基础数学
教科书内容
一. 线性代数
向量
矩阵
集合
标量
张量
范数
内积
向量正交
正交基
特征值分解
奇异值分解
二. 概率论
条件概率
联合概率
全概率公式
逆概率
贝叶斯公式
贝叶斯定理
先验概率
后验概率
似然概率
最大似然估计法
最大后验概率法
离散型随机变量
连续型随机变量
概率质量函数
概率密度函数
两点分布
二项分布
泊松分布
均匀分布
指数分布
正态分布
数字特征
数学期望
方差
协方差
三. 数理统计
样本
总体
统计量
参数估计
假设检验
置信区间
区间估计
泛化能力
泛化误差
欠拟合
过拟合
噪声
偏差
四. 优化相关
目标函数
全局最小值
局部极小值
无约束优化
约束优化
拉格朗日函数
梯度下降法
梯度方向
一阶导数
二阶导数
牛顿法
泰勒展开
线性搜索方法
置信域方法
启发式算法
五.信息论
信息熵
互信息
信息增益
KL 散度
最大熵原理
AI涉及内容
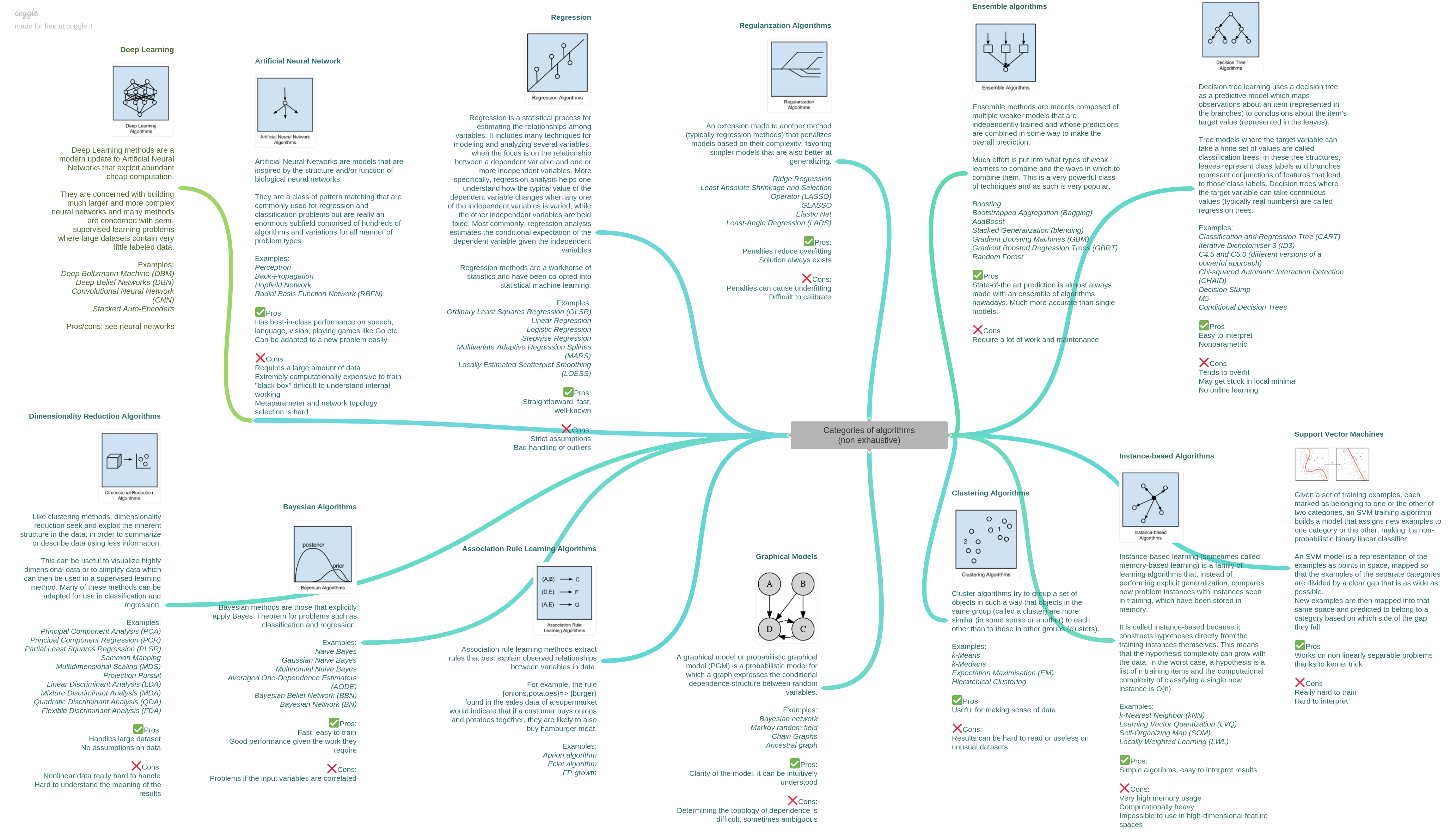
一. 线性代数
- 向量
- 矩阵
- 集合
- 标量
- 张量
- 范数
- 内积
- 向量正交
- 正交基
- 特征值分解
- 奇异值分解
矩阵分解
总结:前面的都是基础概念性的内容,后面的三个分解很重要,奇异值分解也属于矩阵分解里的一种,在很多应用中其实都会用到,譬如推荐系统,主题模型等。在一些其他的算法思想里其实也有用到,我们求特征向量的时候,其实也是在做特征值分解,主成分分析/因子分析 其实都用到了矩阵分解。尤其是当数据量比较小的时候,可以先不上深度学习,先用简单又基础的方法试一下,看看效果怎么样,作为baseline,加大数据集后,再采取更深层次的算法来做。
二. 概率论
- 条件概率
- 联合概率
- 全概率公式
- 逆概率
- 贝叶斯公式
- 贝叶斯定理
- 先验概率
- 后验概率
- 似然概率
- 最大似然估计法
- 最大后验概率法
- 离散型随机变量
- 连续型随机变量
- 概率质量函数
- 概率密度函数
- 两点分布
- 二项分布
- 泊松分布
- 均匀分布
- 指数分布
- 正态分布
- 数字特征
- 数学期望
- 方差
协方差
总结:概率论的内容也非常重要,掌握好了才能理解我们在机器学习/深度学习里经常出现的一些概念。它包含在我们算法的很多方面,譬如,数据是否符合正态分布/泊松分布,什么情况下可以用最大似然估计法等等,贝叶斯的定理除了运用在贝叶斯算法中,还有没有其他的算法有运用到这个思想的,条件概率个联合概率等,在后续的信息论出现的作用是什么?都需要我们队每个知识点好好掌握。重点掌握我加粗的知识点。
三. 数理统计
- 样本
- 总体
- 统计量
- 参数估计
- 假设检验
- 置信区间
- 区间估计
- 泛化能力
- 泛化误差
- 欠拟合
- 过拟合
- 噪声
偏差
总结:同样,前面是基础知识,后面的几点更为关键。泛化能力和泛化误差是我们衡量这个模型跑完了能否拿到实际场景中去应用的一个重要指标;欠拟合 or 过拟合 也是我们在模型训练的过程中需要注意和解决的两点;偏差方差等也属于评价指标,我们需要达到一个trade-off,所以如何平衡也是需要关注的。其实也可以这样看,如果数据中出现了噪音,迭代次数过少(或者一些其他原因),导致模型欠拟合,那么它的偏差大,方差小,如果过拟合,则偏差小,方差大,不管哪种情况,这个模型的泛化能力都不行,没法拿到真实场景中去用,所以我们需要对其进行调整,这个时候我们就会关注到数据本身和模型调参上。数据本身如果有噪音和异常点应该如何找到并去除,模型跳槽应该如何避免欠拟合和过拟合,都是我们在掌握这些知识点时需要重点关注的点。
四. 优化相关
- 目标函数
- 全局最小值
- 局部极小值
- 无约束优化
- 约束优化
- 拉格朗日函数
- KKT条件与对偶函数
- 梯度下降法
- 一阶导数
- 二阶导数
- 牛顿法
- 泰勒展开
- 线性搜索方法
- 置信域方法
启发式算法
总结:优化部分的内容也是非常重要的一环。当我们设定了目标函数后,就会采取各种优化算法来去优化目标函数的值,使目标函数的值最小(/最大,一般是最小,根据具体情况而定),如何使目标函数的值下降的最快,这时我们就引出了梯度下降,因为沿着负梯度下降的方向是函数值减小的最快方向,由此我们可以引出多种梯度下降的方法,包括批梯度,随机梯度,mini-batch等等。当然,这是针对一阶函数优化来说的,如果是二阶函数,我们就会考虑到用牛顿法,什么时候会出现二阶函数呢?在xgboost里针对目标函数的优化我们就会涉及到二阶函数的优化。而在这些优化函数的计算中,都会涉及到泰勒展开,在SVM里又会因为要求支持向量所以会引出拉格朗日乘子法和KKT条件,从一点去发散,我们可以发现很多知识点。所以在针对具体的算法学习过程中再去掌握这些数学知识点,高效而且有用。在深度学习中涉及到的优化算法相对就少一些,没有机器学习里的那么多,但是这些基础性的东西还是需要掌握的。
五.信息论
- 信息熵
- 互信息
- 信息增益
- KL 散度
- 最大熵原理
- 交叉熵和相对熵的对比
各种熵之间的关系
总结:信息论这一章非常重要,基本上每个知识点都是重点,因为很多情况下我们都会使用交叉熵作为损失函数,所以得弄明白它的原理和为什么我们经常使用它做损失函数的原因。对于一些特殊的情况,可以做出哪些变型,也是在掌握了这些基础上才会做的,所以大家要好好掌握。
国内查看评论需要代理~