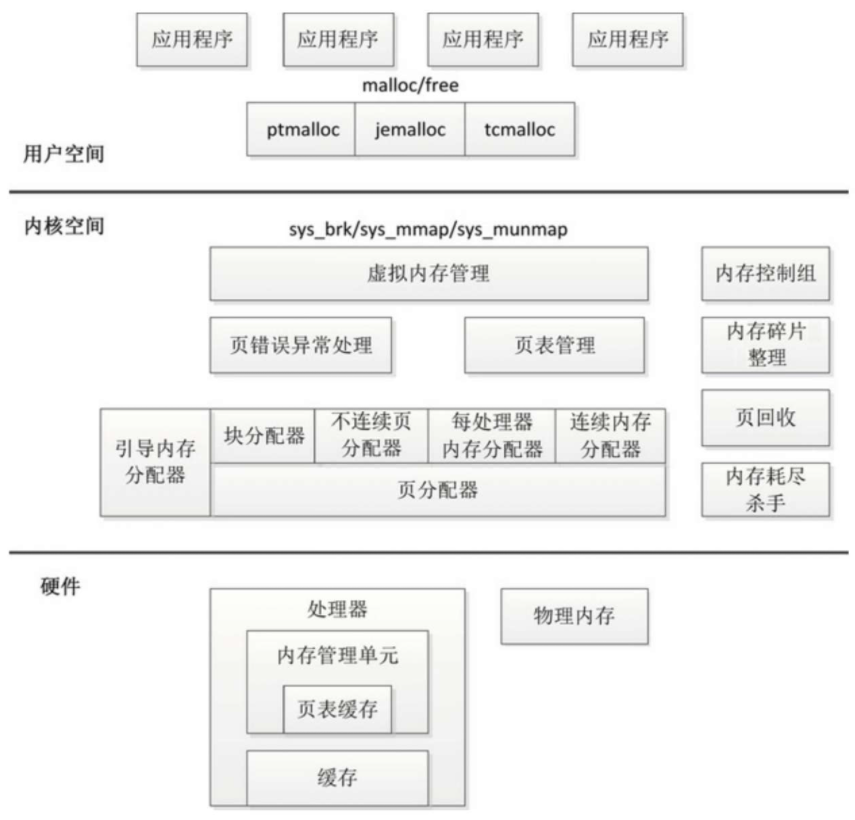
内存管理子系统的架构如图所示,分为用户空间、内核空间和硬件3个层面。
虚拟地址空间布局
虚拟地址划分
虚拟地址的最大宽度是48位
在编译ARM64架构的Linux内核时,可以选择虚拟地址宽度。
- (1)如果选择页长度4KB,默认的虚拟地址宽度是39位。
- (2)如果选择页长度16KB,默认的虚拟地址宽度是47位。
- (3)如果选择页长度64KB,默认的虚拟地址宽度是42位。
- (4)可以选择48位虚拟地址。
所有进程共享内核虚拟地址空间,每个进程有独立的用户虚拟地址空间,同一个线程组的用户线程共享用户虚拟地址空间,内核线程没有用户虚拟地址空间。
用户虚拟地址布局
进程的用户虚拟地址空间的起始地址是0,长度是TASK_SIZE,由每种处理器架构定义自己的宏TASK_SIZE。
ARM64架构定义的宏TASK_SIZE如下所示。
- (1)32位用户空间程序:TASK_SIZE的值是TASK_SIZE_32,即0x100000000,等于4GB。
- (2)64位用户空间程序:TASK_SIZE的值是TASK_SIZE_64,即2VA_BITS字节,VA_BITS是编译内核时选择的虚拟地址位数。
进程的用户虚拟地址空间包含以下区域。
-(1)代码段、数据段和未初始化数据段。
-(2)动态库的代码段、数据段和未初始化数据段。
-(3)存放动态生成的数据的堆。
-(4)存放局部变量和实现函数调用的栈。
-(5)存放在栈底部的环境变量和参数字符串。
-(6)把文件区间映射到虚拟地址空间的内存映射区域。
内核使用内存描述符mm_struct描述进程的用户虚拟地址空间,内存描述符的主要成员如下所示。
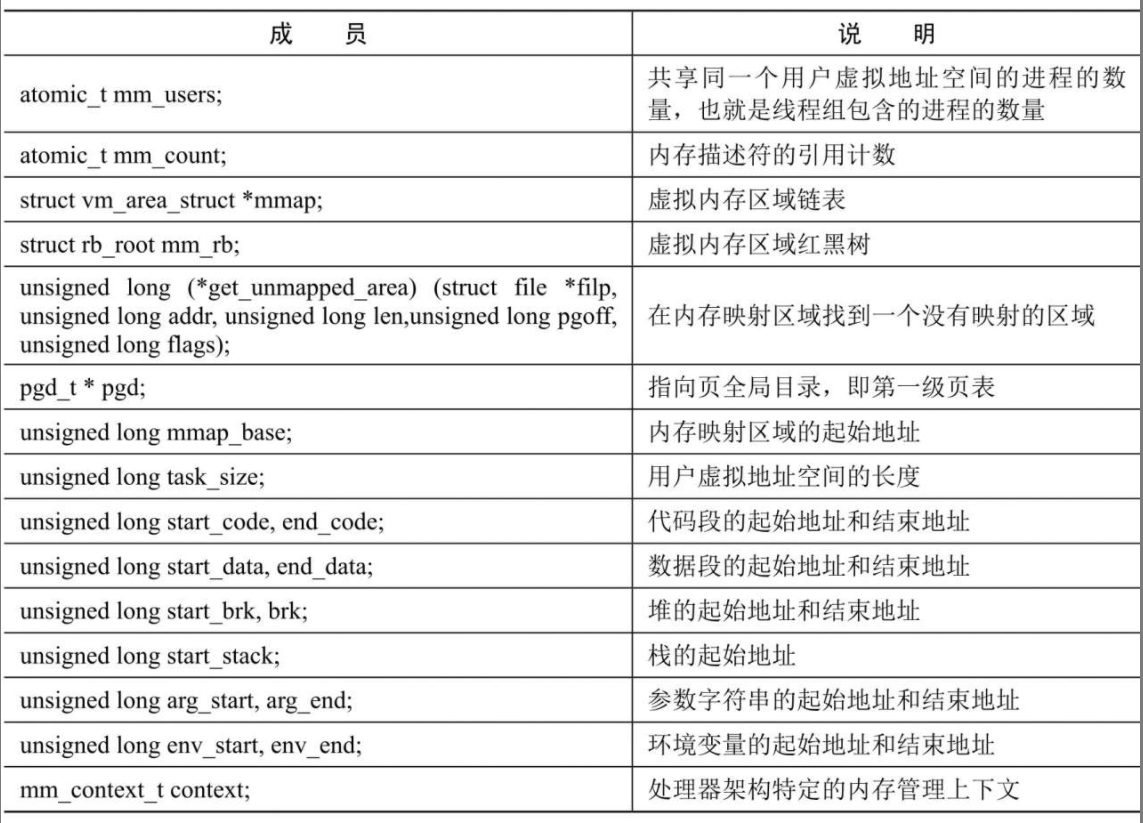
进程描述符(task_struct)中和内存描述符相关的成员如下表

如果进程不属于线程组,那么进程描述符和内存描述符的关系如下
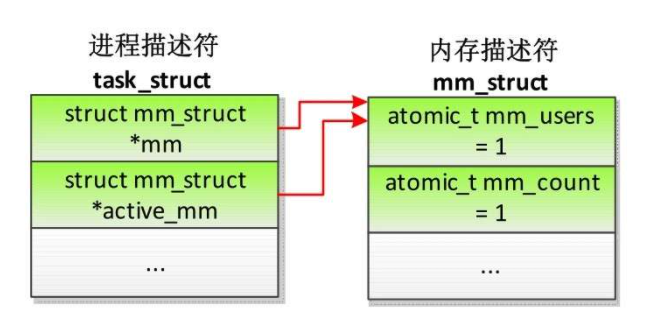
如果两个进程属于同一个线程组,那么进程描述符和内存描述符的关系如下
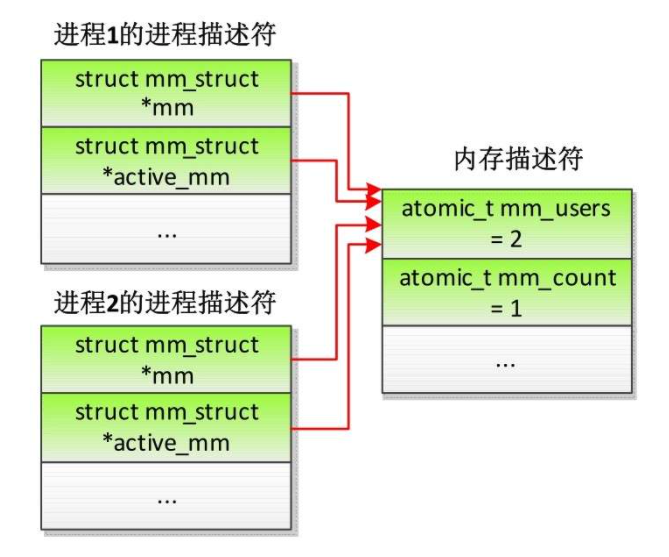
内核线程的进程描述符和内存描述符的关系如下
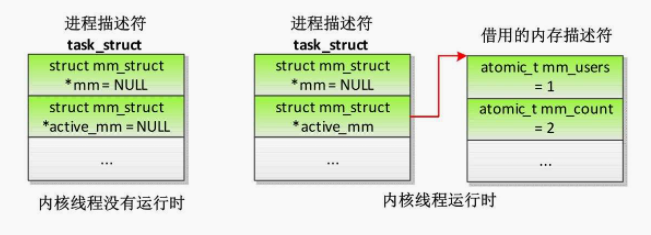
当内核线程没有运行的时候,进程描述符的成员mm和active_mm都是空指针;
当内核线程运行的时候,借用上一个进程的内存描述符,在被借用进程的用户虚拟地址空间的上方运行,进程描述符的成员active_mm指向借用的内存描述符
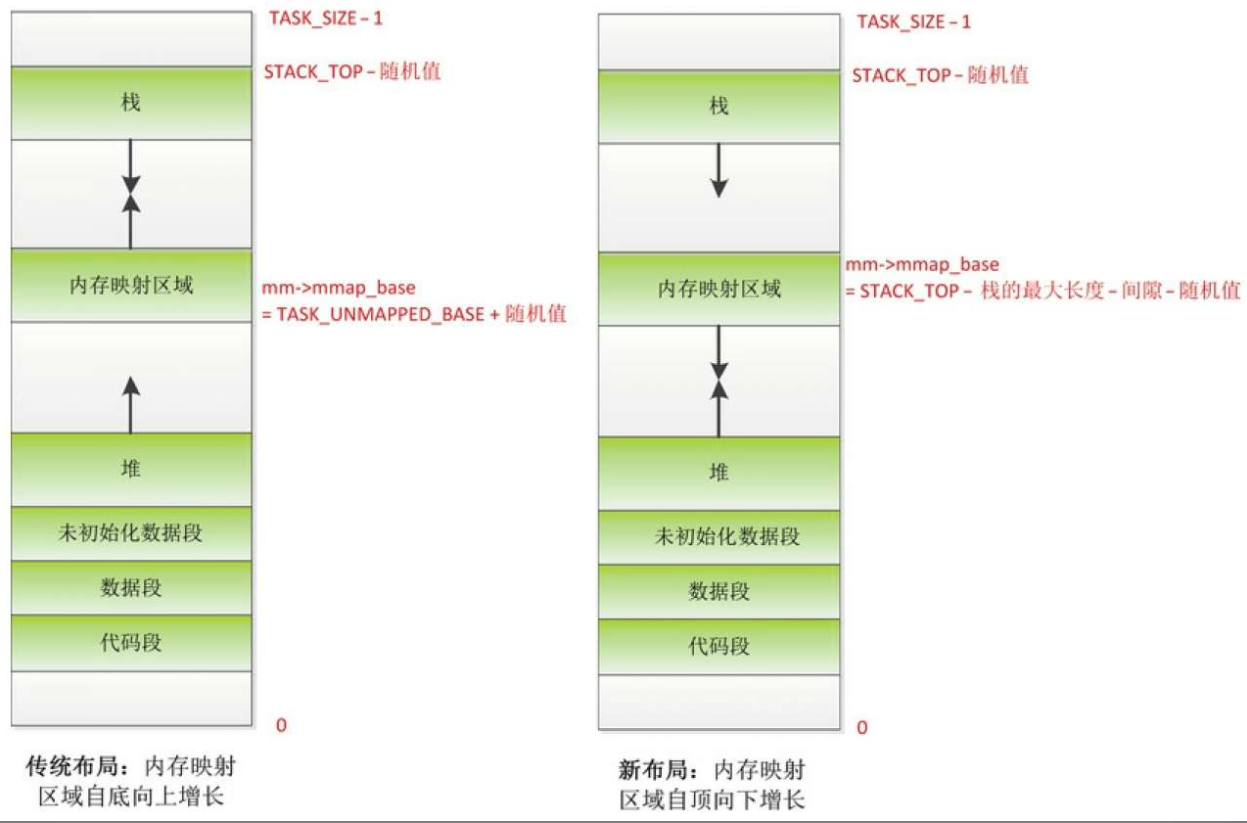
STACK_TOP是每种处理器架构自定义的宏,ARM64架构定义的STACK_TOP如下所示;
如果是64位用户空间程序,STACK_TOP的值是TASK_SIZE_64;
如果是32位用户空间程序,STACK_TOP的值是异常向量的基准地址0xFFFF0000。
内核地址布局
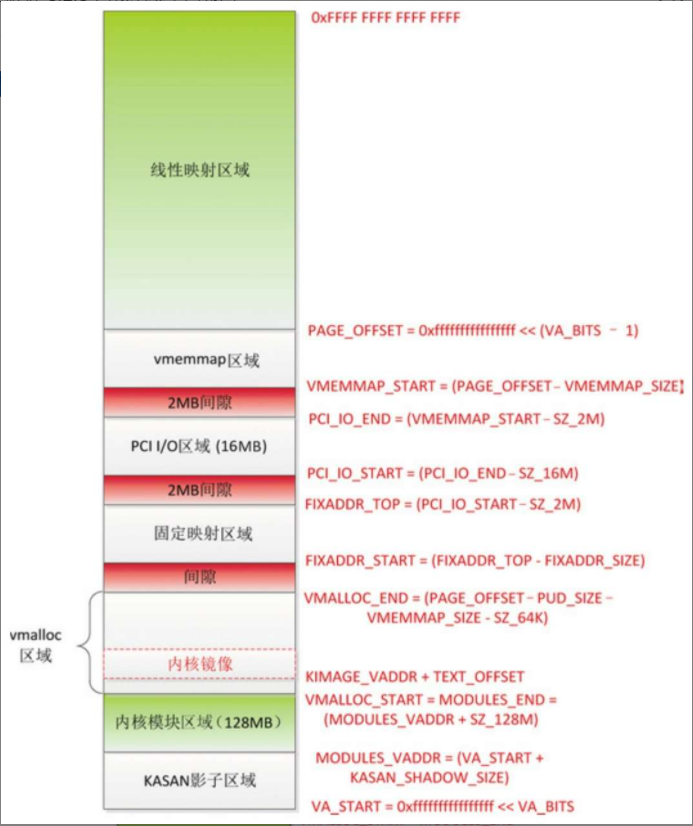
- (1)线性映射区域的范围是[PAGE_OFFSET, 264−1],起始位置是PAGE_OFFSET =(0xFFFF FFFFFFFF FFFF << (VA_BITS-1)),长度是内核虚拟地址空间的一半。称为线性映射区域的原因是虚拟地址和物理地址是线性关系:虚拟地址 =((物理地址 − PHYS_OFFSET)+ PAGE_OFFSET),其中PHYS_OFFSET是内存的起始物理地址。
- (2)vmemmap区域的范围是[VMEMMAP_START, PAGE_OFFSET),长度是VMEMMAP_SIZE =(线性映射区域的长度 / 页长度 * page结构体的长度上限)。内核使用page结构体描述一个物理页,内存的所有物理页对应一个page结构体数组。如果内存的物理地址空间不连续,存在很多空洞,称为稀疏内存。vmemmap区域是稀疏内存的page结构体数组的虚拟地址空间。
- (3)PCI I/O区域的范围是[PCI_IO_START, PCI_IO_END),长度是16MB,结束地址是PCI_IO_END= (VMEMMAP_START − 2MB)。
- (4)固定映射区域的范围是[FIXADDR_START, FIXADDR_TOP),长度是FIXADDR_SIZE,结束地址是FIXADDR_TOP = (PCI_IO_START − 2MB)。固定地址是编译时的特殊虚拟地址,编译的时候是一个常量,在内核初始化的时候映射到物理地址。
- (5)vmalloc区域的范围是[VMALLOC_START, VMALLOC_END),起始地址是VMALLOC_START,等于内核模块区域的结束地址,结束地址是VMALLOC_END =(PAGE_OFFSET −PUD_SIZE − VMEMMAP_SIZE − 64KB),其中PUD_SIZE是页上级目录表项映射的地址空间的长度。
- (6)内核模块区域的范围是[MODULES_VADDR, MODULES_END),长度是128MB,起始地址是MODULES_VADDR =(内核虚拟地址空间的起始地址 + KASAN影子区域的长度)。内核模块区域是内核模块使用的虚拟地址空间。
- (7)KASAN影子区域的起始地址是内核虚拟地址空间的起始地址,长度是内核虚拟地址空间长度的1/8。
物理地址空间布局
物理地址是处理器在系统总线上看到的地址
处理器通过外围设备控制器的寄存器访问外围设备,寄存器分为控制寄存器、状态寄存器和数据寄存器三大类,外围设备的寄存器通常被连续地编址。
处理器对外围设备寄存器的编址方式有两种。
- (1)I/O映射方式(I/O-mapped):英特尔的x86处理器为外围设备专门实现了一个单独的地址空间,称为“I/O地址空间”或“I/O端口空间”,处理器通过专门的I/O指令(如x86的in和out指令)来访问这一空间中的地址单元。
- (2)内存映射方式(memory-mapped):使用精简指令集的处理器通常只实现一个物理地址空间,外围设备和物理内存使用统一的物理地址空间,处理器可以像访问一个内存单元那样访问外围设备,不需要提供专门的I/O指令。
内存映射
内存映射是在进程的虚拟地址空间中创建一个映射,分为以下两种。
- (1)文件映射:文件支持的内存映射,把文件的一个区间映射到进程的虚拟地址空间,数据源是存储设备上的文件。
- (2)匿名映射:没有文件支持的内存映射,把物理内存映射到进程的虚拟地址空间,没有数据源。通常把文件映射的物理页称为文件页,把匿名映射的物理页称为匿名页。
根据修改是否对其他进程可见和是否传递到底层文件,内存映射分为共享映射和私有映射。
- (1)共享映射:修改数据时映射相同区域的其他进程可以看见,如果是文件支持的映射,修改会传递到底层文件。
- (2)私有映射:第一次修改数据时会从数据源复制一个副本,然后修改副本,其他进程看不见,不影响数据源。
内存映射的原理
- (1)创建内存映射的时候,在进程的用户虚拟地址空间中分配一个虚拟内存区域。
- (2)Linux内核采用延迟分配物理内存的策略,在进程第一次访问虚拟页的时候,产生缺页异常。如果是文件映射,那么分配物理页,把文件指定区间的数据读到物理页中,然后在页表中把虚拟页映射到物理页;如果是匿名映射,那么分配物理页,然后在页表中把虚拟页映射到物理页。
编程接口
- (1)mmap()用来创建内存映射。
- 进程创建匿名的内存映射,把内存的物理页映射到进程的虚拟地址空间。
- 进程把文件映射到进程的虚拟地址空间,可以像访问内存一样访问文件,不需要调用系统调用read()和write()访问文件,从而避免用户模式和内核模式之间的切换,提高读写文件的速度。
- 两个进程针对同一个文件创建共享的内存映射,实现共享内存。
- (2)mremap()用来扩大或缩小已经存在的内存映射,可能同时移动。
- (3)munmap()用来删除内存映射。
- (4)brk()用来设置堆的上界。
- (5)remap_file_pages()用来创建非线性的文件映射,即文件区间和虚拟地址空间之间的映射不是线性关系,现在被废弃了。
- (6)mprotect()用来设置虚拟内存区域的访问权限。
- (7)madvise()用来向内核提出内存使用的建议,应用程序告诉内核期望怎样使用指定的虚拟内存区域,以便内核可以选择合适的预读和缓存技术。
数据结构
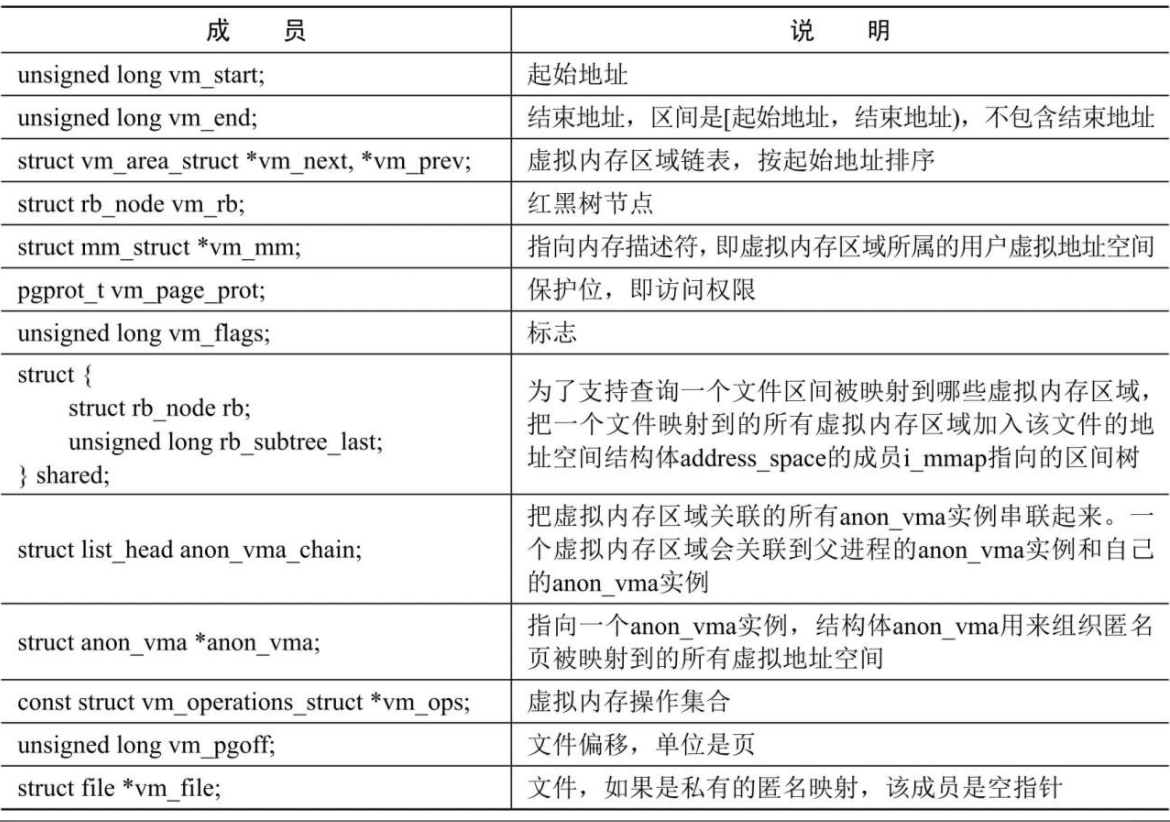
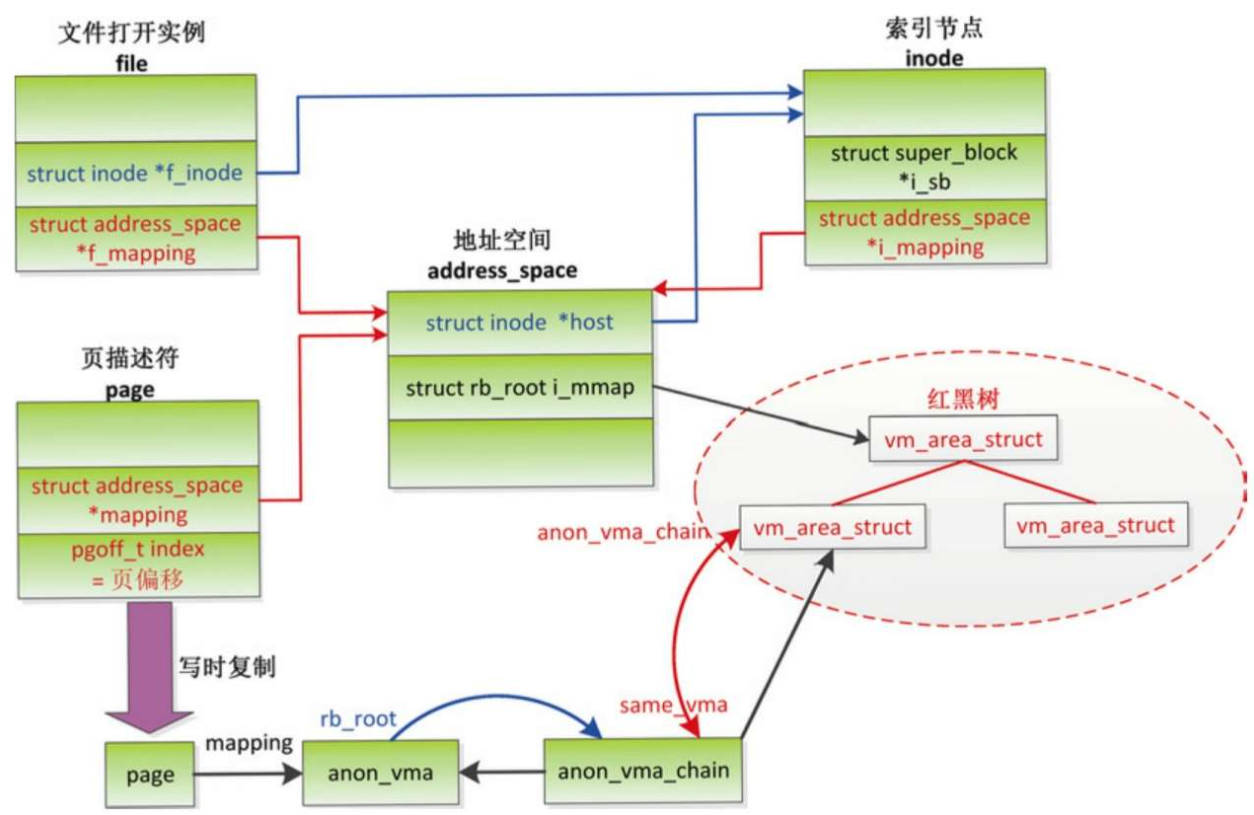
虚拟内存区域是分配给进程的一个虚拟地址范围,内核使用结构体vm_area_struct描述虚拟内存区域
文件映射的虚拟内存区域
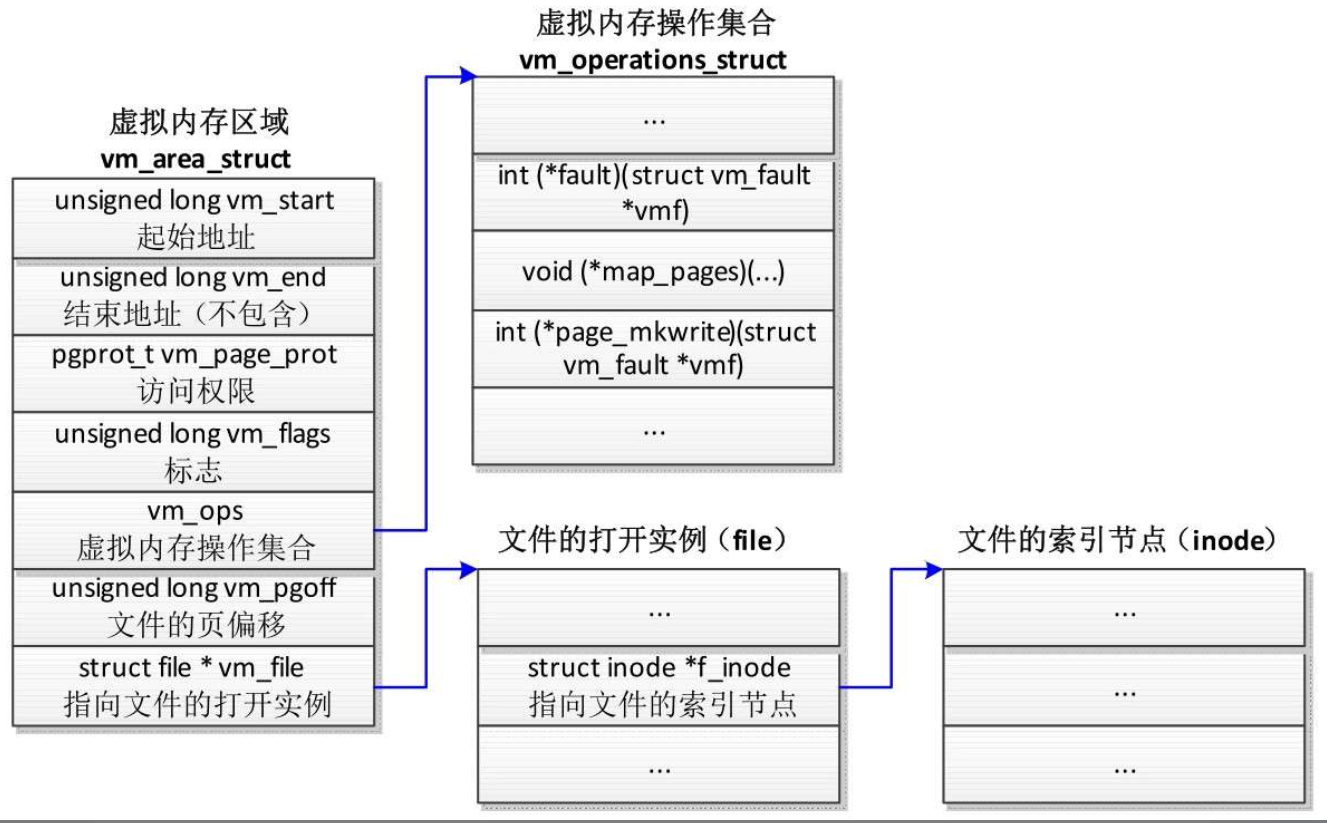
- (1)成员vm_file指向文件的一个打开实例(file)。索引节点代表一个文件,描述文件的属性。
- (2)成员vm_pgoff存放文件的以页为单位的偏移。
- (3)成员vm_ops指向虚拟内存操作集合,创建文件映射的时候调用文件操作集合中的mmap方法(file->f_op->mmap)以注册虚拟内存操作集合。例如:假设文件属于EXT4文件系统,文件操作集合中的mmap方法是函数ext4_file_mmap,该函数把虚拟内存区域的成员vm_ops设置为ext4_file_vm_ops。
共享匿名映射的虚拟内存区域
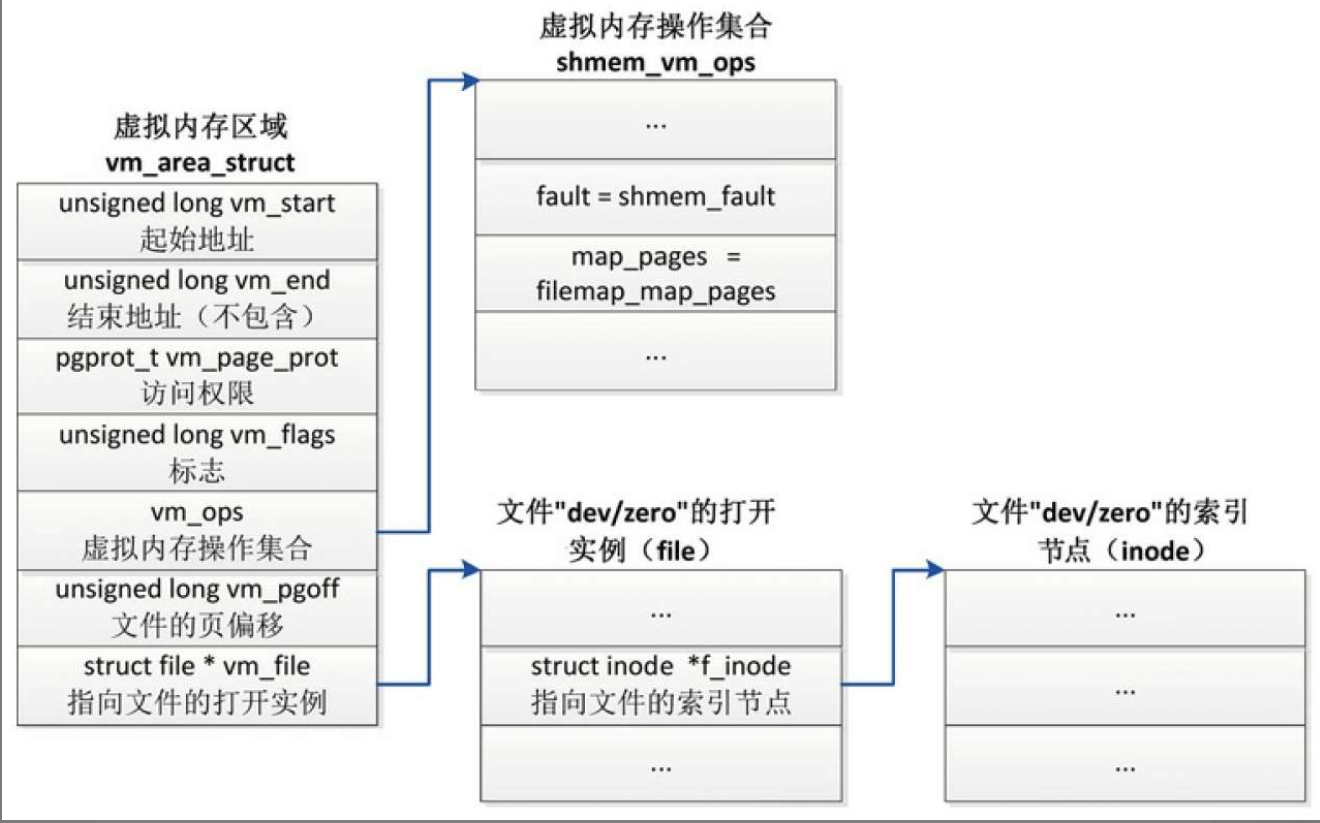
- (1)成员vm_file指向文件的一个打开实例(file)。
- (2)成员vm_pgoff存放文件的以页为单位的偏移。
- (3)成员vm_ops指向共享内存的虚拟内存操作集合shmem_vm_ops。
私有匿名映射的虚拟内存区域

- 成员vm_file没有意义,是空指针。
- 成员vm_pgoff没有意义。
- 成员vm_ops是空指针。
创建内存映射
C标准库封装了函数mmap用来创建内存映射,内核提供了POSIX标准定义的系统调用mmap
系统调用
1 | sys_mmap |
两个系统调用的区别是:mmap指定的偏移的单位是字节,而mmap2指定的偏移的单位是页。
系统调用sys_mmap的执行流程
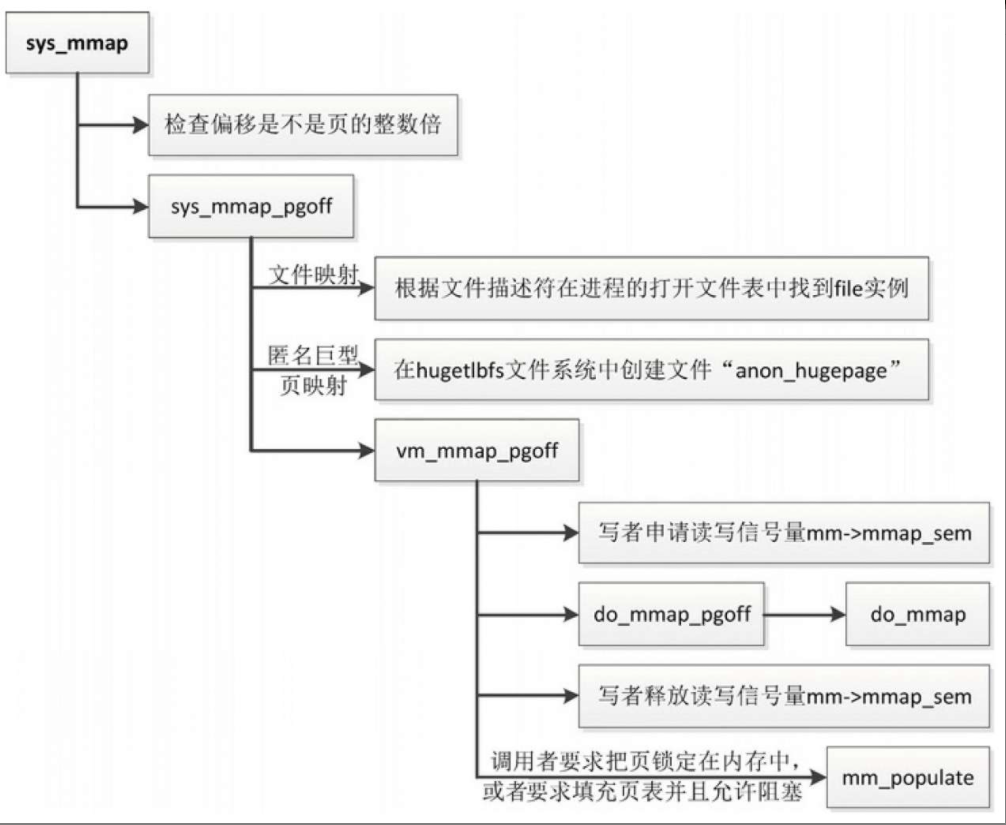
- (1)检查偏移是不是页的整数倍,如果偏移不是页的整数倍,返回“-EINVAL”。
- (2)如果偏移是页的整数倍,那么把偏移转换成以页为单位的偏移,然后调用函数sys_mmap_pgoff。
- (3)调用函数vm_mmap_pgoff进行处理。
- 以写者身份申请读写信号量mm->mmap_sem。
- 把创建内存映射的主要工作委托给函数do_mmap。
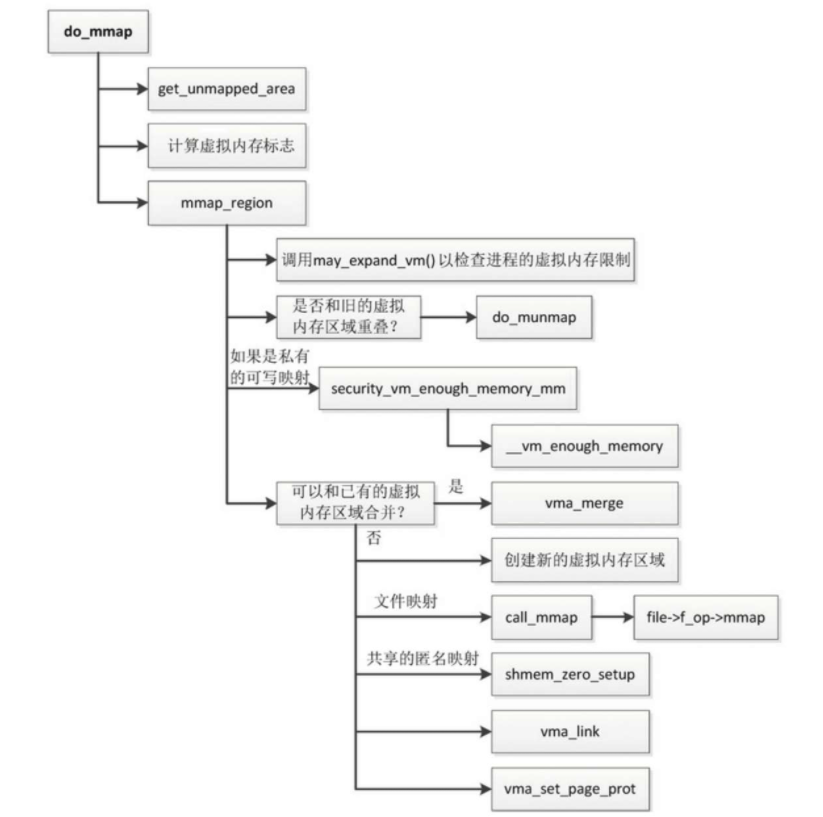
- 调用函数get_unmapped_area,从进程的虚拟地址空间分配一个虚拟地址范围。函数get_unmapped_area根据情况调用特定函数以分配虚拟地址范围。
- 如果是创建文件映射或匿名巨型页映射,那么调用file->f_op->get_unmapped_area以分配虚拟地址范围。
- 如果是创建共享的匿名映射,那么调用shmem_get_unmapped_area以分配虚拟地址范围。
- 如果是创建私有的匿名映射,那么调用mm->get_unmapped_area以分配虚拟地址范围。ARM64架构的内核在装载程序时,如果选择传统布局,函数arch_pick_mmap_layout把mm->get_unmapped_area设置为函数arch_get_unmapped_area。
- 计算虚拟内存标志。
把系统调用中指定的保护位和标志合并到一个标志集合中 - 调用函数mmap_region以创建虚拟内存区域
- 调用函数may_expand_vm以检查进程申请的虚拟内存是否超过限制
- 如果是固定映射,调用者强制指定虚拟地址范围,可能和旧的虚拟内存区域重叠,那么需要从旧的虚拟内存区域删除重叠的部分
- 如果是私有的可写映射,检查所有进程申请的虚拟内存的总和是否超过物理内存的容量
- 如果可以和已有的虚拟内存区域合并,那么调用函数vma_merge,和已有的虚拟内存区域合并。
- 如果不能和已有的虚拟内存区域合并,处理如下
- 创建新的虚拟内存区域。
- 如果是文件映射,那么调用文件的文件操作集合中的mmap方法(file->f_op->mmap), mmap方法的主要功能是设置虚拟内存区域的虚拟内存操作集合(vm_area_struct.vm_ops),其中的fault方法很重要:第一次访问虚拟页的时候,触发页错误异常,异常处理程序将调用虚拟内存操作集合中的fault方法以把文件的数据读到内存。
- 如果是共享的匿名映射,那么在内存文件系统tmpfs中创建一个名为“/dev/zero”的文件,并且创建文件的一个打开实例file,虚拟内存区域的成员vm_file指向这个打开实例,把虚拟内存操作集合设置为shmem_vm_ops。如果没有开启共享内存的配置宏CONFIG_SHMEM, shmem_vm_ops等价于generic_file_vm_ops。
- 调用函数vma_link,把虚拟内存区域添加到链表和红黑树中。如果虚拟内存区域关联文件,那么把虚拟内存区域添加到文件的区间树中,文件的区间树用来跟踪文件被映射到哪些虚拟内存区域。
- 调用函数vma_set_page_prot,根据虚拟内存标志(vma->vm_fags)计算页保护位(vma->vm_page_prot),如果共享的可写映射想要把页标记为只读,目的是跟踪写事件,那么从页保护位删除可写位。
- 调用函数get_unmapped_area,从进程的虚拟地址空间分配一个虚拟地址范围。函数get_unmapped_area根据情况调用特定函数以分配虚拟地址范围。
- 释放读写信号量mm->mmap_sem。
- 如果调用者要求把页锁定在内存中,或者要求填充页表并且允许阻塞,那么调用函数mm_populate,分配物理页,并且在页表中把虚拟页映射到物理页。常见的情况是:创建内存映射的时候不分配物理页,等到进程第一次访问虚拟页的时候,生成页错误异常,页错误异常处理程序分配物理页,在页表中把虚拟页映射到物理页。
虚拟内存过量提交策略
虚拟内存过量提交,是指所有进程提交的虚拟内存的总和超过物理内存的容量,内存管理子系统支持3种虚拟内存过量提交策略。
- OVERCOMMIT_GUESS(0):猜测,估算可用内存的数量,因为没法准确计算可用内存的数量,所以说是猜测。
- OVERCOMMIT_ALWAYS(1):总是允许过量提交。
- OVERCOMMIT_NEVER(2):不允许过量提交。
默认策略是猜测,用户可以通过文件“/proc/sys/vm/overcommit_memory”修改策略。
在创建新的内存映射时,调用函数__vm_enough_memory根据虚拟内存过量提交策略判断内存是否足够
删除内存映射
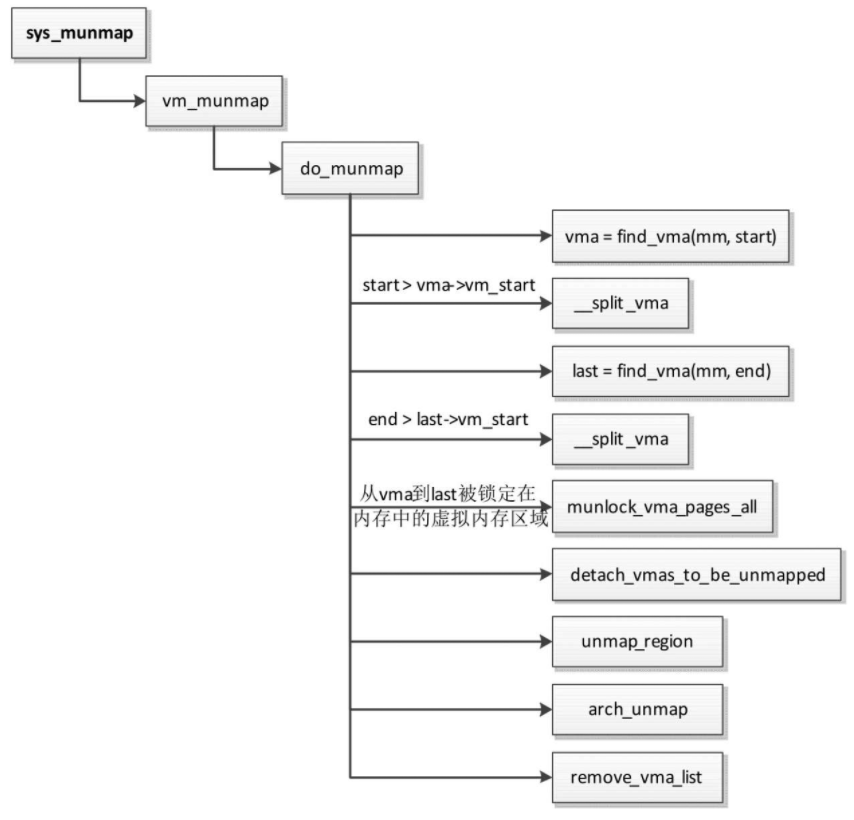
- 根据起始地址找到要删除的第一个虚拟内存区域vma。
- 如果只删除虚拟内存区域vma的一部分,那么分裂虚拟内存区域vma。
- 根据结束地址找到要删除的最后一个虚拟内存区域last。
- 如果只删除虚拟内存区域last的一部分,那么分裂虚拟内存区域last。
- 针对所有删除目标,如果虚拟内存区域被锁定在内存中(不允许换出到交换区),那么调用函数munlock_vma_pages_all以解除锁定。
- 调用函数detach_vmas_to_be_unmapped,把所有删除目标从进程的虚拟内存区域链表和树中删除,单独组成一条临时的链表。
- 调用函数unmap_region,针对所有删除目标,在进程的页表中删除映射,并且从处理器的页表缓存中删除映射。
- 调用函数arch_unmap执行处理器架构特定的处理。各种处理器架构自定义函数arch_unmap,它默认是一个空函数。
- 调用函数remove_vma_list删除所有目标。
物理内存组织
体系结构
- 非一致内存访问(Non-Uniform Memory Access, NUMA):指内存被划分成多个内存节点的多处理器系统,访问一个内存节点花费的时间取决于处理器和内存节点的距离。每个处理器有一个本地内存节点,处理器访问本地内存节点的速度比访问其他内存节点的速度快。NUMA是中高端服务器的主流体系结构。
- 对称多处理器(Symmetric Multi-Processor, SMP):即一致内存访问(Uniform MemoryAccess, UMA),所有处理器访问内存花费的时间是相同的。每个处理器的地位是平等的,仅在内核初始化的时候不平等:“0号处理器作为引导处理器负责初始化内核,其他处理器等待内核初始化完成。”
在实际应用中可以采用混合体系结构,在NUMA节点内部使用SMP体系结构。
内存模型
内存模型是从处理器的角度看到的物理内存分布情况,内核管理不同内存模型的方式存在差异。
内存管理子系统支持3种内存模型。
- 平坦内存(Flat Memory):内存的物理地址空间是连续的,没有空洞。
- 不连续内存(Discontiguous Memory):内存的物理地址空间存在空洞,这种模型可以高效地处理空洞。
- 稀疏内存(Sparse Memory):内存的物理地址空间存在空洞。如果要支持内存热插拔,只能选择稀疏内存模型。
三层结构
内存管理子系统使用节点(node)、区域(zone)和页(page)三级结构描述物理内存。
内存节点
内存节点分两种情况。
- NUMA系统的内存节点,根据处理器和内存的距离划分。
- 在具有不连续内存的UMA系统中,表示比区域的级别更高的内存区域,根据物理地址是否连续划分,每块物理地址连续的内存是一个内存节点。
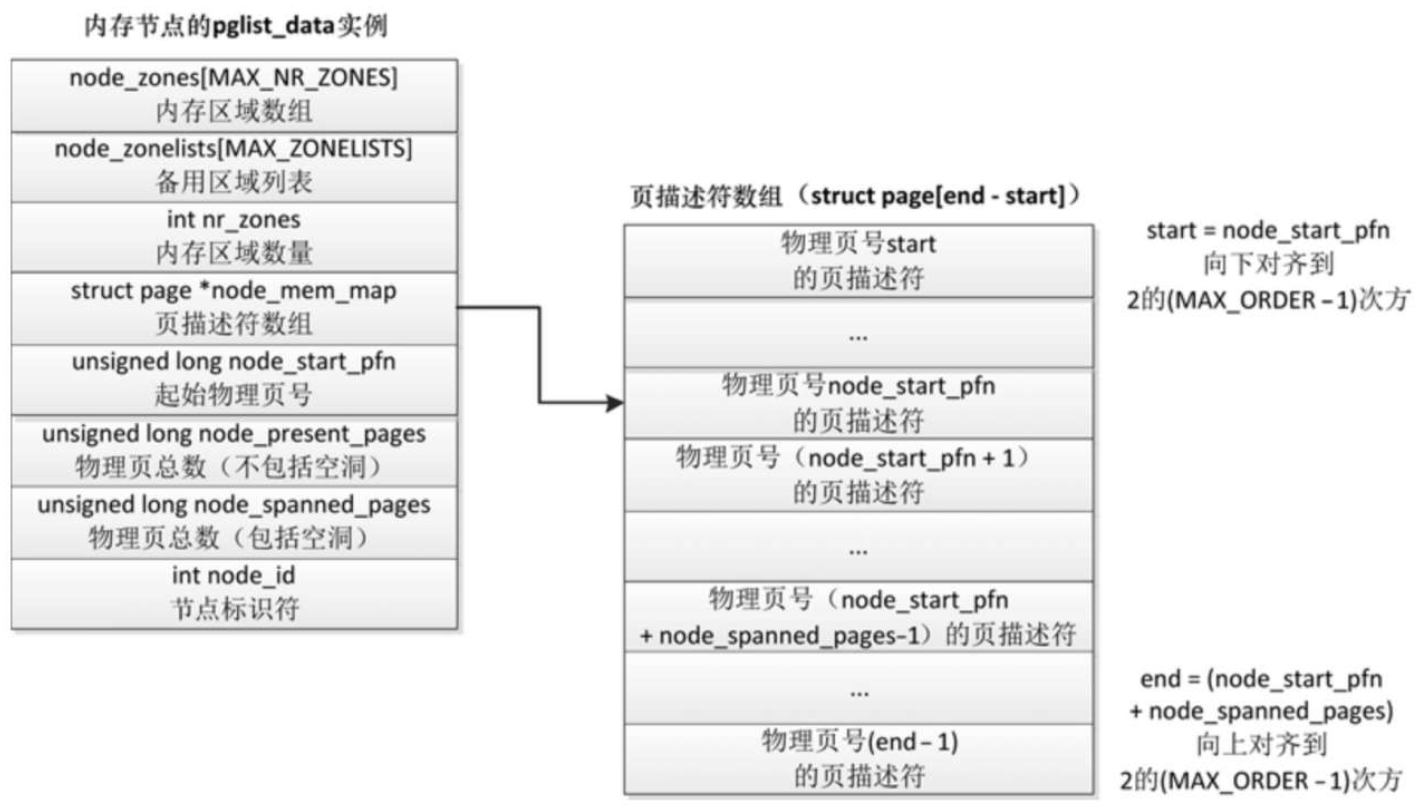
- 成员node_id是节点标识符。
- 成员node_zones是内存区域数组,成员nr_zones是内存节点包含的内存区域的数量。
- 成员node_start_pfn是起始物理页号,成员node_present_pages是实际存在的物理页的总数,成员node_spanned_pages是包括空洞的物理页总数。
- 成员node_mem_map指向页描述符数组,每个物理页对应一个页描述符。注意:成员node_mem_map可能不是指向数组的第一个元素,因为页描述符数组的大小必须对齐到2的(MAX_ORDER − 1)次方,(MAX_ORDER − 1)是页分配器可分配的最大阶数。
内存区域
内存节点被划分为内存区域
- DMA区域(ZONE_DMA):DMA是“Direct Memory Access”的缩写,意思是直接内存访问。如果有些设备不能直接访问所有内存,需要使用DMA区域。
- DMA32区域(ZONE_DMA32):64位系统,如果既要支持只能直接访问16MB以下内存的设备,又要支持只能直接访问4GB以下内存的32位设备,那么必须使用DMA32区域。
- 普通区域(ZONE_NORMAL):直接映射到内核虚拟地址空间的内存区域,直译为“普通区域”,意译为“直接映射区域”或“线性映射区域”。内核虚拟地址和物理地址是线性映射的关系,即虚拟地址 =(物理地址 + 常量)。是否需要使用页表映射?不同处理器的实现不同,例如ARM处理器需要使用页表映射,而MIPS处理器不需要使用页表映射。
- 高端内存区域(ZONE_HIGHMEM):这是32位时代的产物,内核和用户地址空间按1 : 3划分,内核地址空间只有1GB,不能把1GB以上的内存直接映射到内核地址空间,把不能直接映射的内存划分到高端内存区域。通常把DMA区域、DMA32区域和普通区域统称为低端内存区域。64位系统的内核虚拟地址空间非常大,不再需要高端内存区域。
- 可移动区域(ZONE_MOVABLE):它是一个伪内存区域,用来防止内存碎片,后面讲反碎片技术的时候具体描述。
- 设备区域(ZONE_DEVICE):为支持持久内存(persistent memory)热插拔增加的内存区域。
物理页
每个物理页对应一个page结构体,称为页描述符
内存节点的pglist_data实例的成员node_mem_map指向该内存节点包含的所有物理页的页描述符组成的数组
伙伴分配器
内核初始化完毕后,使用页分配器管理物理页
当前使用的页分配器是伙伴分配器,伙伴分配器的特点是算法简单且效率高。
基本的伙伴分配器
连续的物理页称为页块(page block)。
阶(order)是伙伴分配器的一个术语,是页的数量单位,2n个连续页称为n阶页块。
满足以下条件的两个n阶页块称为伙伴(buddy)。
- 两个页块是相邻的,即物理地址是连续的。
- 页块的第一页的物理页号必须是2n的整数倍。
- 如果合并成(n+1)阶页块,第一页的物理页号必须是2n+1的整数倍。
这是伙伴分配器(buddy allocator)这个名字的来源。
伙伴分配器分配和释放物理页的数量单位是阶。
分配n阶页块的过程如下。
- 查看是否有空闲的n阶页块,如果有,直接分配;如果没有,继续执行下一步。
- 查看是否存在空闲的(n+1)阶页块,如果有,把(n+1)阶页块分裂为两个n阶页块,一个插入空闲n阶页块链表,另一个分配出去;如果没有,继续执行下一步。
- 查看是否存在空闲的(n+2)阶页块,如果有,把(n+2)阶页块分裂为两个(n+1)阶页块,一个插入空闲(n+1)阶页块链表,另一个分裂为两个n阶页块,一个插入空闲n阶页块链表,另一个分配出去;如果没有,继续查看更高阶是否存在空闲页块。
释放n阶页块时,查看它的伙伴是否空闲,如果伙伴不空闲,那么把n阶页块插入空闲的n阶页块链表;如果伙伴空闲,那么合并为(n+1)阶页块,接下来释放(n+1)阶页块。
- 支持内存节点和区域,称为分区的伙伴分配器(zoned buddy allocator)。
- 为了预防内存碎片,把物理页根据可移动性分组。
- 针对分配单页做了性能优化,为了减少处理器之间的锁竞争,在内存区域增加1个每处理器页集合。
分区的伙伴分配器
数据结构
分区的伙伴分配器专注于某个内存节点的某个区域。
内存区域的结构体成员free_area用来维护空闲页块,数组下标对应页块的阶数。
结构体free_area的成员free_list是空闲页块的链表(暂且忽略它是一个数组,3.7.3节将介绍), nr_free是空闲页块的数量。
内存区域的结构体成员managed_pages是伙伴分配器管理的物理页的数量,不包括引导内存分配器分配的物理页。
内存区域的结构体成员free_area用来维护空闲页块,数组下标对应页块的阶数。结构体free_area的成员free_list是空闲页块的链表1
2
3
4
5
6
7
8
9struct zone{
struct free_area free_area[MAX_ORDER];
...
}
struct free_area{
struct list_head free_list[MIGRATE_TYPES;
...
}
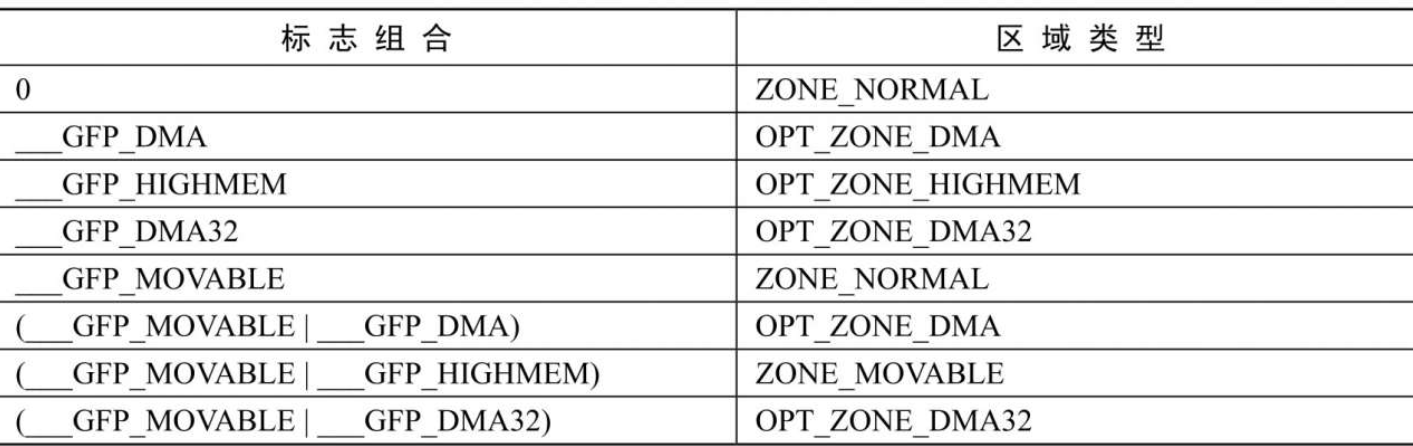
首选区域类型
根据分配标志得到首选区域类型
备用区域列表
如果首选的内存节点和区域不能满足页分配请求,可以从备用的内存区域借用物理页,借用必须遵守以下原则。
- 一个内存节点的某个区域类型可以从另一个内存节点的相同区域类型借用物理页,例如节点0的普通区域可以从节点1的普通区域借用物理页。
- 高区域类型可以从低区域类型借用物理页,例如普通区域可以从DMA区域借用物理页。
- 低区域类型不能从高区域类型借用物理页,例如DMA区域不能从普通区域借用物理页。
包含所有内存节点的备用区域列表有两种排序方法。
- 节点优先顺序:先根据节点距离从小到大排序,然后在每个节点里面根据区域类型从高到低排序。
- 区域优先顺序:先根据区域类型从高到低排序,然后在每个区域类型里面根据节点距离从小到大排序。
节点优先顺序的优点是优先选择距离近的内存,缺点是在高区域耗尽以前就使用低区域,例如DMA区域一般比较小,节点优先顺序会增大DMA区域耗尽的概率。
区域优先顺序的优点是减小低区域耗尽的概率,缺点是不能保证优先选择距离近的内存。
区域水线
首选的内存区域在什么情况下从备用区域借用物理页?
这个问题要从区域水线开始说起。每个内存区域有3个水线。
- 高水线(high):如果内存区域的空闲页数大于高水线,说明该内存区域的内存充足。
- 低水线(low):如果内存区域的空闲页数小于低水线,说明该内存区域的内存轻微不足。
- 最低水线(min):如果内存区域的空闲页数小于最低水线,说明该内存区域的内存严重不足。
防止过度借用
和高区域类型相比,低区域类型的内存相对少,是稀缺资源,而且有特殊用途
例如DMA区域用于外围设备和内存之间的数据传输。
为了防止高区域类型过度借用低区域类型的物理页,低区域类型需要采取防卫措施,保留一定数量的物理页。
一个内存节点的某个区域类型从另一个内存节点的相同区域类型借用物理页,后者应该毫无保留地借用。
可移动性分组
在系统长时间运行后,物理内存可能出现很多碎片,可用物理页很多,但是最大的连续物理内存可能只有一页。内存碎片对用户程序不是问题,因为用户程序可以通过页表把连续的虚拟页映射到不连续的物理页。但是内存碎片对内核是一个问题,因为内核使用直接映射的虚拟地址空间,连续的虚拟页必须映射到连续的物理页。内存碎片是伙伴分配器的一个弱点。
为了预防内存碎片,内核根据可移动性把物理页分为3种类型。
- 不可移动页:位置必须固定,不能移动,直接映射到内核虚拟地址空间的页属于这一类。
- 可移动页:使用页表映射的页属于这一类,可以移动到其他位置,然后修改页表映射。
- 可回收页:不能移动,但可以回收,需要数据的时候可以重新从数据源获取。后备存储设备支持的页属于这一类。
内核把具有相同可移动性的页分组。为什么这种方法可以减少碎片?
试想:如果不可移动页出现在可移动内存区域的中间,会阻止可移动内存区域合并。
这种方法把不可移动页聚集在一起,可以防止不可移动页出现在可移动内存区域的中间。
每处理器页集合
内核针对分配单页做了性能优化,为了减少处理器之间的锁竞争,在内存区域增加1个每处理器页集合。
1 | struct zone{ |
内存区域在每个处理器上有一个页集合,页集合中每种迁移类型有一个页链表。页集合有高水线和批量值,页集合中的页数量不能超过高水线。
申请单页加入页链表,或者从页链表返还给伙伴分配器,都是采用批量操作,一次操作的页数量是批量值。
从某个内存区域申请某种迁移类型的单页时,从当前处理器的页集合中该迁移类型的页链表分配页,如果页链表是空的,先批量申请页加入页链表,然后分配一页。
缓存热页是指刚刚访问过物理页,物理页的数据还在处理器的缓存中。如果要申请缓存热页,从页链表首部分配页;
如果要申请缓存冷页,从页链表尾部分配页。
释放单页时,把页加入当前处理器的页集合中。如果释放缓存热页,加入页链表首部;
如果释放缓存冷页,加入页链表尾部。如果页集合中的页数量大于或等于高水线,那么批量返还给伙伴分配器。
分配页
分配接口
页分配器提供了以下分配页的接口。
- alloc_pages(gfp_mask, order)请求分配一个阶数为order的页块,返回一个page实例。
- alloc_page(gfp_mask)是函数alloc_pages在阶数为0情况下的简化形式,只分配一页。
__get_free_pages(gfp_mask, order)对函数alloc_pages做了封装,只能从低端内存区域分配页,并且返回虚拟地址。__get_free_page(gfp_mask)是函数__get_free_pages在阶数为0情况下的简化形式,只分配一页。get_zeroed_page(gfp_mask)是函数get_free_pages在为参数gfp_mask设置了标志位GFP_ZERO且阶数为0情况下的简化形式,只分配一页,并且用零初始化。
分配标志位
- 区域修饰符:指定从哪个区域类型分配页
1 | __GFP_DMA:从DMA区域分配页。 |
- 页移动性和位置提示:指定页的迁移类型和从哪些内存节点分配页。
1 | __GFP_MOVABLE:申请可移动页,也是区域修饰符。 |
- 水线修饰符。
1 | __GFP_HIGH:指明调用者是高优先级的,为了使系统能向前推进,必须准许这个请求。例如,创建一个I/O上下文,把脏页回写到存储设备。 |
- 回收修饰符。
1 | __GFP_IO:允许读写存储设备。 |
- 行动修饰符。
1 | __GFP_COLD:调用者不期望分配的页很快被使用,尽可能分配缓存冷页(数据不在处理器的缓存中)。 |
复合页
如果设置了标志位__GFP_COMP并且分配了一个阶数大于0的页块,页分配器会把页块组成复合页(compound page)。
复合页最常见的用处是创建巨型页。复合页的第一页叫首页(head page),其他页都叫尾页(tail page)
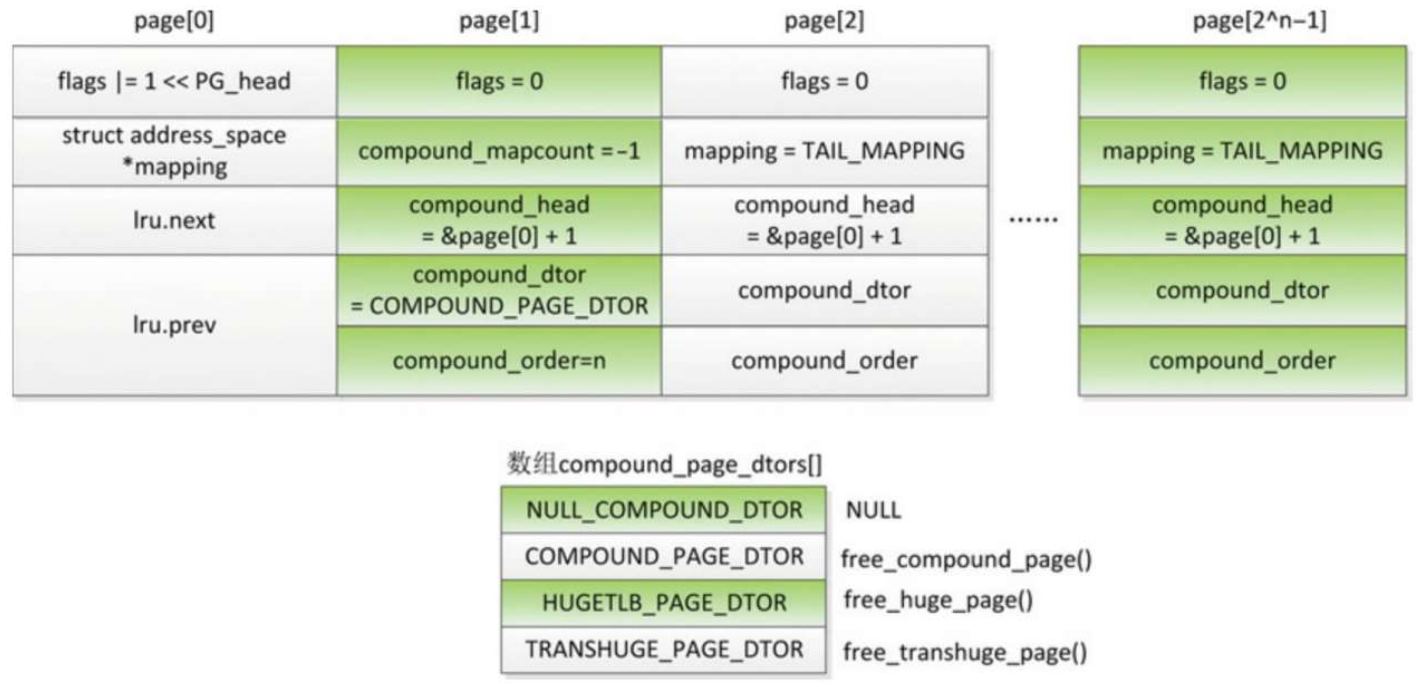
- 首页设置标志PG_head。
- 第一个尾页的成员compound_mapcount表示复合页的映射计数,即多少个虚拟页映射到这个物理页,初始值是−1。这个成员和成员mapping组成一个联合体,占用相同的位置,其他尾页把成员mapping设置为一个有毒的地址。
- 第一个尾页的成员compound_dtor存放复合页释放函数数组的索引,成员compound_order存放复合页的阶数n。这两个成员和成员lru.prev占用相同的位置。
- 所有尾页的成员compound_head存放首页的地址,并且把最低位设置为1。这个成员和成员lru.next占用相同的位置。
释放页
释放接口
void __free_pages(struct page *page, unsigned int order),第一个参数是第一个物理页的page实例的地址,第二个参数是阶数。void free_pages(unsigned long addr, unsigned int order),第一个参数是第一个物理页的起始内核虚拟地址,第二个参数是阶数。
块分配器
为了解决小块内存的分配问题,Linux内核提供了块分配器,最早实现的块分配器是SLAB分配器。
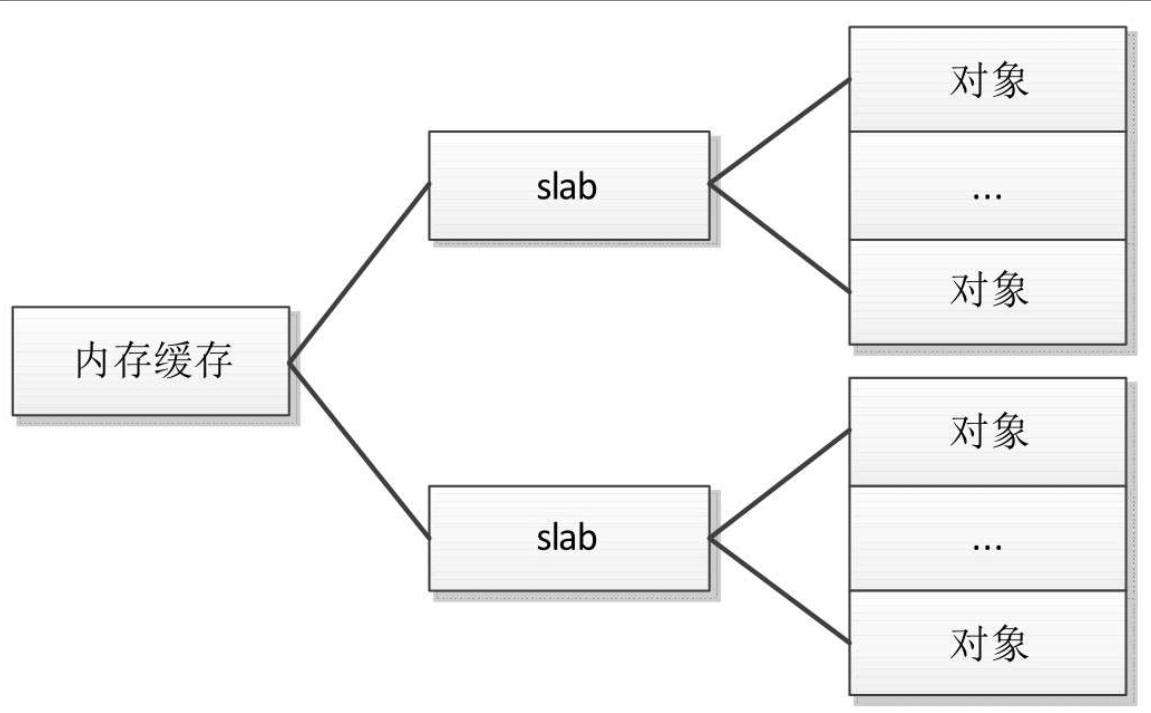
SLAB分配器的作用不仅仅是分配小块内存,更重要的作用是针对经常分配和释放的对象充当缓存。
SLAB分配器的核心思想是:为每种对象类型创建一个内存缓存,每个内存缓存由多个大块(slab,原意是大块的混凝土)组成,一个大块是一个或多个连续的物理页,每个大块包含多个对象。
SLAB采用了面向对象的思想,基于对象类型管理内存,每种对象被划分为一类,例如进程描述符(task_struct)是一个类,每个进程描述符实例是一个对象。
SLAB分配器在某些情况下表现不太好,所以Linux内核提供了两个改进的块分配器。
- 在配备了大量物理内存的大型计算机上,SLAB分配器的管理数据结构的内存开销比较大,所以设计了SLUB分配器。
- 在小内存的嵌入式设备上,SLAB分配器的代码太多、太复杂,所以设计了一个精简的SLOB分配器。
SLOB是”Simple List Of Blocks”的缩写,意思是简单的块链表。
目前SLUB分配器已成为默认的块分配器。
编程接口
3种块分配器提供了统一的编程接口
分配内存
1
void kmalloc
重新分配内存
1
void krealloc
释放内存
1
void kfree
使用通用的内存缓存的缺点是:块分配器需要找到一个对象的长度刚好大于或等于请求的内存长度的通用内存缓存,如果请求的内存长度和内存缓存的对象长度相差很远,浪费比较大
例如申请36字节,实际分配的内存长度是64字节,浪费了28字节。
所以有时候使用者需要创建专用的内存缓存,编程接口如下。
创建内存缓存
1
2
3
4
5
6
7struct kmem_cache kmem_cache_create(...)
name:名称。
size:对象的长度。
align:对象需要对齐的数值。
fags:SLAB标志位。
ctor:对象的构造函数。
如果创建成功,返回内存缓存的地址,否则返回空指针。从指定的内存缓存分配对象
1
2
3
4kmem_cache_alloc(kmem_cache *cache, fags)
cachep:从指定的内存缓存分配。
fags:传给页分配器的分配标志位,当内存缓存没有空闲对象,向页分配器请求分配页的时候使用这个分配标志位。
如果分配成功,返回对象的地址,否则返回空指针。释放对象
1
2
3kmem_cache_free(cachep, objp)
cachep:对象所属的内存缓存。
objp:对象的地址。销毁内存缓存
1
2kmem_cache_destroy(kmem_cache)
s:内存缓存。
SLAB分配器
数据结构
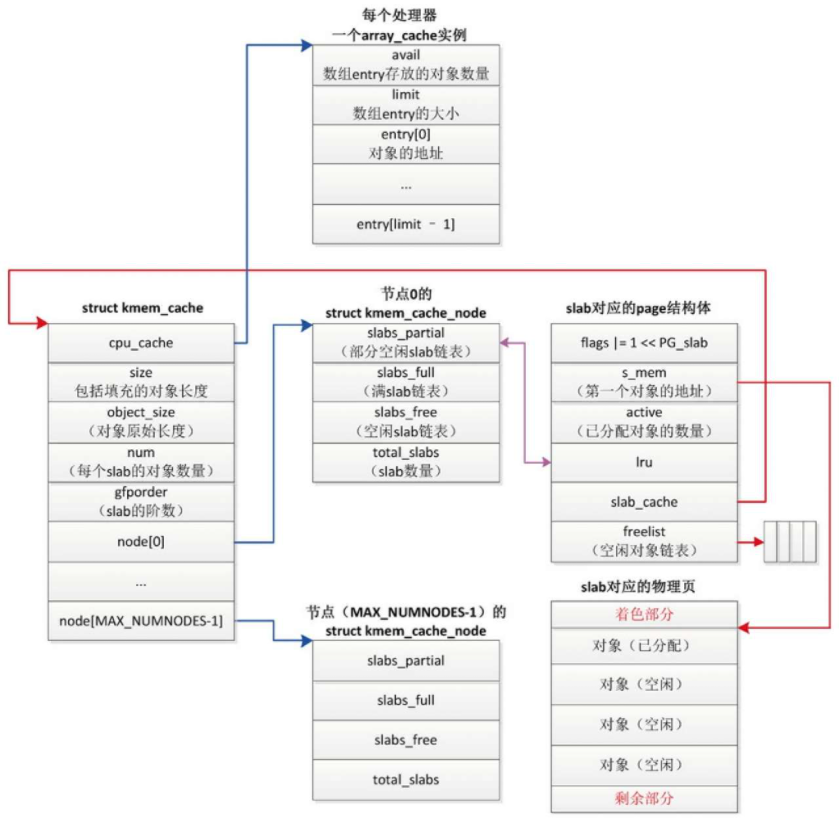
- 每个内存缓存对应一个kmem_cache实例
- 成员gfporder是slab的阶数
- 成员num是每个slab包含的对象数量
- 成员object_size是对象原始长度
- 成员size是包括填充的对象长度。
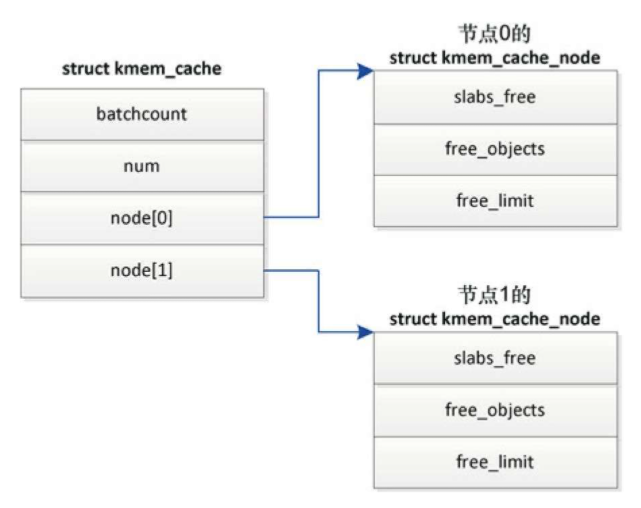
- 每个内存节点对应一个kmem_cache_node实例
kmem_cache_node实例包含3条slab链表,成员total_slabs是slab数量- 链表slabs_partial把部分对象空闲的slab链接起来
- 链表slabs_full把没有空闲对象的slab链接起来
- 链表slabs_free把所有对象空闲的slab链接起来
计算slab长度
函数calculate_slab_order负责计算slab长度
着色
slab是一个或多个连续的物理页,起始地址总是页长度的整数倍,不同slab中相同偏移的位置在处理器的一级缓存中的索引相同。
如果slab的剩余部分的长度超过一级缓存行的长度,剩余部分对应的一级缓存行没有被利用
如果对象的填充字节的长度超过一级缓存行的长度,填充字节对应的一级缓存行没有被利用。
这两种情况导致处理器的某些缓存行被过度使用,另一些缓存行很少使用。
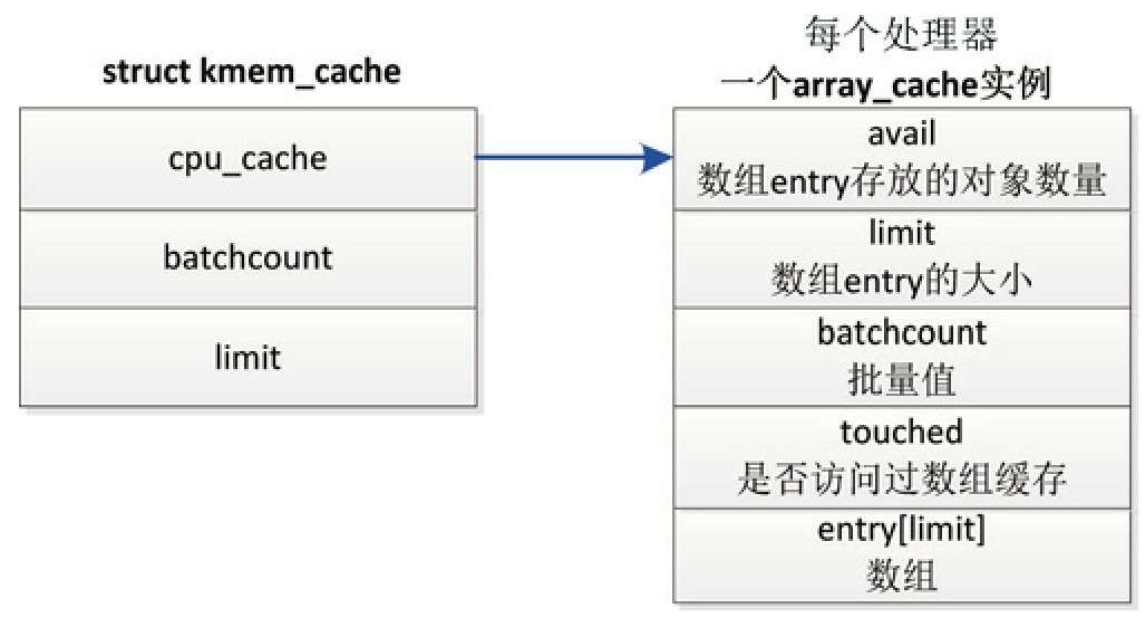
每处理器数组缓存
内存缓存为每个处理器创建了一个数组缓存(结构体array_cache)。
释放对象时,把对象存放到当前处理器对应的数组缓存中;
分配对象的时候,先从当前处理器的数组缓存分配对象,采用后进先出(Last In First Out, LIFO)的原则,这种做法可以提高性能。
对NUMA的支持
SLAB分配器怎么支持NUMA系统。如图所示,内存缓存针对每个内存节点创建一个kmem_cache_node实例。
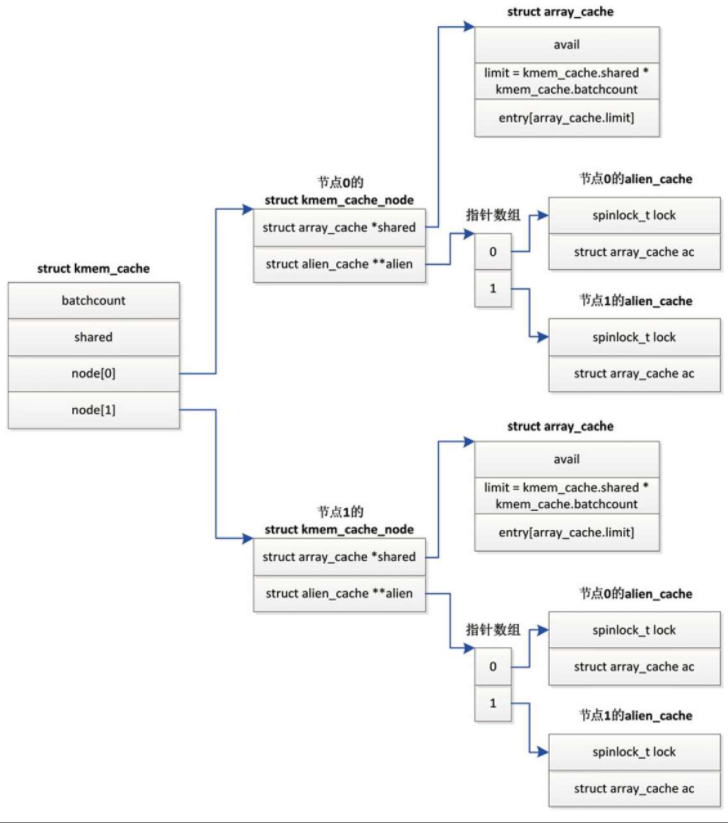
kmem_cache_node实例的成员shared指向共享数组缓存,成员alien指向远程节点数组缓存,每个节点一个远程节点数组缓存
这两个成员有什么用处呢?
用来分阶段释放从其他节点借用的对象,先释放到远程节点数组缓存,然后转移到共享数组缓存,最后释放到远程节点的slab。
分配和释放本地内存节点的对象时,也会使用共享数组缓存。
- 申请分配对象时,如果当前处理器的数组缓存是空的,共享数组缓存里面的对象可以用来重填。
- 释放对象时,如果当前处理器的数组缓存是满的,并且共享数组缓存有空闲空间,那么可以转移一部分对象到共享数组缓存,不需要把对象批量归还给slab,然后把正在释放的对象添加到当前处理器的数组缓存中。
内存缓存合并
为了减少内存开销和增加对象的缓存热度,块分配器会合并相似的内存缓存。
在创建内存缓存的时候,从已经存在的内存缓存中找到一个相似的内存缓存,和原始的创建者共享这个内存缓存。
3种块分配器都支持内存缓存合并。
回收内存
节点n的空闲对象的数量限制 = (1 + 节点的处理器数量)* kmem_cache.batchcount+kmem_cache.num。
SLAB分配器定期回收对象和空闲slab,实现方法是在每个处理器上向全局工作队列添加1个延迟工作项,工作项的处理函数是cache_reap。
每个处理器每隔2秒针对每个内存缓存执行。
- 回收节点n(假设当前处理器属于节点n)对应的远程节点数组缓存中的对象。
- 如果过去2秒没有从当前处理器的数组缓存分配对象,那么回收数组缓存中的对象。
每个处理器每隔4秒针对每个内存缓存执行。
- 如果过去4秒没有从共享数组缓存分配对象,那么回收共享数组缓存中的对象。
- 如果过去4秒没有从空闲slab分配对象,那么回收空闲slab。
不连续页分配器
当设备长时间运行后,内存碎片化,很难找到连续的物理页。
在这种情况下,如果需要分配长度超过一页的内存块,可以使用不连续页分配器,分配虚拟地址连续但是物理地址不连续的内存块。
在32位系统中,不连续页分配器还有一个好处:优先从高端内存区域分配页,保留稀缺的低端内存区域。
编程接口
不连续页分配器提供了以下编程接口
- vmalloc函数:分配不连续的物理页并且把物理页映射到连续的虚拟地址空间。
- vfree函数:释放vmalloc分配的物理页和虚拟地址空间。
- vmap函数:把已经分配的不连续物理页映射到连续的虚拟地址空间。
- vunmap函数:释放使用vmap分配的虚拟地址空间。
内核还提供了以下函数
- kvmalloc函数:先尝试使用kmalloc分配内存块,如果失败,那么使用vmalloc函数分配不连续的物理页。
- kvfree函数:如果内存块是使用vmalloc分配的,那么使用vfree释放,否则使用kfree释放。
数据结构
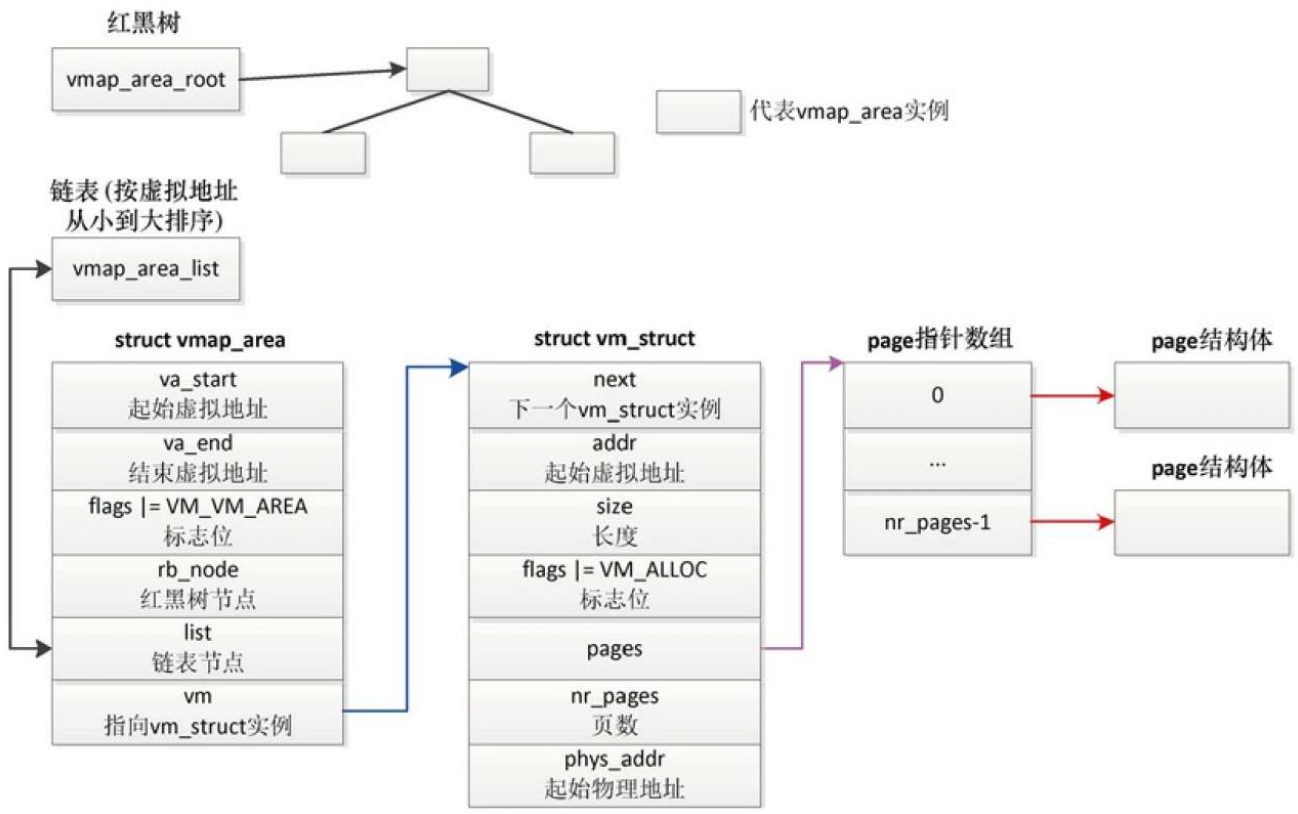
- 每个虚拟内存区域对应一个vmap_area实例
- 每个vmap_area实例关联一个vm_struct实例
技术原理
vmalloc的执行过程分为3步
- 分配虚拟内存区域
- 分配vm_struct实例和vmap_area实例;然后遍历已经存在的vmap_area实例,在两个相邻的虚拟内存区域之间找到一个足够大的空洞
- 如果找到了,把起始虚拟地址和结束虚拟地址保存在新的vmap_area实例中,然后把新的vmap_area实例加入红黑树和链表
- 最后把新的vmap_area实例关联到vm_struct实例。
- 分配物理页
vm_struct实例的成员nr_pages存放页数n;分配page指针数组,数组的大小是n, vm_struct实例的成员pages指向page指针数组;然后连续执行n次如下操作:从页分配器分配一个物理页,把物理页对应的page实例的地址存放在page指针数组中。 - 在内核的页表中把虚拟页映射到物理页
函数vmap和函数vmalloc的区别仅仅在于不需要分配物理页
每处理器内存分配器
每处理器变量为每个处理器生成一个变量的副本,每个处理器访问自己的副本,从而避免了处理器之间的互斥和处理器缓存之间的同步,提高了程序的执行速度
编程接口
每处理器变量分为静态和动态两种
静态每处理器变量
使用宏“DEFINE_PER_CPU(type, name)”定义普通的静态每处理器变量
使用宏“DECLARE_PER_CPU(type, name)”声明普通的静态每处理器变量。
动态每处理器变量
最常用的是宏alloc_percpu(type)。
释放处理器变量内存
使用函数free_percpu释放动态每处理器变量的内存。
访问每处理器变量
宏“this_cpu_ptr(ptr)”用来得到当前处理器的变量副本的地址
宏“get_cpu_var(var)”用来得到当前处理器的变量副本的值。
技术原理
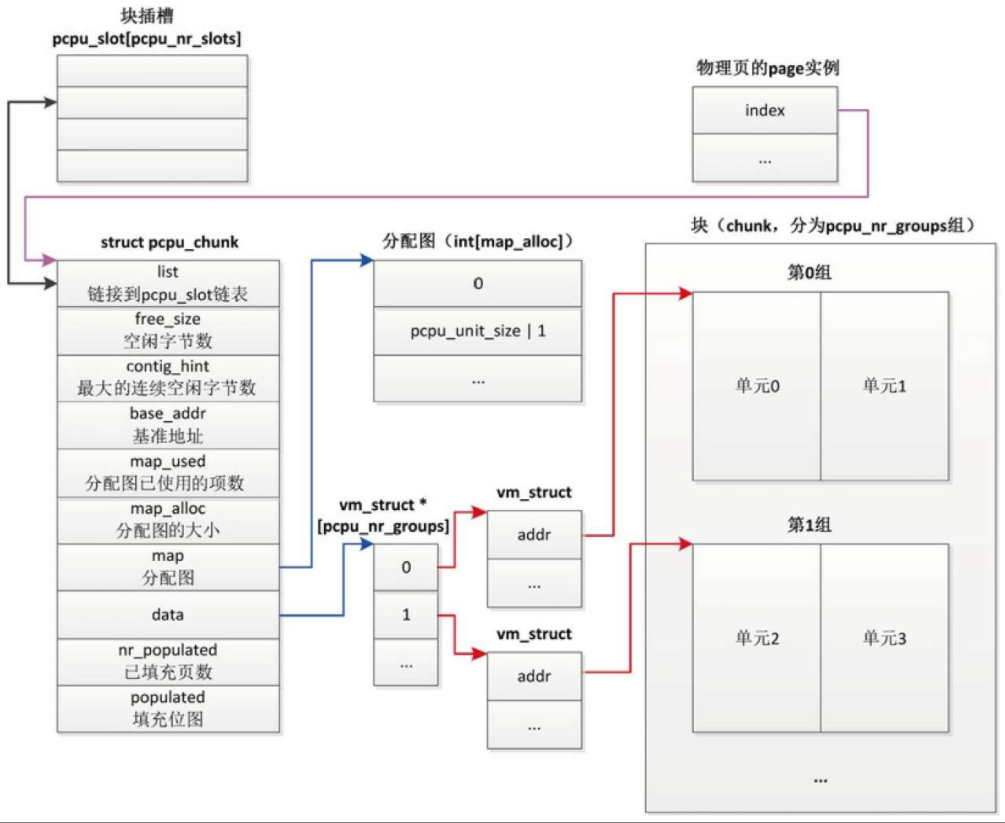
每处理器区域是按块(chunk)分配的,每个块分为多个长度相同的单元(unit),每个处理器对应一个单元。
在NUMA系统上,把单元按内存节点分组,同一个内存节点的所有处理器对应的单元属于同一个组。
分配块的方式有两种
- 基于vmalloc区域的块分配。从vmalloc虚拟地址空间分配虚拟内存区域,然后映射到物理页。
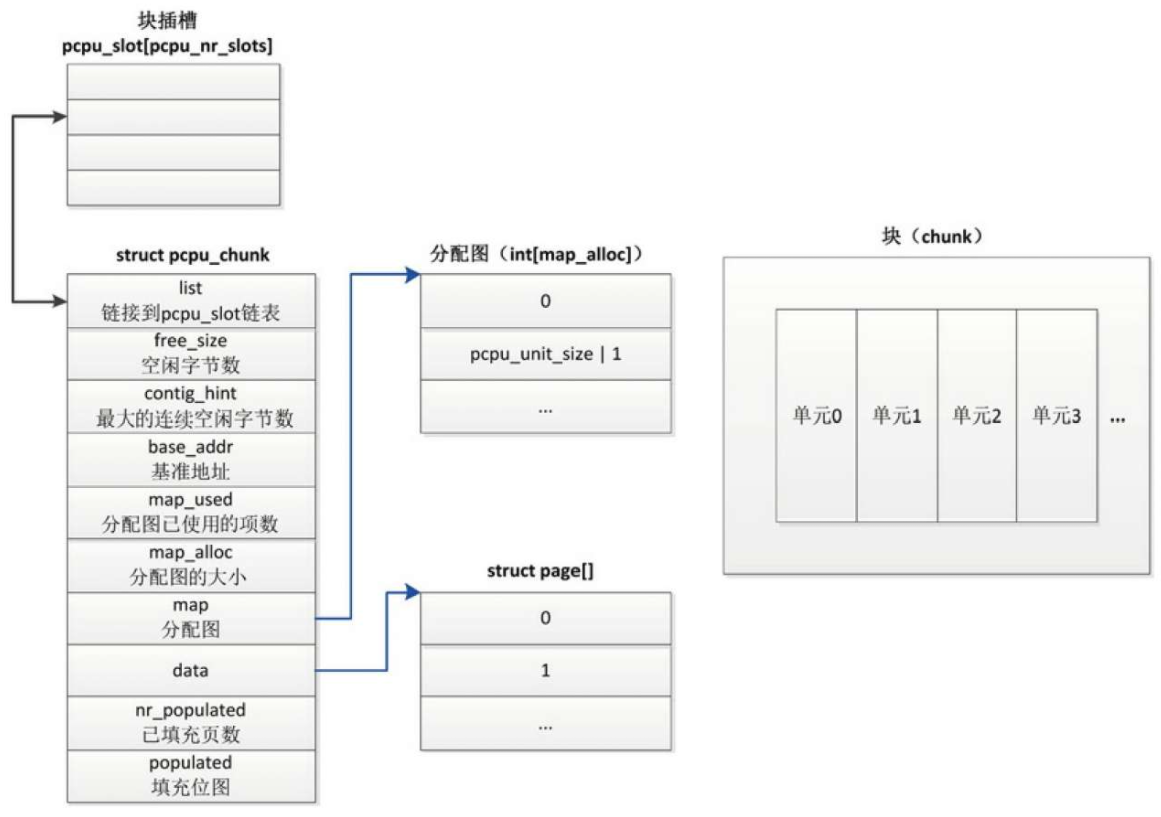
基于vmalloc区域的块分配,适合多处理器系统 - 基于内核内存的块分配。直接从页分配器分配页,使用直接映射的内核虚拟地址空间。
基于内核内存的块分配,适合单处理器系统或者处理器没有内存管理单元部件的情况,目前这种块分配方式不支持NUMA系统。
基于vmalloc区域的每处理器内存分配器
基于内核内存的每处理器内存分配器
页表
统一页表框架
在Linux 4.11版本以前,Linux内核把页表分为4级。
- 页全局目录(Page Global Directory, PGD)
- 页上层目录(Page Upper Directory, PUD)
- 页中间目录(Page Middle Directory, PMD)
- 直接页表(Page Table, PT)。
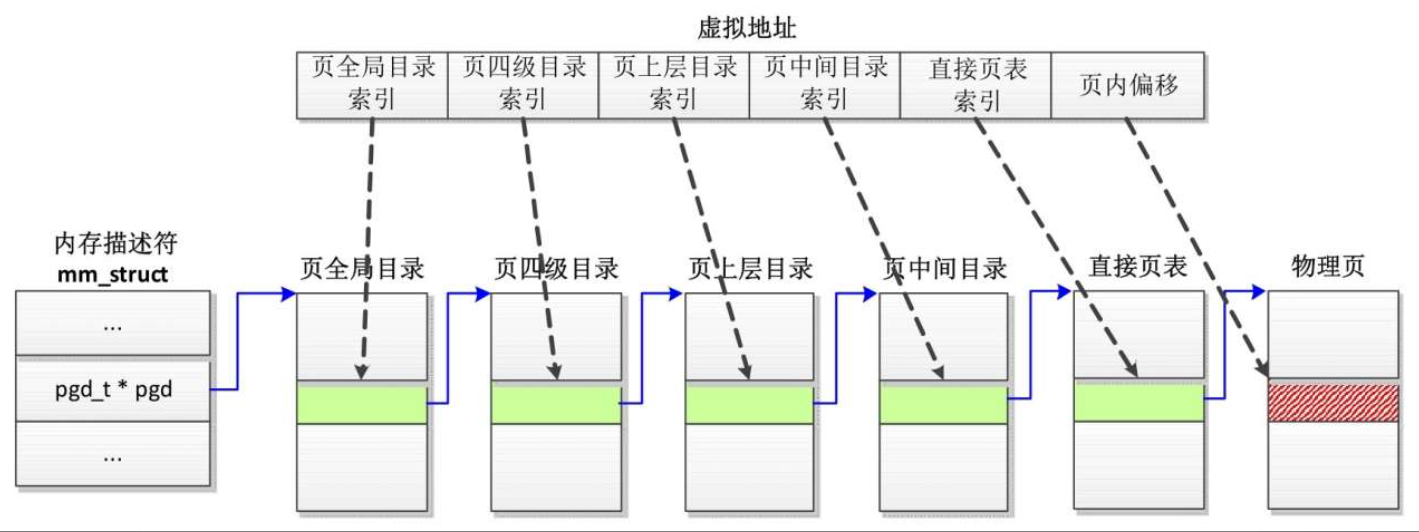
查询页表,把虚拟地址转换成物理地址的过程如下。
- 根据页全局目录的起始地址和页全局目录索引得到页全局目录表项的地址,然后从表项得到页四级目录的起始地址。
- 根据页四级目录的起始地址和页四级目录索引得到页四级目录表项的地址,然后从表项得到页上层目录的起始地址。
- 根据页上层目录的起始地址和页上层目录索引得到页上层目录表项的地址,然后从表项得到页中间目录的起始地址。
- 根据页中间目录的起始地址和页中间目录索引得到页中间目录表项的地址,然后从表项得到直接页表的起始地址。
- 根据直接页表的起始地址和直接页表索引得到页表项的地址,然后从表项得到页帧号。
- 把页帧号和页内偏移组合成物理地址。
页表缓存
处理器的内存管理单元(Memory Management Unit, MMU)负责把虚拟地址转换成物理地址,为了改进虚拟地址到物理地址的转换速度,避免每次转换都需要查询内存中的页表
处理器厂商在内存管理单元里面增加了一个称为TLB(Translation Lookaside Buffer)的高速缓存,TLB直译为转换后备缓冲区,意译为页表缓存。
TLB表项格式
不同处理器架构的TLB表项的格式不同。ARM64处理器的每条TLB表项不仅包含虚拟地址和物理地址,也包含属性:内存类型、缓存策略、访问权限、地址空间标识符(Address Space Identifier,ASID)和虚拟机标识符(Virtual Machine Identifier, VMID)。
地址空间标识符区分不同进程的页表项,虚拟机标识符区分不同虚拟机的页表项。
TLB管理
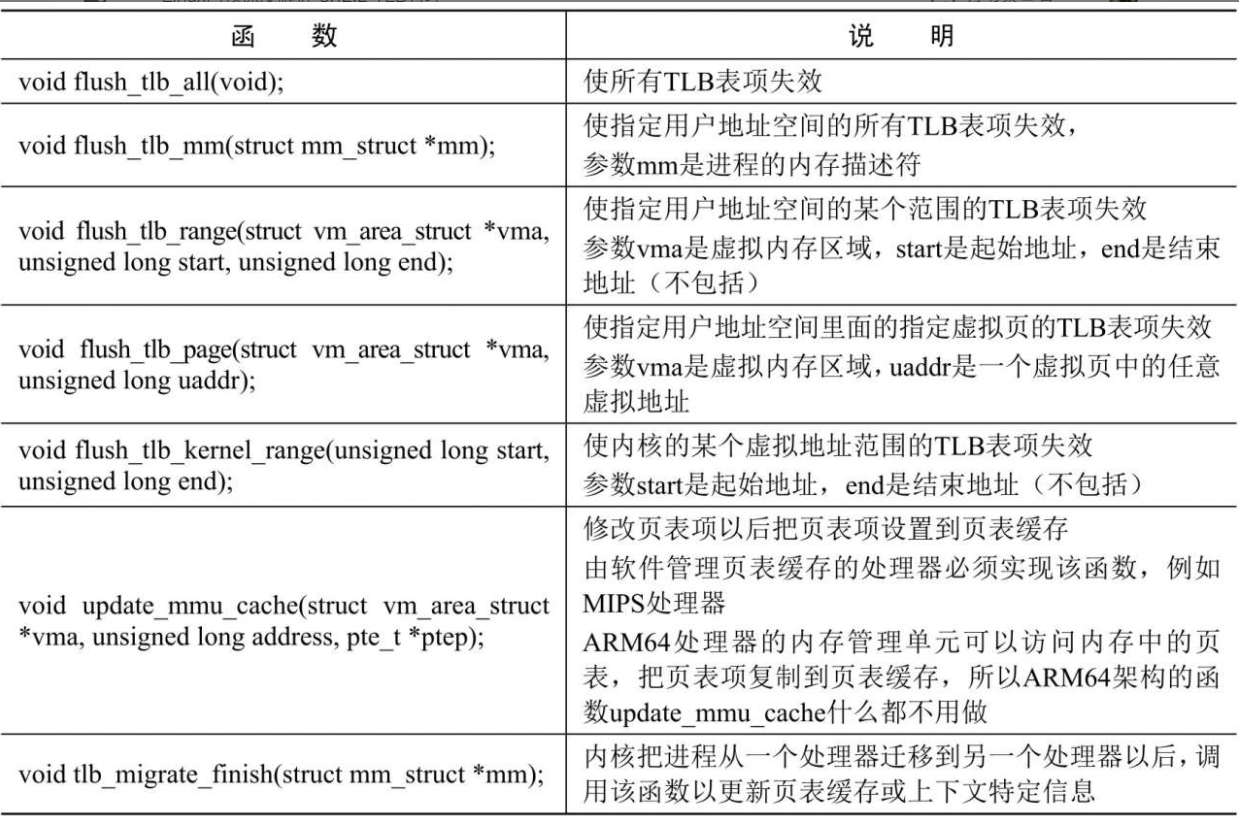
如果内核修改了可能缓存在TLB里面的页表项,那么内核必须负责使旧的TLB表项失效,内核定义了每种处理器架构必须实现的函数
地址空间标识符
为了减少在进程切换时清空页表缓存的需要
ARM64处理器的页表缓存使用非全局(not global,nG)位区分内核和进程的页表项(nG位为0表示内核的页表项)
使用地址空间标识符(AddressSpace Identifier, ASID)区分不同进程的页表项。
巨型页
当运行内存需求量较大的应用程序时,如果使用长度为4KB的页,将会产生较多的TLB未命中和缺页异常,严重影响应用程序的性能。
如果使用长度为2MB甚至更大的巨型页,可以大幅减少TLB未命中和缺页异常的数量,大幅提高应用程序的性能。
这正是内核引入巨型页(Huge Page)的直接原因。
巨型页首先需要处理器支持,然后需要内核支持,内核有如下两种实现方式。
- 使用hugetlbfs伪文件系统实现巨型页。hugetlbfs文件系统是一个假的文件系统,只是利用了文件系统的编程接口。使用hugetlbfs文件系统实现的巨型页称为hugetblfs巨型页、传统巨型页或标准巨型页,统一称为标准巨型页。
- 透明巨型页。标准巨型页的优点是预先分配巨型页到巨型页池,进程申请巨型页的时候从巨型页池取,成功的概率很高,缺点是应用程序需要使用文件系统的编程接口。透明巨型页的优点是对应用程序透明,缺点是动态分配,在内存碎片化的时候分配成功的概率很低。
处理器对巨型页的支持
标准巨型页
透明巨型页
页错误异常处理
处理器架构特定部分
用户空间页错误异常
从函数handle_mm_fault开始的部分是所有处理器架构共用的部分,函数handle_mm_fault负责处理用户空间的页错误异常。
用户空间页错误异常是指进程访问用户虚拟地址生成的页错误异常,分两种情况。
- 进程在用户模式下访问用户虚拟地址,生成页错误异常。
- 进程在内核模式下访问用户虚拟地址,生成页错误异常。进程通过系统调用进入内核模式,系统调用传入用户空间的缓冲区,进程在内核模式下访问用户空间的缓冲区。
如果页错误异常处理程序确认虚拟地址属于分配给进程的虚拟内存区域,并且虚拟内存区域授予触发页错误异常的访问权限,就会运行到函数handle_mm_fault。
函数handle_mm_fault的执行流程如图
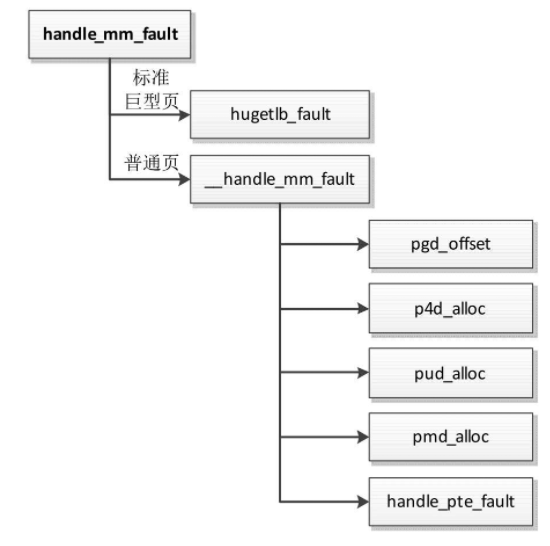
如果虚拟内存区域使用标准巨型页,那么调用函数hugetlb_fault处理标准巨型页的页错误异常。
如果虚拟内存区域使用普通页,那么调用函数__handle_mm_fault处理普通页的页错误异常。
- 在页全局目录中查找虚拟地址对应的表项。
- 在页四级目录中查找虚拟地址对应的表项,如果页四级目录不存在,那么先创建页四级目录。
- 在页上层目录中查找虚拟地址对应的表项,如果页上层目录不存在,那么先创建页上层目录。
- 在页中间目录中查找虚拟地址对应的表项,如果页中间目录不存在,那么先创建页中间目录。
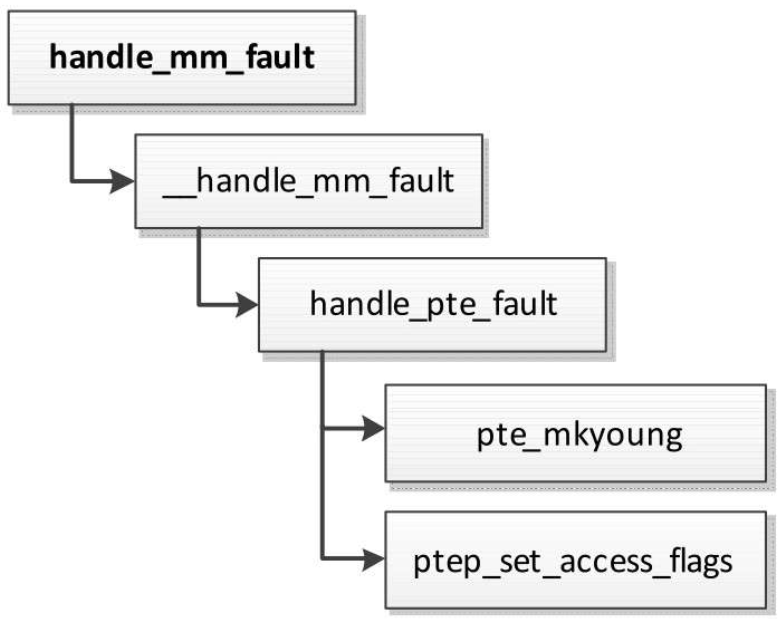
- 到达直接页表,调用函数handle_pte_fault来处理。
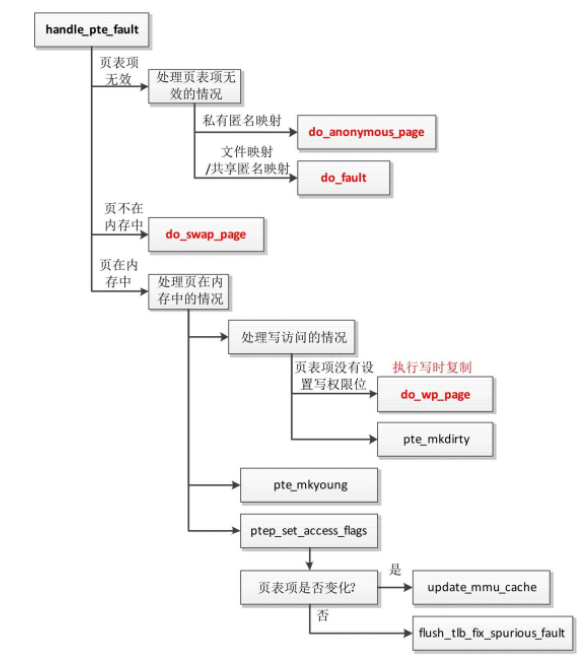
函数handle_pte_fault处理直接页表,执行流程如图
匿名页的缺页异常
什么情况会触发匿名页的缺页异常呢?
- 函数的局部变量比较大,或者函数调用的层次比较深,导致当前栈不够用,需要扩大栈。
- 进程调用malloc,从堆申请了内存块,只分配了虚拟内存区域,还没有映射到物理页,第一次访问时触发缺页异常。
- 进程直接调用mmap,创建匿名的内存映射,只分配了虚拟内存区域,还没有映射到物理页,第一次访问时触发缺页异常。
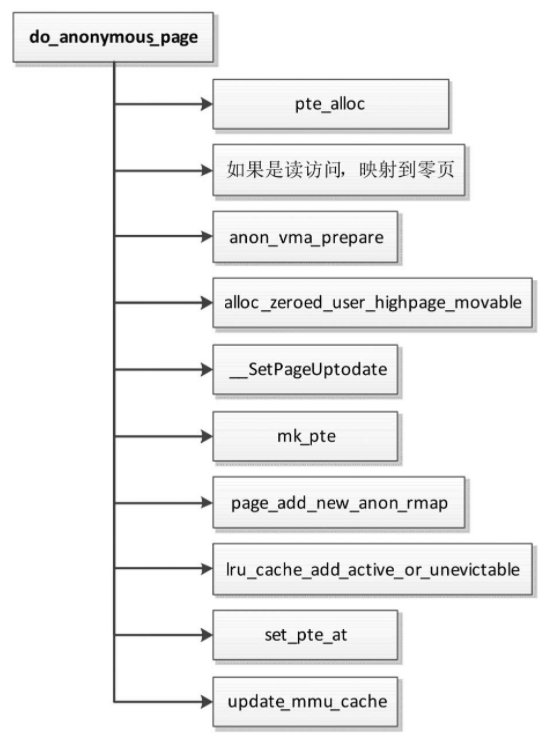
函数do_anonymous_page处理私有匿名页的缺页异常,执行流程如图
文件页的缺页异常
什么情况会触发文件页的缺页异常呢?
- 启动程序的时候,内核为程序的代码段和数据段创建私有的文件映射,映射到进程的虚拟地址空间,第一次访问的时候触发文件页的缺页异常。
- 进程使用mmap创建文件映射,把文件的一个区间映射到进程的虚拟地址空间,第一次访问的时候触发文件页的缺页异常。
函数do_fault处理文件页和共享匿名页的缺页异常,执行流程如图
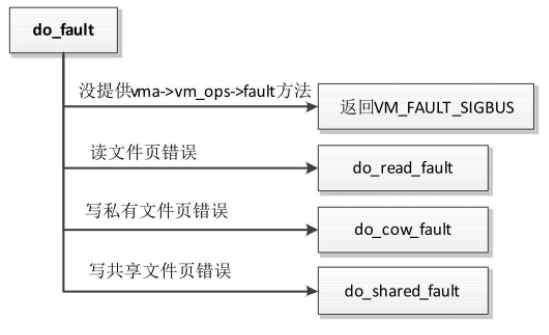
- 如果虚拟内存区域没有提供处理页错误异常的方法(vm_area_struct.vm_ops->fault),返回错误号VM_FAULT_SIGBUS。
- 如果缺页异常是由读文件页触发的,调用函数do_read_fault以处理读文件页错误。
- 如果缺页异常是由写私有文件页触发的,那么调用函数do_cow_fault以处理写私有文件页错误,执行写时复制。
- 如果缺页异常是由写共享文件页触发的,那么调用函数do_shared_faul以处理写共享文件页错误。
处理读文件页错误
处理读文件页错误的方法如下。
- 把文件页从存储设备上的文件系统读到文件的页缓存(每个文件有一个缓存,因为以页为单位,所以称为页缓存)中。
- 设置进程的页表项,把虚拟页映射到文件的页缓存中的物理页。函数do_read_fault处理读文件页错误
do read fault执行流程如图
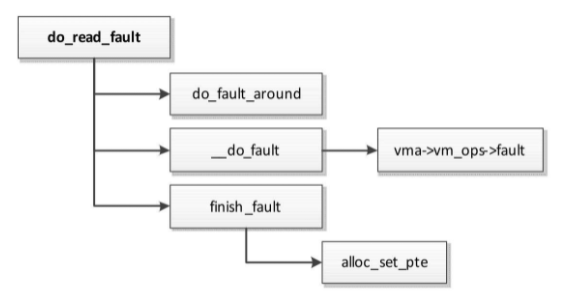
- 为了减少页错误异常的次数,如果正在访问的文件页后面的几个文件页也被映射到进程的虚拟地址空间,那么预先读取到页缓存中。
全局变量fault_around_bytes控制总长度,默认值是64KB。如果页长度是4KB,就一次读取16页。 - 把文件页读到文件的页缓存中。
- 设置页表项,把虚拟页映射到文件的页缓存中的物理页。
函数__do_fault需要使用虚拟内存区域的虚拟内存操作集合中的fault方法(vm_area_struct.vm_ops->fault)来把文件页读到内存中。
进程调用mmap创建文件映射的时候,文件所属的文件系统会注册虚拟内存区域的虚拟内存操作集合,fault方法负责处理文件页的缺页异常。
函数finish fault的执行流程
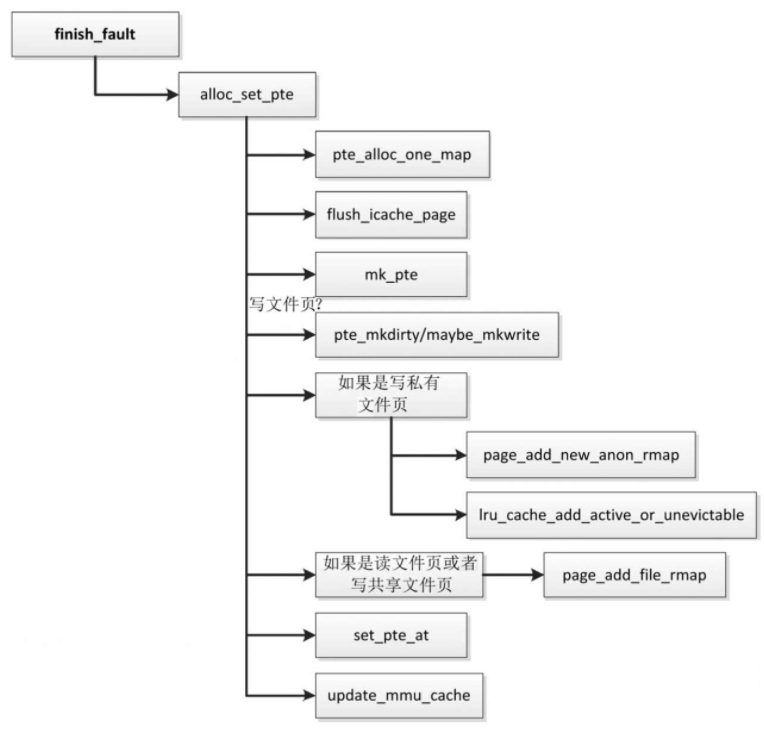
- 如果直接页表不存在,那么分配直接页表,根据虚拟地址在直接页表中查找页表项,并且锁住页表。
- 如果在锁住页表以后发现页表项不是空表项,说明其他处理器修改了同一页表项,那么当前处理器放弃处理。
- 从指令缓存中冲刷页。
- 使用页帧号和访问权限生成页表项的值。
- 如果是写访问,设置页表项的脏标志位和写权限位。
- 如果写私有文件页,那么处理如下。
- 建立物理页到虚拟页的反向映射
- 把物理页添加到活动LRU链表或不可回收LRU链表中,页回收算法需要从LRU链表中选择需要回收的物理页
- 如果读文件页或写共享文件页,那么把文件页的页表映射计数加1。
- 设置页表项。
- 更新处理器的页表缓存。
处理写私有文件页错误
函数do_cow_fault处理写私有文件页错误,执行流程如图
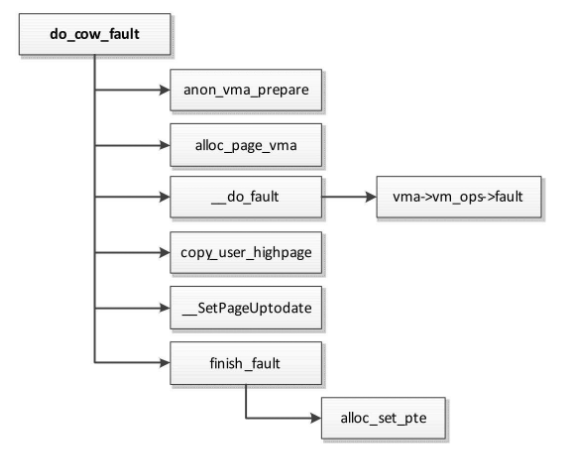
- 关联一个anon_vma实例到虚拟内存区域
- 因为后面需要执行写时复制,所以预先为副本分配一个物理页。
- 把文件页读到文件的页缓存中。第20行代码,把文件的页缓存中物理页的数据复制到副本物理页。
- 设置副本页描述符的标志位PG_uptodate,表示物理页包含有效的数据。
- 设置页表项,把虚拟页映射到副本物理页。
处理写共享文件页错误
处理写共享文件页错误的方法如下。
- 把文件页从存储设备上的文件系统读到文件的页缓存中。
- 设置进程的页表项,把虚拟页映射到文件的页缓存中的物理页。
函数do_shared_fault处理写共享文件页错误,执行流程如图
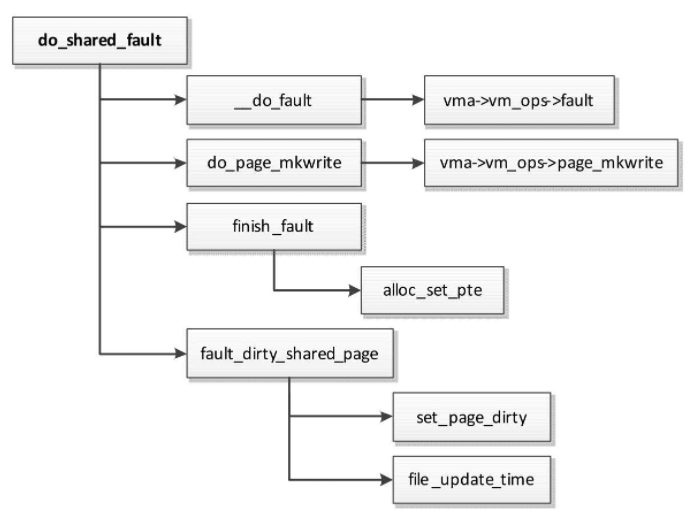
- 把文件页读到文件的页缓存中。
- 如果创建内存映射的时候文件所属的文件系统注册了虚拟内存操作集合中的page_mkwrite方法,那么调用该方法,通知文件系统“页即将变成可写的”,文件系统判断是否允许写或者等待页进入适当的状态。
- 设置页表项,把虚拟页映射到文件的页缓存中的物理页。
- 设置页的脏标志位,表示页的数据被修改。如果文件所属的文件系统没有注册虚拟内存操作集合中的page_mkwrite方法,那么更新文件的修改时间。
写时复制
有两种情况会执行写时复制(Copy on Write, CoW)。
- 进程分叉生成子进程的时候,为了避免复制物理页,子进程和父进程以只读方式共享所有私有的匿名页和文件页。当其中一个进程试图写只读页时,触发页错误异常,页错误异常处理程序分配新的物理页,把旧的物理页的数据复制到新的物理页,然后把虚拟页映射到新的物理页。
- 进程创建私有的文件映射,然后读访问,触发页错误异常,异常处理程序把文件读到页缓存,然后以只读模式把虚拟页映射到文件的页缓存中的物理页。接着执行写访问,触发页错误异常,异常处理程序执行写时复制,为文件的页缓存中的物理页创建一个副本,把虚拟页映射到副本。这个副本是进程的私有匿名页,和文件脱离关系,修改副本不会导致文件变化。
函数do_wp_page处理写时复制,执行流程如图
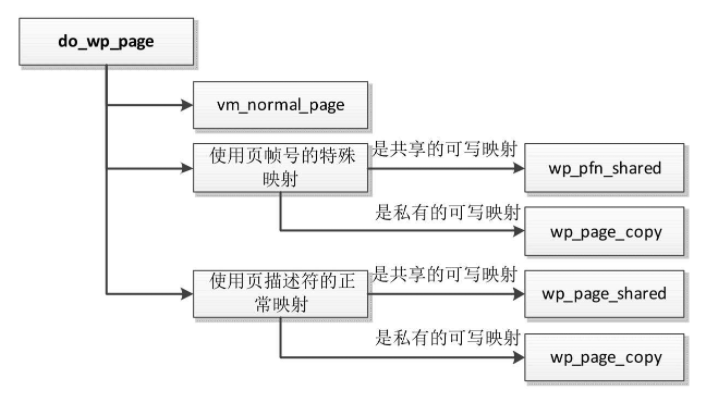
调用函数vm_normal_page,从页表项得到页帧号,然后得到页帧号对应的页描述符。
特殊映射不希望关联页描述符,直接使用页帧号,可能是因为页描述符不存在,也可能是因为不想使用页描述符。特殊映射有两种实现。
- 有些处理器架构在页表项中定义了特殊映射位PTE_SPECIAL。
- 有些处理器架构的页表项没有空闲的位,使用更复杂的实现方案:页帧号(Page FrameNumber, PFN)映射,虚拟内存区域设置了标志位VM_PFNMAP,内核提供了函数remap_pfn_range()来把页帧号映射到进程的虚拟页。还有混合映射,虚拟内存区域设置了标志位VM_MIXEDMAP,映射可以包含页描述符或页帧号。
使用页帧号的特殊映射。
- 如果是共享的可写映射,不需要复制物理页,调用函数wp_pfn_shared来设置页表项的写权限位。
- 如果是私有的可写映射,调用函数wp_page_copy以复制物理页,然后把虚拟页映射到新的物理页。
使用页描述符的正常映射。
- 如果是共享的可写映射,不需要复制物理页,调用函数wp_page_shared来设置页表项的写权限位。
- 如果是私有的可写映射,调用函数wp_page_copy以复制物理页,然后把虚拟页映射到新的物理页。
函数wp_page_copy执行写时复制,执行流程如图
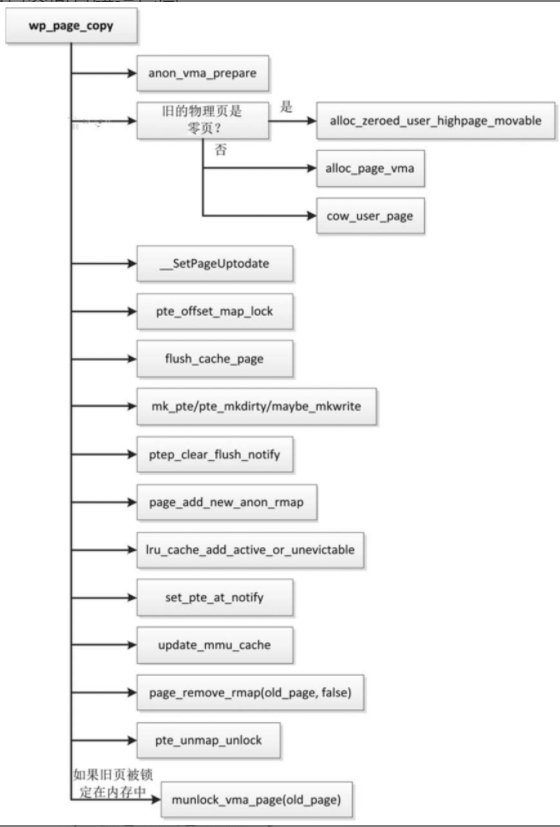
- 关联一个anon_vma实例到虚拟内存区域,匿名页的反向映射时具体介绍
- 复制物理页,分以下两种情况
- 如果是零页,那么分配一个物理页,然后用零初始化。
- 如果不是零页,那么分配一个物理页,然后把数据复制到新的物理页。
- 设置新页的标志位PG_uptodate,表示物理页包含有效的数据。
- 锁住页表。锁住以后重新读页表项,如果页表项和锁住以前的页表项不同,说明其他处理器修改了同一页表项,那么当前处理器放弃更新页表项。
- 从缓存中冲刷页。
- 使用新的物理页和访问权限生成页表项的值。
- 把页表项清除,并且冲刷页表缓存。
- 建立新物理页到虚拟页的反向映射,在描述匿名页的反向映射时具体介绍。
- 把物理页添加到活动LRU链表或不可回收LRU链表中,页回收算法需要从LRU链表中选择需要回收的物理页。
- 修改页表项。
- 更新页表缓存。
- 删除旧物理页到虚拟页的反向映射。
- 释放页表的锁。
- 如果页表项映射到新的物理页,并且旧的物理页被锁定在内存中,那么把旧的物理页解除锁定。
内核模式页错误异常
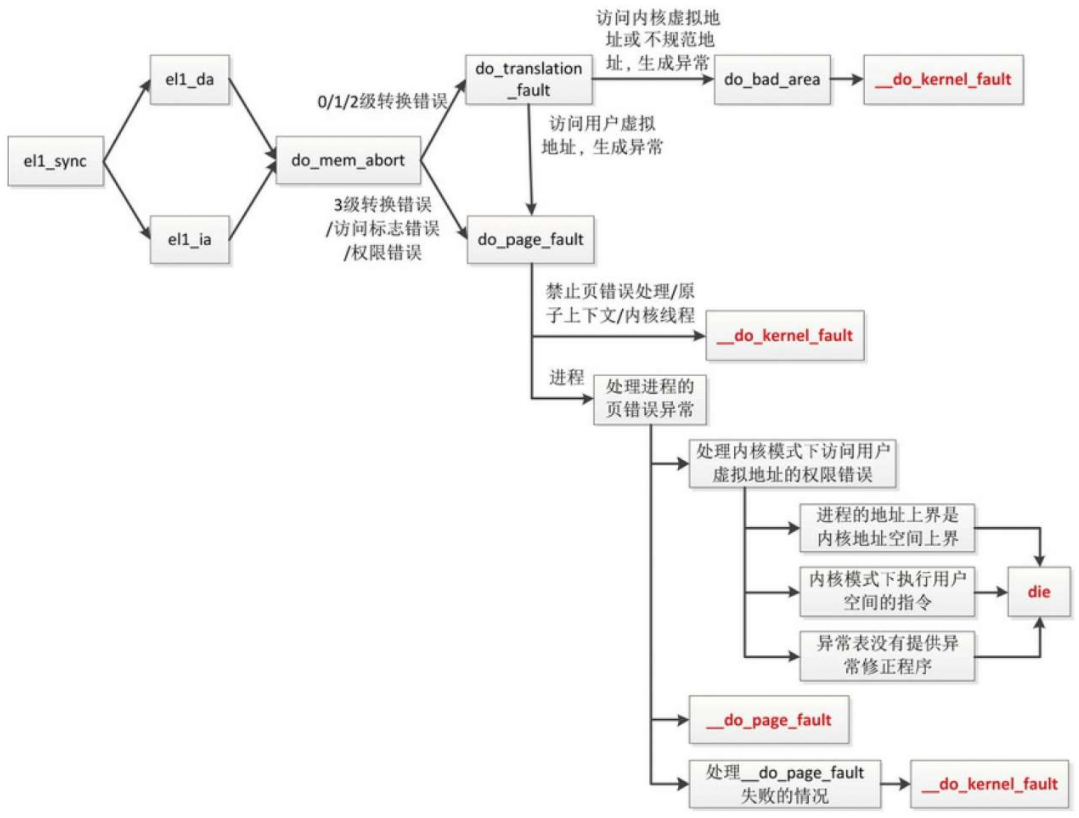
反碎片技术
内存碎片分为内部碎片和外部碎片,内部碎片指内存页里面的碎片,外部碎片指空闲的内存页分散,很难找到一组物理地址连续的空闲内存页,无法满足超过一页的内存分配请求。
对于内核来说,外部碎片是一个问题,内核有时候需要分配超过一页的物理内存,因为内核使用线性映射区域的虚拟地址,所以必须分配连续的物理页。
如果进程使用巨型页,外部碎片是一个问题,因为巨型页需要连续的物理页。
虚拟可移动区域和根据可移动性分组是预防外部碎片的技术,成块回收和内存碎片整理是在出现外部碎片以后消除外部碎片的技术。
1 | 为了解决外部碎片问题,内核引入了以下反碎片技术。 |
虚拟可移动区域
可移动区域(ZONE_MOVABLE)是一个伪内存区域,基本思想很简单:把物理内存分为两个区域,一个区域用于分配不可移动的页,另一个区域用于分配可移动的页,防止不可移动页向可移动区域引入碎片。
使用方法
使用方法可移动区域必须由管理员配置,配置方法如下。
使用内核引导参数
kernelcore=nn[KMGTPE](K表示单位是KB, M表示单位是MB)指定不可移动区域的大小;也可以使用kernelcore=mirror指定使用镜像的内存作为不可移动区域,使用其他内存作为可移动区域。1
2
3内存镜像是内存冗余技术的一种,是为了提高服务器的可靠性,防止内存故障导致服务器的数据永久丢失或者系统宕机。
内存镜像的工作原理与硬盘的热备份类似,内存镜像是将内存数据做两个拷贝,分别放在主内存和镜像内存中。
系统工作时会向两个内存中同时写入数据,因此使得内存数据有两套完整的备份。使用内核引导参数
movablecore=nn[KMG]指定可移动区域的大小。- 如果同时指定参数kernelcore和movablecore,那么不可移动区域的大小取参数kernelcore和(物理内存容量 − 参数movablecore)的最大值。
技术原理
技术原理可移动区域(ZONE_MOVABLE)没有包含任何物理内存,所以我们说它是伪内存区域,或者说是虚拟的内存区域。可移动区域借用最高内存区域的内存
在32位系统上最高的内存区域通常是高端内存区域(ZONE_HIGHMEM),在64位系统上最高的内存区域通常是普通区域(ZONE_NORMAL)。
内存碎片整理
内存碎片整理(memory compaction,直译为“内存紧缩”,意译为“内存碎片整理”)的基本思想是:从内存区域的底部扫描已分配的可移动页,从内存区域的顶部扫描空闲页,把底部的可移动页移到顶部的空闲页,在底部形成连续的空闲页。
使用方法
编译内核时,如果需要内存碎片整理功能,必须开启配置文件mm/Kconfig定义的配置宏CONFIG_COMPACTION,默认开启。
内存碎片整理技术提供了以下配置文件。
- 文件
/proc/sys/vm/compact_memory:向这个文件写入任何整数值(数值没有意义),触发内存碎片整理。 - 文件
/proc/sys/vm/compact_unevictable_allowed:用来设置是否允许内存碎片整理移动不可回收的页(进程使用系统调用mlock把页锁定在内存中),如果设置为1,表示允许,默认值是1。 - 文件
/proc/sys/vm/extfrag_threshold:用来设置外部碎片的阈值,取值范围是0~1000,默认值是500。
这个参数影响内核在申请连续页失败的时候选择直接回收页还是选择内存碎片整理。
内核计算出内存区域的碎片指数,碎片指数趋向0表示分配失败是因为内存不足,碎片指数趋向1000表示分配失败是因为内存碎片。
如果碎片指数小于或等于外部碎片的阈值,选择直接回收页;如果碎片指数大于阈值,那么选择内存碎片整理。
页回收
申请分配页的时候,页分配器首先尝试使用低水线分配页。
如果使用低水线分配失败,说明内存轻微不足,页分配器将会唤醒内存节点的页回收内核线程,异步回收页,然后尝试使用最低水线分配页。
如果使用最低水线分配失败,说明内存严重不足,页分配器将会直接回收页。
物理页根据是否有存储设备支持分为两类
- 交换支持的页:没有存储设备支持的物理页,包括匿名页,以及tmpfs文件系统(内存中的文件系统)的文件页和进程在修改私有的文件映射时复制生成的匿名页。
- 存储设备支持的文件页。
针对不同的物理页,采用不同的回收策略
- 交换支持的页:采用页交换的方法,先把页的数据写到交换区,然后释放物理页。
- 存储设备支持的文件页
- 如果是干净的页,即把文件从存储设备读到内存以后没有修改过,可以直接释放
- 如果是脏页,即把文件从存储设备读到内存以后修改过,那么先写回到存储设备,然后释放物理页。
页回收算法还会回收slab缓存。
使用专用slab缓存的内核模块可以使用函数register_shrinker注册收缩器,页回收算法调用所有收缩器的函数以释放对象。
根据什么原则选择回收的物理页?
内核使用LRU(Least Recently Used,最近最少使用)算法选择最近最少使用的物理页。
回收物理页的时候,如果物理页被映射到进程的虚拟地址空间,那么需要从页表中删除虚拟页到物理页的映射。
怎么知道物理页被映射到哪些虚拟页?
需要通过反向映射的数据结构,虚拟页映射到物理页是正向映射,物理页映射到虚拟页是反向映射。
数据结构
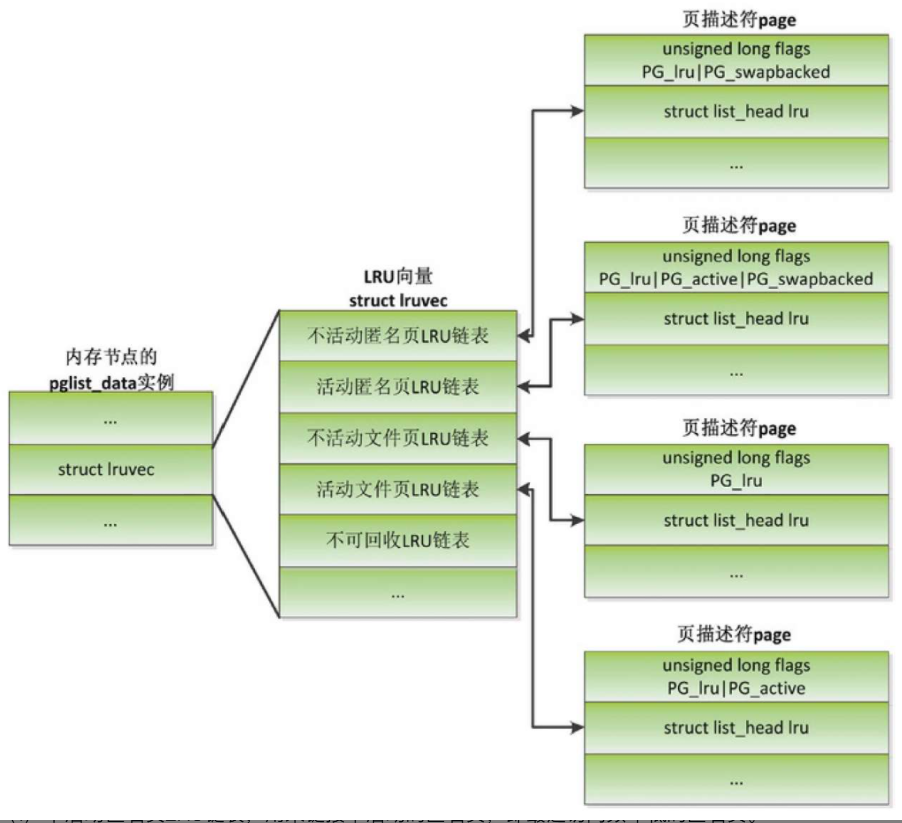
- 不活动匿名页LRU链表,用来链接不活动的匿名页,即最近访问频率低的匿名页。
- 活动匿名页LRU链表,用来链接活动的匿名页,即最近访问频率高的匿名页。
- 不活动文件页LRU链表,用来链接不活动的文件页,即最近访问频率低的文件页。
- 活动文件页LRU链表,用来链接活动的文件页,即最近访问频率高的文件页。
- 不可回收LRU链表,用来链接使用mlock锁定在内存中、不允许回收的物理页。
在LRU链表中,物理页的页描述符的特征如下
- 页描述符设置PG_lru标志位,表示物理页在LRU链表中。
- 页描述符通过成员lru加入LRU链表。
- 如果是交换支持的物理页,页描述符会设置PG_swapbacked标志位。
- 如果是活动的物理页,页描述符会设置PG_active标志位。
- 如果是不可回收的物理页,页描述符会设置PG_unevictable标志位。
每条LRU链表中的物理页按访问时间从大到小排序,链表首部的物理页的访问时间离当前最近,物理页从LRU链表的首部加入
页回收算法从不活动LRU链表的尾部取物理页回收,从活动LRU链表的尾部取物理页并移动到不活动LRU链表中。
怎么确定页的活动程度?
- 如果是页表映射的匿名页或文件页,根据页表项中的访问标志位确定页的活动程度。
当处理器的内存管理单元把虚拟地址转换成物理地址的时候,如果页表项没有设置访问标志位,就会生成页错误异常。
- 如果是没有页表映射的文件页,进程通过系统调用read或write访问文件,文件系统在文件的页缓存中查找文件页,为文件页的页描述符设置访问标志位(PG_referenced)。
何来的反向映射?
回收页表映射的匿名页或文件页时,需要从页表中删除映射
内核需要知道物理页被映射到哪些进程的虚拟地址空间,需要实现物理页到虚拟页的反向映射。
- 匿名页的反向映射的简要视图

- 匿名页的反向映射的详细视图
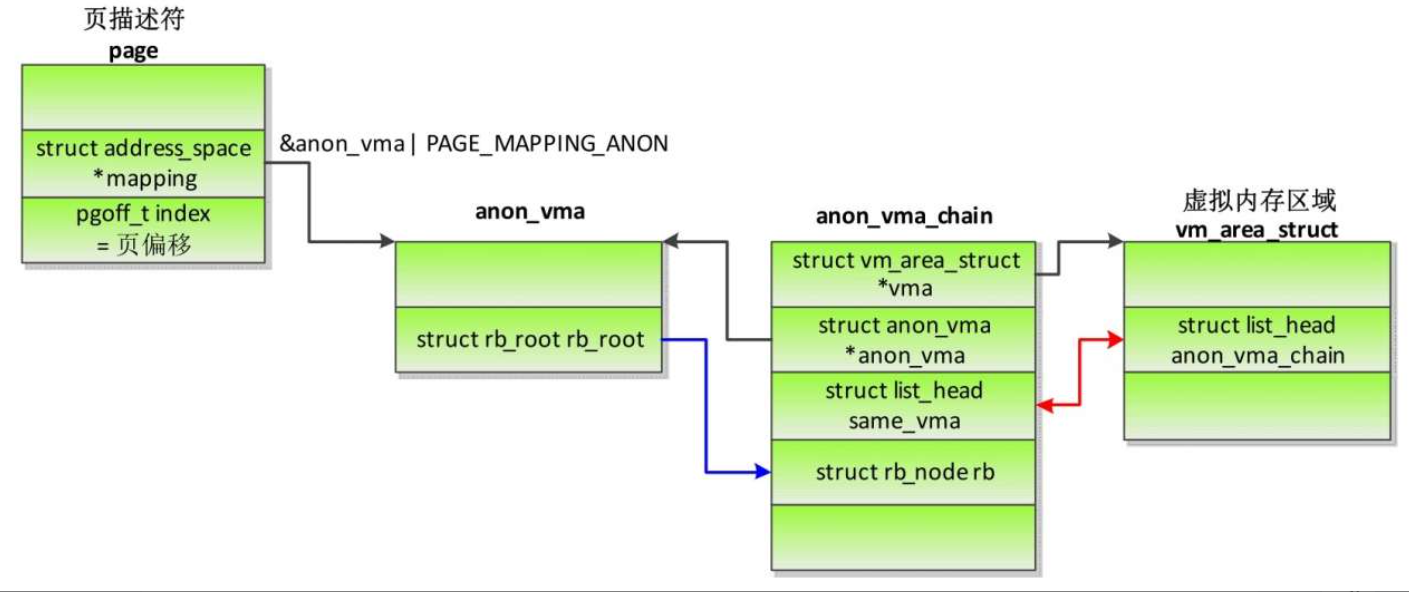
从一个进程分叉生成子进程的时候,子进程把父进程的虚拟内存完全复制一份
子进程把父进程的每个vm_area_struct实例复制一份,对每个vm_area_struct实例执行下面的操作。
- 分叉生成子进程时反向映射的简要视图
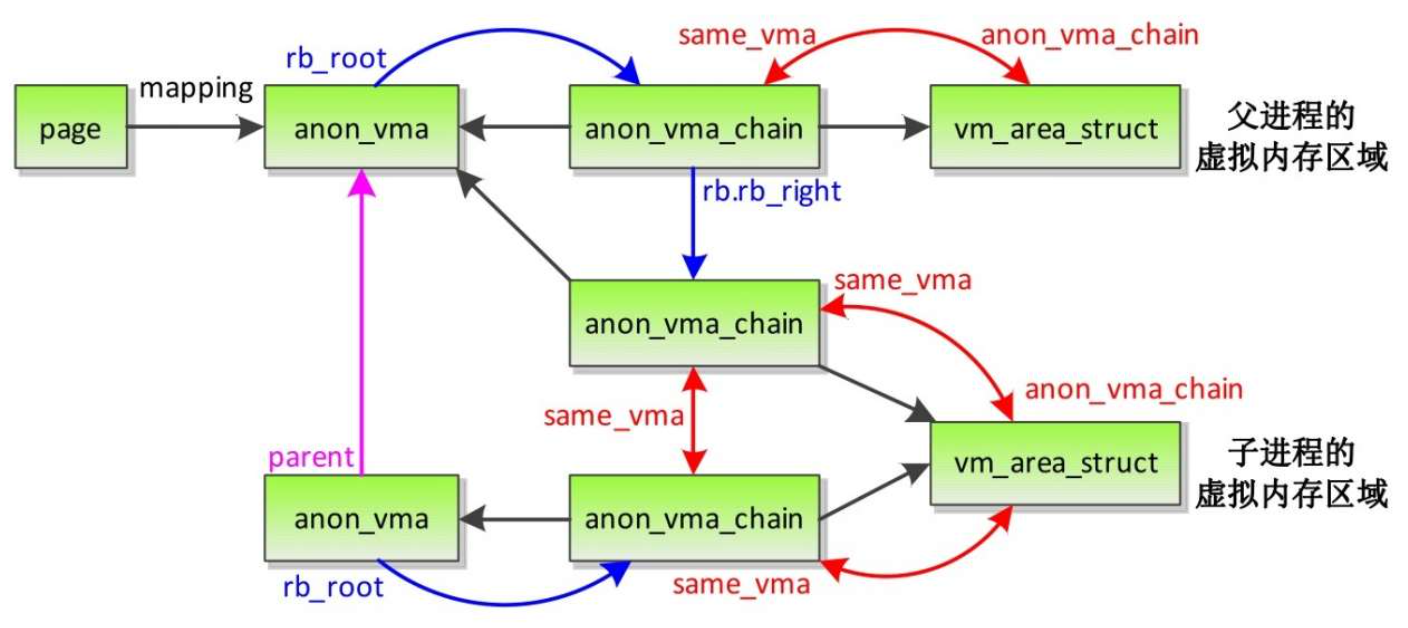
- 分叉生成子进程时反向映射的详细视图
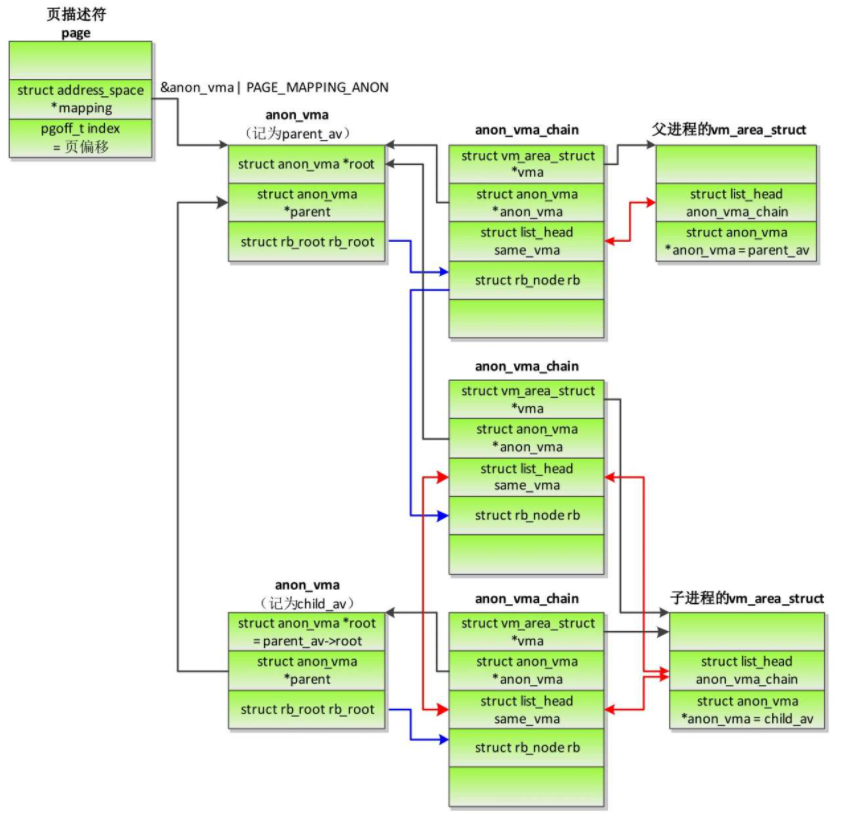
- 文件页的反向映射
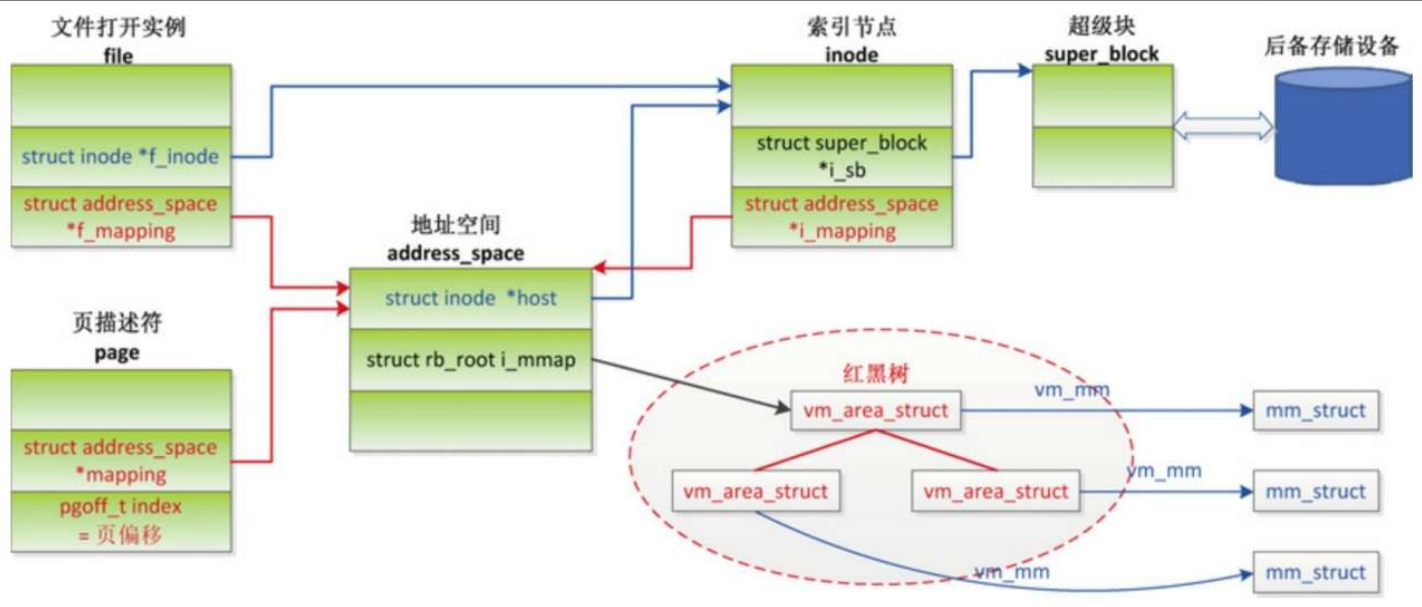
对于私有的文件映射,在写的时候生成页错误异常,页错误异常处理程序执行写时复制,新的物理页和文件脱离关系,属于匿名页
- 私有的文件映射写时复制
发起页回收
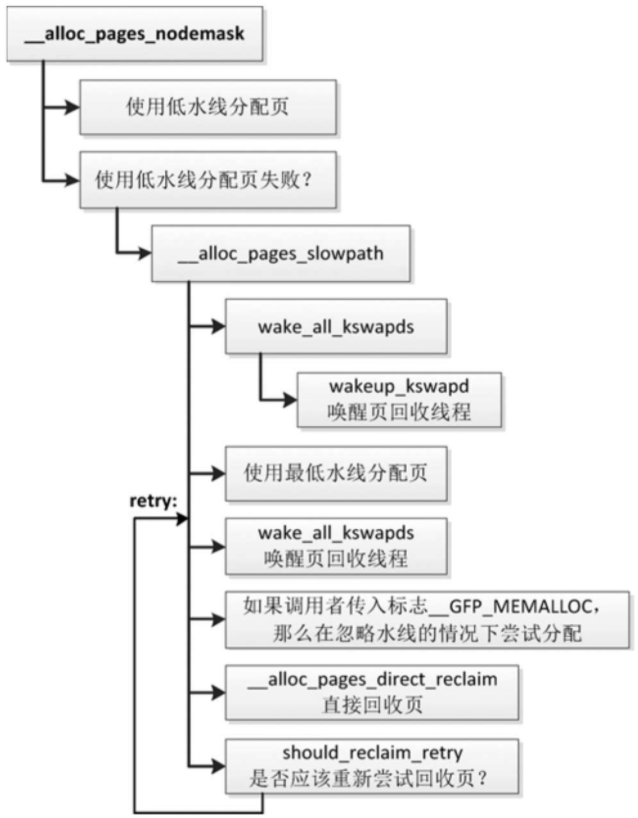
申请分配页的时候,页分配器首先尝试使用低水线分配页。
如果使用低水线分配失败,说明内存轻微不足,页分配器将会唤醒所有符合分配条件的内存节点的页回收线程,异步回收页,然后尝试使用最低水线分配页。
如果分配失败,说明内存严重不足,页分配器将会直接回收页。
如果直接回收页失败,那么判断是否应该重新尝试回收页。
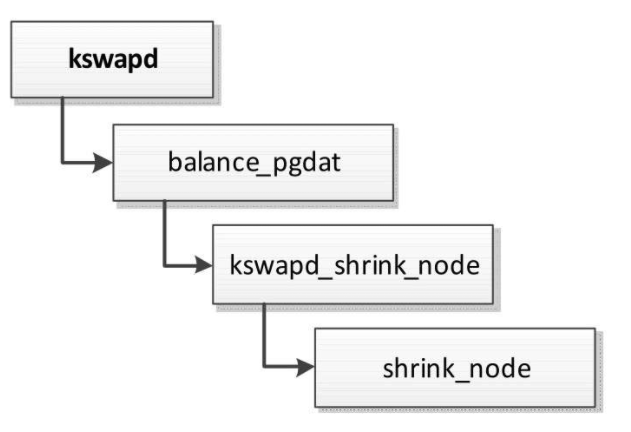
异步回收
每个内存节点有一个页回收线程,执行流程如图所示。
如果内存节点的所有内存区域的空闲页数小于高水线,页回收线程就会反复尝试回收页,调用函数shrink_node以回收内存节点中的页。
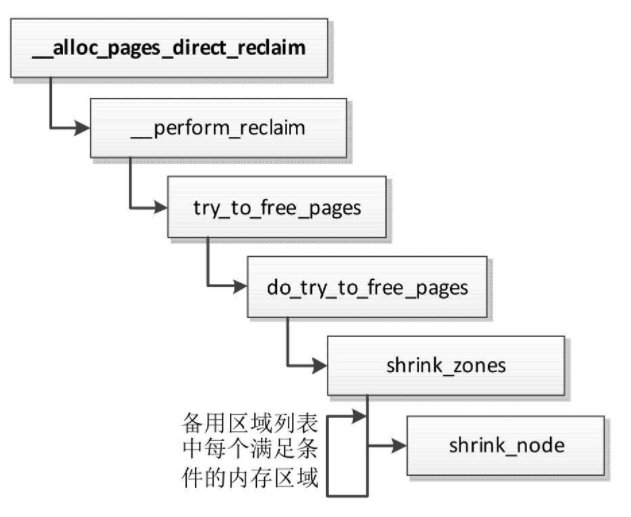
直接回收
直接回收页的执行流程如图所示,针对备用区域列表中符合分配条件的每个内存区域,调用函数shrink_node来回收内存区域所属的内存节点中的页。
回收页是以内存节点为单位执行的,函数shrink_node负责回收内存节点中的页
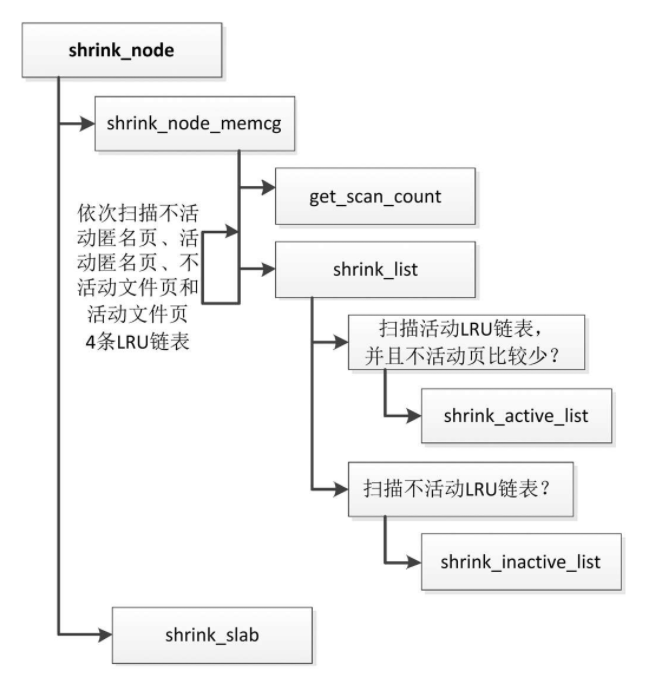
- 回收内存节点中的页
- 调用函数get_scan_count,计算需要扫描多少个不活动匿名页、活动匿名页、不活动文件页和活动文件页。
- 依次扫描不活动匿名页、活动匿名页、不活动文件页和活动文件页4条LRU链表,针对每条LRU链表
- 如果是活动LRU链表,并且不活动页比较少,那么调用函数shrink_active_list,把一部分活动页转移到不活动链表中。
- 如果是不活动LRU链表,那么调用函数shrink_inactive_list以回收不活动页。
- 调用函数shrink_slab以回收slab缓存。
- 判断是否应该重试回收页
如果直接回收16次全都失败,或者即使回收所有可回收的页,也还是无法满足水线,那么应该放弃重试回收
计算扫描的页数
页回收算法每次扫描多少页?扫描多少个匿名页和多少个文件页,怎么分配匿名页和文件页的比例?
扫描优先级用来控制一次扫描的页数,如果扫描优先级是n,那么一次扫描的页数是(LRU链表中的总页数 >> n),可以看出:“扫描优先级的值越小,扫描的页越多”。
页回收算法从默认优先级12开始,如果回收的页数没有达到目标,那么提高扫描优先级,把扫描优先级的值减1,然后继续扫描。扫描优先级的最小值为0,表示扫描LRU链表中的所有页。
两个参数用来控制扫描的匿名页和文件页的比例
- 参数
"swappiness"控制换出匿名页的积极程度,取值范围是0~100,值越大表示匿名页的比例越高,默认值是60。
可以通过文件”/proc/sys/vm/swappiness”配置换出匿名页的积极程度。 - 针对匿名页和文件页分别统计最近扫描的页数和从不活动变为活动的页数,计算比例(从不活动变为活动的页数 / 最近扫描的页数)。
如果匿名页的比例值比较大,说明匿名页的活动程度高,文件页的活动程度低,那么应该降低扫描的匿名页所占的比例,提高扫描的文件页所占的比例。
收缩活动页链表
当不活动页比较少的时候,页回收算法收缩活动页链表,也就是从活动页链表的尾部取物理页并转移到不活动页链表中,把活动页转换成不活动页。
函数shrink_active_list负责从活动页链表中转移物理页到不活动页链表中,有4个参数。
unsigned long nr_to_scan:指定扫描的页数。struct lruvec *lruvec:LRU向量的地址。struct scan_control *sc:扫描控制结构体。enum lru_list lru:LRU链表的索引,取值是LRU_ACTIVE_ANON(活动匿名页LRU链表)或LRU_ACTIVE_FILE(活动文件页LRU链表)。
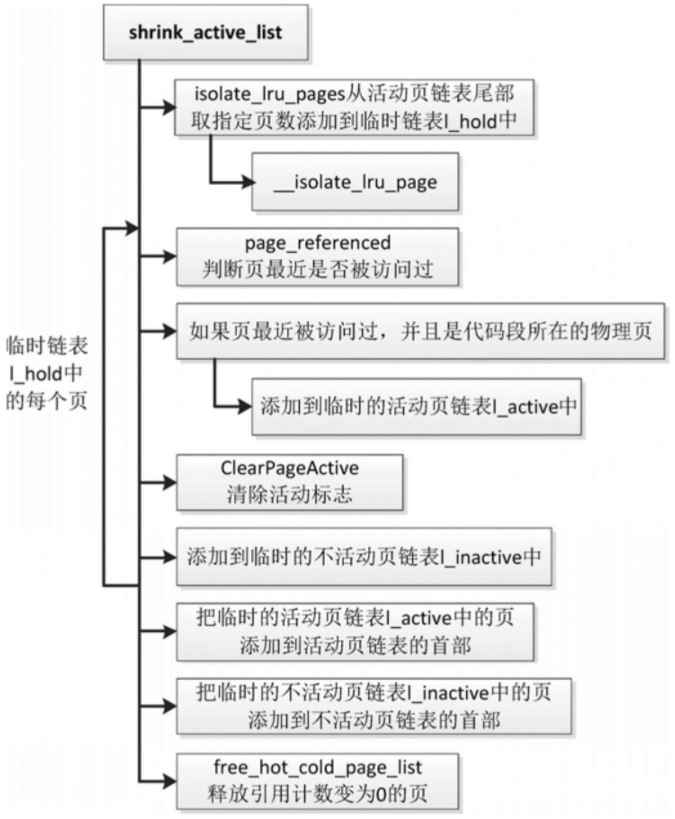
将活动页转换成不活动页的规则如下。
- 对有执行权限并且有存储设备支持的文件页(就是程序的代码段所在的物理页)做了特殊处理
如果页表项设置了访问标志位,那么保留在活动页链表中;如果页表项没有设置访问标志位,那么转移到不活动页链表中。 - 如果是匿名页或其他类型的文件页,转移到不活动页链表中。
回收不活动页
函数shrink_inactive_list负责回收不活动页,有4个参数。
unsigned long nr_to_scan:指定扫描的页数。struct lruvec *lruvec:LRU向量的地址。struct scan_control *sc:扫描控制结构体。enum lru_list lru:LRU链表的索引,取值是LRU_INACTIVE_ANON(不活动匿名页LRU链表)或LRU_INACTIVE_FILE(不活动文件页LRU链表)。
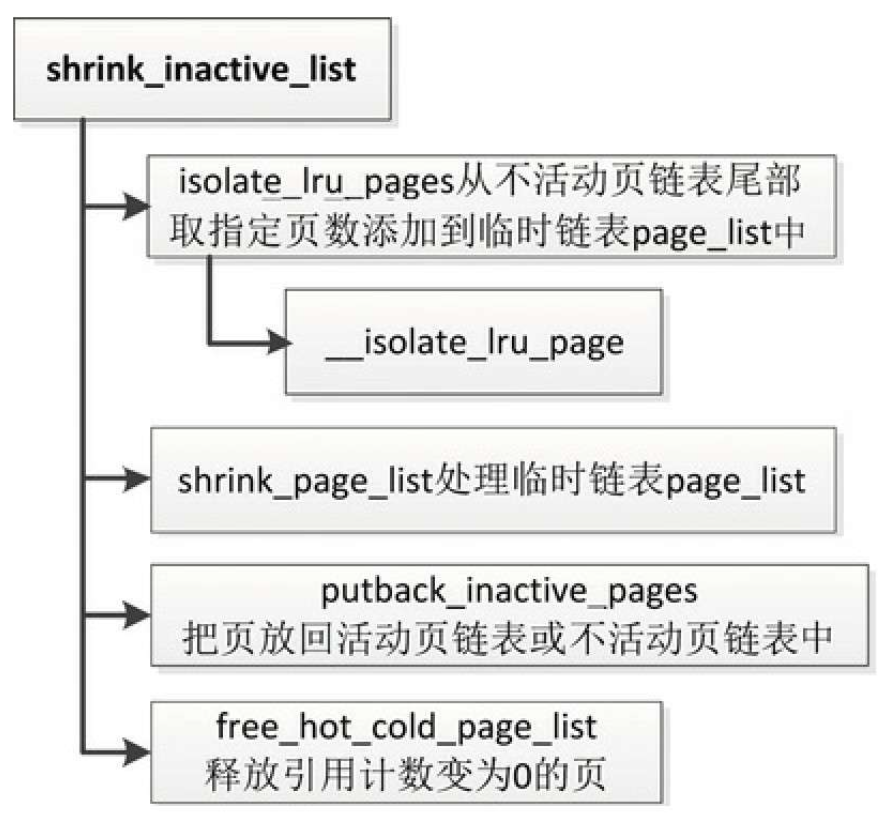
- 调用函数isolate_lru_pages,从不活动页链表的尾部取指定页数添加到临时链表page_list中。
- 调用函数shrink_page_list来处理临时链表page_list中的所有页。
- 有些不活动页可能被转换成活动页,有些不活动页可能保留在不活动页链表中,调用函数putback_inactive_pages,把这些不活动页放回到对应的链表中。
- 调用函数free_hot_cold_page_list释放引用计数变为0的页,作为缓存冷页释放。
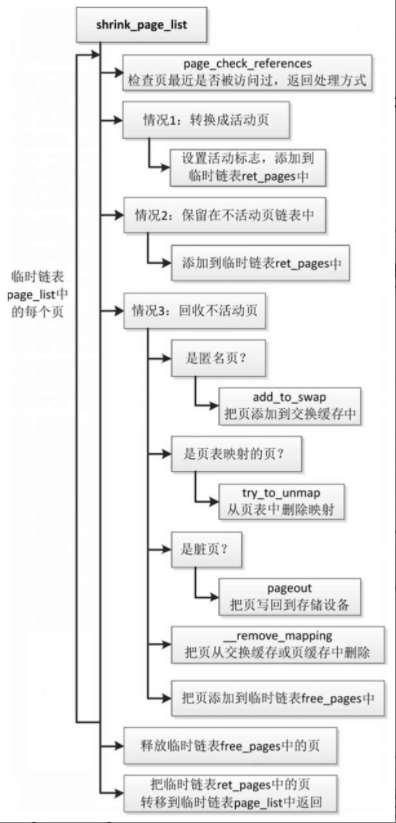
回收不活动页的主要工作是由函数shrink_page_list实现
页交换
页交换(swap)的原理是:当内存不足的时候,把最近很少访问的没有存储设备支持的物理页的数据暂时保存到交换区,释放内存空间,当交换区中存储的页被访问的时候,再把数据从交换区读到内存中。
交换区可以是一个磁盘分区,也可以是存储设备上的一个文件。
技术原理
数据结构
交换区首部:交换区的第一页是交换区首部,内核使用数据结构swap_header描述交换区首部

交换区信息:内核定义了交换区信息数组swap_info,每个数组项存储一个交换区的信息。
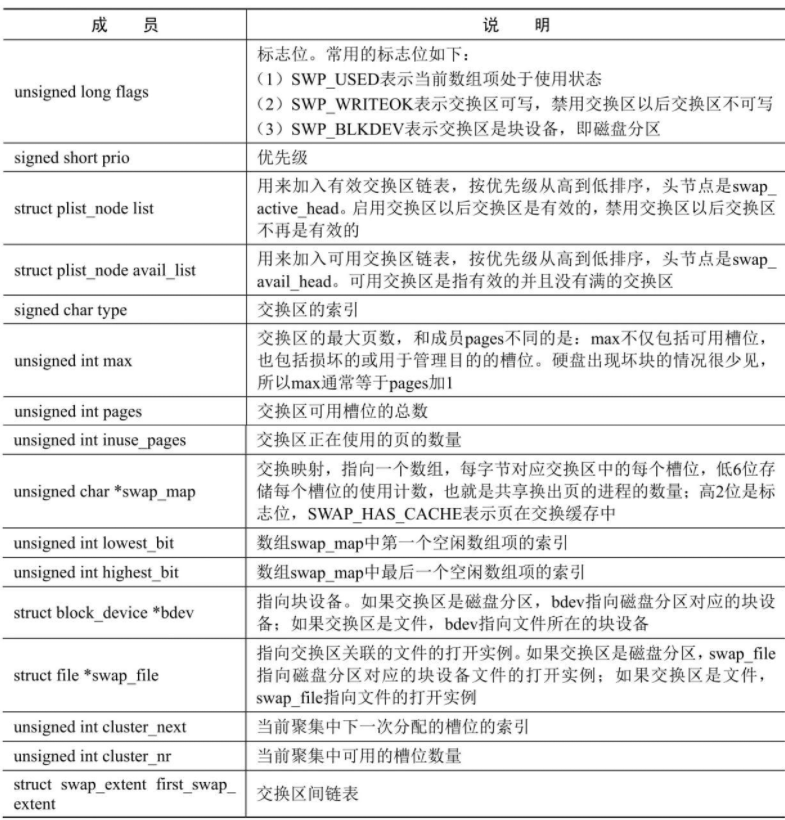
交换区间:用来把交换区的连续槽位映射到连续的磁盘块。
- 如果交换区是磁盘分区,因为磁盘分区的块是连续的,所以只需要一个交换区间。
- 如果交换区是文件,因为文件对应的磁盘块不一定是连续的,所以对于每个连续的磁盘块范围,需要使用一个交换区间来存储交换区的连续槽位和磁盘块范围的映射关系。
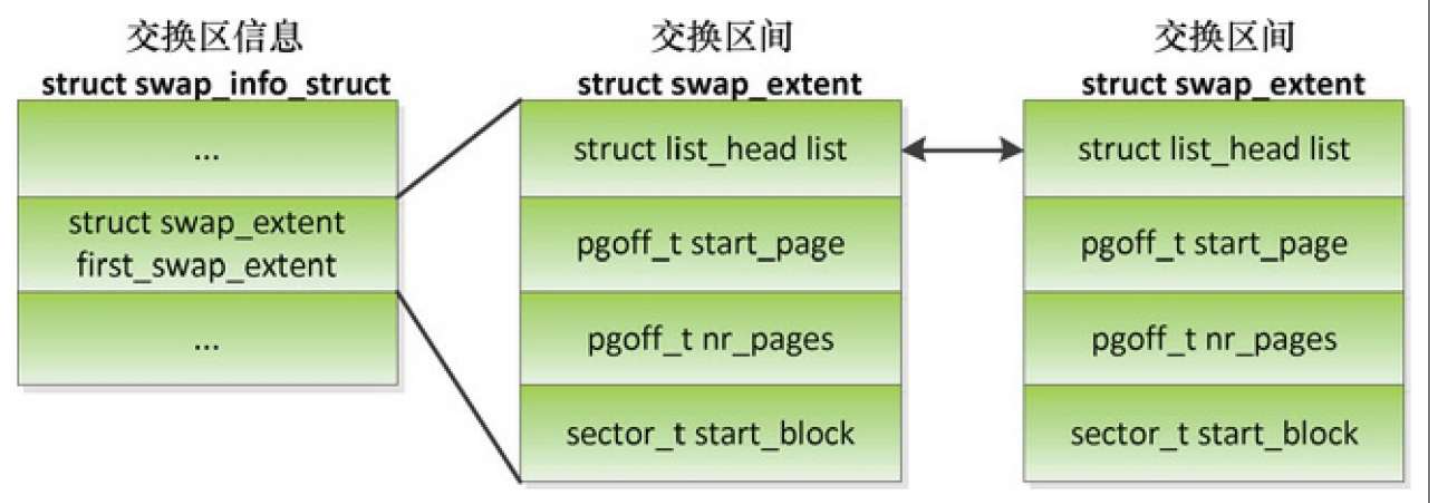
交换槽位缓存: 为了加快为换出页分配交换槽位的速度,每个处理器有一个交换槽位缓存swp_slots
为换出页分配交换槽位的时候,首先从当前处理器的交换槽位缓存分配,如果交换槽位缓存没有空闲槽位,那么从交换区分配槽位以重新填充交换槽位缓存。
交换项: 内核定义了数据类型swp_entry_t以存储换出页在交换区中的位置,我们称为交换项,高7位存储交换区的索引,其他位存储页在交换区中的偏移(单位是页)。
交换缓存, 为什么需要交换缓存?
换出页可能由多个进程共享,进程的页表项存储页在交换区中的位置。当某个进程访问页的数据时,把页从交换区换入内存中,把页表项指向内存页。
问题是:其他进程怎么找到内存页?
从交换区换入页的时候,把页放在交换缓存中,直到共享同一个页的所有进程请求换入页,知道这一页在内存中新的位置为止。如果没有交换缓存,内核无法确定一个共享的内存页是不是已经换入内存中。
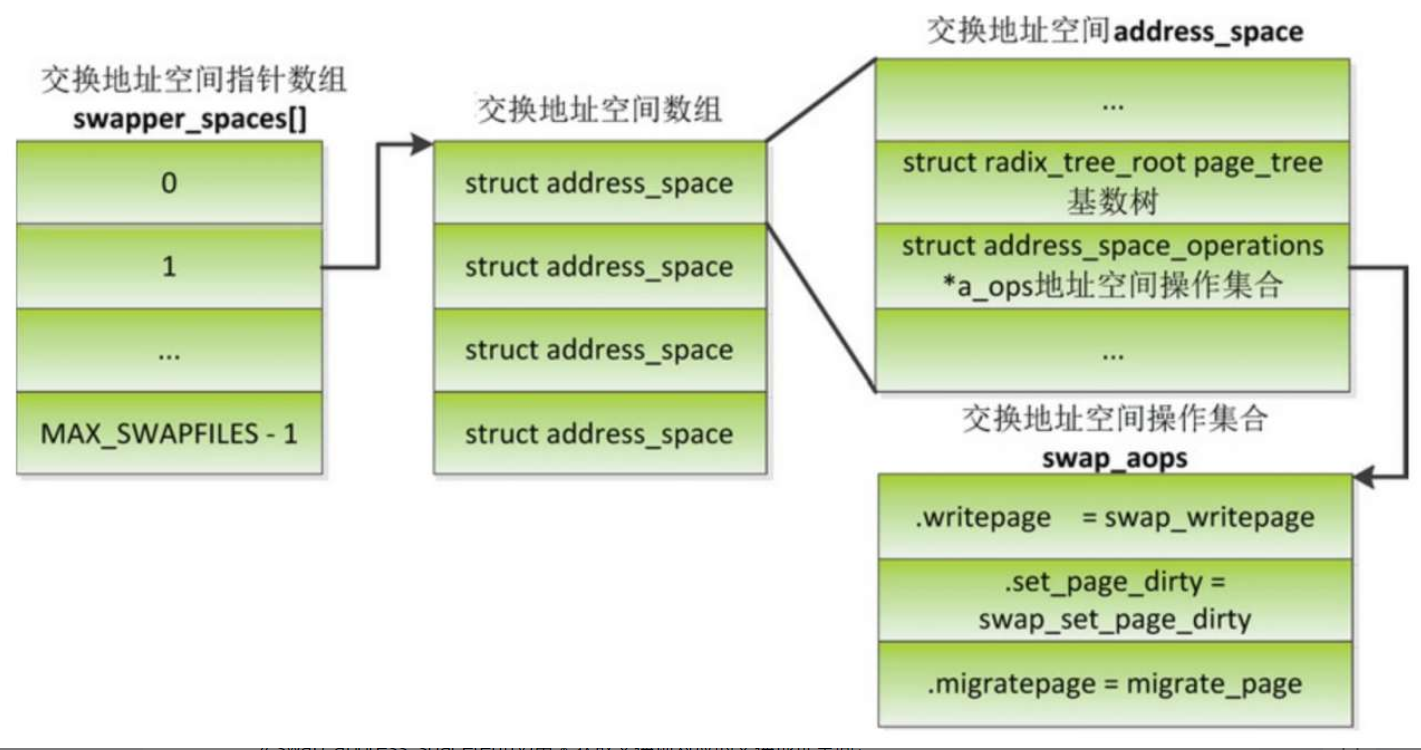
交换缓存是使用地址空间结构体address_space实现的,用来把交换区的槽位映射到内存页,全局数组swapper_spaces存储每个交换区的交换地址空间数组的地址,全局数组nr_swapper_spaces存储每个交换区的交换缓存数量。
回收匿名页
函数shrink_inactive_list回收不活动匿名页的执行流程
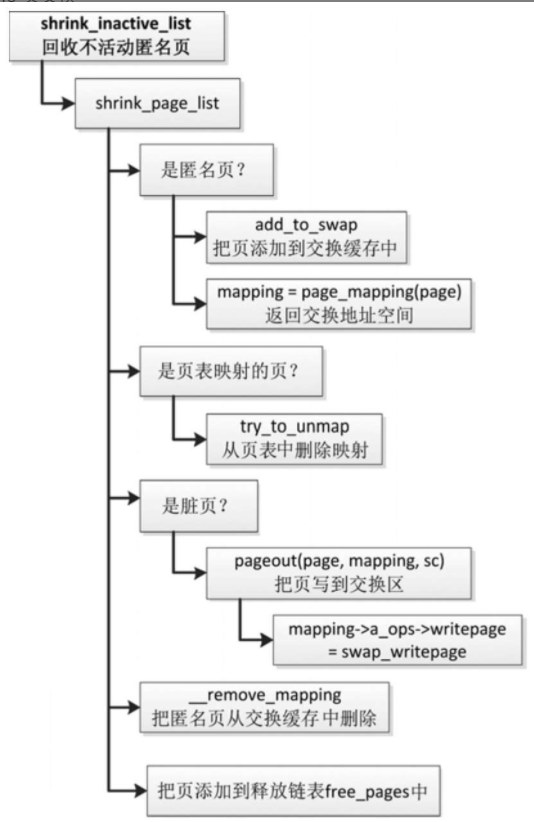
- 调用函数add_to_swap,从优先级最高的交换区分配交换槽位,把页加入交换缓存。
- 调用函数page_mapping,获取交换地址空间。
- 调用函数try_to_unmap,根据反向映射的数据结构找到物理页被映射到的所有虚拟页,针对每个虚拟页,执行操作:首先从进程的页表中删除旧的映射,如果页表项设置了脏标志位,那么把脏标志位转移到页描述符,然后在交换映射中把交换槽位的使用计数加1,最后在页表项中保存交换区的索引和偏移。
- 如果是脏页,那么调用函数pageout,把页回写到存储设备,函数pageout调用交换地址空间的writepage方法swap_writepage,把页写到交换区。
- 调用函数__remove_mapping,把匿名页从交换缓存中删除。
- 把页添加到释放链表free_pages中。函数add_to_swap的执行流程如下。
- 调用函数get_swap_page,从优先级最高的交换区分配一个槽位。2)如果是透明巨型页,拆分成普通页。
- 如果是透明巨型页,拆分成普通页。
- 调用函数add_to_swap_cache,把页添加到交换缓存中,给页描述符设置标志位PG_swapcache,表示页在交换缓存中,页描述符的成员private存储交换项。
换入匿名页
匿名页被换出到交换区以后,访问页时,生成页错误异常。
函数handle_pte_fault发现“页表项不是空表项,但是页不在内存中”,知道页已经被换出到交换区,调用函数do_swap_page以把页从交换区读到内存中。
函数do_swap_page的执行流程如下
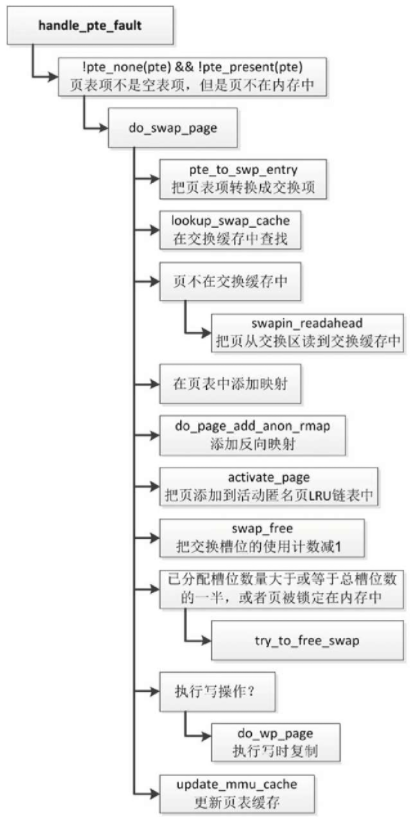
- 调用函数pte_to_swp_entry,把页表项转换成交换项,交换项包含了交换区的索引和偏移。
- 调用函数lookup_swap_cache,在交换缓存中根据交换区的偏移查找页。
- 如果页不在交换缓存中,那么调用函数swapin_readahead,把页从交换区读到交换缓存。
- 在页表中添加映射。
- 调用函数do_page_add_anon_rmap,添加反向映射。
- 调用函数activate_page,把页添加到活动匿名页LRU链表中。
- 调用函数swap_free,在交换映射中把交换槽位的使用计数减1。
- 如果已分配槽位数量大于或等于总槽位数的一半,或者页被锁定在内存中,那么调用函数try_to_free_swap,尝试释放交换槽位:如果交换槽位的使用计数是0,那么把页从交换缓存中删除,并且释放交换槽位。
- 如果执行写操作,那么调用函数do_wp_page以执行写时复制。10)调用函数update_mmu_cache,更新页表缓存。
回收slab缓存
使用slab缓存的内核模块可以注册收缩器,页回收算法遍历收缩器链表,调用每个收缩器来收缩slab缓存,释放对象。
编程接口
使用slab缓存的内核模块可以使用函数register_shrinker注册收缩器:
1 | int register_shrinker(struct shrinker *shrinker); |
使用函数unregister_shrinker注销收缩器
1 | void unregister_shrinker(struct shrinker *shrinker); |
数据结构
收缩器的数据结构

- 方法count_objects:返回可释放对象的数量。
- 方法scan_objects:释放对象,返回释放的对象数量。如果返回SHRINK_STOP,表示停止扫描。
- 成员seeks:控制扫描的对象数量的因子,扫描的对象数量和这个因子成反比,即因子越大,扫描的对象越少。如果使用者不知道合适的数值,可以设置为宏DEFAULT_SEEKS,值为2。
- 成员batch:批量释放的数量,如果为0,使用默认值128。
- 成员fags:标志位,目前定义了两个标志位,SHRINKER_NUMA_AWARE表示感知NUMA内存节点,SHRINKER_MEMCG_AWARE表示感知内存控制组。
- 成员list:内部使用的成员,用来把收缩器添加到收缩器链表中。
- 成员nr_deferred:内部使用的成员,记录每个内存节点延迟到下一次扫描的对象数量。
方法scan_objects的第二个参数sc用来传递控制信息

- 成员gfp_mask:分配掩码。
- 成员nr_to_scan:应该扫描的对象数量。
- 成员nid:对于感知NUMA内存节点的收缩器,需要知道当前正在回收的内存节点的编号。
- 成员memcg:对于感知内存控制组的收缩器,需要知道正在回收的内存控制组。
技术原理
函数shrink_slab遍历收缩器链表shrinker_list,针对每个收缩器,把主要工作委托给函数do_shrink_slab。
内存耗尽杀手
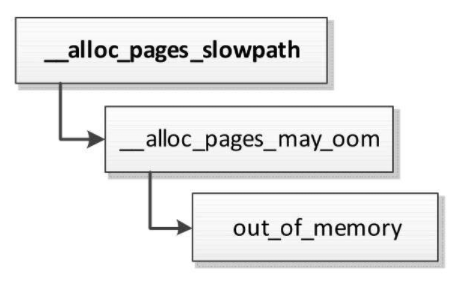
当内存严重不足的时候,页分配器在多次尝试直接页回收失败以后,就会调用内存耗尽杀手(OOM killer, OOM是“Out of Memory”的缩写),选择进程杀死,释放内存。
使用方法
/proc/sys/vm/oom_kill_allocating_task:是否允许杀死正在申请分配内存并触发内存耗尽的进程,避免扫描进程链表选择进程,非零值表示允许,0表示禁止,默认禁止。/proc/sys/vm/oom_dump_tasks:是否允许内存耗尽杀手杀死进程的时候打印所有用户进程的内存使用信息,非零值表示允许,0表示禁止,默认允许。/proc/sys/vm/panic_on_oom:是否允许在内存耗尽的时候内核恐慌(panic),重启系统。0表示禁止内核恐慌;1表示允许内核恐慌,但是如果进程通过内存策略或cpuset限制了允许使用的内存节点,这些内存节点耗尽内存,不需要重启系统,可以杀死进程,因为其他内存节点可能有空闲的内存;2表示强制执行内核恐慌。默认值是0。如果把参数panic_on_oom设置成非零值,优先级比参数oom_kill_allocating_task高。
内存耗尽杀手计算进程的坏蛋分数(badness score),选择坏蛋分数最高的进程,坏蛋分数的范围是0~1000,0表示不杀死,1000表示总是杀死。
- 管理员可以通过文件
/proc/<pid>/oom_score_adj为指定进程设置分数调整值,取值范围是−1000~1000,值越大导致坏蛋分数越高,分数调整值−1000将会导致坏蛋分数是0,表示禁止杀死本进程。 - 可以通过文件
/proc/<pid>/oom_score查看指定进程的坏蛋分数。
技术原理
内存耗尽杀手分为全局的内存耗尽杀手和内存控制组的内存耗尽杀手。
内存控制组的内存耗尽杀手是指内存控制组的内存使用量超过硬限制的时候,从内存控制组选择进程杀死,
全局的内存耗尽杀手是指内存严重不足的时候,从整个系统选择进程杀死。
这里只介绍全局的内存耗尽杀手。
内存耗尽杀手的核心函数是out_of_memory,执行流程如图
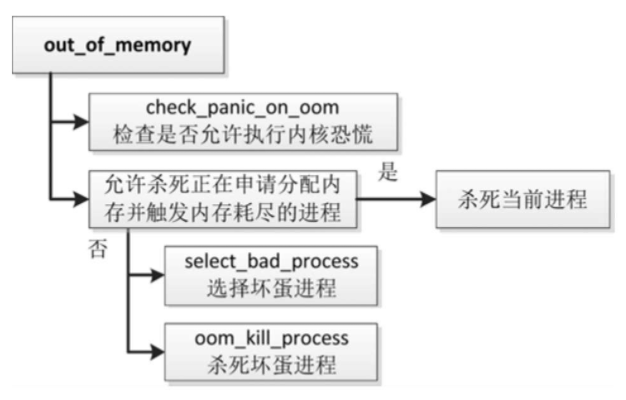
- 调用函数check_panic_on_oom,检查是否允许执行内核恐慌,如果允许,那么重启系统。
- 如果允许杀死正在申请分配内存并触发内存耗尽的进程,那么杀死当前进程。
- 调用函数select_bad_process,选择坏蛋进程。
- 调用函数oom_kill_process,杀死坏蛋进程。
函数select_bad_process负责选择坏蛋进程,遍历进程链表,调用函数oom_evaluate_task计算进程的坏蛋分数,选择坏蛋分数最高的进程。
- 函数oom_badness负责计算进程的坏蛋分数,坏蛋分数的范围是0~1000,0表示不杀死,1000表示总是杀死
函数oom_kill_process负责杀死坏蛋进程,执行流程如下。
- 如果被选中的进程有子进程,那么从所有子进程中选择坏蛋分数最高的子进程代替父进程牺牲,试图使丢失的工作数量最小化。
假设有一个服务器进程,每当一个客户端连接进来,创建一个子进程负责和特定的客户端通信。如果杀死服务器进程,将会导致客户端无法连接进来;如果杀死一个子进程,只影响一个客户端,影响面小。
- 向被选中的进程发送杀死信号SIGKILL。
内存资源控制器
控制组(cgroup)的内存资源控制器用来控制一组进程的内存使用量,启用内存资源控制器的控制组简称内存控制组(memcg)。控制组把各种资源控制器称为子系统,内存资源控制器也称为内存子系统。
使用方法
编译内核时需要开启以下配置宏
- 控制组的配置宏CONFIG_CGROUPS。
- 内存资源控制器的配置宏CONFIG_MEMCG。
可选的配置宏如下
- 内存资源控制器交换扩展(也称为交换控制器)的配置宏
CONFIG_MEMCG_SWAP,控制进程使用的交换区的大小,依赖配置宏CONFIG_MEMCG和页交换的配置宏CONFIG_SWAP。 - 配置宏
CONFIG_MEMCG_SWAP_ENABLED控制是否默认开启交换控制器,默认开启,依赖配置宏CONFIG_MEMCG_SWAP。可以在引导内核时通过内核参数swapaccount=指定是否开启交换控制器,参数值为1表示开启,参数值为0表示关闭。
控制组已经从版本1(cgroup v1)演进到版本2(cgroup v2),主要的改进如下。
- 版本1可以创建多个层级树,版本2只有一个统一的层级树。
- 在版本2中,进程只能加入作为叶子节点的控制组(即没有子控制组),根控制组是个例外(进程默认属于根控制组)。
控制组版本1可以创建多个控制组层级树,但是每种资源控制器只能关联一个控制组层级树,内存资源控制器只能关联一个控制组层级树。
控制组版本1和版本2的内存资源控制器是互斥的:如果使用了控制组版本1的内存资源控制器,就不能使用控制组版本2的内存资源控制器;
同样,如果使用了控制组版本2的内存资源控制器,就不能使用控制组版本1的内存资源控制器。
控制组版本1的内存资源控制器
- memory.use_hierarchy:启用分层记账,默认禁止。内存控制组启用分层记账以后,子树中的所有内存控制组的内存使用都会被记账到这个内存控制组。
- memory.limit_in_bytes:设置或查看内存使用的限制(硬限制),默认值是“max”。
- memory.soft_limit_in_bytes:设置或查看内存使用的软限制,默认值是“max”。软限制和硬限制的区别是:内存使用量可以超过软限制,但是不能超过硬限制,页回收算法会优先从内存使用量超过软限制的内存控制组回收内存。
- memory.memsw.limit_in_bytes:设置或查看内存+交换区的使用限制,默认值是“max”。
- memory.swappiness:设置或查看交换积极程度。
- memory.oom_control:控制是否禁止内存耗尽杀手,1表示禁止,0表示启用,默认启用内存耗尽杀手。
- memory.stat:查看内存使用的各种统计值。
- memory.usage_in_bytes:查看当前内存使用量。
- memory.memsw.usage_in_bytes:查看当前内存+交换区的使用量。
- memory.max_usage_in_bytes:查看记录的最大内存使用量。
- memory.memsw.max_usage_in_bytes:查看记录的最大内存+交换区使用量。
- memory.failcnt:查看内存使用量命中限制的次数。
- memory.memsw.failcnt:查看内存+交换区的使用量命中限制的次数。
- memory.kmem.limit_in_bytes:设置或查看内核内存的使用限制。
- memory.kmem.usage_in_bytes:查看当前内核内存使用量。
- memory.kmem.failcnt:查看内核内存使用量命中限制的次数。
- memory.kmem.max_usage_in_bytes:查看记录的最大内核内存使用量。
- memory.kmem.tcp.limit_in_bytes:设置或查看TCP缓冲区的内存使用限制。
- memory.kmem.tcp.usage_in_bytes:查看当前TCP缓冲区的内存使用量。
- memory.kmem.tcp.failcnt:查看TCP缓冲区内存使用量命中限制的次数。
- memory.kmem.tcp.max_usage_in_bytes:查看记录的最大TCP缓冲区内存使用量。
控制组版本2的内存资源控制器
- memory.low:内存使用低界限,默认值是0。用来保护一个控制组可以分配到指定数量的内存,这种保护只能尽力而为,没有绝对的保证。如果一个控制组和所有祖先的内存使用量在低界限以下,并且可以从其他不受保护的控制组回收内存,那么这个控制组的内存不会被回收。
- memory.high:内存使用高界限,内存使用节流(throttle)限制,默认值是“max”。这是控制内存使用的主要机制。如果一个控制组的内存使用量超过高界限,那么这个控制组里面的所有进程将会被节流,从这个控制组回收内存。
- memory.max:内存使用硬限制,默认值是“max”。如果一个控制组的内存使用量达到硬限制,将会在这个控制组中调用内存耗尽杀手选择进程杀死。
- memory.current:查看控制组和所有子孙的当前内存使用量。
- memory.stat:查看内存使用的各种统计值。
- memory.swap.max:交换区使用硬限制,默认值是“max”。如果一个控制组的交换区使用量达到硬限制,那么不会换出这个控制组的匿名页。
- memory.swap.current:查看控制组和所有子孙的当前交换区使用量
根控制组对资源使用量没有限制,并且不允许在根控制组配置资源使用限制,进程默认属于根控制组。创建子进程的时候,子进程继承父进程加入的控制组。
控制组版本1和版本2的内存资源控制器的区别如下
- 控制组版本1的内存资源控制器默认禁止分层记账方式,可以配置;控制组版本2的内存资源控制器总是使用分层记账方式,不可配置。
- 对交换区的记账方式不同:控制组版本1使用内存+交换区记账方式,即记录内存使用量和交换区使用量的总和;控制组版本2对交换区单独记账。
- 控制组版本1的内存资源控制器默认启用内存耗尽杀手,可以配置;控制组版本2的内存资源控制器总是启用内存耗尽杀手,不可配置。
技术原理
数据结构
内存资源控制器的数据结构是结构体mem_cgroup
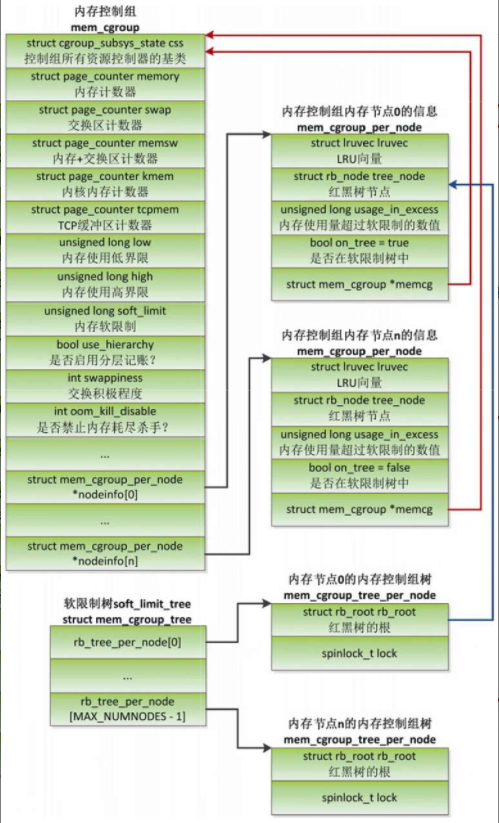
- 成员css:结构体cgroup_subsys_state是所有资源控制器的基类,结构体mem_cgroup是它的一个派生类。
- 成员memory:内存计数器,记录内存的限制和当前使用量。
- 成员swap:(控制组版本2的)交换区计数器,记录交换区的限制和当前使用量。
- 成员memsw:(控制组版本1的)内存+交换区计数器,记录内存+交换区的限制和当前使用量。
- 成员kmem:(控制组版本1的)内核内存计数器,记录内核内存的限制和当前使用量。
- 成员tcpmem:(控制组版本1的)TCP套接字缓冲区计数器,记录TCP套接字缓冲区的限制和当前使用量
- 成员low:(控制组版本2的)内存使用低界限。
- 成员high:(控制组版本2的)内存使用高界限
- 成员soft_limit:(控制组版本1的)内存使用的软限制。
- 成员use_hierarchy:控制是否启用分层记账。
- 成员swappiness:控制交换的积极程度。
- 成员oom_kill_disable:控制是否禁止内存耗尽杀手。
- 成员nodeinfo:每个内存节点对应一个mem_cgroup_per_node实例,存放内存控制组在每个内存节点上的信息。
进程怎么知道它属于哪个内存控制组?
给定一个进程,得到进程所属的内存控制组的方法如下
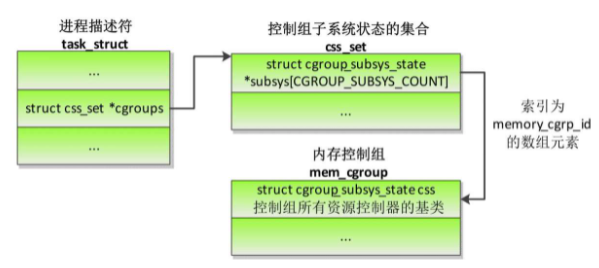
- 根据进程描述符的成员cgroups得到结构体css_set,结构体css_set是控制组子系统状态的集合。
- 根据css_set.subsys[memory_cgrp_id]得到内存控制组的第一个成员css的地址。结构体css_set的成员subsys指向每种资源控制器的结构体cgroup_subsys_state,其中索引为memory_cgrp_id(枚举常量)的数组元素指向内存控制组的第一个成员css。
- 如果css_set.subsys[memory_cgrp_id]是空指针,说明进程没有加入内存控制组,默认属于根内存控制组,全局变量root_mem_cgroup指向根内存控制组。
- 如果css_set.subsys[memory_cgrp_id]不是空指针,把地址减去结构体mem_cgroup中成员css的偏移,就是内存控制组的地址。
内存描述符怎么知道它属于哪个内存控制组?
内存描述符的成员owner指向进程描述符。
如果进程属于线程组,那么成员owner指向线程组组长的进程描述符。
1 | struct mm_struct{ |
怎么知道物理页属于哪个内存控制组?
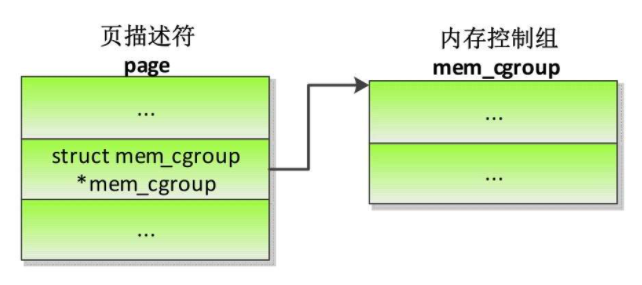
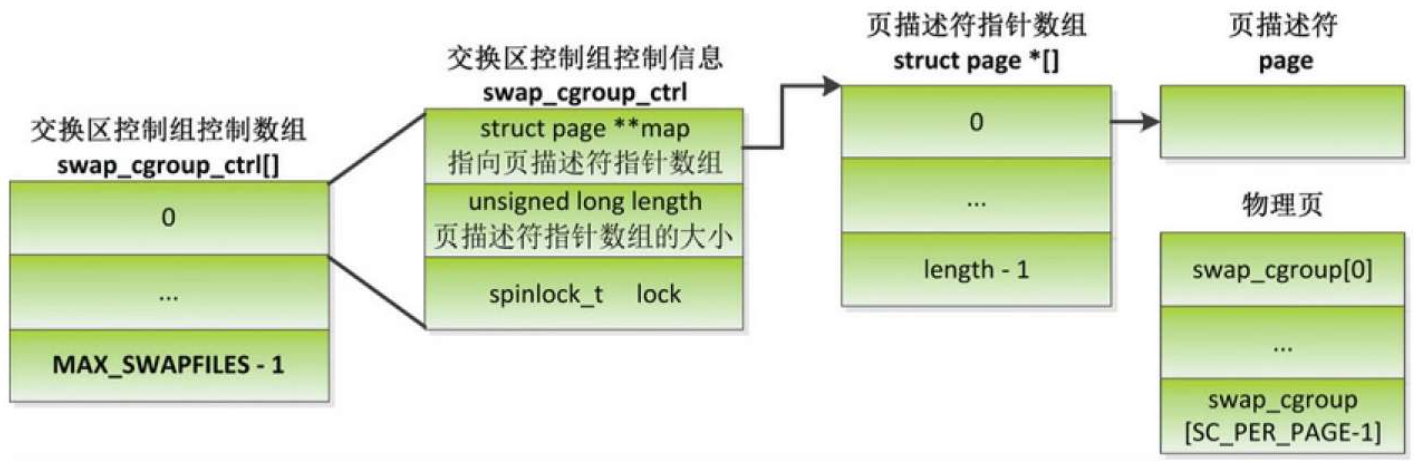
为什么换入页时要使用换出时页所属的内存控制组?
假设进程1和进程2共享一个交换支持的页,把进程1加入内存控制组cg1,进程2属于内存控制组cg2。
假设物理页是由进程1申请分配的,所以页属于内存控制组cg1。
把页换出到交换区的时候,把内存控制组cg1的交换区使用量加1,把内存使用量减1。
假设在换出页以后进程2先访问页,把页从交换区换入。
如果使用进程2所属的内存控制组,那么页属于内存控制组cg2,把内存控制组cg2的内存使用量加1。
释放交换槽位的时候,把内存控制组cg2的交换区使用量减1,这就出现问题了:“换出页时把内存控制组cg1的交换区使用量加1,换入页以后,释放交换槽位的时候,把内存控制组cg2的交换区使用量减1。”
所以在换入页时要使用换出时页所属的内存控制组,换出时需要保存交换槽位到页所属的内存控制组的映射关系。
处理器缓存
现代处理器一纳秒可以执行几十条指令,但是需要几十纳秒才能从物理内存取出一个数据,速度差距超过两个数量级别,导致处理器花费很长时间等待从内存读取数据。为了解决处理器执行速度和内存访问速度不匹配的问题,在处理器和内存之间增加了缓存。缓存和内存的区别如下。
- 缓存是静态随机访问存储器(Static Random Access Memory, SRAM),访问速度接近于处理器的速度,但是集成度低,和内存相比,在容量相同的情况下体积大,并且价格昂贵。
- 内存是动态随机访问存储器(Dynamic Random Access Memory, DRAM),访问速度慢,但是集成度高,和缓存相比,在容量相同的情况下体积小。
通常使用多级缓存,一级缓存集成在处理器内部,离处理器最近,容量小,访问时间是1个时钟周期。二级缓存可能在处理器内部或外部,容量更大,访问时间是大约10个时钟周期。有些高端处理器有三级甚至四级缓存。在SMP系统中,处理器的每个核有独立的一级缓存,所有核共享二级缓存。
为了支持同时取指令和取数据,一级缓存分为一级指令缓存(i-cache, instruction cache)和一级数据数据(d-cache, data cache)。二级缓存是指令和数据共享的统一缓存(unified cache)。
缓存结构
缓存策略
缓存维护
SMP缓存一致性
利用缓存提高性能的编程技巧
连续内存分配器
在系统长时间运行后,内存可能碎片化,很难找到连续的物理页,连续内存分配器(ContiguousMemory Allocator, CMA)使得这种情况下分配大的连续内存块成为可能。
嵌入式系统中的许多设备不支持分散聚集和I/O映射,需要连续的大内存块。
1 | 例如手机上1300万像素的摄像头,一个像素占用3字节,拍摄一张照片需要大约37MB内存。 |
一种解决方案是为设备保留一块大的内存区域
缺点是:当设备驱动不使用的时候(大多数时间手机摄像头是空闲的),内核的其他模块不能使用这块内存。
连续内存分配器试图解决这个问题,保留一块大的内存区域,当设备驱动不使用的时候,内核的其他模块可以使用
当然有要求:只有申请可移动类型的页时可以借用;当设备驱动需要使用的时候,把已经分配的页迁移到其他地方,形成物理地址连续的大内存块。
技术原理
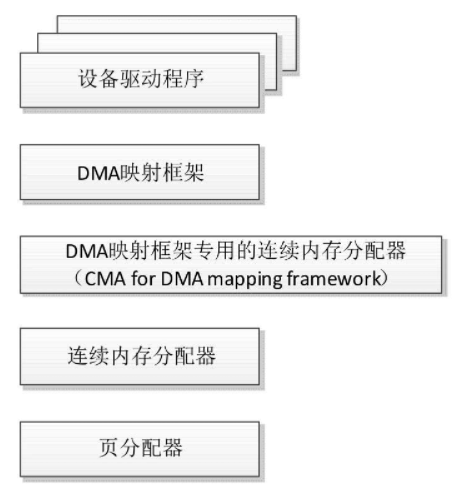
连续内存分配器是DMA映射框架的辅助框架,设备驱动程序不能直接使用连续内存分配器
- 连续内存分配器是在页分配器的基础上实现的,提供的接口cma_alloc用来从CMA区域分配页,接口cma_release用来释放从CMA区域分配的页。
- 在连续内存分配器的基础上实现了DMA映射框架专用的连续内存分配器,简称DMA专用连续内存分配器,提供的接口dma_alloc_from_contiguous用来从CMA区域分配页,接口dma_release_from_contiguous用来释放从CMA区域分配的页。
- DMA映射框架从DMA专用连续内存分配器分配或释放页,为设备驱动程序提供的接口dma_alloc_coherent和dma_alloc_noncoherent用来分配内存,接口dma_free_coherent和dma_free_noncoherent用来释放内存。
- 设备驱动程序调用DMA映射框架提供的函数来分配或释放内存。
国内查看评论需要代理~