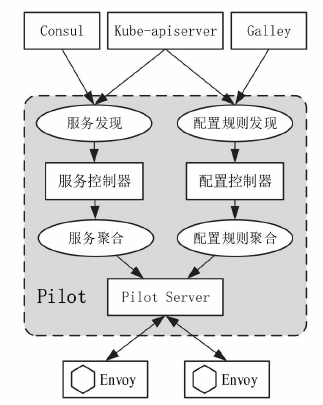
如图所示,Pilot 主要包含服务发现、配置规则发现及服务器三大模块。
服务发现及配置规则发现用于从底层注册中心发现原始资源,并且服务于Pilot服务器,提供xDS配置源。
Pilot服务器处理Envoy实例的连接请求,服务于xDS配置的生成与分发。
Pilot的启动与初始化
Pilot的启动
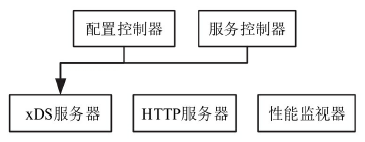
Pilot是通过pilot-discovery进程启动的,如图所示,主要包括配置控制器、服务控制器、xDS服务器、HTTP服务器和性能监视器等模块。其中:
- xDS服务器用于处理Envoy代理的xDS请求,以及控制相关配置的生成及下发;
- 配置控制器主要用于监视底层注册中心及更新配置规则,并通知 xDS 服务器异步更新xDS配置;
- 服务控制器主要用于监视底层注册中心、更新服务及服务实例,并通知 xDS 服务器异步更新xDS配置;
- HTTP服务器主要提供REST接口供管理员获取Debug信息;
- 性能监视器主要提供性能分析的接口,可通过此接口获取进程运行时内存、CPU占用等。
Pilot的启动流程如图所示,需要执行以下步骤:
- 命令行参数解析,解析所需的配置文件、服务器地址等日志系统配置;
- 初始化 Kubernetes 客户端。在 Kubernetes 集群中,底层服务发现需要监视Kube-apiserver,所以这里需要创建Kubernetes客户端;
- 加载服务网格配置,主要是网格中所有的Envoy实例共享的一些全局配置,包括Mixer服务器地址、连接管理相关的设置及访问日志格式等;
- 加载服务网格网络配置,支持同一网格多网络之间的服务直接访问,例如Kubernetes多集群的场景;
- 初始化Config Controller(配置控制器)、Pilot核心模块,监视底层注册中心的配置规则,并异步通知xDS服务器;
- 初始化 Service Controller(服务控制器)、Pilot 核心模块,监视底层注册中心服务及服务实例,并异步通知xDS服务器;
- 初始化Pilot服务器,主要涉及xDS Server、HTTP服务器,处理所有xDS连接,生成xDS配置并下发;
- 初始化多集群服务发现,适用于多个Kubernetes集群共用同一套控制面的场景;
- 启动所有Pilot Server及控制器,开始监听底层平台及处理下游xDS请求。
Pilot Server的初始化
Pilot Server作为xDS的服务端,实现了各种发现服务功能,对外提供HTTP、非安全的gRPC接口和安全的gRPC接口。
如图所示,Pilot Server主要包含gRPC服务器及HTTP服务器两部分:HTTP服务器提供了一种方便剖析 Pilot运行时状态的 REST API,包含性能分析数据及 Debug 信息查询;安全及非安全的gRPC 服务器均实现了 xDS 协议的服务端,提供ADS接口API。
Pilot Server的初始化流程如下所述,如图所示。
- 创建DiscoveryService,DiscoveryService是一个HTTP请求多路复用器,并注册性能分析处理器。
- 创建EnvoyXdsServer,实现了Envoy服务发现ADS接口,用于处理xDS请求,生成配置并进行分发。EnvoyXdsServer 是 Pilot 最核心的功能模块,主要功能包括维护Envoy代理的连接、处理异步的事件通知、生成xDS配置等。
- 向 HTTP多路复用器注册 Debug处理器,提供 Pilot运行时配置查询及分发状态查询。
- 初始化非安全gRPC服务器,并向其注册xDS API处理函数(由EnvoyXdsServer提供)。
- 初始化安全 gRPC 服务器,并向其注册 xDS API 处理函数(由 EnvoyXdsServer提供)。
- 分别注册三种服务器的启动回调,在Pilot启动的最后环节统一启动。
服务发现
Pilot 服务发现指 Istio 服务、服务实例、服务端口及服务身份信息的发现,目前通过两种不同的平台适配器支持Kubernetes和Consul两种服务注册中心。在Adapter之上,Pilot通过抽象聚合层提供统一的接口,使EnvoyXdsServer无须感知底层平台的差异。
服务发现模型
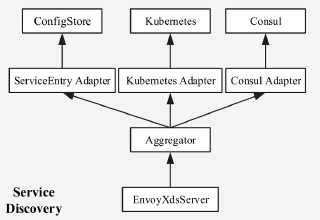
服务聚合
在Istio服务模型中,除了有网格内的服务,还有网格外的服务。Istio通过ServiceEntry定义网格外的服务。
在Kubernetes环境下,ServiceEntry与其他配置规则一样也是通过CRD定义的,因此ServiceEntry服务发现是基于ConfigStore实现的。
也就是说基于ServiceEntry的服务发现是一种两级发现服务
- 第1级是Config Controller通过ConfigStore实现的配置发现
- 第2级是Service Controller通过ServiceEntry适配器实现的服务发现。
服务聚合器 Aggregator 是 Pilot 对所有 Adapter 的抽象封装,它通过注册接口提供Adapter的注册,通过ServiceDiscovery接口实现服务、服务实例及服务端口的检索功能

服务发现的异步通知机制
异步通知的实现依赖于回调函数,当有更新事件(增加、删除、更新)产生时,系统在捕获到事件的同时执行回调函数。
如果事件回调函数的执行周期较长并且事件更新频率较高,则为了保证事件接收不会阻塞,一般会先进行上半部处理,将事件发送到队列,然后通过下半部(事件消费者)处理

Pilot 服务发现的异步通知机制也是基于此通用模型实现的。通过 Controller 接口,Aggregator控制器对上层EnvoyXdsServer提供了服务事件处理的注册方式

异步通知的实现原理
EnvoyXdsServer 在初始化时会通过 AppendServiceHandler 及AppendInstanceHandler分别向Aggregator注册服务、服务实例的更新事件处理回调函数。Aggregator 实际上是分别调用各 Adapter的回调注册接口,然后将回调函数注册到各个Adapter上。
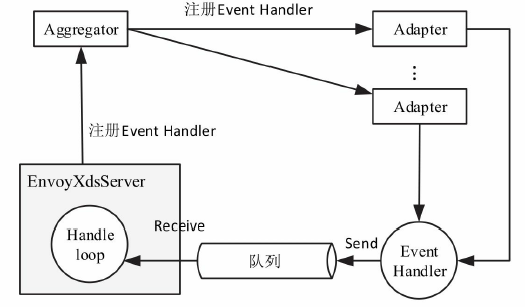
各平台的Adapter基于底层注册中心提供的资源监视方式来监控资源的变化。例如,Kubernetes平台提供了资源的监听API,Adapter通过Kubernetes Informer监听Service及Endpoint 资源的变化。资源的变化会异步触发事件处理回调函数的执行。这里,EnvoyXdsServer 注册的事件处理回调函数是 clearCache,clearCache 会将事件更新通知发送到队列中,由 EnvoyXdsServer 启动单独的协程在队列的另一端接收通知,并执行下半部处理(分发配置)。
Kubernetes Adapter
在Kubernetes中,资源对象Service表示服务,Endpoint表示服务实例。除此之外,还需要通过Pod、Node获取Envoy代理的标签及可用域等信息。
因此,Kubernetes Adapter通过SharedInformerFactory创建4种类型的SharedInformer,并通过AddEventHandler接口注册ResourceEventHandler资源事件处理函数。
这里的ResourceEventHandler不完全等同于EnvoyXdsServer注册的回调函数
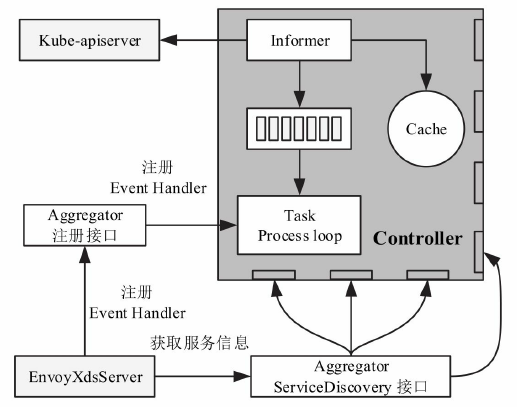
前面提到了任务队列,这里的队列不同于常见的队列模型,在任务队列中不仅存储消息通知,还存储任务处理Handler。
这种方式的好处是释放了任务队列处理Loop,对于不同类型的消息通知,可以做到完全透明。
EnvoyXdsServer 可以通过注册接口AppendServiceHandler与AppendInstanceHandler注册Kubernetes事件处理回调函数。
目前Service类型的资源事件处理Handler的功能包括:EnvoyXdsServer注册的Event Handler(clearCache)执行及Controller缓存状态的维护。
Endpoint资源任务处理Handler没有利用clearCache,而只更新EDS,这是Istio在1.0版本之后对xDS的优化(增量EDS特性)。
当Endpoint更新时,只更新受影响的服务的EDS,生成增量的EDS配置,并将其下发到Envoy,避免了冗余的LDS、RDS、CDS配置下发
配置规则发现
Pilot配置规则指网络路由规则、Mixer配置规则及网络安全规则,包含VirtualService、DestinationRule、Gateway、ServiceEntry 等。
目前 Pilot 支持对接三种不同的注册中心:Kubernetes、MCP服务器和文件系统。
Pilot配置控制器分别实现了三种平台适配器,在平台适配器之上,控制器实现了一个抽象的接口封装,通过此接口对xDS服务器提供配置规则的查询。
为了实现不同的适配器聚合,在Pilot 中,这三种平台适配器都实现了同一个接口:ConfigStoreCache
ConfigStoreCache基于ConfigStore实现异步的事件通知机制:主动同步本地状态与远端存储,并提供接收更新事件通知及处理的能力。
并且事件处理Handler必须在控制器运行前注册。ConfigStoreCache借鉴了Kubernetes Informer的设计思想
其中ConfigStore接口描述了一组平台无关的API,底层平台必须支持这些API来存储和检索Istio配置:

Pilot的配置发现模型
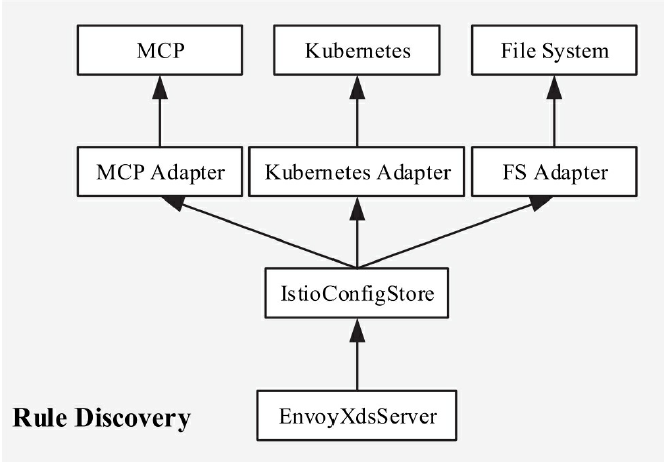
本地文件系统适配器
本地文件系统适配器的基本工作原理是通过监视器周期性地读取本地配置文件,将配置规则缓存在内存中,并维护配置的增加、更新、删除事件,当缓存有变化时,异步通知执行事件回调
- 创建一个缓冲区 Store,用于存储所有配置,同时,为了保证配置的合法性,必须提供相关配置的校验功能。所以,Store结构由map及validator组成,并实现ConfigStore接口,提供增删改查功能。
- 创建 Monitor 文件系统监视器。Monitor 周期性地检查配置文件,并根据配置的变化更新 Store。这里,Monitor采用轮询方式检查并读取配置,与本地缓存原来的配置进行比较,以此判断配置更新与否。这种方式比较浪费CPU、I/O资源,可利用Inotify异步获取文件系统的通知事件,减少文件读取及配置的对比次数,同时能减小配置更新的时延。
- 更新Store,并且发送更新事件到事件队列。
- 事件处理器从事件队列中接收事件,并调用事件处理回调函数进行处理。
Kubernetes适配器
基于Kubernetes的Config发现利用了Kubernetes Informer的监听能力。在Kubernetes集群中,Config以CustomResource的形式存在。Pilot通过配置控制器即CRD Controller监听Kube-apiserver配置规则资源,维护所有资源的缓存Store,并触发事件处理回调函数。
CRD Controller实现了ConfigStoreCache接口,对外提供Config的事件处理Handler注册及Config资源检索。
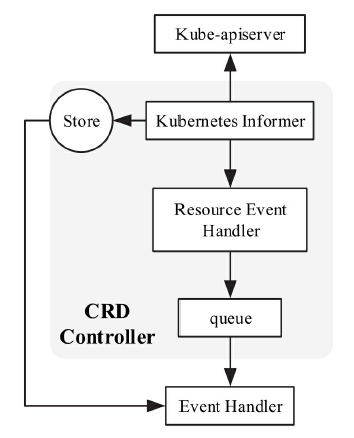
Kubernetes适配器存在两级事件处理Handler:第1级是Kubernetes Informer的资源事件处理函数,由Informer 自身接口注册;第 2 级是 CRD控制器的事件处理,由ConfigStoreCache.RegisterEventHandler方法注册。
两级事件处理通过任务队列相连接,这样设计也是为了避免当 Config 更新速度过快时,相应的事件处理执行过慢导致更新事件阻塞。这样的异步非阻塞模型也是Kubernetes Controller Manager典型的资源处理模型。
配置规则聚合
配置规则 Aggregator 其实是一种 ConfigStore 接口的封装,它提供了一种更为具体的资源检索方式。
在上一节 Pilot 的配置发现模型中,我们已经发现平台适配器提供的ConfigStore只能提供底层的检索方式:需要指定资源的类型,虽然使用起来更为灵活,但是不够方便。
因此Pilot 设计者最初通过IstioConfigStore 提供更为方便的检索方式,支持条件检索

我们可以将配置聚合器更多地看作一种缓存资源检索的抽象封装,并不算真正的聚合,这是因为Pilot 目前并不支持同时配置多种类型的配置注册中心。
配置聚合器是任意类型的平台适配器的抽象,提供面向开发者的更加友好的检索接口,甚至支持条件检索。
Config Aggregator与服务发现聚合器一样,都为EnvoyXdsServer服务,提供xDS配置生成的数据源
配置发现异步通知
配置发现异步通知的实现原理与上一节服务发现异步通知的实现原理基本相同
首先EnvoyXdsServer在初始化时通过配置聚合器的ConfigStoreCache.RegisterEventHandler方法向Config平台适配器注册Event Handler,Event Handler的处理过程实际上就是通知xDS Server本身发起一次全量的xDS配置分发。
然后Config平台适配器在启动后,会监视底层注册中心的Config更新(Add、Delete、Update),当配置资源更新时执行对应的Event Handler。
不同的平台适配器的Event Handler执行方式略有差异,例如:Kubernetes适配器在接收到Config更新时,通过发送事件通知的方式异步地通知执行Event Handler
Envoy的配置分发
Envoy的正常工作离不开正确的配置,Envoy的基本配置包含Listener、Route、Cluster与Endpoint,而路由、认证、授权等配置的动态更新是Service Mesh发展的必然趋势。
Pilot作为服务网格的指挥官,承着动态配置生成及下发的重任。
配置分发的时机
从Pilot的角度来看,存在两种配置分发模式:主动模式和被动模式。
主动模式指Pilot主动将配置下发到Sidecar,由Config与服务更新事件触发。
被动模式指由Pilot接收Sidecar的连接请求(DiscoveryRequest),然后做出响应(DiscoveryResponse)。
主动模式和被动模式的区别在于,主动模式是由底层注册中心的资源更新触发的,被动模式是由外部客户端的Envoy请求触发的。
实际上,被动模式是前提,即Envoy主动发起订阅请求,订阅某些资源,Pilot 在内部维护所有客户端订阅的资源信息;当Pilot 监听到后端注册中心的Config或者服务更新时,会根据客户端订阅的资源主动生成配置信息并下发到Envoy。
在Pilot中配置的分发由EnvoyXdsServer负责
被动模式
在被动模式下,EnvoyXdsServer通过StreamAggregatedResources接收Sidecar的资源订阅请求,其原理为:EnvoyXdsServer 首先接收 gRPC 连接,然后初始化 XdsConnection对象,启动DiscoveryRequest接收线程,后台任务最后循环读取请求队列Channel,如图所示
被动模式下的请求处理模块工作流程
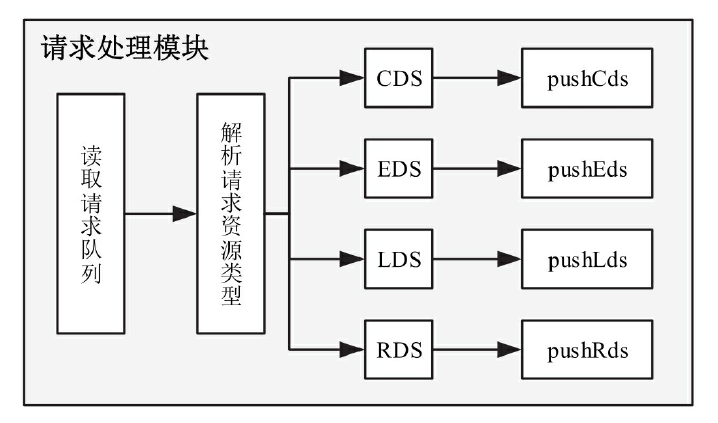
主动模式
在主动模式下,EnvoyXdsServer 通过 StreamAggregatedResources 请求处理模块读取pushChannel中的XdsEvent,然后通过pushConnection向Sidecar下发xDS配置,如图所示。
主动模式与被动模式一样,最终复用相同的push接口(pushCds、pushEds、pushLds、pushRds)。
主动模式下请求处理模块的工作流程
主动模式的xDS分发
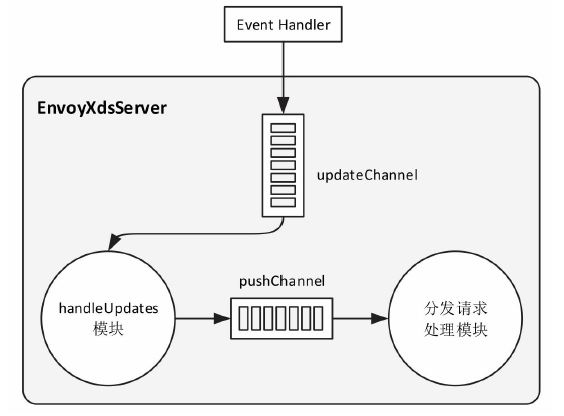
主动模式的xDS分发由底层注册中心的Event Handler异步通知,如图所示。
Event Handler 首先将更新事件发送到 updateChannel 中,然后 EnvoyXdsServer 通过handleUpdates接收更新事件,进行防抖动、更新缓存等处理,并向每个XdsConnection的pushChannel发送XdsEvent通知。
请求处理模块在接收到通知事件后,生成xDS配置并将其发送到xDS客户端。
至此完整的异步配置更新、分发流程结束。为了加速配置分发且提高系统的稳定性,
Listener的生成
顶级 Envoy 配置包含一个 Listener(监听器)列表,每个 Listener 的主要属性及其含义如表
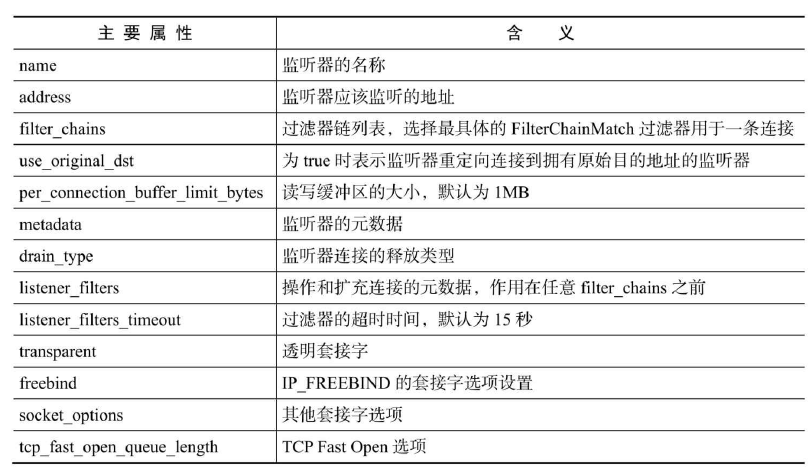
Listener最重要的属性是filter_chains,该属性定义了一组过滤器链,Envoy的工作线程对于每一条连接都会根据匹配标准选择一条过滤器链进行执行,然后选择指定的路由将流量转发出去。
Pilot 针对不同的代理类型分别生成对应的 Listener 配置,然后以 DiscoveryResponse的形式发送到代理。
目前有三种代理类型:sidecar,用于应用容器的Sidecar代理;ingress和router,用于网格边缘的路由转发。
ConfigGenerator(配置生成器)的 BuildListeners 方法负责 Listener 的配置生成。如图所示,不同类型的代理的 Listener 配置生成略有不同:sidecar 类型通过buildSidecarListeners生成包含所有Inbound、Outbound及应用管理端口、代理转发端口的监听器列表;router或ingress类型通过buildGatewayListeners生成所有Gateway资源的监听器列表
Route的生成
Envoy包含一个router过滤器,Istio通过设置它来执行高级路由任务。这对于处理边缘流量(传统反向代理请求处理)及建立从服务到服务的Envoy网格都很有用。
Envoy同时可以作为正向代理使用。
router过滤器实现了HTTP转发,可用于几乎所有部署Envoy的HTTP代理场景。router过滤器的主要职责是遵循在已配置的路由表中指定的指令,除了处理转发和重定向,还处理失败重试、统计等。
HTTP的RouteConfiguration配置的主要属性及其含义如表所示。
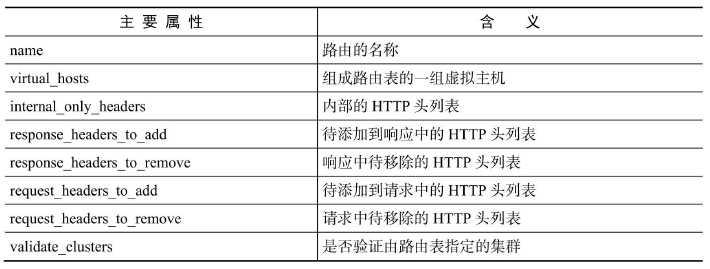
可见virtual_hosts(虚拟主机)是路由配置的核心,每个virtual_hosts都有一个逻辑名称及一组根据请求头 Host 路由到它的域名。
这允许单个监听器为多个顶级域名路径提供服务。
一旦根据域名选中一个virtual_hosts,它的 routes 就会被处理,以决定需要被路由到哪个上游集群及是否需要重定向。
VirtualHost配置的主要属性及其含义如表所示
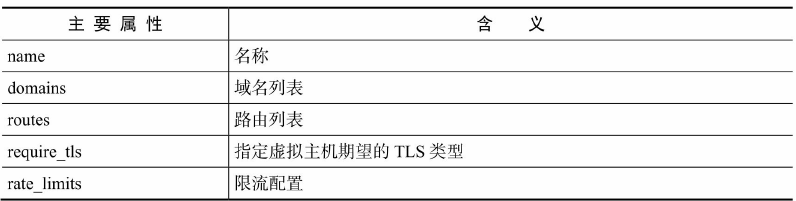
ConfigGenerator的BuildHTTPRoutes方法负责Route的配置生成。
如图所示,对于不同类型的代理,Route的配置生成略有不同:sidecar类型通过buildSidecarOutboundHTTPRouteConfig生成所有outbound端口的路由配置;router、ingress类型通过buildGatewayListeners生成所有Gateway资源的路由配置。
Cluster的生成
Cluster定义了一个上游集群,以及路由到此集群的负载均衡配置、连接管理和熔断等
Cluster配置的主要属性及其含义
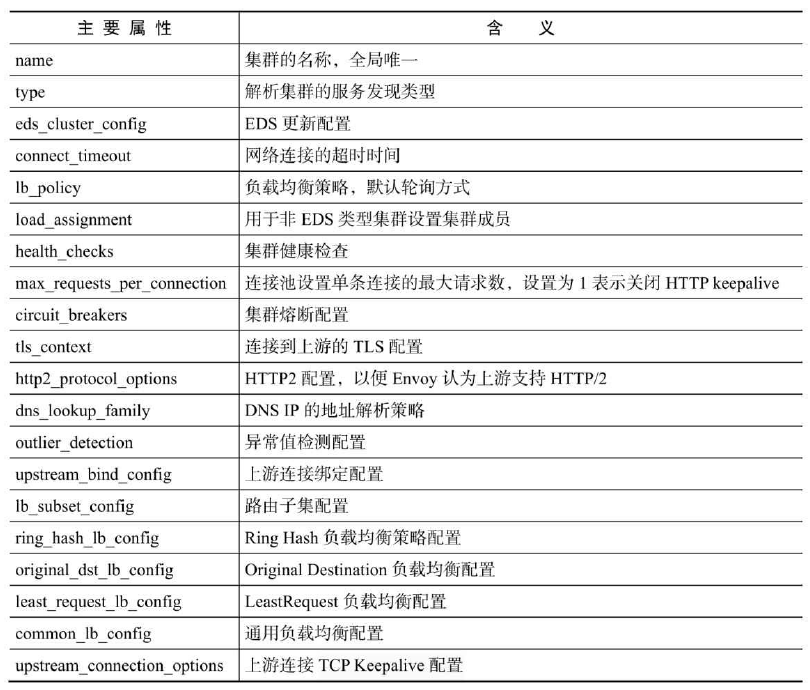
Cluster 的配置生成方式与 Route 的配置生成方式类似,都通过 ConfigGenerator 的BuildClusters方法生成。
但是在Cluster的配置生成中做了缓存优化,将Cluster缓存起来,避免对每个代理进行重复计算,浪费CPU资源。
对于所有代理来说,Outbound Cluster基本相同,所以Pilot利用这一特性进行了缓存优化。
之所以不完全相同,是因为在Istio 1.1中新增的两个特性会导致Outbound Cluster不尽相同:
- Sidecar资源对象允许定义sidecar类型的代理的服务依赖;
- 通过定义Config及服务的有效范围,可以指定Config规则的作用范围及服务的可访问范围(在同一命名空间或者整个网格内)。
Endpoint的生成
在Envoy中,集群中的所有成员都叫作Endpoint,不同于Kubernetes Endpoint,Envoy通过 EDS 动态获取集群的成员配置。
在 xDS 中,Endpoint 的配置 API 是ClusterLoadAssignment,它由具有不同位置属性的负载均衡 Endpoint 组成,将所有的Endpoint都按照位置信息分组,可以方便Envoy支持基于位置信息的负载均衡策略。
ClusterLoadAssignment配置的主要属性及其含义

从负载均衡角度来看,每个集群都是独立的,负载均衡发生在集群内的所有位置的主机(Endpoint)之间或者以更精细的粒度发生在同一位置的主机(LocalityLbEndpoints)之间。
对于一个特定的Endpoint实例来说,某个主机的有效负载均衡权重为它本身的权重乘以它所在位置的负载均衡权重。
ClusterLoadAssignment 与 Cluster 配置的生成有些类似:都使用了缓存,每个ClusterLoadAssignment都对应一个Cluster。
但是ClusterLoadAssignment与Cluster的生成又有些区别:ClusterLoadAssignment的生成发生在EnvoyXdsServer handleUpdates接收更新事件之后,生成push队列XdsEvent事件之前,而Cluster的生成发生在EnvoyXdsServer请求处理模块接收到XdsEvent之后,配置分发之前。
Pilot设计亮点
作为 Istio 数据面的司令官,Pilot 控制中枢系统,它的性能好坏直接影响服务网格的大规模可扩展、配置时延等。
如果 Pilot 的性能低,配置生成效率也低,那么它将难以管理大规模服务网格。
比如服务网格拥有成千上万服务及数十万服务实例,配置生成的效率很低,难以满足服务及Config更新带来的配置更新需要,将会造成Pilot负载很高,用户体验很差。
Istio社区网络工作组很早就已经意识到这个问题,并在近期的版本中相继做了很多优化工作,本节选取具有代表性的4个优化点进行讲解
三级缓存优化
缓存模型是软件系统中最常用的一种性能优化机制,通过缓存一定的资源,减少CPU利用率、网络I/O 等,Pilot 在设计之初就重复利用缓存来降低系统 CPU 及网络开销。
目前在Pilot层面存在三级资源的缓存
以Kubernetes平台为例,所有服务及配置规则的监听都通过Kubernetes Informer实现。
我们知道Informer的LIST-WATCH原理是通过在客户端本地维护资源的缓存实现的。此为Pilot平台适配层的一级缓存。
平台层的资源(Service、Endpoint、VirtualService、DestinationRule 等)都是原始的API模型,对于具体的Sidecar、Gateway配置规则的生成涉及平台层原始资源的选择,以及从原始资源到 Istio资源模型的转换。
如果在xDS配置生成过程中重复执行原始资源的选择与转换,则非常影响性能。因此Istio在中间层做了Istio资源模型的缓存优化。
最上面的一层缓存则是 xDS 配置的缓存。具体来讲,目前在 xDS 层面有两种配置缓存:Cluster与Endpoint,这两种资源较为通用,很少被Envoy代理的设置所影响。因此在xDS层面对Cluster及Endpoint进行缓存,能极大提高Pilot的性能。
随着 Istio 的发展与成熟,越来越多的缓存优化逐渐成型。当然,任何事物都有两面性,缓存技术同样带来了巨大的内存开销,我们同样需要综合权衡利弊。
去抖动分发
随着集群规模的增大,Config及服务、服务实例的数量成倍增长,任何更新都可能会导致Envoy配置规则的改变,如果每一次的更新都引起Pilot重新计算及分发xDS配置,那么可能导致 Pilot 过载及 Envoy的不稳定。
这些都难以支撑大规模服务网格的需求,因此Pilot在内部以牺牲xDS配置的实时性为代价换取了稳定性。
具体的去抖动优化是通过EnvoyXdsServer的handleUpdates模块完成的,其主要根据最小静默时间及最大延迟时间两个参数控制分发事件的发送来实现。
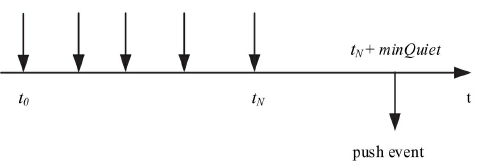
图展示了利用最小静默时间进行去抖动的原理:tN表示在一个推送周期内第N次接收到更新事件的时间,如果从 t0到 tN不断有更新事件发生,并且在tN时刻之后的最小静默时间段内没有更新事件发生,那么根据最小静默时间原理,EnvoyXdsServer 将会在 tN+minQuiet 时刻发送分发事件到pushChannel。
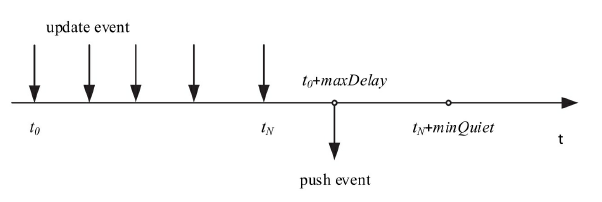
图展示了最大延迟的去抖动原理:在很长的时间段内源源不断地产生更新事件,并且事件的出现频率很高,不能满足最小静默时间的要求,如果单纯依赖最小静默时间机制无法产生 xDS 分发事件,则会导致相当大的延迟,甚至可能影响 Envoy 的正常工作。
根据最大延迟机制,如果当前时刻距离t0时刻超过最大延迟时间,则无论是否满足最小静默时间的要求,EnvoyXdsServer也会分发事件到pushChannel。
增量EDS
我们知道,在集群或者网格中,数量最多、变化最快的必然是服务实例,在Kubernetes平台上,服务实例就是Endpoint(Kubernetes平台的服务实例资源)。
尤其是,在应用滚动升级或者故障迁移的过程中会产生非常多的服务实例的更新事件。
而单纯的服务实例的变化并不会影响 Listener、Route、Cluster 等xDS 配置,如果仅仅由于服务实例的变化触发全量的 xDS 配置生成与分发,则会浪费很多计算资源与网络带宽资源,同时影响 Envoy代理的稳定性。
Istio在1.1版本中引入增量EDS特性,专门针对以上场景对Pilot进行优化。首先,服务实例的 EventHandler 不同于前面提到的通用的事件处理回调函数(直接发送全量更新事件到updateChannel)。
增量EDS异步分发的主要流程如图所示
可以看到Kubernetes的Endpoint资源在更新时,首先在平台适配层由updateEDS将其转换为 Istio 特有的 IstioEndpoint 模型;
然后EnvoyXdsServer 通过对比其缓存的IstioEndpoint 资源,检查是否需要全量下发配置,并更新缓存;当仅仅存在 Endpoints 更新事件时,Pilot只需要进行增量EDS分发;
随后EnvoyXdsServer将增量EDS分发事件发送到updateChannel,
EnvoyXdsServer是如何判断是否可以进行增量 EDS 分发的?
EnvoyXdsServer 全局缓存所有服务的 IstioEndpoint 及在每个推送周期内发生变化的服务列表。EnvoyXdsServer是通过IstioEndpoint缓存判断是否需要全量配置下发的。
资源隔离
随着用户对 Istio 服务网格的需求越来越旺盛,Istio 社区充分认识到服务隔离或者说作用范围的必要性。
通过有效定义访问范围及服务的有效作用范围,可以大大消除网格规模增加带来的配置规模几何级的增长,目前在理论上可支持无限大规模的服务网格。
Istio 目前充分利用命名空间隔离的概念,在两方面做了可见范围的优化:用 Sidecar API资源定义Envoy代理可以访问的服务;用服务及配置(VirtuslService、DestinationRule)资源定义其有效范围。
- Sidecar API资源是Istio 1.1新增的特性,目前支持为同一命名空间下的所有Envoy或者通过标签选择为特定的 Envoy 定义其对外可访问的服务(支持具体的服务名称或者命名空间的基本服务)。
- 服务及配置规则的可见范围。目前可定义同一命名空间可见或者全局范围可见。Istio通过其实现服务访问层面的隔离,同Sidecar API资源一起减少xDS配置数量。
源码解析
Istio Pilot的代码分为Pilot-Discovery和Pilot-Agent,其中Pilot-Agent用于在数据面负责Envoy的生命周期管理,Pilot-Discovery才是控制面进行流量管理的组件
本文将重点分析控制面部分,即Pilot-Discovery的代码。
下图是Pilot-Discovery组件代码的主要结构
Pilot-Discovery的入口函数为:pilot/cmd/pilot-discovery/main.go中的main方法。main方法中创建了Discovery Server,Discovery Server中主要包含三部分逻辑:
Config Controller
Config Controller用于管理各种配置数据,包括用户创建的流量管理规则和策略。Istio目前支持三种类型的Config Controller:
- Kubernetes:使用Kubernetes来作为配置数据的存储,该方式的直接依附于Kubernetes强大的CRD机制来存储配置数据,简单方便,是Istio最开始使用的配置存储方案。
- MCP (Mesh Configuration Protocol):使用Kubernetes来存储配置数据导致了Istio和Kubernetes的耦合,限制了Istio在非Kubernetes环境下的运用。为了解决该耦合,Istio社区提出了MCP,MCP定义了一个向Istio控制面下发配置数据的标准协议,Istio Pilot作为MCP Client,任何实现了MCP协议的Server都可以通过MCP协议向Pilot下发配置,从而解除了Istio和Kubernetes的耦合。如果想要了解更多关于MCP的内容,请参考文后的链接。
- Memory:一个在内存中的Config Controller实现,主要用于测试。
目前Istio的配置包括:
- Virtual Service: 定义流量路由规则。
- Destination Rule: 定义和一个服务或者subset相关的流量处理规则,包括负载均衡策略,连接池大小,断路器设置,subset定义等等。
- Gateway: 定义入口网关上对外暴露的服务。
- Service Entry: 通过定义一个Service Entry可以将一个外部服务手动添加到服务网格中。
- Envoy Filter: 通过Pilot在Envoy的配置中添加一个自定义的Filter。
Service Controller
Service Controller用于管理各种Service Registry,提出服务发现数据,目前Istio支持的Service Registry包括:
- Kubernetes:对接Kubernetes Registry,可以将Kubernetes中定义的Service和Instance采集到Istio中。
- Consul: 对接Consul Catalog,将Consul中定义的Service采集到Istio中。
- MCP: 和MCP config controller类似,从MCP Server中获取Service和Service Instance。
- Memory: 一个内存中的Service Controller实现,主要用于测试。
Discovery Service
Discovery Service中主要包含下述逻辑:
- 启动GRPC Server并接收来自Envoy端的连接请求。
- 接收Envoy端的xDS请求,从Config Controller和Service Controller中获取配置和服务信息,生成响应消息发送给Envoy。
- 监听来自Config Controller的配置变化消息和来自Service Controller的服务变化消息,并将配置和服务变化内容通过xDS接口推送到Envoy。(备注:目前Pilot未实现增量变化推送,每次变化推送的是全量配置,在网格中服务较多的情况下可能会有性能问题)。
Pilot-Discovery 业务流程
Pilot-Disocvery包括以下主要的几个业务流程
初始化Pilot-Discovery的各个主要组件
Pilot-Discovery命令的入口为pilot/cmd/pilot-discovery/main.go中的main方法,在该方法中创建Pilot Server,Server代码位于文件pilot/pkg/bootstrap/server.go中。Server主要做了下面一些初始化工作:
- 创建并初始化Config Controller
- 创建并初始化Service Controller
- 创建并初始化Discovery Server,Pilot中创建了基于Envoy V1 API的HTTP Discovery Server和基于Envoy V2 API的GPRC Discovery Server。由于V1已经被废弃,本文将主要分析V2 API的GRPC Discovery Server。
- 将Discovery Server注册为Config Controller和Service Controller的Event Handler,监听配置和服务变化消息。
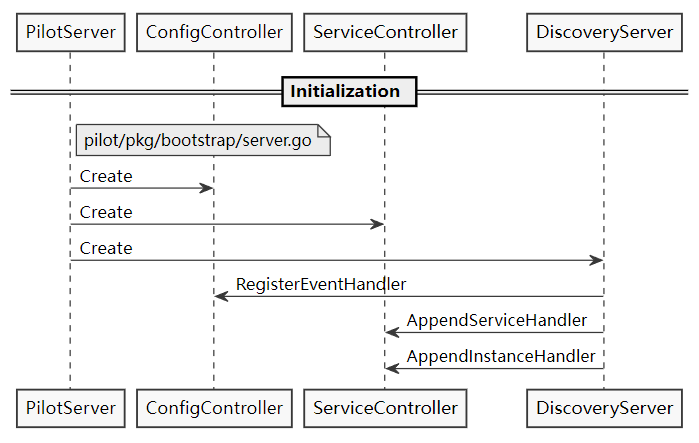
创建GRPC Server并接收Envoy的连接请求
Pilot Server创建了一个GRPC Server,用于监听和接收来自Envoy的xDS请求。pilot/pkg/proxy/envoy/v2/ads.go 中的 DiscoveryServer.StreamAggregatedResources方法被注册为GRPC Server的服务处理方法。
当GRPC Server收到来自Envoy的连接时,会调用DiscoveryServer.StreamAggregatedResources方法,在该方法中创建一个XdsConnection对象,并开启一个goroutine从该connection中接收客户端的xDS请求并进行处理;如果控制面的配置发生变化,Pilot也会通过该connection把配置变化主动推送到Envoy端。
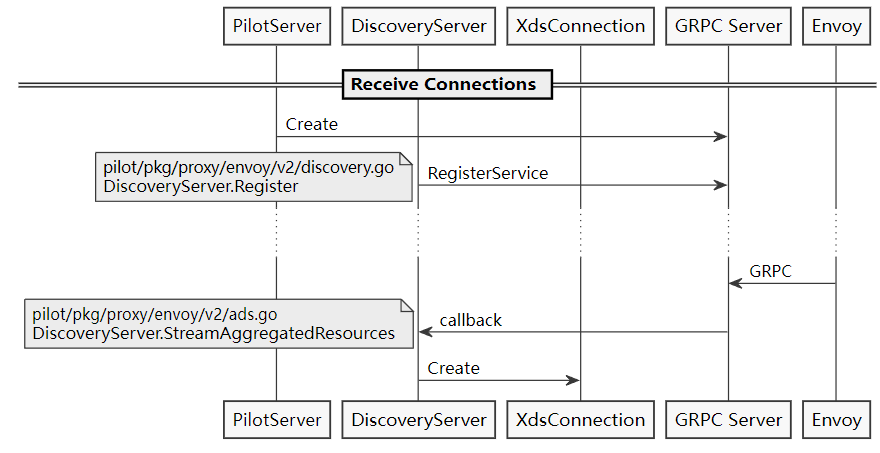
配置变化后向Envoy推送更新
这是Pilot中最复杂的一个业务流程,主要是因为代码中采用了多个channel和queue对变化消息进行合并和转发。该业务流程如下:
- Config Controller或者Service Controller在配置或服务发生变化时通过回调方法通知Discovery Server,Discovery Server将变化消息放入到Push Channel中。
- Discovery Server通过一个goroutine从Push Channel中接收变化消息,将一段时间内连续发生的变化消息进行合并。如果超过指定时间没有新的变化消息,则将合并后的消息加入到一个队列Push Queue中。
- 另一个goroutine从Push Queue中取出变化消息,生成XdsEvent,发送到每个客户端连接的Push Channel中。
- 在DiscoveryServer.StreamAggregatedResources方法中从Push Channel中取出XdsEvent,然后根据上下文生成符合xDS接口规范的DiscoveryResponse,通过GRPC推送给Envoy端。(GRPC会为每个client连接单独分配一个goroutine来进行处理,因此不同客户端连接的StreamAggregatedResources处理方法是在不同goroutine中处理的)

响应Envoy主动发起的xDS请求
Pilot和Envoy之间建立的是一个双向的Streaming GRPC服务调用,因此Pilot可以在配置变化时向Envoy推送,Envoy也可以主动发起xDS调用请求获取配置。Envoy主动发起xDS请求的流程如下:
- Envoy通过创建好的GRPC连接发送一个DiscoveryRequest
- Discovery Server通过一个goroutine从XdsConnection中接收来自Envoy的DiscoveryRequest,并将请求发送到ReqChannel中
- Discovery Server的另一个goroutine从ReqChannel中接收DiscoveryRequest,根据上下文生成符合xDS接口规范的DiscoveryResponse,然后返回给Envoy。
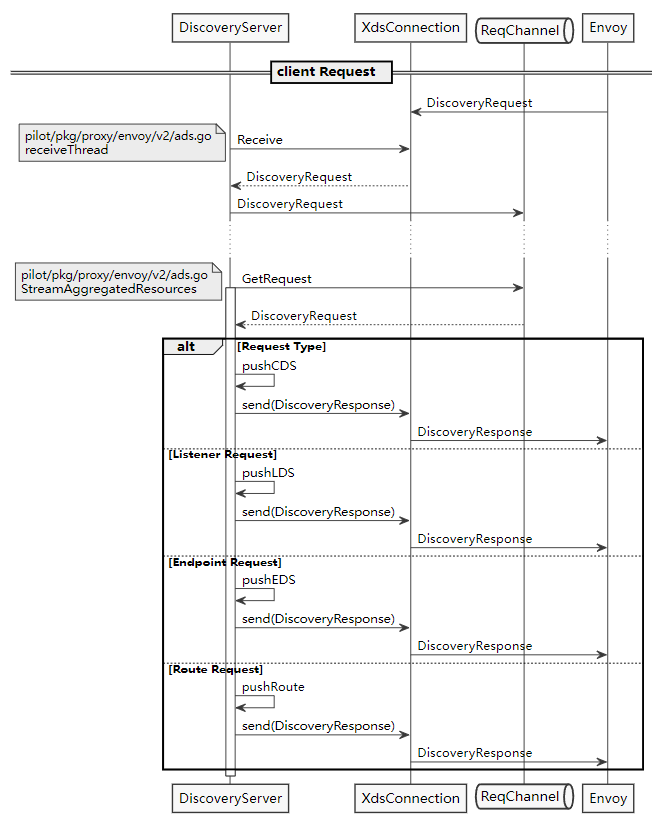
Discovery Server业务处理关键代码片段
下面是Discovery Server的关键代码片段和对应的业务逻辑注解,为方便阅读,代码中只保留了逻辑主干,去掉了一些不重要的细节。
处理xDS请求和推送的关键代码
该部分关键代码位于istio.io/istio/pilot/pkg/proxy/envoy/v2/ads.go文件的StreamAggregatedResources 方法中。
StreamAggregatedResources方法被注册为GRPC Server的handler,对于每一个客户端连接,GRPC Server会启动一个goroutine来进行处理。
代码中主要包含以下业务逻辑:
- 从GRPC连接中接收来自Envoy的xDS 请求,并放到一个channel reqChannel中
- 从reqChannel中接收xDS请求,根据xDS请求的类型构造响应并发送给Envoy
- 从connection的pushChannel中接收Service或者Config变化后的通知,构造xDS响应消息,将变化内容推送到Envoy端
1 | // StreamAggregatedResources implements the ADS interface. |
处理服务和配置变化的关键代码
该部分关键代码位于istio.io/istio/pilot/pkg/proxy/envoy/v2/discovery.go文件中,用于监听服务和配置变化消息,并将变化消息合并后通过Channel发送给前面提到的 StreamAggregatedResources 方法进行处理。
ConfigUpdate是处理服务和配置变化的回调函数,service controller和config controller在发生变化时会调用该方法通知Discovery Server。
1 | func (s *DiscoveryServer) ConfigUpdate(req *model.PushRequest) { |
在debounce方法中将连续发生的PushRequest进行合并,如果一段时间内没有收到新的PushRequest,再发起推送;以避免由于服务和配置频繁变化给系统带来较大压力。
1 | // The debounce helper function is implemented to enable mocking |
总结-完整业务流程

Mixer
自Istio 1.5 起,Istio 标准指标由 Envoy 代理直接导出。 在先前的 Istio 版本中,Mixer 生成了这些指标。
Mixer提供三个核心功能:
- 前置条件检查(Precondition Checking)
某一服务响应外部请求前,通过Envoy向Mixer发送Check请求,检查该请求是否满足一定的前提条件,包括白名单检查、ACL检查等。
- 配额管理(Quota Management)
当多个请求发生资源竞争时,通过配额管理机制可以实现对资源的有效管理。
- 遥测报告上报(Telemetry Reporting)
该服务处理完请求后,通过Envoy向Mixer上报日志、监控等数据。
历史版本
- Istio telemetry with Mixer(1.4之前)
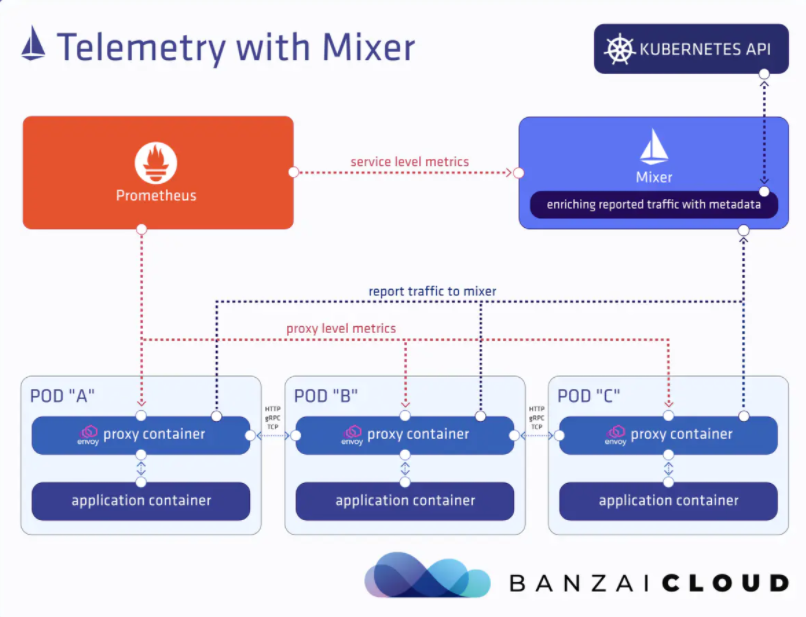
- Mixerless的实现—Istio Telemetry V2(1.5之后)
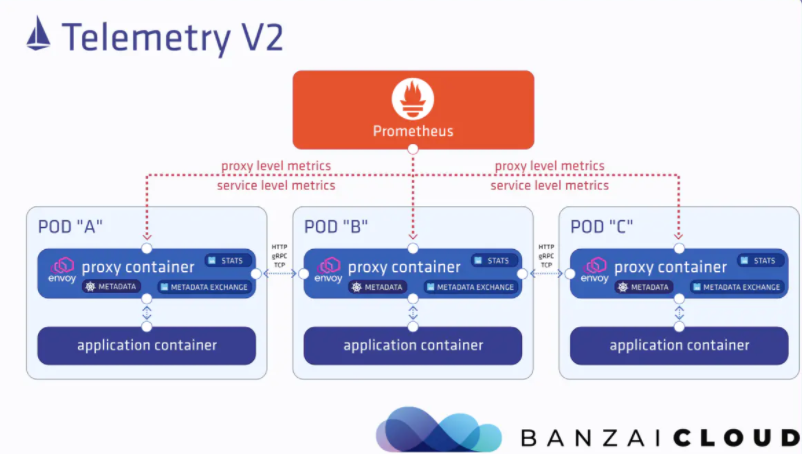
旧版Mixer不足
Istio最大的毛病就是qps始终很低,有大牛统计过如下分析
1 | netty4.1的HTTP转发的demo,没做任何优化和调教,轻松10万+的QPS |
最开始Service Mesh以Linkerd/Envoy为代表
主要是以proxy/sidecar的形式出现
功能基本都在sidecar中
请求通过sidecar转发,期间发生的各种检查/判断/操作,都是在sidecar中进行。
1 | #传统分布式 |
只是多了一层proxy/sidecar的转发,
接着出现第二代演进,Istio出现
1 | #第一版服务网格 |
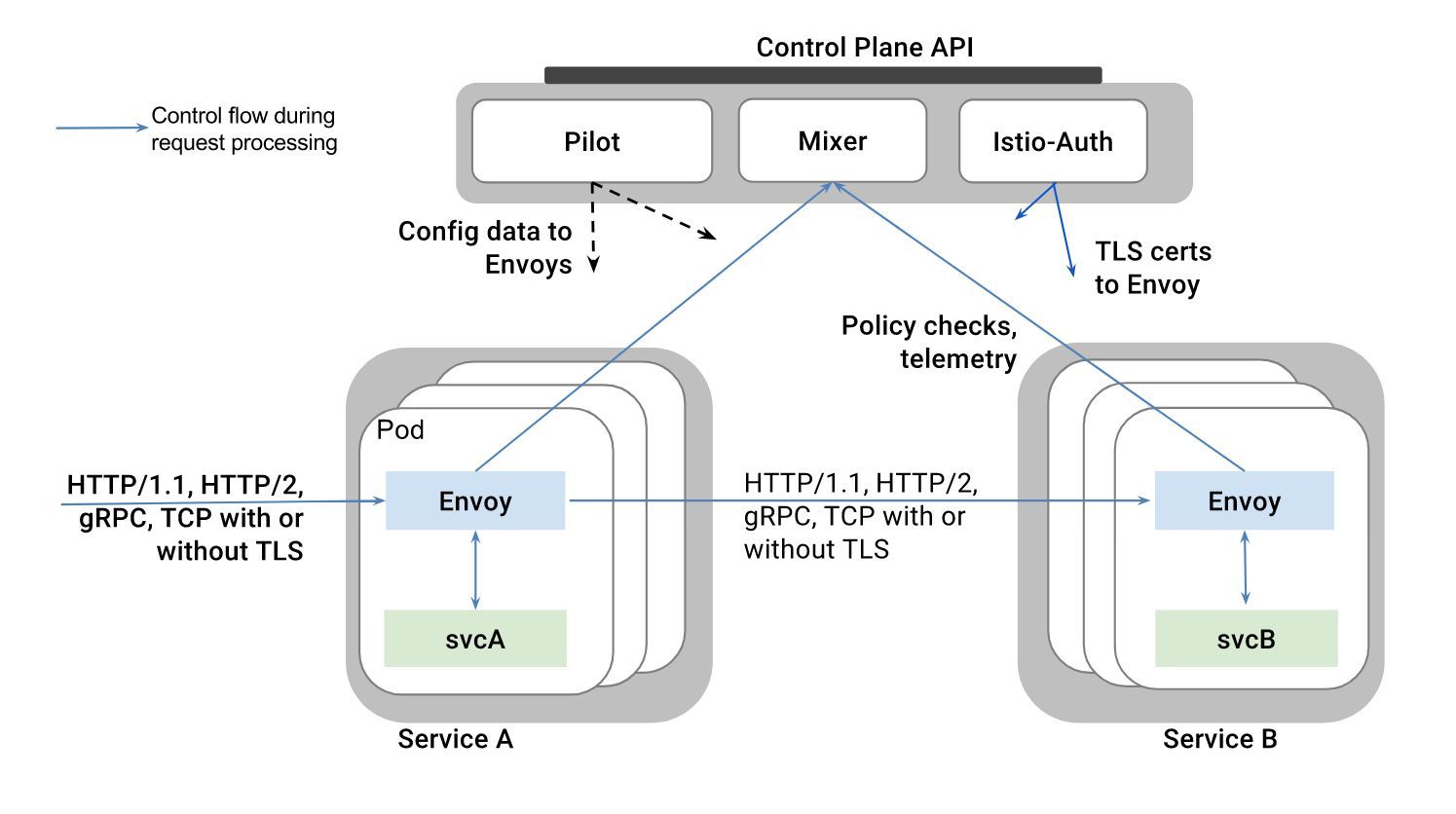
控制平面的三大模块如上图,
其中的Pilot和Auth都不直接参与到流量的处理流程
因此他们不会对运行时性能产生直接影响
mixer的工作,就需要envoy从每次请求中获取信息,然后发起两次对mixer的请求:
- 在转发请求之前:这时需要做前提条件检查和配额管理,只有满足条件的请求才会做转发
- 在转发请求之后:这时要上报日志等,术语上称为遥感信息,Telemetry,或者Reporting。
第二代Istio服务网格特性
原有的sidecar被归结为data plane,然后在data plane上增加control plane。
1 | data plane 只负责转发,其中部分数据来自Pilot和Auth。 |
旧版Mixer的改进
在Envoy中增加mixer filter。
这个Filter和控制面的Mixer组件进行通讯,完成策略控制和遥测数据收集功能。
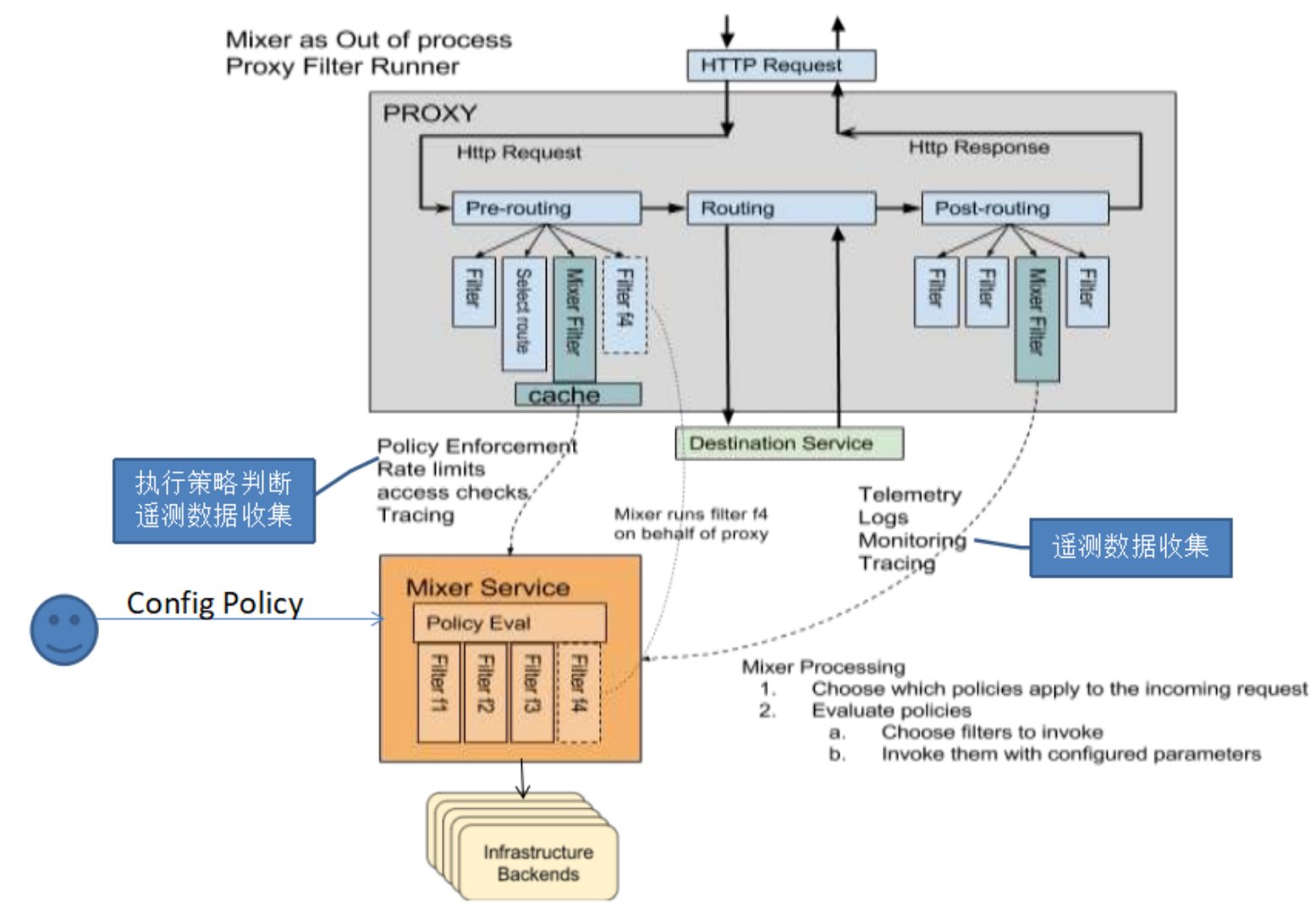
关键在于增加了缓存:
Mixer Filter中保存有策略判断所需的数据缓存,因此大部分策略判断在Envoy中就处理了,不需要发送请求到Mixer。
另外Envoy收集到的遥测数据会先保存在Envoy的缓存中,每隔一段时间再通过批量的方式上报到Mixer。
缓存的工作如下:
1 | Sidecar 中包含本地缓存,一大部分的前置检查可以通过缓存来进行。 |
敖大大针对改进产生的疑问:
1 | “一大部分的前置检查可以通过缓存来进行”,大部分? |
旧版Mixer Cache
为了保证运行时性能,避免每次请求都远程访问Mixer核心逻辑,Istio特意为Mixer增加了缓存
1 | 但是Mixer Cache不放在Envoy |
因为缓存在Mixer而不再Envoy所以造成以下局势尴尬局面
- 要明确划分数据平面和控制平面的界限,Mixer就必须独立于Envoy
- Mixer和Envoy之间就变成了远程访问,存在性能瓶颈
- 为了解决性能问题,避免远程访问,就需要将cache加在envoy一侧
- 然后就不得不面对缓存总数呈现笛卡尔乘积的威胁
旧版Mixer 属性
每次请求中的各个属性
来源于属性词汇
1 | request.path: xyz/abc |
Istio中首要的属性生产者是Envoy,然后特定的Mixer适配器和服务也会产生属性。
引用属性
Envoy会提交所有的Attribute,而在CheckResponse的应答中,PreconditionResult 表示前置条件检查的结果:
| 字段 | 类型 | 描述 |
|---|---|---|
| status | google.rpc.Status | 状态码OK表示所有前置条件均满足。 任何其它状态码表示不是所有的前置条件都满足 并且在detail中描述为什么。 |
| validDuration | google.protobuf.Duratio | 时间量,在此期间这个结果可以认为是有效的 |
| validUseCount | int32 | 可使用的次数,在此期间这个结果可以认为是有效的 |
| attributes | CompressedAttributes | mixer返回的属性。 返回的切确属性集合由mixer配置的adapter决定。 这些属性用于传送新属性 这些新属性是Mixer根据输入的属性集合和它的配置派生的。 |
| referencedAttributes | ReferencedAttribute | 在匹配条件并生成结果的过程中使用到的全部属性集合。 |
流程如上图
Envoy请求带一些属性过来a=1,b=2,c=3,e=0,f=0
Mixer在CheckResponse返回referencedAttributes内容a,b,c
Envoy关心这些
引用属性,才知道Mixer的Adpater对哪些属性感兴趣
Mixer Cache需要缓存Mixer整个CheckResponse的结果,避免每次都让Envoy请求Mixer
旧版Mixer Cache设计之道
将返回的ReferencedAttributes的key做简单hash得到的值作为新的key,
其他返回结果在value
Mixer Cache分为两个部分
- check cache
- quota cache
新版Mixerless
所谓 Mixer V2 其最终目标就是将现有的 out-of-process 的插件模型最终用基于 WASM 的 in-proxy 扩展模型来替代。
那么很自然的就想要把Mixer的功能合并到Sidecar做,将遥测和服务鉴权能力下沉到每个服务的代理Proxy Envoy中。
这机智的大脑,那问题来了,Envoy是C++写的,Mixer是Go的,怎么把功能加进去?直接撸袖子再写一把C++吗?
纠结了很久,Envoy开始提供Web Assembly(WASM)的支持,成了扩展Envoy解药。
定制Metrics
大致分两步:
- 第一步,配置EnvoyFilter。
- 第二步,在pod中添加annotations。不难理解,由于遥测下沉到Envoy了,因此每一个pod都需要将想要让Prometheus监控的指标声明出来。
国内查看评论需要代理~