现存资源
| 集群名称 | 地域 | 节点数量 | 节点池 |
|---|---|---|---|
| 联调 | 华东1 | 5 | 2核16G CentOS 7.6 |
| 生产k8s | 华东1 | 7 | 4核32G Centos7.6 |
| 测试 | 华东1 | 6 | 4核16G Centos7.6 |
资源申请
一阶段需申请资源
| 集群名称 | 地域 | 节点数量 | 节点池 |
|---|---|---|---|
| 实验 | 华东1 | 3 | 2核8G CentOS 7.6 |
- 专用网络VPC ?
- 虚拟交换机
- 网络插件:Flannel、Terway (免费提供选择)
容器运行时:Container、Docker、安全沙箱 (免费提供选择)
Ack套件使用费
- EIP 费用(公网访问): api server给公网ip
- NAT 费用(公网访问): 让vpc拥有公网访问能力
- SLB 费用
2核4G
SLB 费用:¥ 0.561 /时 、¥ 0.680 /GB
EIP 费用:¥ 0.680 /GB
ECS 费用:¥ 1.21 /时
二阶段需申请资源
| 集群名称 | 地域 | 节点数量 | 节点池 |
|---|---|---|---|
| 实验 | 华东1 | 5 | 待定 |
实验内容
集群的操作
- 创建k8s普通集群、Ack托管版(无Master)集群、Ask集群(无Master、Node)
- 升级集群
- 连接操控&join扩容集群
节点的操作
- Ack节点池管理
- 节点的管理
- 节点的调度和运维(亲和、污点)
集群网络
- 理解Terway、Flannel、Calico
- 理解Service、Ingress
- 阿里云容器网络CNI
- 如何给Pod挂载弹性公网IP
- 修改Pod镜像保持IP不变
- Service管理
- 创建服务
- 管理服务
- Service的负载均衡配置注意事项
- 通过Annotation配置负载均衡
- 通过使用已有SLB的服务公开应用
- SLB Ingress管理
- SLB Ingress Controller组件管理
- 使用默认生成的SLB实例
- 使用指定的SLB实例
- 通过Secret配置TLS证书实现HTTPS访问
- Nginx Ingress管理
- 安装Nginx Ingress Controller
- Ingress基本操作
- Ingress高级用法
- 网络管理最佳实践
- 安全组的使用
- IPv6的使用
- 部署高可靠Ingress Controller
- 优化集群DNS
- 使用Ambassador Edge Stack管理Ingress资源
- Serverless集群基于与解析PrivateZone的服务发现
应用
- 工作负载
- 无状态Deployment
- 有状态StatefulSet
- 守护DaemonSet
- 任务Job
- 定时任务CronJob
- 容器组Pod
存储
CSI
- 了解 CSI
- 安装插件
- OSS
- 使用云盘静态存储卷
- 通过控制台使用云盘静态存储卷
- 使用动态云盘卷
- 存储类(StorageClass)
- NAS
- 使用NAS静态存储卷
- 通过控制台使用NAS静态存储卷
FlexVolume
- 了解 FlexVolume
- 安装插件
- OSS
- 使用云盘静态存储卷
- 通过控制台使用云盘静态存储卷
- 使用动态云盘卷
- 存储类(StorageClass)
- NAS
- 使用NAS静态存储卷
- 通过控制台使用NAS静态存储卷
自动伸缩
- 资源层自动伸缩
- 托管节点自动伸缩
- ACK节点和ASK的配合
- 调度层自动伸缩
- HPA实验
- VPA实验
- CronHPA实验
灰度发布
- 使用阿里云的自动模式/手动模式创建灰度发布
- Ingress实现法度恢复和蓝绿发布
总结
- Kubelet通过Eviction Signal来记录监控到的Node节点使用情况。
- Eviction Signal支持:memory.available, nodefs.available, nodefs.inodesFree, imagefs.available, imagefs.inodesFree。
- 通过设置Hard Eviction Thresholds和Soft Eviction Thresholds相关参数来触发Kubelet进行Evict Pods的操作。
- Evict Pods的时候根据Pod QoS和资源使用情况挑选Pods进行Kill。
- Kubelet通过eviction-pressure-transition-period防止Node Condition来回切换引起scheduler做出错误的调度决定。
- Kubelet通过–eviction-minimum-reclaim来保证每次进行资源回收后,Node的最少可用资源,以避免频繁被触发Evict Pods操作。
- 当Node Condition为MemoryPressure时,Scheduler不会调度新的QoS Class为BestEffort的Pods到该Node。
- 当Node Condition为DiskPressure时,Scheduler不会调度任何新的Pods到该Node。
知识点
Node的管理
Node的隔离与恢复
Kubernetes提供了一种机制,既可以将Node纳入调度范围,也可以将Node脱离调度范围。
在spec部分指定unschedulable为true;1
2
3
4
5
6
7
8apVersion:v1
kind:Node
metadata:
name: k8s-node
labels:
kubernetes.io/hostname: k8s-node
spec:
unschedulable: true
1 | kubectl patch node k8s-node '{"spec":{“unschedulable:true”}}' |
如果需要将某个Node重新纳入集群调度范围,则将unschedulable设置为false,再次执行kubectl replace或kubectl patch命令就能恢复系统对该Node的调度。
Node的扩容
Kubernetes集群中,一个新Node的加入是非常简单的。
在新的Node上安装Docker、kubelet和kube-proxy服务,然后配置kubelet和kube-proxy的启动参数,
将Master URL指定为当前Kubernetes集群Master的地址,最后启动这些服务。
通过kubelet默认的自动注册机制,新的Node将会自动加入现有的Kubernetes集群中
Kubernetes资源管理
Pod的两个重要参数:CPU Request与Memory Request
即使系统资源严重不足,也需要保障这些Pod的存活,Kubernetes中该保障机制
- 通过资源限额来确保不同的Pod只能占用指定的资源。
- 允许集群的资源被超额分配,以提高集群的资源利用率。
- 为Pod划分等级,确保不同等级的Pod有不同的服务质量(QoS),资源不足时,低等级的Pod会被清理,以确保高等级的Pod稳定运行。
CPU与Memory是被Pod使用的,因此在配置Pod时可以通过参数CPU Request及Memory Request为其中的每个容器指定所需使用的CPU与Memory量
Kubernetes会根据Request的值去查找有足够资源的Node来调度此Pod,如果没有则调度失败。
一个程序所使用的CPU与Memory是一个动态的量,确切地说是一个范围,跟它的负载密切相关
负载增加时,CPU和Memory的使用量也会增加。因此最准确的说法是某个进程的CPU使用量为0.1个CPU~1个CPU,内存占用则为500MB~1GB。
对应到Kubernetes的Pod容器上,就是下面这4个参数:
spec.container[].resources.requests.cpu;spec.container[].resources.limits.cpu;spec.container[].resources.requests.memory;spec.container[].resources.limits.memory。
limits对应资源量的上限,即最多允许使用这个上限的资源量
对于Memory这种不可压缩资源来说,它的Limit设置就是一个问题了
如果设置得小了当进程在业务繁忙期试图请求超过Limit限制的Memory时,此进程就会被Kubernetes杀掉。
因此Memory的Request与Limit的值需要结合进程的实际需求谨慎设置。
如果不设置CPU或Memory的Limit值,会怎样呢?
在这种情况下该Pod的资源使用量有一个弹性范围,我们不用绞尽脑汁去思考这两个Limit的合理值,但问题也来了,考虑下面的例子:
2
3
运行3天后,Pod A的访问请求大增,内存需要增加到1.5GB,此时Node A的剩余内存只有200MB,由于Pod A新增的内存已经超出系统资源
所以在这种情况下,Pod A就会被Kubernetes杀掉。
Kubernetes提供了另外两个相关对象:LimitRange及ResourceQuota,前者解决request与limit参数的默认值和合法取值范围等问题,后者则解决约束租户的资源配额问题。
计算资源管理
基于Requests和Limits的Pod调度机制
Pod创建成功时,Kubernetes调度器(Scheduler)会为该Pod选择一个节点来执行。
对于每种计算资源(CPU和Memory)而言,每个节点都有一个能用于运行Pod的最大容量值。
调度器在调度时,首先要确保调度后该节点上所有Pod的CPU和内存的Requests总和,不超过该节点能提供给Pod使用的CPU和Memory的最大容量值。
1 | 例如,某个节点上的CPU资源充足,而内存为4GB,其中3GB可以运行Pod,而某Pod的MemoryRequests为1GB、Limits为2GB,那么在这个节点上最多可以运行3个这样的Pod。 |
Requests和Limits的背后机制
kubelet在启动Pod的某个容器时,会将容器的Requests和Limits值转化为相应的容器启动参数传递给容器执行器(Docker或者rkt)
如果容器的执行环境是Docker,那么容器的如下4个参数是这样传递给Docker的。
spec.container[].resources.requests.cpu
spec.container[].resources.limits.cpu
spec.container[].resources.requests.memory
spec.container[].resources.limits.memory
如果一个容器在运行过程中使用了超出了其内存Limits配置的内存限制值,那么它可能会被杀掉,如果这个容器是一个可重启的容器,那么之后它会被kubelet重新启动。
因此对容器的Limits配置需要进行准确测试和评估。与内存Limits不同的是,CPU在容器技术中属于可压缩资源
因此对CPU的Limits配置一般不会因为偶然超标使用而导致容器被系统杀掉。
计算资源相关常见问题分析
- Pod状态为Pending,错误信息为FailedScheduling。如果Kubernetes调度器在集群中找不到合适的节点来运行Pod,那么这个Pod会一直处于未调度状态
- 添加更多的节点到集群中。
- 停止一些不必要的运行中的Pod,释放资源。
- 检查Pod的配置
- 容器被强行终止(Terminated):如果容器使用的资源超过了它配置的Limits,那么该容器可能会被强制终止。
资源配置范围管理(LimitRange)
默认情况下Kubernetes不会对Pod加上CPU和内存限制,这意味着Kubernetes系统中任何Pod都可以使用其所在节点的所有可用的CPU和内存。
通过配置Pod的计算资源Requests和Limits,我们可以限制Pod的资源使用,
但对于Kubernetes集群管理员而言,配置每一个Pod的Requests和Limits是烦琐的,而且很受限制
- 集群中的每个节点都有2GB内存,集群管理员不希望任何Pod申请超过2GB的内存
- 集群由同一个组织中的两个团队共享,分别运行生产环境和开发环境。生产环境最多可以使用8GB内存,而开发环境最多可以使用512MB内存。这两个环境创建不同的命名空间,并为每个命名空间设置不同的限制来满足这个需求。
- 用户创建Pod时使用的资源可能会刚好比整个机器资源的上限稍小,而恰好剩下的资源大小非常尴尬,不足以运行其他任务但整个集群加起来又非常浪费
针对这些需求,Kubernetes提供了LimitRange机制对Pod和容器的Requests和Limits配置进一步做出限制。
- 创建一个Namespace
- 为Namespace设置LimitRange
1 | apiVersion: v1 |
不论是CPU还是内存,在LimitRange中,Pod和Container都可以设置Min、Max和MaxLimit/Requests Ratio参数
Container还可以设置Default Request和Default Limit参数,而Pod不能设置Default Request和Default Limit参数。
对Pod和Container的参数解释如下
- Container的Min(上面的100m和3Mi)是Pod中所有容器的Requests值下限;Container的Max(上面的2和1Gi)是Pod中所有容器的Limits值上限;
- Container的Default Request(上面的200m和100Mi)是Pod中所有未指定Requests值的容器的默认Requests值;Container的Default Limit(上面的300m和200Mi)是Pod中所有未指定Limits值的容器的默认Limits值。
- 对于同一资源类型,这4个参数必须满足以下关系:Min ≤ Default Request ≤ Default Limit ≤Max。
- Pod的Min(上面的200m和6Mi)是Pod中所有容器的Requests值的总和下限;Pod的Max(上面的4和2Gi)是Pod中所有容器的Limits值的总和上限。当容器未指定Requests值或者Limits值时,将使用Container的Default Request值或者Default Limit值。
- Container的Max Limit/Requests Ratio(上面的5和4)限制了Pod中所有容器的Limits值与Requests值的比例上限;而Pod的Max Limit/Requests Ratio(上面的3和2)限制了Pod中所有容器的Limits值总和与Requests值总和的比例上限。
1 | 如果设置了Container的Max,那么对于该类资源而言,整个集群中的所有容器都必须设置Limits,否则无法成功创建。 |
资源服务质量管理(Resource QoS)
在Kubernetes的资源QoS体系中,需要保证高可靠性的Pod可以申请可靠资源,而一些不需要高可靠性的Pod可以申请可靠性较低或者不可靠的资源
Kubernetes中Pod的Requests和Limits资源配置有如下特点。
- 如果Pod配置的Requests值等于Limits值,那么该Pod可以获得的资源是完全可靠的。
- 如果Pod的Requests值小于Limits值,那么该Pod获得的资源可分成两部分:
- 完全可靠的资源,资源量的大小等于Requests值;
- 不可靠的资源,资源量最大等于Limits与Requests的差额,这份不可靠的资源能够申请到多少,取决于当时主机上容器可用资源的余量。
通过这种机制Kubernetes可以实现节点资源的超售(Over Subscription)
比如在CPU完全充足的情况下,某机器共有32GiB内存可提供给容器使用,容器配置为Requests值1GiB,Limits值为2GiB
那么在该机器上最多可以同时运行32个容器,每个容器最多可以使用2GiB内存
如果这些容器的内存使用峰值能错开,那么所有容器都可以正常运行。
Requests和Limits对不同计算资源类型的限制机制
容器的资源配置满足以下两个条件:
- Requests<=节点可用资源
- Requests<=Limits。
可压缩资源(CPU)
- Pod可以得到Pod的Requests配置的CPU使用量,而能否使用超过Requests值的部分取决于系统的负载和调度以及Limit。
- 空闲CPU资源按照容器Requests值的比例分配。
2
3
4
那么A和B恰好得到在它们的Requests中定义的CPU用量:即1CPU和2CPU。
如果A和B都需要更多的CPU资源,而恰好此时系统的其他任务释放出1.5CPU
那么这1.5CPU将按照A和B的Requests值的比例1∶2分配给A和B,即最终A可使用1.5CPU,B可使用3CPU。
- 如果Pod使用了超过在Limits 10中配置的CPU用量,那么cgroups会对Pod中的容器的CPU使用进行限流(Throttled);如果Pod没有配置Limits 10,那么Pod会尝试抢占所有空闲的CPU资源
不可压缩资源(内存)
- Pod可以得到在Requests中配置的内存。如果Pod使用的内存量小于它的Requests的配置,那么这个Pod可以正常运行(除非出现操作系统级别的内存不足等严重问题);如果Pod使用的内存量超过了它的Requests的配置,那么这个Pod有可能被Kubernetes杀掉;
2
3
4
此时程序压力增大Pod B向系统申请的总量不超过自己的Requests值的内存,那么Kubernetes可能会直接杀掉Pod A;
另外一种情况是Pod A使用了超过Requests而不到Limits的内存量,此时Kubernetes将一个新的Pod调度到这台机器上,新的Pod需要使用内存
而只有Pod A使用了超过了自己的Requests值的内存,那么Kubernetes也可能会杀掉Pod A来释放内存资源。
- 如果Pod使用的内存量超过了它的Limits设置,那么操作系统内核会杀掉Pod所有容器的所有进程中使用内存最多的一个,直到内存不超过Limits为止
对调度策略的影响
- Kubernetes的kubelet通过计算Pod中所有容器的Requests的总和来决定对Pod的调度。
- 不管是CPU还是内存,Kubernetes调度器和kubelet都会确保节点上所有Pod的Requests的总和不会超过在该节点上可分配给容器使用的资源容量上限。
服务质量等级(QoS Classes)
在一个超用(Over Committed,容器Limits总和大于系统容量上限)系统中,由于容器负载的波动可能导致操作系统的资源不足,最终可能导致部分容器被杀掉。
在这种情况下,我们当然会希望优先杀掉那些不太重要的容器,那么如何衡量重要程度呢?
Kubernetes将容器划分成3个QoS等级:Guaranteed(完全可靠的)、Burstable(弹性波动、较可靠的)和BestEffort(尽力而为、不太可靠的)
这三种优先级依次递减
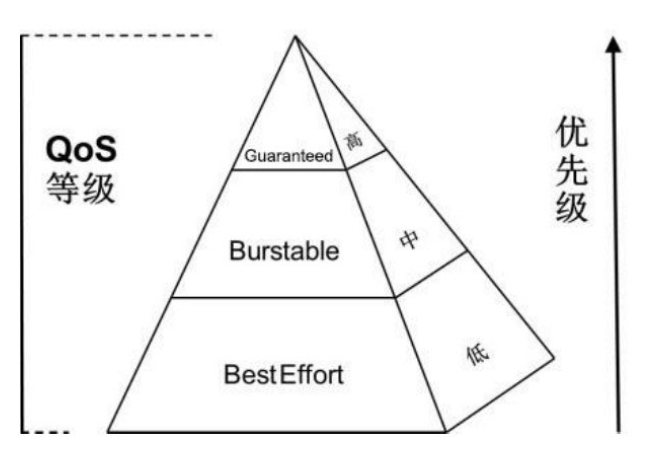
为了简化模式及避免引入太多的复杂性,QoS级别直接由Requests和Limits来定义
Guaranteed
Pod中的所有容器对所有资源类型都定义了Limits和Requests,并且所有容器的Limits值都和Requests值全部相等(且都不为0),那么该Pod的QoS级别就是Guaranteed。
BestEffort
如果Pod中所有容器都未定义资源配置(Requests和Limits都未定义),那么该Pod的QoS级别就是BestEffort。
Burstable
当一个Pod既不为Guaranteed级别,也不为BestEffort级别时,该Pod的QoS级别就是Burstable。
Burstable级别的Pod包括两种情况。
- 第1种情况:Pod中的一部分容器在一种或多种资源类型的资源配置中定义了Requests值和Limits值(都不为0),且Requests值小于Limits值;
- 第2种情况:Pod中的一部分容器未定义资源配置(Requests和Limits都未定义)。
注意:在容器未定义Limits时,Limits值默认等于节点资源容量的上限。
Kubernetes QoS的工作特点
由于内存是不可压缩的资源,所以针对内存资源紧缺的情况,会按照以下逻辑进行处理。
- BestEffort Pod的优先级最低,在这类Pod中运行的进程会在系统内存紧缺时被第一优先杀掉。
- Burstable Pod的优先级居中,这类Pod初始时会分配较少的可靠资源,但可以按需申请更多的资源。
- Guaranteed Pod的优先级最高,而且一般情况下这类Pod只要不超过其资源Limits的限制就不会被杀掉。
OOM计分系统
OOM(Out Of Memory)计分规则包括如下内容。
- OOM计分的计算方法为:计算进程使用内存在系统中占的百分比,取其中不含百分号的数值,再乘以10的结果,这个结果是进程OOM的基础分;
将进程OOM基础分的分值再加上这个进程的OOM分数调整值OOM_SCORE_ADJ的值,作为进程OOM的最终分值(除root启动的进程外)。
在系统发生OOM时,OOM Killer会优先杀掉OOM计分更高的进程。 - 进程的OOM计分的基本分数值范围是0~1000,如果A进程的调整值OOM_SCORE_ADJ减去B进程的调整值的结果大于1000,那么A进程的OOM计分最终值必然大于B进程,会优先杀掉A进程。
- 不论调整OOM_SCORE_ADJ值为多少,任何进程的最终分值范围也是0~1000。
| Service 质量 | oom_score_adj |
|---|---|
| Guaranteed | -998 |
| Burstable | min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
| BestEffort | 1000 |
- BestEffort Pod设置OOM_SCORE_ADJ调整值为1000,因此BestEffort Pod中容器里所有进程的OOM最终分肯定是1000。
- Guaranteed Pod设置OOM_SCORE_ADJ调整值为-998,因此Guaranteed Pod中容器里所有进程的OOM最终分一般是0或者1(因为基础分不可能是1000)。
- Burstable Pod规则分情况说明
1
2
3
4
5
6
7
8
9如果Burstable Pod的内存Requests超过了系统可用内存的99.8%,那么这个Pod的OOM_SCORE_ADJ调整值固定为2;
否则设置OOM_SCORE_ADJ调整值为1000-10×(% of memory requested);
如果内存Requests为0,那么OOM_SCORE_ADJ调整值固定为999。
这样的规则能确保OOM_SCORE_ADJ调整值的范围为2~999,而Burstable Pod中所有进程的OOM最终分数范围为2~1000。
Burstable Pod进程的OOM最终分数始终大于Guaranteed Pod的进程得分,因此它们会被优先杀掉。
如果一个Burstable Pod使用的内存比它的内存Requests少,那么可以肯定的是它的所有进程的OOM最终分数会小于1000,此时能确保它的优先级高于BestEffort Pod。
如果在一个Burstable Pod的某个容器中某个进程使用的内存比容器的Requests值高,那么这个进程的OOM最终分数会是1000,否则它的OOM最终分会小于1000。
假设在下面的容器中有一个占用内存非常大的进程,那么当一个使用内存超过其Requests的Burstable Pod与另外一个使用内存少于其Requests的Burstable Pod发生内存竞争冲突时,前者的进程会被系统杀掉。
如果在一个Burstable Pod内部有多个进程的多个容器发生内存竞争冲突,那么此时OOM评分只能作为参考,不能保证完全按照资源配置的定义来执行OOM Kill。
OOM还有一些特殊的计分规则,如下所述。
- kubelet进程和Docker进程的调整值OOM_SCORE_ADJ为-998。
- 如果配置进程调整值OOM_SCORE_ADJ为-999,那么这类进程不会被OOM Killer杀掉。
QoS的需要解决的问题
- 当前的QoS策略都是假定主机不启用内存Swap。如果主机启用了Swap,那么上面的QoS策略可能会失效
由于Kubernetes和Docker尚不支持内存Swap空间的隔离机制,所以这一功能暂时还未实现。 - 更丰富的QoS策略。当前的QoS策略都是基于Pod的资源配置(Requests和Limits)来定义的,而资源配置本身又承担着对Pod资源管理和限制的功能。两种不同维度的功能使用同一个参数来配置,可能会导致某些复杂需求无法满足
比如当前Kubernetes无法支持弹性的、高优先级的Pod。自定义QoS优先级能提供更大的灵活性,完美地实现各类需求,但同时会引入更高的复杂性,而且过于灵活的设置会给予用户过高的权限,对系统管理也提出了更大的挑战。
Pod驱逐机制
kubelet需要解决硬件资源紧缺保证Node的稳定
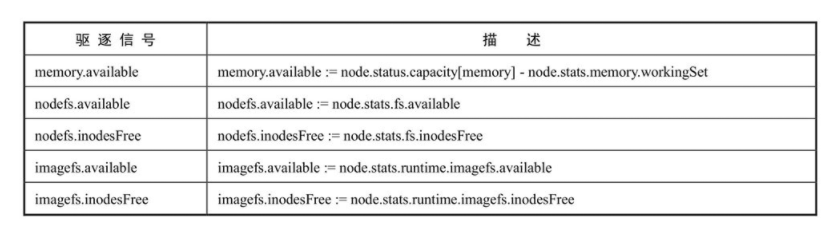
memory.available的值取自cgroupfs
kubelet支持以下两种文件系统。
- (1)nodefs:保存kubelet的卷和守护进程日志等。
- (2)imagefs:在容器运行时保存镜像及可写入层。
驱逐阈值
软驱逐
--eviction-soft:描述驱逐阈值(例如memory.available<1.5GiB),如果满足这一条件的持续时间超过宽限期,就会触发对Pod的驱逐动作。
--eviction-soft-grace-period:驱逐宽限期(例如memory.available=1m30s),用于定义达到软阈值之后持续时间超过多久才进行驱逐。
--eviction-max-pod-grace-period:在达到软阈值后,终止Pod的最大宽限时间(单位为s)。
硬驱逐
--evction-hard=memory.available<100Mi:--eviction-hard驱逐硬阈值,一旦达到阈值,就会触发对Pod的驱逐操作
驱逐频率
kubelet的--housekeeping-interval参数定义了一个时间间隔,kubelet每隔一个这样的时间间隔就会对驱逐阈值进行评估。
节点的状况
kubelet会持续向Master报告节点状态的更新过程,这一频率由参数--node-status-update-frequency指定,默认为10s。
节点状况的抖动
如果一个节点的状况在软阈值的上下抖动,但是又没有超过宽限期,则会导致该节点的相应状态在True和False之间不断变换,可能会对调度的决策过程产生负面影响。
使用参数--eviction-pressure-transition-period(在脱离压力状态前需要等待的时间,默认值为5m0s),为kubelet设置在脱离压力状态之前需要等待的时间。
回收Node级别的资源
kubelet在驱逐用户Pod之前,会尝试回收Node级别的资源。在观测到磁盘压力的情况下,基于服务器是否为容器运行时定义了独立的imagefs,会导致不同的资源回收过程。
有Imagefs的情况
- (1)如果nodefs文件系统达到了驱逐阈值,则kubelet会删掉死掉的Pod、容器来清理空间。
- (2)如果imagefs文件系统达到了驱逐阈值,则kubelet会删掉所有无用的镜像来清理空间。
没有Imagefs的情况
如果nodefs文件系统达到了驱逐阈值,则kubelet会按照下面的顺序来清理空间。
- (1)删除死掉的Pod、容器。
- (2)删除所有无用的镜像。
驱逐用户的Pod
kubelet会按照下面的标准对Pod的驱逐行为进行判断。
- ◎ Pod要求的服务质量。
- ◎ 根据Pod调度请求的被耗尽资源的消耗量。
接下来kubelet按照下面的顺序驱逐Pod。
- ◎ BestEffort:紧缺资源消耗最多的Pod最先被驱逐。
- ◎ Burstable:根据相对请求来判断,紧缺资源消耗最多的Pod最先被驱逐,如果没有Pod超出它们的请求,则策略会瞄准紧缺资源消耗量最大的Pod。
- ◎ Guaranteed:根据相对请求来判断,紧缺资源消耗最多的Pod最先被驱逐,如果没有Pod超出它们的请求,策略会瞄准紧缺资源消耗量最大的Pod。
资源最少回收量
驱逐Pod可能只回收了很少的资源,这就导致了kubelet反复触发驱逐阈值。另外,回收磁盘这样的资源,是需要消耗时间的。
kubelet可以对每种资源都定义minimum-reclaim。
kubelet一旦监测到了资源压力,就会试着回收不少于minimum-reclaim的资源数量,使得资源消耗量回到期望的范围
节点资源紧缺情况下的系统行为
调度器的行为
在节点资源紧缺的情况下(MemoryPressure、DiskPressure),节点会向Master报告这一状况。在Master上运行的调度器(Scheduler)以此为信号,不再继续向该节点调度新的Pod
Node的OOM行为
| Service 质量 | oom_score_adj |
|---|---|
| Guaranteed | -998 |
| Burstable | min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
| BestEffort | 1000 |
kubelet根据Pod的QoS为每个容器都设置了一个oom_score_adj值
如果节点在kubelet能够回收内存之前遭遇了系统的OOM(内存不足),节点则依赖oom_killer的设置进行响应
如果kubelet无法在系统OOM之前回收足够的内存,则oom_killer会根据内存使用比率来计算oom_score,将得出的结果和oom_score_adj相加,得分最高的Pod首先被驱逐。
预期的行为应该是拥有最低服务质量并消耗和调度请求相关内存量最多的容器第一个被结束,以回收内存。
现阶段的问题
1.kubelet无法及时观测到内存压力kubelet
目前从cAdvisor定时获取内存使用状况的统计情况。如果内存使用在这个时间段内发生了快速增长,且kubelet无法观察到MemoryPressure,则可能会触发OOMKiller
2.kubelet可能会错误地驱逐更多的Pod
这也是状态搜集存在时间差导致的。未来可能会通过按需获取根容器的统计信息来减少计算偏差(https://github.com/google/cadvisor/issues/1247)。
Pod Disruption Budget(主动驱逐保护)
- 节点的维护或升级时(kubectl drain)。
- 对应用的自动缩容操作(autoscaling down)。
由于节点不可用(Not Ready)导致的Pod驱逐就不能被称为主动了
对PodDisruptionBudget的定义包括如下两部分。
- Label Selector:用于筛选被管理的Pod。
- minAvailable:指定驱逐过程需要保障的最少Pod数量。
minAvailable可以是一个数字,也可以是一个百分比,例如100%就表示不允许进行主动驱逐。
实践操作
1 | apiVersion: policy/v1beta1 |
资源配额管理(Resource Quotas)
如果一个Kubernetes集群被多个用户或者多个团队共享,就需要考虑资源公平使用的问题,因为某个用户可能会使用超过基于公平原则分配给其的资源量。
我们可以定义资源配额,这个资源配额可以为每个命名空间都提供一个总体的资源使用的限制:它可以限制命名空间中某种类型的对象的总数目上限,也可以设置命名空间中Pod可以使用的计算资源的总上限。
下面的例子展示了一个非常适合使用资源配额来做资源控制管理的场景。
2
- 在名为testing的命名空间中,限制使用1 CPU和1GB内存; 在名为production的命名空间中,资源使用不受限制。
在Master中开启资源配额选型
kube-apiserver的–admission-control参数值中添加ResourceQuota参数进行开启
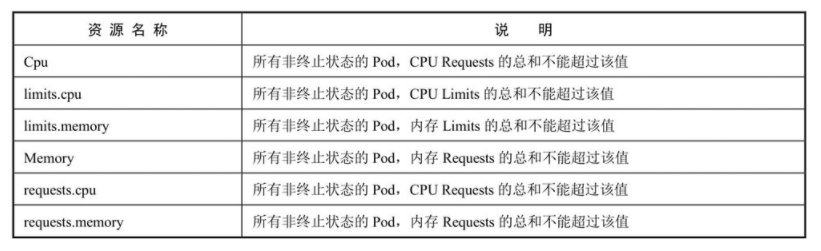
计算资源配额(Compute Resource Quota)
资源配额可以限制一个命名空间中所有Pod的计算资源的总和
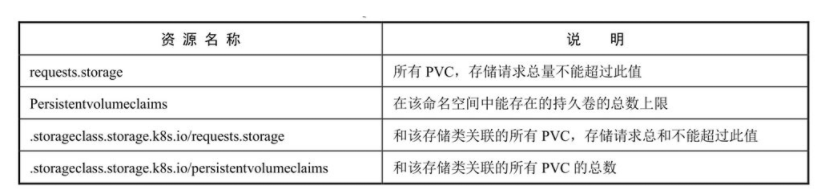
存储资源配额(Volume Count Quota)
可以在给定的命名空间中限制所使用的存储资源(Storage Resources)的总量
对象数量配额(Object Count Quota)
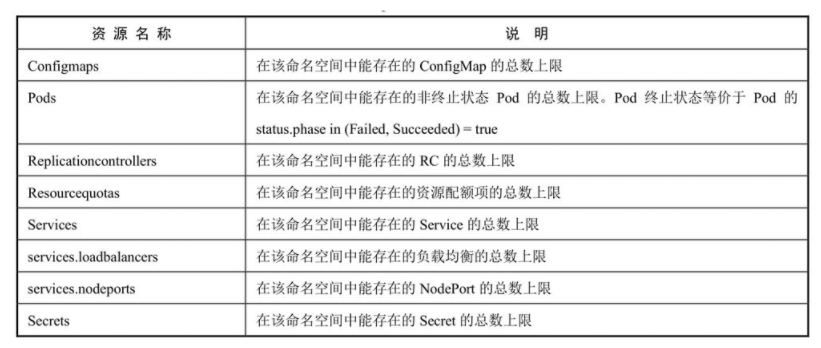
指定类型的对象数量可以被限制
配额的作用域(Quota Scopes)
每项资源配额都可以单独配置一组作用域,配置了作用域的资源配额只会对符合其作用域的资源使用情况进行计量和限制,作用域范围内超过了资源配额的请求都会报验证错误。

BestEffort作用域可以限定资源配额来追踪pods资源的使用;
Terminating、NotTerminating和NotBestEffort这三种作用域可以限定资源配额来追踪以下资源的使用
- cpu
- limits.cpu
- limits.memory
- memory
- pods
- requests.cpu
- requests.memory
在资源配额(ResourceQuota)中设置Requests和Limits
如果在资源配额中指定了requests.cpu或requests.memory,那么它会强制要求每个容器都配置自己的CPU Requests或CPU Limits(可使用LimitRange提供的默认值)。
同理如果在资源配额中指定了limits.cpu或limits.memory,那么它也会强制要求每个容器都配置自己的内存Requests或内存Limits(可使用LimitRange提供的默认值)。
资源配额的定义
1 | apiVersion: v1 |
共享存储机制
- StorageClass的定义,管理员可以将存储资源定义为某种类别(Class),正如存储设备对于自身的配置描述(Profile),例如
快速存储,慢速存储,有数据冗余,无数据冗余等。 - PVC则是用户对存储资源的一个”申请”
- PV是对底层网络共享存储的抽象, 将共享存储定义为一种”资源”
PV详解
PV作为存储资源,主要包括存储能力、访问模式、存储类型、回收策略、后端存储类型等关键信息的设置
1 | apiVersion: v1 |
- 存储能力(Capacity)
- 存储卷模式(Volume Mode)
可选项包括Filesystem(文件系统)和Block(块设备) - 访问模式(Access Modes)
- ReadWriteOnce(RWO):读写权限,并且只能被单个Node挂载。
- ReadOnlyMany(ROX):只读权限,允许被多个Node挂载。
- ReadWriteMany(RWX):读写权限,允许被多个Node挂载。
- 存储类别(Class)
通过storageClassName参数指定一个StorageClass资源对象的名称 - 回收策略(Reclaim Policy)
- 保留:保留数据,需要手工处理。
- 回收空间:简单清除文件的操作
(例如执行rm -rf /thevolume/*命令)。 - 删除:与PV相连的后端存储完成Volume的删除操作(如AWS EBS、GCE PD、Azure Disk、OpenStack Cinder等设备的内部Volume清理)。
- 挂载参数(Mount Options)
- 节点亲和性(Node Affinity)
PVC详解
PVC作为用户对存储资源的需求申请,主要包括存储空间请求、访问模式、PV选择条件和存储类别等信息的设置。
PVC的关键配置参数说明如下。
- 资源请求(Resources):描述对存储资源的请求,目前仅支持request.storage的设置,即存储空间大小。
- 访问模式(Access Modes):PVC也可以设置访问模式,用于描述用户应用对存储资源的访问权限。其三种访问模式的设置与PV的设置相同。
- 存储卷模式(Volume Modes):PVC也可以设置存储卷模式,用于描述希望使用的PV存储卷模式,包括文件系统和块设备。
- PV选择条件(Selector):通过对Label Selector的设置,可使PVC对于系统中已存在的各种PV进行筛选。系统将根据标签选出合适的PV与该PVC进行绑定。选择条件可以使用matchLabels和matchExpressions进行设置,如果两个字段都设置了,则Selector的逻辑将是两组条件同时满足才能完成匹配。
- 存储类别(Class): PVC在定义时可以设定需要的后端存储的类别(通过storageClassName字段指定),以减少对后端存储特性的详细信息的依赖。只有设置了该Class的PV才能被系统选出,并与该PVC进行绑定。
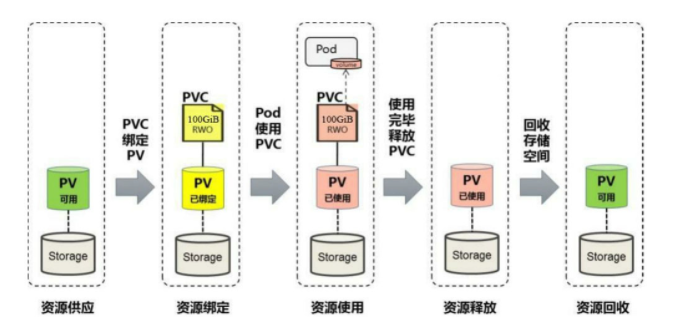
PV和PVC的生命周期
资源供应
Kubernetes支持两种资源的供应模式:静态模式(Static)和动态模式(Dynamic)
- 静态模式:集群管理员手工创建许多PV,在定义PV时需要将后端存储的特性进行设置。
- 动态模式:集群管理员无须手工创建PV,而是通过StorageClass的设置对后端存储进行描述,标记为某种类型。
资源绑定
用户定义好PVC之后,系统将根据PVC对存储资源的请求(存储空间和访问模式)在已存在的PV中选择一个满足PVC要求的PV,一旦找到,就将该PV与用户定义的PVC进行绑定,用户的应用就可以使用这个PVC了。
如果在系统中没有满足PVC要求的PV,PVC则会无限期处于Pending状态,直到等到系统管理员创建了一个符合其要求的PV。
PV一旦绑定到某个PVC上,就会被这个PVC独占,不能再与其他PVC进行绑定了。
在这种情况下,当PVC申请的存储空间比PV的少时,整个PV的空间就都能够为PVC所用,可能会造成资源的浪费。
如果资源供应使用的是动态模式,则系统在为PVC找到合适的StorageClass后,将自动创建一个PV并完成与PVC的绑定。
资源使用
Pod使用Volume的定义,将PVC挂载到容器内的某个路径进行使用。Volume的类型为persistentVolumeClaim。
在容器应用挂载了一个PVC后,就能被持续独占使用。不过多个Pod可以挂载同一个PVC,应用程序需要考虑多个实例共同访问一块存储
资源释放
当用户对存储资源使用完毕后,用户可以删除PVC,与该PVC绑定的PV将会被标记为“已释放”,但还不能立刻与其他PVC进行绑定。
通过之前PVC写入的数据可能还被留在存储设备上,只有在清除之后该PV才能再次使用。
资源回收
对于PV,管理员可以设定回收策略,用于设置与之绑定的PVC释放资源之后如何处理遗留数据的问题。
只有PV的存储空间完成回收,才能供新的PVC绑定和使用。
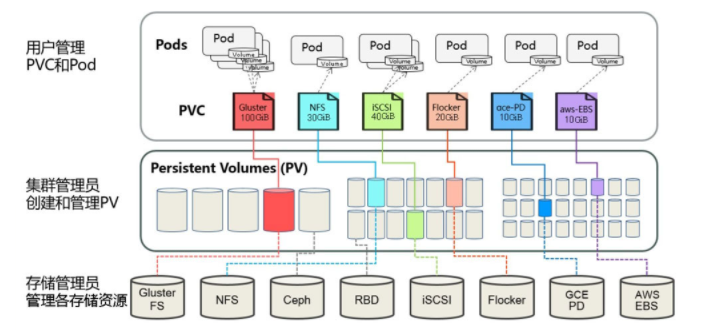
在静态资源供应模式下,通过PV和PVC完成绑定,并供Pod使用的存储管理机制
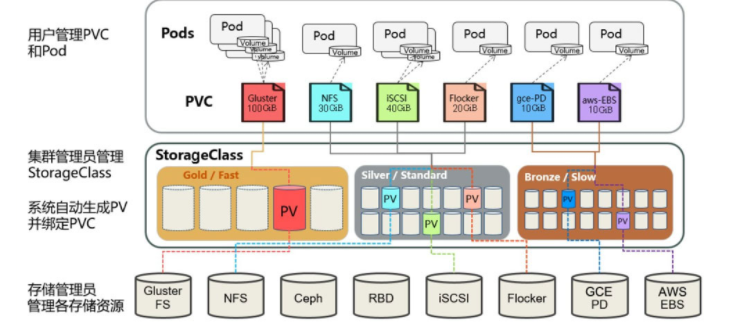
在动态资源供应模式下,通过StorageClass和PVC完成资源动态绑定(系统自动生成PV),并供Pod使用的存储管理机制。
StorageClass详解
StorageClass作为对存储资源的抽象定义,对用户设置的PVC申请屏蔽后端存储的细节,一方面减少了用户对于存储资源细节的关注,另一方面减轻了管理员手工管理PV的工作,由系统自动完成PV的创建和绑定,实现了动态的资源供应。
基于StorageClass的动态资源供应模式将逐步成为云平台的标准存储配置模式。
StorageClass的定义主要包括名称、后端存储的提供者(provisioner)和后端存储的相关参数配置。
StorageClass一旦被创建出来,则将无法修改。如需更改,则只能删除原StorageClass的定义重建。
StorageClass的关键配置参数
- 提供者(Provisioner)
- 参数(Parameters)
Kubesphere迁移阿里Ack
Node情况
| 机器Ip | 配额 | 角色 | 污点 | 容器CountLimit |
|---|---|---|---|---|
| 10.0.0.11 | 2核16g | work | 无 | 110 |
| 10.0.0.12 | 4核16g | work | 无 | 110 |
| 10.209.0.234 | 4核8g | work | 无 | 110 |
| 10.0.0.48 | 8核16g | work | node.kubernetes.io/not-ready=:PreferNoSchedule | 110 |
| 10.0.0.46 | 8核16g | work | trino=:PreferNoSchedule | 110 |
| 10.0.0.47 | 8核16g | master,control-plan | 无 | 110 |
业务Namespaces情况
| 名称 | 容器数量 | Cpu用量 | 内存用量 | 资源配额(ResourceQuota) | LimitRange(Pod、Container) |
|---|---|---|---|---|---|
| mia | 21 | 1.93core | 35g | Cpu无限制、内存无限制、count限制暂无(Pod、Service、Deployment、Job) | 暂无 |
| online | 1(maliang-v1:statefulSet) | 0m | 466m | Cpu无限制、内存无限制、、count限制暂无(Pod、Service、Deployment、Job) | 暂无 |
核心Replica、Stateful、Daemon
| 名称 | namespace | Kind | replicas | resources | Qos | 其他 |
|---|---|---|---|---|---|---|
| reports-v1(旧大表哥,在宋小福首页九宫格中使用) | mia | Deployment | 1 | 暂无资源限制 | BestEffort | 暂无其他设置注意 |
| trino-coordinator(计算引擎Master节点) | mia | Deployment | 1 | 4G/8G,1/6C | Burstable | 设置有点多,具体看yaml吧 |
| trino-worker(计算引擎工作节点) | mia | Deployment | 4 | 4G/8G,1/6C | Burstable | 这个设置了很多nodeSelector、read及live探针,affinity 启动command,configMap,hostAliases |
| exporter-v1(大表哥导出服务) | mia | Deployment | 2 | 无限制 | BestEffort | 这个有env,有python的一端command脚本 |
| pan-backend-v1(大盘子服务端) | mia | Deployment | 1 | 无限制 | BestEffort | 这个没啥特殊要注意的点 |
| pan-client-v1(大盘子前端web服务) | mia | Deployment | 3 | 无限制 | BestEffort | 这个没啥特殊要注意的点 |
| app-search(全文搜索服务) | mia | Deployment | 1 | 无限制 | BestEffort | 这个env设置了很多es的参数,还放了sessionkey |
| miaaa-2-es(大表哥数据同步至 app-search) | mia | Deployment | 1 | 无限制 | BestEffort | 我觉得没啥特殊的 |
| miaaa-v4(未知) | mia | Deployment | 1 | 无限制 | BestEffort | 做了很多的hostAlias,设置了一些env |
| miaaa-client-pre(大表哥预发环境) | mia | Deployment | 1 | 无限制 | BestEffort | 放了configMap, env, command , hostAliases |
| miaaa-client-v4(大表哥前端正式环境) | mia | Deployment | 3 | 无限制 | BestEffort | 没啥说的 |
| logstash(大表哥日志搬运) | mia | Deployment | 1 | 无限制 | BestEffort | 没啥说的 |
集群情况
单独做出一个集群, Ack托管, 无需管理Master
Jenkins的托管如何处理
镜像仓库的处理
配置新用户及证书
进入目录
cd /etc/kubernetes/pki
生产密钥 .key 文件 (pki目录下执行)
umask 077;openssl genrsa -out fanjj.key 2048
openssl req -new -key fanjj.key -out fanjj.csr -subj “/O=k8s/CN=fanjj”
O=组织信息,CN=用户名
根据 .key 和 .csr 文件生成了 .crt 文件 (pki目录下执行)
openssl x509 -req -in fanjj.csr -CA ca.crt -CAkey ca.key \
-CAcreateserial -out fanjj.crt -days 365
新建集群配置 (pki目录下执行)
kubectl config set-cluster k8s –server=https://192.168.2.152:6443 \
–certificate-authority=ca.crt –embed-certs=true –kubeconfig=/root/fanjj.conf
查看集群配置 (pki目录下执行)
kubectl config view –kubeconfig=/root/fanjj.conf
新建用户配置 (pki目录下执行)
kubectl config set-credentials fanjj –client-certificate=fanjj.crt \
–client-key=fanjj.key –embed-certs=true –kubeconfig=/root/fanjj.conf
新建上下文配置 (pki目录下执行)
kubectl config set-context fanjj@k8s –cluster=k8s –user=fanjj \
–kubeconfig=/root/fanjj.conf
切换上下文配置 (pki目录下执行)
kubectl config use-context fanjj@k8s –kubeconfig=/root/fanjj.conf
绑定角色 clusterrole可以自己建立一个
kubectl create clusterrolebinding fanjj –clusterrole=cluster-admin –user=fanjj
1 | curl -X POST https://oapi.dingtalk.com/robot/send?access_token=c9d95fbd615adcabc8805204f35d21b8811cb5809a6b2397a60cf6b7bd742941 -H "Content-Type: application/json" -d '{msgtype:"markdown","markdown":{"title":"部署成功","text":"## 部署成功\n - 构建人:沈伟-@15216821371\n - 工程:gateway\n - 稳定运行"},"at":{"atMobiles":[15216821371],"isAtAll": false}}' |
Sealos 使用问题
遇到Schedule或者Controller挂了
请到master节点的/etc/kubernetes/manifests目录下, kube-scheduler.yaml/kube-controller-manager.yaml设置以下这两个参数
1 | - --leader-elect-lease-duration=15s |
LibC
编译内核
镜像下载:https://cdn.kernel.org/pub/linux/kernel/v5.x/
修复内核配置:https://unix.stackexchange.com/questions/680261/preparing-the-installer-to-update-linux-kernel-in-a-virtualbox-causes-errors-con
证书相关:https://blog.csdn.net/m0_47696151/article/details/121574718
Kafka命令大全
创建一个主题:./bin/kafka-topics.sh –bootstrap-server localhost:9092 –create –replication-factor 1 –partitions 1 –topic test
查看所有主题:./bin/kafka-topics.sh –bootstrap-server localhost:9092 –list
查看某个主题的详细信息:./bin/kafka-topics.sh –bootstrap-server localhost:9092 –describe –topic dev_apiInfo_A_low
删除一个主题:./bin/kafka-topics.sh –bootstrap-server localhost:9092 –delete –topic dev_apiInfo_A_low
发送消息到一个主题:./bin/kafka-console-producer.sh –broker-list localhost:9092 –topic test
从一个主题消费消息:./bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic test –from-beginning
在一个消费者组中消费消息:./bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic test –group test-group
// 查看消费偏移量
./bin/kafka-consumer-groups.sh –bootstrap-server localhost:9092 –describe –group dataService_consumer
./bin/kafka-consumer-groups.sh –bootstrap-server localhost:9092 –describe –group proxyService_consumer
// 更改消费偏移量
./bin/kafka-consumer-groups.sh –bootstrap-server localhost:9092 –group dataService_consumer –reset-offsets –to-offset 165000 –topic dev_apiInfo_A_low –execute
./bin/kafka-consumer-groups.sh –bootstrap-server localhost:9092 –group dataService_consumer –topic dev_raspUpload_A_low –reset-offsets –to-latest –execute
// 更改topic的分区数量
./bin/kafka-topics.sh –bootstrap-server localhost:9092 –alter –topic dev_flowUpload_A_low –partitions 3
1、DaemonAgent, 最开始产品覆盖面, DevOps构建SCA、开发测试Iast, 缺运行时环境的应用侧安全,朝着运行时的应用资产安全+Rasp插件做; 提取软件成分、Api等应用资产及外围安全也有Rasp防护, 于是DaemonAgent一季度造出搜集器和扫描器、搜集器参考Faclo(Sysdiag 小佑科技的参考商)、扫描器引用来源SCA客户端(用同一套分析器, 引出Scanner的Command命令解析器区别于WhaleFall, 结果包装输出SBOM和自带漏洞库); 这一套Q1上了之后没有做产品化等产品设计
Q2 Falco本地化规则引擎,本地化一是抄思想不抄代码,二是c++工程组员接受度、三是和Scanner融合考虑,开始推进Golang规则引擎; 期间也在等产品设计, 等到后来还是先往DaemonAgent堆功能,输出了技术的原理给产品, 造3.20;3.21这些系列
2、新架构, 分两期; 理论上优化代码为主,然后重点往横向扩容方向堆机器解决性能痛点
二期的时间跨度拉的是长, 拉长是任务的清晰度规划和估时模糊, 一些细节段做的时候不理方案, 评估380多个口子做
方案梳理落档没有这个习惯, 造成技术实现是一个个小孤岛, 协调的人要各个孤岛上来回跳
3、能力或者说认知上面, 做事情两个人一个小团队去推进, 对别的事情感知度不大的、做好自己份内事; 还是经常分享为主吧
切换内核
sudo vi /etc/default/grub
GRUB_DEFAULT=0
0代表第一项系统内核镜像
最后生成一下配置
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
升级gcc
sudo yum install devtoolset-7-gcc*
Bpf常用函数
以下是一些常用的eBPF函数列表:
- bpf_map_lookup_elem: 在BPF Map中查找指定的元素,并返回其值。
- bpf_map_update_elem: 向BPF Map中插入或更新指定的元素。
- bpf_trace_printk: 输出调试信息到内核日志中,方便调试eBPF程序。
- bpf_get_current_comm: 获取当前进程的名称,用于调试和监控。
- bpf_get_smp_processor_id: 获取当前CPU的ID,用于实现CPU亲和性。
- bpf_skb_load_bytes: 加载网络数据包中指定偏移量和长度的字节数据,用于网络包过滤和分析。
- bpf_skb_store_bytes: 在网络数据包中指定偏移量处写入指定长度的字节数据,用于网络包修改。
- bpf_perf_event_output: 将指定的数据写入性能事件流,用于实现性能分析和监控。
- bpf_ktime_get_ns: 获取当前系统时间戳,用于实现时间相关的功能。
- bpf_xdp_adjust_head: 调整网络数据包的头部偏移量,用于实现网络数据包修改和处理。
- bpf_skb_get_tunnel_key: 获取网络数据包中的隧道键值,用于网络虚拟化和隧道协议处理。
- bpf_getsockopt: 获取套接字选项的值,用于套接字编程和网络协议处理。
- bpf_setsockopt: 设置套接字选项的值,用于套接字编程和网络协议处理。
- bpf_clone_redirect: 创建一个进程副本,并重定向其网络流量,用于实现网络流量控制和隔离。
- bpf_redirect: 重定向网络流量到指定的网络接口或套接字,用于实现网络流量控制和重定向。
增加k8s WebHook
–audit-webhook-config-file=/etc/kubernetes/audit-webhook-config.yaml
–audit-webhook-batch-max-wait=1s
–audit-webhook-batch-max-size=100
audit-webhook-config.yaml
apiVersion: v1
clusters:
- cluster:
server: http://192.168.2.174:9765/k8s-audit
name: metric
contexts: - context:
cluster: metric
user: “”
name: default-context
current-context: default-context
kind: Config
preferences: {}
users: []
挂载设置
echo 1 > /proc/sys/fs/may_detach_mounts
windows设置静态路由
route add 100.64.2.27 mask 255.255.255.255 192.168.2.172
route add 192.168.2.172 mask 255.255.255.255 192.168.66.1
route CHANGE 100.64.2.27 MASK 255.255.255.255 192.168.66.1 IF 16
Linux设置静态路由
sudo ip route add 10.244.1.5/32 via 192.168.2.x
端口转发:使用端口转发技术,将从开发机发出的数据包转发到 k8s 集群中的服务器。具体的操作方式可以使用工具如 socat、netcat、ssh 等实现,例如可以在开发机上执行以下命令:
$ socat tcp-listen:8080,fork tcp:192.168.2.172:80
该命令将在开发机的 8080 端口上启动一个 TCP 监听器,当有数据包到达时,将数据包转发到 k8s 集群中的服务器的 80 端口。
SSH 隧道:使用 SSH 隧道技术,将从开发机发出的数据包通过 SSH 连接隧道转发到 k8s 集群中的服务器。具体的操作方式可以使用工具如 ssh、autossh 等实现,例如可以在开发机上执行以下命令:
$ ssh -L 8080:192.168.2.172:80 user@192.168.2.172
该命令将在开发机上启动一个 SSH 连接隧道,将本地的 8080 端口转发到 k8s 集群中的服务器的 80 端口。在隧道建立后,您可以在开发机上通过访问 http://localhost:8080 来访问 k8s 集群中的 Pod。
启动集群
同步时间
yum -y install ntpdate
ntpdate ntp1.aliyun.com
astpos run localhost/labring/kubernetes-docker:v1.24.10-4.1.6-amd64 \
localhost/labring/flannel:v0.20.2-amd64 \
localhost/labring/helm:v3.8.2 –masters 192.168.2.177 –nodes 192.168.2.178,192.168.2.179 –passwd TcsecK8s@2023test
astpos run 192.168.2.171:5000/astp/infra:1.0.1 –env PGSQL_NODE=192.168.2.178 –env NFS_IP=192.168.2.178 –env WEB_NODE=192.168.2.179
astpos run localhost/kubernetes-docker:v1.24.10-4.1.6-amd64 localhost/labring/kube-ovn:v1.10.5 localhost/helm:v3.8.2 –masters=192.168.2.171 –nodes=192.168.2.172,192.168.2.173,192.168.2.174 -p TcsecK8s@2023nw
astpos run labring/kubernetes:v1.24.0 labring/calico:v3.22.1 labring/helm:v3.8.2 –masters=192.168.2.171 –nodes=192.168.2.172,192.168.2.173,192.168.2.174 -p TcsecK8s@2023nw
es相关命令
调整副本数
1 | curl -XPUT 'http://192.168.2.152:9200/test_index/_settings' -d '{ |
调整分片数
1 | curl -XPUT 'http://localhost:9200/wwh_test2/' -d '{ |
1 | curl -X POST -H 'Content-Type: application/json' 'http://100.64.0.5:9200/app_hole_log_list_v3-2023051118380989/_search' -d '{"query":{"bool":{"must":[{"match_all":{}}],"must_not":[],"should":[]}},"from":0,"size":10,"sort":[],"aggs":{}}' |
网络相关命令
sudo route add default gw 172.19.66.2
sudo ifconfig ens33 172.19.66.190/24 up
qume启动麒麟机器命令
qemu-system-aarch64.exe -m 8192 -cpu cortex-a72 -smp 8,sockets=4,cores=2 -M virt -bios E:\Kylin\Kylin\QEMU_EFI.fd -device VGA -device nec-usb-xhci -device usb-mouse -device usb-kbd -drive if=none,file=E:\Kylin\Kylin\kylindisk.qcow2,id=hd0 -device virtio-blk-device,drive=hd0 -drive if=none,file=,id=cdrom,media=cdrom -device virtio-scsi-device -device scsi-cd,drive=cdrom -net nic -net user,hostfwd=tcp::2222-:22
astp/Tcsec@2019
root/Tcsec@1947
./python_loader –script xxx.py
conda
conda info -e
conda activate base
k8s密码
192.168.2.171
TcsecK8s@2022nw
192.168.2.179
TcsecK8s@2023test
192.168.2.152
TcsecK8s@2022
麒麟服务器
外网:192.168.2.205 tcsec /Ngcdc@2014
内网:192.168.101.151 tcsec /Ngcdc@2014
kube-ovn
kubect get node
kubect get subnet 查看子网情况
kubect get ip 查看ip分配情况
kubectl ko nbctl show 查看北向数据库
子网
1 | apiVersion: kubeovn.io/v1 |
kube-ovn的service是用了ovn的loadbalance
而不是用了kubeproxy的iptables
网关
查看路由表
kubectl ko nbctl lr-route-list ovn-cluster
编辑子网
kubect edit subnets.kubeovn.io subnet1
Es
- 查看占用排序: curl -XGET “http://192.168.2.152:9200/_cat/indices?v&s=store.size:desc"
- 删除索引: curl -X DELETE “http://192.168.2.152:9200/sw*"
SCA
https://192.168.2.140:10000/login
https://192.168.2.78:10000/login
Tcsec Tcsec1947
SAST
dataFlowEngine来源于shiftLeft的开源产品
antlr4另一个编译解释器、替代gcc和javac、语言支持
javasrc cpg的导出
jimple class的cpg soot解析类,生成cpg
semanticcpg 语法的cpg
x2cpg
fortify
证书
查看证书到期时间
openssl x509 -noout -in your_certificate.crt -dates
Debug
kube-debug -container “88e50e289640” -debugport 38080
kube-debug -localhost
kube-debug -node “192.168.1.13” -debugport 38081
kube-debug -pod “astp-core-84d99f5478-ng8wh” -namespace “daily” -kubeconfig “/etc/kubernetes/admin.conf” -debugport 38082
kube-debug -pod “postgres-5979894b7c-b6qhz” -namespace “infra” -kubeconfig “/etc/kubernetes/admin.conf” -debugport 38082
./kube-debug -pod “postgres-5979894b7c-b6qhz” -namespace “infra” -kubeconfig “/etc/kubernetes/admin.conf” -debugport 28080
vmtool –action getInstances –className java.util.concurrent.ConcurrentHashMap –limit 1000 –express ‘instances[*].size()’
国内查看评论需要代理~