系统设计原则
高并发原则
无状态
应用无状态、配置文件有状态,那么应用容易水平扩展
拆分&&服务化
如果开发人员少,资源有限,就没有必要对系统拆分(拆分商品和订单)
如果类似京东秒杀系统,访问量大且投入资源充足可按功能拆分系统
- 系统维度
按照功能/业务拆分;比如商品系统、购物车、结算、订单系统等
- 功能维度
对于功能模块可以按照不同的业务逻辑状态再进行划分;例如要优惠券拆分优惠券创建系统、领券系统、用券系统等
- 读写维度
按照读写不同的压力进行拆分;读的量大于写,因此拆分商品写服务、商品读服务
- AOP维度
根据访问特征;比如商品详情页可以分为CDN、页面渲染模块等
- 纵深维度
按照纵深的维度,最底层的是基础服务,最上层的是业务服务;代码结构一般按照MVC三层架构来进行划分。
随系统拆分越来越多,需要考虑服务自动注册与发行
其次还要考虑服务的分组、隔离
随着调用量增加还考虑服务的限流、黑白名单
还要一些细节上的超时时间、重试机制、服务路由(能动态切换不同分组),故障补偿等
消息队列
功能:用消息队列进行服务解耦、异步处理、流量肖峰/缓冲等
如果订阅者太多,订阅单个消息队列会成为瓶颈,此时考虑对消息队列进行多个镜像复制集群
考虑的问题?
- 处理生成消息失败
- 消息重复接收的场景
- 对消息重复,业务层面需要进行防重处理
- 有些消息队列提供重试,重试完还未成功,对不容忍失败的业务场景要做好后续的数据处理工作
- 如:增加日志、报警灯
数据闭环
数据闭环如商品详情页,数据来源太多,影响服务稳定性因素也多
最好的颁发就是使用到的数据进行异构存储,形成数据闭环
1 | 数据异构:MQ机制接收数据变更,存储到合适的存储引擎如Redis |
数据缓存
浏览器缓存
设置响应头Expires、Cache-control控制
适用于对实时性不敏感的数据,如商品详情页、广告词
不适用价格、库存等要求较高的数据
App客户端缓存
App所需要的如首屏数据缓存下来,如网络异常也有客户端降级的托底数据展示给用户
CDN缓存
有些页面、活动页、图片等服务考虑将推送到离用户最近的CDN节点
有推送机制(内容变更主动推CDN节点)和拉取机制(访问节点,当没有内容回源到服务器拿到内容缓存到节点)
Nginx缓存
- proxy_cache:使用内存级/SSD级代理来缓存内容
- proxy_cache_lock:使用lock机制,将多个回源合并一个,减少回源量,并设置lock超时时间
应用层缓存
应用部署一组Redis,先读本机的Redis获取数据,多机之间使用主从机制同步数据
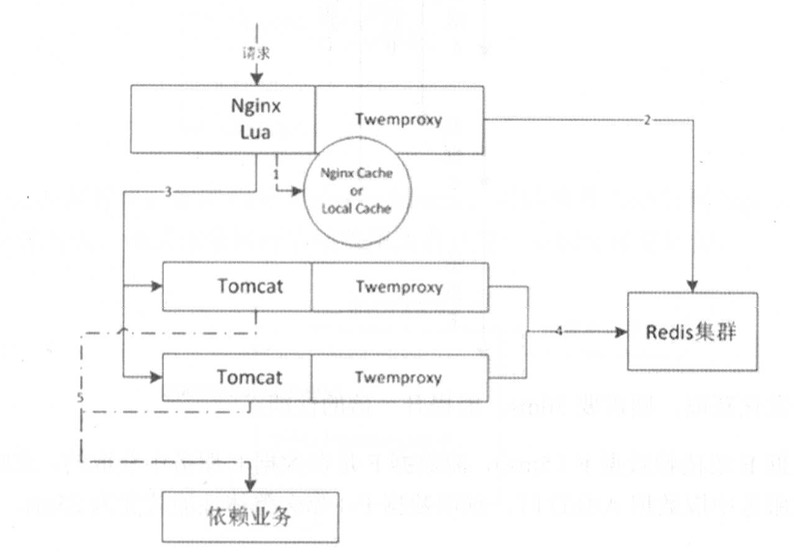
- 先进(nginx+lua)读取本地proxy cache/local cache
- 如果不命中,则接入层会读取分布式Redis集群
- 如果还不命中,则回源到Tomcat,然后读取Tomcat应用堆内的cache
- 如果缓存还没命中,则调用依赖业务来获取数据,然后异步化写到Redis集群
高可用原则
降级
高可用服务,重要设计就是降级开关
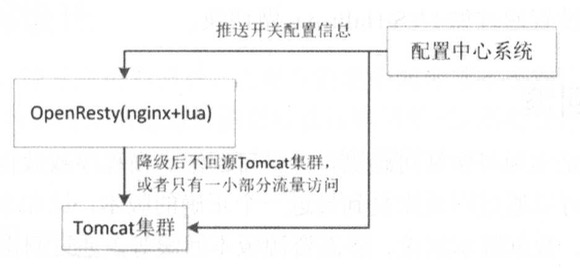
- 开关集中化管理:推送机制把开关推送到各个应用
- 可降级多级读服务:服务调用降级为只读本地缓存、只读分布式缓存、只读默认降级数据
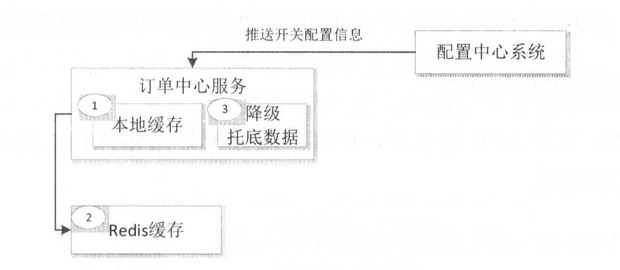
- 开关前置化:如
Nginx->Tomcat;可以将开关前置到Nginx接入层,降级后不回源Tomcat集群或只有一小部分流量访问
限流
防止恶意请求流量、恶意攻击或防止流量超出系统峰值
- 恶意请求只访问到cache
- 对穿透到后端应用的流量用
Nginx的limit模块处理 - 对恶意IP可以使用
nginx deny进行屏蔽
切流量
多机房某个机房挂了或某个机架挂了或某台服务器挂了,都需要如下手段切流量
1:DNS 切换机房入口
2: HttpDns 客户端配置DNS,绕过运营商DNS
3: LVS/HAProxy 切换故障的Nginx接入层
4: Nginx: 切换故障的应用层
可回滚
版本华可审计可追溯
- 事务回滚
- 代码库回滚
- 部署版本回滚
- 数据版本回滚
- 静态资源版本回滚
- 应用配置回滚
业务设计原则
防重设计
如下单扣库存需要防止重复扣减库存,解决方案考虑防重Key、防重表
幂等设计
消息中间件基本不保证不发重复消息
因此重复消息等接口需要设计幂等处理
状态与状态机
交易系统设计中订单状态(待付款、待发货、已发货、完成)和逆向状态(取消、退款)
考虑要不要使用状态机来驱动状态的变更和后续流程节点操作,尤其是状态很多的时候使用状态机能够更好地控制状态迁移
隔离
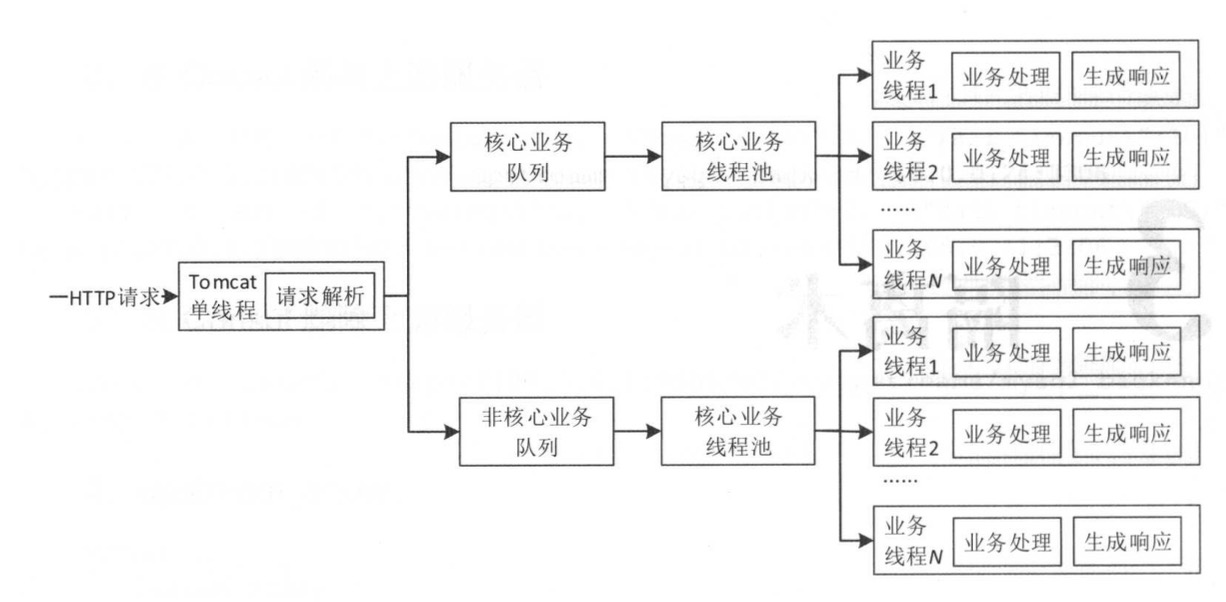
线程隔离
线程隔离主要指线程池隔离,将请求分类交给不同的线程池处理,当一种业务的请求处理发送问题,不会将故障扩散带其他线程池,从而保证其他服务可用
进程隔离
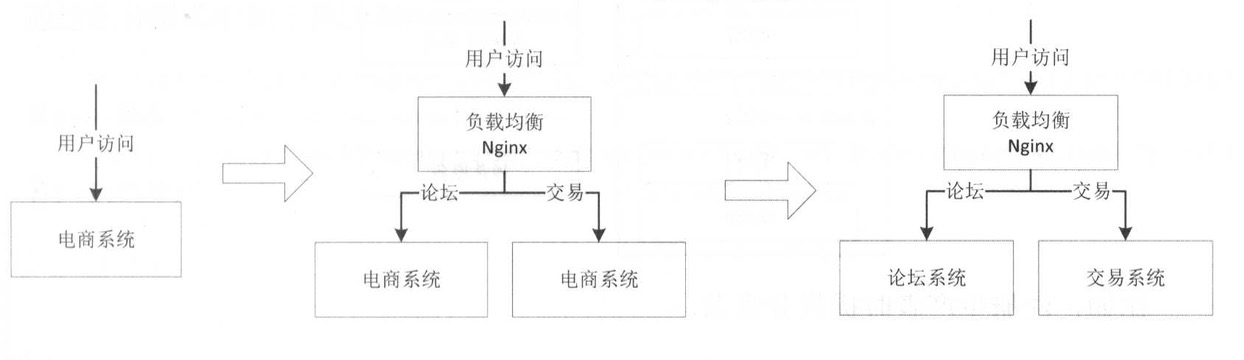
刚开始都是从零到一做系统,而不是上来就系统拆分,这样开发出的大而全系统,系统中某个功能/模块出现问题,整个系统就不可用了
解决方案是部署多个实例,通过均衡负责进行转发,但无法避免某个Bug导致系统不可用的风险
因此较好的方案是拆分多个子系统实现物理隔离,通过进程隔离使得某个子系统出现问题时不会应影响到其他子系统
集群隔离
随系统发展需要服务化技术,通过部署多个服务形成的服务集群,来提升系统容量,多个服务集群进行隔离
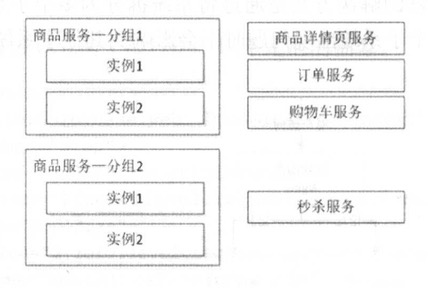
机房隔离
当一个机房服务发送问题时,DNS/负载均衡将请求全部切换另一个机房
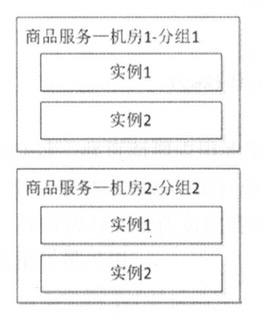
读写隔离
通过主从模式将读和写集群分离,读服务只从Redis集群获取数据,当主Redis集群出现问题,从Redis集群还是可用,从而不影响用户
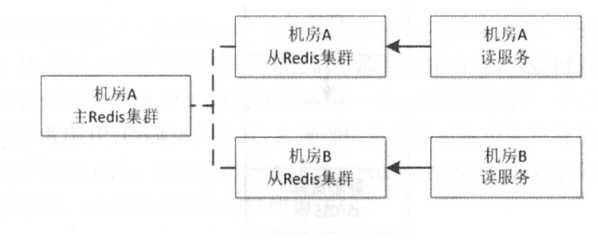
动静隔离
JS/CSS静态资源放入CDN,
热点隔离
秒杀、抢购属于非常适合的热点例子
对于这类热点应用将秒杀和抢购做成独立系统或服务进行隔离,从而保证秒杀和抢购不影响主流程
资源隔离
常见的CPU、磁盘、内存资源都存在竞争问题
使用Docker容器虚拟化进行资源隔离
限流技术
限流算法
常见的限流算法有:令牌桶、漏铜、计数器(粗暴限流实现)
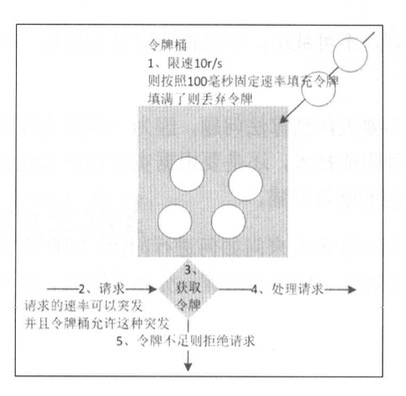
令牌桶
- 假设限制2r/s,则按照500毫秒的固定速率往桶中添加令牌
- 桶中最多存放b个令牌,当桶满时,新添加的令牌被丢弃或拒绝
- 当一个n个字节大小的数据包到达,将从桶中删除n个令牌,接着数据包被发送到网络上
- 如果桶中的令牌不足n个,则不会删除令牌,且该数据包被限流(要么丢弃,要么缓冲区等待)
漏桶算法
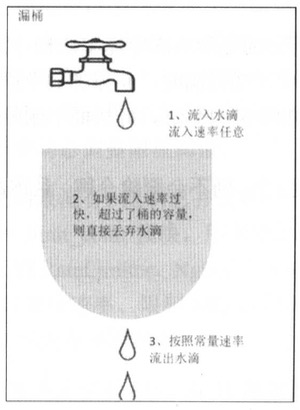
漏铜作为计量工具,可用于流量整形和流量控制
- 一个固定容量的漏桶,按照常量固定速率流出水滴
- 如果桶是空的,则不需要流出水滴
- 可以以任意速率流入水滴到漏桶
- 如果流入水滴超出了桶的容量,则流入的水滴溢出(被丢弃),而漏桶容量是不变的
区别
- 令牌桶允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌或4个令牌,并允许一定程度的突发流量
- 漏桶限制的是常量流出速率,流入请求速率任意,当流入的请求数累积到漏桶容量,则新流入的请求被拒绝
应用级限流
限流总并发/总连接/总请求数
Tomcat的Connector其中一种配置如下几个参数
acceptCount:如果Tomcat线程都忙响应,新来的连接会进入队列排队,超出队列大小拒绝连接
macConnections:瞬时最大连接数,超出会排队等待
maxThreads:Tomcat能启动用来处理请求最大线程数,如果请求处理量一直远远大于最大线程数,会引起响应变慢甚至僵死
限流资源数
对数据库连接、线程采用池技术管理来限制总资源数,如连接池、线程池
限流某个接口的总并发数和请求书
采用Java的AtomicLong或Semaphore进行限流
Hystrix在信号量模式也使用了Semaphore限制某个接口的总并发数
限制某个接口的时间窗请求数
即一个时间窗口内的请求数,如限制某个接口/服务每秒/每分钟/每天的请求数

平滑限流某个接口的请求数
之前的限流不能很好的应对突发请求,即瞬间请求可能都被允许,从而导致一些问题,即没有进行平均速率请求处理
使用Guava的RateLimiter提供的令牌桶算法可用于平滑突发限流和平滑预热限流
1 | RateLimiter limiter = Ratelimiter.create(5); |
- 1:
Ratelimiter.create(5);表示桶容量为5,每秒新增5个令牌,即每隔200毫秒新增一个令牌 - 2:
limiter.acquire(),表示消费一个令牌,如果当前桶有足够令牌,则成功(返回值为0),如果桶中没有令牌,则暂停一段时间(返回值为暂停的时间数量)
分布式限流
Nginx+Lua实现复杂的令牌桶或漏桶算法,从而进行分布式口子上的限流

接入层限流
接入层指请求流量入口,该层主要目的有:负载均衡、非法请求过滤、请求聚合、缓存、降级、A/B测试、服务质量监控
对Nginx接入层限流可以使用Nginx自带的两个模块:连接数限流ngx_http_limit_conn_module或漏桶算法实现的请求限流ngx_http_limit_req_module
降级技术
降级按照是否自动化可分为:
自动开关降级和人工开关降级降级按照功能可分为:
读服务降级和写服务降级降级按照处于系统层次可分为:
多级降级
自动开关降级
自动降级根据系统负载、资源使用情况、SLA等指标进行降级
超时降级
当访问数据/http响应慢, 且该服务不是核心服务可以在超时后自动降级
比如商品详情页上有推荐内容/评价
统计失败次数降级
依赖不稳定API,比如调用外部机票服务,当失败调用次数达到一定阈值自动降级(熔断器),然后异步线程去探测服务是否恢复了,恢复则取消降级
故障降级
如果远程服务(网络故障、DNS故障、HTTP服务返回错误的状态码、RPC服务抛出异常)直接降级
降级后处理方案:默认值、兜底数据(比如广告、提前准备好的静态页面)、缓存(之前访问暂存的一些缓存数据)、降级数据池
限流降级
因访问了过大而导致系统崩溃,开发者会使用限流限制访问量,后续请求就会被降级
降级页面处理方案: 排队页面,无货,错误页
人工开关降级
开关存放在配置文件、数据库、Redis/Zookeeper,定期同步开关数据,通过判断Key的值来决定是否降级
读服务降级
读降级一般采用的策略
- 暂时切换读(降级到读缓存、降级到走静态化)
- 暂时屏蔽读(屏蔽读入口、屏蔽某个读服务)
还有页面静态化
平时网站走动态化渲染商品详情页,到了大促来临之际将其切换为静态化来减少对核心资源的占用,从而提升性能
通过一个程序定期推送静态页到缓存或者生产到磁盘,出问题时直接切过去
写服务降级
写服务大多数场景是不可降级的,不过可以将同步操作转为异步操作,或者限制写的量/比例
正常情况下为同步扣除库存,在性能扛不住时,降级为异步操作
例如秒杀场景可以直接降级为异步,从而保护系统
如下单操作可在大促销时暂时降级,将下单数据写入Redis,等峰值过去再同步回DB
多级降级
缓存是离用户越近越高效,而降级是离用户越近对系统保护得越好
页面JS降级开关:主要控制页面功能的降级,在JS脚本部署功能降级开关,在适当实际开关
接入层降级开关:主要控制请求入口的降级,请求进入后会首先进入接入层,接入层可配种功能降级开关,根据实际情况进行人工/自动降级
应用层降级开关:主要控制业务的降级,在应用中配置相应的功能开关,根据实际业务情况进行自动/人工降级
缓存技术
缓存是系统快速响应中的关键技术,是一组被保存起来以备将来使用的东西
缓存算法
缓存技术专用术语
缓存命中:请求的数据在缓存中没有命中:cache miss如果缓存中有存储空间,没有命中的对象会被存储到缓存中存储成本:当数据存放缓存所需要的时间和空间就是成本缓存失效:当存储在缓存中的数据需要更新,意味着缓存中的数据失效了替代策略:当缓存没有命中,缓存容量也满了,就需要缓存移除旧数据再加新数据
LRU(Least-Recently-Used)
替换最近请求最少的对象, 在CPU缓存淘汰和虚拟内存系统中效果最好
LFU(Least-Frequently-Used)
替换访问次数最少的缓存,保留最常用、最流行的对象
LRU2(Least-Recently-Used2)
LRU的变种,两次访问过的对象放入缓存池,池满后把两次最少使用的缓存对象去除
2Q(Two Queues)
把访问数据放入LRU缓存中,如果对象再访问就转移第二个、更大的LRU缓存
去除缓存对象为保持第一个缓存池是第二个缓存池的1/3,当缓存的访问负载是固定时候,LRU换成LRU2
LRU-Threshold
不缓存超过某一Size的对象,其他和LRU相同
MRU(Most Recently Used)
MRU与LRU相对,移除最近使用最多的对象
FIFO
FIFO通过队列跟踪所有缓存对象,容量满的时候排在前面的缓存会被踢走
RandomCache
随机缓存,随意的替换缓存数据
缓存回收策略
- 基于空间
基于空间指缓存设置了存储空间,如设置为10MB,当达到存储空间上限时,按照一定的策略移除数据
- 基于容量
基于容量指缓存设置了最大大小,当缓存的条目超过最大大小时,按照一定的策略移除旧数据
基于时间
- TTL:存活期,即缓存数据从创建开始直到到期的一个时间段(缓存数据都将过期)
- TTI:空闲期,即缓存数据多久没被访问后移除缓存的时间
浏览器缓存
HTTP 1.1引入实体标签E-TAG, E-TAG是文件或对象的唯一标识,这意味着可以请求一个资源以及提供所持有的文件
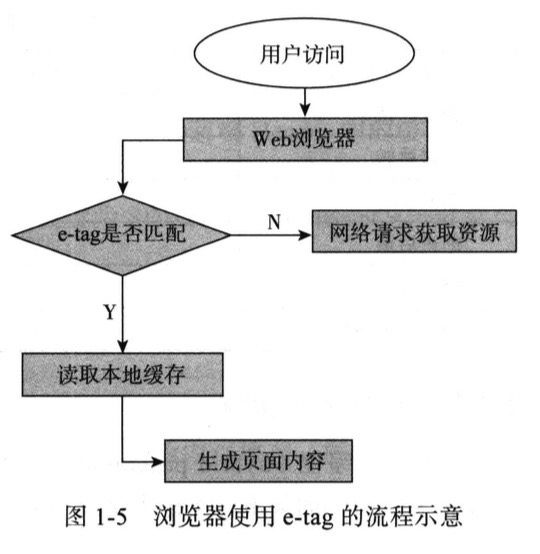
如果某一个文件的E-TAG是有效,那么服务器会生成304-Not Modified应答(浏览器直接从本地缓存取数据)
否则会发送200-OK应答(如果数据有变化,将整个数据重新发给浏览器)
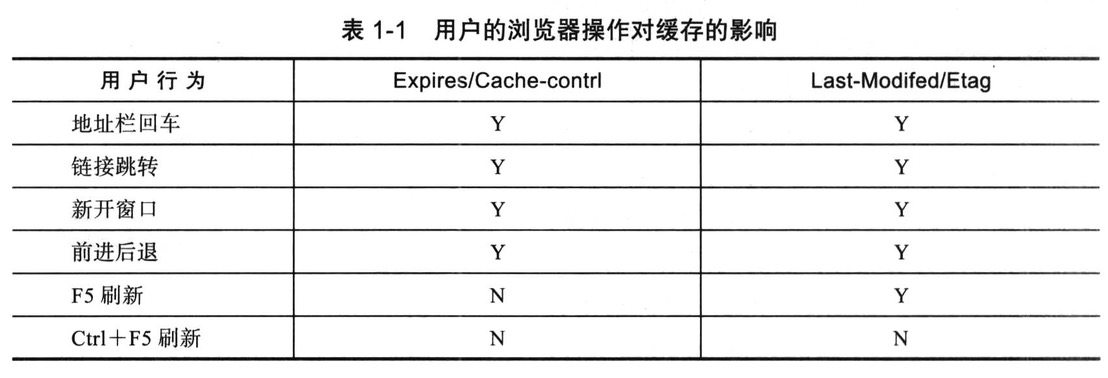
Last-Modified/ETag与Cache-Control/Expires的作用是不一样的,如果检测到本地缓存还在有效的时间范围内,浏览器则直接使用本地缓存,不会发送任何请求
两者在一起使用时,Cache-Control/Expires的优先级要高于Last-modified/ETag (即当本地副本数据根据Cache-Control/Expires发现还在有效期内,则不会发送请求去询问服务器修改时间Last-Modified或标签实体E-Tag)
后端缓存
接入层缓存
Nginx+Lua配合Redis可以在网关进行缓存操作
数据库缓存
Mysql的查询缓存
Query Cache作用于整个Mysql实例,主要用于缓存Mysql中的ResultSet,也就是一条Sql语句执行的结果集,所以仅仅只能针对于Select语句
Query Cache流程
1 | Mysql会根据直接预先设定好的Hash算法将接收到的Select语句以字符串方式进行Hash |
当然数据变化频繁使用Query Cache可能得不偿失
query_cache_size:缓存ResultSet的内存大小query_cache_type:设置在任何场景下使用QueryCache
InnoDB缓存性能
innodb_buffer_pool_size是影响性能的关键参数
用来设置缓存InnoDB索引及数据块的内存区域大小
当操作一个InnoDB表的时候,返回的所有数据或查询过程中用到的任何一个索引块,都会在这个内存区域中查询一遍
table_cache是Mysql重要的性能参数
主要用于设置table高速缓存的数量
当某一连接访问表的时候,Mysql先检查当前已经缓存表的数量,如果已经在缓存中,则直接访问缓存中的表加快查询速度,如果未被缓存则将当前表添加进缓存并进行查询
应用级缓存
多级缓存的系统架构
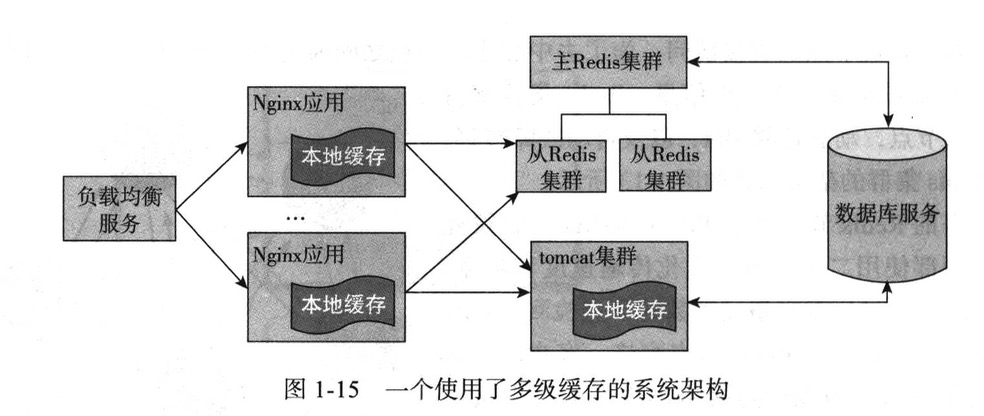
Nginx应用服务器读取本地缓存,实现本地缓存方式Lua Shared Dict,或者面向磁盘或内存的Nginx Proxy Cache,以及本地的Redis实现等
如果本地缓存命中直接返回,如果本地缓存没有命中,就会进一步读取相应的分布式缓存Redis分布式缓存集群
如果分布式缓存命中则直接返回响应数据,并回写到Nginx应用服务器的本地缓存中
如果Redis分布式缓存集群也没有命中,就会回源到Tomcat集群,在回源到Tomcat集群也使用轮询和一致性哈希作为负载均衡算法
在Tomcat集群应用中首先读取本都平台级缓存,如果平台级缓存命中则直接返回数据,并会同步写到主Redis集群,然后再同步到从Redis集群
如果所有缓存都没有命中,则只能查询数据库或者相关的服务获取相关数据并返回,当然数据库也是有缓存的
国内查看评论需要代理~