TCP分段与UDP/IP分片
(MTU最大传输单元,MSS最大分段大小)
1 | TCP报文段如果很长的话,会在发送时发生分段,在接受时进行重组,同样IP数据报在长度超过一定值时也会发生分片,在接收端再将分片重组。 |
MTU
计算机沟通必须有标准:tcp/ip v4,还有ipv6,但是没有普遍
Link链路层->Internet网络层->Transport(Tcp层),Link时常与Internet来回主要是因为MTU进行数据包分片
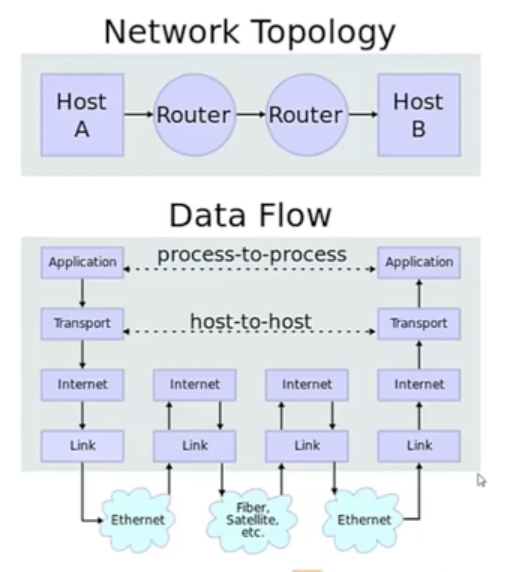
IP数据包进入协议栈的封装
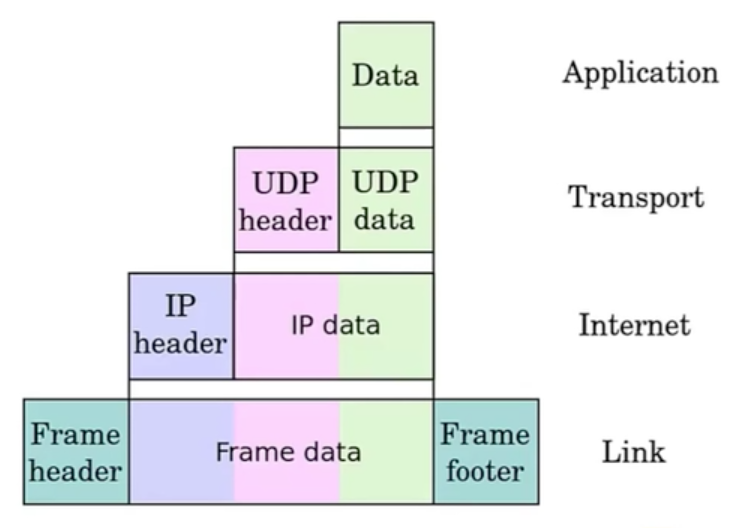
Link层有头尾包裹,检测FrameData和FrameHeader标识相关的信息传输过来是否出错
以太网FrameData最小46个字节,不足填0,最大1500个字节,称为MTU(最大传输单元)
当我们传输的数据超过最大传输单元MTU,在IP层进行分片数据包分成若干个片
之前ADSL猫的MTU只有1480字节,还有光纤各不一样,所以经常会在Link与Internet之间来回切数据包
MSS(最大分段大小)
MSS是TCP里的一个概念(首部的选项字段中)。
MSS是TCP数据包每次能够传输的最大数据分段,TCP报文段的长度大于MSS时,要进行分段传输。
1 | TCP协议在建立连接的时候通常要协商双方的MSS值,每一方都有用于通告它期望接收的MSS选项(MSS选项只出现在SYN报文段中,即TCP三次握手的前两次)。 |
总结
UDP不会分段,就由IP来分。TCP会分段,当然就不用IP来分了!
另外IP数据报分片后,只有第一片带有UDP首部或ICMP首部,其余的分片只有IP头部,到了端点后根据IP头部中的信息再网络层进行重组。
而TCP报文段的每个分段中都有TCP首部,到了端点后根据TCP首部的信息在传输层进行重组。
IP数据报分片后,只有到达目的地后才进行重组,而不是向其他网络协议,在下一站就要进行重组。
最后一点对IP分片的数据报来说,即使只丢失一片数据也要重新传整个数据报(既然有重传,说明运输层使用的是具有重传功能的协议,如TCP协议)
这是因为IP层本身没有超时重传机制——由更高层(比如TCP)来负责超时和重传。
当来自TCP报文段的某一段(在IP数据报的某一片中)丢失后
TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报(可能有多个IP分片),没有办法只重传数据报中的一个数据分片。
网络
IP
IP特点
不可靠,无连接
不可靠:ip数据包不保证一定传送到,ip数据如果在中途路由器内存用完,则丢掉整个数据包,到达机器利用icmp传达(ICMP协议规定:目的主机必须返回ICMP回送应答消息给源主机。如果源主机在一定时间内收到应答,则认为主机可达。)
数据包如果保证一定送到则利用tcp协议
无连接:ip数据包每个处理都相互独立,不是顺序发送,A->B各个数据包走的线路不一样,B可能先收到后面的数据包
IP数据包如下
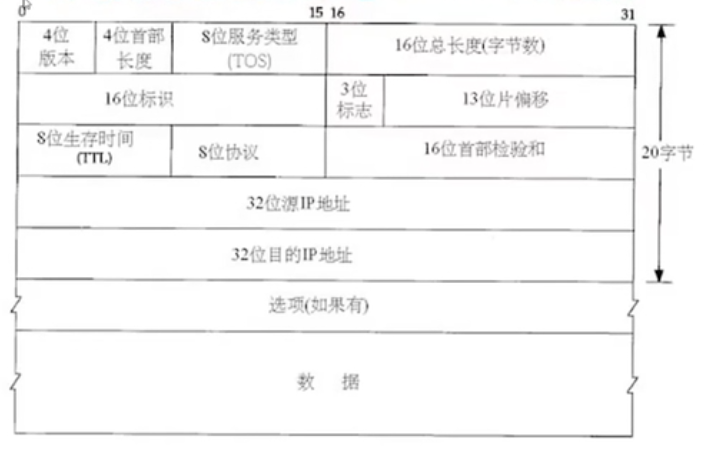
网络传输数据都由BigEndian,windows/linux都LittleEndian,但网络传输是BigEndian
在cpu内存地址,存储方式主流的英特尔都是LittleEndian
由之前IP数据包协议栈的封装
IPheader就是4位版本+4位首部长度+8位服务类型(TOS)+16位数据包总长度
8位生存时间TTL:每经过一个Link中的TTL减1,如果减到0发不到就系统认为发不到就丢弃并报告错误
8位协议:怎样方式传输,tcp还是如何
16位首部检验和:算数据有无差错
32位源IP地址:发送源头
32位目的IP地址:发送目的地
ipv4,32位地址40多亿,当时没有考虑到会人手一台电脑
Ipv6,128位地址足够用,已经使用,但是推广缓慢,只有部分骨干网络学校网络使用
ipv4大部分地址掌握在美国人手中,所以推ipv6不值当,国内的话对长城有影响
TCP
- TCP如何利用ip到达自己的目的地
- TCP首部
- TCP的状态变迁
- TCP的连接建立
- TCP的连接断开
- TCP的数据交互
如何承载在IP上传输
IP特点:无连接,不可靠, TCP如何变成可靠与有链接?
总结特性如下:
TCP将数据分割报文段
TCP将数据分为好几段报文段
定时器
每当tcp发出去之后建立一个定时器(a->b,如果a等定时器还未回复,则再尝试发送一次,尝试次数一定数目告诉应用程序,发送失败),也有一种所谓的粘包现象:发送端发了3次,接收端只收了1次
延迟确认
当tcp收到数据包,进行延迟确认(十次确认的包,用一次确认就行了),在确认的时候会将乱序的数据包重新排序,也会砍重复数据包
检验和
tcp还会检验和,用来检测数据是否出现错误,当tcp检验和正常
流量控制
为了让tcp服务稳定下来,利用了流量控制,防止较快的机器过意压榨了减慢的机器
TCP首部

ip首部20个字节,tcp首部也是20个字节,在都没有选项的情况下
假如数据通过以太网传输,最小需要46个字节,ip+tcp=20+20还差六个字节则补0填充
tcp首部四个字节
在网络传输都是bigEndian,传输过程中在程序A打开端口号,作sourcePort,接收程序B打开端口号作为DestinationPort
源ip+源端口号+目标ip+目标端口号作为一个socket pair四元组,
Sequence Number4个字节
包的序号Seq,用于解决网络包乱序(reordering)。
Sequence Numbertcp分割数据包每个包都有一个Sequence Number,当我确认的时候也会根据Sequence Number来进行确认
Acknowledgement Number4个字节
Ack用于确认收到Seq(Ack = Seq + 1,表示收到了Seq及Seq之前的数据包,期待Seq + 1),用于解决丢包。
Data offset4个位
数据偏移(即首部长度):占4位,它指出TCP报文段的数据起始处距离TCP报文段的起始处有多远。“数据偏移”的单位是32位字,即以4字节为计算单位。
Reserved(保留字段)占6位
保留为今后使用,但目前应置为0。
TCPFlag(标志位):占6位
分别表示6个标志:紧急URG,确认ACK,推送PSH(PuSH),复位RST(ReSeT),同步SYN,终止FIN(FINis)
- URG—— 当URG= 1 时,表明紧急指针字段有效。它告诉系统此报文段中有紧急数据,应尽快传送(相当于高优先级的数据)。
- ACK—— 当ACK= 1 时确认号字段有效,当ACK= 0 时,确认号无效。
- PSH(PuSH) ——接收TCP收到PSH= 1 的报文段,就尽快地交付接收应用进程,而不再等到整个缓存都填满了后再向上交付。
- RST(ReSeT)—— 当RST= 1 时,表明TCP连接需要释放连接,然后再重新建立运输连接。
- SYN—— 同步SYN= 1 表示这是一个连接请求或连接接受报文。
- FIN(FINis) ——用来释放一个连接。FIN= 1 表明此报文段的发送端的数据已发送完毕,并要求释放运输连接。
Window size占2字节
Window Size,又叫Advertised Window,可以近似理解为滑动窗口(Sliding Window)的大小,用于流控。
用来让对方设置发送窗口的依据,单位为字节。
表示接收缓冲区的空闲空间,16位,用来告诉TCP连接对端自己能够接收的最大数据长度。
2个字节大小为65535,窗口大小量
CheckSum
检验和,windows内部局域网传过来的的东西也可能没做检查,如果出错也不管,不要太信任checksum
Urgent point
UrgentPointers(紧急指针字段):占16位,指出在本报文段中紧急数据共有多少个字节(紧急数据放在本报文段数据的最前面)。
TCP的状态变迁
tcp是如何利用ip提供了可靠的字节流传输服务,面向连接且有状态还有序
其实是把tcp每台机器做出了状态机
11种状态如下
CLOSED:
实际上不存在的状态初始状态,表示TCP连接是“关闭着的”或“未打开的”。
LISTEN :
服务器等待客户端来连接表示服务器端的某个SOCKET处于监听状态,可以接受客户端的连接。
SYN_RCVD :
服务器确认首次连接表示服务器接收到了来自客户端请求连接的SYN报文。在正常情况下,这个状态是服务器端的SOCKET在建立TCP连接时的三次握手会话过程中的一个中间状态,很短暂,基本上用netstat很难看到这种状态,除非故意写一个监测程序,将三次TCP握手过程中最后一个ACK报文不予发送。当TCP连接处于此状态时,再收到客户端的ACK报文,它就会进入到ESTABLISHED 状态。
SYN_SENT :
客户端尝试来连接服务器
这个状态与SYN_RCVD 状态相呼应,当客户端SOCKET执行connect()进行连接时,它首先发送SYN报文,然后随即进入到SYN_SENT 状态,并等待服务端的发送三次握手中的第2个报文。SYN_SENT 状态表示客户端已发送SYN报文。ESTABLISHED :
建立了连接,双方可发送数据表示TCP连接已经成功建立。
FIN_WAIT_1 :
等待对方关闭这个状态得好好解释一下,其实FIN_WAIT_1 和FIN_WAIT_2 两种状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET进入到FIN_WAIT_1 状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2 状态。当然在实际的正常情况下,无论对方处于任何种情况下,都应该马上回应ACK报文,所以FIN_WAIT_1 状态一般是比较难见到的,而FIN_WAIT_2 状态有时仍可以用netstat看到。
FIN_WAIT_2 :
等待对方关闭上面已经解释了这种状态的由来,实际上FIN_WAIT_2状态下的SOCKET表示半连接,即有一方调用close()主动要求关闭连接。
注意:FIN_WAIT_2 是没有超时的(不像TIME_WAIT 状态),这种状态下如果对方不关闭(不配合完成4次挥手过程),那这个 FIN_WAIT_2 状态将一直保持到系统重启,越来越多的FIN_WAIT_2 状态会导致内核crash。TIME_WAIT :
等待自己应用程序关闭表示收到了对方的FIN报文,并发送出了ACK报文。
TIME_WAIT状态下的TCP连接会等待2*MSL(Max Segment Lifetime,最大分段生存期,指一个TCP报文在Internet上的最长生存时间。每个具体的TCP协议实现都必须选择一个确定的MSL值,RFC 1122建议是2分钟,但BSD传统实现采用了30秒,Linux可以cat /proc/sys/net/ipv4/tcp_fin_timeout看到本机的这个值),然后即可回到CLOSED 可用状态了。如果FIN_WAIT_1状态下,收到了对方同时带FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。(这种情况应该就是四次挥手变成三次挥手的那种情况)CLOSING :
等待对方确认自己关闭这种状态在实际情况中应该很少见,属于一种比较罕见的例外状态。正常情况下,当一方发送FIN报文后,按理来说是应该先收到(或同时收到)对方的ACK报文,再收到对方的FIN报文。但是CLOSING 状态表示一方发送FIN报文后,并没有收到对方的ACK报文,反而却也收到了对方的FIN报文。什么情况下会出现此种情况呢?那就是当双方几乎在同时close()一个SOCKET的话,就出现了双方同时发送FIN报文的情况,这是就会出现CLOSING 状态,表示双方都正在关闭SOCKET连接。
CLOSE_WAIT :
等待自己应用程序关闭表示正在等待关闭。怎么理解呢?当对方close()一个SOCKET后发送FIN报文给自己,你的系统毫无疑问地将会回应一个ACK报文给对方,此时TCP连接则进入到CLOSE_WAIT状态。接下来呢,你需要检查自己是否还有数据要发送给对方,如果没有的话,那你也就可以close()这个SOCKET并发送FIN报文给对方,即关闭自己到对方这个方向的连接。有数据的话则看程序的策略,继续发送或丢弃。简单地说,当你处于CLOSE_WAIT 状态下,需要完成的事情是等待你去关闭连接。
LAST_ACK :
等待最后一次确认消息当被动关闭的一方在发送FIN报文后,等待对方的ACK报文的时候,就处于LAST_ACK 状态。当收到对方的ACK报文后,也就可以进入到CLOSED 可用状态了。
状态变迁图
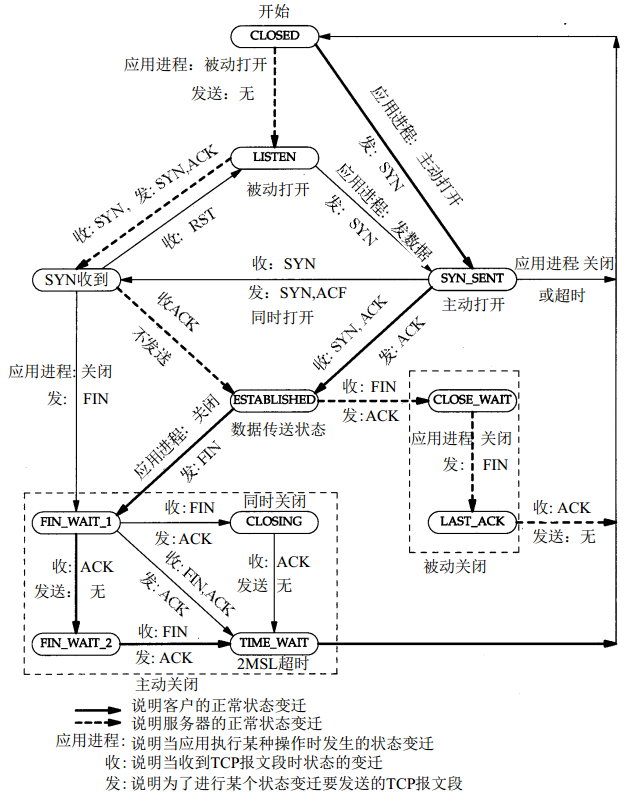
Server
Closed->Listen->SYC_RECEIVED->ESTABLISHED->
CLOSE_WAIT->LAST_ACK在
SYC_RECEIVED->ESTABLISHED会建立一个socket pair四元组
Client
CLOSED->SYN_SENT->ESTABLISHED->
FIN_WAIT_1->FIN_WAIT_2->TIME_WAITTIME_WAIT:进入这个阶段socket pair不可用,必须得等待timeout
三次握手,四次挥手
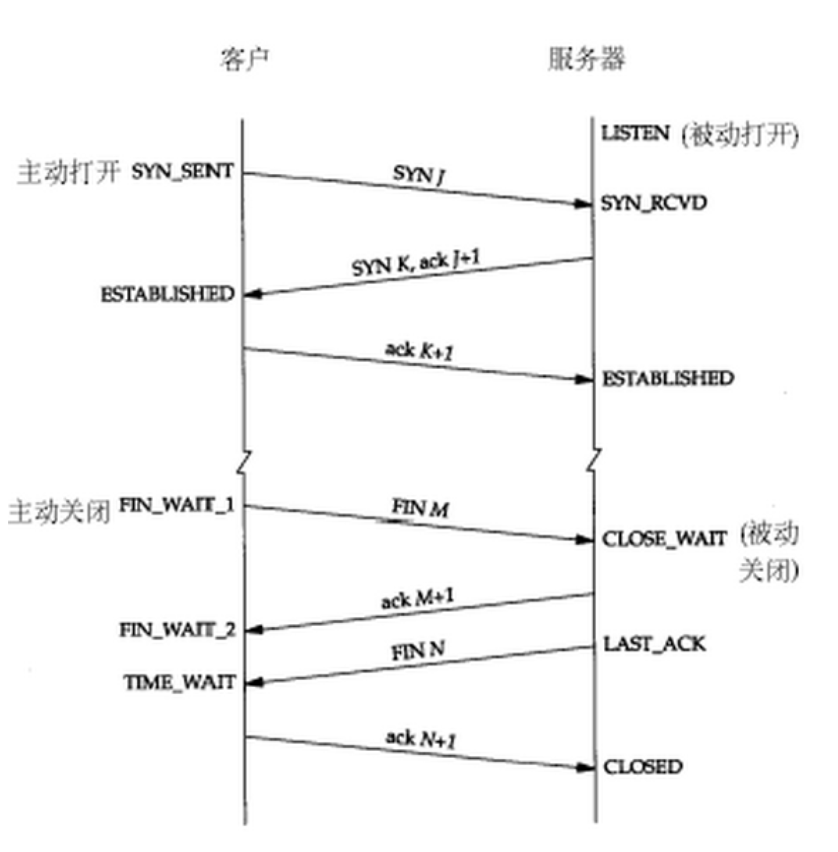
为什么关闭四次,连接是三次?
断开经过四次,是因为tcp是全双工协议,两边都可以发送并且没有关联
而连接最简单的方式也是两个一来一回四次握手,但此处进行了优化:将server端回复的ACK同server端自己的SYN合并在一个报文中发送给client,所以减少为三次。
但挥手要回收大量资源是耗时操作;因此不能强制将server端回复的ACK同server端自己的FIN合并在一个报文中发送给client”所以通常认为挥手需要四次。
为什么会有TIME_WAIT状态?
IP头部有TTL8位生存时间,表示经过设备的数量,TIME_WAIT确保要么送达目的地,要么通过网络一次次流转后让它自亡,一般2分钟,这样为了防止有的无用的包在网络上无限传播下去,浪费网络带宽
一般数据包来回两趟所以2分钟乘以2约等于4分钟
从主动关闭这方来看,这段时间不能使用,保证了新建的链接不会与上一次的链接数据混乱
不常见的异常
RST异常
- 客户端连接服务器,超时了发送了RST复位
- 应用程序处理了一部分消息,误认为客户端有问题发送了RST复位
Listen会保持一个队列
队列保存三次握手OK的socket,但是上层应用程序还没处理socket,对于客户端认为和服务器进入了ESTABLISHED,而服务器还没进入,所以发过来的数据会暂存,等待应用来处理
如果队列满了客户端的新建链接,服务器既不返回错误也不确认,就返回超时……
握手过程中的其他问题
建连接时SYN超时
server收到client发的SYN并回复Ack(SYN)(此处称为Ack1)后,如果client掉线了(或网络超时),那么server将无法收到client回复的Ack(Ack(SYN))(此处称为Ack2),连接处于一个中间状态(非成功非失败)。
为了解决中间状态的问题,server如果在一定时间内没有收到Ack2,会重发Ack1(不同于数据传输过程中的重传机制)。Linux下,默认重试5次,加上第一次最多共发送6次;重试间隔从1s开始翻倍增长(一种指数回退策略,Exponential Backoff),5次的重试时间分别为1s, 2s, 4s, 8s, 16s,第5次发出后还要等待32s才能判断第5次也超时。所以,至多共发送6次,经过1s + 2s + 4s+ 8s+ 16s + 32s = 2^6 -1 = 63s,TCP才会认为SYN超时断开这个连接。
SYN FLOOD攻击
可以利用建连接时的SYN超时机制发起SYN Flood攻击——给server发一个SYN就立即下线,于是服务器默认需要占用资源63s才会断开连接。
发SYN的速度是很快的,这样,攻击者很容易将server的SYN队列资源耗尽,使server无法处理正常的新连接。
针对该问题,Linux提供了一个tcp_syncookies参数解决这个问题——当SYN队列满了后,TCP会通过源地址端口、目标地址端口和时间戳构造一个特别的Sequence Number发回去,称为SYN Cookie
如果是攻击者则不会有响应,如果是正常连接,则会把这个SYN Cookie发回来,然后server端可以通过SYN Cookie建连接(即使你不在SYN队列中)。
至于SYN队列中的连接,则不做处理直至超时关闭。请注意,不要用tcp_syncookies参数来处理正常的大负载连接情况,因为SYN Cookie本质上也破坏了建连接的SYN超时机制,是妥协版的TCP协议。
对于正常的连接请求,有另外三个参数可供选择:
tcp_synack_retries参数设置SYN超时重试次数tcp_max_syn_backlog参数设置最大SYN连接数(SYN队列容量)tcp_abort_on_overflow参数使SYN请求处理不过来的时候拒绝连接
ISN的同步
ISN(初始化序列号,Inital Sequence Number),通信的双方要同步对方ISN——所以叫SYN(全称Synchronize Sequence Numbers)
- 首先,不能选择静态的ISN。例如,如果连接建好后始终用1来做ISN,如果client发了30个segment(假设一个字节一个segment)过去,但是网络断了,于是 client重连,又用了1做ISN,但是旧连接的那些segment(称为
“迷途的重复分组”)到了,由于区分连接的五元组相同(称该新连接为旧连接的“化身”),server会把它们当做新连接中的segment。 - 然后从上例还能够得知,需要使ISN随时钟动态增长,以保证新连接的ISN大于旧连接。
- 最后从安全等角度考虑,也不能使ISN的增长呈现规律性(如简单随时钟正比例增长)。这很容易理解,如果增长规律过于简单,则很容伪造ISN对网络两端发起攻击。
最终,设计了多种ISN增长算法,普遍使ISN随时钟动态增长,并具有一定的随机性。
RFC793中描述了一种简单的ISN增长算法:ISN会和一个假的时钟绑在一起,这个时钟会在每4微秒对ISN做加一操作,直到超过2^32,又从0开始。
这样一个ISN的周期大约是4.55个小时。定义segment在网络上的最大存活时间为MSL(Maximum Segment Lifetime),网络中存活时间超过MSL的分组将被丢弃。
因此,如果使用RFC793中的ISN增长算法,则MSL的值必须小于4.55小时,以保证不会在相邻的连接中重用ISN(TIME_WAIT也有该作用)。同时,这间接限制了网络的大小(当然4.55小时的MSL已经能构造非常大的网络了)。
挥手过程中的其他问题
为什么需要TIME_WAIT
在TCP状态机中,从TIME_WAIT状态到CLOSED状态,有一个超时时间2 MSL。为什么需要TIME_WAIT状态,且超时时间为2 MSL?主要有两个原因:
2 * MSL确保有足够的时间让被动方收到了ACK或主动方收到了被动方发超时重传的FIN。即如果被动方没有收到Ack,就会触发被动方重传FIN,发送Ack+接收FIN正好2个MSL,TIME_WAIT状态的连接收到重传的FIN后,重传Ack,再等待2 * MSL时间。- 确保有足够的时间让
“迷途的重复分组”过期丢弃。这只需要1 * MSL即可,超过MSL的分组将被丢弃,否则很容易同新连接的数据混在一起(仅仅依靠ISN是不行的)。
大规模出现TIME_WAIT
一个常见问题是大规模出现TIME_WAIT,通常是在高并发短连接的场景中,会消耗很多资源。
网上大部分文章都是教你打开两个参数,tcp_tw_reuse或tcp_tw_recycle。这两个参数默认都是关闭的,tcp_tw_recycle比tcp_tw_reuse更为激进;要想使用二者,还需要打开tcp_timestamps(默认打开),否则无效。不过,打开这两个参数可能会让TCP连接出现诡异的问题:如上所述,如果不等待超时就重用连接的话,新旧连接的数据可能会混在一起,比如新连接握手期间收到了旧连接的FIN,则新连接会被重置。因此,使用这两个参数时应格外小心。
各参数详细如下:
tcp_tw_reuse:官方文档上说tcp_tw_reuse加上tcp_timestamps可以保证客户端(仅客户端)在协议角度的安全,但是需要在两端都打开tcp_timestamps。tcp_tw_recycle:如果是tcp_tw_recycle被打开了话,会假设对端开启了tcp_timestamps,然后会去比较时间戳,如果时间戳变大了,就可以重用连接(NAT网络有可能建连接失败,出现”connection time out”的错误)。
补充一个参数:
tcp_max_tw_buckets:控制并发的TIME_WAIT的数量(默认180000),如果超限,系统会把多余的TIME_WAIT连接destory掉,然后在日志里打一个警告(如“time wait bucket table overflow”)。官网文档说这个参数是用来对抗DDoS攻击的,需要根据实际情况考虑。
关于TIME_WAIT的建议
总之TIME_WAIT出现在主动发起挥手的一方,即谁发起挥手谁就要牺牲资源维护那些等待从TIME_WAIT转换到CLOSED状态的连接。TIME_WAIT的存在是必要的,因此与其通过上述参数破协议来逃避TIME_WAIT,不如好好优化业务(如改用长连接等),针对不同业务优化TIME_WAIT问题。
对于HTTP服务器,可以设置HTTP的KeepAlive参数,在应用层重用TCP连接来处理多个HTTP请求(需要浏览器配合),让client端(即浏览器)发起挥手,这样TIME_WAIT只会出现在client端。
TCP重传机制
TCP协议通过重传机制保证所有的segment都可以到达对端,通过滑动窗口允许一定程度的乱序和丢包(滑动窗口还具有流量控制等作用,暂不讨论)。注意,此处重传机制特指数据传输阶段,握手、挥手阶段的传输机制与此不同。
TCP是面向字节流的,Seq与Ack的增长均以字节为单位。
在最朴素的实现中,为了减少网络传输,接收端只回复最后一个连续包的Ack,并相应移动窗口。
比如,发送端发送1,2,3,4,5一共五份数据(假设一份数据一个字节),接收端快速收到了Seq 1,Seq 2,于是回Ack 3,并移动窗口;然后收到了Seq 4,由于在此之前未收到过Seq 3(乱序),如果仍在窗口内,则只填充窗口,但不发送Ack 5,否则丢弃Seq 3(与丢包的效果相似);
假设在窗口内,则等以后收到Seq 3时,发现Seq 4及以前的数据包都收到了,则回Ack 5,并移动窗口。
超时重传机制
当发送方发现等待Seq 3的Ack(即Ack 4)超时后,会认为Seq 3发送“失败”,重传Seq 3。一旦接收方收到Seq 3,会立即回Ack 4。
发送方无法区分是
Seq 3丢包、接收方故障、还是Ack 4丢包,本文统一表述为Seq发送“失败”。
这种方式有些问题:假设目前已收到了Seq 4;由于未收到Seq 3,导致发送方重传Seq 3,在收到重传的Seq 3之前,包括新收到的Seq 5和刚才收到的Seq 4都不能回复Ack,很容易引发发送方重传Seq 4、Seq5。接收方之前已经将Seq 4、Seq 5保存到窗口中,此时重传Seq 4、Seq 5明显造成浪费。
也就是说,超时重传机制面临“重传一个还是重传所有”的问题即:
- 重传一个:仅重传timeout的包(即Seq 3),后续包等超时后再重传。节省资源,但效率略低。
- 重传所有:每次都重传timeout包及之后所有的数据(即Seq 3、4、5)。效率更高(如果带宽未打满),但浪费资源。
可知,两种方法都属于超时重传机制,各有利弊,但二者都需要等待timeout,是基于时间驱动的,性能与timeout的长度密切相关。如果timeout很长(普遍情况),则两种方法的性能都会受到较大影响。
快速重传机制
最理想的方案是:在超时之前,通过某种机制要求发送方尽快重传timeout的包(即Seq 3),如快速重传机制(Fast Retransmit)。
这种方案浪费资源(浪费多少取决于“重传一个还是重传所有”,见下),但效率非常高(因为不需要等待timeout了)。
快速重传机制不基于时间驱动,而基于数据驱动:如果包没有连续到达,就Ack最后那个可能被丢了的包;如果发送方连续收到3次相同的Ack,就重传对应的Seq。
1 | 比如:假设发送方仍然发送1,2,3,4,5共5份数据;接收方先收到Seq 1,回Ack 2; |
示意图如下:
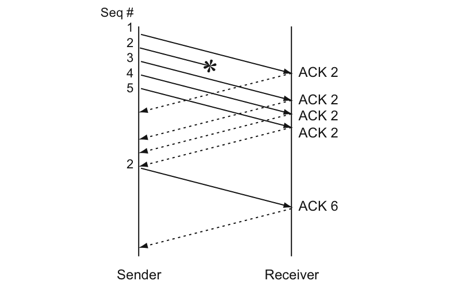
快速重传解决了timeout的问题,但依然面临“重传一个还是重传所有”的问题。对于上面的示例来说,是只重传Seq 2呢还是重传Seq 2、3、4、5呢?
如果只使用快速重传,则必须重传所有:因为发送方并不清楚上述连续的4次Ack 2是因为哪些Seq传回来的。
1 | 假设发送方发出了Seq 1到Seq 20供20份数据 |
TCP的流量控制
RTT算法
根据前文对TCP超时重传机制的介绍,我们知道Timeout的设置对于重传非常重要:
- 设长了,重发就慢,丢了老半天才重发,没有效率,性能差。
- 设短了,会导致可能并没有丢就重发。于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
而且这个超时时间在不同的网络环境下不同,必须动态设置。
为此TCP引入了RTT(Round Trip Time,环回时间):一个数据包从发出去到回来的时间。
这样,发送端就大约知道正常传输需要多少时间,据此计算RTO(Retransmission TimeOut,超时重传时间)。
算法有以下实现
- 经典算法
- 首先采样RTT,记下最近几次的RTT值。
- 然后使用加权移动平均算法(
Weighted Moving Average Method)做平滑,计算SRTT(Smoothed RTT) - 最后计算RTO:
RTO = min [ UBOUND, max [ LBOUND, (β * SRTT) ] ](通常取1.3≤β≤2.0)
- Karn / Partridge 算法
- Jacobson / Karels 算法
TCP滑动窗口
TCP使用滑动窗口(Sliding Window)做流量控制与乱序重排
TCP头里有一个字段叫Window(或Advertised Window),用于接收方通知发送方自己还有多少缓冲区可以接收数据。
发送方根据接收方的处理能力来发送数据,不会导致接收方处理不过来,是谓流量控制。暂且把Advertised Window当做滑动窗口,更容易理解滑动窗口如何完成流量控制,后面介绍拥塞控制时再说明二者的区别。
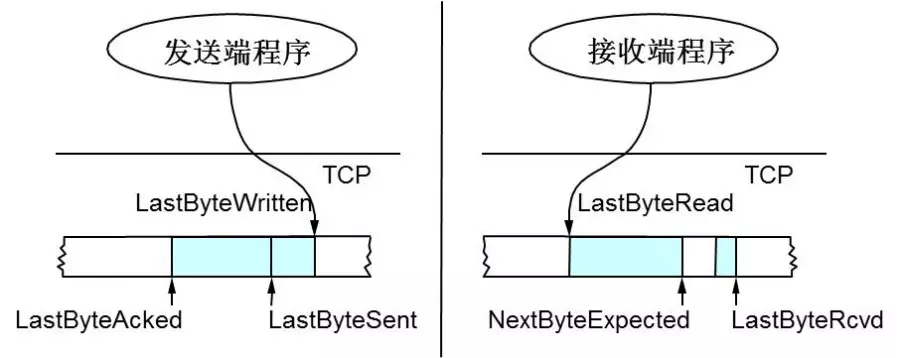
假设位置序号从左向右增长(常见的读、写缓冲区设计),解释一下:
- 发送方:
LastByteAcked指向收到的连续最大Ack的位置;LastByteSent指向已发送的最后一个字节的位置;LastByteWritten指向上层应用已写完的最后一个字节的位置。 - 接收方:
LastByteRead指向上层应用已读完的最后一个字节的位置;NextByteExpected指向收到的连续最大Seq的位置;LastByteRcvd指向已收到的最后一个字节的位置。可以看到NextByteExpected与LastByteRcvd中间有些Seq还没有到达,对应空白区。
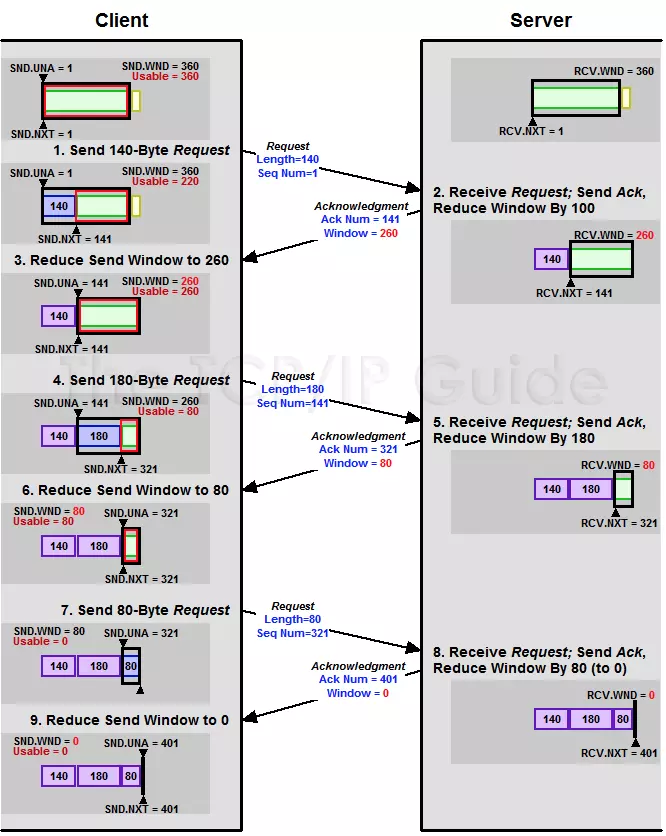
Advertised Window衡量接收方还能接收的数据量,发送方要根据Advertised Window决定接下来发送的数据量上限,即EffectiveWindow(可能为0)。
据此在接收方计算Advertised Window,在发送方计算Effective Window:
- 接收方在Ack中记录自己的
AdvertisedWindow = MaxRcvBuffer – (LastByteRcvd - LastByteRead),随Ack回复到发送方。 - 发送方根据Ack中的
Advertised Window值,需保证LastByteSent - LastByteAcked ≤ AdvertisedWindow,则窗口内剩余可发送的数据大小EffectiveWindow = AdvertisedWindow - (LastByteSent - LastByteAcked),以保证接收方可以处理。
发送缓冲区的滑动窗口
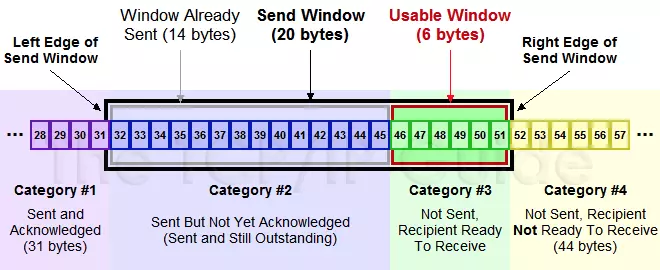
上图分为4个部分:
#1是已发送已确认的数据,即LastByteAcked之前的区域。#2是已发送未确认的数据,即LastByteAcked与LastByteSent之间的区域,大小不超过AdvertisedWindow。#3是窗口内未发送的数据,即LastByteSent与窗口右界之间的区域,大小等于EffectiveWindow(可能为0)。#4是窗口外未发送的数据,即窗口右界与LastByteWritten之间的区域。
其中,#2 + #3组成了滑动窗口,总大小不超过AdvertisedWindow,二者比例受到接收方的处理速度与网络情况的影响(如果丢包严重或处理速度慢于发送速度,则#2:#3会越来越大)。
以下是一个AdvertisedWindow的调整过程,EffectiveWindow随之变化;
TCP的拥塞控制
为什么要进行拥塞控制?
假设网络已经出现拥塞,如果不处理拥塞,那么延时增加,出现更多丢包,触发发送方重传数据,加剧拥塞情况,继续恶性循环直至网络瘫痪。可知,拥塞控制与流量控制的适应场景和目的均不同。
拥塞发生前,可避免流量过快增长拖垮网络;拥塞发生时,唯一的选择就是降低流量。
主要使用4种算法完成拥塞控制:
- 1:慢启动
- 2:拥塞避免
- 3:拥塞发生
- 4:快速恢复
算法1、2适用于拥塞发生前,算法3适用于拥塞发生时,算法4适用于拥塞解决后(相当于拥塞发生前)。
rwnd(Receiver Window,接收者窗口)与cwnd(Congestion Window,拥塞窗口)的概念:
rwnd是用于流量控制的窗口大小,即上述流量控制中的AdvertisedWindow,主要取决于接收方的处理速度,由接收方通知发送方被动调整。cwnd是用于拥塞处理的窗口大小,取决于网络状况,由发送方探查网络主动调整。
介绍流量控制时,我们在没有考虑cwnd,认为发送方的滑动窗口最大即为rwnd。
实际上需要同时考虑流量控制与拥塞处理,则发送方窗口的大小不超过min{rwnd, cwnd}。
下述4种拥塞控制算法只涉及对cwnd的调整,同介绍流量控制时一样,暂且不考虑rwnd,假定滑动窗口最大为cwnd;但读者应明确rwnd、cwnd与发送方窗口大小的关系。
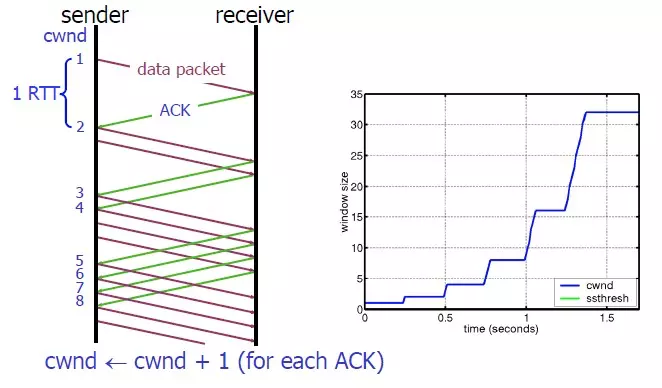
慢启动算法
慢启动算法(Slow Start)作用在拥塞产生之前:对于刚刚加入网络的连接,要一点一点的提速,不要妄图一步到位。
如下:
- 连接刚建好,初始化
cwnd = 1(当然,通常不会初始化为1,太小),表明可以传一个MSS大小的数据。 - 每收到一个ACK,
cwnd++,线性增长。 - 每经过一个RTT,
cwnd = cwnd * 2,指数增长(主要增长来源)。 - 还有一个
ssthresh(slow start threshold),当cwnd >= ssthresh时,就会进入拥塞避免算法。
因此如果网速很快的话,Ack返回快,RTT短,那么这个慢启动就一点也不慢。下图说明了这个过程:
拥塞避免算法
前面说过,当cwnd >= ssthresh(通常ssthresh = 65535)时,就会进入拥塞避免算法(Congestion Avoidance):缓慢增长,小心翼翼的找到最优值。如下:
- 每收到一个Ack,
cwnd = cwnd + 1/cwnd,显然cwnd > 1时无增长。 - 每经过一个RTT,
cwnd++,线性增长(主要增长来源)。
慢启动算法主要呈指数增长,粗犷型,速度快(“慢”是相对于一步到位而言的);
而拥塞避免算法主要呈线性增长,精细型,速度慢,但更容易在不导致拥塞的情况下,找到网络环境的cwnd最优值。
拥塞发生时的算法
慢启动与拥塞避免算法作用在拥塞发生前,采取不同的策略增大cwnd;如果已经发生拥塞,则需要采取策略减小cwnd。
那么TCP如何判断当前网络拥塞了呢?
很简单,如果发送方发现有Seq发送失败(表现为“丢包”),就认为网络拥塞了。
丢包后有两种重传方式,对应不同的网络情况,也就对应着两种拥塞发生时的控制算法:
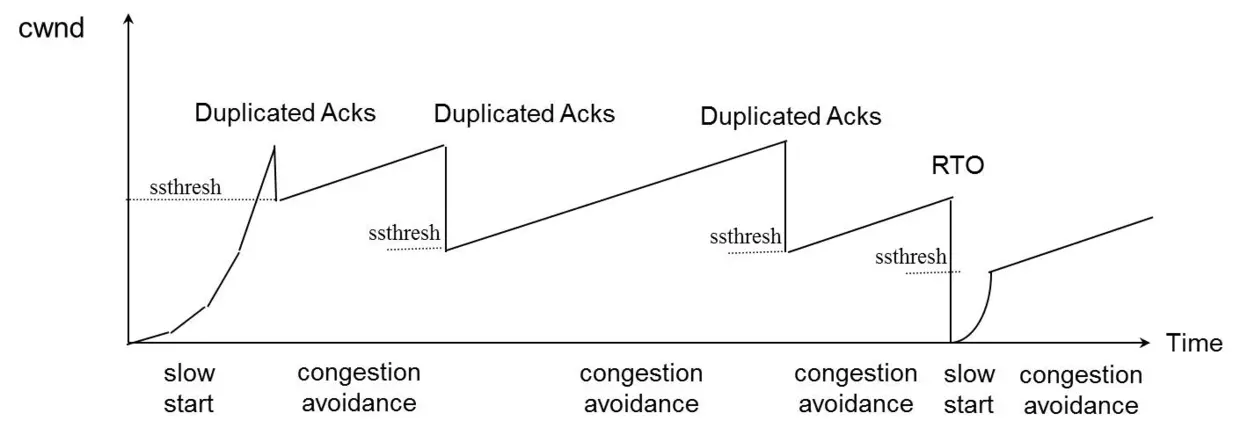
超时重传。TCP认为这种情况太糟糕,调整力度比较大
ssthresh = cwnd /2cwnd = 1,重新进入慢启动过程(网络糟糕,要慢慢调整)
快速重传。TCP认为这种情况通常比RTO超时好一些,主流实现TCP Reno的调整力度更柔和(TCP Tahoe的实现和RTO超时一样暴躁):
ssthresh = cwnd /2cwnd = cwnd /2,进入快速恢复算法(网络没那么糟,可以快速调整,见下)
可以看到,不管是哪种重传方式,ssthresh都会变成cwnd的一半,仍然是指数回退,待拥塞消失后再逐渐增长回到新的最优值,总体上在最优值(动态)附近震荡。
回退后根据不同的网络情况,可以选择不同的恢复算法。慢启动已经介绍过了,下面介绍快速恢复算法。
快速恢复算法
如果触发了快速重传,即发送方收到至少3次相同的Ack,那么TCP认为网络情况不那么糟,也就没必要提心吊胆的,可以适当大胆的恢复。
为此设计快速恢复算法(Fast Recovery),下面介绍TCP Reno中的实现。
回顾一下,进入快速恢复之前,cwnd和sshthresh已被更新:
ssthresh = cwnd /2cwnd = cwnd /2
然后,进入快速恢复算法:
cwnd = ssthresh + 3 * MSS(尝试一步到位)- 重传重复Ack对应的Seq
- 如果再收到该重复Ack,则
cwnd++,线性增长(缓慢调整) - 如果收到了新Ack,则
cwnd = ssthresh,然后就进入了拥塞避免的算法了
cwnd变化图
TCP数据传输过程
交互式与成块的数据
时间延迟确认
Nagle算法
让数据饱满,数据量小的不发出去,存着等一定量才发送,游戏开发一般关闭这个算法接收窗口大小
windowsSize
TCP的定时器
重传定时器
当客户端给另一机器发送信息,对方没有确认也没返回错误,过一段时间tcp底层会认为要重传数据包
坚持定时器(Persist)
tcp两边传输会通过接收窗口windowsSize,一边狂穿另一边会给对方windowsSize为0,表示无法处理发送过来的大量信息,后期通过坚持定时器来看windowsSize是否可在接受数据不为0
保活定时器(KeepAlive)
当双方不传消息,无法探知对方还存在,tcp实现底层可通过保活定时器来确定是否对方在否
一般应用程序都不这个定时器,直接发送数据包过去,收到就是存活,由应用程序来确认而不需要tcp自己通过保活定时器来确认
2MSL定时器(TIME_WAIT)
两倍最大生存时间
WireShark
以太网有头部和尾部,但是在wireShark没有头尾,wireShark也只是模拟捕获以太网传输的数据,如果这个数据在以太网没法通过也不会到应用程序,所以wireShark只是模拟,CIC检查和所以就去掉了
tcp头部为何先放端口信息?
当tcp消息到达处理计算机,先根据端口有没有程序处理,如果端口都没有是不是没有必要考虑后面的检查
三次握手会不会被恶意使用
假如说server端遇到恶意客户端,客户端发送SYN,服务到那返回SYN+ACK,但客户端没有返回ACK挂起了了服务端消耗的资源,客户端无所谓……..这就所谓的DDOS
消息确认有没有弱点
seq,ack,以前A机器发送B机器,但是C机器截获,通过分析预测,来模拟seq和ack,从而串改数据包,在linux底层做了预防和处理
SocketApi
对于C级别的SocketApi,伯克利Socket
小于1024的端口位需要root权限
Api历史
伯克利Socket,也称为BSD Socket
4.2版本发布1983年非常成熟
1989年的时候全部的UNIX操作系统均可采用
最终成为POSIX标准2008
头文件
sys/socket.h函数和数据结构定义在头文件中netinet/in.hIPv4和v6相关的协议族需要的信息sys/un.hUNIX机器间通信的相关信息arpa/inet.h处理数字从操作系统字节序到网络字节序,这里将LittleEndian和BigEndian的字节序netdb.h映射服务到IP地址
SocketApi函数
socket()创建socketbind()绑定socket到IP地址和端口listen()服务器监听客户端的链接connect()客户端连接到服务器accept()应用程序完成3此握手的客户端链接send(),recv(),write(),read()机器间相互发送数据,返回的True,只是表示本机已经写入操作系统等信息,并不是到达网络目标机器read返回-1网络故障
read返回0是操作成功但是无数据了
read非0是读了多少字节到buffer
close()关闭socket,双工的两个通道全部关闭了,不是我这边关闭单通道gethostbyname(),gethostbyaddr()v4专有select(),poll()处理多个连接的读、写和错误状态getsocketopt()得到对应的socket选项值setsocketopt()设置对应的socket选项值kqueue,epoll,iocp各个平台有各个单独的处理多个连接的优化,出来先后顺序就是这个
例子
基于linux,该实例实现了服务端传了一个hello world给客户端。
- socket()创建socket
- bind()绑定socket到IP地址和端口
- listen()服务器监听客户端的连接
- connect()客户端连接到服务器
- accept()应用程序接受完成3次握手的客户端连接
- send() recv() write() read()机器间相互发送数据
- close() 关闭socket
- gethostbyname() gethostbyaddr() V4专有
- select() poll() 处理多个连接的读、写和错误状态
- getsockopt()得到对应socket的选项值
- setsockopt()设置对应socket的选项值
具体代码如下:
服务端部分
1 |
|
客户端部分
1 |
|
客户端和服务端哪一边主动的调用了close函数,哪一边进入TIME_WAIT

哪一边主动close哪边就进入TIME_WAIT,发生在了服务器的TIME_WAIT
国内查看评论需要代理~