进程
Linux内核把进程称为任务(task),进程的虚拟地址空间分为用户虚拟地址空间和内核虚拟地址空间,所有进程共享内核虚拟地址空间,每个进程有独立的用户虚拟地址空间。
进程有两种特殊形式:没有用户虚拟地址空间的进程称为内核线程,共享用户虚拟地址空间的进程称为用户线程,通常在不会引起混淆的情况下把用户线程简称为线程。共享同一个用户虚拟地址空间的所有用户线程组成一个线程组。
C标准库的进程术语和Linux内核的进程术语的对应关系如表

结构体task_struct是进程描述符
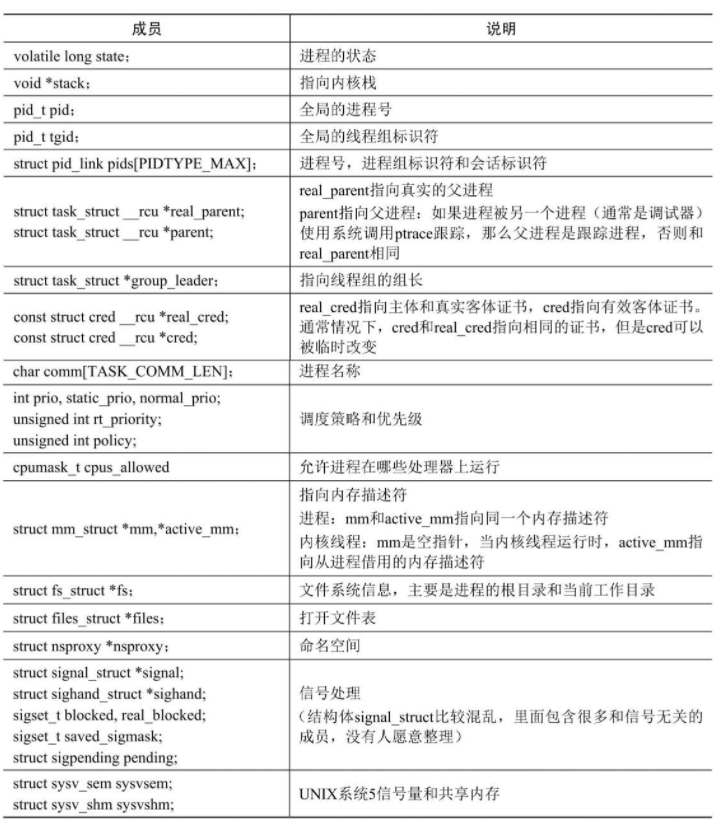
命名空间
和虚拟机相比,容器是一种轻量级的虚拟化技术,直接使用宿主机的内核,使用命名空间隔离资源。
Linux内核提供的命名空间如表
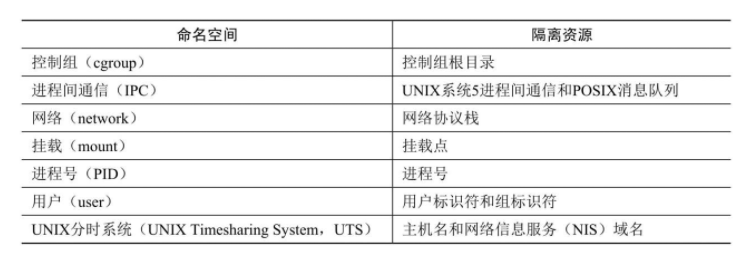
可以使用以下两种方法创建新的命名空间。
- 调用clone创建子进程时,使用标志位控制子进程是共享父进程的命名空间还是创建新的命名空间。
- 调用unshare创建新的命名空间,不和已存在的任何其他进程共享命名空间。
进程也可以使用系统调用setns,绑定到一个已经存在的命名空间。
1 | 进程描述符的成员“nsproxy”指向一个命名空间代理,命名空间代理包含除了用户以外的所有其他命名空间的地址。 |
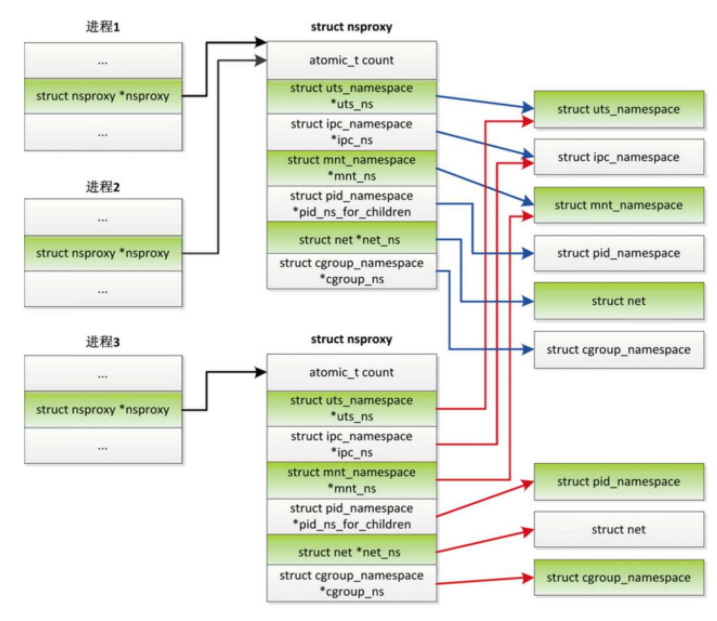
进程号命名空间用来隔离进程号,对应的结构体是pid_namespace。
每个进程号命名空间独立分配进程号。
进程号命名空间按层次组织成一棵树,初始进程号命名空间是树的根,对应全局变量init_pid_ns,所有进程默认属于初始进程号命名空间。
创建进程时,从进程所属的进程号命名空间到初始进程号命名空间都会分配进程号。
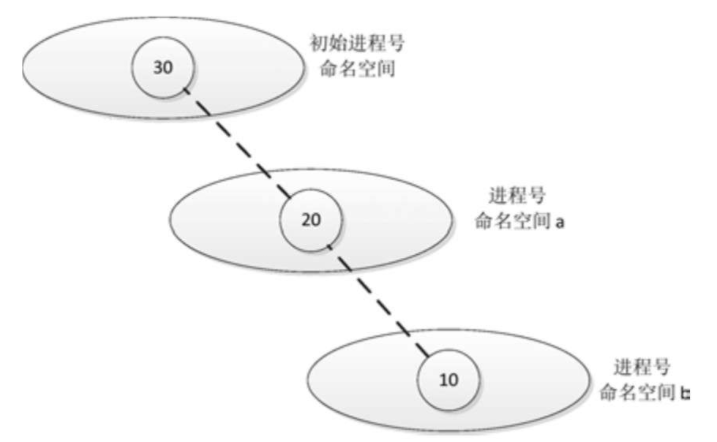
如图所示,假设某个进程属于进程号命名空间b, b的父命名空间是a, a的父命名空间是初始进程号命名空间,从b到初始的每一级命名空间依次分配进程号10、20和30。
进程标识符
进程有以下标识符。
- 进程标识符:进程所属的进程号命名空间到根的每层命名空间,都会给进程分配一个标识符。
- 线程组标识符:多个共享用户虚拟地址空间的进程组成一个线程组,线程组中的主进程称为组长,线程组标识符就是组长的进程标识符。当调用系统调用clone传入标志CLONE_THREAD以创建新进程时,新进程和当前进程属于一个线程组。进程描述符的成员tgid存放线程组标识符,成员group_leader指向组长的进程描述符。
- 进程组标识符:多个进程可以组成一个进程组,进程组标识符是组长的进程标识符。进程可以使用系统调用setpgid创建或者加入一个进程组。会话和进程组被设计用来支持shell作业控制,shell为执行单一命令或者管道的进程创建一个进程组。进程组简化了向进程组的所有成员发送信号的操作。
- 会话标识符:多个进程组可以组成一个会话。当进程调用系统调用setsid的时候,创建一个新的会话,会话标识符是该进程的进程标识符。创建会话的进程是会话的首进程。
1
2
3Linux是多用户操作系统,用户登录时会创建一个会话,用户启动的所有进程都属于这个会话。
登录shell是会话首进程,它所使用的终端就是会话的控制终端,会话首进程通常也被称为控制进程。
当用户退出登录时,所有属于这个会话的进程都将被终止。
假设某个进程属于进程号命名空间b, b的父命名空间是a, a的父命名空间是初始进程号命名空间,从b到初始的每一级命名空间分配的进程号依次是10、20和30。
进程标识符数据结构如图
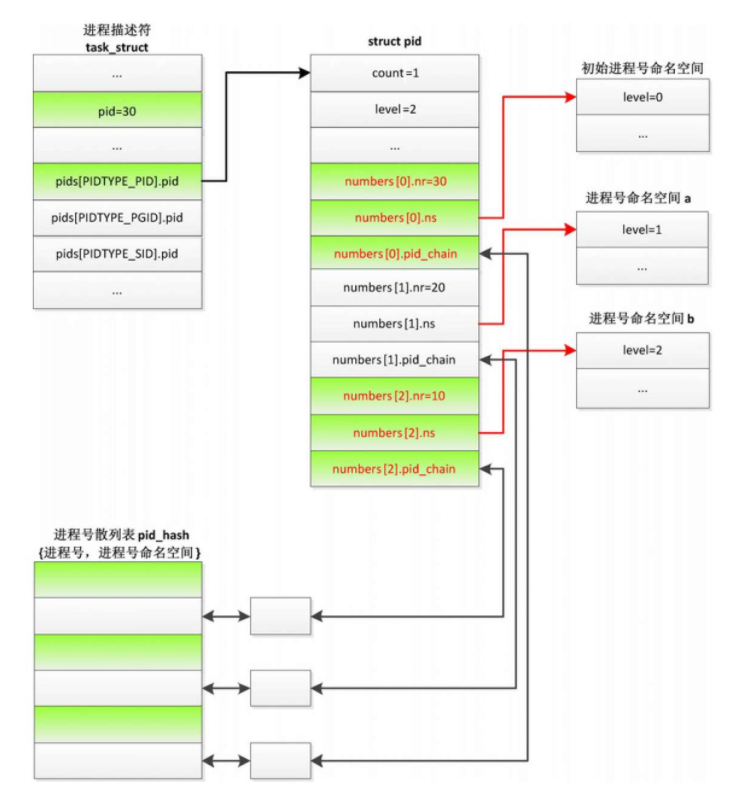
- 成员pid存储全局进程号,即初始进程号命名空间分配的进程号30。
- 成员pids[PIDTYPE_PID].pid指向结构体pid,存放3个命名空间分配的进程号。
- 成员pids[PIDTYPE_PGID].pid指向进程组组长的结构体pid(限于篇幅,图中没画出)。
- 成员pids[PIDTYPE_SID].pid指向会话首进程的结构体pid(限于篇幅,图中没画出)。
进程标识符结构体pid的成员如下
- 成员count是引用计数。
- 成员level是进程所属的进程号命名空间的层次。
- 数组numbers的元素个数是成员level的值加上1,3个元素依次存放初始命名空间、a和b三个命名空间分配的进程号。numbers[i].nr是进程号命名空间分配的进程号,numbers[i].ns指向进程号命名空间的结构体pid_namespace, numbers[i].pid_chain用来把进程加入进程号散列表pid_hash,根据进程号和命名空间计算散列值。
进程关系
进程1分叉生成进程2,进程1称为父进程,进程2称为子进程。进程1多次分叉生成进程2和进程3,进程2和进程3的关系是兄弟关系。
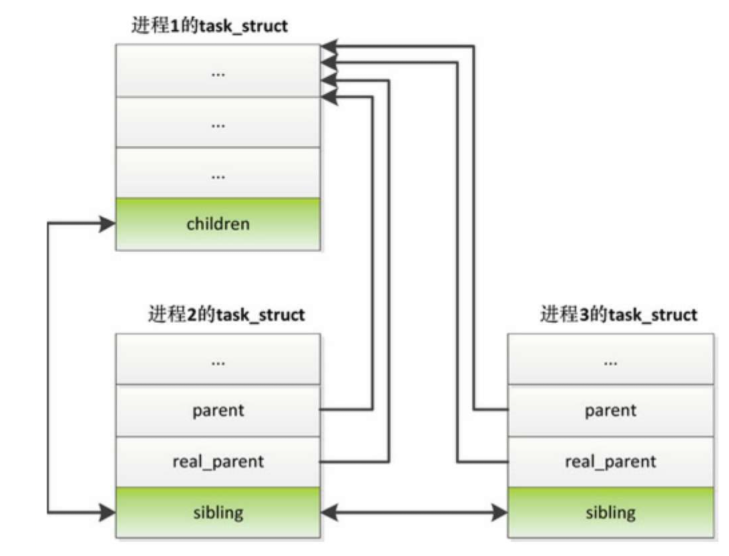
如图所示,一个进程的所有子进程被链接在一条子进程链表上,头节点是父进程的成员children,链表节点是子进程的成员sibling。
子进程的成员real_parent指向父进程的进程描述符,成员parent用来干什么呢?
如果子进程被某个进程(通常是调试器)使用系统调用ptrace跟踪,那么成员parent指向跟踪者的进程描述符,否则成员parent也指向父进程的进程描述符。
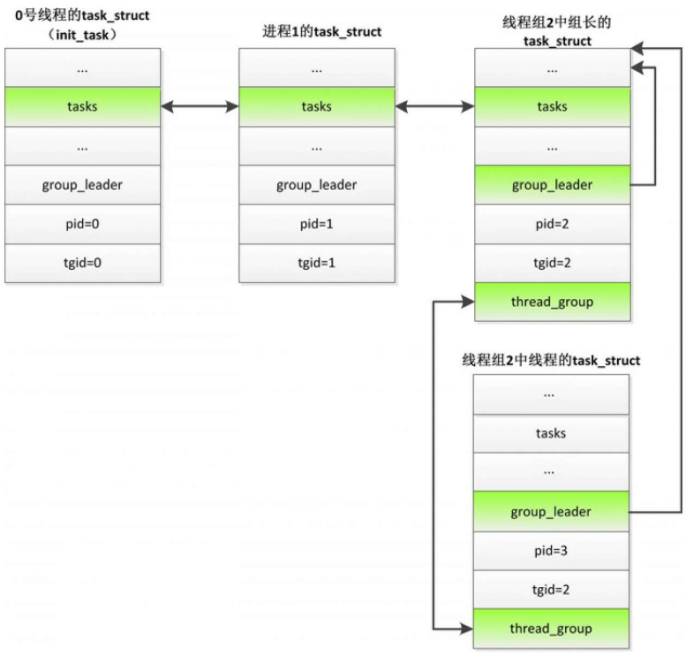
如图所示,进程管理子系统把所有进程链接在一条进程链表上,头节点是0号线程的成员tasks,链表节点是每个进程的成员tasks。
对于线程组,只把组长加入进程链表。
一个线程组的所有线程链接在一条线程链表上,头节点是组长的成员thread_group,链表节点是线程的成员thread_group。
线程的成员group_leader指向组长的进程描述符,成员tgid是线程组标识符,成员pid存放自己的进程标识符。
启动程序
当我们在shell进程里面执行命令/sbin/hello.elf &以启动程序hello时,shell进程首先创建子进程,然后子进程装载程序hello.elf

下面描述创建新进程和装载程序的过程
创建新进程
在Linux内核中,新进程是从一个已经存在的进程复制出来的。内核使用静态数据构造出0号内核线程,0号内核线程分叉生成1号内核线程和2号内核线程(kthreadd线程)。1号内核线程完成初始化以后装载用户程序,变成1号进程,其他进程都是1号进程或者它的子孙进程分叉生成的;其他内核线程是kthreadd线程分叉生成的。
3个系统调用可以用来创建新的进程
- fork(分叉):子进程是父进程的一个副本,采用了写时复制的技术。
- vfork:用于创建子进程,之后子进程立即调用execve以装载新程序的情况。为了避免复制物理页,父进程会睡眠等待子进程装载新程序。现在fork采用了写时复制的技术,vfork失去了速度优势,已经被废弃。
- clone(克隆):可以精确地控制子进程和父进程共享哪些资源。这个系统调用的主要用处是可供pthread库用来创建线程。
clone是功能最齐全的函数,参数多,使用复杂,fork是clone的简化函数。
系统调用1
SYSCALL_DEFINE0(fork)
把宏展开以后是1
asmlinkage long sys_fork(void)
1 | “SYSCALL_DEFINE”后面的数字表示系统调用的参数个数,“SYSCALL_DEFINE0”表示系统调用没有参数,“SYSCALL_DEFINE6”表示系统调用有6个参数,如果参数超过6个,使用宏“SYSCALL_DEFINEx”。 |
创建新进程的进程p和生成的新进程的关系有3种情况。
- 新进程是进程p的子进程。
- 如果clone传入标志位CLONE_PARENT,那么新进程和进程p拥有同一个父进程,是兄弟关系。
- 如果clone传入标志位CLONE_THREAD,那么新进程和进程p属于同一个线程组。
创建新进程的3个系统调用在文件“kernel/fork.c”中,它们把工作委托给函数_do_fork。
函数_do_fork
函数_do_fork的执行流程
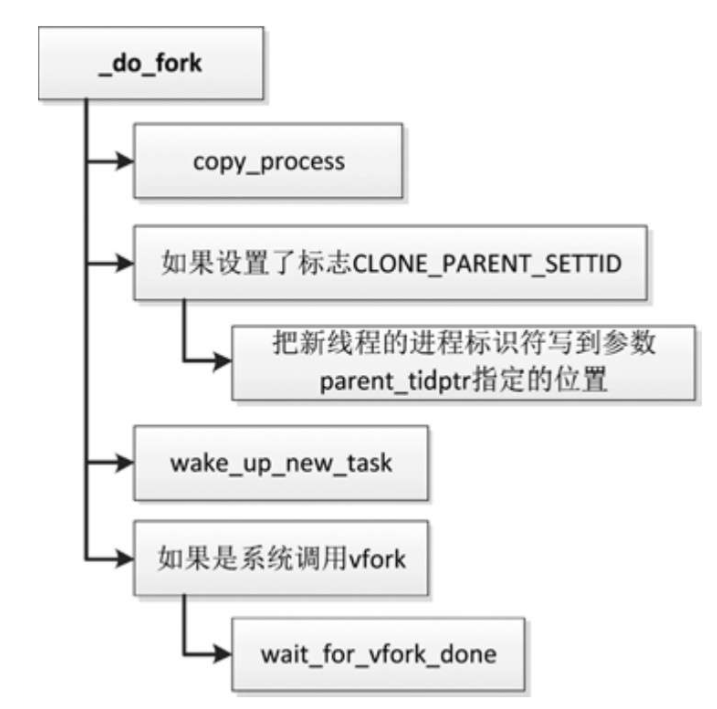
- 调用函数copy_process以创建新进程。
- 如果参数clone_fags设置了标志CLONE_PARENT_SETTID,那么把新线程的进程标识符写到参数parent_tidptr指定的位置。
- 调用函数wake_up_new_task以唤醒新进程。
- 如果是系统调用vfork,那么当前进程等待子进程装载程序。
函数copy_process
创建新进程的主要工作由函数copy_process实现,其执行流程如图
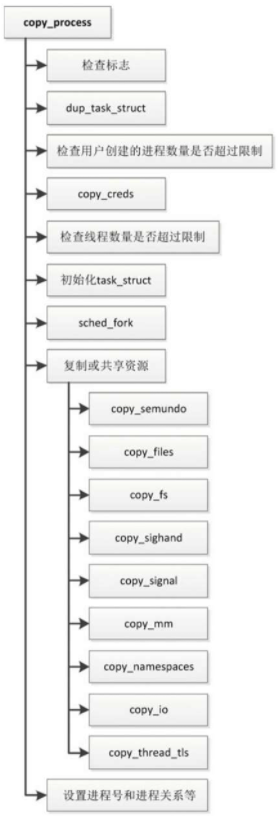
- 检查标志:以下标志组合是非法的。
- 同时设置CLONE_NEWNS和CLONE_FS,即新进程属于新的挂载命名空间,同时和当前进程共享文件系统信息。
- 同时设置CLONE_NEWUSER和CLONE_FS,即新进程属于新的用户命名空间,同时和当前进程共享文件系统信息。
- 设置CLONE_THREAD,未设置CLONE_SIGHAND,即新进程和当前进程属于同一个线程组,但是不共享信号处理程序。
- 设置CLONE_SIGHAND,未设置CLONE_VM,即新进程和当前进程共享信号处理程序,但是不共享虚拟内存。
- 新进程想要和当前进程成为兄弟进程,并且当前进程是某个进程号命名空间中的1号进程。这种标志组合是非法的,说明1号进程不存在兄弟进程。
- 新进程和当前进程属于同一个线程组,同时新进程属于不同的用户命名空间或者进程号命名空间。这种标志组合是非法的,说明同一个线程组的所有线程必须属于相同的用户命名空间和进程号命名空间。
函数dup_task_struct:函数dup_task_struct为新进程的进程描述符分配内存,把当前进程的进程描述符复制一份,为新进程分配内核栈。
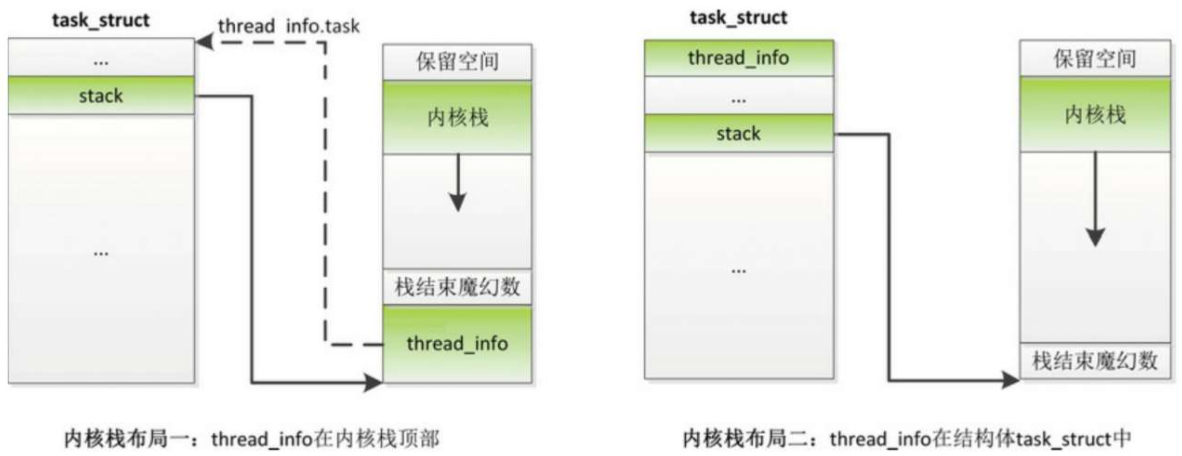
内核栈有两种布局。
- 结构体thread_info占用内核栈的空间,在内核栈顶部,成员task指向进程描述符。
- 结构体thread_info没有占用内核栈的空间,是进程描述符的第一个成员。
检查用户的进程数量限制
如果拥有当前进程的用户创建的进程数量达到或者超过限制,并且用户不是根用户,也没有忽略资源限制的权限(CAP_SYS_RESOURCE)和系统管理权限(CAP_SYS_ADMIN),那么不允许创建新进程。- 函数copy_creds:函数copy_creds负责复制或共享证书,证书存放进程的用户标识符、组标识符和访问权限。
- 检查线程数量限制:如果线程数量达到允许的线程最大数量,那么不允许创建新进程。
- 函数sched_fork:函数sched_fork为新进程设置调度器相关的参数
复制或者共享资源如下
- UNIX系统5信号量。只有属于同一个线程组的线程之间才会共享UNIX系统5信号量
- 打开文件表。只有属于同一个线程组的线程之间才会共享打开文件表。函数copy_files复制或者共享打开文件表
- 文件系统信息。进程的文件系统信息包括根目录、当前工作目录和文件模式创建掩码。只有属于同一个线程组的线程之间才会共享文件系统信息。
- 信号处理程序。只有属于同一个线程组的线程之间才会共享信号处理程序。函数copy_sighand复制或者共享信号处理程序
- 信号结构体。只有属于同一个线程组的线程之间才会共享信号结构体。函数copy_signal复制或共享信号结构体
- 虚拟内存。只有属于同一个线程组的线程之间才会共享虚拟内存。函数copy_mm复制或共享虚拟内存
- 命名空间。函数copy_namespaces创建或共享命名空间
- I/O上下文。函数copy_io创建或者共享I/O上下文
复制寄存器值。调用函数copy_thread_tls复制当前进程的寄存器值,并且修改一部分寄存器值。
进程有两处用来保存寄存器值:从用户模式切换到内核模式时,把用户模式的各种寄存器保存在内核栈底部的结构体pt_regs中;
进程调度器调度进程时,切换出去的进程把寄存器值保存在进程描述符的成员thread中。
因为不同处理器架构的寄存器不同,所以各种处理器架构需要自己定义结构体pt_regs和thread_struct,实现函数copy_thread_tls。进程保存寄存器值处
- 设置进程号和进程关系。函数copy_process的最后部分为新进程设置进程号和进程关系
唤醒新进程
函数wake_up_new_task负责唤醒刚刚创建的新进程
- 把新进程的状态从TASK_NEW切换到TASK_RUNNING
- 在SMP系统上,创建新进程是执行负载均衡的绝佳时机,为新进程选择一个负载最轻的处理器。
- 锁住运行队列
- 更新运行队列的时钟。
- 根据公平运行队列的平均负载统计值,推算新进程的平均负载统计值。第15行代码,把新进程插入运行队列。
- 检查新进程是否可以抢占当前进程。
- 在SMP系统上,调用调度类的task_woken方法。
- 释放运行队列的锁。
新进程第一次运行
新进程第一次运行,是从函数ret_from_fork开始执行。函数ret_from_fork是由各种处理器架构自定义的函数

在介绍函数copy_thread时,我们已经说过:如果新进程是内核线程,寄存器x19存放线程函数的地址,寄存器x20存放线程函数的参数;如果新进程是用户进程,寄存器x19的值是0。
函数ret_from_fork的执行过程如下
- 调用函数schedule_tail,为上一个进程执行清理操作。
- 如果寄存器x19的值是0,说明当前进程是用户进程,那么使用寄存器x28存放当前进程的thread_info结构体的地址,然后跳转到标号ret_to_user返回用户模式。
- 如果寄存器x19的值不是0,说明当前进程是内核线程,那么调用线程函数。
函数schedule_tail的执行过程如下。

- 调用函数finish_task_switch(),为上一个进程执行清理操作,
- 执行运行队列的所有负载均衡回调函数。
- 开启内核抢占。
- 如果pthread库在调用clone()创建线程时设置了标志位CLONE_CHILD_SETTID,那么新进程把自己的进程标识符写到指定位置。
装载程序
当调度器调度新进程时,新进程从函数ret_from_fork开始执行,然后从系统调用fork返回用户空间,返回值是0。
接着新进程使用系统调用execve装载程序。
Linux内核提供了两个装载程序的系统调用

两个系统调用的主要区别是:如果路径名是相对的,那么execve解释为相对调用进程的当前工作目录,而execveat解释为相对文件描述符dirfd指向的目录。
如果路径名是绝对的,那么execveat忽略参数dirfd。
- 参数argv是传给新程序的参数指针数组,数组的每个元素存放一个参数字符串的地址,argv[0]应该指向要装载的程序的名称。
- 参数envp是传给新程序的环境指针数组,数组的每个元素存放一个环境字符串的地址,环境字符串的形式是“键=值”。
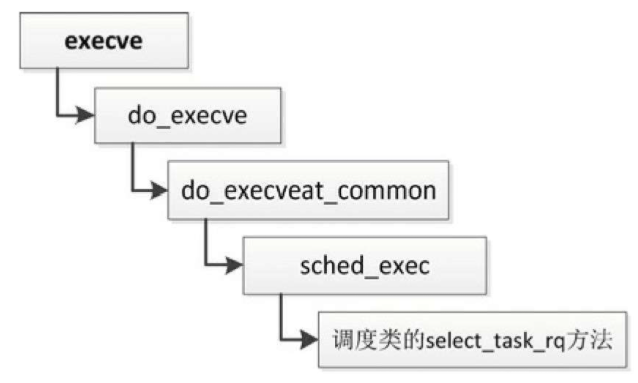
两个系统调用最终都调用函数do_execveat_common,其执行流程如图
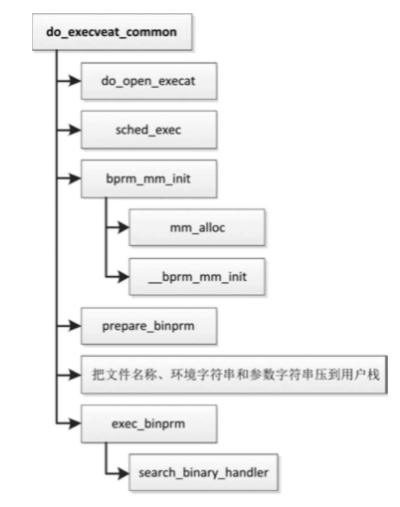
- 调用函数do_open_execat打开可执行文件。
- 调用函数sched_exec。装载程序是一次很好的实现处理器负载均衡的机会,因为此时进程在内存和缓存中的数据是最少的。选择负载最轻的处理器,然后唤醒当前处理器上的迁移线程,当前进程睡眠等待迁移线程把自己迁移到目标处理器。
- 调用函数bprm_mm_init创建新的内存描述符,分配临时的用户栈。
- 调用函数prepare_binprm设置进程证书,然后读文件的前面128字节到缓冲区。
- 依次把文件名称、环境字符串和参数字符串压到用户栈
- 调用函数exec_binprm。函数exec_binprm调用函数search_binary_handler,尝试注册过的每种二进制格式的处理程序,直到某个处理程序识别正在装载的程序为止。
二进制格式
每种二进制格式必须提供下面3个函数。
- load_binary用来加载普通程序。
- load_shlib用来加载共享库。
- core_dump用来在进程异常退出时生成核心转储文件。程序员使用调试器(例如GDB)分析核心转储文件以找出原因。min_coredump指定核心转储文件的最小长度。每种二进制格式必须使用函数register_binfmt向内核注册。
下面介绍常用的二进制格式:ELF格式和脚本格式。
装载ELF程序
- ELF文件:ELF(Executable and Linkable Format)是可执行与可链接格式,主要有以下4种类型。
- 目标文件(object file),也称为可重定位文件(relocatable file),扩展名是“.o”,多个目标文件可以链接生成可执行文件或者共享库。
- 可执行文件(executable file)。
- 共享库(shared object file),扩展名是“.so”。
- 核心转储文件(core dump file)。
ELF文件分成4个部分:ELF首部、程序首部表(program header table)、节(section)和节首部表(section header table)。
实际上,一个文件不一定包含全部内容,而且它们的位置也不一定像图中这样安排,只有ELF首部的位置是固定的,其余各部分的位置和大小由ELF首部的成员决定。
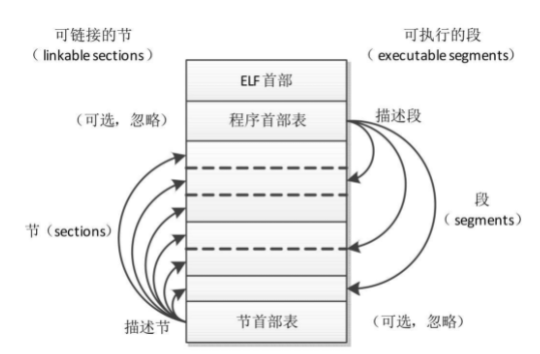
程序首部表就是我们所说的段表(segment table),段(segment)是从运行的角度描述,节(section)是从链接的角度描述,一个段包含一个或多个节。在不会混淆的情况下,我们通常把节称为段,例如代码段(text section),不称为代码节。
ELF首部的成员及说明
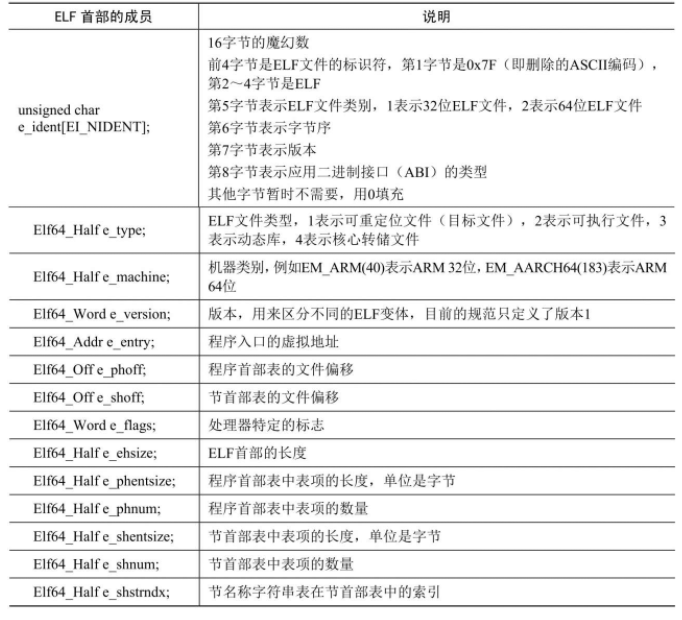
程序首部表中每条表项的成员及说明
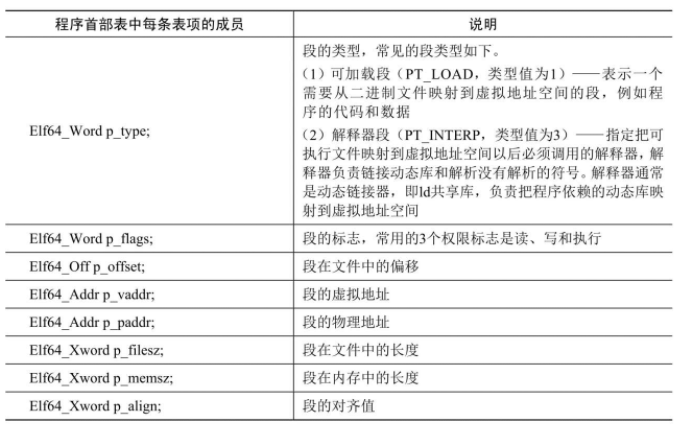
节首部表中每条表项的成员及说明
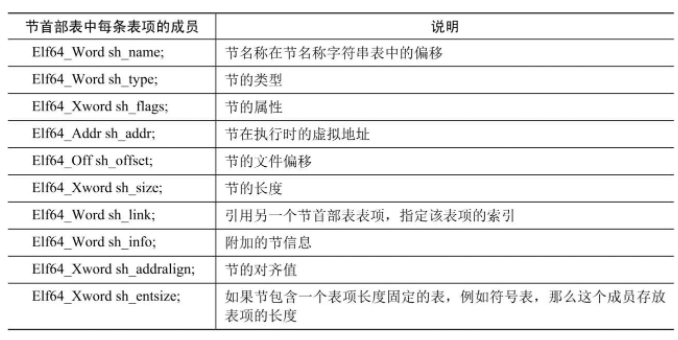
重要的节说明
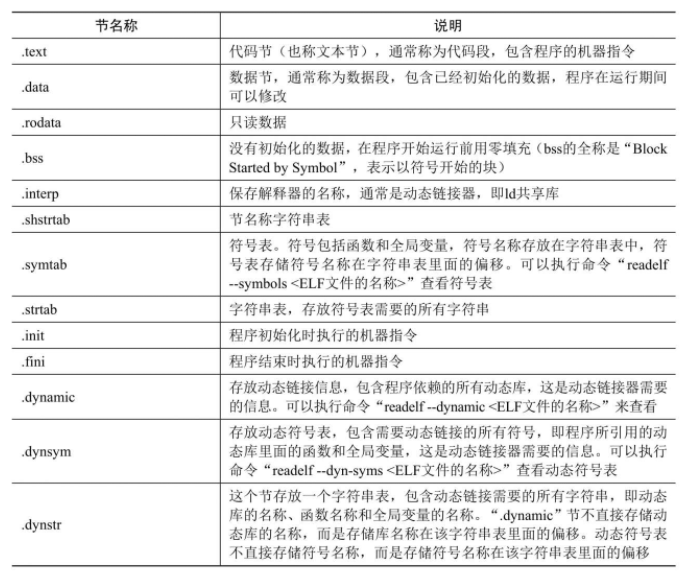
相关命令
- 查看ELF首部:readelf -h <ELF文件的名称>。
- 查看程序首部表:readelf -l <ELF文件的名称>。
- 查看节首部表:readelf -S <ELF文件的名称>。
源文件“fs/binfmt_elf.c”定义的函数load_elf_binary负责装载ELF程序,主要步骤如下
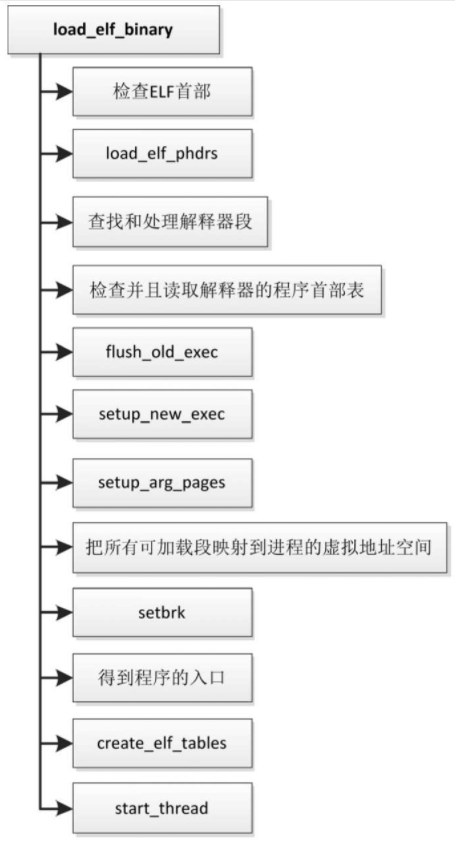
- 检查ELF首部。检查前4字节是不是ELF魔幻数,检查是不是可执行文件或者共享库,检查处理器架构。
- 读取程序首部表。
- 在程序首部表中查找解释器段,如果程序需要链接动态库,那么存在解释器段,从解释器段读取解释器的文件名称,打开文件,然后读取ELF首部。
- 检查解释器的ELF首部,读取解释器的程序首部表。
- 调用函数fush_old_exec终止线程组中的所有其他线程,释放旧的用户虚拟地址空间,关闭那些设置了“执行execve时关闭”标志的文件。
- 调用函数setup_new_exec。函数setup_new_exec调用函数arch_pick_mmap_layout以设置内存映射的布局,在堆和栈之间有一个内存映射区域,传统方案是内存映射区域向栈的方向扩展,另一种方案是内存映射区域向堆的方向扩展,从两种方案中选择一种。然后把进程的名称设置为目标程序的名称,设置用户虚拟地址空间的大小。
- 以前调用函数bprm_mm_init创建了临时的用户栈,现在调用函数set_arg_pages把用户栈定下来,更新用户栈的标志位和访问权限,把用户栈移动到最终的位置,并且扩大用户栈。
- 把所有可加载段映射到进程的虚拟地址空间。
- 调用函数setbrk把未初始化数据段映射到进程的用户虚拟地址空间,并且设置堆的起始虚拟地址,然后调用函数padzero用零填充未初始化数据段。
- 得到程序的入口。如果程序有解释器段,那么把解释器程序中的所有可加载段映射到进程的用户虚拟地址空间,程序入口是解释器程序的入口,否则就是目标程序自身的入口。
- 调用函数create_elf_tables依次把传递ELF解释器信息的辅助向量、环境指针数组envp、参数指针数组argv和参数个数argc压到进程的用户栈。
- 调用函数start_thread设置结构体pt_regs中的程序计数器和栈指针寄存器。当进程从用户模式切换到内核模式时,内核把用户模式的各种寄存器保存在内核栈底部的结构体pt_regs中。因为不同处理器架构的寄存器不同,所以各种处理器架构必须自定义结构体pt_regs和函数start_thread
装载脚本程序
源文件“fs/binfmt_script.c”定义的函数load_script负责装载脚本程序,主要步骤如下。
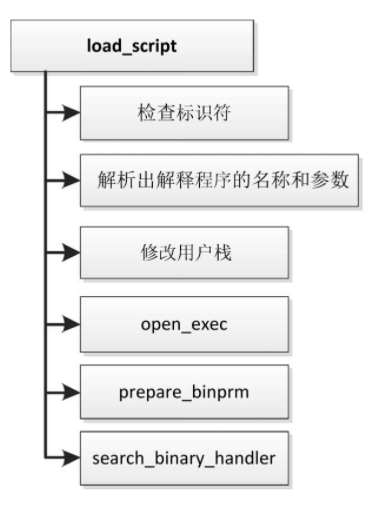
- 检查前两字节是不是脚本程序的标识符。
- 解析出解释程序的名称和参数。
- 从用户栈删除第一个参数,然后依次把脚本程序的文件名称、传给解释程序的参数和解释程序的名称压到用户栈。
- 调用函数open_exec打开解释程序文件。
- 调用函数prepare_binprm设置进程证书,然后读取解释程序文件的前128字节到缓冲区。
- 调用函数search_binary_handler,尝试注册过的每种二进制格式的处理程序,直到某个处理程序识别解释程序为止。
进程退出
进程退出分两种情况:进程主动退出和终止进程。Linux内核提供了以下两个使进程主动退出的系统调用。
- exit用来使一个线程退出。
1 | void exit(int status); |
- Linux私有的系统调用exit_group用来使一个线程组的所有线程退出。
1 | void exit_group(int status); |
glibc库封装了库函数exit、_exit和_Exit用来使一个进程退出,这些库函数调用系统调用exit_group。库函数exit和_exit的区别是exit会执行由进程使用atexit和on_exit注册的函数。
注意:我们编写用户程序时调用的函数exit,是glibc库的函数exit,不是系统调用exit。
终止进程是通过给进程发送信号实现的,Linux内核提供了发送信号的系统调用。
kill用来发送信号给进程或者进程组。
1
int kill(pid_t pid, int sig);
tkill用来发送信号给线程,参数tid是线程标识符。
1
int tkill(int tid, int sig);
tgkill用来发送信号给线程,参数tgid是线程组标识符,参数tid是线程标识符。
1
int tgkill(int tgid, int tid, int sig);
tkill和tgkill是Linux私有的系统调用,tkill已经废弃,被tgkill取代。
当进程退出的时候,根据父进程是否关注子进程退出事件,处理存在如下差异。
- 如果父进程关注子进程退出事件,那么进程退出时释放各种资源,只留下一个空的进程描述符,变成僵尸进程,发送信号SIGCHLD(CHLD是child的缩写)通知父进程,父进程在查询进程终止的原因以后回收子进程的进程描述符。
- 如果父进程不关注子进程退出事件,那么进程退出时释放各种资源,释放进程描述符,自动消失。
进程默认关注子进程退出事件,如果不想关注,可以使用系统调用sigaction针对信号SIGCHLD设置标志SA_NOCLDWAIT(CLD是child的缩写),以指示子进程退出时不要变成僵尸进程,或者设置忽略信号SIGCHLD。
怎么查询子进程终止的原因?
Linux内核提供了3个系统调用来等待子进程的状态改变,状态改变包括:子进程终止,信号SIGSTOP使子进程停止执行,或者信号SIGCONT使子进程继续执行。
这3个系统调用如下。
pid_t waitpid(pid_t pid, int *wstatus, int options);int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);pid_t wait4(pid_t pid, int *wstatus, int options, struct rusage *rusage);
注意:wait4已经废弃,新的程序应该使用waitpid和waitid。
子进程退出以后需要父进程回收进程描述符,如果父进程先退出,子进程成为“孤儿”,谁来为子进程回收进程描述符呢?
父进程退出时需要给子进程寻找一个“领养者”,按照下面的顺序选择领养“孤儿”的进程。
- 如果进程属于一个线程组,且该线程组还有其他线程,那么选择任意一个线程。
- 选择最亲近的充当“替补领养者”的祖先进程。进程可以使用系统调用prctl(PR_SET_CHILD_SUBREAPER)把自己设置为“替补领养者”(subreaper)。
- 选择进程所属的进程号命名空间中的1号进程。
线程组退出
系统调用exit_group实现线程组退出,执行流程如图所示,把主要工作委托给函数do_group_exit,执行流程如下
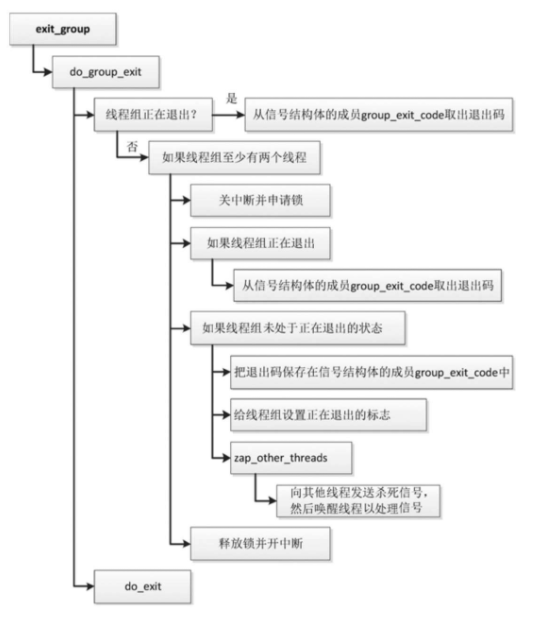
- 如果线程组正在退出,那么从信号结构体的成员group_exit_code取出退出码。
- 如果线程组未处于正在退出的状态,并且线程组至少有两个线程,那么处理如下。
- 关中断并申请锁。
- 如果线程组正在退出,那么从信号结构体的成员group_exit_code取出退出码。
- 如果线程组未处于正在退出的状态,那么处理如下。
- 把退出码保存在信号结构体的成员group_exit_code中,传递给其他线程。
- 给线程组设置正在退出的标志。
- 向线程组的其他线程发送杀死信号,然后唤醒线程,让线程处理杀死信号。
- 释放锁并开中断。
- 当前线程调用函数do_exit以退出。
假设一个线程组有两个线程,称为线程1和线程2,线程1调用exit_group使线程组退出,线程1的执行过程如下。
- 把退出码保存在信号结构体的成员group_exit_code中,传递给线程2。
- 给线程组设置正在退出的标志。
- 向线程2发送杀死信号,然后唤醒线程2,让线程2处理杀死信号。(4)线程1调用函数do_exit以退出。
线程2退出的执行流程如图所示,线程2准备返回用户模式的时候,发现收到了杀死信号,于是处理杀死信号,调用函数do_group_exit,函数do_group_exit的执行过程如下
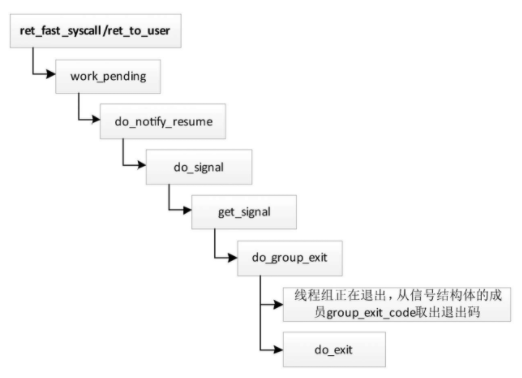
- 因为线程组处于正在退出的状态,所以线程2从信号结构体的成员group_exit_code取出退出码。
- 线程2调用函数do_exit以退出。
线程2可能在以下3种情况下准备返回用户模式。
- 执行完系统调用。
- 被中断抢占,中断处理程序执行完。
- 执行指令时生成异常,异常处理程序执行完。
函数do_exit的执行过程如下。
- 释放各种资源,把资源对应的数据结构的引用计数减一,如果引用计数变成0,那么释放数据结构。
- 调用函数exit_notify,先为成为“孤儿”的子进程选择“领养者”,然后把自己的死讯通知父进程。
- 把进程状态设置为死亡(TASK_DEAD)。
- 最后一次调用函数schedule以调度进程。死亡进程最后一次调用函数schedule调度进程时,进程调度器做了如下特殊处理

- 执行调度类的task_dead方法。
- 如果结构体thread_info放在进程描述符里面,而不是放在内核栈的顶部,那么释放进程的内核栈。
- 把进程描述符的引用计数减1,如果引用计数变为0,那么释放进程描述符。
终止进程
系统调用kill(源文件“kernel/signal.c”)负责向线程组或者进程组发送信号,执行流程如图所示。
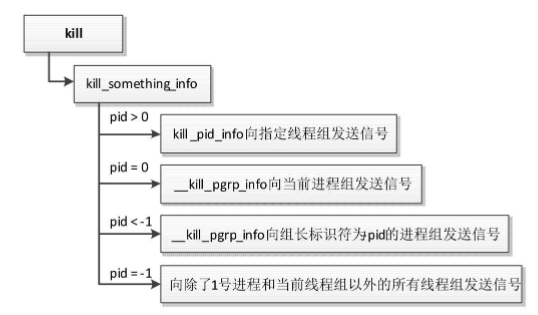
- 如果参数pid大于0,那么调用函数kill_pid_info来向线程pid所属的线程组发送信号。
- 如果参数pid等于0,那么向当前进程组发送信号。
- 如果参数pid小于−1,那么向组长标识符为-pid的进程组发送信号。
- 如果参数pid等于−1,那么向除了1号进程和当前线程组以外的所有线程组发送信号。函数kill_pid_info负责向线程组发送信号,执行流程如图所示,函数check_kill_permission检查当前进程是否有权限发送信号,函数__send_signal负责发送信号。
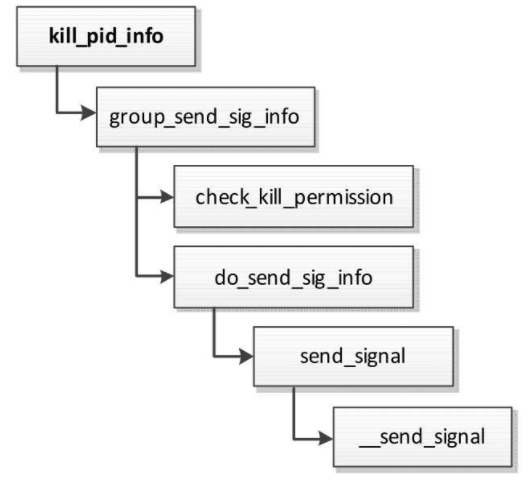
- 如果目标线程忽略信号,那么没必要发送信号。
- 确定把信号添加到哪个信号队列和集合。线程组有一个共享的信号队列和集合,每个线程有一个私有的信号队列和集合。如果向线程组发送信号,那么应该把信号添加到线程组共享的信号队列和集合中;如果向线程发送信号,那么应该把信号添加到线程私有的信号队列和集合中。
- 如果是传统信号,并且信号集合已经包含同一个信号,那么没必要重复发送信号。
- 判断分配信号队列节点时是否可以忽略信号队列长度的限制:对于传统信号,如果是特殊的信号信息,或者信号的编码大于0,那么允许忽略;如果是实时信号,那么不允许忽略。
- 分配一个信号队列节点。
- 如果分配信号队列节点成功,那么把它添加到信号队列中。
- 如果某个进程正在通过信号文件描述符(signalfd)监听信号,那么通知进程。signalfd是进程创建用来接收信号的文件描述符,进程可以使用select或poll监听信号文件描述符。
- 把信号添加到信号集合中。
- 调用函数complete_signal:如果向线程组发送信号,那么需要在线程组中查找一个没有屏蔽信号的线程,唤醒它,让它处理信号。
上一节已经介绍过,当线程准备从内核模式返回用户模式时,检查是否收到信号,如果收到信号,那么处理信号。
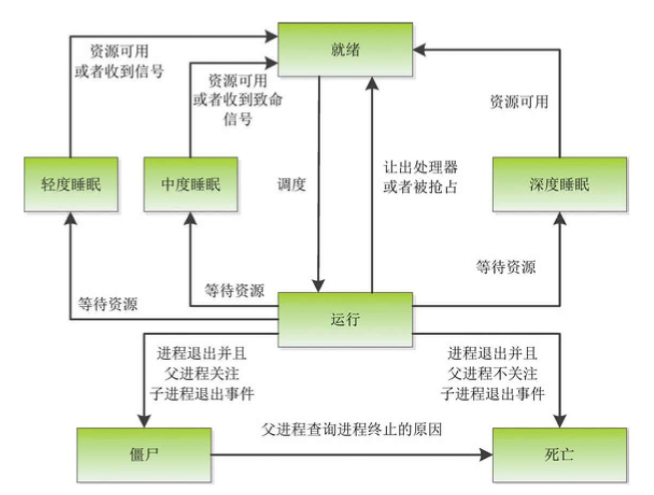
进程状态
进程主要有以下状态。
- 就绪状态:进程描述符的字段state是TASK_RUNNING(Linux内核没有严格区分就绪状态和运行状态),正在运行队列中等待调度器调度。
- 运行状态:进程描述符的字段state是TASK_RUNNING,被调度器选中,正在处理器上运行。
- 轻度睡眠:也称为可打断的睡眠状态,进程描述符的字段state是TASK_INTERRUPTIBLE,可以被信号打断。
- 中度睡眠:进程描述符的字段state是TASK_KILLABLE,只能被致命的信号打断。
- 深度睡眠:也称为不可打断的睡眠状态,进程描述符的字段state是TASK_UNINTERRUPTIBLE,不能被信号打断。
- 僵尸状态:进程描述符的字段state是TASK_DEAD,字段exit_state是EXIT_ZOMBIE。如果父进程关注子进程退出事件,那么子进程在退出时发送SIGCHLD信号通知父进程,变成僵尸进程,父进程在查询子进程的终止原因以后回收子进程的进程描述符。
- 死亡状态:进程描述符的字段state是TASK_DEAD,字段exit_state是EXIT_DEAD。如果父进程不关注子进程退出事件,那么子进程退出时自动消亡。进程状态变迁如图
进程调度
调度策略Linux内核支持的调度策略如下。
- 限期进程使用限期调度策略(SCHED_DEADLINE)。
- 实时进程支持两种调度策略:先进先出调度(SCHED_FIFO)和轮流调度(SCHED_RR)。
- 普通进程支持两种调度策略:标准轮流分时(SCHED_NORMAL)和空闲(SCHED_IDLE)。
以前普通进程还有一种调度策略,称为批量调度策略(SCHED_BATCH), Linux内核引入完全公平调度算法以后,批量调度策略被废弃了,等同于标准轮流分时策略。
限期调度策略有3个参数:运行时间runtime、截止期限deadline和周期period。
如图所示,每个周期运行一次,在截止期限之前执行完,一次运行的时间长度是runtime。
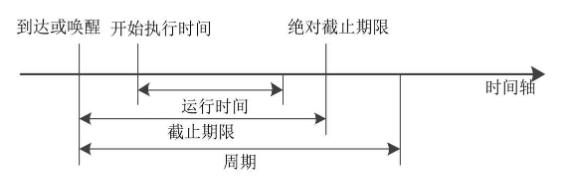
先进先出调度没有时间片,非常霸道,如果没有更高优先级的实时进程,并且它不睡眠,那么它将一直霸占处理器。
轮流调度有时间片,进程用完时间片以后加入优先级对应运行队列的尾部,把处理器让给优先级相同的其他实时进程。
标准轮流分时策略使用完全公平调度算法,把处理器时间公平地分配给每个进程。
空闲调度策略用来执行优先级非常低的后台作业,优先级比使用标准轮流分时策略和相对优先级为19的普通进程还要低,进程的相对优先级对空闲调度策略没有影响。
进程优先级
限期进程的优先级比实时进程高,实时进程的优先级比普通进程高。限期进程的优先级是−1。
实时进程的实时优先级是1~99,优先级数值越大,表示优先级越高。普通进程的静态优先级是100~139,优先级数值越小,表示优先级越高,可通过修改nice值(即相对优先级,取值范围是−20~19)改变普通进程的优先级,优先级等于120加上nice值。
在task_struct结构体中,可以看到4个成员和优先级有关:

相关解释如表
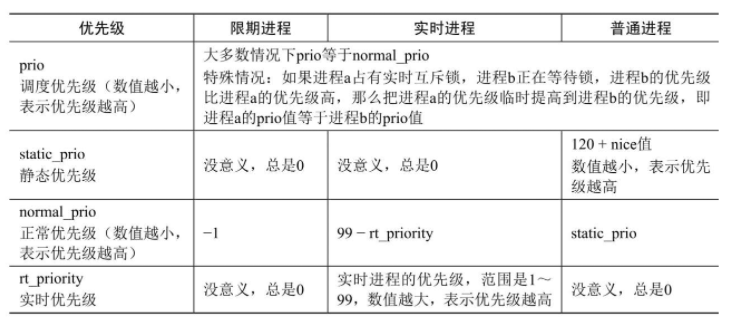
1 | 如果优先级低的进程占有实时互斥锁,优先级高的进程等待实时互斥锁 |
调度类
为了方便添加新的调度策略,Linux内核抽象了一个调度类sched_class,目前实现了5种调度类
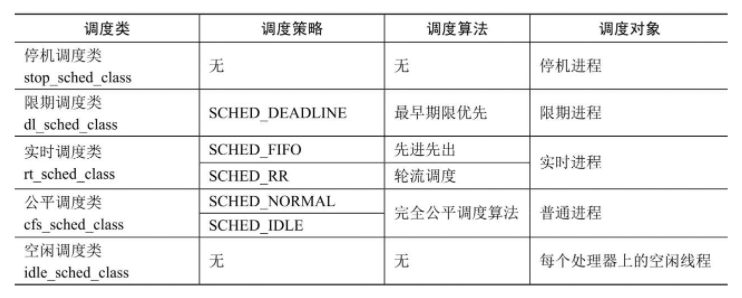
这5种调度类的优先级从高到低依次为:停机调度类、限期调度类、实时调度类、公平调度类和空闲调度类。
停机调度类
停机调度类是优先级最高的调度类,停机进程(stop-task)是优先级最高的进程,可以抢占所有其他进程,其他进程不可以抢占停机进程。停机(stop是指stop machine)的意思是使处理器停下来,做更紧急的事情。
目前只有迁移线程属于停机调度类,每个处理器有一个迁移线程(名称是migration/<cpu_id>),用来把进程从当前处理器迁移到其他处理器,迁移线程对外伪装成实时优先级是99的先进先出实时进程。
停机进程没有时间片,如果它不主动让出处理器,那么它将一直霸占处理器。
引入停机调度类的一个原因是:支持限期调度类,迁移线程的优先级必须比限期进程的优先级高,能够抢占所有其他进程,才能快速处理调度器发出的迁移请求,把进程从当前处理器迁移到其他处理器。
限期调度类
限期调度类使用最早期限优先算法,使用红黑树(一种平衡的二叉树)把进程按照绝对截止期限从小到大排序,每次调度时选择绝对截止期限最小的进程。
如果限期进程用完了它的运行时间,它将让出处理器,并且把它从运行队列中删除。在下一个周期的开始,重新把它添加到运行队列中。
实时调度类
实时调度类为每个调度优先级维护一个队列

位图bitmap用来快速查找第一个非空队列。数组queue的下标是实时进程的调度优先级,下标越小,优先级越高。
每次调度,先找到优先级最高的第一个非空队列,然后从队列中选择第一个进程。
使用先进先出调度策略的进程没有时间片,如果没有优先级更高的进程,并且它不主动让出处理器,那么它将一直霸占处理器。
使用轮流调度策略的进程有时间片,用完时间片以后,进程加入队列的尾部。默认的时间片是5毫秒,可以通过文件/proc/sys/kernel/sched_rr_timeslice_ms修改时间片。
公平调度类
公平调度类使用完全公平调度算法。完全公平调度算法引入了虚拟运行时间的概念
虚拟运行时间 = 实际运行时间 × nice 0对应的权重 / 进程的权重
nice值和权重的对应关系如下

nice 0对应的权重是1024, nice n-1的权重大约是nice n权重的1.25倍。
使用空闲调度策略的普通进程的权重是3, nice值对权重没有影响,定义如下:1
完全公平调度算法使用红黑树把进程按虚拟运行时间从小到大排序,每次调度时选择虚拟运行时间最小的进程。
显然进程的静态优先级越高,权重越大,在实际运行时间相同的情况下,虚拟运行时间越短,进程累计的虚拟运行时间增加得越慢,在红黑树中向右移动的速度越慢,被调度器选中的机会越大,被分配的运行时间相对越多。
调度器选中进程以后分配的时间片是多少呢?
调度周期:在某个时间长度可以保证运行队列中的每个进程至少运行一次,我们把这个时间长度称为调度周期。
调度最小粒度:为了防止进程切换太频繁,进程被调度后应该至少运行一小段时间,我们把这个时间长度称为调度最小粒度。
默认值是0.75毫秒,可以通过文件“/proc/sys/kernel/sched_min_granularity_ns”调整。
如果运行队列中的进程数量大于8,那么调度周期等于调度最小粒度乘以进程数量,否则调度周期是6毫秒。
进程的时间片的计算公式如下
进程的时间片=(调度周期×进程的权重 / 运行队列中所有进程的权重总和)
按照这个公式计算出来的时间片称为理想的运行时间。
空闲调度类
每个处理器上有一个空闲线程,即0号线程。空闲调度类的优先级最低,仅当没有其他进程可以调度的时候,才会调度空闲线程。
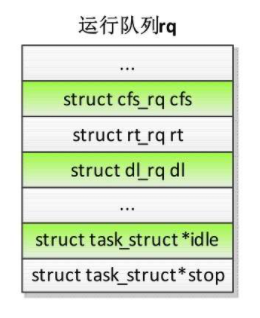
运行队列
每个处理器有一个运行队列,结构体是rq,定义的全局变量如下1
DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
结构体rq中嵌入了公平运行队列cfs、实时运行队列rt和限期运行队列dl,停机调度类和空闲调度类在每个处理器上只有一个内核线程,不需要运行队列,直接定义成员stop和idle分别指向迁移线程和空闲线程。
任务分组
任务分组的意义
我们先看以下两种场景。
- 执行
make -j10(选项“-j10”表示同时执行10条命令),编译Linux内核,同时运行视频播放器,如果给每个进程平均分配CPU时间,会导致视频播放很卡。 - 用户1启动100个进程,用户2启动1个进程,如果给每个进程平均分配CPU时间,用户2的进程只能得到不到1%的CPU时间,用户2的体验很差。
怎么解决呢?
把进程分组。
对于第一种场景,把编译Linux内核的所有进程放在一个任务组中,把视频播放器放在另一个任务组中,给两个任务组分别分配50%的CPU时间。
对于第二种场景,给用户1和用户2分别创建一个任务组,给两个任务组分别分配50%的CPU时间。
任务分组的方式
Linux内核支持以下任务分组方式。
- 自动组:创建会话时创建一个自动组,会话里面的所有进程是自动组的成员。启动一个终端窗口时就会创建一个会话。在运行过程中可以通过文件“/proc/sys/kernel/sched_autogroup_enabled”开启或者关闭该功能,默认值是1。实现自动组的源文件是“kernel/sched/auto_group.c”。
- CPU控制组:可以使用cgroup创建任务组和把进程加入任务组。cgroup已经从版本1(cgroupv1)演进到版本2(cgroup v2),版本1可以创建多个控制组层级树,版本2只有一个控制组层级树。
需要打开配置宏CONFIG_CGROUPS和CONFIG_CGROUP_SCHED,如果公平调度类要支持任务组,打开配置宏CONFIG_FAIR_GROUP_SCHED;如果实时调度类要支持任务组,打开配置宏CONFIG_RT_GROUP_SCHED。
使用cgroup版本1的CPU控制器配置的方法如下
在目录
“/sys/fs/cgroup”下挂载tmpfs文件系统1
mount -t tmpfs cgroup_root /sys/fs/cgroup
在目录
“/sys/fs/cgroup”下创建子目录“cpu”。1
mkdir /sys/fs/cgroup/cpu
在目录
“/sys/fs/cgroup/cpu”下挂载cgroup文件系统,把CPU控制器关联到控制组层级树1
mount -t cgroup -o cpu none /sys/fs/cgroup/cpu
创建两个任务组。
1
2
3cd /sys/fs/cgroup/cpu
mkdir multimedia #创建multimedia任务组
mkdir browser #创建browser任务组指定两个任务组的权重。
1
2echo 2048 > multimedia/cpu.shares
echo 1024 > browser/cpu.shares把线程加入任务组
1
2echo pid1 > browser/tasks
echo pid2 > multimedia/tasks也可以把线程组加入任务组,指定线程组中的任意一个线程的标识符,就会把线程组的所有线程加入任务组
1
2echo pid1 > browser/cgroup.procs
echo pid2 > multimedia/cgroup.procs
cgroup版本2从内核4.15版本开始支持CPU控制器。使用cgroup版本2的CPU控制器配置的方法如下
在目录
“/sys/fs/cgroup”下挂载tmpfs文件系统。1
mount -t tmpfs cgroup_root /sys/fs/cgroup
在目录
“/sys/fs/cgroup”下挂载cgroup2文件系统。1
mount -t cgroup2 none /sys/fs/cgroup
在根控制组开启CPU控制器。
1
2cd /sys/fs/cgroup
echo "+cpu" > cgroup.subtree_control创建两个任务组。
1
2mkdir multimedia
mkdir browser指定两个任务组权重
1
2echo 2048 > multimedia/cpu.weight
echo 1024 > browser/cpu.weight把线程组加入控制组
1
2echo pid1 > browser/cgroup.procs
echo pid2 > multimedia/cgroup.procs把线程加入控制组。
控制组默认只支持线程组,如果想把线程加入控制组,必须先把控制组的类型设置成线程化的控制组,方法是写字符串“threaded”到文件“cgroup.type”中。在线程化的控制组中,如果写文件“cgroup.procs”,将会把线程组中的所有线程加入控制组。1
2
3
4echo threaded > browser/cgroup.type
echo pid1 > browser/cgroup.threads
echo threaded > multimedia/cgroup.type
echo pid2 > multimedia/cgroup.threads
数据结构
任务组的结构体是task_group。默认的任务组是根任务组(全局变量root_task_group),默认情况下所有进程属于根任务组。
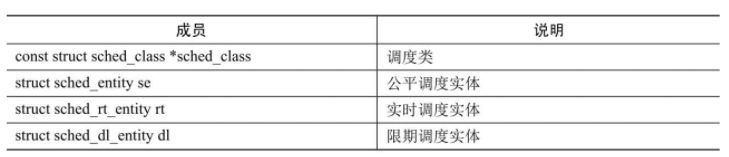
引入任务组以后,因为调度器的调度对象不仅仅是进程,所以内核抽象出调度实体,调度器的调度对象是调度实体,调度实体是进程或者任务组。
如表所示,进程描述符中嵌入了公平、实时和限期3种调度实体,成员sched_class指向进程所属的调度类,进程可以更换调度类,并且使用调度类对应的调度实体。
任务组在每个处理器上有公平调度实体、公平运行队列、实时调度实体和实时运行队列
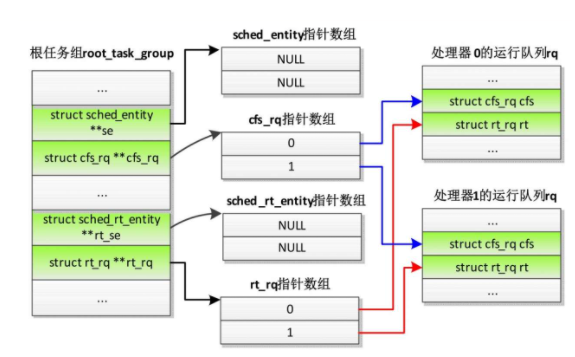
根任务组比较特殊:没有公平调度实体和实时调度实体。
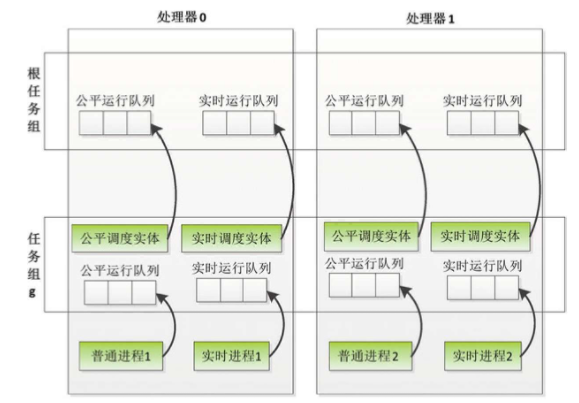
为什么任务组在每个处理器上有一个公平调度实体和一个公平运行队列呢?
因为任务组包含多个进程,每个进程可能在不同的处理器上运行。同理,任务组在每个处理器上也有一个实时调度实体和一个实时运行队列。
在每个处理器上,计算任务组的公平调度实体的权重的方法如下(参考源文件“kernel/sched/fair.c”中的函数update_cfs_shares)。
- 公平调度实体的权重 = 任务组的权重 × 负载比例
- 公平调度实体的负载比例 = 公平运行队列的权重/(任务组的平均负载 − 公平运行队列的平均负载 + 公平运行队列的权重)
- 公平运行队列的权重 = 公平运行队列中所有调度实体的权重总和
- 任务组的平均负载 = 所有公平运行队列的平均负载的总和
为什么负载比例不是公平运行队列的平均负载除以任务组的平均负载?
公平运行队列的权重是实时负载,而公平运行队列的平均负载是上一次计算的负载值,更新被延迟了,我们使用实时负载计算权重。
在每个处理器上,任务组的实时调度实体的调度优先级,取实时运行队列中所有实时调度实体的最高调度优先级。
用数据结构描述任务组的调度实体和运行队列,如图
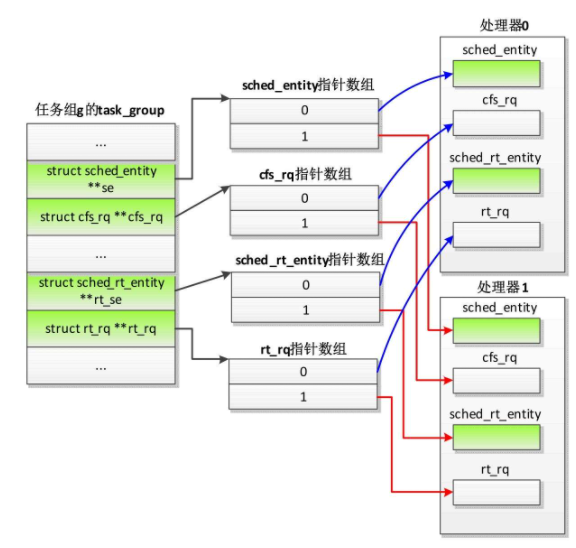
根任务组没有公平调度实体和实时调度实体,公平运行队列指针指向运行队列中嵌入的公平运行队列,实时运行队列指针指向运行队列中嵌入的实时运行队列
假设普通进程p在处理器n上运行,它属于任务组g,数据结构如图
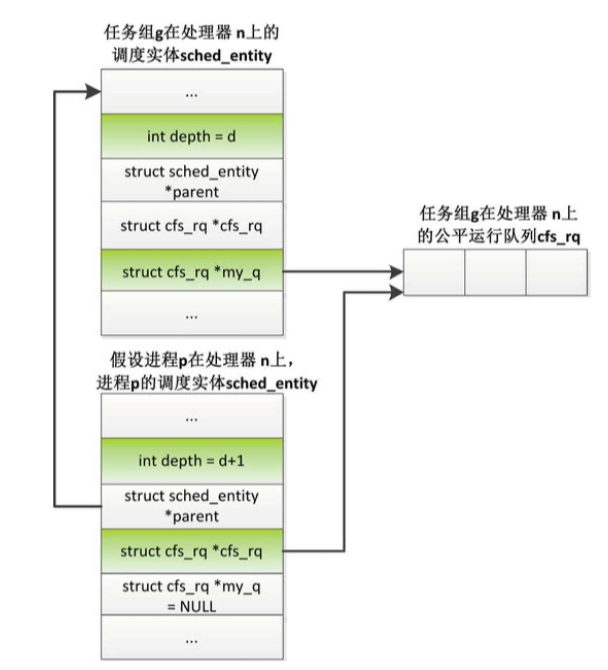
- 成员depth是调度实体在调度树中的深度,任务组g的深度是d,进程p的深度是(d+1)。
- 成员parent指向调度树中的父亲,进程p的父亲是任务组g。
- 成员cfs_rq指向调度实体所属的公平运行队列。进程p所属的公平运行队列是任务组g在处理器n上拥有的公平运行队列。
- 成员my_q指向调度实体拥有的公平运行队列,任务组拥有公平运行队列,进程没有公平运行队列。任务组g在每个处理器上有一个公平调度实体和一个公平运行队列,处理器n上的调度实体的成员my_q指向处理器n上的公平运行队列。
调度进程
调度进程的核心函数是__schedule(),函数原型如下
1 | kernel/sched/core.c |
参数preempt表示是否抢占调度,值为true表示抢占调度,强制剥夺当前进程对处理器的使用权;值为false表示主动调度,当前进程主动让出处理器。
主动调度进程的函数是schedule(),它把主要工作委托给函数schedule()。
函数schedule的主要处理过程如下。
- 调用pick_next_task以选择下一个进程。
- 调用context_switch以切换进程。
选择下一个进程
函数pick_next_task负责选择下一个进程
一般情况是:从优先级最高的调度类开始,调用调度类的pick_next_task方法来选择下一个进程,如果选中了下一个进程,就调度这个进程,否则继续从优先级更低的调度类选择下一个进程。
现在支持5种调度类,优先级从高到低依次是停机、限期、实时、公平和空闲。
- 停机调度类选择下一个进程。停机调度类中用于选择下一个进程的函数是pick_next_task_stop,算法是:如果运行队列的成员stop指向某个进程,并且这个进程在运行队列中,那么返回成员stop指向的进程,否则返回空指针。
- 限期调度类选择下一个进程。限期调度类中用于选择下一个进程的函数是pick_next_task_dl,算法是:从限期运行队列选择绝对截止期限最小的进程,就是红黑树中最左边的进程。限期调度类不支持任务组,所以不需要考虑调度实体是任务组的情况。
- 实时调度类选择下一个进程。实时调度类中用于选择下一个进程的函数是pick_next_task_rt,算法如下。
- 如果实时运行队列没有加入运行队列(rt_rq.rt_queued等于0,如果在一个处理器上所有实时进程在一个周期内用完了运行时间,就会把实时运行队列从运行队列中删除),那么返回空指针。
- 从根任务组在当前处理器上的实时运行队列开始,选择优先级最高的调度实体。
- 如果选中的调度实体是任务组,那么继续从这个任务组在当前处理器上的实时运行队列中选择优先级最高的调度实体,重复这个步骤,直到选中的调度实体是进程为止。
- 公平调度类选择下一个进程。公平调度类中用于选择下一个进程的函数是pick_next_task_fair,算法如下。
- 从根任务组在当前处理器上的公平运行队列中,选择虚拟运行时间最小的调度实体,就是红黑树中最左边的调度实体。
- 如果选中的调度实体是任务组,那么继续从这个任务组在当前处理器上的公平运行队列中选择虚拟运行时间最小的调度实体,重复这个步骤,直到选中的调度实体是进程为止。
- 空闲调度类选择下一个进程。空闲调度类中用于选择下一个进程的函数是pick_next_task_idle,算法是:返回运行队列的成员idle指向的空闲线程。
切换进程
切换进程的函数是context_switch,执行的主要工作如下。
- switch_mm_irqs_off负责切换进程的用户虚拟地址空间。
- switch_to负责切换处理器的寄存器。
函数context_switch的代码如下

prepare_task_switch执行进程切换的准备工作,调用每种处理器架构必须定义的函数prepare_arch_switch。
ARM64架构没有定义函数prepare_arch_switch,使用默认定义,它是一个空的宏。1
2
3mm = next->mm;
oldmm = prev->active_mm;
arch_start_context_switch(prev);
函数arch_start_context_switch开始上下文切换,是每种处理器架构必须定义的函数。
ARM64架构没有定义函数arch_start_context_switch,使用默认定义,它也是一个空的宏。
1 | if(!mm){ |
如果下一个进程是内核线程(成员mm是空指针),内核线程没有用户虚拟地址空间,那么需要借用上一个进程的用户虚拟地址空间,把借来的用户虚拟地址空间保存在成员active_mm中,内核线程在借用的用户虚拟地址空间的上面运行。
函数enter_lazy_tlb通知处理器架构不需要切换用户虚拟地址空间,这种加速进程切换的技术称为惰性TLB。
ARM64架构定义的函数enter_lazy_tlb是一个空函数。
1 | if(!prev->mm){ |
如果上一个进程是内核线程,那么把成员active_mm设置成空指针,断开它和借用的用户虚拟地址空间的联系,把它借用的用户虚拟地址空间保存在运行队列的成员prev_mm中。
1 | // 这里只切换寄存器状态和栈 |
函数switch_to是每种处理器架构必须定义的函数,负责切换处理器的寄存器。
barrier()是编译器优化屏障,防止编译器优化时调整switch_to和finish_task_switch的顺序。
函数finish_task_switch负责在进程切换后执行清理工作。
如果下一个进程是用户进程,那么调用函数switch_mm_irqs_off切换进程的用户虚拟地址空间。
切换用户虚拟地址空间
ARM64架构使用默认的switch_mm_irqs_off,其定义如下1
2
3
4include/linux/mmu_context.h
函数switch_mm的代码如下

- 如果切换到内核的内存描述符init_mm,那么把寄存器TTBR0_EL1设置为保留的地址空间标识符0和保留的零页empty_zero_page的物理地址。
目前只有这种情况需要切换到内核的内存描述符init_mm:内核支持处理器热插拔,当处理器下线时,如果空闲线程借用用户进程的内存描述符,那么必须切换到内核的内存描述符init_mm。
寄存器TTBR0_EL1(转换表基准寄存器0,Translation table base register 0)用来存放进程的地址空间标识符和页全局目录的物理地址,其中高16位是地址空间标识符,处理器的页表缓存使用地址空间标识符区分不同进程的虚拟地址。 - 这是函数__switch_mm的重点,调用函数check_and_switch_context为进程分配地址空间标识符
切换寄存器
宏switch_to把这项工作委托给函数__switch_to

- 调用函数fpsimd_thread_switch以切换浮点寄存器。第7行代码,调用函数tls_thread_switch以切换线程本地存储相关的寄存器。
- 调用函数hw_breakpoint_thread_switch以切换调试寄存器。
- 调用函数contextidr_thread_switch把上下文标识符寄存器CONTEXTIDR_EL1设置为下一个进程的进程号。
- 调用函数entry_task_switch使用当前处理器的每处理器变量entry_task记录下一个进程的进程描述符的地址,因为内核使用用户栈指针寄存器SP_EL0存放当前进程的进程描述符的第一个成员thread_info的地址,但是用户空间会改变用户栈指针寄存器SP_EL0,所以使用当前处理器的每处理器变量entry_task记录下一个进程的进程描述符的地址,以便从用户空间进入内核空间时可以恢复用户栈指针寄存器SP_EL0。
- 调用函数uao_thread_switch根据下一个进程可访问的虚拟地址空间上限恢复用户访问覆盖(User Access Override, UAO)状态。开启UAO特性以后,get_user()/put_user()使用非特权的加载/存储指令访问用户地址空间,当使用函数set_fs(KERNEL_DS)把进程可访问的地址空间上限设置为内核地址空间上限时,设置覆盖位允许非特权的加载/存储指令访问内核地址空间。
- dsb(ish)是数据同步屏障,确保屏障前面的缓存维护操作和页表缓存维护操作执行完。
- 调用函数cpu_switch_to以切换通用寄存器。
函数cpu_switch_to切换下面这些通用寄存器。- 由被调用函数负责保存的寄存器x19~x28。被调用函数必须保证这些寄存器在函数执行前后的值相同,如果被调用函数需要使用其中一个寄存器,必须先把寄存器的值保存在栈里面,在函数返回前恢复寄存器的值。
- 寄存器x29,即帧指针(Frame Pointer, FP)寄存器。
- 栈指针(Stack Pointer, SP)寄存器。❑ 寄存器x30,即链接寄存器(Link Register, LR),它存放函数的返回地址。
- 用户栈指针寄存器SP_EL0,内核使用它存放当前进程的进程描述符的第一个成员thread_info的地址。

执行清理工作
函数finish_task_switch在从进程prev切换到进程next后为进程prev执行清理工作

- rq是当前处理器的运行队列,如果进程prev是内核线程,那么rq->prev_mm存放它借用的内存描述符。这里把rq->prev_mm设置为空指针。
- 函数vtime_task_switch(prev)计算进程prev的时间统计。
- 函数finish_lock_switch(rq, prev)把prev->on_cpu设置为0,表示进程prev没有在处理器上运行;然后释放运行队列的锁,开启硬中断。
- 函数finish_arch_post_lock_switch()在执行完函数finish_lock_switch()以后,执行处理器架构特定的清理工作。ARM64架构没有定义,使用默认的空函数。
- 如果进程prev是内核线程,那么把它借用的内存描述符的引用计数减1,如果引用计数减到0,那么释放内存描述符。
- 如果进程prev的状态是TASK_DEAD,即进程主动退出或者被终止,那么执行以下清理操作。
- 调用进程prev所属调度类的task_dead方法。
- 调用函数put_task_stack:如果结构体thread_info放在进程描述符里面,而不是放在内核栈的顶部,那么释放进程的内核栈。
- 把进程描述符的引用计数减1,如果引用计数变为0,那么释放进程描述符。
调度时机
调度进程的时机如下。
- 进程主动调用schedule()函数。
- 周期性地调度,抢占当前进程,强迫当前进程让出处理器。
- 唤醒进程的时候,被唤醒的进程可能抢占当前进程。
- 创建新进程的时候,新进程可能抢占当前进程。如果编译内核时开启对内核抢占的支持,那么内核会增加一些抢占点。
主动调度
进程在用户模式下运行的时候,无法直接调用schedule()函数,只能通过系统调用进入内核模式,如果系统调用需要等待某个资源,例如互斥锁或信号量,就会把进程的状态设置为睡眠状态,然后调用schedule()函数来调度进程。
进程也可以通过系统调用sched_yield()让出处理器,这种情况下进程不会睡眠。
在内核中,有以下3种主动调度方式。
- 直接调用schedule()函数来调度进程。
- 调用有条件重调度函数cond_resched()。
在非抢占式内核中,函数cond_resched()判断当前进程是否设置了需要重新调度的标志,如果设置了,就调度进程;
在抢占式内核中,函数cond_resched()是空函数,没有作用。- 如果需要等待某个资源,例如互斥锁或信号量,那么把进程的状态设置为睡眠状态,然后调用schedule()函数以调度进程。
周期调度
有些“流氓”进程不主动让出处理器,内核只能依靠周期性的时钟中断夺回处理器的控制权,时钟中断是调度器的脉搏。
时钟中断处理程序检查当前进程的执行时间有没有超过限额,如果超过限额,设置需要重新调度的标志。
当时钟中断处理程序准备把处理器还给被打断的进程时,如果被打断的进程在用户模式下运行,就检查有没有设置需要重新调度的标志,如果设置了,调用schedule()函数以调度进程。
周期调度的函数是scheduler_tick(),它调用当前进程所属调度类的task_tick方法。
如果需要重新调度,就为当前进程的thread_info结构体的成员fags设置需要重新调度的标志位(_TIF_NEED_RESCHED),中断处理程序在返回的时候会检查这个标志位。
限期调度类的周期调度
限期调度类的task_tick方法是函数task_tick_dl,函数task_tick_dl把主要工作委托给update_curr_dl函数,函数update_curr_dl的主要代码如下
- 计算限期进程的剩余运行时间。
- 如果限期进程用完了运行时间或者主动让出处理器,处理如下。
- 设置节流标志。
- 把当前进程从限期运行队列中删除。
- 如果当前进程被临时提升为限期进程(因为占用某个限期进程等待的实时互斥锁),或者绝对截止期限已经过期,那么把当前进程重新加入限期运行队列,补充运行时间(如果绝对截止期限没有到期,函数start_dl_timer启动高精度定时器,到期时间是当前进程的绝对截止期限,到期的时候把进程重新加入限期运行队列,补充运行时间)。
- 如果当前进程不在限期运行队列中,或者虽然在限期运行队列中但是绝对截止期限不是最小的,那么给当前进程设置需要重新调度的标志位。
实时调度类的周期调度
实时调度类的task_tick方法是函数task_tick_rt,其主要代码如下
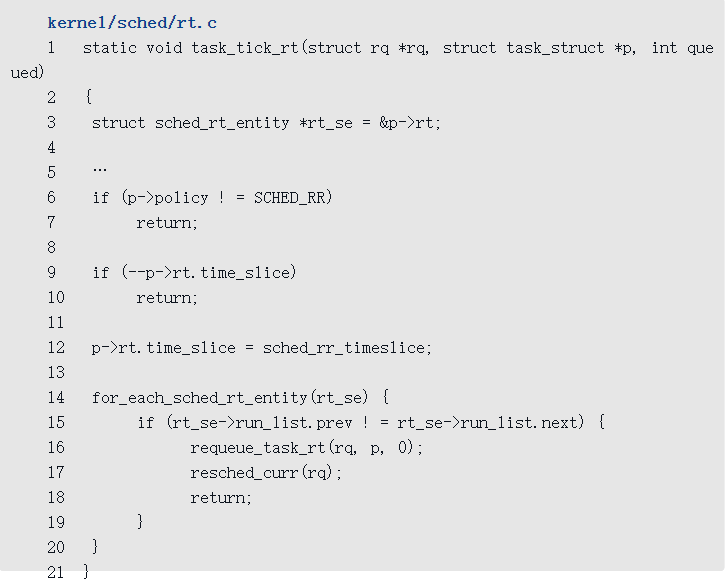
- 如果调度策略不是轮流调度,那么直接返回。
- 把时间片减一,如果没用完时间片,那么返回。
- 如果用完了时间片,那么重新分配时间片。
- 从当前进程到根任务组的任何一个层次,如果实时调度实体不是实时运行队列的唯一调度实体,那么把当前进程重新添加到实时运行队列的尾部,并且设置需要重新调度的标志位。
公平调度类的周期调度
公平调度类的task_tick方法是函数task_tick_fair,其主要代码如下

从当前进程到根任务组的每级公平调度实体,调用函数entity_tick。函数entity_tick的主要代码如下

如果公平运行队列的进程数量超过1,那么调用函数check_preempt_tick。函数check_preempt_tick的代码如下

- 如果当前调度实体的运行时间超过了理想的运行时间,那么设置需要重新调度的标志位。
理想的运行时间=(调度周期×当前公平调度实体的权重/公平运行队列中所有调度实体的权重总和)。 - 如果当前调度实体的运行时间大于或等于调度最小粒度,并且当前调度实体的虚拟运行时间和公平运行队列中第一个调度实体的虚拟运行时间的差值大于理想的运行时间,那么设置需要重新调度的标志位。
中断返回时调度
如果进程正在用户模式下运行,那么中断抢占时,ARM64架构的中断处理程序的入口是e10_irq。
中断处理程序执行完以后,跳转到标号ret_to_user以返回用户模式。
标号ret_to_user判断当前进程的进程描述符的成员thread_info.fags有没有设置标志位集合_TIF_WORK_MASK中的任何一个标志位,如果设置了其中一个标志位,那么跳转到标号work_pending,
标号work_pending调用函数do_notify_resume

函数do_notify_resume判断当前进程的进程描述符的成员thread_info.fags有没有设置需要重新调度的标志位_TIF_NEED_RESCHED,如果设置了,那么调用函数schedule()以调度进程。

唤醒进程时抢占
唤醒进程的时候,被唤醒的进程可能抢占当前进程
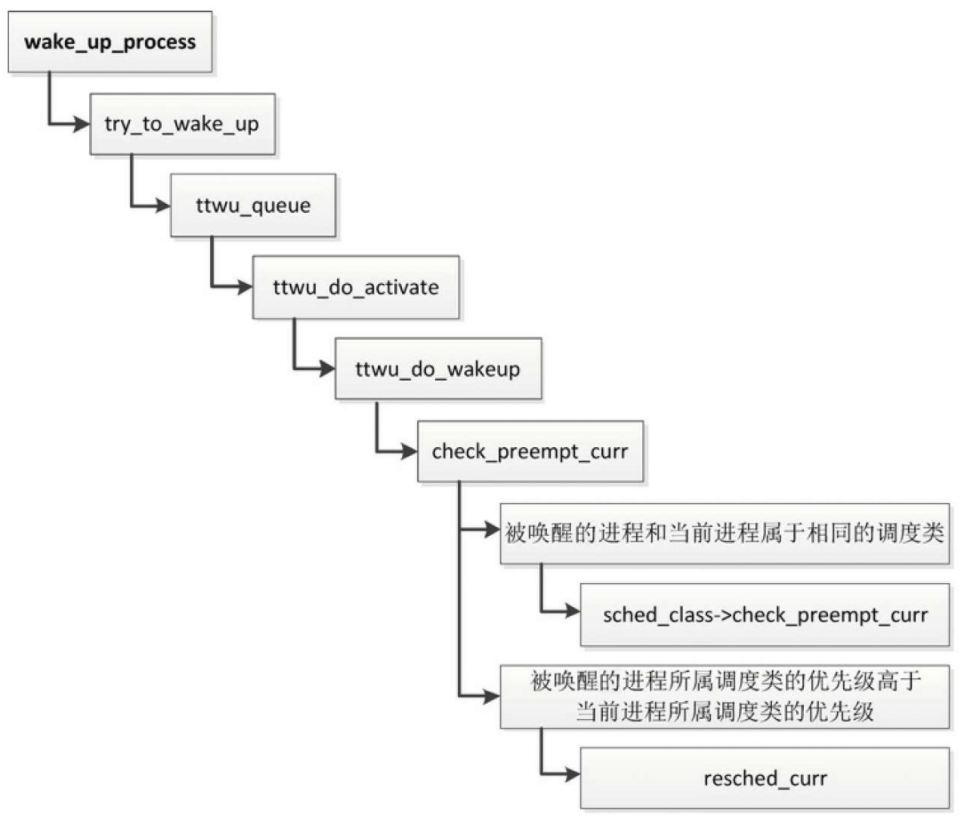
- 如果被唤醒的进程和当前进程属于相同的调度类,那么调用调度类的check_preempt_curr方法以检查是否可以抢占当前进程。
- 如果被唤醒的进程所属调度类的优先级高于当前进程所属调度类的优先级,那么给当前进程设置需要重新调度的标志。
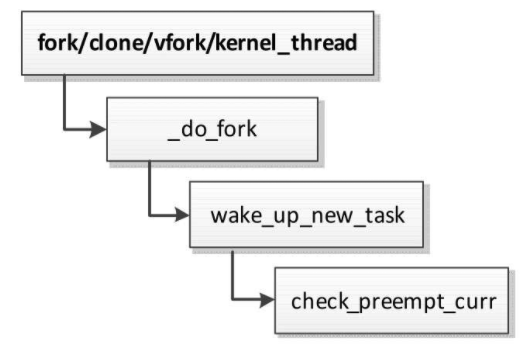
创建新进程时抢占
使用系统调用fork、clone或vfork创建新进程的时候,新进程可能抢占当前进程
使用函数kernel_thread创建新的内核线程的时候,新的内核线程可能抢占当前进程
内核抢占
内核抢占是指当进程在内核模式下运行的时候可以被其他进程抢占,需要打开配置宏CONFIG_PREEMPT。
如果不支持内核抢占,当进程在内核模式下运行的时候,不会被其他进程抢占,带来的问题是:如果一个进程在内核模式下运行的时间很长,将导致交互式进程等待的时间很长,响应很慢,用户体验差。
内核抢占就是为了解决这个问题。支持抢占的内核称为抢占式内核,不支持抢占的内核称为非抢占式内核。
个人计算机的桌面操作系统要求响应速度快,适合使用抢占式内核
服务器要求业务的吞吐率高,适合使用非抢占式内核。
每个进程的thread_info结构体有一个类型为int的成员preempt_count,称为抢占计数器,如图所示。

其中第0~7位是抢占计数,第8~15位是软中断计数,第16~19位是硬中断计数,第20位是不可屏蔽中断计数。
进程在内核模式下运行时,可以调用preempt_disable()以禁止其他进程抢占,preempt_disable()把抢占计数器的抢占计数部分加1。
local_bh_disable()禁止软中断抢占,把抢占计数器的软中断计数部分加2;
函数__do_softirq()在执行软中断之前把软中断计数部分加1。
中断处理程序会把抢占计数器的硬中断计数部分加1,表示在硬中断上下文里面。
不可屏蔽中断的处理程序会把抢占计数器的不可屏蔽中断计数部分和硬中断计数部分分别加1,表示在不可屏蔽中断上下文里面。
进程在内核模式下运行的时候,如果抢占计数器的值不是0,那么其他进程不能抢占。
可以看出,如果禁止软中断抢占,那么同时也禁止了其他进程抢占。
内核抢占增加了一些抢占点。
- 在调用preempt_enable()开启抢占的时候。
- 在调用local_bh_enable()开启软中断的时候。
- 在调用spin_unlock()释放自旋锁的时候。
- 在中断处理程序返回内核模式的时候。
- 开启内核抢占时抢占:在调用preempt_enable()开启抢占的时候,把抢占计数器的抢占计数部分减1,如果抢占计数器变成0,并且当前进程设置了重新调度标志位,那么执行抢占调度
- 开启软中断时抢占:在调用local_bh_enable()开启软中断的时候,如果抢占计数器变成0,并且为当前进程设置了重新调度标志位,那么执行抢占调度。
- 释放自旋锁时抢占:调用spin_unlock()释放自旋锁的时候,调用函数preempt_enable()开启抢占,如果抢占计数器变成0,并且当前进程设置了重新调度标志位,那么执行抢占调度。
- 中断处理程序返回内核模式时抢占:如果进程正在内核模式下运行,那么中断抢占时,ARM64架构的中断处理程序的入口是el1_irq。
中断处理程序执行完以后,如果进程的抢占计数器是0,并且设置了需要重新调度的标志位,那么调用函数el1_preempt,函数el1_preempt调用函数preempt_schedule_irq以执行抢占调度。
如果被选中的进程也设置了需要重新调度的标志位,那么继续执行抢占调度。
高精度调度时钟
调度器选择一个进程运行以后,周期调度函数检查进程的运行时间是否超过限额。如果时钟频率是100赫兹,时钟每隔10毫秒发送一次中断请求,那么对进程运行时间的控制精度只能达到10毫秒。高精度时钟的精度是纳秒,如果硬件层面有一个高精度时钟,那么可以使用高精度调度时钟精确地控制进程的运行时间。启用高精度调度时钟的方法如下。
- 打开高精度定时器的配置宏CONFIG_HIGH_RES_TIMERS,自动打开高精度调度时钟的配置宏CONFIG_SCHED_HRTICK。
- 头文件
kernel/sched/features.h默认禁止调度特性“高精度调度时钟”:SCHED_FEAT(HRTICK, false),需要修改为默认开启。
当公平调度类调用函数pick_next_task_fair以选择一个普通进程时,启动高精度定时器,把相对超时设置为普通进程的理想运行时间。
当限期调度类调用函数pick_next_task_dl以选择一个限期进程时,启动高精度定时器,把相对超时设置为限期进程的运行时间。
SMP调度
在SMP系统中,进程调度器必须支持以下特性。
- 需要使每个处理器的负载尽可能均衡。
- 可以设置进程的处理器亲和性(affinity),即允许进程在哪些处理器上执行。
- 可以把进程从一个处理器迁移到另一个处理器。
进程的处理器亲和性
设置进程的处理器亲和性,用通俗的话说,就是把进程绑定到某些处理器,只允许进程在某些处理器上执行
默认情况是进程可以在所有处理器上执行。
进程描述符增加了以下两个成员

成员cpus_allowed保存允许的处理器掩码,成员nr_cpus_allowed保存允许的处理器数量。
应用编程接口
内核提供两个系统调用
sched_setaffinity用来设置进程的处理器亲和性掩码
1
int sched_setaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);
sched_getaffinity用来获取处理器亲和性掩码
1
int sched_getaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);
内核线程可以使用以下函数设置处理器亲和性掩码。
kthread_bind用来把一个刚刚创建的内核线程绑定到一个处理器
1
void kthread_bind(struct task_struct *p, unsigned int cpu);
set_cpus_allowed_ptr用来设置内核线程的处理器亲和性掩码
1
int set_cpus_allowed_ptr(struct task_struct *p, const struct cpumask *new_mask);
使用cpuset配置
管理员可以使用cpuset设置进程的处理器亲和性。
cpuset用来控制进程在哪些处理器上执行,以及从哪些内存节点分配内存。
cpuset可以单独使用,也可以作为cgroup的一个资源控制器使用(cpuset合并到内核的时间比cgroup早,2.6.12版本引入cpuset,2.6.24版本引入cgroup)。
cpuset在单独使用的时候,可以使用cpuset伪文件系统配置,配置方法如下
创建目录
/dev/cpuset1
mkdir /dev/cpuset
把cpuset伪文件系统挂载到目录
dev/cpuset下1
mount -t cpuset none /dev/cpuset
创建cpuset,假设名字是
abc1
2cd /dev/cpuset
mkdir abc把处理器分配到cpuset, 假设把处理器2和3分配到cpuset abc,需要在目录
/dev/cpuset/abc下配置1
2cd abc
echo 2-3 > cpuset.cpus把线程关联到cpuset,假设线程10关联到cpuset abc, 需要在目录
/dev/cpuset/abc下配置1
echo 10 > tasks
查看线程10关联的cpuset
1
cat /proc/10/cpuset
cgroup已经从版本1(cgroup v1)演进到版本2(cgroup v2),目前cgroup v2不支持cpuset控制器。
使用cgroup v1的cpuset控制器的配置方法如下。
在目录
/sys/fs/cgroup下挂载tmpfs文件系统1
mount -t tmpfs cgroup_root /sys/fs/cgroup
在目录
/sys/fs/cgroup下创建子目录cpuset1
mkdir /sys/fs/cgroup/cpuset
把cgroup伪文件系统挂载到目录
/sys/fs/cgroup/cpuset,把cpuset控制器关联到控制组层级树。1
mount -t cgroup -o cpuset cpuset /sys/fs/cgroup/cpuset
创建控制组,假设名称是
abc。1
2cd /sys/fs/cgroup/cpuset
mkdir abc把处理器分配到控制组,假设把处理器2和3分配到控制组abc,需要在目录
/sys/fs/cgroup/cpuset/abc下配置。1
2cd abc
echo 2-3 > cpuset.cpus把线程加入控制组,假设把线程20加入控制组abc。
1
echo 20 > tasks
也可以把线程组加入控制组,指定线程组中任意一个线程的标识符,就会把线程组的所有线程加入控制组。假设把线程10所属的线程组加入控制组abc。
1
echo 10 > cgroup.procs
查看线程10的cpuset
1
cat /proc/10/cpuset
对调度器的扩展
在SMP系统上,调度类增加了以下方法

- select_task_rq方法用来为进程选择运行队列,实际上就是选择处理器。
- migrate_task_rq方法用来在进程被迁移到新的处理器之前调用。
- task_woken方法用来在进程被唤醒以后调用。
- set_cpus_allowed方法用来在设置处理器亲和性的时候执行调度类的特殊处理。
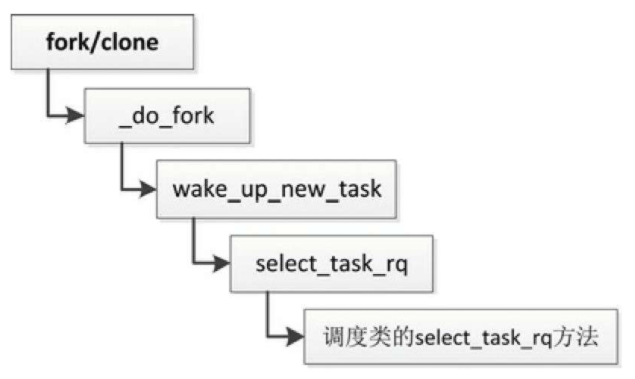
以下两种情况下,进程在内存和缓存中的数据是最少的,是有价值的实现负载均衡的机会。
- 调用fork或clone以创建新进程,如图所示
- 调用execve装载程序,如图所示
限期调度类的处理器负载均衡
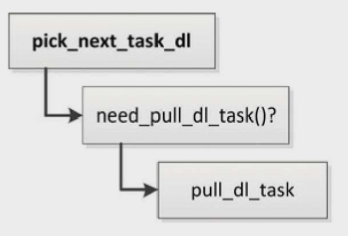
限期调度类的处理器负载均衡比较简单,如图所示。
调度器选择下一个限期进程的时候,如果当前正在执行的进程是限期进程,将会试图从限期进程超载的处理器把限期进程拉过来。
限期进程超载的定义如下。
- 限期运行队列至少有两个限期进程。
- 至少有一个限期进程绑定到多个处理器。
函数pull_dl_task负责从限期进程超载的处理器把限期进程拉过来,其代码如下


- 如果不存在限期进程超载的处理器,那么不需要处理。
- 针对每个限期进程超载的处理器t,处理如下。
- 如果当前处理器正在执行的限期进程的绝对期限小于处理器t的下一个限期进程的绝对期限,那么不需要拉限期进程过来。
- 如果处理器t上限期进程的数量小于2,那么不需要拉限期进程过来。
- 在处理器t上选择一个绝对期限最小、处于就绪状态并且绑定的处理器集合包含当前处理器的限期进程。
- 如果目标进程的绝对期限小于上一个拉过来的限期进程的绝对期限,并且小于当前处理器正在执行的限期进程的绝对期限,那么处理如下。
- 如果目标进程的绝对期限小于处理器t正在执行的限期进程的绝对期限,那么不要把目标进程拉过来。
- 当前处理器把目标进程从处理器t拉过来。
实时调度类的处理器负载均衡
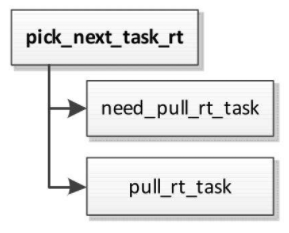
实时调度类的处理器负载均衡和限期调度类相似,如图所示。
调度器选择下一个实时进程时,如果当前处理器的实时运行队列中的进程的最高调度优先级比当前正在执行的进程的调度优先级低,将会试图从实时进程超载的处理器把可推送实时进程拉过来。
实时进程超载的定义如下。
- 实时运行队列至少有两个实时进程。
- 至少有一个可推送实时进程。可推送实时进程是指绑定到多个处理器的实时进程,可以在处理器之间迁移。
函数pull_rt_task负责从实时进程超载的处理器把可推送实时进程拉过来,其代码如下:

- 如果不存在实时进程超载的处理器,那么不需要处理。
- 针对每个实时进程超载的处理器t,处理如下。
- 如果处理器t上可推送实时进程的第二高调度优先级比当前处理器上实时进程的最高调度优先级高(数值越大,优先级越低),那么可以考虑拉实时进程过来,否则不用考虑。
- 在处理器t上选择一个调度优先级最高、处于就绪状态并且绑定的处理器集合包含当前处理器的实时进程。
- 如果目标进程的调度优先级比当前处理器上实时进程的最高调度优先级高,处理如下。
- 如果目标进程的调度优先级比处理器t正在执行的进程的调度优先级高,那么不要把目标进程拉过来。这种情况下目标进程正在被唤醒,还没机会调度。
- 当前处理器把目标进程拉过来。
公平调度类的处理器负载均衡
处理器拓扑
目前多处理器系统有两种体系结构。
- 非一致内存访问(Non-Uniform Memory Access, NUMA):指内存被划分成多个内存节点的多处理器系统,访问一个内存节点花费的时间取决于处理器和内存节点的距离。每个处理器有一个本地内存节点,处理器访问本地内存节点的速度比访问其他内存节点的速度快。
- 对称多处理器(Symmetric Multi-Processor, SMP):即一致内存访问(Uniform MemoryAccess, UMA),所有处理器访问内存花费的时间是相同的。每个处理器的地位是平等的,仅在内核初始化的时候不平等:
“0号处理器作为引导处理器负责初始化内核,其他处理器等待内核初始化完成。”
在实际应用中可以采用混合体系结构,在NUMA节点内部使用SMP体系结构。
处理器内部的拓扑如下。
- 核(core):一个处理器包含多个核,每个核有独立的一级缓存,所有核共享二级缓存。
- 硬件线程:也称为逻辑处理器或者虚拟处理器,一个处理器或者核包含多个硬件线程,硬件线程共享一级缓存和二级缓存。MIPS处理器的叫法是同步多线程(Simultaneous Multi-Threading,SMT),英特尔对它的叫法是超线程。
当一个进程在不同的处理器拓扑层次上迁移的时候,付出的代价是不同的。
- 如果从同一个核的一个硬件线程迁移到另一个硬件线程,进程在一级缓存和二级缓存中的数据可以继续使用。
- 如果从同一个处理器的一个核迁移到另一个核,进程在源核的一级缓存中的数据失效,在二级缓存中的数据可以继续使用。
- 如果从同一个NUMA节点的一个处理器迁移到另一个处理器,进程在源处理器的一级缓存和二级缓存中的数据失效。
- 如果从一个NUMA节点迁移到另一个NUMA节点,进程在源处理器的一级缓存和二级缓存中的数据失效,并且访问内存可能变慢。
可以看出处理器拓扑层次越高,迁移进程付出的代价越大。
调度域和调度组
软件看到的处理器是最底层的处理器。
- 如果处理器支持硬件线程,那么最底层的处理器是硬件线程。
- 如果处理器不支持硬件线程,支持多核,那么最底层的处理器是核。
- 如果处理器不支持多核和硬件线程,那么最底层的处理器是物理处理器。
本书中的描述基于“处理器支持多核和硬件线程”这个假设。
内核按照处理器拓扑层次划分调度域层次,每个调度域包含多个调度组,调度组和调度域的关系如下。
- 每个调度组的处理器集合是调度域的处理器集合的子集。
- 所有调度组的处理器集合的并集是调度域的处理器集合。
- 不同调度组的处理器集合没有交集。
如果我们把硬件线程、核、物理处理器和NUMA节点都理解为对应层次的处理器,那么可以认为:调度域对应更高层次的一个处理器,调度组对应本层次的一个处理器。一个硬件线程调度域对应一个核,每个调度组对应核的一个硬件线程;一个核调度域对应一个物理处理器,每个调度组对应物理处理器的一个核;一个处理器调度域对应一个NUMA节点,每个调度组对应NUMA节点的一个处理器。
每个处理器有一个基本的调度域,它是硬件线程调度域,向上依次是核调度域、处理器调度域和NUMA节点调度域。
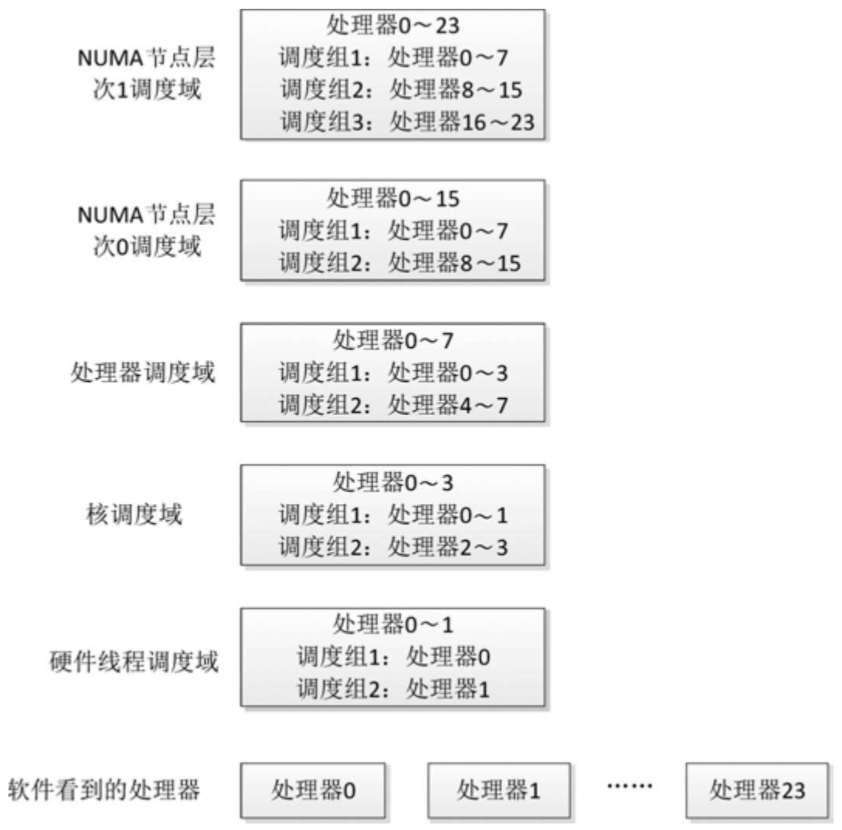
举例说明:假设系统只有一个处理器,处理器包含两个核,每个核包含两个硬件线程,软件看到的处理器是硬件线程,即处理器0~3,调度域层次树如图所示。
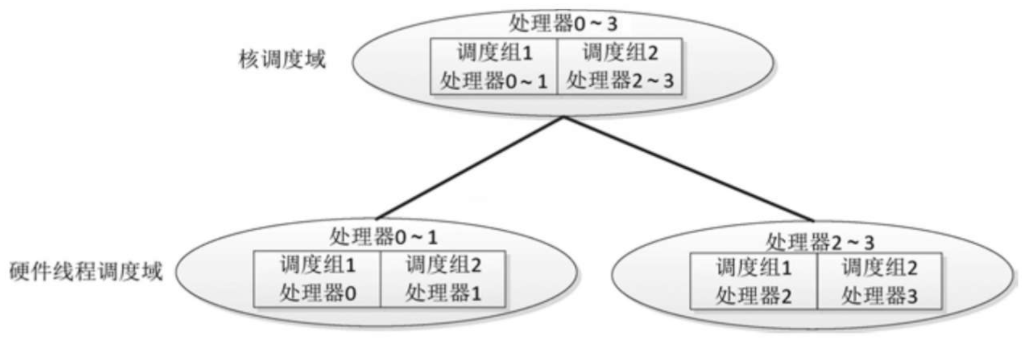
- 两个硬件线程调度域:一个硬件线程调度域包含处理器0~1,分为两个调度组,调度组1包含处理器0,调度组2包含处理器1;另一个硬件线程调度域包含处理器2~3,分为两个调度组,调度组1包含处理器2,调度组2包含处理器3。
- 一个核调度域包含处理器0~3,分为两个调度组,调度组1包含处理器0~1,调度组2包含处理器2~3。
考虑到NUMA节点之间的距离不同,把NUMA节点调度域划分为多个层次,算法是:把节点0到其他节点之间的距离按从小到大排序,去掉重复的数值,如果有n个距离值,记为数组d[n],那么划分n个层次,层次i(0 <= i < n)的标准是节点之间的距离小于或等于d[i]。
算法假设:节点0到节点j的距离在任意节点i到节点j的距离之中是最大的。
举例说明1:假设系统划分为3个NUMA节点,节点编号是0~2,节点0到节点1的距离是100,节点0到结节2的距离是200,那么划分2个NUMA节点调度域层次。
- 层次0的标准是节点之间的距离小于或等于100。
- 层次1的标准是节点之间的距离小于或等于200。
举例说明2:以举例说明1作为基础,每个NUMA节点包含2个处理器,每个处理器包含2个核,每个核包含2个硬件线程,总共24个硬件线程,软件看到的处理器是最底层的硬件线程,即24个处理器。硬件线程0和1看到的调度域层次树如图所示。
负载均衡算法
计算公平运行队列的平均负载
把运行历史划分成近似1毫秒的片段,每个片段称为一个周期,为了方便执行移位操作,把一个周期定义为1024微秒。
一个周期的加权负载:load = 周期长度 × 处理器频率 × 公平运行队列的权重。
公平运行队列的加权负载总和:load_sum = load +(y × load_sum),其中y是衰减系数,y32=0.5。
把公式展开以后如下所示

加权时间总和:time_sum = 周期长度 + (y × time_sum)。
加权平均负载:load_avg = load_sum / time_sum。
计算处理器负载
基于上面的公平运行队列的加权平均负载,计算5种处理器负载,计算公式如下

其中i的取值是0~4, load_avg是根任务组的公平运行队列的加权平均负载。
5种负载的区别是,历史负载和当前负载的比例不同,i越大,历史负载占的比例越大,处理器负载曲线越平滑。在处理器不空闲、即将空闲和空闲等不同情况下实现负载均衡时,使用不同的处理器负载。
迁移线程
每个处理器有一个迁移线程,线程名称是“migration/<cpu_id>”,属于停机调度类,可以抢占所有其他进程,其他进程不可以抢占它。
迁移线程有两个作用。
- 调度器发出迁移请求,迁移线程处理迁移请求,把进程迁移到目标处理器。
- 执行主动负载均衡。
如图所示,每个处理器有一个停机工作管理器,成员thread指向迁移线程的进程描述符,成员works是停机工作队列的头节点,每个节点是一个停机工作,数据类型是结构体cpu_stop_work。
内核提供了两个添加停机工作的函数。
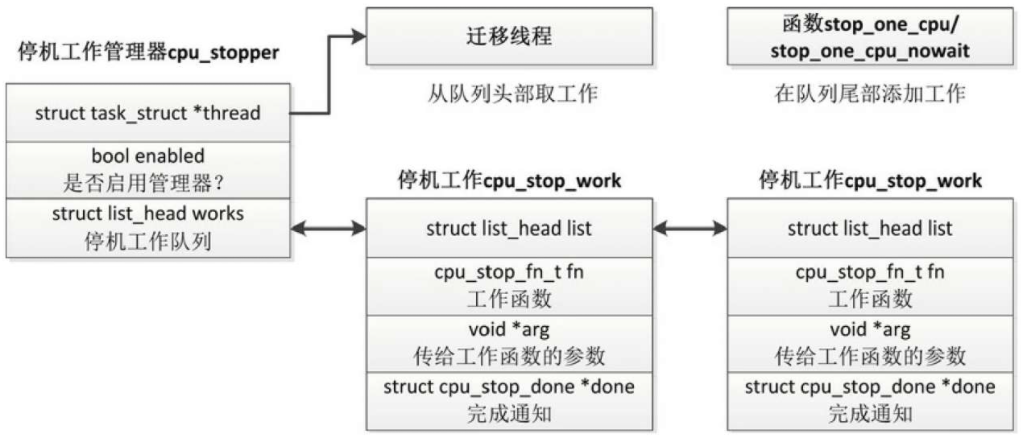
stop_one_cpu用来向指定处理器添加停机工作,并且等待停机工作完成。
1
int stop_one_cpu(unsigned int cpu, cpu_stop_fn fn, void *arg);
stop_one_cpu_nowait用来指定处理器添加停机工作, 但是不等待停机工作完成
1
bool stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg, struct cpu_stop_work *work_buf);
迁移线程的线程函数是smpboot_thread_fn,如果当前处理器的停机工作队列不是空的,重复执行下面的步骤
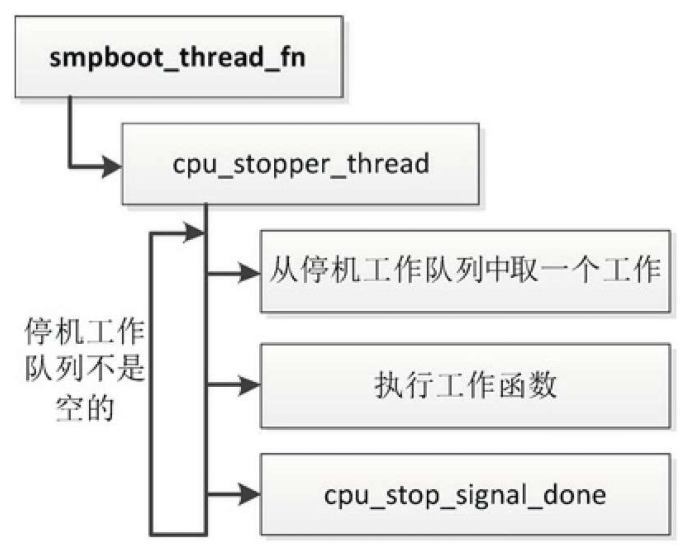
- 从停机工作队列中取一个工作。
- 执行工作函数。
- 如果发起请求的进程正在等待,那么发送处理完成的通知。
调用系统调用sched_setaffinity以设置进程的处理器亲和性时,如果进程正在执行或者被唤醒,假设进程在处理器n上,调度器就会向处理器n的迁移线程发出迁移请求:“向处理器n的停机工作队列添加一个工作,工作函数是migration_cpu_stop”,然后唤醒处理器n的迁移线程,等待迁移线程处理完迁移请求。
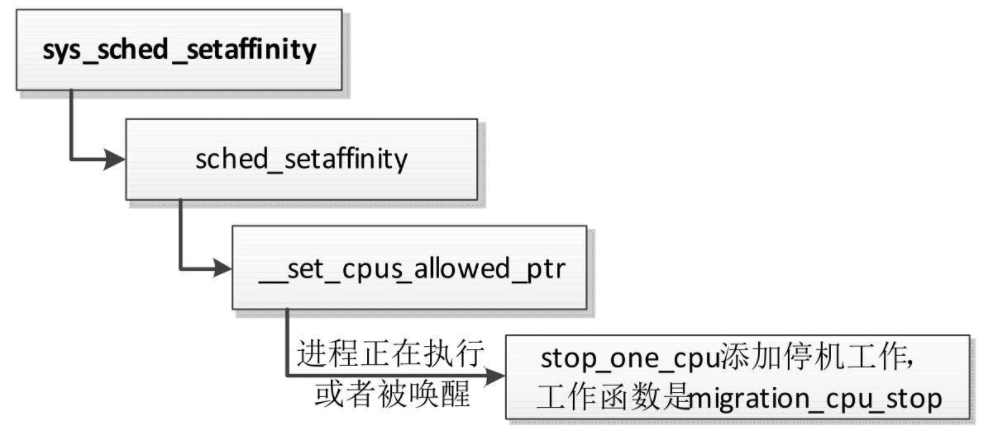
函数migration_cpu_stop负责把进程从当前处理器迁移到目标处理器,参数的类型是结构体migration_arg,成员task是需要迁移的进程,成员dest_cpu是目标处理器

- 检查进程p是否在当前处理器上。
- 如果进程p在当前处理器的运行队列中,那么把进程p迁移到目标处理器,从当前处理器的运行队中列删除,添加到目标处理器的运行队列中。
- 如果进程p正在睡眠,那么使用进程描述符的成员wake_cpu记录目标处理器,等到唤醒进程p的时候迁移到目标处理器。
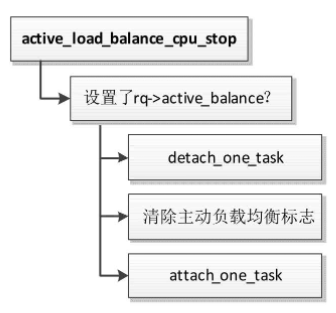
公平调度类执行处理器负载均衡失败的时候,为最忙处理器设置主动负载均衡标志,唤醒最忙处理器的迁移线程。函数active_load_balance_cpu_stop负责执行主动负载均衡,执行流程如图所示,先判断运行队列是否设置了主动负载均衡标志,如果设置了,那么从当前处理器的运行队列中选择一个公平调度类的进程,清除运行队列的主动负载均衡标志,把进程迁移到目标处理器。
隔离处理器
有时我们想把一部分处理器作为专用处理器,比如在网络设备上为了提高转发速度,让一部分处理器专门负责转发报文,实现方法是在引导内核时向内核传递参数“isolcpus=<CPU列表>”,隔离这些处理器,被隔离的处理器不会参与SMP负载均衡。如果没有把进程绑定到被隔离的处理器,那么不会有进程在被隔离的处理器上执行。
CPU列表有下面3种格式。
<cpu number>, ..., <cpu number>- 按升序排列的范围:
<cpu number>-<cpu number> - 混合格式:
<cpu number>, ..., <cpu number>-<cpu number>
例如“isolcpus=1,2,10-20”表示隔离处理器1、2和10~20。
国内查看评论需要代理~