RSS(receive side scaling):网卡多队列
RPS(receive packet Steering):RSS的软件实现
RFS(receive flwo Steering): 基于flow的RPS
Accelerated RFS: RFS的硬件实现
XPS(transmit packet Steering):应用在发送方向
GRO: Generic Receive Offloading
Large Receive Offloading (LRO) 是一个硬件优化,GRO 是 LRO 的一种软件实现。
两种方案的主要思想都是:通过合并“足够类似”的包来减少传送给网络栈的包数,这有助于减少 CPU 的使用量。
例如考虑大文件传输的场景,包的数量非常多,大部分包都是一段文件数据。相比于每次都将小包送到网络栈,可以将收到的小包合并成一个很大的包再送到网络栈。
GRO 使协议层只需处理一个 header,而将包含大量数据的整个大包送到用户程序。
RSS: Receive Side Scaling
RPS: Receive Packet Steering
每个 NAPI 变量都会运行在相应 CPU 的软中断的上下文中。而且,触发硬中断的这个 CPU 接下来会负责执行相应的软中断处理函数来收包。
换言之同一个 CPU 既处理硬中断,又处理相应的软中断。
一些网卡(例如 Intel I350)在硬件层支持多队列。这意味着收进来的包会被通过 DMA 放到位于不同内存的队列上,而不同的队列有相应的 NAPI 变量管理软中断 poll()过程。
因此多个 CPU 同时处理从网卡来的中断,处理收包过程。
这个特性被称作 RSS(Receive Side Scaling,接收端扩展)。
RPS (Receive Packet Steering,接收包控制,接收包引导)是 RSS 的一种软件实现。
因为是软件实现的,意味着任何网卡都可以使用这个功能,即便是那些只有一个接收队列的网卡。
但是因为它是软件实现的,这意味着 RPS 只能在 packet 通过 DMA 进入内存后,RPS 才能开始工 作。
RFS: Receive Flow Steering
RFS(Receive flow steering)和 RPS 配合使用。
RPS 试图在 CPU 之间平衡收包,但是没考虑数据的本地性问题,如何最大化 CPU 缓存的命中率。
RFS 将属于相同 flow 的包送到相同的 CPU 进行处理,可以提高缓存命中率。
XPS: Transmit Packet Steering
XPS是针对发送方向的,即从网卡发送出去时,如果有多个发送队列,选择使用哪个队列。
可通过如下命令设置,此命令表示运行在f指定的cpu上的应用调用socket发送的数据会从网卡的tx-n队列发送出去。echo f > /sys/class/net/<dev>/queues/tx-<n>/xps_cpus
GRO、RSS、RPS、XPS、RFS
流程图
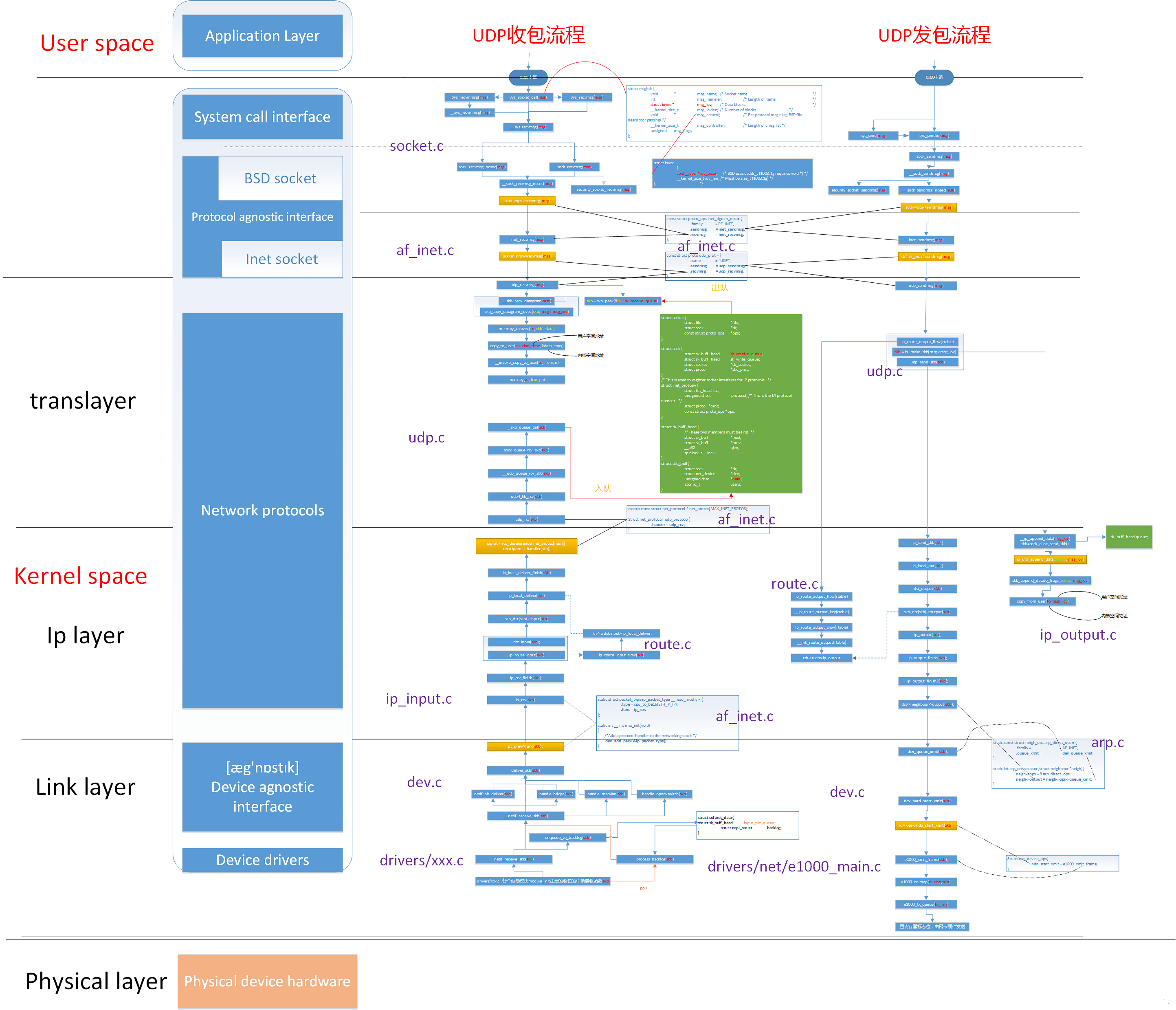
UDP发包流程
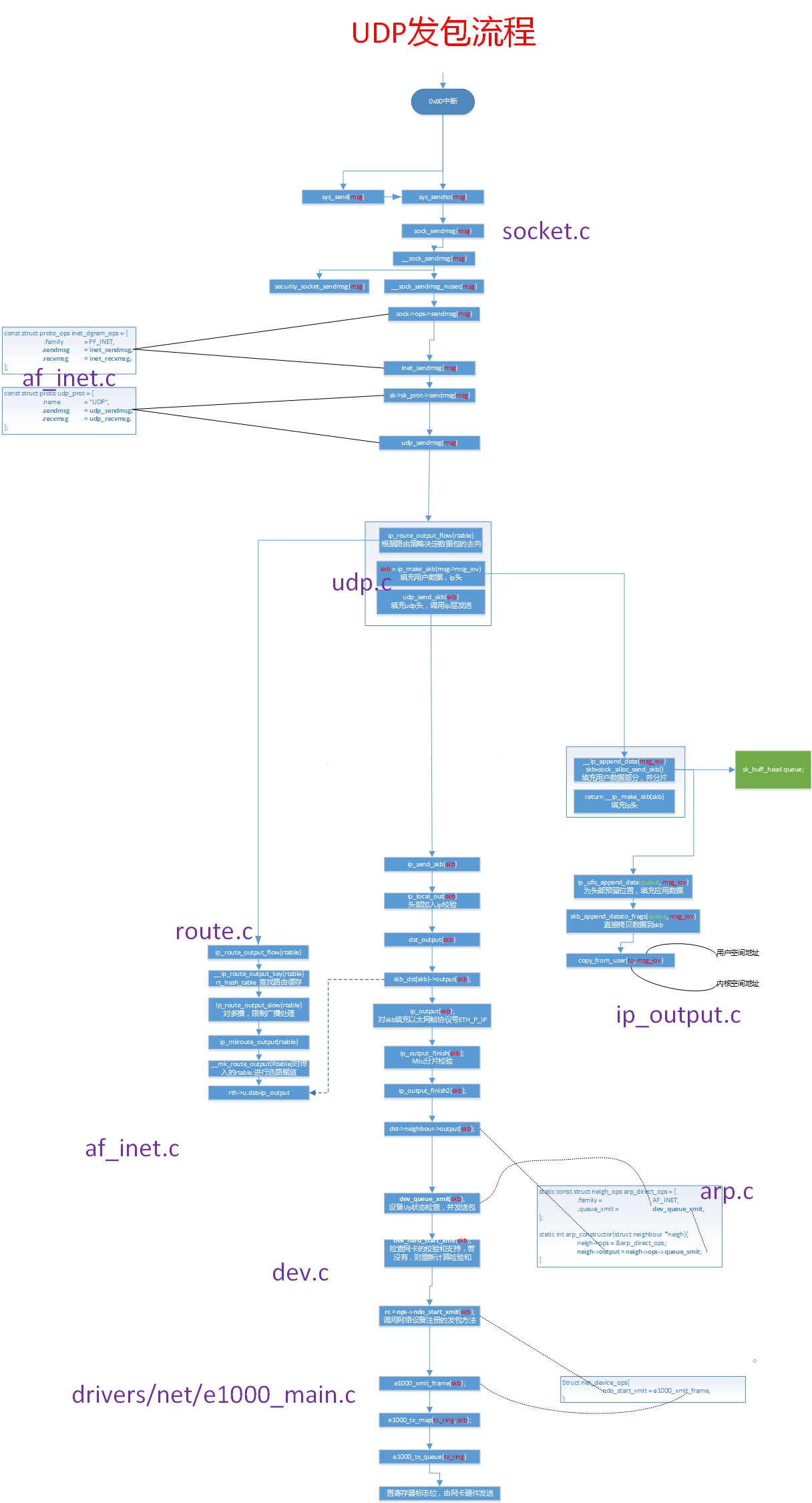
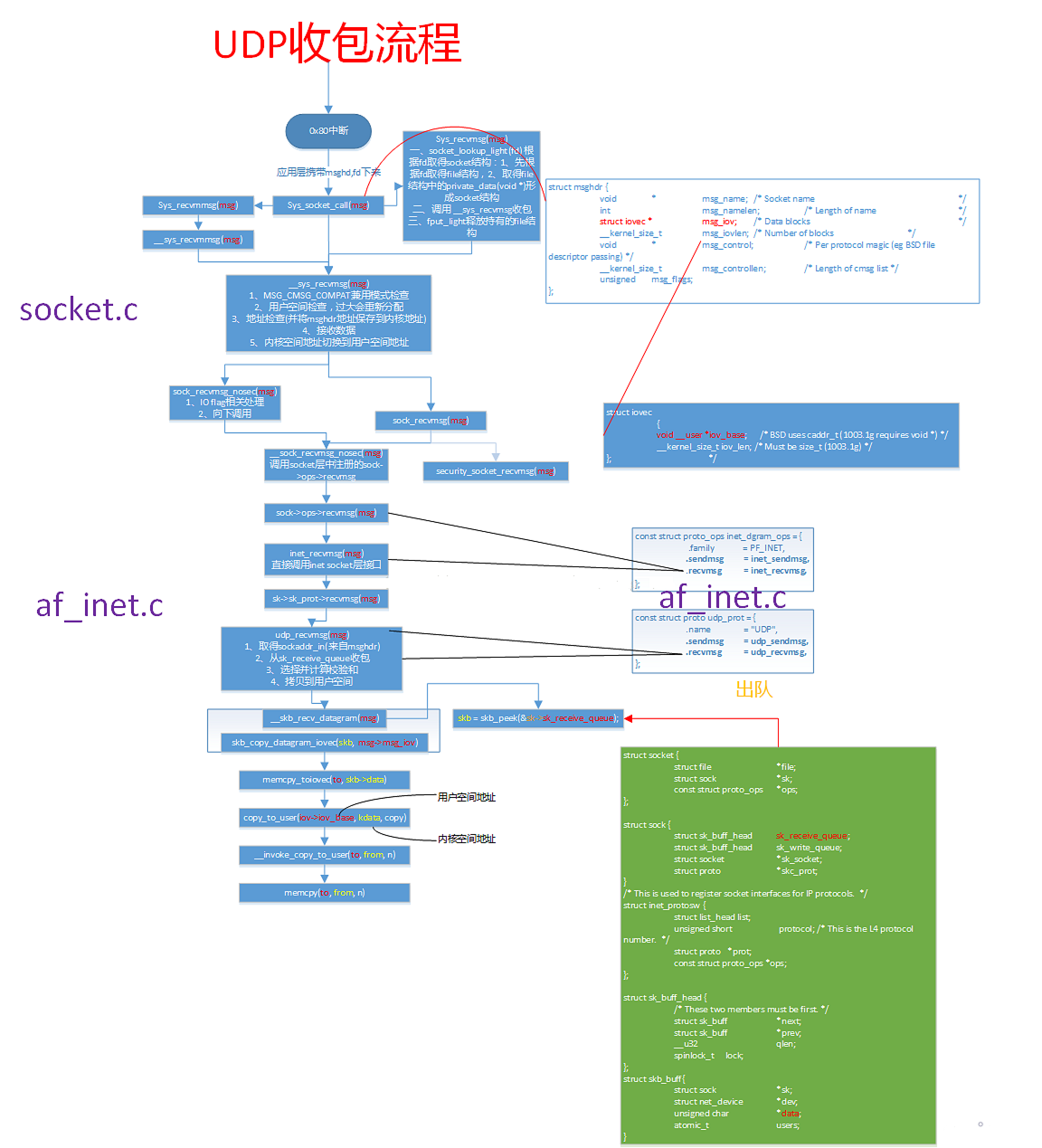
UDP收包流程
UPD收包流程-内核中断收包
重要数据结构
sk_buf
sk_buf是Linux网络协议栈最重要的数据结构之一,该数据结构贯穿于整个数据包处理的流程。
由于协议采用分层结构,上层向下层传递数据时需要增加包头,下层向上层数据时又需要去掉包头。
sk_buff中保存了L2,L3,L4层的头指针,这样在层传递时只需要对数据缓冲区改变头部信息,并调整sk_buff中的指针,而不需要拷贝数据,这样大大减少了内存拷贝的需要。
sk_buf的示意图
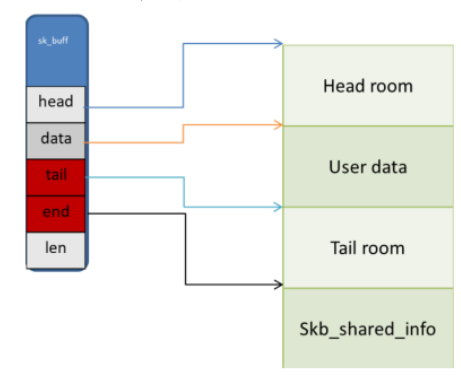
各字段含义如下
- head:指向分配给的线性数据内存首地址。
- data:指向保存数据内容的首地址。
- tail:指向数据的结尾。
- end:指向分配的内存块的结尾。
- len:数据的长度。
- head room: 位于head至data之间的空间,用于存储:protocol header,例如:TCP header, IP header, Ethernet header等。
- user data: 位于data至tail之间的空间,用于存储:应用层数据,一般系统调用时会使用到。
- tail room: 位于tail至end之间的空间,用于填充用户数据未使用完的空间。
- skb_shared_info: 位于end之后,用于存储特殊数据结构skb_shared_info,该结构用于描述分片信息。
sk_buf的常用操作函数如下
- alloc_skb:分配sk_buf。
- skb_reserve:为sk_buff设置header空间。
- skb_put:添加用户层数据。
- skb_push:向header空间添加协议头。
- skb_pull:复位data至数据区。
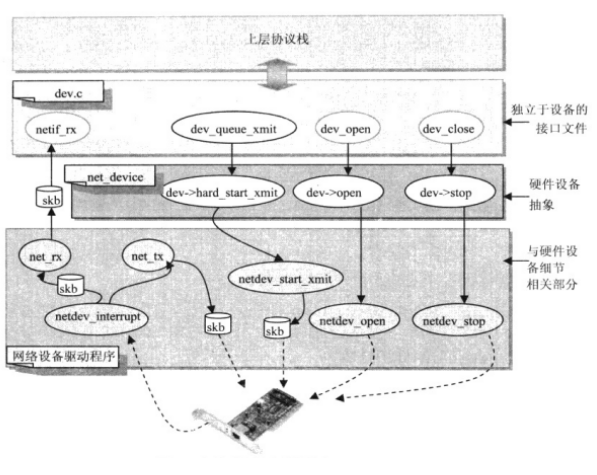
net_device
在网络适配器硬件和软件协议栈之间需要一个接口,共同完成操作系统内核中协议栈数据处理与异步收发的功能。在Linux网络体系结构中,这个接口要满足以下要求:
- (1)抽象出网络适配器的硬件特性。
- (2)为协议栈提供统一的调用接口。
以上两个要求在Linux内核的网络体系结构中分别由两个软件(设备独立接口文件dev.c和网络设备驱动程序)和一个主要的数据结构net_device实现。
socket
内核中的进程可以通过socket结构体来访问linux内核中的网络系统中的传输层、网络层以及数据链路层,也可以说socket是内核中的进程与内核中的网络系统的桥梁。
我们知道在TCP层中使用两个协议:tcp协议和udp协议。
而在将TCP层中的数据往下传输时,要使用网络层的协议,而网络层的协议很多,不同的网络使用不同的网络层协议。
我们常用的因特网中,网络层使用的是IPV4和IPV6协议。
所以在内核中的进程在使用struct socket提取内核网络系统中的数据时,不光要指明struct socket的类型(用于说明是提取TCP层中tcp协议负载的数据,还是udp层负载的数据),还要指明网络层的协议类型(网络层的协议用于负载TCP层中的数据)。
linux内核中的网络系统中的网络层的协议,在linux中被称为address family(地址簇,通常以AF_XXX表示)或protocol family(协议簇,通常以PF_XXX表示)。
softnet_data
每个CPU都有其队列,用来接收进来的帧, 每个CPU都有其数据结构用来处理入口和出口流量, 因此不同CPU之间没有必要上锁
softnet_data结构内的字段就是 NIC 和网络层之间处理队列,它从NIC中断和POLL方法之间传递数据信息。
1 | struct softnet_data |
throttle、avg_blog、cng_level: 这三个参数由拥塞管理算法使用
- throttle: 如果为真则超负荷
- avg_blog: input_pkt_queue队列长度加权后的平均值
- cng_level:代表拥塞等级
- input_pkt_queue: 用来保存进来的帧,非NAPI也会使用此字段
- backlog_dev:类型是net_device, 代表一个设备在已关联的CPU上为net_rx_action调度以准备执行,是由非NAPI驱动程序使用
- poll_list:双向列表,其中设备都带有输入帧等着被处理
- output_queue、completion_queue: 设备列表, 其中的设备有数据要传输, 另一个已成功传输因此可以释放掉
传输
UDP数据包发送宏观视角
从宏观上看,一个数据包从用户程序到达硬件网卡的整个过程如下:
1、使用系统调用(如 sendto,sendmsg 等)写数据
2、数据分段socket顶部,进入socket协议族(protocol family)系统
3、协议族处理:数据跨越协议层,这一过程(在许多情况下)转变数据(数据)转换成数据包(packet)
4、数据传输路由层,这会涉及路由缓存和ARP缓存的更新;如果目的MAC不在ARP缓存表中,将触发一次ARP广播来查找MAC地址
5、穿过协议层,packet到达设备无关层(设备不可知层)
6、使用XPS(如果启用)或散列函数选择发送坐标
7、调用网卡驱动的发送函数
8、数据传送到网卡的 qdisc(queue纪律,排队规则)
9、qdisc会直接发送数据(如果可以),或者将其放到串行,然后触发NET_TX类型软中断(softirq)的时候再发送
10、数据从qdisc传送给驱动程序
11、驱动程序创建所需的DMA映射,刹车网卡从RAM读取数据
12、驱动向网卡发送信号,通知数据可以发送了
13、网卡从RAM中获取数据并发送
14、发送完成后,设备触发一个硬中断(IRQ),表示发送完成
15、中断硬处理函数被唤醒执行。对许多设备来说,会这触发NET_RX类型的软中断,然后NAPI投票循环开始收包
16、poll函数会调用驱动程序的相应函数,解除DMA映射,释放数据
UDP/TCP数据包接收宏观视角
第一部分硬中断
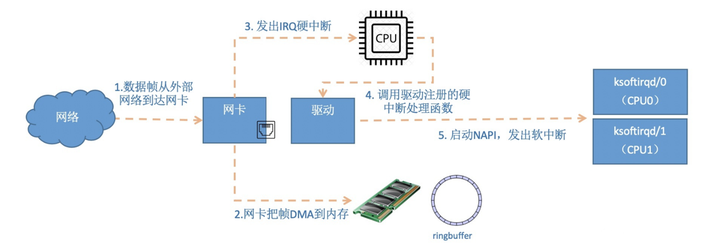
1、当数据帧从网线到达网卡上的时候,第一站是网卡的接收队列。网卡在分配给自己的RingBuffer中寻找可用的内存位置,找到后DMA引擎会把数据DMA到网卡之前关联的内存里,这个时候CPU都是无感的。当DMA操作完成以后,网卡会像CPU发起一个硬中断,通知CPU有数据到达。
2、网卡的硬中断注册的处理函数是igb_msix_ring。 间接调用napi_schedule1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28//file: drivers/net/ethernet/intel/igb/igb_main.c
static irqreturn_t igb_msix_ring(int irq, void *data)
{
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
void __raise_softirq_irqoff(unsigned int nr)
{
trace_softirq_raise(nr);
or_softirq_pending(1UL << nr);
}
//file: include/linux/irq_cpustat.h
3、硬中断list_add_tail修改了CPU变量softnet_data里的poll_list,将驱动napi_struct传过来的poll_list添加了进来。
其中softnet_data中的poll_list是一个双向列表,其中的设备都带有输入帧等着被处理。
紧接着__raise_softirq_irqoff触发了一个软中断NET_RX_SOFTIRQ
4、ksoftirqd内核线程处理软中断
第二部分软中断
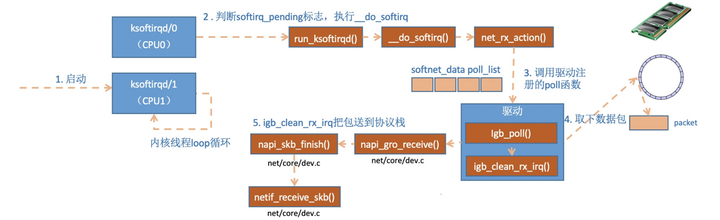
1、ksoftirqd_should_run
1 | static int ksoftirqd_should_run(unsigned int cpu) |
2、在__do_softirq中,判断根据当前CPU的软中断类型,调用其注册的action方法。
1 | asmlinkage void __do_softirq(void) |
在网络子系统初始化小节, 我们看到我们为NET_RX_SOFTIRQ注册了处理函数net_rx_action。所以net_rx_action函数就会被执行到了。
3、net_rx_action
1 | static void net_rx_action(struct softirq_action *h) |
我们再来把精力集中到这个核心函数net_rx_action上来。
函数开头的time_limit和budget是用来控制net_rx_action函数主动退出的,目的是保证网络包的接收不霸占CPU不放。
等下次网卡再有硬中断过来的时候再处理剩下的接收数据包。 其中budget可以通过内核参数调整。
这个函数中剩下的核心逻辑是获取到当前CPU变量softnet_data,对其poll_list进行遍历, 然后执行到网卡驱动注册到的poll函数。
对于igb网卡来说,就是igb驱动力的igb_poll函数了。
1 | static int igb_poll(struct napi_struct *napi, int budget) |
在读取操作中,igb_poll的重点工作是对igb_clean_rx_irq的调用。
1 | static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget) |
igb_fetch_rx_buffer和igb_is_non_eop的作用就是把数据帧从RingBuffer上取下来。为什么需要两个函数呢?因为有可能帧要占多多个RingBuffer,所以是在一个循环中获取的,直到帧尾部。获取下来的一个数据帧用一个sk_buff来表示。收取完数据以后,对其进行一些校验,然后开始设置sbk变量的timestamp, VLAN id, protocol等字段。接下来进入到napi_gro_receive中:1
2
3
4
5
6
7//file: net/core/dev.c
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
skb_gro_reset_offset(skb);
return napi_skb_finish(dev_gro_receive(napi, skb), skb);
}
dev_gro_receive这个函数代表的是网卡GRO特性,可以简单理解成把相关的小包合并成一个大包就行,目的是减少传送给网络栈的包数,这有助于减少 CPU 的使用量。我们暂且忽略,直接看napi_skb_finish, 这个函数主要就是调用了netif_receive_skb。1
2
3
4
5
6
7
8
9
10//file: net/core/dev.c
static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb)
{
switch (ret) {
case GRO_NORMAL:
if (netif_receive_skb(skb))
ret = GRO_DROP;
break;
......
}
在netif_receive_skb中,数据包将被送到协议栈中。声明,以下也都属于软中断的处理过程
第三部分网络协议栈处理
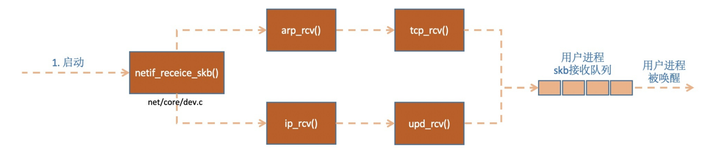
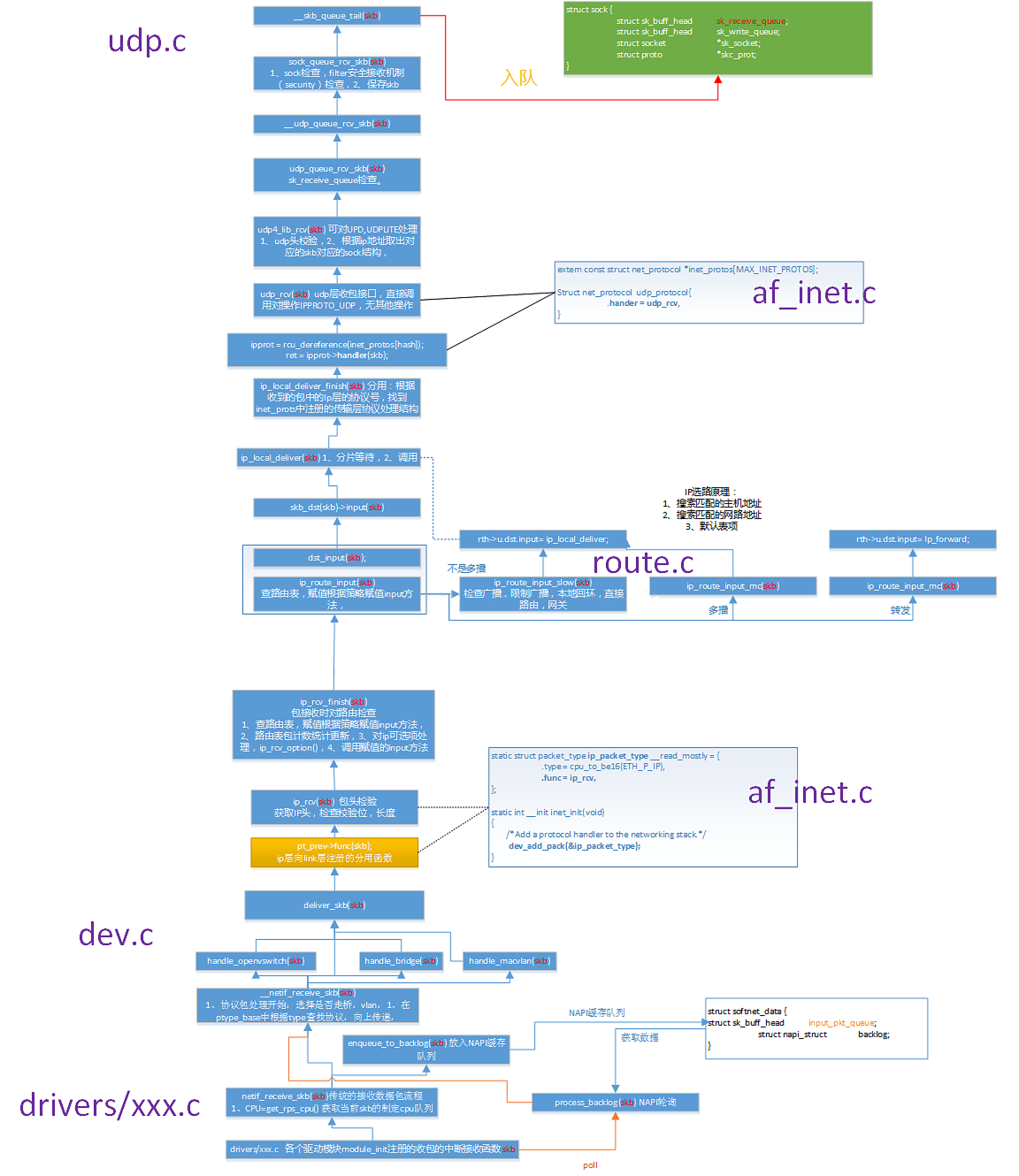
netif_receive_skb函数会根据包的协议,假如是udp包,会将包依次送到ip_rcv(),udp_rcv()协议处理函数中进行处理。
1 | //file: net/core/dev.c |
接着__netif_receive_skb_core取出protocol,它会从数据包中取出协议信息,然后遍历注册在这个协议上的回调函数列表。
ptype_base 是一个 hash table,在协议注册小节我们提到过。ip_rcv 函数地址就是存在这个 hash table中的。
1 | //file: net/core/dev.c |
IP协议层处理
linux在ip协议层都做了什么,包又是怎么样进一步被送到udp或tcp协议处理函数中的。
1 | //file: net/ipv4/ip_input.c |
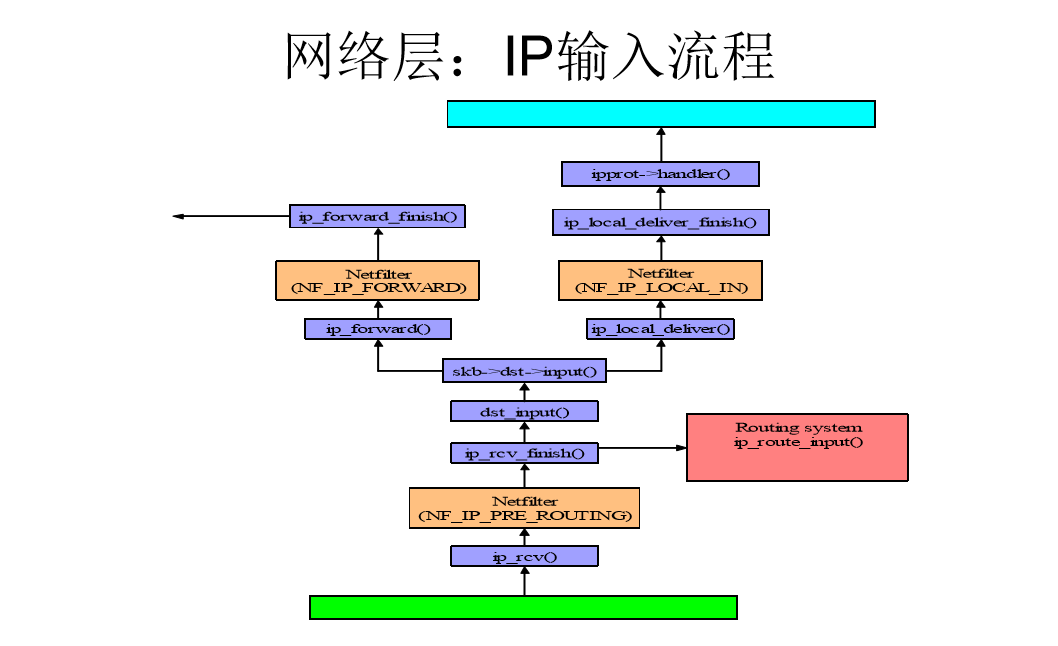
这里NF_HOOK是一个钩子函数,当执行完注册的钩子后就会执行到最后一个参数指向的函数ip_rcv_finish。
1 | static int ip_rcv_finish(struct sk_buff *skb) |
跟踪ip_route_input_noref 后看到它又调用了 ip_route_input_mc。
在ip_route_input_mc中,函数ip_local_deliver被赋值给了dst.input, 如下:
1 | //file: net/ipv4/route.c |
所以回到ip_rcv_finish中的return dst_input(skb)。
1 | /* Input packet from network to transport. */ |
skb_dst(skb)->input调用的input方法就是路由子系统赋的ip_local_deliver。
1 | //file: net/ipv4/ip_input.c |
如协议注册小节看到inet_protos中保存着tcp_rcv()和udp_rcv()的函数地址。
这里将会根据包中的协议类型选择进行分发,在这里skb包将会进一步被派送到更上层的协议中,udp和tcp。
UDP协议层处理
udp协议的处理函数是udp_rcv。
1 | //file: net/ipv4/udp.c |
__udp4_lib_lookup_skb是根据skb来寻找对应的socket,当找到以后将数据包放到socket的缓存队列里。
如果没有找到,则发送一个目标不可达的icmp包。
1 | //file: net/ipv4/udp.c |
sock_owned_by_user判断的是用户是不是正在这个socker上进行系统调用(socket被占用)
如果没有那就可以直接放到socket的接收队列中。
如果有那就通过sk_add_backlog把数据包添加到backlog队列。
当用户释放的socket的时候,内核会检查backlog队列,如果有数据再移动到接收队列中。
sk_rcvqueues_full接收队列如果满了的话,将直接把包丢弃。
接收队列大小受内核参数net.core.rmem_max和net.core.rmem_default影响。
网络各模块职责
桥接
桥接主要是指,接收到数据包的Linux主机,充当一个L2层网桥的作用,如果发现自己收到的数据包不是发给自己的,就将数据包发送到所在LAN中对应的主机上。在这个过程中,Linux主机会通过地址学习机制来记忆所处LAN中不同主机对应的网桥接口,并通过一定的aging机制来保证学习到地址的时效性和可靠性。
所以桥接是一个L2层发生的事情,不涉及到L3,因此此处和路由系统也就没有交互,但其实可以理解为“L2层面的路由”
对应到实际的Linux中,桥接的处理往往是交给网桥虚拟设备来进行的。我们需要把不同的设备绑定到这个虚拟设备网桥的不同接口上,然后就起到了一个虚拟的“交换机”的效果,我们就可以将Linux主机当作一个交换机来在LAN中使用了。尤其是当同一个主机有多张网卡,且多张网卡对应不同的网络时,我们就可以依靠网桥在L2层次联通多个不同的网络。
然而桥接固然会起到连接不同LAN的作用,但是有一个问题:如果多个L2网络之间的连接通过多个网桥进行,在最终形成的拓扑结构中出现了环路的情况,那么就会导致在任意一台交换机进行广播时数据包出现在环路中不断循环,消耗环路上交换机的处理资源。
针对上面提到的这种情况,我们通过生成树协议来选择不同交换机之间的连接是否相通,来避免在整体网络拓扑上产生环路的情况,并且能够保证快速感知网络中每一处连接的中断,通过调整其他局部网络连接的连通让整个网络不会中断,从而使整个网络具备冗余链路特性,提高了整体网络的可靠性。
除此之外,我们在利用交换机架设比较大的网络时,会采用分层结构。就是说将中心交换机和边缘交换机分离,这样能够保证每个局部网络中彼此通信的流量大部分是分离的(因为在同一个边缘交换机的管理下,数据包不会扩散到整个更大的网络范围内),并且也方便了我们进行布线、管理大量的主机。
对于桥接的配置,我们一般会使用brctl去操作Linux上的网桥设备,会通过sysfs对桥接相关的各种内核参数进行配置。
IPV4
IPV4是目前最常见的L3路由协议,适用范围非常广泛,也被直接集成到了Linux内核中,在内核引导的时候就会加载其协议处理函数。
IPV4协议具体的内容和特性,相信科班的同学都应该在计网课程上学习过,包括报头字段含义、分段/重组、MTU调整、IP选项以及校验和等等。这里就不具体讲述IPV4的内容了,书上把这些基本内容又讲了一遍,后面又对照着Linux网络IPV4模块的代码过了一遍,整体上还是比较复杂的,细节非常多,在缺乏足够实践积累的情况下,理解效果非常有限。这里就提几个我印象比较深的细节吧,感觉我之后还是要把这部分细读若干遍的
IPV4协议处理函数(内核)最开始会对接收到的IPV4数据包进行一系列的健康检查,重点是检验报头中各个字段是否满足一定的条件,如果发现存在问题,就会直接抛弃数据包,并发送一个报错的ICMP数据包回去。
数据包健康检查无误后,就会调用Netfiliter留下的钩子函数,来对数据包进行一些定制化操作(依照用户在iptables上定义的各种规则),当经过Netfiliter的处理后,内核就会判断是将该数据包发送到本地,还是进行转发。同时,还会分析和处理一些IP报头中的选项信息,更新主机上的相关L3统计信息。
对于转发,还是很简单的,内核会处理IP选项,然后根据报头来确认该数据包是可以被转发的,查路由表获得下一跳地址,递减TTL。在实际发送之前,还会根据当前路径MTU来决定是否要进行IP分片,最后交给实际的网络设备,将数据包发送到外部。
对于本地传递,如果接受到的数据包是分片过的,就需要做分片重组工作,这个在具体的源码中也是有特定函数来负责对IP数据包进行重组的,过程也是相当复杂的
另外,L4层(如TCP UDP)传输数据是在L3的基础上进行的,在源码中就体现为L4传输层的代码就会调用一些函数,把数据交由L3送出去。在这个过程中,L4会先将待发送的数据放到一个缓冲区内,积累适量的数据后再通知L3进行实际的发送,这样提高了整体的网络数据发送效率。并且,L4还可能根据L3的MTU情况,通过控制数据缓冲区的大小来控制后续L3的发送是否会分片,进一步细致化控制数据的发送。
最后,IPV4中还包括了IP端点子系统来保证一定的传输要求(方便记录信息、控制速率等),包括了IP统计模块让我们可以观测机器上IP层运行的情况若何,并通过多样化的配置方法来对IP子系统的各类内核参数进行配置,以满足我们想要达成的效果。
L4协议和ICMP
在Linux的网络栈中,L4协议也有对应的协议处理函数,比如TCP UDP等。IP模块在处理数据包时,会根据数据包里的L4标识来决定传递给哪一个L4协议处理函数。
不同的L4处理函数发生的地方也可能是不同的:有可能全部发生在内核空间,有可能全部发生在用户空间,也可能同时在内核和用户空间都有发生。
ICMP协议是调试和探查网络情况的重要协议,起到了很重要的工具作用。书中也比较详细地讲解了ICMP协议在Linux网络栈中的实现,这里就不详细介绍了,日后遇到和ICMP协议相关较大的问题,再来细读这一部分。
不过还是要对几个关键的ICMP信息种类有一些了解:常规的ping(ehco和reply消息)、不可达提示、次佳路由提醒、TTL超时提醒、时钟同步提醒等等,这些类别的ICMP消息可能会在我们之后的工作过程被大量识别和使用
邻居子系统
邻居子系统可以直接被理解为是“L2层的路由”,负责的是在L2层网络中通过逻辑地址(IP)找到物理地址(设备MAC)的过程。协议栈在发送数据时,当上层L3协议提供了L3地址后(一般是IP),协议栈就通过邻居子系统中保存的L2地址和L3地址之间的映射关系,寻找到对应的L2地址,并根据L2地址进行封包发送。同样的,原则上,在协议栈接受数据时,我们也可以通过邻居子系统来获得接受数据包对应的L3地址(如果需要的话)
在传送一个数据包时,首先由本地主机路由子系统选择L3目的地址,如果下一跳在同一网络,邻居层就把L3地址解析为L2地址(通过邻居子系统),并将这个关联放到缓存之中,然后根据L2地址进行本地网络的数据发送。所以说,邻居子系统更多管理的是L2层和L3层之间发生的事情。
常见的邻居协议有ARP和ND协议,前者用于IPv4中,后者用于IPv6中,两者是完全不同的设计,ND是ICMPv6提供的一个函数,但其实两者起到的作用是一致的。
邻居子系统的查找表,对应了L2层和L3层地址之间的映射关联,是个hash表,每一个表项代表一个neighbor情况,保存网络中邻居的状态,并进行网络不可达性检测,为数据在L2层的发送做了充分必要的准备条件。
值得一提的是,邻居子系统的表中保存的每一个neighbor项,都有对应的状态(被称为NUD),通过状态的变化流转,邻居子系统会对每一个neighbor项根据其对应状态进行不同的操作,在访问使用到每一个neighbor项后,对应的结果也和其状态有关。
除了最基本的状态表,为了加速整个邻居子系统的性能,邻居子系统中还有对应的缓存表,来缓存近期经常使用的热点数据。
邻居子系统所做的基本操作就是看到未知的IP地址,就向本地网络广播询问请求,等待IP对应的本地网络中的主机回应(如果有的话),然后将其保存到自己的表中,完成整个操作。除此之外,就是定时检测表中neighbor项的状态情况,根据不同的状态情况做出对应的调整以及响应其他子系统的查询请求。
另外,由于网络中的情况复杂多变,因此邻居子系统也需要进行垃圾回收,这个主要是通过对每一个存在的表项(即neighbor记录)计算引用计数而得到的,系统同时使用同步和异步的垃圾回收来提升整体的性能表现;除此之外,当邻居子系统获知了一些重要的事件发生时(例如邻居位置发生变化或失效),会通过通知链通知给其他相关的子系统,进行进一步的状态调整。
当然,我们也可以通过procfs来进行邻居子系统相关的内核参数配置,对整个系统进行定制化的调整和优化。也可以使用ip neighbor命令在用户空间来直接和邻居子系统交互,譬如手动添加删除neigbor记录等等。
路由
路由子系统最核心的功能就是提供路由信息的查询和维护,数据包要从此处发到某个IP地址,下一跳在哪,发送到路由器的哪个接口,这就需要路由子系统进行协助。
保存路由信息的表就是路由表,Linux中使用两张路由表,一张用来保存本地地址的路由规则,另一张用于外部网络路由规则。查询路由规则时,使用最长前缀匹配算法查询,使用线索树来进行存储和索引。不直接使用哈希表是因为在海量路由数据的情况下,哈希表会存在碰撞和冲突严重的情况,还需要进行动态的rehash,而线索树则不需要,直接通过最长前缀匹配算法查询,避免了此类情况。同样的,为了加速查询路由信息的整体性能表现,路由表也有缓存表,这个就是哈希表了。
Linux中的路由子系统还有一些高级功能,比如策略路由,原本的Linux只有两张路由表,但使用策略路由可以定义多张路由表,每张路由表在不同的触发条件下使用(比如对指定的数据包做特殊标记,来进行对特定路由表的匹配),从而实现更加复杂灵活和多样化可定制的路由控制。
除此之外,还有多路径路由,对于同一个路由,可以为有不同服务质量要求的服务提供不同的路径、分散流量、提供冗余链路等,动态化地利用整个网络上的资源,消除了单路由模式下的种种局限性。
netfiliter的钩子函数一部分也是嵌入到路由子系统的,使用iptable的时候最好要意识到这一点。路由子系统同时也和其他的网络子系统有非常密切的交互,比如网络设备的状态变化,就会引起路由表的添加、删除或是更新,路由缓存同时也要被刷新。另外,一些复杂路由协议的运行(比如OSPF RIP等),需要用户态的路由协议守护进程来支持。
在路由子系统中,同样也存在垃圾回收,并且和邻居子系统的垃圾回收的模式基本相似,都是以引用计数作为基本依据,然后使用异步回收和同步回收并用的策略来提高整体的性能表现。
同样的对于路由子系统,我们也可以进行灵活的定制化配置,通过ip和route命令在用户空间操作路由子系统,例如添加删除路由信息等。通过procfs调节路由子系统中各个可调节的内核参数,来优化路由系统的整体表现。
网络子系统
- 作用:使Linux成为一个可扩展的网络操作系统
- 支持多协议族INET, INET6, UNIX…
- 支持多种类型的网络设备以太网卡、无线网卡…
- 领略顶级大师作品,成为C高手的绝佳参考
- 开闭原则
- 对扩展开放:可增加新的协议族、协议、网络设备
- 对修改封闭:而无需改动框架的代码
- 面向接口编程
- 无处不在的函数指针
- 依赖倒置原则
- 依赖于抽象的接口,而不是具体的实现。
- net_protocol_family, net_device
- 高性能
- 模块化,高可维护性;框架化,高可扩展性
- 开闭原则
- 各种网络技术汇聚与此,成为网络高手的绝佳参考
- IPv4, IPv6, IPSec,策略路由, QoS,网桥,..
层次划分
套接口层
作用:一为上层应用提供协议无关的通用网络编程接口
遵循BSD socket规范,如connect, recvmsg, sendmsghttp://en.wikipedia.org/wiki/BSD socket
―为下层各种协议提供族接口和机制,使具体协议族可以注册到系统中
- 核心数据结构
- struct net_protocol_family
- inet_family_ops
- struct socket- struct sock
- struct inet protosw- struct proto_ops- struct proto
传输层
INET协议族:传输层
作用:一实现传输层协议
- TCP
- UDP
- RAW
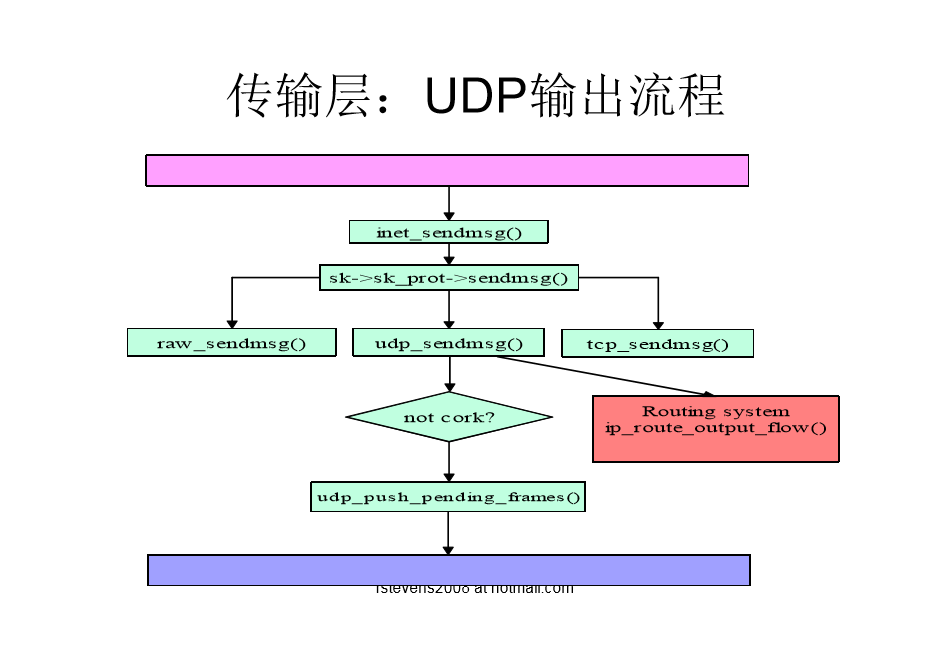
UDP的输出流程图
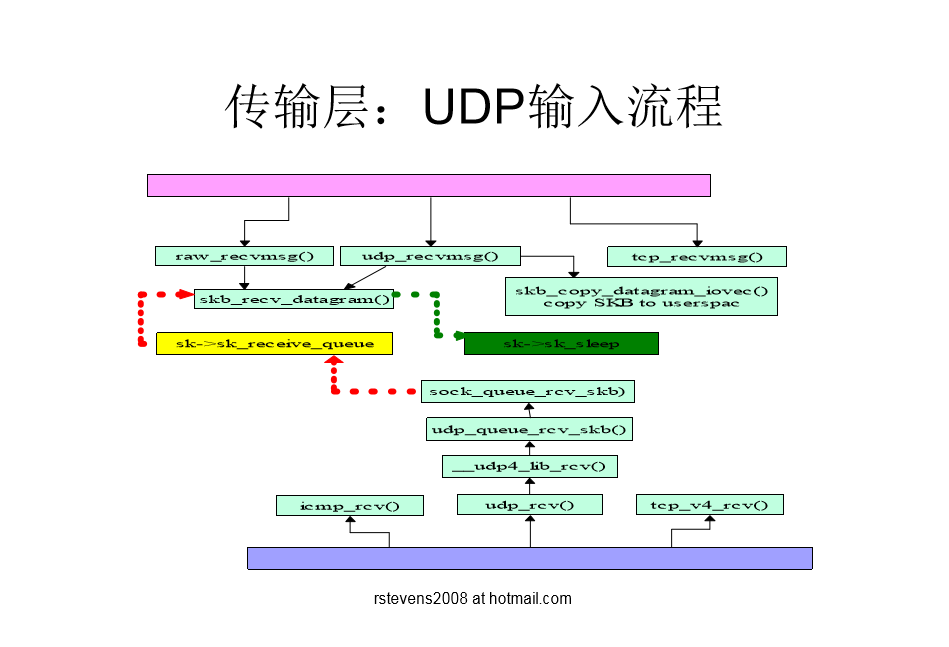
UDP的输入流程图
网络层
INET协议族:网络层
作用:L3层协议处理
- 提供与传输层的接口
- 路由
- 分片
- 邻居发现
- netfilter
核心数据结构:
- struct net_protocol
- handler()
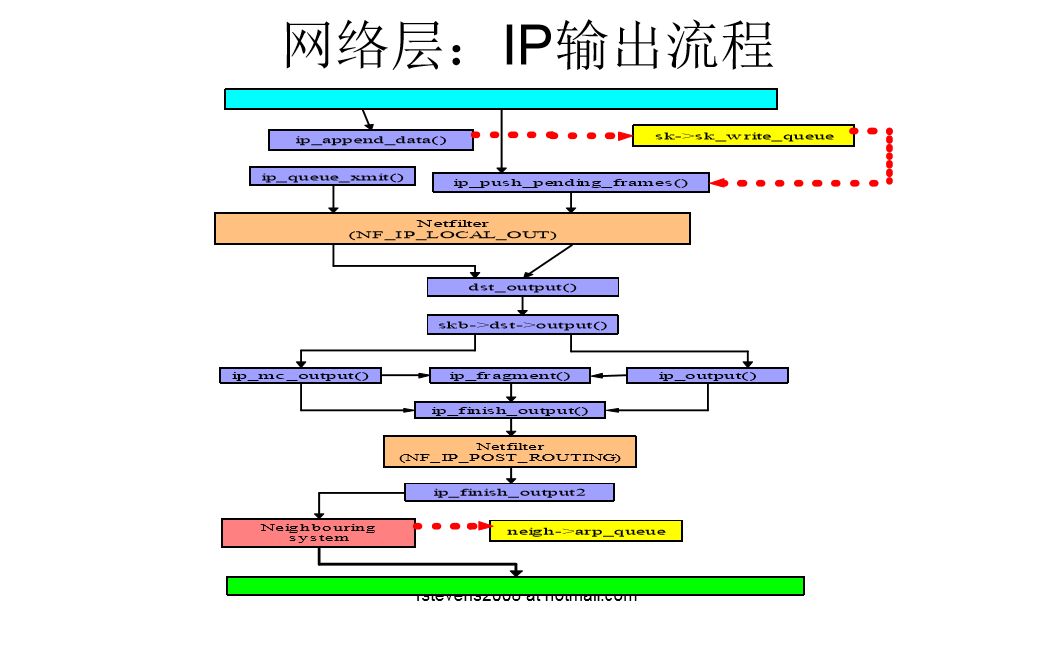
IP输出流程图
IP输入流程图
路由子系统
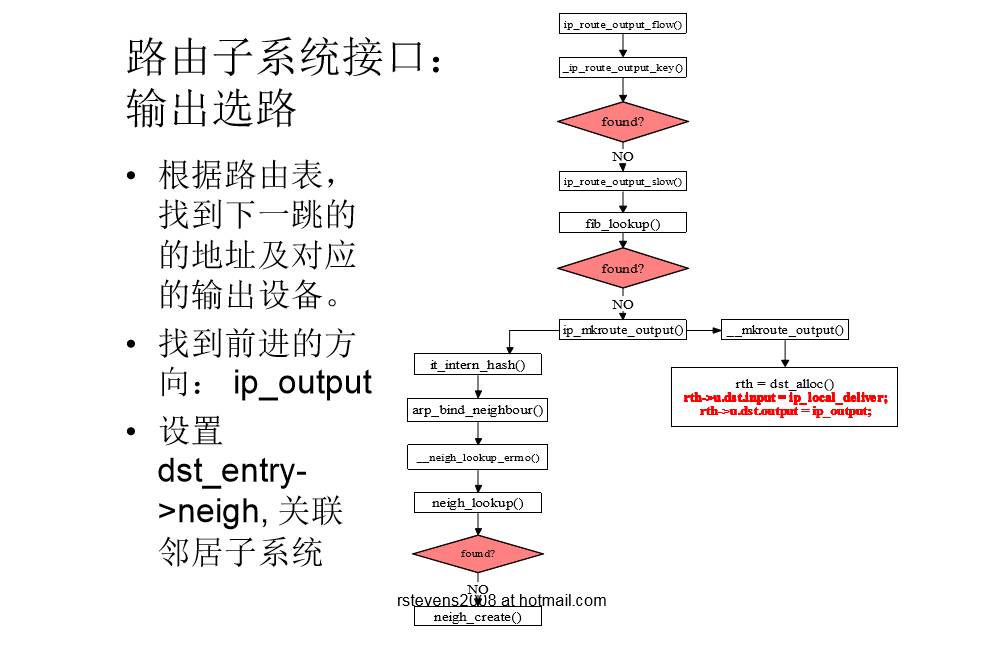
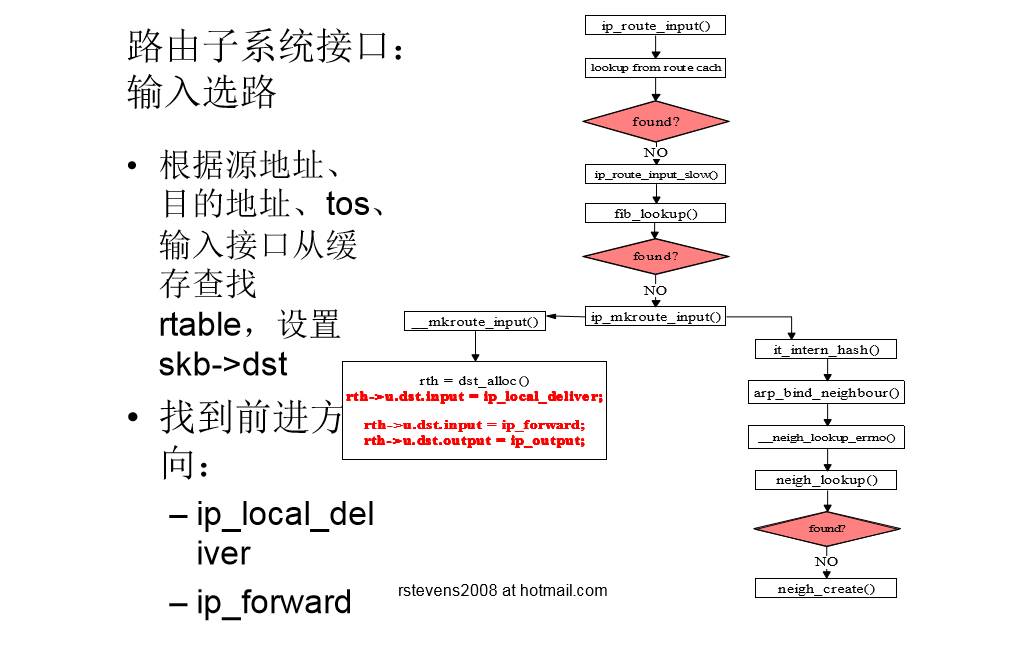
- 作用:
- 输入选路:确定数据包是本地处理还是转发
- 输出选路:确定输出接口和下一跳地址。
两层架构:
- 路由缓存:提高路由性能
- 路由表(FIB):缓存不命中,则查找路由表
核心数据结构
- struct rtable:协议相关的缓存信息(IPv4源地址、目的地址)
- struct dst entry:协议无关的缓存信息,嵌套在rtable中
- input() 数据包的输出处理函数
- output() 数据包的输入处理函数
- struct flowi: cache lookup keys
输出选路流程图
输入选路流程图
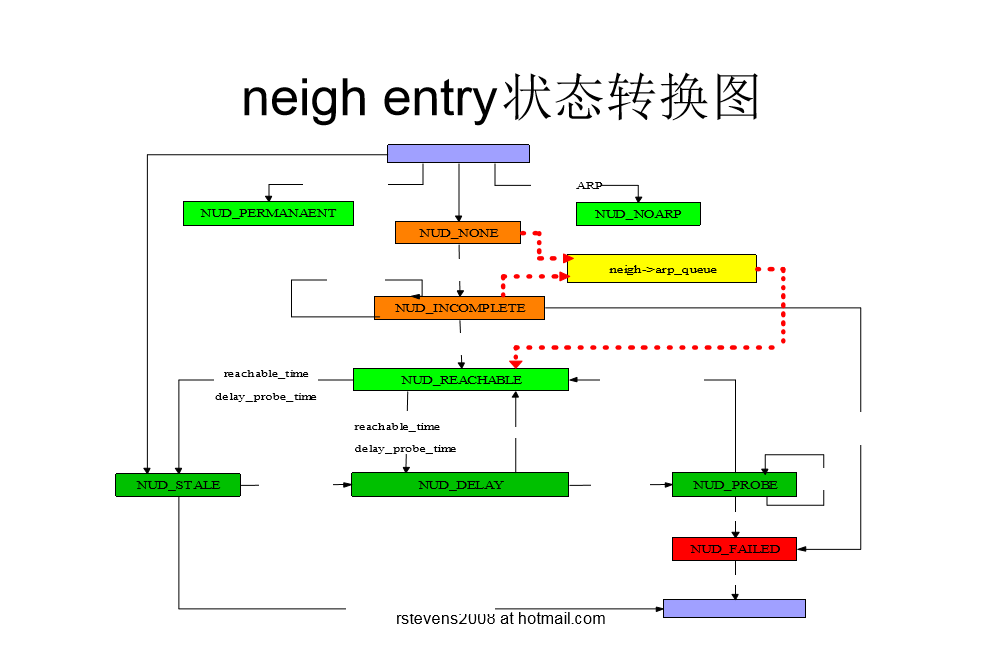
邻居子系统
- 作用:
- 从邻居获取下一跳的L2层地址
- 两层架构:
- 协议无关层:
- 协议相关层:支持多种邻居协议
- IPv4: ARP
- IPv6: neighbour discovery
- 核心数据结构
- struct neighbour
- nud_state
- output()
- arp_queue
- struct neighbour
- struct neigh_ops
neigh entry状态转换图
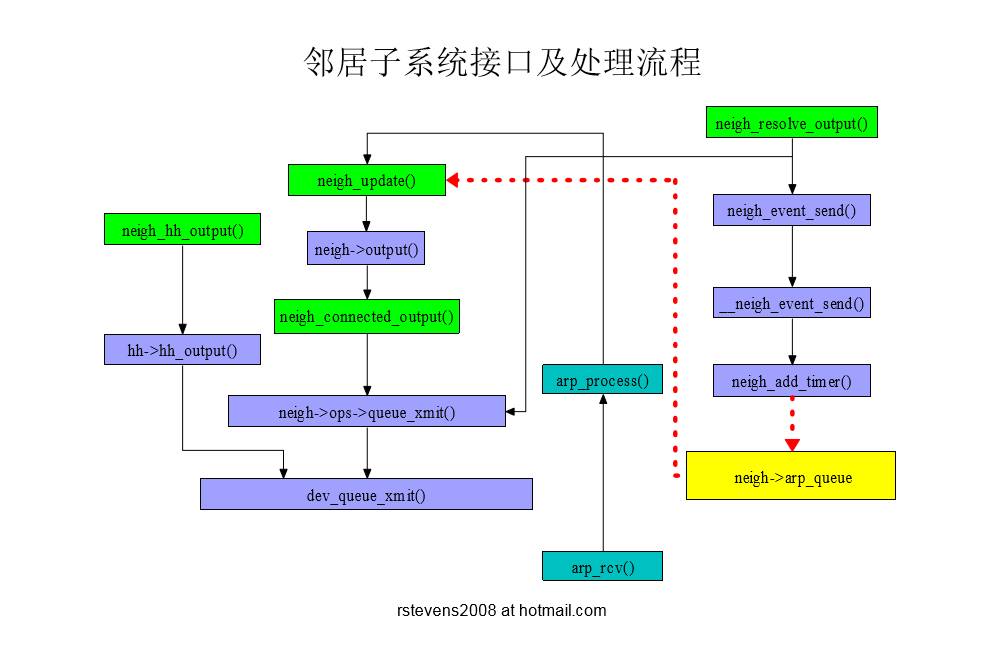
邻居子系统对外接口
- neigh_connected_output
- 当邻居项处于CONNECTED状态时;直接构建L2层首部
- neigh_hh_output
- 如果输出网络设备支持L2地址cache,则直接复制cache的地址;效率更高
- neigh_resolve_output
- 当邻居项处于非 CONNECTED状态时;慢速发送
- 数据包有可能需要缓存到队列
邻居子系统接口及其处理流程
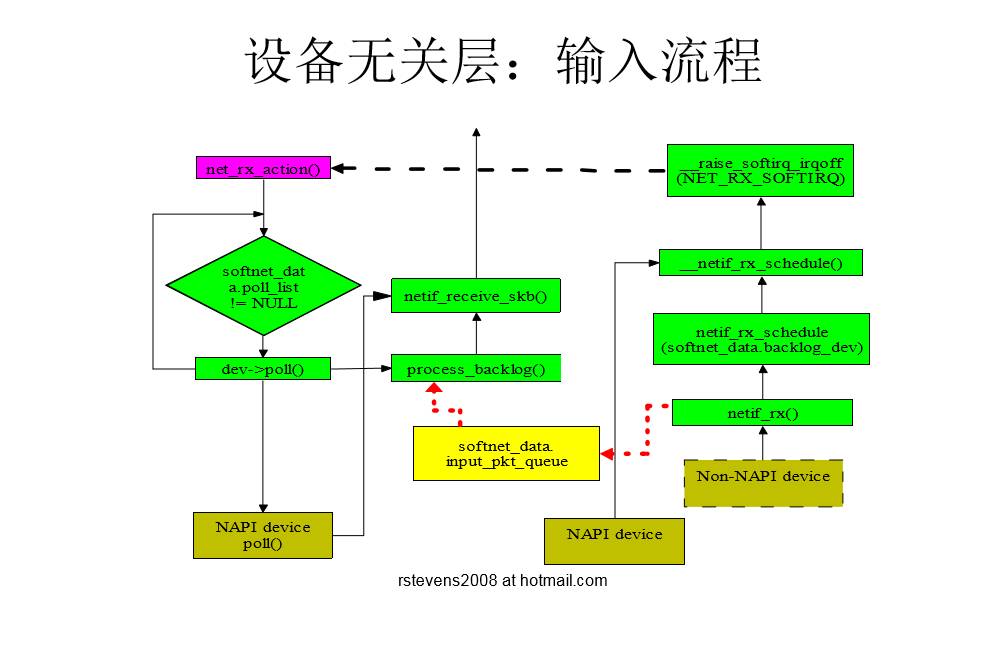
设备无关层介绍
- 作用
- 定义设备驱动程序的接口,屏蔽下层具体网络设备驱动程序的实现
- 定义L3层的接口,屏蔽具体的packet类型
- 网络软中断
- 软中断的作用:异步编程,提高性能
- 输出软中断
- 输入软中断
- 输出:经过QoS子系统
- 输入的两种方式:NAPI,Non-NAPI
核心数据结构:
- struct packet_type
- func()
- struct net_device
- struct softnet_data
- poll_list
- input_pkt_queue
- backlog_dev
设备无关层输出流程图
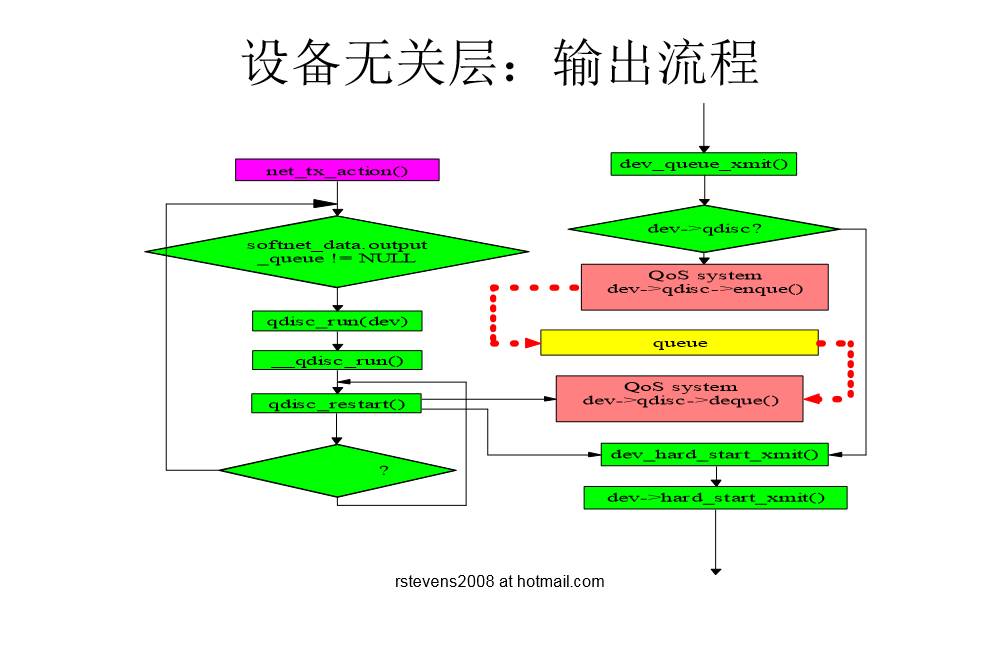
Qos子系统
- 作用:
- 输入输出时的流量控制;
- 从而提供不同质量的服务
- 核心逻辑与具体QoS排队规则分离。
- 核心数据结构
- struct Qdisc_ops
- enqueue()
- dequeue()
默认排队规则
- priority FIFO
- struct Qdisc_ops pfifo_fast_ops
- 三级队列
- 根据IP首部TOS字段选择队列
- 0级最高,1级次之,2级最低
- 入队函数:pfifo_fast_enqueue
- 出队函数:pfifo_fast_dequeue
设备无关层的输入流程图
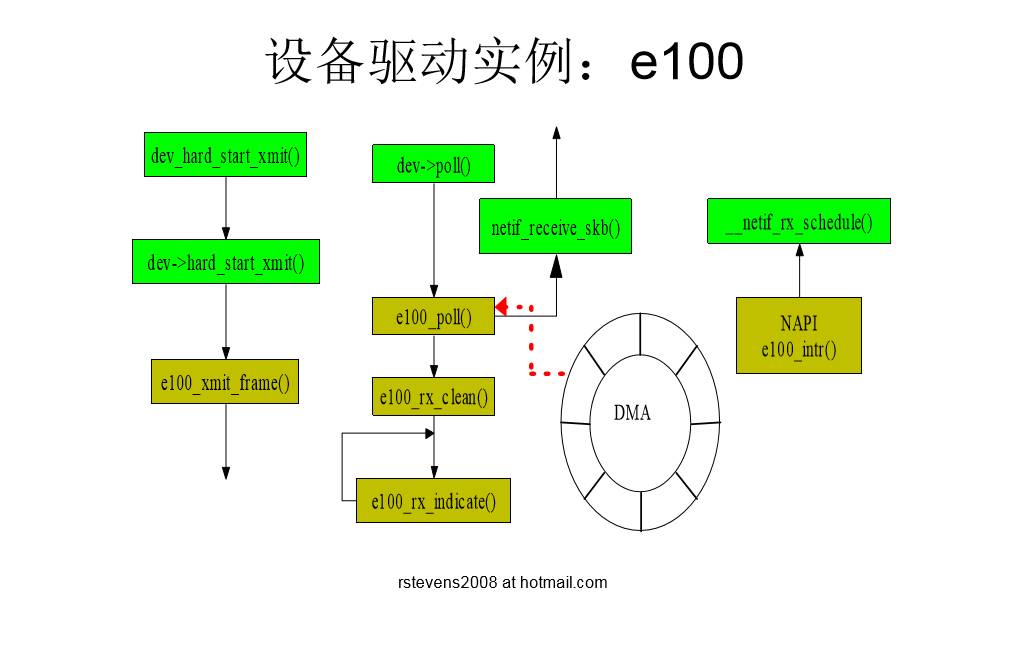
网络设备驱动程序
- 作用:
- 实现对特定网络设备的控制
- 遵循规范,接入网络子系统
- 相关技术:
- DMA
- SKB环形队列
- NAPI
- 中断+轮询,一次中断可接收多个SKB,提高性能
- Non-NAPI
- 每次中断只能接收一个SKB,性能较低
- DMA
设备驱动实例
- 创建DMA环形缓冲区
-e100_rx_alloc_list - 建立DMA映射
- e100_rx_alloc_skb
- 网卡接收数据,直接放入环形缓冲区;然后产生中断
- 内核处理中断。将设备挂入napi poll list,然后触发软中断
- e100_intr
- netif_rx_schedule
- 软中断调用poll函数处理收到的数据包。
- net_rx_action
- e100_poll
- e100_rx_clean
- e100_rx_indicate
- pci_unmap_single
- netif_receive_skb
一个具体的设备驱动示例
iptables
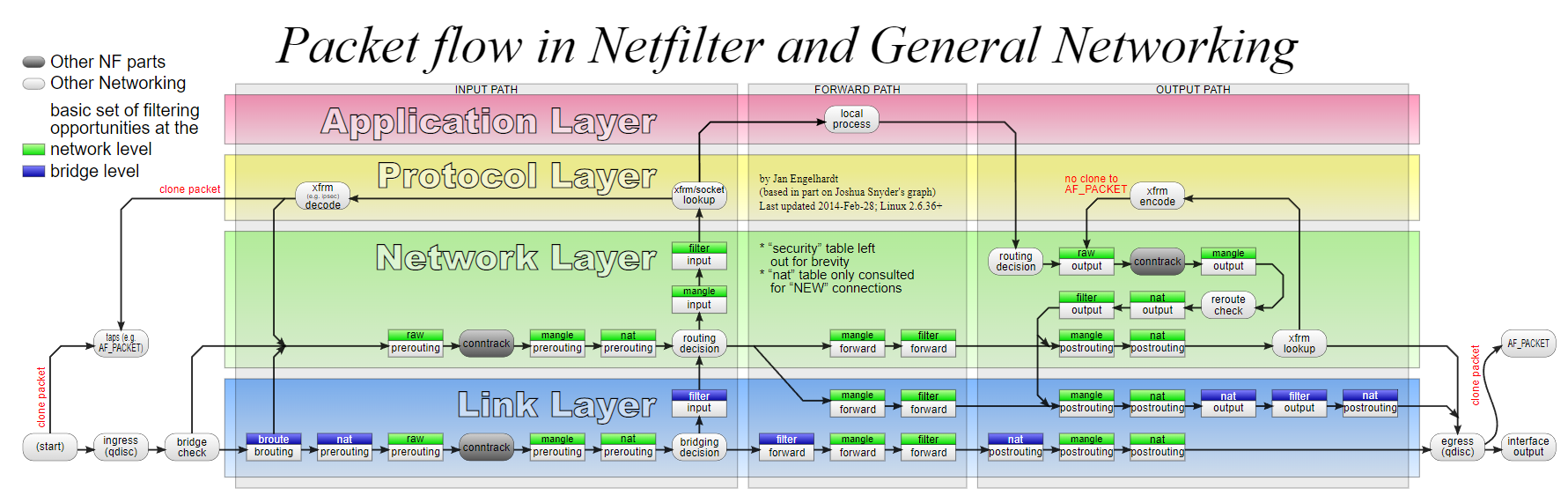
基础及原理
在 Linux 生态系统中,iptables 是使 用很广泛的防火墙工具之一,它基于内核的包过滤框架(packet filtering framework) netfilter
每个进入网络系统的包(接收或发送)在经过协议栈时都会触发这些 hook,程序 可以通过注册 hook 函数的方式在一些关键路径上处理网络流量。
iptables 相关的内核模块在这些 hook 点注册了处理函数,因此可以通过配置 iptables 规则来使得网络流量符合防火墙规则。
Netfilter Hooks
netfilter 提供了 5 个 hook 点。包经过协议栈时会触发内核模块注册在这里的处理函数 。
触发哪个 hook 取决于包的方向(是发送还是接收)、包的目的地址、以及包在上一个 hook 点是被丢弃还是拒绝等等。
下面几个 hook 是内核协议栈中已经定义好的:
- NF_IP_PRE_ROUTING: 接收到的包进入协议栈后立即触发此 hook,在进行任何路由判断 (将包发往哪里)之前
- NF_IP_LOCAL_IN: 接收到的包经过路由判断,如果目的是本机,将触发此 hook
- NF_IP_FORWARD: 接收到的包经过路由判断,如果目的是其他机器,将触发此 hook
- NF_IP_LOCAL_OUT: 本机产生的准备发送的包,在进入协议栈后立即触发此 hook
- NF_IP_POST_ROUTING: 本机产生的准备发送的包或者转发的包,在经过路由判断之后, 将触发此 hook
注册处理函数时必须提供优先级,以便 hook 触发时能按照 优先级高低调用处理函数。这使得多个模块(或者同一内核模块的多个实例)可以在同一 hook 点注册,并且有确定的处理顺序。
内核模块会依次被调用,每次返回一个结果给 netfilter 框架,提示该对这个包做什么操作。
IPTables 表和链(Tables and Chains)
iptables 使用 table 来组织规则,根据用来做什么类型的判断(the type of decisions they are used to make)标准,将规则分为不同 table。
例如,如果规则是处理 网络地址转换的,那会放到 nat table;如果是判断是否允许包继续向前,那可能会放到 filter table。
在每个 table 内部,规则被进一步组织成 chain,内置的 chain 是由内置的 hook 触发 的。chain 基本上能决定(basically determin)规则何时被匹配。
下面可以看出,内置的 chain 名字和 netfilter hook 名字是一一对应的:
- PREROUTING: 由 NF_IP_PRE_ROUTING hook 触发
- INPUT: 由 NF_IP_LOCAL_IN hook 触发
- FORWARD: 由 NF_IP_FORWARD hook 触发
- OUTPUT: 由 NF_IP_LOCAL_OUT hook 触发
- POSTROUTING: 由 NF_IP_POST_ROUTING hook 触发
chain 使管理员可以控制在包的传输路径上哪个点(where in a packet’s delivery path)应用策略。
因为每个 table 有多个 chain,因此一个 table 可以在处理过程中的多 个地方施加影响。特定类型的规则只在协议栈的特定点有意义,因此并不是每个 table 都 会在内核的每个 hook 注册 chain。
内核一共只有 5 个 netfilter hook,因此不同 table 的 chain 最终都是注册到这几个点 。
例如,有三个 table 有 PRETOUTING chain。当这些 chain 注册到对应的 NF_IP_PRE_ROUTING hook 点时,它们需要指定优先级,应该依次调用哪个 table 的 PRETOUTING chain,优先级从高到低。
我们一会就会看到 chain 的优先级问题。
table 种类
先来看看 iptables 提供的 table 类型。这些 table 是按规则类型区分的。
Filter Table
filter table 是最常用的 table 之一,用于判断是否允许一个包通过。
在防火墙领域,这通常称作“过滤”包(”filtering” packets)。这个 table 提供了防火墙 的一些常见功能。
NAT Table
nat table 用于实现网络地址转换规则。
当包进入协议栈的时候,这些规则决定是否以及如何修改包的源/目的地址,以改变包被 路由时的行为。nat table 通常用于将包路由到无法直接访问的网络。
Mangle Table
mangle (修正)table 用于修改包的 IP 头。
例如,可以修改包的 TTL,增加或减少包可以经过的跳数。
这个 table 还可以对包打只在内核内有效的“标记”(internal kernel “mark”),后 续的 table 或工具处理的时候可以用到这些标记。标记不会修改包本身,只是在包的内核表示上做标记。
Raw Table
iptables 防火墙是有状态的:对每个包进行判断的时候是依赖已经判断过的包。
建立在 netfilter 之上的连接跟踪(connection tracking)特性使得 iptables 将包 看作已有的连接或会话的一部分,而不是一个由独立、不相关的包组成的流。
连接跟踪逻辑在包到达网络接口之后很快就应用了。
raw table 定义的功能非常有限,其唯一目的就是提供一个让包绕过连接跟踪的框架。
Security Table
security table 的作用是给包打上 SELinux 标记,以此影响 SELinux 或其他可以解读 SELinux 安全上下文的系统处理包的行为。这些标记可以基于单个包,也可以基于连接。
每种 table 实现的 chain
前面已经分别讨论了 table 和 chain,接下来看每个 table 里各有哪些 chain。
另外我们还将讨论注册到同一 hook 的不同 chain 的优先级问题。
例如如果三个 table 都有PRETOUTING chain,那应该按照什么顺序调用它们呢?
下面的表格展示了 table 和 chain 的关系。横向是 table, 纵向是 chain,Y 表示 这个 table 里面有这个 chain。
例如第二行表示 raw table 有PRETOUTING和OUTPUT两个chain。
具体到每列从上倒下的顺序就是netfilter hook触发的时候(对应table的)chain 被调用的顺序。
有几点需要说明一下。在下面的图中,nat table被细分成了 DNAT (修改目的地址) 和 SNAT(修改源地址),以更方便地展示他们的优先级。
另外我们添加了路由决策点 和连接跟踪点,以使得整个过程更完整全面:
| Tables/Chains | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| (路由判断) | - | - | - | Y | - |
| raw | Y | - | - | Y | - |
| (连接跟踪) | Y | - | - | Y | - |
| mangle | Y | Y | Y | Y | Y |
| nat (DNAT) | Y | - | - | Y | - |
| (路由判断) | Y | - | - | Y | - |
| filter | - | Y | Y | Y | - |
| security | - | Y | Y | Y | - |
| nat (SNAT) | - | Y | - | Y | Y |
当一个包触发 netfilter hook 时,处理过程将沿着列从上向下执行。 触发哪个hook(列)和包的方向(ingress/egress)、路由判断、过滤条件等相关。
特定事件会导致 table 的 chain 被跳过。
例如只有每个连接的第一个包会去匹配 NAT 规则,对这个包的动作会应用于此连接后面的所有包。到这个连接的应答包会被自动应用反方向的 NAT 规则。
Chain 遍历优先级
假设服务器知道如何路由数据包,而且防火墙允许数据包传输,下面就是不同场景下包的游走流程:
- 收到的、目的是本机的包:
PRETOUTING->INPUT - 收到的、目的是其他主机的包:
PRETOUTING->FORWARD->POSTROUTING - 本地产生的包:
OUTPUT->POSTROUTING
综合前面讨论的 table 顺序问题,我们可以看到对于一个收到的、目的是本机的包:首先依次经过PRETOUTING chain 上面的raw、mangle、nattable;然后依次经过INPUTchain 的mangle、filter、security、nattable,然后才会到达本机的某个socket。
IPTables 规则
规则放置在特定table的特定chain里面。
当chain被调用的时候,包会依次匹配chain里面的规则。每条规则都有一个匹配部分和一个动作部分
匹配
规则的匹配部分指定了一些条件,包必须满足这些条件才会和相应的将要执行的动作(target)进行关联。
匹配系统非常灵活,还可以通过 iptables extension 大大扩展其功能。规则可以匹配协 议类型、目的或源地址、目的或源端口、目的或源网段、接收或发送的接口(网卡)、协议 头、连接状态等等条件。
这些综合起来,能够组合成非常复杂的规则来区分不同的网络流量。
目标
包符合某种规则的条件而触发的动作(action)叫做目标(target)。
目标分为两种类型:
- 终止目标(terminating targets):这种 target 会终止 chain 的匹配,将控制权转移回 netfilter hook。根据返回值的不同,hook 或者将包丢弃,或者允许包进行下一阶段的处理
- 非终止目标(non-terminating targets):非终止目标执行动作,然后继续 chain 的执行。虽然每个 chain 最终都会回到一个终止目标,但是在这之前,可以执行任意多个非终止目标
每个规则可以跳转到哪个 target 依上下文而定,例如table 和 chain 可能会设置 target 可用或不可用。
规则里激活的 extensions 和匹配条件也影响 target 的可用性。
跳转到用户自定义 chain
这里要介绍一种特殊的非终止目标:跳转目标(jump target)。
jump target 是跳转到其 他 chain 继续处理的动作。我们已经讨论了很多内置的 chain,它们和调用它们的 netfilter hook 紧密联系在一起。
然而iptables 也支持管理员创建他们自己的用于管理 目的的 chain。
向用户自定义 chain 添加规则和向内置的 chain 添加规则的方式是相同的。
不同的地方在于,用户定义的 chain 只能通过从另一个规则跳转(jump)到它,因为它们没有注册到 netfilter hook。
用户定义的 chain 可以看作是对调用它的 chain 的扩展。
例如用户定义的 chain 在结束的时候,可以返回 netfilter hook,也可以继续跳转到其他自定义 chain。
这种设计使框架具有强大的分支功能,使得管理员可以组织更大更复杂的网络规则。
IPTables 和连接跟踪
在讨论 raw table 和 匹配连接状态的时候,我们介绍了构建在 netfilter 之上的连接跟踪系统。
连接跟踪系统使得 iptables 基于连接上下文而不是单个包来做出规则判断,给 iptables 提供了有状态操作的功能。
连接跟踪在包进入协议栈之后很快(very soon)就开始工作了。在给包分配连接之前所做的工作非常少,只有检查 raw table 和一些基本的完整性检查。
跟踪系统将包和已有的连接进行比较,如果包所属的连接已经存在就更新连接状态,否则就创建一个新连接。
如果 raw table 的某个 chain 对包标记为目标是 NOTRACK,那这个包会跳过连接跟踪系统。
连接的状态
连接跟踪系统中的连接状态有
- NEW:如果到达的包关连不到任何已有的连接,但包是合法的,就为这个包创建一个新连接。对 面向连接的(connection-aware)的协议例如 TCP 以及非面向连接的(connectionless )的协议例如 UDP 都适用
- ESTABLISHED:当一个连接收到应答方向的合法包时,状态从 NEW 变成 ESTABLISHED。对 TCP 这个合法包其实就是 SYN/ACK 包;对 UDP 和 ICMP 是源和目 的 IP 与原包相反的包
- RELATED:包不属于已有的连接,但是和已有的连接有一定关系。这可能是辅助连接( helper connection),例如 FTP 数据传输连接,或者是其他协议试图建立连接时的 ICMP 应答包
- INVALID:包不属于已有连接,并且因为某些原因不能用来创建一个新连接,例如无法 识别、无法路由等等
- UNTRACKED:如果在 raw table 中标记为目标是 UNTRACKED,这个包将不会进入连 接跟踪系统
- SNAT:包的源地址被 NAT 修改之后会进入的虚拟状态。连接跟踪系统据此在收到 反向包时对地址做反向转换
- DNAT:包的目的地址被 NAT 修改之后会进入的虚拟状态。连接跟踪系统据此在收到 反向包时对地址做反向转换
这些状态可以定位到连接生命周期内部,管理员可以编写出更加细粒度、适用范围更大、更 安全的规则。
calico网络插件
基础概念
业界的networkpolicy实现
当前社区对于k8s的networkpolicy的实现,不外乎三种方案:
| 方案 | 依赖 | 案例 | 支持的CNI |
|---|---|---|---|
| 基于iptables+ipset实现规则 | 容器流量需要经过宿主机的协议栈 | calico felix | calico、flannel、terway |
| 基于ovs流表实现规则 | 使用openvswitch | openshift-sdn | openshift-sdn |
| 基于ebpf hook实现规则 | 需要较高版本内核 | cilium | cilium、flannel、terway |
calico在route路由项维护各个PodCIDR路由项指的Host主机地址
又通过felix维护一套王正的networkPolicy的iptables规则项
calico/felix组织架构
calico在部署架构上做了多次演进。calico的完整架构包括了若干组件:
calico/kube-controllers: calico控制器,用于监听一些k8s资源的变更,从而进行相应的calico资源的变更。例如根据networkpolicy对象的变更,变更相应的calicopolicy对象pod2daemon: 一个initcontainer,用于构建一个Unix Domain Socket,来让Felix程序与 Dikastes (calico中支持istio的一种sidecar,详见 calico的istio集成 )进行加密通信.cni plugin/ipam plugin: 标准的CNI插件,用于配置/解除网络;分配/回收网络配置calico-nodecalico-node其实是一个数据面工具总成,包括了:felix: 管理节点上的容器网卡、路由、ACL规则;并上报节点状态bird/bird6: 用来建立bgp连接, 并根据felix配置的路由,在不同节点间分发confd: 根据当前集群数据生成本地brid的配置calicoctl: calico的CLI工具。datastore plugin: 即calico的数据库,可以是独立的etcd,也可以以crd方式记录于所在集群的k8s中typha: 类似于数据库代理,可以尽量少避免有大量的连接建立到apiserver。适用于超过100个node的集群。
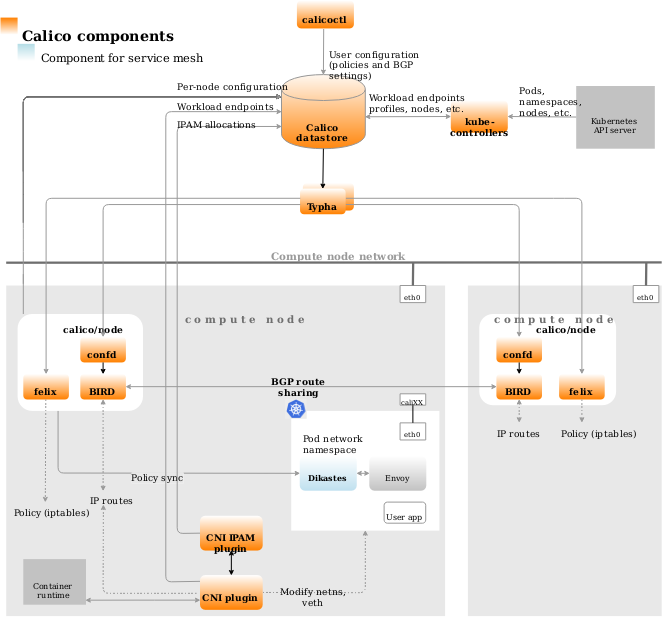
实现原理
在网络连通性(Networking)方面:calico的数据面是非常简单的三层路由转发。路由的学习和分发由bgp协议完成。
如果k8s的下层是VPC之类的三层网络环境,则需要进行overlay,calico支持ipip封装实现overlay。
在网络安全性方面:calico考虑到其Networking是依赖宿主机协议栈进行路由转发实现的,因此可以基于iptables+ipset进行流量标记、地址集规划、流量处理(放行或DROP),并且基于这些操作可以实现:
- networkpolicy的抽象概念
- calico自定义的networkpolicy,为了在openstack场景下应用而设计
- calico自定义的profile,已废弃。
这里所有的iptables规则都作用在:
- pod在宿主机namespace中的veth网卡(calico中将之称为workload)
- 宿主机nodeIP所在网卡(calico中将之称为host-endpoint,实际上这部分规则不属于k8s的networkpolicy范畴)。
主要包括如下几类规则
- iptables的INPUT链规则中,会先跳入 cali-INPUT 链,在 cali-INPUT 链中,会判断和处理两种方向的流量:
- pod访问node( cali-wl-to-host )实际上这个链中只走了 cali-from-wl-dispatch 链
- 来自node的流量( cali-from-host-endpoint )
- iptables的OUTPUT链中,会首先跳入 cali-OUTPUT 链,在 cali-OUTPUT 链中,主要会处理:
- 访问node的流量( cali-to-host-endpoint )的流量
- iptables的FORWARD链中,会首先跳入 cali-FORWARD 链,在 cali-FORWARD 链中会处理如下几种流量:
1
2
3
4
5cali-from-hep-forward
cali-from-wl-dispatch
cali-to-wl-dispatch
cali-to-hep-forward
cali-cidr-block
k8s的networkpolicy只需要关注上述流量中与pod相关的流量,因此只需要关心:1
2cali-from-wl-dispatch
cali-to-wl-dispatch
这两个链的规则,对应到pod的egress和ingress networkpolicy。
- 除了nat表,在raw和mangle表中还有对calico关注的网卡上的收发包进行初始标记的规则,和最终的判断规则。
- 在
https://github.com/projectcalico/felix/blob/master/rules/static.go中可以看到完整的静态iptables表项的设计
- 在
接着iptables规则中还会在cali-from-wl-dispatch和cali-to-wl-dispatch两个链中根据收包/发包的网卡判断这是哪个pod,走到该pod的egress或ingress链中。
每个pod的链中则又设置了对应networkpolicy实例规则的链以此递归调用。
这样pod的流量经过INPUT/OUTPUT/FORWARD等链后,递归地走了多个链,每个链都会Drop或者Return,如果把链表走一遍下来一直Return,会Return到INPUT/OUTPUT/FORWARD, 然后执行ACCEPT,也就是说这个流量满足了某个networkpolicy的规则限制。
如果过程中被Drop了,就表示受某些规则限制,这个链路不通。
felix实现networkpolicy的案例
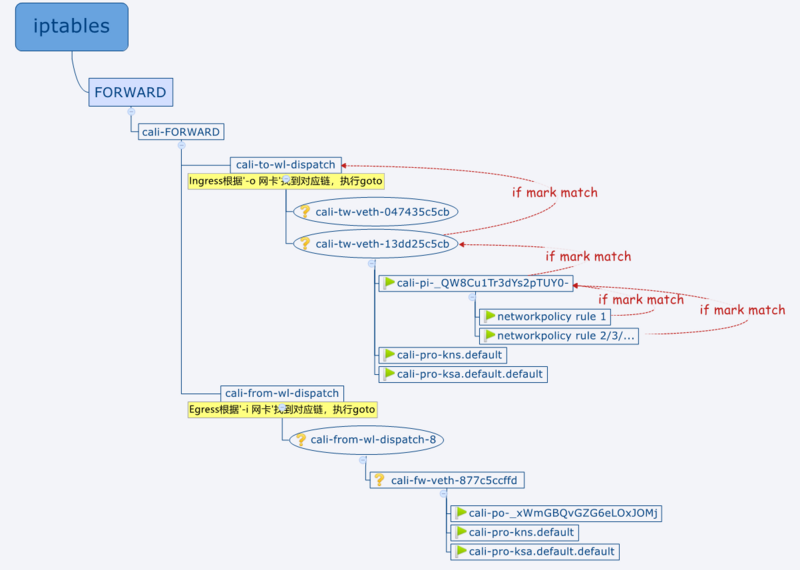
我们通过一个简单的例子来描述iptables这块的链路顺序。
1 | spec: |
- 他作用于
hyapp=server的label的pod - 这类pod出方向不限制
- 这类pod的入站规则中只允许如下几种流量:
hyapp=client1
我们使用iptables -L或iptables-save命令来分析机器上的iptables规则。
因为是入站规则,所以我们可以观察iptables表中的cali-to-wl-dispatch链。
另外该networkpolicy的作用pod只有一个,它的host侧网卡是veth-13dd25c5cb。
我们可以看到如下的几条规则:1
2
3
4
5Chain cali-to-wl-dispatch (1 references)
target prot opt source destination
cali-to-wl-dispatch-0 all -- anywhere anywhere [goto] /* cali:Ok_j0t6AwtLyoFYU */
cali-tw-veth-13dd25c5cb all -- anywhere anywhere [goto] /* cali:909gC5dwdBI3E96S */
DROP all -- anywhere anywhere /* cali:4M4uUxEEGrRKj1PR */ /* Unknown interface */
注意这里有一个cali-to-wl-dispatch-0的链,是用来做前缀映射的, 该链的规则下包含所有cali-tw-veth-0这个前缀的链
1 | Chain cali-to-wl-dispatch-0 (1 references) |
这是felix设计上用于减少iptables规则遍历次数的一个优化手段。
我们通过iptables-save |grep cali-to-wl-dispatch命令,可以发现如下的规则:
1 | cali-to-wl-dispatch -o veth-13dd25c5cb -m comment --comment "cali:909gC5dwdBI3E96S" -g cali-tw-veth-13dd25c5cb |
意思就是在cali-to-wl-dispatch链中,根据pod在host侧网卡的名字,会执行cali-tw-veth-13dd25c5cb链, 我们再看这条链
1 | Chain cali-tw-veth-13dd25c5cb (1 references) |
- 第1、2条:如果ct表中能检索到该连接的状态,我们直接根据状态来确定这个流量的处理方式,这样可以省略很大一部分工作。
- 第3条:先对包进行标记(将第17位置0),在本链的规则执行完毕后,会判断标记是否match(判断第17位是否有被置1),不匹配(没有被置1)就DROP;
- 第4条:如果该网卡对应的pod有相关的networkpolicy,要再打一次mark,与之前的mark做与计算后目前mark应该是
0xfffcffff(17、18位为0); - 第5条:如果包
mark match 0x0/0x20000(第18位为0), 执行cali-pi-_QW8Cu1Tr3dYs2pTUY0-链进入networkpolicy的判断。 - 第6、7条:如果networkpolicy检查通过,会对包进行mark修改, 所以检查是否
mark match 0x10000/0x10000, 匹配说明通过,直接RETURN,不再检查其他的规则;如果mark没有修改,与原先一致,视为没有任何一个networkpolicy允许该包通过,直接DROP - 第8、9、10、11条:当没有任何相关的networkpolicy时(即第4~7条不存在)才会被执行,执行calico的 profile 策略,分成namespace维度和serviceaccount维度,如果在这两个策略里没有对包的mark做任何修改,就表示通过。这两个策略是calico的概念,且为了不与networkpolicy混淆,已经被弃用了。因此此处都是空的。
- 第12条:如果包没有进入 上述两个profile链,DROP。
接着看networkpolicy的链
cali-pi-_QW8Cu1Tr3dYs2pTUY0-,只要在这个链里执行Return前有将包打上mark使其match 0x10000/0x10000就表示匹配了某个networkpolicy规则,包允许放行:
1 | Chain cali-pi-_QW8Cu1Tr3dYs2pTUY0- (1 references) |
- 第1、2条:如果
src ip match ipset: cali40s:9WLohU2k-3hMTr5j-HlIcA0,将包mark or 0x10000, 并检查是否match,match就RETUR。 我们可以在机器上执行ipset list cali40s:9WLohU2k-3hMTr5j-HlIcA0,可以看到这个ipset里包含的就是networkpolicy中指明的、带有 hyapp=client1 这个label的两个pod的ip。 - 第3、4、5、6条则是针对networkpolicy中的第二部分规则,先对包设置正向标记,然后将要隔离的
src IP/IP段进行判断并做反向标记,接着判断src段是否在准入范围,如果在,并且目的端口匹配,并且标记为正向,就再对包进行MARK or 0x10000,这样最终判断match了就会Return。 - 实际上我们可以看到,这里就算不match,这个链执行完了也还是会RETURN的,所以这个链执行的结果是通过mark返回给上一级的,这就是为什么调用该链的上一级,会在调用完毕后要判断mark并确认是否ACCEPT。
至此一个完整的networkpolicy的实现链路就完成了。
cilium网络插件
安装指南
所有机器升级内核
导入升级内核的yum源
1 | rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org |
查看可用版本 kernel-lt指长期稳定版 kernel-ml指最新版
1 | yum --disablerepo="*" --enablerepo="elrepo-kernel" list available |
安装kernel-ml
1 | yum --enablerepo=elrepo-kernel install kernel-ml kernel-ml-devel -y |
设置启动项
查看系统上的所有可用内核
1 | awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg |
设置新的内核为grub2的默认版本
1 | grub2-set-default 'CentOS Linux (5.7.7-1.el7.elrepo.x86_64) 7 (Core) 查看自己本机内核版本' |
生成 grub 配置文件并重启
1 | grub2-mkconfig -o /boot/grub2/grub.cfg |
接下来按照kubeadm的安装以及cilium官网的安装流程继续
深入理解 Cilium 的 eBPF 收发包路径
为什么要关注 eBPF?
网络成为瓶颈
大家已经知道网络成为瓶颈,但我是从下面这个角度考虑的:近些年业界使用网络的方式 ,使其成为瓶颈(it is the bottleneck in a way that is actually pretty recent) 。
网络一直都是 I/O 密集型的,但直到最近,这件事情才变得尤其重要。
分布式任务(workloads)业界一直都在用,但直到近些年,这种模型才成为主流。 虽然何时成为主流众说纷纭,但我认为最早不会早于 90 年代晚期。
公有云的崛起,我认为可能是网络成为瓶颈的最主要原因。
这种情况下,用于管理依赖和解决瓶颈的工具都已经过时了。
但像 eBPF 这样的技术使得网络调优和整流变得简单很多。 eBPF 提供的许多能力是其他工具无法提供的,或者即使提供了,其代价也要比 eBPF 大的多。
eBPF 无处不在
eBPF 正在变得无处不在,我们可能会争论这到底是一件好事还是坏事(eBPF 也确实带了一些安全问题),但当前无法忽视的事实是:Linux 内核的网络开发者们正在将 eBPF 应用于各种地方
其结果是eBPF 与内核的默认收发包路径( datapath)耦合得越来越紧(more and more tightly coupled with the default datapath)。
性能就是金钱
“Metrics are money” 这是今年 Paris Kernel Recipes 峰会上,来自 Synthesio 的 Aurelian Rougemont 的精彩分享。
他展示了一些史诗级的调试案例,感兴趣的可以去看看;但更重要的是,他从更高层次提出了这样一个观点:理解这些东西是如何工作的,最终会产生资本收益
为客户节省金钱,为自己带来收入。
如果你能从更少的资源中榨取出更高的性能,使软件运行更快,那显然你对公司的贡献就更大。
Cilium 就是这样一个能让你带来更大价值的工具。
在进一步讨论之前,我先简要介绍一下eBPF是什么,以及为什么它如此强大。
eBPF 是什么?
图 2.1. eBPF 代码示例:丢弃源 IP 命中黑名单的 ARP 包
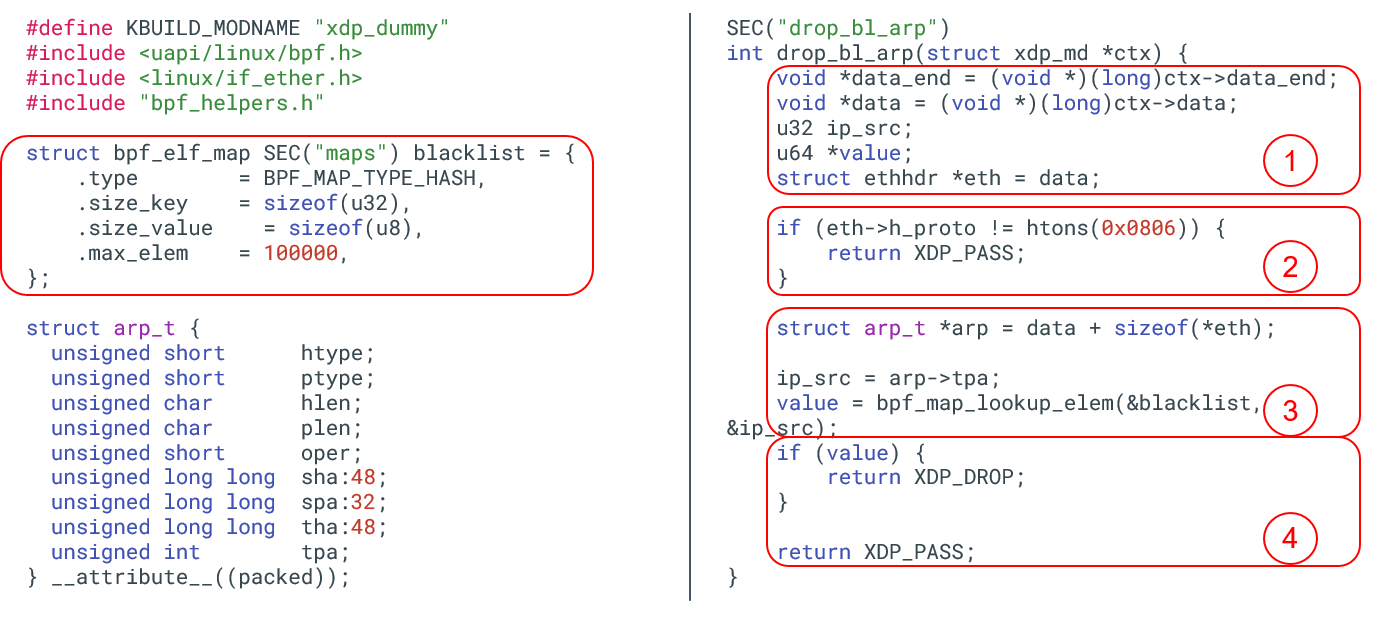
BPF 程序有多种类型,图 2.1 是其中一种,称为 XDP BPF 程序。
- XDP 是 eXpress DataPath(特快数据路径)。
- XDP 程序可以直接加载到网络设备上。
- XDP 程序在数据包收发路径上很前面的位置就开始执行,下面会看到例子。
BPF 程序开发方式:
- 编写一段 BPF 程序
- 编译这段 BPF 程序
- 用一个特殊的系统调用将编译后的代码加载到内核
这实际上就是编写了一段内核代码,并动态插入到了内核(written kernel code and dynamically inserted it into the kernel)。
图 2.1 中的程序使用了一种称为 map 的东西,这是一种特殊的数据结构,可用于 在内核和用户态之间传递数据,例如通过一个特殊的系统从用户态向 map 里插入数据。
这段程序的功能:丢弃所有源 IP 命中黑名单的 ARP 包。右侧四个框内的代码功能:
- 初始化以太帧结构体(ethernet packet)。
- 如果不是 ARP 包,直接退出,将包交给内核继续处理。
- 至此已确定是 ARP,因此初始化一个 ARP 数据结构,对包进行下一步处理。例 如,提取出 ARP 中的源 IP,去之前创建好的黑名单中查询该 IP 是否存在。
- 如果存在,返回丢弃判决(XDP_DROP);否则,返回允许通行判决( XDP_PASS),内核会进行后续处理。
你可能不会相信,就这样一段简单的程序,会让服务器性能产生质的飞跃,因为它此时已 经拥有了一条极为高效的网络路径。
为什么 eBPF 如此强大?
三方面原因:
- 快速(fast)
- 灵活(flexible)
- 数据与功能分离(separates data from functionality)
快速
eBPF 几乎总是比 iptables 快,这是有技术原因的。
- eBPF 程序本身并不比 iptables 快,但 eBPF 程序更短。
- iptables 基于一个非常庞大的内核框架(Netfilter),这个框架出现在内核 datapath 的多个地方,有很大冗余。
因此同样是实现 ARP drop 这样的功能,基于 iptables 做冗余就会非常大,导致性能很低。
灵活
这可能是最主要的原因。你可以用 eBPF 做几乎任何事情。
eBPF 基于内核提供的一组接口,运行 JIT 编译的字节码,并将计算结果返回给内核。例如 内核只关心 XDP 程序的返回是 PASS, DROP 还是 REDIRECT。至于在 XDP 程序里做什么, 完全看你自己。
数据与功能分离
nftables 和 iptables 也能干这个事情,但功能没有 eBPF 强大。例如,eBPF 可以使 用 per-cpu 的数据结构,因此能取得更极致的性能。
eBPF 真正的优势是将“数据与功能分离”这件事情做地非常干净:可以在 eBPF 程序不中断的情况下修改它的运行方式。具体方式是修改它访 问的配置数据或应用数据,例如黑名单里规定的 IP 列表和域名。
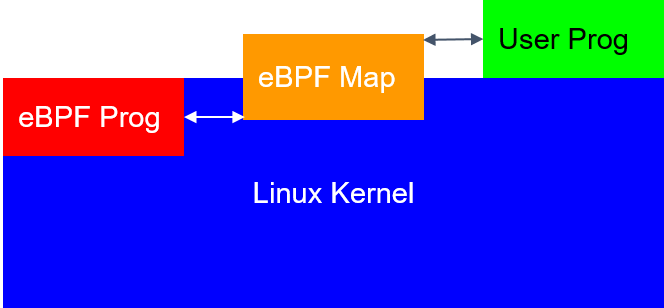
Cilium 是什么,为什么要关注它?
我认为理解 eBPF 代码还比较简单,多看看内核代码就行了,但配置和编写 eBPF 就要难多了。
Cilium 是一个很好的 eBPF 之上的通用抽象,覆盖了分布式系统的绝大多数场景。Cilium 封装了 eBPF,提供一个更上层的 API。
如果你使用的是 Kubernetes,那你至少应该听说过 Cilium。 Cilium 提供了 CNI 和 kube-proxy replacement 功能,相比 iptables 性能要好很多。
接下来开始进入本文重点。
内核默认 datapath
本节将介绍数据包是如何穿过 network datapath(网络数据路径)的:包括从硬件到内核,再到用户空间。
这里将只介绍 Cilium 所使用的 eBPF 程序,其中有 Cilium logo 的地方,都是 datapath 上 Cilium 重度使用 BPF 程序的地方。
本文不会过多介绍硬件相关内容,因为理解 eBPF 基本不需要硬件知识,但显然理解了硬件原理也并无坏处。另外由于时间限制,我将只讨论接收部分。
L1 -> L2(物理层->数据链路层)
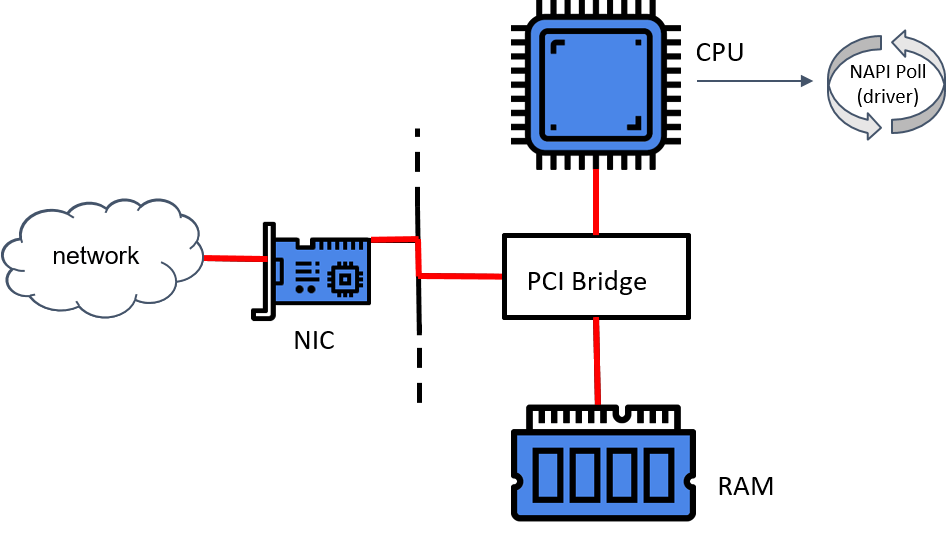
网卡收包简要流程
- 网卡驱动初始化。
- 网卡获得一块物理内存,作用收发包的缓冲区(ring-buffer)。这种方式称为 DMA(直接内存访问)。
- 驱动向内核 NAPI(New API)注册一个轮询(poll )方法。
- 网卡从云上收到一个包,将包放到 ring-buffer。
- 如果此时 NAPI 没有在执行,网卡就会触发一个硬件中断(HW IRQ),告诉处理器 DMA 区域中有包等待处理。
- 收到硬中断信号后,处理器开始执行 NAPI。
- NAPI 执行网卡注册的 poll 方法开始收包。
关于 NAPI poll 机制
- 这是 Linux 内核中的一种通用抽象,任何等待不可抢占状态发生(wait for a preemptible state to occur)的模块,都可以使用这种注册回调函数的方式。
- 驱动注册的这个 poll 是一个主动式 poll(active poll),一旦执行就会持续处理 ,直到没有数据可供处理,然后进入 idle 状态。
- 在这里,执行 poll 方法的是运行在某个或者所有 CPU 上的内核线程(kernel thread)。 虽然这个线程没有数据可处理时会进入 idle 状态,但如前面讨论的,在当前大部分分布 式系统中,这个线程大部分时间内都是在运行的,不断从驱动的 DMA 区域内接收数据包。
- poll 会告诉网卡不要再触发硬件中断,使用软件中断(softirq)就行了。此后这些 内核线程会轮询网卡的 DMA 区域来收包。之所以会有这种机制,是因为硬件中断代价太 高了,因为它们比系统上几乎所有东西的优先级都要高。
我们接下来还将多次看到这个广义的 NAPI 抽象,因为它不仅仅处理驱动,还能处理许多其他场景。内核用 NAPI 抽象来做驱动读取(driver reads)、epoll 等等。
NAPI 驱动的 poll 机制将数据从 DMA 区域读取出来,对数据做一些准备工作,然后交给比 它更上一层的内核协议栈。
同样这里不会深入展开驱动层做的事情,而主要关注内核所做的一些更上层的事情,例如
- 分配 socket buffers(skb)
- BPF
- iptables
- 将包送到网络栈(network stack)和用户空间
1.NAPI poll
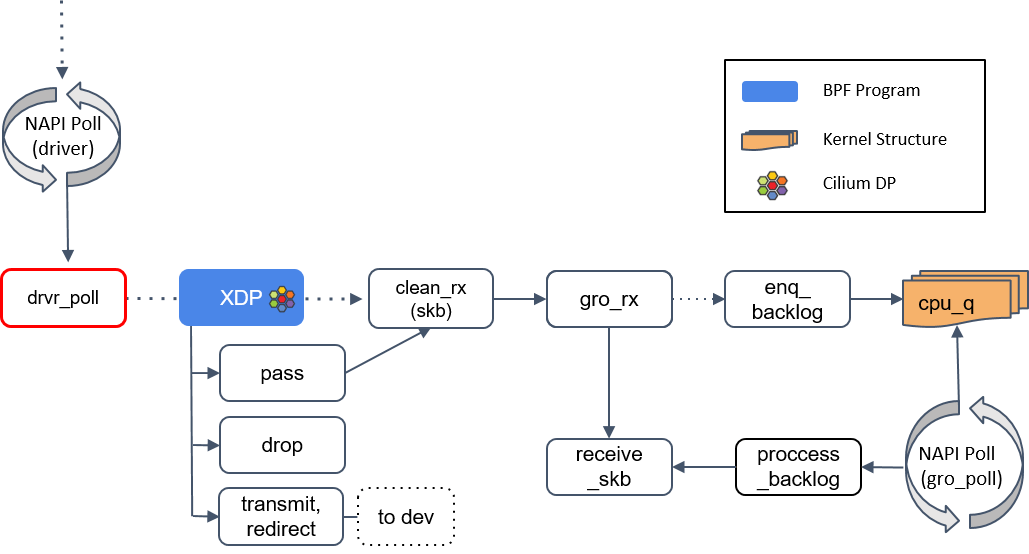
2.XDP 程序处理
如果驱动支持 XDP,那 XDP 程序将在 poll 机制内执行。如果不支持,那 XDP 程序将只能在更后面执行(run significantly upstack,见 Step 6),性能会变差, 因此确定你使用的网卡是否支持 XDP 非常重要。
XDP 程序返回一个判决结果给驱动,可以是 PASS, TRANSMIT, 或 DROP。
Transmit 非常有用,有了这个功能,就可以用 XDP 实现一个 TCP/IP 负载均衡器。 XDP 只适合对包进行较小修改,如果是大动作修改,那这样的 XDP 程序的性能 可能并不会很高,因为这些操作会降低 poll 函数处理 DMA ring-buffer 的能力。
更有趣的是 DROP 方法,因为一旦判决为 DROP,这个包就可以直接原地丢弃了,而 无需再穿越后面复杂的协议栈然后再在某个地方被丢弃,从而节省了大量资源。如果本次 分享我只能给大家一个建议,那这个建议就是:在 datapath 越前面做 tuning 和 dropping 越好,这会显著增加系统的网络吞吐。
如果返回是 PASS,内核会继续沿着默认路径处理包,到达 clean_rx() 方法。
3.clean_rx():创建 skb
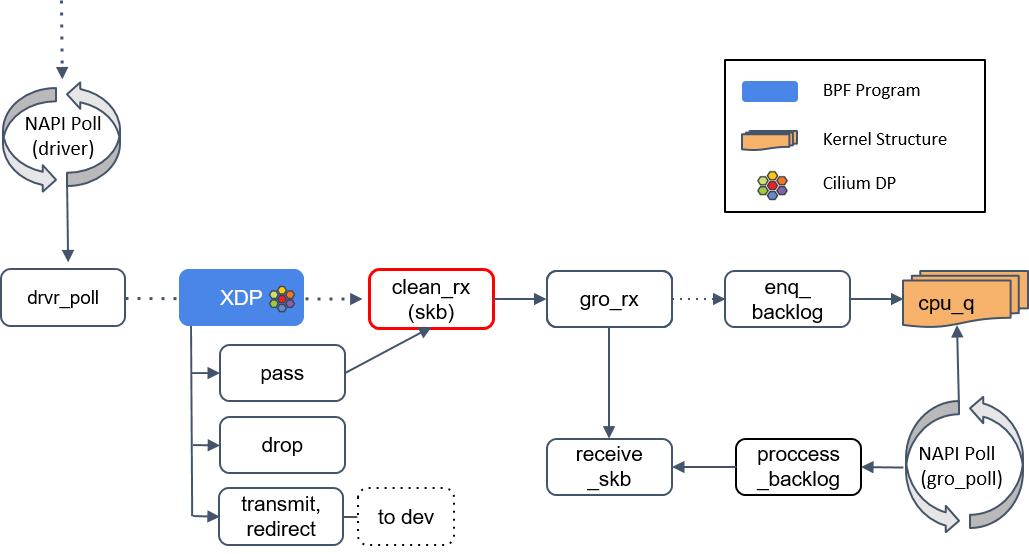
如果返回是 PASS,内核会继续沿着默认路径处理包,到达 clean_rx() 方法。
这个方法创建一个 socket buffer(skb)对象,可能还会更新一些统计信息,对 skb 进行硬件校验和检查,然后将其交给 gro_receive() 方法。
4.gro_receive()
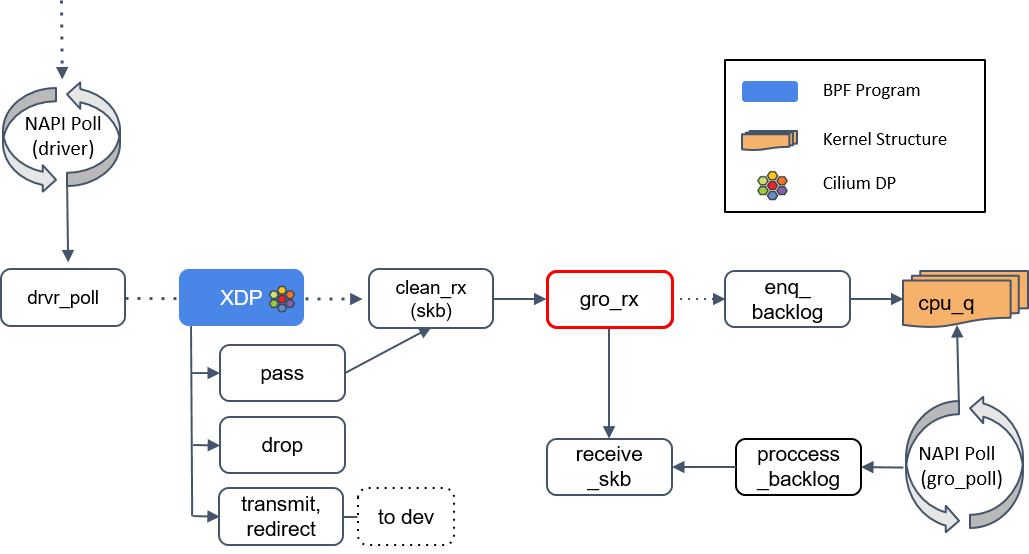
GRO 是一种较老的硬件特性(LRO)的软件实现,功能是对分片的包进行重组然后交给更上层,以提高吞吐。
GRO 给协议栈提供了一次将包交给网络协议栈之前,对其检查校验和 、修改协议头和发送应答包(ACK packets)的机会。
- 如果 GRO 的 buffer 相比于包太小了,它可能会选择什么都不做。
- 如果当前包属于某个更大包的一个分片,调用 enqueue_backlog 将这个分片放到某个 CPU 的包队列。当包重组完成后,会交给 receive_skb() 方法处理。
- 如果当前包不是分片包,直接调用 receive_skb(),进行一些网络栈最底层的处理。
5.receive_skb()
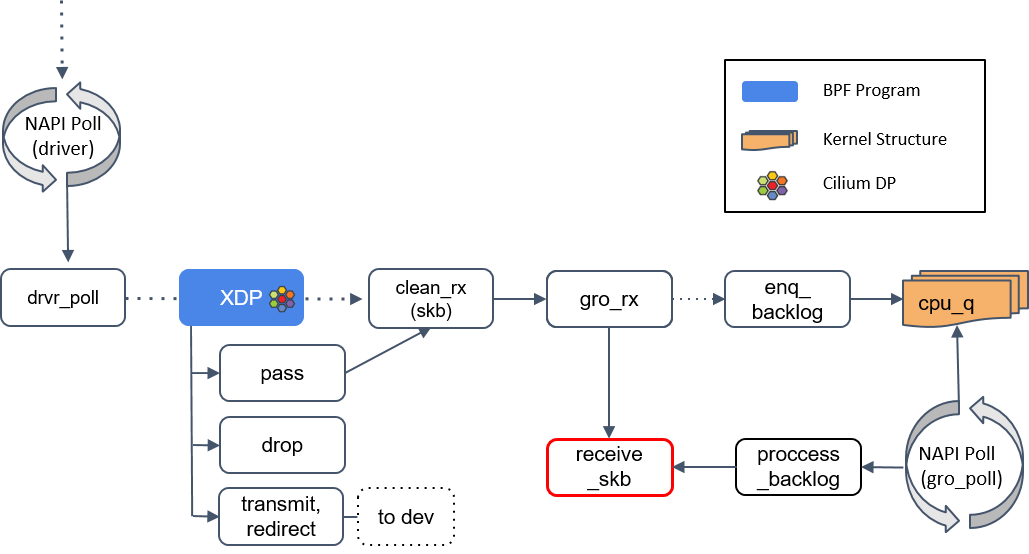
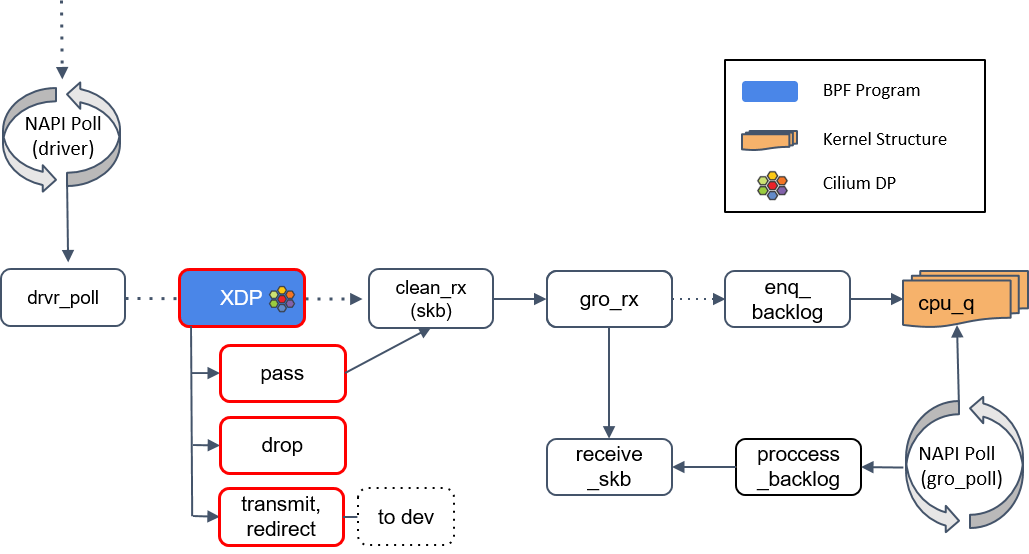
receive_skb()之后会再次进入 XDP 程序点。
L2 -> L3(数据链路层 -> 网络层)
6.通用 XDP 处理(gXDP)
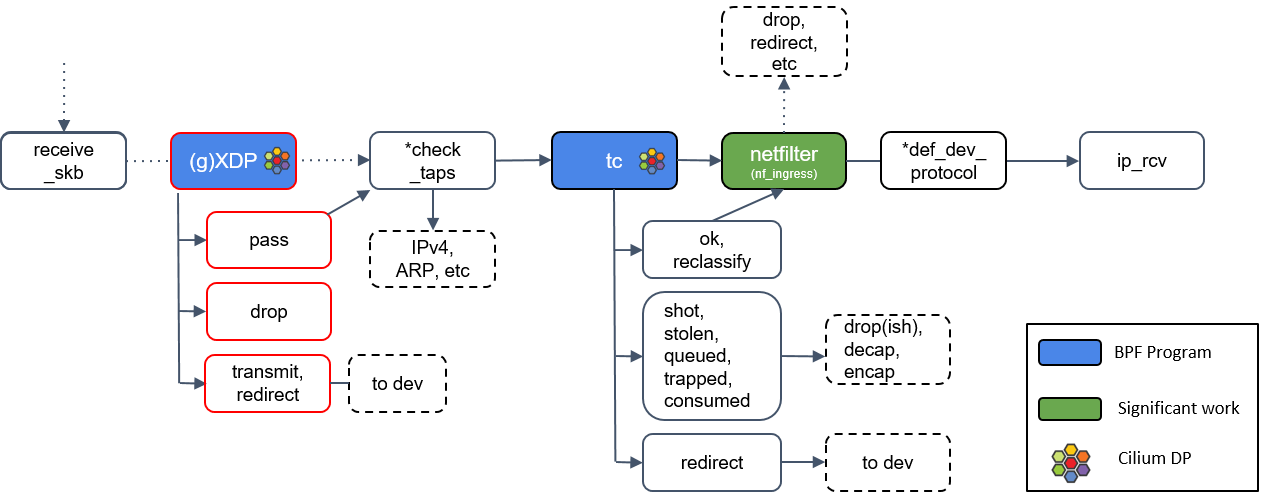
receive_skb() 之后,我们又来到了另一个 XDP 程序执行点。这里可以通过 receive_xdp() 做一些通用(generic)的事情,因此我在图中将其标注为 (g)XDP
Step 2 中提到,如果网卡驱动不支持 XDP,那 XDP 程序将延迟到更后面执行,这个 “更后面”的位置指的就是这里的 (g)XDP。
7.Tap 设备处理
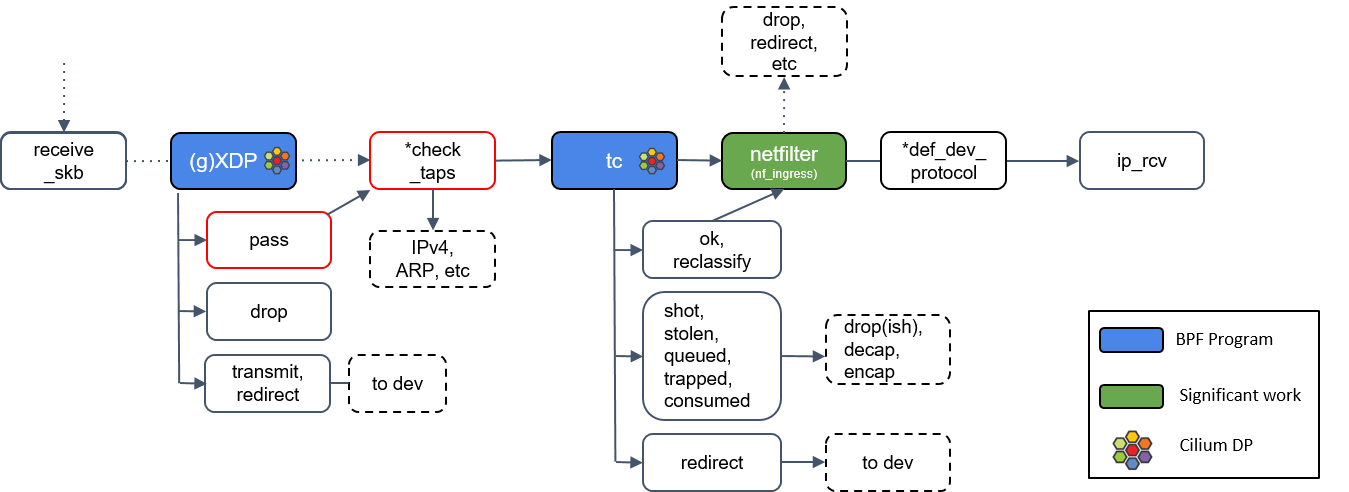
图中有个*check_taps框,但其实并没有这个方法:receive_skb()会轮询所有的 socket tap,将包放到正确的 tap 设备的缓冲区。
tap 设备监听的是三层协议(L3 protocols),例如 IPv4、ARP、IPv6 等等。如果 tap 设 备存在,它就可以操作这个 skb 了。
8.tc(traffic classifier)处理
接下来我们遇到了第二种 eBPF 程序:tc eBPF。
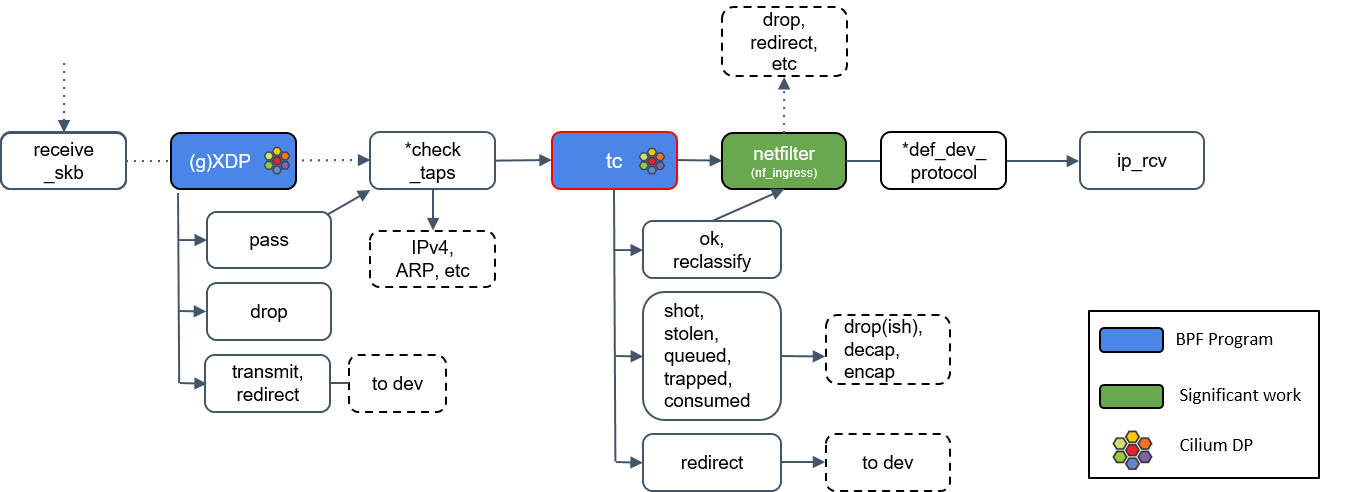
tc(traffic classifier,流量分类器)是 Cilium 依赖的最基础的东西,它提供了多种功 能,例如修改包(mangle,给 skb 打标记)、重路由(reroute)、丢弃包(drop),这 些操作都会影响到内核的流量统计,因此也影响着包的排队规则(queueing discipline )。
Cilium 控制的网络设备,至少被加载了一个 tc eBPF 程序。
译者注:如何查看已加载的 eBPF 程序,可参考 Cilium Network Topology and Traffic Path on AWS。
9.Netfilter 处理
如果 tc BPF 返回 OK,包会再次进入 Netfilter。
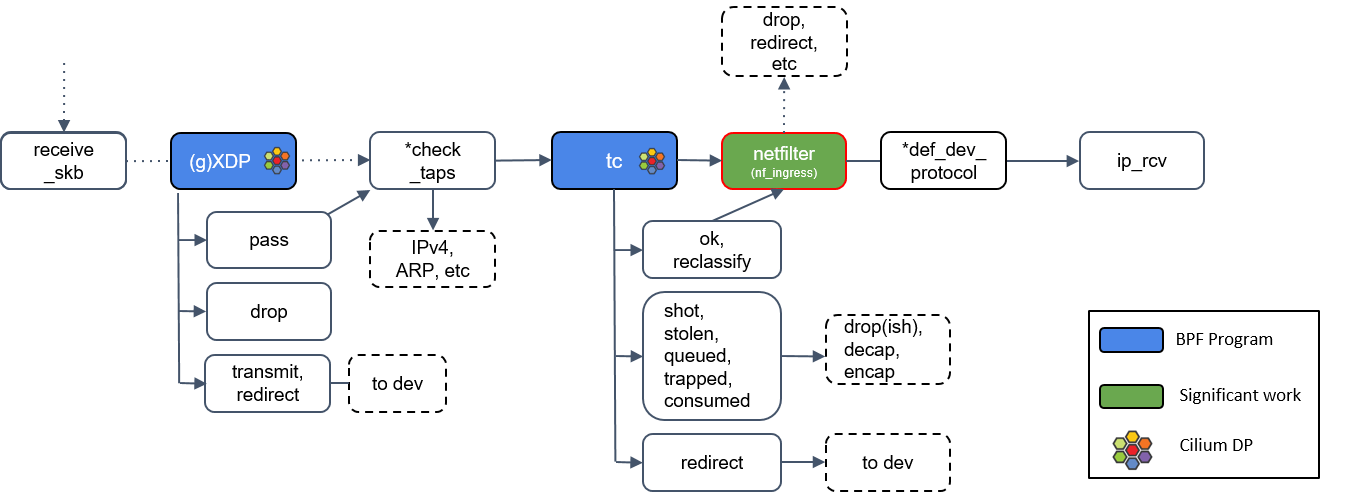
Netfilter 也会对入向的包进行处理,这里包括 nftables 和 iptables 模块。
有一点需要记住的是:Netfilter 是网络栈的下半部分(the “bottom half” of the network stack),因此 iptables 规则越多,给网络栈下半部分造成的瓶颈就越大。*def_dev_protocol框是二层过滤器(L2 net filter),由于 Cilium 没有用到任何 L2 filter,因此这里我就不展开了。
10.L3 协议层处理:ip_rcv()
最后,如果包没有被前面丢弃,就会通过网络设备的ip_rcv()方法进入协议栈的三层( L3)—— 即 IP 层 —— 进行处理。
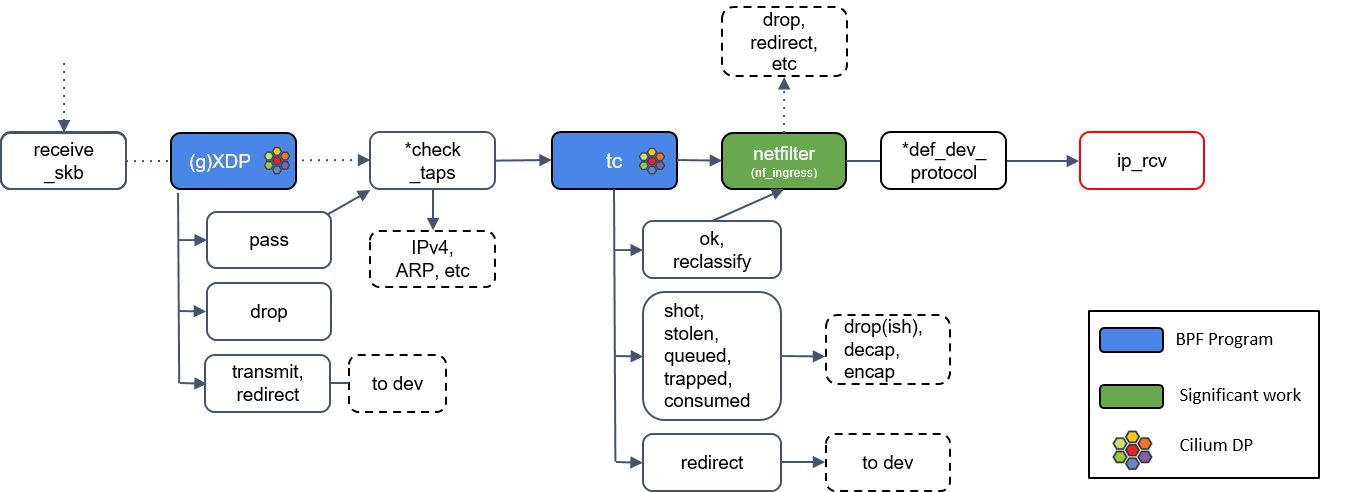
接下来我们将主要关注这个函数,但这里需要提醒大家的是,Linux 内核也支持除了 IP 之 外的其他三层协议,它们的 datapath 会与此有些不同。
L3 -> L4(网络层 -> 传输层)
11.Netfilter L4 处理
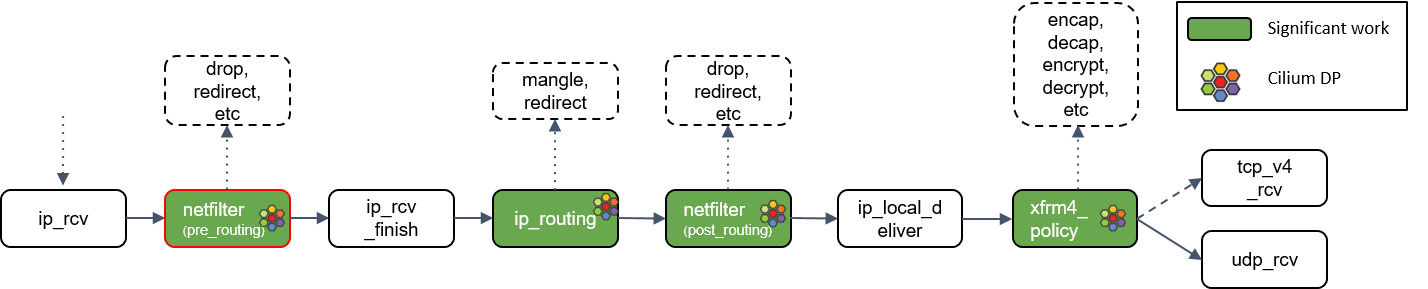
ip_rcv() 做的第一件事情是再次执行 Netfilter 过滤,因为我们现在是从四层(L4)的 视角来处理 socker buffer。因此,这里会执行 Netfilter 中的任何四层规则(L4 rules )。
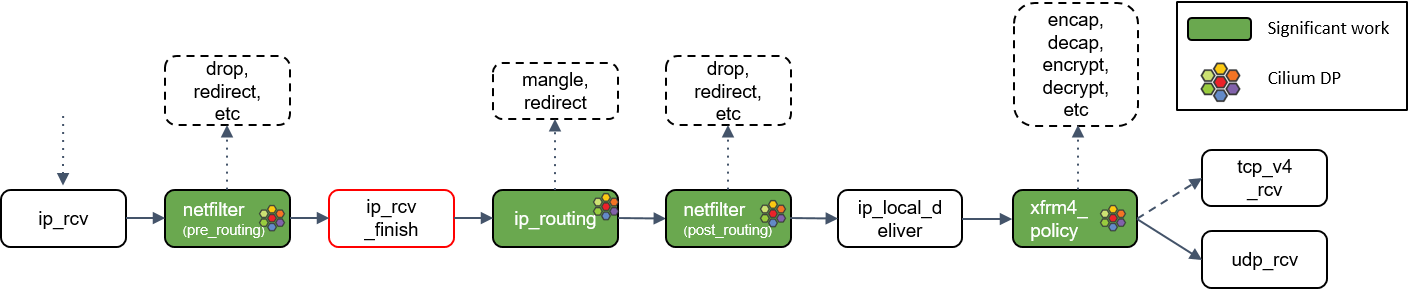
12.ip_rcv_finish() 处理
Netfilter 执行完成后,调用回调函数ip_rcv_finish()。
ip_rcv_finish()立即调用ip_routing()对包进行路由判断。
13.ip_routing() 处理
ip_routing()对包进行路由判断,例如看它是否是在 lookback 设备上,是否能 路由出去(could egress),或者能否被路由,能否被unmangle到其他设备等等。
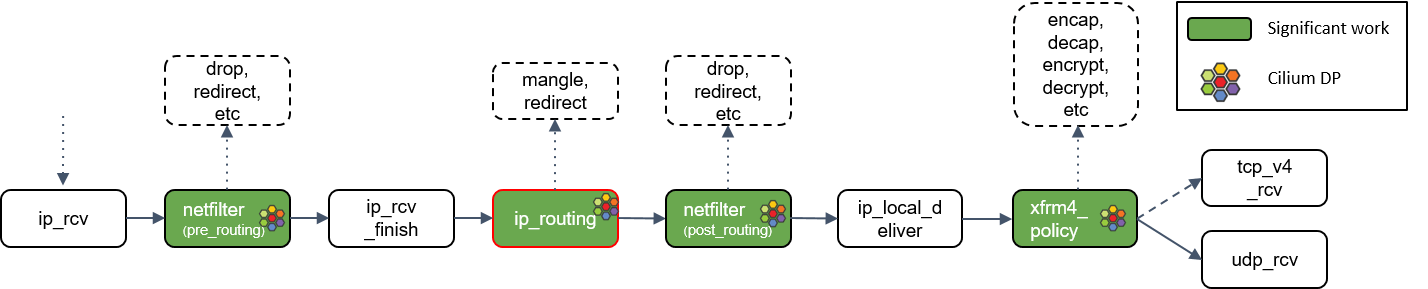
在 Cilium 中,如果没有使用隧道模式(tunneling),那就会用到这里的路由功能。相比 隧道模式,路由模式会的 datapath 路径更短,因此性能更高。
14.目的是本机:ip_local_deliver() 处理
根据路由判断的结果,如果包的目的端是本机,会调用ip_local_deliver()方法。
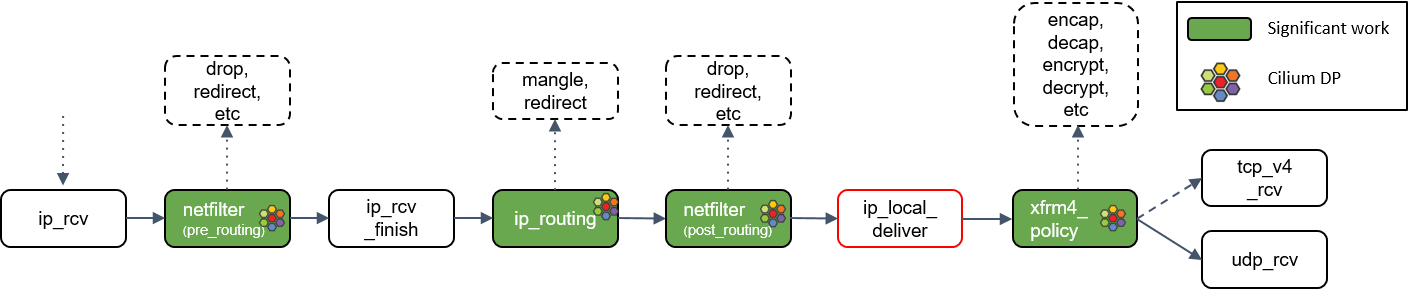
ip_local_deliver()会调用xfrm4_policy()。
15.xfrm4_policy() 处理
xfrm4_policy()完成对包的封装、解封装、加解密等工作。例如,IPSec 就是在这里完成的。
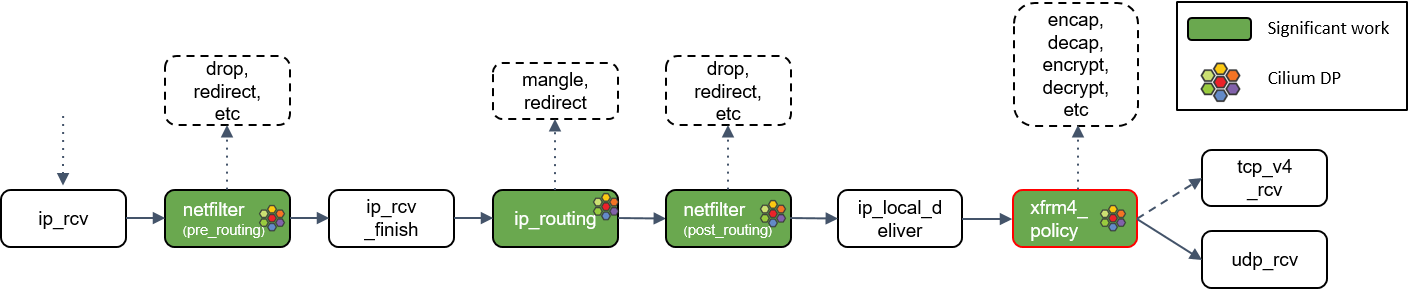
最后,根据四层协议的不同,ip_local_deliver() 会将最终的包送到 TCP 或 UDP 协议 栈。这里必须是这两种协议之一,否则设备会给源 IP 地址回一个 ICMP destination unreachable 消息。
接下来我将拿 UDP 协议作为例子,因为 TCP 状态机太复杂了,不适合这里用于理解 datapath 和数据流。但不是说 TCP 不重要,Linux TCP 状态机还是非常值得好好学习的。
L4(传输层,以 UDP 为例)
16.udp_rcv() 处理
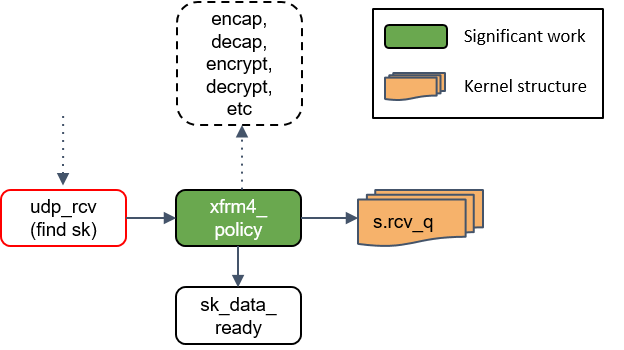
udp_rcv()对包的合法性进行验证,检查 UDP 校验和。然后,再次将包送到xfrm4_policy()进行处理。
17.xfrm4_policy() 再次处理
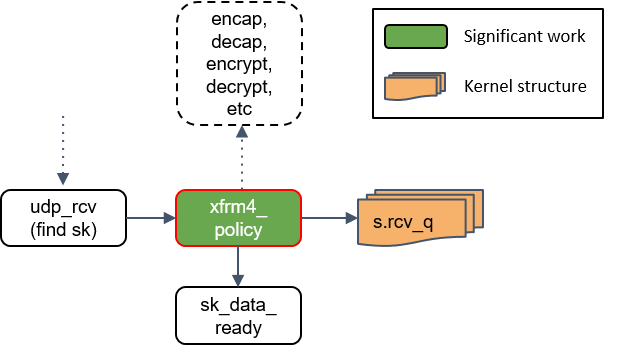
这里再次对包执行 transform policies 是因为,某些规则能指定具体的四层协议,所以只 有到了协议层之后才能执行这些策略。
18.将包放入 socket_receive_queue
这一步会拿端口(port)查找相应的 socket,然后将 skb 放到一个名为socket_receive_queue的链表。
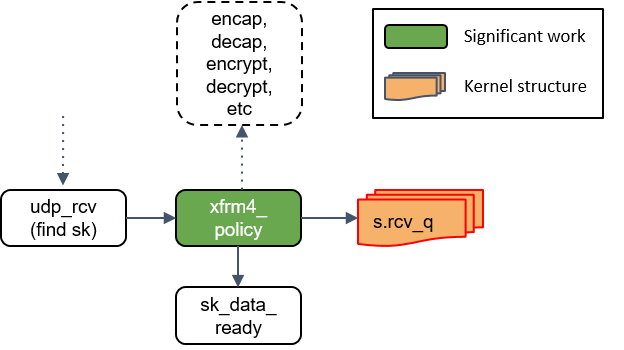
19.通知 socket 收数据:sk_data_ready()
最后udp_rcv() 调用 sk_data_ready() 方法,标记这个 socket 有数据待收。
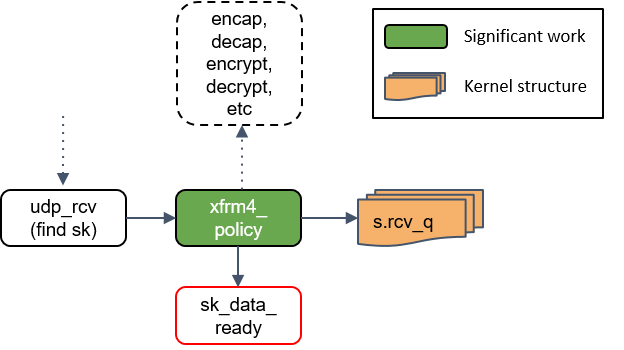
本质上,一个 socket 就是 Linux 中的一个文件描述符,这个描述符有一组相关的文件操 作抽象,例如 read、write 等等。
网络栈下半部分小结
以上 Step 1~19 就是 Linux 网络栈下半部分(bottom half of the network stack)的全部内容。
接下来我们还会介绍几个内核函数,但它们都是与进程上下文相关的。
L4 - User Space
下图左边是一段 socket listening 程序,这里省略了错误检查,而且 epoll 本质上也 是不需要的,因为 UDP 的 recv 方法以及在帮我们 poll 了。

由于大家还是对 TCP 熟悉一些,因此在这里我假设这是一段 TCP 代码。事实上当我们调 用 recvmsg() 方法时,内核所做的事情就和上面这段代码差不多。对照右边的图:
- 首先初始化一个 epoll 实例和一个 UDP socket,然后告诉 epoll 实例我们想 监听这个 socket 上的 receive 事件,然后等着事件到来。
- 当 socket buffer 收到数据时,其 wait queue 会被上一节的 sk_data_ready() 方法置位(标记)。
- epoll 监听在 wait queue,因此 epoll 收到事件通知后,提取事件内容,返回给用户空间。
- 用户空间程序调用 recv 方法,它接着调用 udp_recv_msg 方法,后者又会调用 cgroup eBPF 程序 —— 这是本文出现的第三种 BPF 程序。Cilium 利用 cgroup eBPF 实现 socket level 负载均衡,这非常酷:
- 一般的客户端负载均衡对客户端并不是透明的,即,客户端应用必须将负载均衡逻辑内置到应用里。
- 有了 cgroup BPF,客户端根本感知不到负载均衡的存在。
- 本文介绍的最后一种 BPF 程序是 sock_ops BPF,用于 socket level 整流(traffic shaping ),这对某些功能至关重要,例如客户端级别的限速(rate limiting)。
- 最后,我们有一个用户空间缓冲区,存放收到的数据。
以上就是 Cilium 基于 eBPF 的内核收包之旅(traversing the kernel’s datapath)。太壮观了!
Kubernets、Cilium 和 Kernel:原子对象对应关系
| Kubernetes | Cilium | Kernel |
|---|---|---|
| Endpoint (includes Pods) | Endpoint | tc, cgroup socket BPF, sock_ops BPF, XDP |
| Network Policy | Cilium Network Policy | XDP, tc, sock-ops |
| Service (node ports, cluster ips, etc) | Service | XDP, tc |
| Node | Node | ip-xfrm (for encryption), ip tables for initial decapsulation routing (if vxlan), veth-pair, ipvlan |
以上就是 Kubernetes 的所有网络对象(the only artificial network objects)。什么意思? 这就是 k8s CNI 所依赖的全部网络原语(network primitives)。
例如LoadBalancer 对象只是 ClusterIP 和 NodePort 的组合,而后二者都属于 Service 对象,所以他们并不是一等对象。
这张图非常有价值,但不幸的是,实际情况要比这里列出的更加复杂,因为 Cilium 本身的 实现是很复杂的。这有两个主要原因,我觉得值得拿出来讨论和体会:
首先,内核 datapath 要远比我这里讲的复杂。
前面只是非常简单地介绍了协议栈每个位置(Netfilter、iptables、eBPF、XDP)能执行的动作。
这些位置提供的处理能力是不同的。
例如XDP 可能是能力最受限的,因为它只是设计用来做快速丢包(fast dropping)和 非本地重定向(non-local redirecting);
但另一方面,它又是最快的程序,因为它在整个 datapath 的最前面,具备对整个 datapath 进行短路处理(short circuit the entire datapath)的能力。
tc 和 iptables 程序能方便地 mangle 数据包,而不会对原来的转发流程产生显著影响。
理解这些东西非常重要,因为这是 Cilium 乃至广义 datapath 里非常核心的东西。如 果遇到底层网络问题,或者需要做 Cilium/kernel 调优,那你必须要理解包的收发/转发 路径,有时你会发现包的某些路径非常反直觉。
第二个原因是,eBPF 还非常新,某些最新特性只有在 5.x 内核中才有。尤其是 XDP BPF, 可能一个节点的内核版本支持,调度到另一台节点时,可能就不支持。
Cilium:实地探索 Pod-to-Service 转发路径及 BPF 处理逻辑
环境及配置信息
Cilium 的 eBPF 转发路径随跨主机网络方案和内核版本而有差异,本文假设:
- 跨主机网络方案:直接路由(BGP [4])
- Linux kernel 4.19:Cilium/eBPF 的较完整功能依赖这个版本及以上的内核
- Cilium 1.8.2,配置:
- kube-proxy-replacement=probe(默认)
- enable-ipv4=true(默认)
- datapath-mode=veth(默认)
- 没有对通信双方应用任何 network policy(默认)
- 两个物理网卡做 bond,宿主机 IP 配置在 bond 上
满足以上 2 & 3 条件下,所有对包的拦截和修改操作都由 BPF 代码完成,不依赖 Netfilter/iptables,即所谓的 kube-proxy free 模式。
其他说明
为方便起见,本文会在宿主机上用 nsenter-ctn 进入到容器执行命令,它 其实是对 nsenter 命令的一个简单封装:
1 | (NODE1) $ cat ~/.bashrc |
这和登录到容器里执行相应的命令效果是一样的,更多信息参考 man nseneter。
1: POD1 eth0 发送
下面几个网络设备在我们的场景中用不到,因此后面的拓扑图中不再画它们
- cilium_net/cilium_host 这对 veth pair 在 Kernel 4.19 + Cilium 1.8 部署中已经没什么作用了(事实上社区在考虑去掉它们)。
- cilium_vxlan 这个设备是 VxLAN 封装/接封装用的,在直接路由模式中不会出现。
拓扑简化为下图
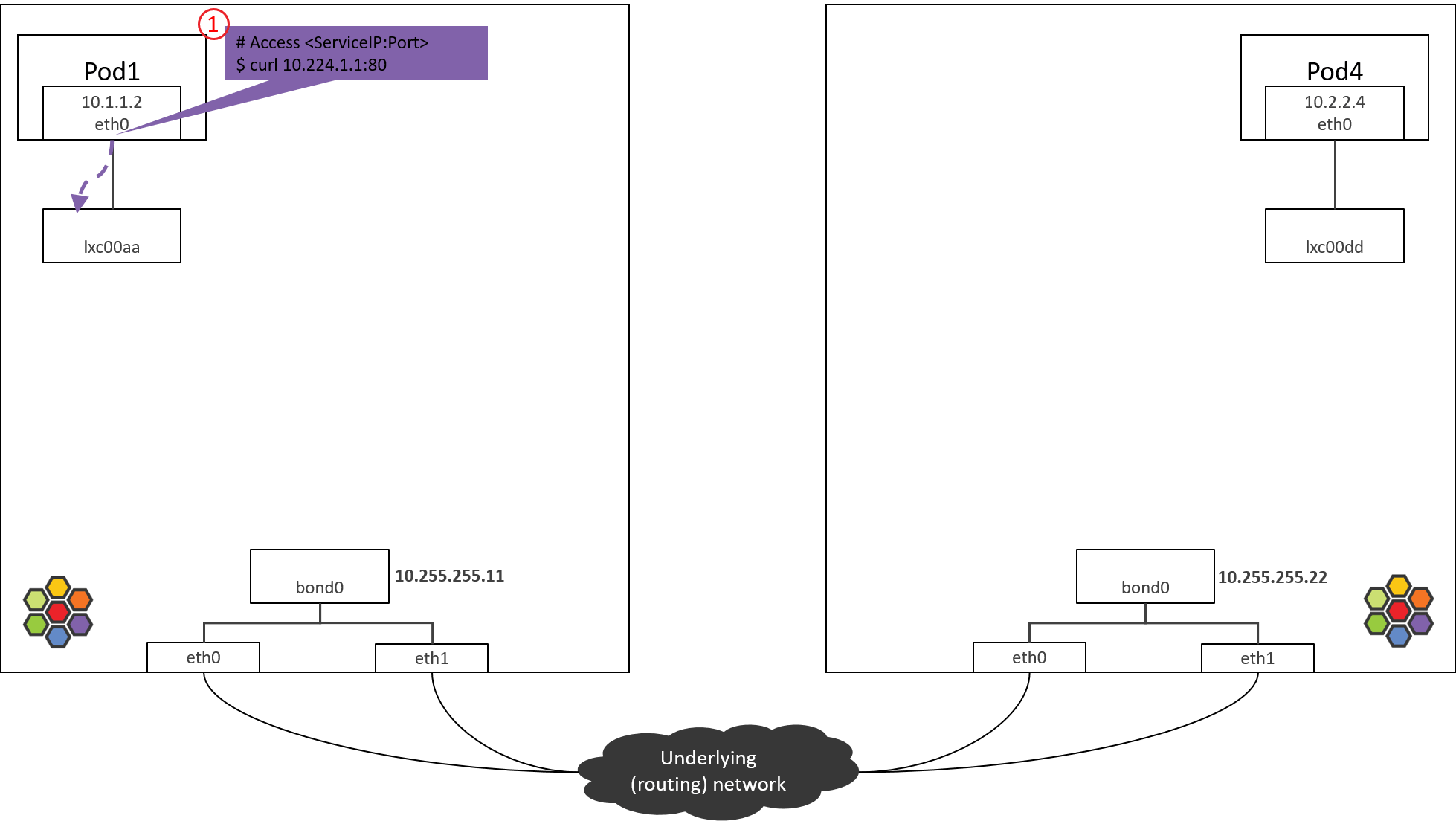
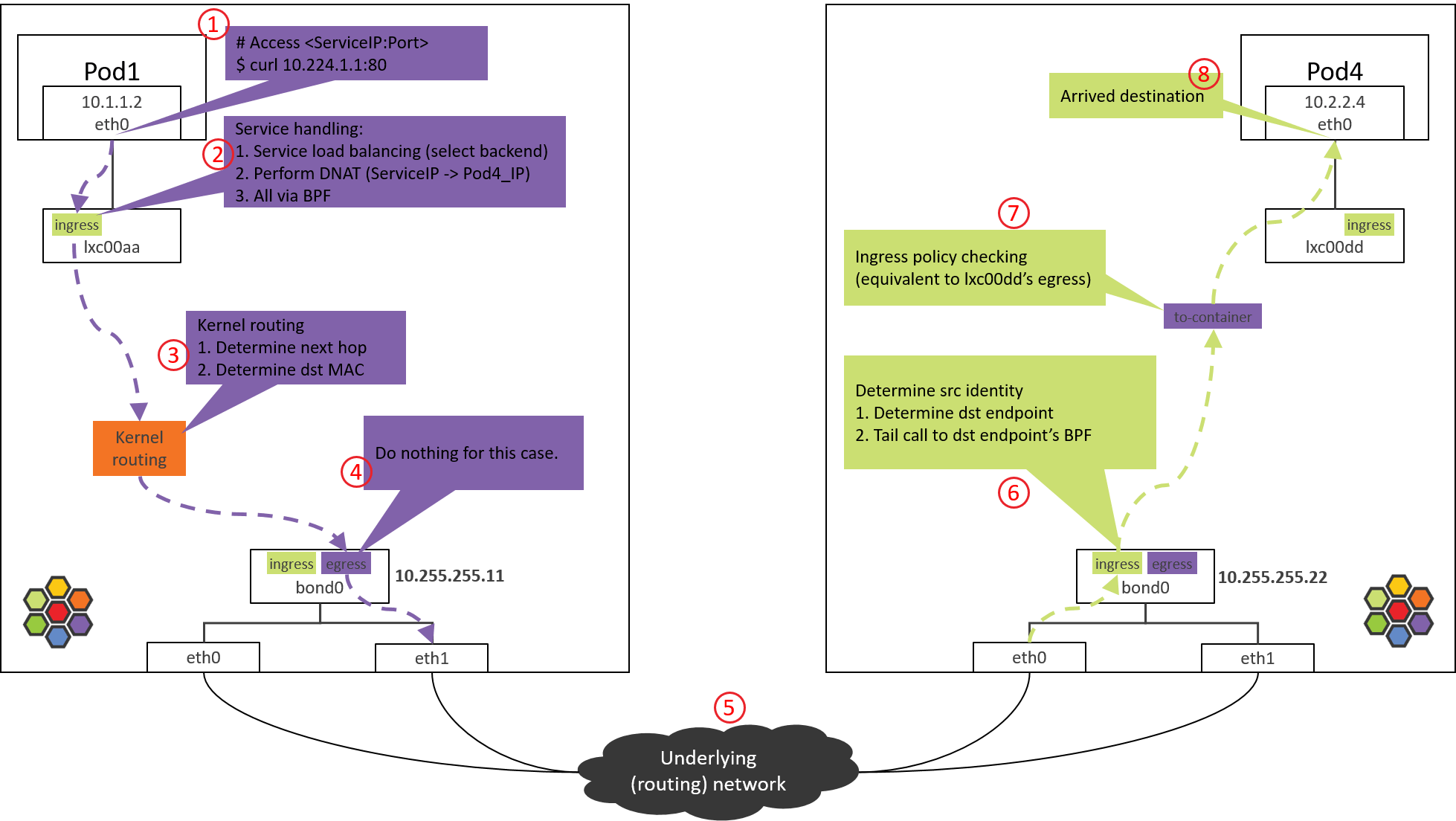
1.1 访问 ServiceIP
从 POD1 访问 ServiceIP 开始,例如
1 | # * -n: execute command in pod's network namespace |
包会从容器的 eth0 虚拟网卡发出去,此时能确定的 IP 和 MAC 地址信息有,
- src_ip=POD1_IP
- src_mac=POD1_MAC
- dst_ip=ServiceIP
这都很好理解,那dst_mac是多少呢?
1.2 确定目的 MAC 地址
确定dst_mac需要查看容器内的路由表和ARP表。
先看路由表
2
3
4
5
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.1.1.1 0.0.0.0 UG 0 0 0 eth0
10.1.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
这台 node 管理的 PodCIDR 是10.1.1.0/24。而10.1.1.1是这个 PodCIDR 的网关, 配置在cilium_host上(ifconfig cilium_host 能看到)。这些都是Cilium agent启动时自己配置的。
由以上路由规则可知:
- 到网关 10.1.1.1 的包,命中第二条路由
- 所有其他包,命中第一条路由(默认路由)
由于 ServiceIP 是10.224.1.1,因此走默认路由,下一跳就是网关10.1.1.1。 所以dst_mac 就要填10.1.1.1对应的 MAC。
MAC 和 IP 的对应关系在 ARP 表里。
查看容器 ARP 表:
1 | (NODE1) $ nsenter-ctn POD1 -n arp -n |
对应的 MAC 地址是3e:74:f2:60:ab:9b。至此,确定了dst_mac,包就可以可以正常发送出去了。
1.3 进一步探究
但是,如果去 NODE1 上查看,会发现这个MAC其实并不是网关cilium_host/cilium_net,宿主机上执行
1 | (NODE1) $ ifconfig cilium_host |
以及
1 | (NODE1) $ ip link | grep 3e:74:f2:60:ab:9b -B 1 |
可以看到,这个MAC属于lxc00aa设备,并且从@符号判断,它属于某个veth pair的一端,另一端的interface index是698。
容器内执行ip link:
1 | (NODE1) $ nsenter-ctn POD1 -n ip link |
可以看到容器的eth0 index就是 698,对端是 699。
至此明白了Cilium 通过 hardcode ARP 表,强制将 Pod 流量的下一跳劫持到veth pair的主机端。这里不过多讨论设计
只说一点:这并不是Cilium独有的设计,其他方案也有这么做的。
2. POD1 eth0 对端设备(lxcxx)BPF 处理
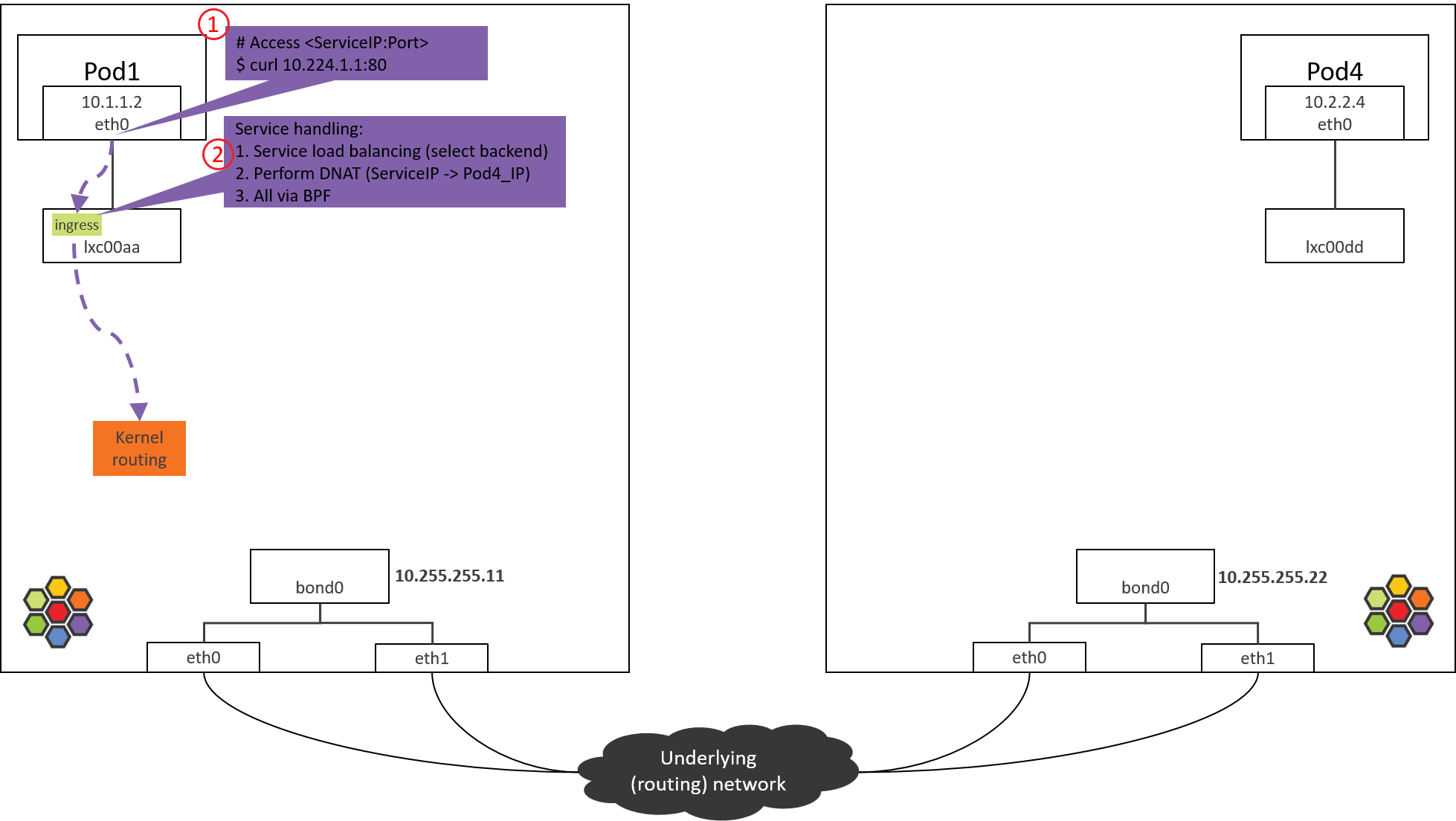
2.1 查看加载的 BPF 程序
包从容器 eth0 发出,然后被 lxc 收进来,因此在 lxc 的 tc ingress hook(注意是 ingress hook 而不是 egress hook)能对容器发出的包进行拦截和处理:
- POD1’s egress corresponds to lxc’s ingress.
- POD1’s ingress corresponds to lxc’s egress.
1 | (NODE1) $ tc filter show dev lxc00aa ingress |
可以看到在tc ingress hook点的确加载了BPF,section是from-container。
这里的section标签from-container是这段程序的唯一标识,在 Cilium 源代码 里搜索这个标签就能找到相应的 BPF 源码。
在 veth pair 模式中,你可以用上面的 tc 命令分别在 eth0 的 ingress/egress 以 及 lxc00aa 的 egress 点查看,最后会发现这些地方都没有加载 BPF。
那就有一个疑问,没有相应的 BPF,怎么对容器的入向包做拦截和处理呢?后面会揭晓。
接下来看这段 BPF 具体做了哪些事情。
2.2 from-container BPF 程序分析
BPF 代码都在 Cilium 源代码的 bpf/ 目录中。为避免本文过长,将只贴出核心调用栈。
大致调用栈如下:
1 | __section("from-container") |
所做的事情
- 对包进行验证,并提取出 L3 proto(协议类型)。
- 如果 L3 proto 是 IPv4,调用 tail_handle_ipv4() 进行处理。
- tail_handle_ipv4() 进一步调用 handle_ipv4_from_lxc(),后者完成:
- Service 负载均衡,即从 Service 的后端 Pod 中选择一个合适的,这里假设选择 NODE2 上的 POD4。
- 创建或更新连接跟踪(CT)记录。
- 执行 DNAT,将包的 dst_ip 由 ServiceIP 改成 POD4_IP。
- 进行容器出向(egress)安全策略验证,这里假设没有安全策略,因此能通过验证。
- 对包进行封装,或者通过主机进行路由,本文只看直接路由的情况。
在送回协议栈之前,调用ipv4_l3()设置 TTL、MAC 地址等:
1 | int ipv4_l3(struct __ctx_buff *ctx, int l3_off, __u8 *smac, __u8 *dmac, struct iphdr *ip4) |
以上假设都成立的情况下,BPF 程序最后返回TC_ACK_OK,这个包就进入内核协议栈继续处理了。
3. NODE1:内核路由判断
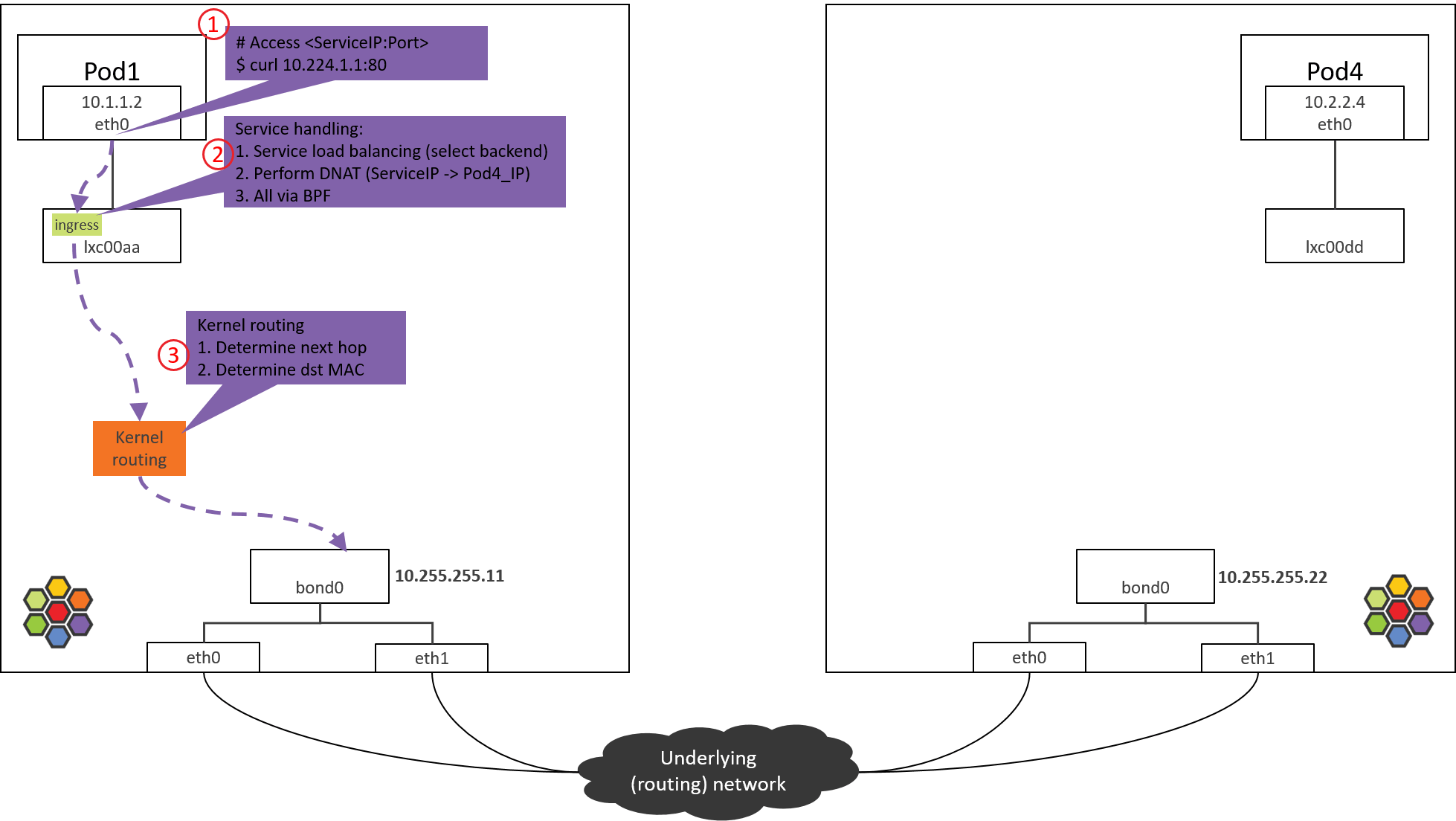
经过 Step 2 的 from-container BPF 程序处理之后,包的 dst_ip 已经是真实 Pod IP(POD4_IP)了。
接下来就进入内核协议栈进行路由(kernel routing)。此时内核就相当于一台路由 器(router),查询内核路由表,根据包的 dst_ip 进行路由判断,确定下一跳。
来看内核路由表:
1 | (NODE1) $ route -n |
根据以上路由规则,只要目的 IP 不是本机 PodCIDR 网段的,都会命中默认路由(第一条) ,走bond0设备。
内核路由子系统(三层路由)、邻居子系统(二层转发),推荐阅读大部头 《深入理解 Linux 网络技术内幕》(中国电力出版社)。
书中所用的内核版本可能 有些老,但基本的路由、转发功能还是一样的。
因此包接下来会到达bond0设备。
本文的 node 都是两个物理网卡做了 bond,如果没有 bond,例如只有一个 eth0 物理网 卡,宿主机 IP 配置在 eth0,那接下来包到达的就是 eth0 物理网卡。
这种主机上配置 了 IP 地址的设备,在 Cilium 里叫 native device。文档或代码中经常会看到。
4. NODE1 bond/物理网卡: egress BPF 处理
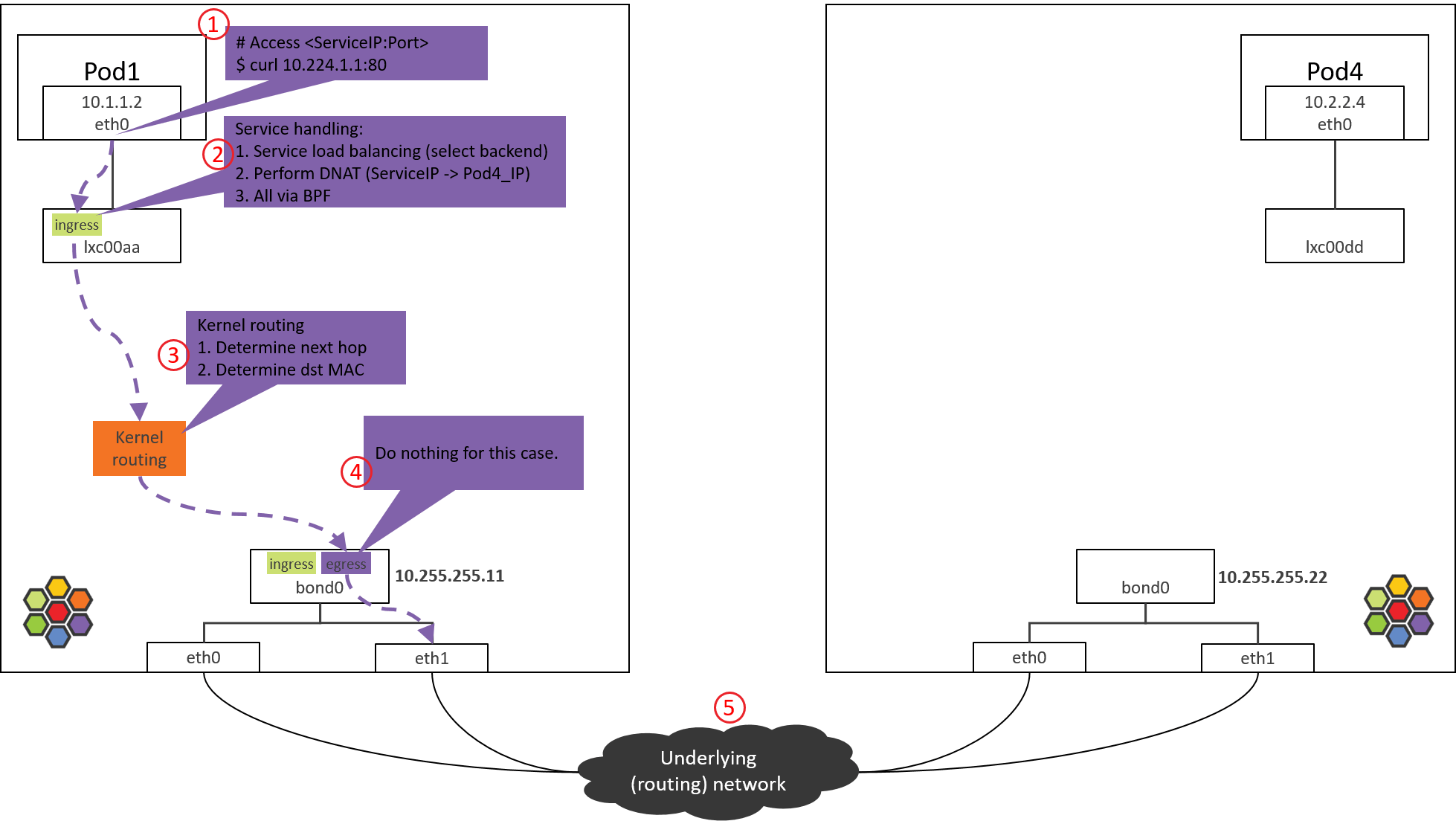
4.1 查看加载的 BPF 程序
查看 bond 设备上的出向(egress)BPF,这是包出宿主机之前最后的 tc BPF hook 点:
1 | (NODE1) $ tc filter show dev bond0 egress |
接下来看代码实现。
4.2 to-netdev BPF 程序分析
调用栈如下
1 | __section("to-netdev") |
粗略地说,对于我们这个 case,这段 BPF 其实并不会做什么实际的事情,程序最后返回TC_ACK_OK放行。
Native device 上的 BPF 主要处理南北向流量,即,容器和集群外交互的流量 [3]。这包括,
- LoadBalancer Service 流量
- 带 externalIPs 的 Service 流量
- NodePort Service 流量
接下来根据内核路由表和 ARP 表封装 L2 头。
4.3 确定源和目的 MAC 地址
与 1.2 节原理一样,就不具体分析了,直接看结果:
1 | route -n |
命中宿主机默认路由,因此会
- 将 bond0 的 MAC 作为 src_mac:MAC 地址只在二层网络内有效,宿主机和 Pod 属于不同二层网络(Cilium 自己管理了一个 CIDR),宿主机做转发时会将 src_mac 换成自己的 MAC。
- 将宿主机网关对应的 MAC 作为 dst_mac:下一跳是宿主机网关。
然后包就经过 bond0 和物理网卡发送到数据中心网络了。
可以在 bond0 及物理网卡上抓包验证,指定 -e 打印 MAC 地址。
5. 数据中心网络:路由转发
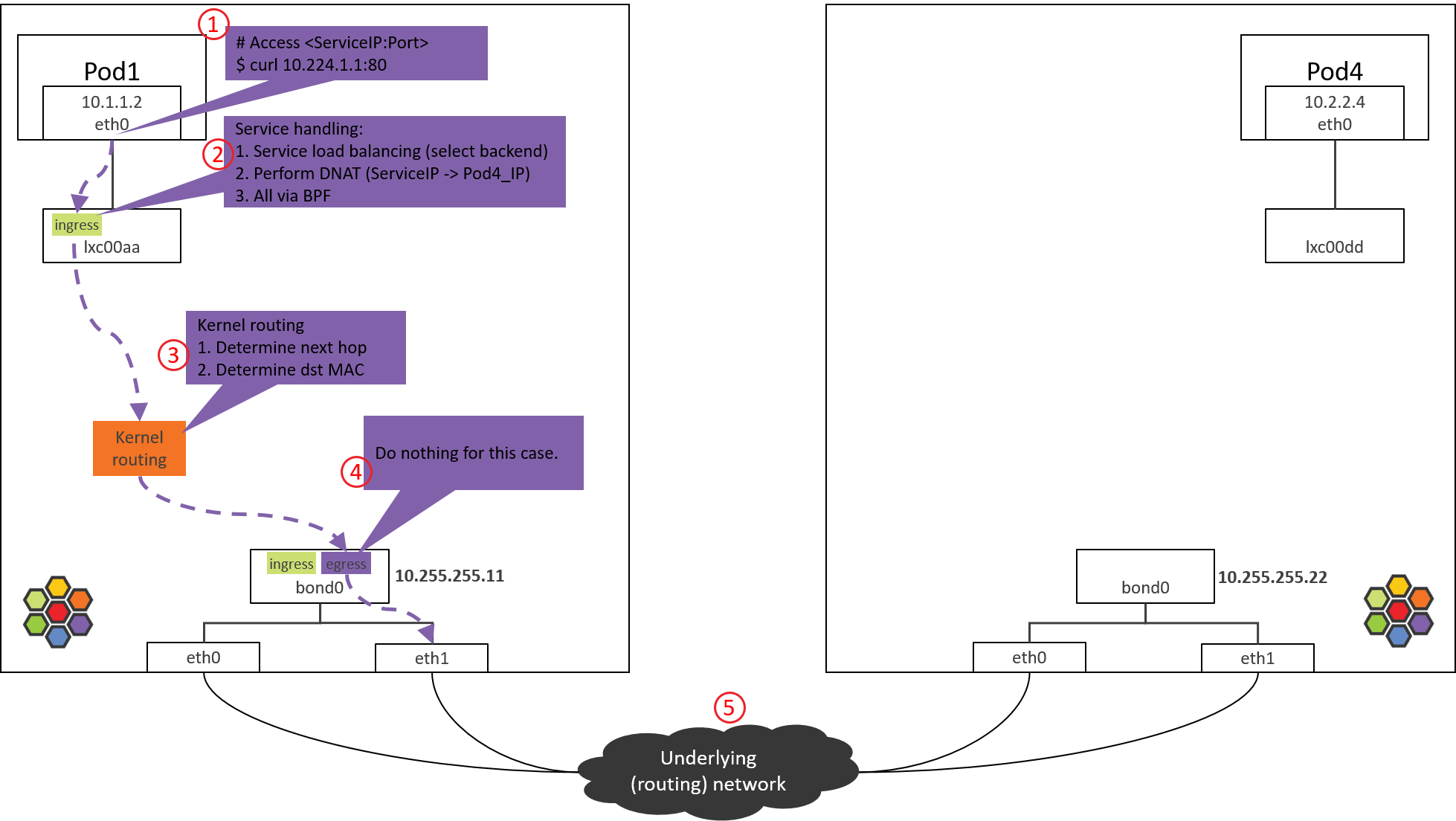
数据中心网络根据dst_ip对包进行路由。
由于 NODE2 之前已经通过 BGP 宣告自己管理了 PodCIDR2 网段,而 POD4_IP 属于 PodCIDR2,因此交换机(路由器)会将包转发给 NODE2。
网络虚拟化:跨主机网络方案。
从网络层次来说,有两种典型的跨主机网络方式:
- 二层、大二层组网:每个 node 内部运行一个软件交换机或软件网桥,代表:OpenStack Neutron+OVS 方式 [1]。
- 三层组网:每个 node 内部运行一个软件路由器(其实就是内核本身,它自带路由功能),每个 node 都是一个三层节点,代表:Cilium+BGP 方式 [4]。
排障时的一个区别:
- 在二层/大二层网络中,对于同一个包,发送方和接收方看到的 src_mac 是一样的,因为二 层转发只修改 dst_mac,不会修改 src_mac。
- 三层组网中,src_mac 和 dst_mac 都会变。
抓包时要理解这一点。
6. NODE2 物理网卡/bond:ingress BPF 处理
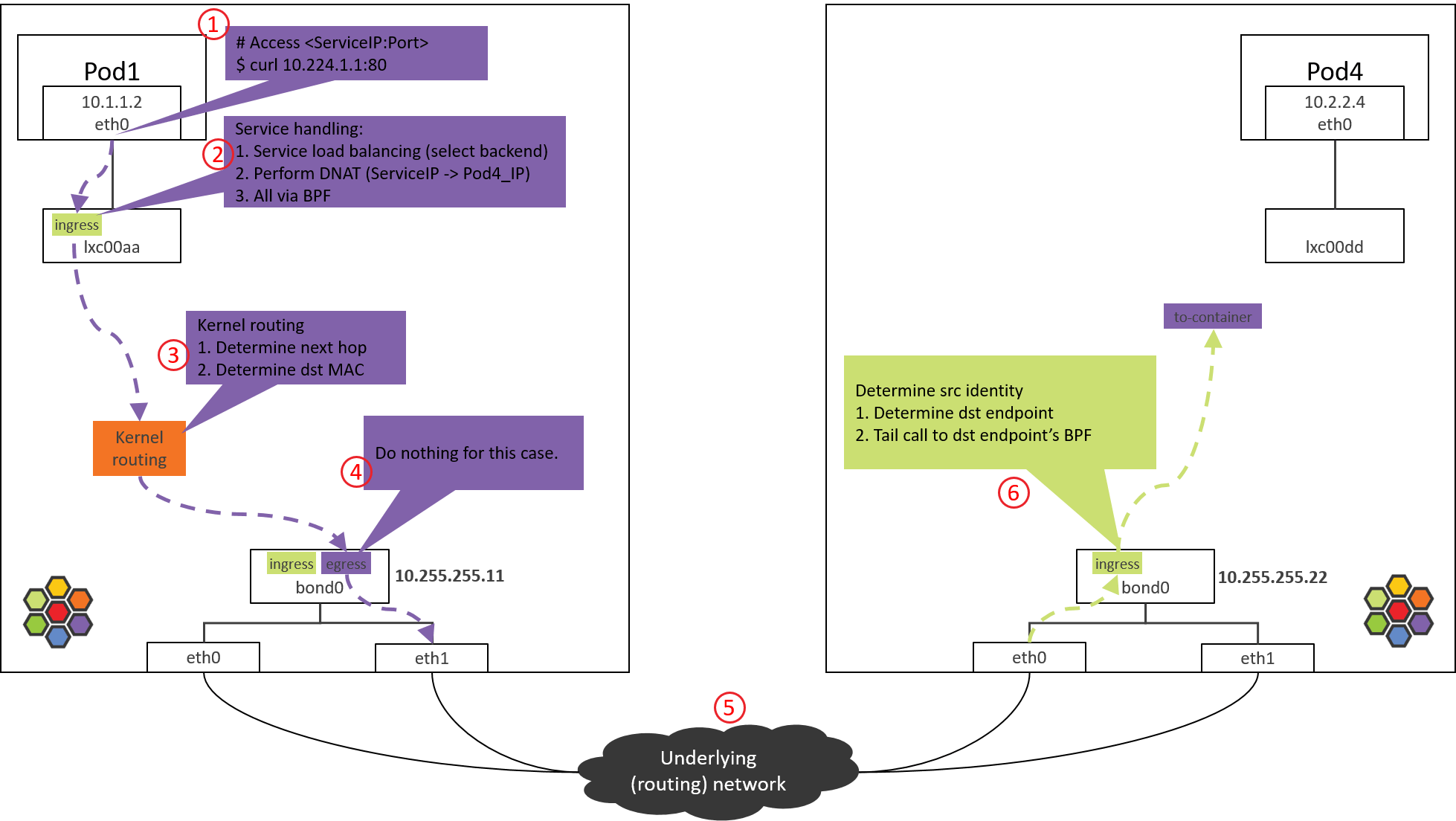
以 Intel 10G 网卡为例,从驱动开始,接收方向调用栈,
1 | // kernel source tree, 4.19 |
大致过程
- 网卡收包
- 如果网卡支持 XDP offload,并且有 XDP 程序,就会执行 XDP 程序。我们这里没有启 用 XDP。
- 创建 skb。
- GRO,对分片的包进行重组。
- Generic XDP 处理:如果网卡不支持 XDP offload,那 XDP 程序会从 step 2 延后到这里执行。
- Tap 处理(此处没有)。
- TC ingress 处理,支持包括 BPF 在内的 TC 程序。
其中的sch_handle_ingress()会进入 TC ingress hook 执行处理。
6.1 查看加载的 BPF 程序
查看 ingress 方向加载的 BPF
1 | tc filter show dev bond0 ingress |
6.2 from-netdev BPF 程序分析
调用栈
1 | __section("from-netdev") |
主要逻辑:
- 调用 handle_netdev() 处理将从宿主机进入 Cilium 管理的网络的流量,具体事情:
- 解析这个包所属的 identity(Cilium 依赖 identity 做安全策略),并存储到包的结构体中。
- 对于 direct routing 模式,从 ipcache 中根据 IP 查询 identity。
- 对于 tunnel 模式,直接从 VxLAN 头中携带过来了。
- 尾调用到 tail_handle_ipv4_from_netdev()。
- 解析这个包所属的 identity(Cilium 依赖 identity 做安全策略),并存储到包的结构体中。
tail_handle_ipv4_from_netdev()进一步调用tail_handle_ipv4(),后者再调用handle_ipv4()。handle_ipv4()做的事情:- 查找 dst_ip 对应的 endpoint(即 POD4)。
- 调用
ipv4_local_delivery()执行处理,这个函数会根据 endpoint id 直接尾调用到 endpoint (POD4) 的 BPF 程序。
7. Pod2 eth0 对端设备(lxcxx)的 BPF 处理
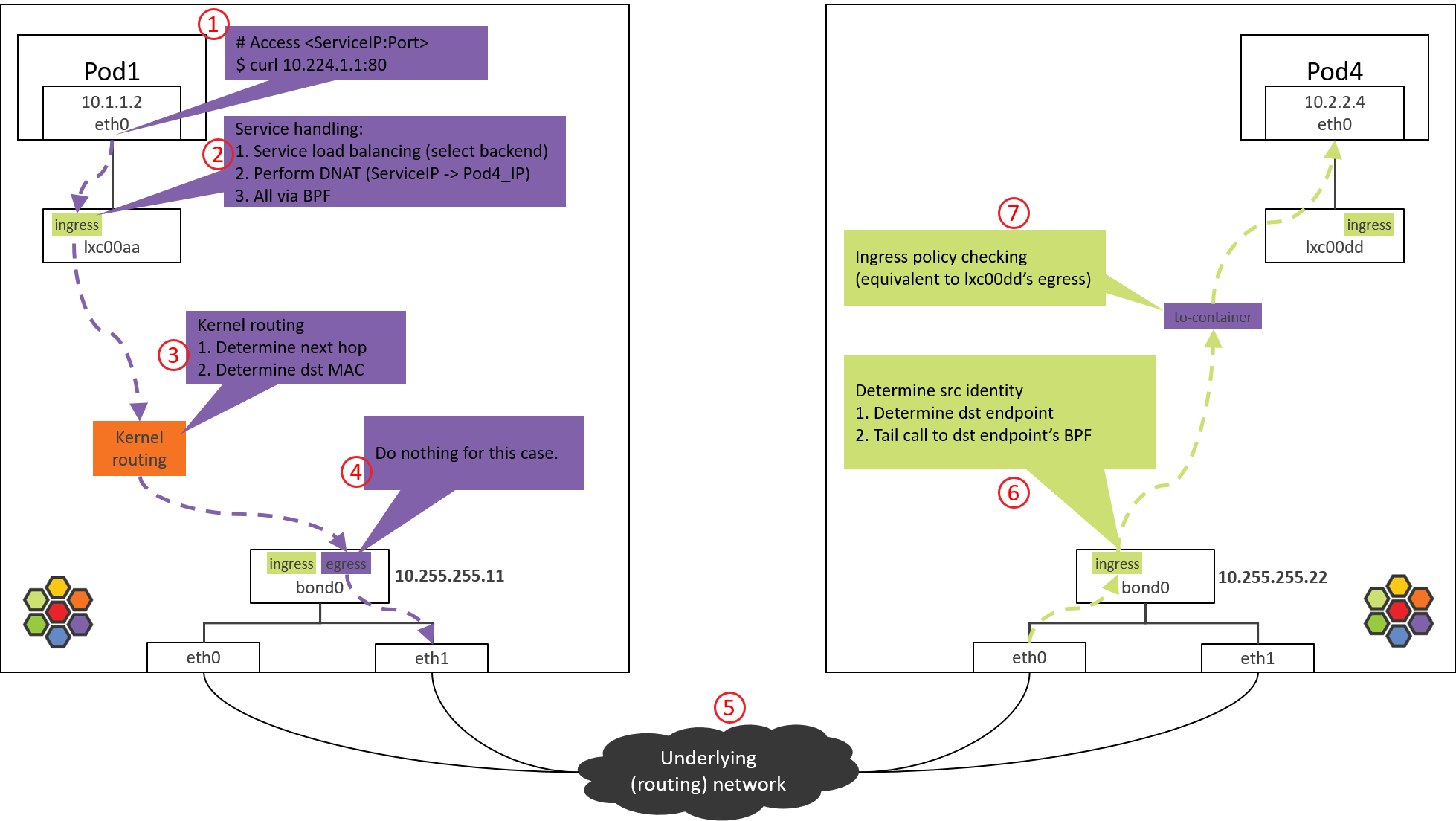
7.1 查看加载的 BPF 程序
跟前面一样,来查看 lxc 设备加载的 BPF 程序
1 | (NODE2) $ tc filter show dev lxc00dd egress |
没有加载任何 BPF 程序,为什么?
因为设计中,这段代码并不是在包经过 egress 点触发执行的(常规 BPF 程序执行方式) ,而是直接从 bond0 的 BPF 程序尾调用过来继续的,即上一节最后的一行代码:
1 | tail_call_dynamic(ctx, &POLICY_CALL_MAP, ep->lxc_id); |
因此不需要通过 tc 加载到 lxc 设备,这也回答了 2.1 节中提出的问题。这使得从 bond0 (或物理网卡)到容器的路径大大缩短,可以显著提升性能。
7.2 to-container BPF 程序分析
这次尾调用到达的是to-containerBPF 程序。调用栈:
1 | __section("to-container") |
所做的事情也很清楚:
- 提取包的 src identity 信息,这个信息此时已经在包的元数据里面了。
- 调用 tail_ipv4_to_endpoint(),这个函数会进一步调用 ipv4_policy() 执行 容器入向(ingress)安全策略检查。
如果包没有被策略拒绝,就会被转发到 lxc00dd 的对端,即 POD4 的虚拟网卡 eth0。
8. 到达 POD4 容器
包到达容器的虚拟网卡,接下来就会被更上层读取了。
总结
本文探索了端到端的 Cilium/eBPF 的包转发路径,并结合 eBPF 代码进行了分析。
受篇幅限制,本文只分析了去向的路径;反向路径(POD4 回包)是类似的,只是 BPF 中处理 reply 包的逻辑会有所不同,感兴趣的可以继续深挖。
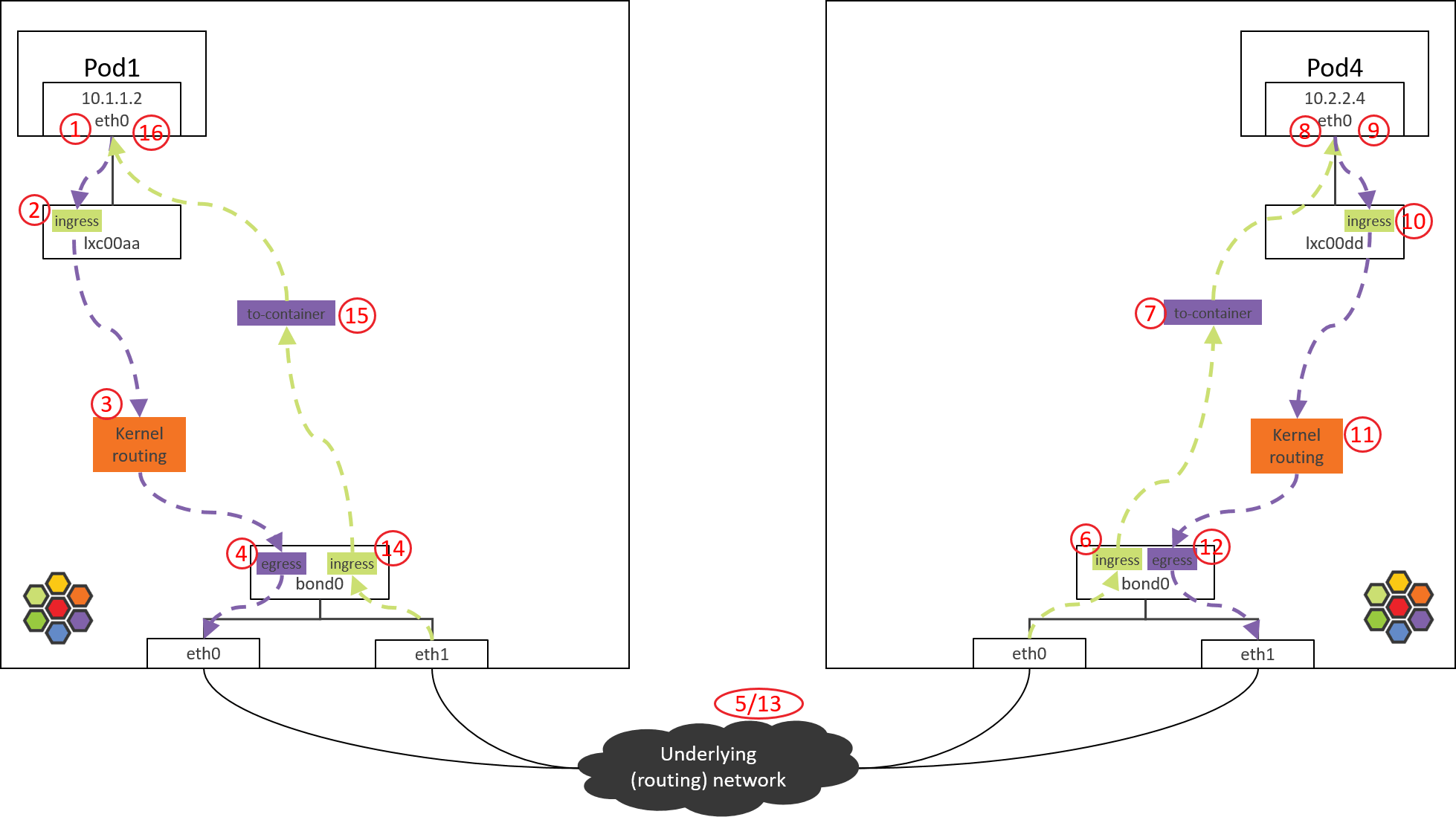
最后非常重要的一点:不要通过对比本文中 Cilium/eBPF 和 OpenStack/OVS 拓扑中的跳数,而对两种方案作出任何性能判断。
本文中,Cilium/eBPF 中的“跳”是一个完全不同的概念,更多地是为了方便理解整个转发过程而标注的序号
例如,从 Step 6 到 Step 7 其实只是一次函数调用,从转发性能考虑,几乎没什么开销。
OpenvSwitch 建设vxlan网络
对于CentOS 7
首先,安装EPEL仓库:
sudo yum install epel-release
接下来,安装CentOS SIG OpenStack仓库:
sudo yum install -y centos-release-openstack-train
清除缓存并更新软件包:
sudo yum clean all
sudo yum update -y
现在,您可以尝试安装openvswitch了:
sudo yum install openvswitch
对于CentOS 8
首先,安装EPEL仓库:
sudo dnf install epel-release
接下来,安装CentOS SIG OpenStack仓库:
sudo dnf install -y centos-release-openstack-train
清除缓存并更新软件包:
sudo dnf clean all
sudo dnf update -y
现在,您可以尝试安装openvswitch了:
sudo dnf install openvswitch
创建ovs bridge
sudo ovs-vsctl add-br ovsbr0
sudo ovs-vsctl add-br ovsbr1
双方机器进行配置
sudo ovs-vsctl add-port ovsbr0 vxlan0 – set interface vxlan0 type=vxlan options:remote_ip=<开发机的IP> options:key=<VXLAN的VNI>
sudo ovs-vsctl add-port ovsbr1 vxlan1 – set interface vxlan1 type=vxlan options:remote_ip=<K8s服务器节点的IP> options:key=<VXLAN的VNI>
sudo ovs-vsctl add-port ovsbr0 vxlan0 – set interface vxlan0 type=vxlan options:remote_ip=192.168.2.167 options:key=1000
sudo ovs-vsctl add-port ovsbr1 vxlan1 – set interface vxlan1 type=vxlan options:remote_ip=192.168.2.174 options:key=1000
双方机器的ip段分配配置
sudo ip addr add 10.66.66.66/32 dev ovsbr0
sudo ip link set ovsbr0 up
ip route add 10.244.0.0/16 dev ovsbr0
sudo ip addr add 10.77.77.77/32 dev ovsbr1
sudo ip link set ovsbr1 up
ip route add 100.64.0.0/16 dev ovsbr1
Iast产品
国内查看评论需要代理~