基本概论
docker是lxc的管理器,lxc是cgroup的管理工具,cgroup是namespace的用户空间的管理接口。namespace是linux内核在task_struct中对进程组管理的基础机制。
再详细点说:
1 | docker是用go来实现的,自动化了对lxc的管理过程,能够自动在线下载相应的发行版本的rootfs。 |
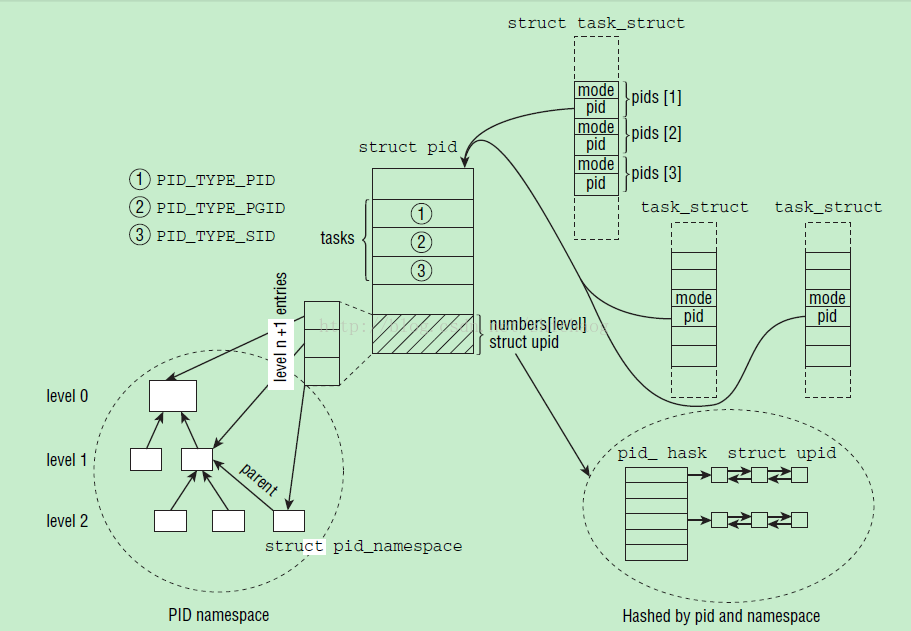
namespace
pid namespace
不同用户的进程就是通过pid namespace隔离开的,且不同 namespace 中可以有相同 PID。
具有以下特征:
- 每个 namespace 中的 pid 是有自己的 pid=1 的进程(类似 /sbin/init 进程)
- 每个 namespace 中的进程只能影响自己的同一个 namespace 或子 namespace 中的进程
因为 /proc 包含正在运行的进程,因此在 container 中的 pseudo-filesystem 的 /proc 目录只能看到自己 namespace 中的进程
因为 namespace 允许嵌套,父 namespace 可以影响子 namespace 的进程
所以子 namespace 的进程可以在父 namespace 中看到但是具有不同的 pid
mnt namespace
类似 chroot,将一个进程放到一个特定的目录执行。
mnt namespace 允许不同 namespace 的进程看到的文件结构不同
这样每个 namespace 中的进程所看到的文件目录就被隔离开了。
同chroot不同,每个namespace中的container在 /proc/mounts 的信息只包含所在 namespace的mount point。
net namespace
网络隔离是通过 net namespace 实现的
每个 net namespace 有独立的 network devices,IP addresses,IP routing tables, /proc/net 目录。
这样每个 container 的网络就能隔离开来。
docker 默认采用 veth 的方式将 container 中的虚拟网卡同 host 上的一个 docker bridge 连接在一起。
uts namespace
UTS (“UNIX Time-sharing System”) namespace 允许每个 container 拥有独立的 hostname 和 domain name
使其在网络上可以被视作一个独立的节点而非 Host 上的一个进程。
ipc namespace
container 中进程交互还是采用 Linux 常见的进程间交互方法
(interprocess communication - IPC), 包括常见的信号量、消息队列和共享内存。
然而同 VM 不同,container 的进程间交互实际上还是 host 上具有相同 pid namespace 中的进程间交互
因此需要在IPC资源申请时加入 namespace 信息 - 每个 IPC 资源有一个唯一的 32bit ID。
user namespace
每个 container 可以有不同的 user 和 group id
也就是说可以以 container 内部的用户在 container 内部执行程序而非 Host 上的用户。
有了以上 6 种 namespace 从进程、网络、IPC、文件系统、UTS 和用户角度的隔离
一个 container 就可以对外展现出一个独立计算机的能力,并且不同 container 从 OS 层面实现了隔离。
然而不同 namespace 之间资源还是相互竞争的,仍然需要类似 ulimit 来管理每个 container 所能使用的资源 - cgroup。
cgroup
cgroups 实现了对资源的配额和度量。
cgroups 的使用非常简单,提供类似文件的接口,在 /sys/fs/cgroup/ 目录下新建一个文件夹即可新建一个 group,在此文件夹中新建task文件
并将pid写入该文件,即可实现对该进程的资源控制。
具体的资源配置选项可以在该文件夹中新建子subsystem,{子系统前缀}.{资源项}是典型的配置方法
如memory.usageinbytes就定义了该group在subsystem memory中的一个内存限制选项。
另外cgroups中的subsystem可以随意组合,一个subsystem可以在不同的group中,也可以一个group包含多个subsystem- 也就是说一个subsystem
memory
内存相关的限制
cpu
在 cgroup 中,并不能像硬件虚拟化方案一样能够定义 CPU 能力,但是能够定义 CPU 轮转的优先级,因此具有较高 CPU 优先级的进程会更可能得到 CPU 运算。
通过将参数写入 cpu.shares ,即可定义改 cgroup 的 CPU 优先级 - 这里是一个相对权重,而非绝对值
blkio
block IO 相关的统计和限制,byte/operation 统计和限制 (IOPS 等),读写速度限制等,但是这里主要统计的都是同步 IO
devices
设备权限限制
步骤
- 在文件系统上建立层次结构
- 挂载文件系统并关联子系统
- 建立控制组
- 设置控制参数
- 将进程加入到控制组
lxc
1 | 可以为容器绑定特定的cpu和memory |
建立新容器 lxc-create -n name -t type
删除容器 lxc-destory -n name
运行容器lxc-start -n name
运行容器中的指令 lxc-execute -n name command
停止运行容器 lxc-stop -n name
连接运行容器 lxc-attach -n name
配置cgroup lxc-cgroup -n name
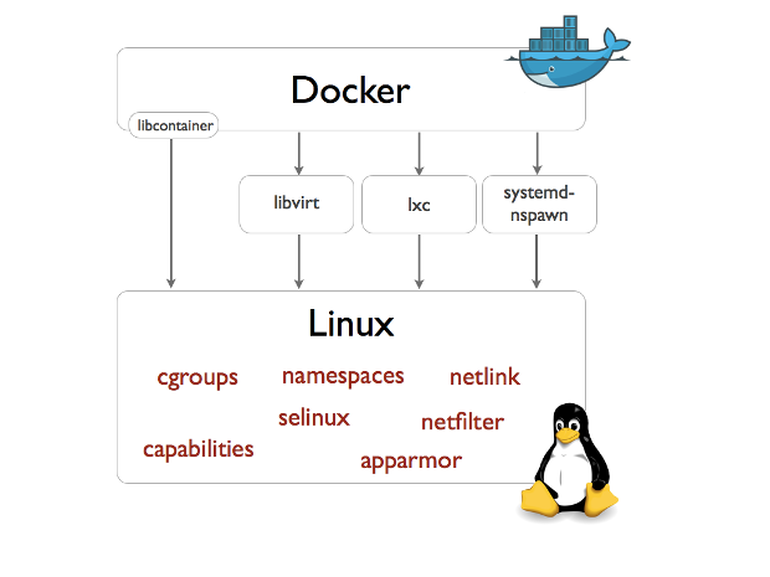
Docker 从 0.9 版本开始使用libcontainer替代lxc,libcontainer和Linux系统的交互图如下:
Cgroup
Cgroups 是 control groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO 等等)的机制。
最初由 google 的工程师提出,后来被整合进 Linux 内核。
Cgroups 也是 LXC 为实现虚拟化所使用的资源管理手段,可以说没有 cgroups 就没有 LXC。
Cgroup作用
- 1.限制进程组可以使用的资源数量,限制进程最大使用的内存等
- 2.进程组的优先级控制,比如为某个进程组分配特定的cpu share
- 3.记录进程组使用的资源数量,比如记录某个进程CPU的使用时间
- 4.进程组隔离,比如通过namespace以达到隔离的目的
- 5.进程组控制,比如可以将进程组挂起或恢复
Cgroup模型
先论进程模型,所有linux进程都拥有一个共同的父进程,叫做init进程
这个进程在内核启动的时候开始执行,然后通过init进程启动其他的进程,这些进程都是init的子进程。
因为所有的进程都有一个共同的父进程。
那么linux的进程模型就是一个单继承层次的模型或者称之为树状模型。
除此之外每一个linux进程但是除了init进程,都继承了一些环境变量(例如PATH环境变量)
Cgroup和进程类似;
Cgroup也是继承体系,并且子cgroup继承其父cgroup的某些属性,
两者最基本的差别在于,进程是单继承体系,而Cgroup可以存在多个不同的继承体系
(意思就是可以有多个单继承体系,每个单继承体系互不影响)
Cgroup概念
Subsystems: 称之为子系统,一个子系统就是一个资源控制器,比如 cpu子系统就是控制cpu时间分配的一个控制器。
Hierarchies: 可以称之为层次体系也可以称之为继承体系,指的是Control Groups是按照层次体系的关系进行组织的。
Control Groups: 一组按照某种标准划分的进程。进程可以从一个Control Groups迁移到另外一个Control Groups中,同时Control Groups中的进程也会受到这个组的资源限制。
Tasks: 在cgroups中,Tasks就是系统的一个进程。
Subsystems
在Red_Hat_Enterprise_Linux-6系列的linux中,默认提供了如下子系统。
blkio这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等) 。
cpu这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
cpuacct这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
cpuset这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
devices这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
freezer这个子系统挂起或者恢复 cgroup 中的任务。
memory这个子系统设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。
net_cls这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
ns名称空间子系统。
子系统、层次结构、控制组和任务之间的关系
资源管理在这个部分通过引入4条规则
- 规则1,一个单继承体系(单层次体系)可以附加1个或者多个子系统
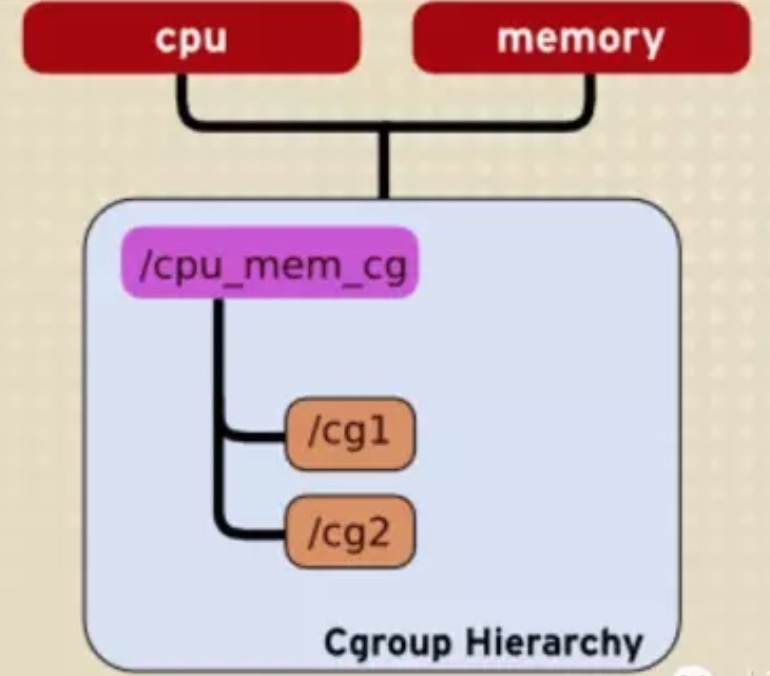
1 | Cpu和Memory两个子系统附加到了cpu_mem_cg的这个继承体系中cg1和cg2是两个Control Groups |
- 规则2,一个子系统不能被附加到多个继承体系中。
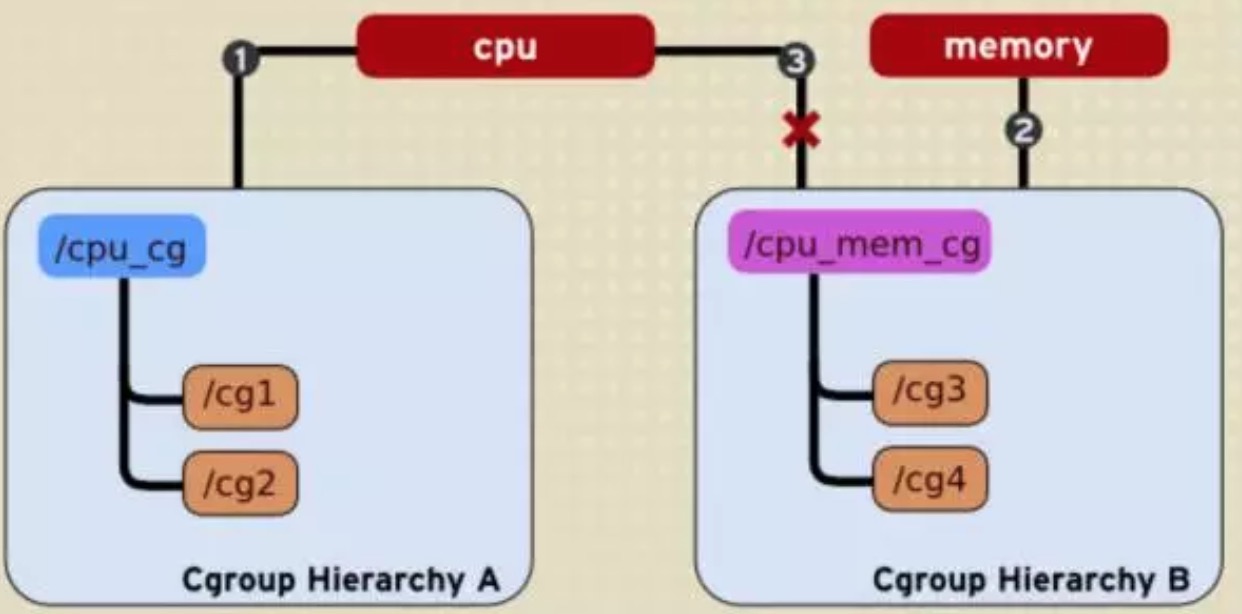
1 | 可以看出CPU子系统已经被附加到左侧的cpu_cg这个继承体系中了 |
规则3
1
2
3
4
5
6每当在系统中创建一个继承体系的时候,会默认再创建一个control groups,并且这个control groups被称之为root cgroup
此时整个系统中的tasks(进程)都属于这个root cgroup。
系统中的进程在一个继承体系中都明确的属于一个control groups
并且这个进程可以从一个control groups移动到另外一个control groups中
但是需要主要的是在一个继承体系中一个进程是没办法同时属于两个control groups的
但是一个进程可以同时属于两个不同的继承体系中的control groups。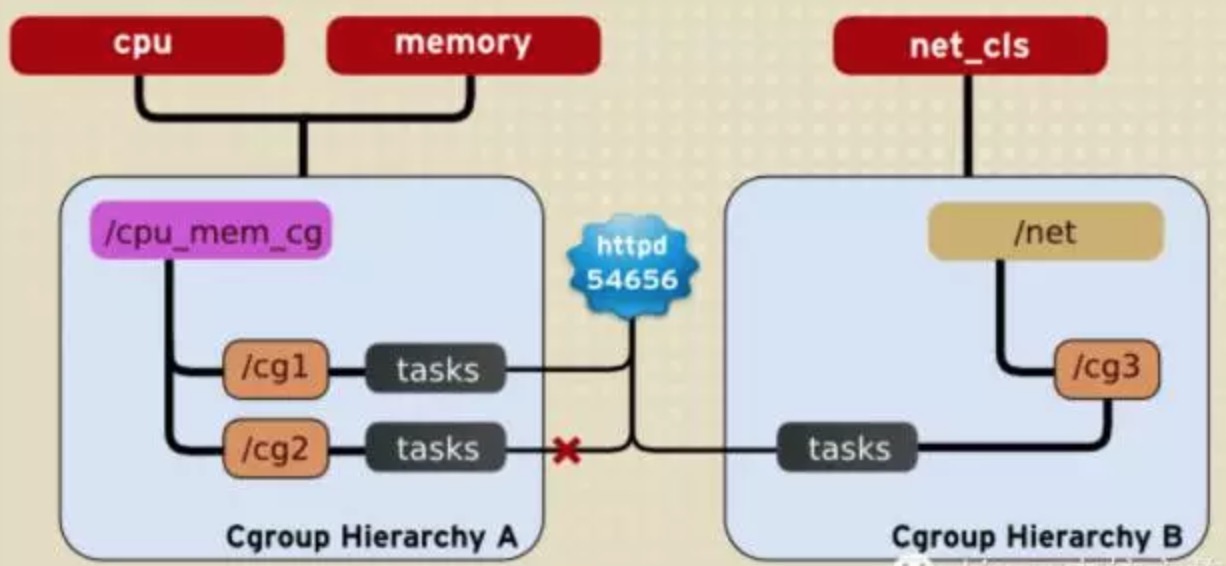
1
2在上面的这副图中可以看出httpd这个进程无法同时属于A继承体系中的cg1和cg2这两个control groups
但是httpd进程却可以同时属于A继承体系中的cg1和B继承体系中的cg3。规则4
1
2
3
4系统上的任何task(进程)通过fork创建子task(进程)的时候
这个子task(进程)自动继承其父task(进程)的control groups成为这个control groups的一员。
此后这个子task(进程)可以移动到其他control groups中
父task(进程)和子task(进程)完全独立。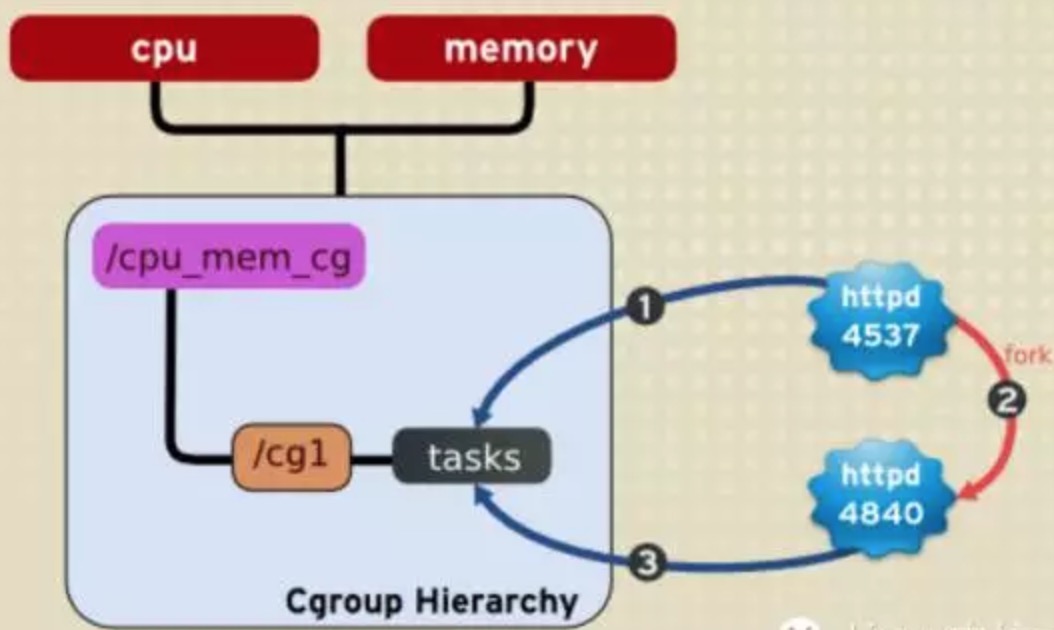
1 | 可以看出httpd进程fork出来的子进程仍然是属于cg1这个control group的。 |
国内查看评论需要代理~