Flink设计理念与基本架构
Flink与主流计算引擎对比
Hadoop MapReduce
MapReduce是由谷歌首次在论文“MapReduce: Simplified Data Processing on Large Clusters”(谷歌大数据三驾马车之一)中提出的,是一种处理和生成大数据的编程模型。
Hadoop MapReduce借鉴了谷歌这篇论文的思想,将大的任务分拆成较小的任务后进行处理,因此拥有更好的扩展性。
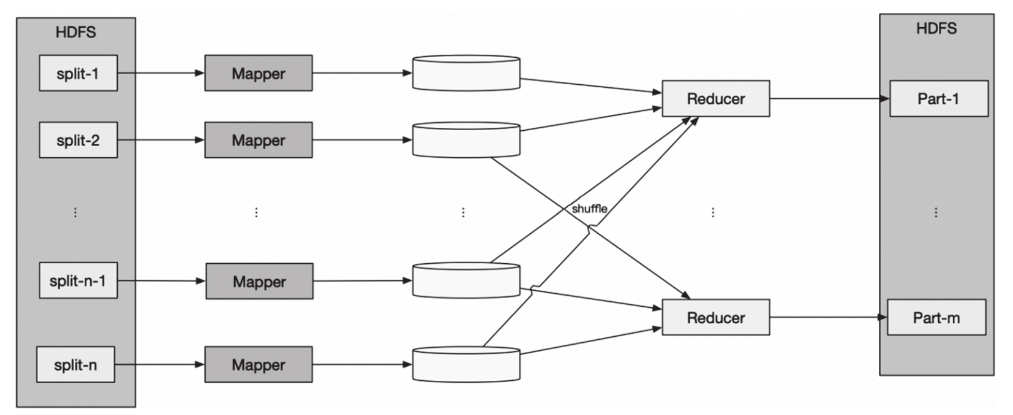
如图所示,Hadoop MapReduce包括两个阶段——Map和Reduce:Map阶段将数据映射为键值对(key/value),map函数在Hadoop中用Mapper类表示;
Reduce阶段使用shuffle后的键值对数据,并使用自身提供的算法对其进行处理,得到输出结果,reduce函数在Hadoop中用Reducer类表示。
其中shuffle阶段对MapReduce模式开发人员透明。
Spark
Spark是由加州大学伯克利分校开源的类Hadoop MapReduce的大数据处理框架。与Hadoop MapReduce相比,它最大的不同是将计算中间的结果存储于内存中,而不需要存储到HDFS中。Spark的基本数据模型为RDD(Resilient Distributed Dataset,弹性分布式数据集)。
RDD是一个不可改变的分布式集合对象,由许多分区(partition)组成,每个分区包含RDD的一部分数据,且每个分区可以在不同的节点上存储和计算。
在Spark中,所有的计算都是通过RDD的创建和转换来完成的。
Spark Streaming是在Spark Core的基础上扩展而来的,用于支持实时流式数据的处理。

如图所示,Spark Streaming对流入的数据进行分批、转换和输出。微批处理无法满足低延迟的要求,只能算是近实时计算。
Structured Streaming是基于Streaming SQL引擎的可扩展和容错的流式计算引擎。
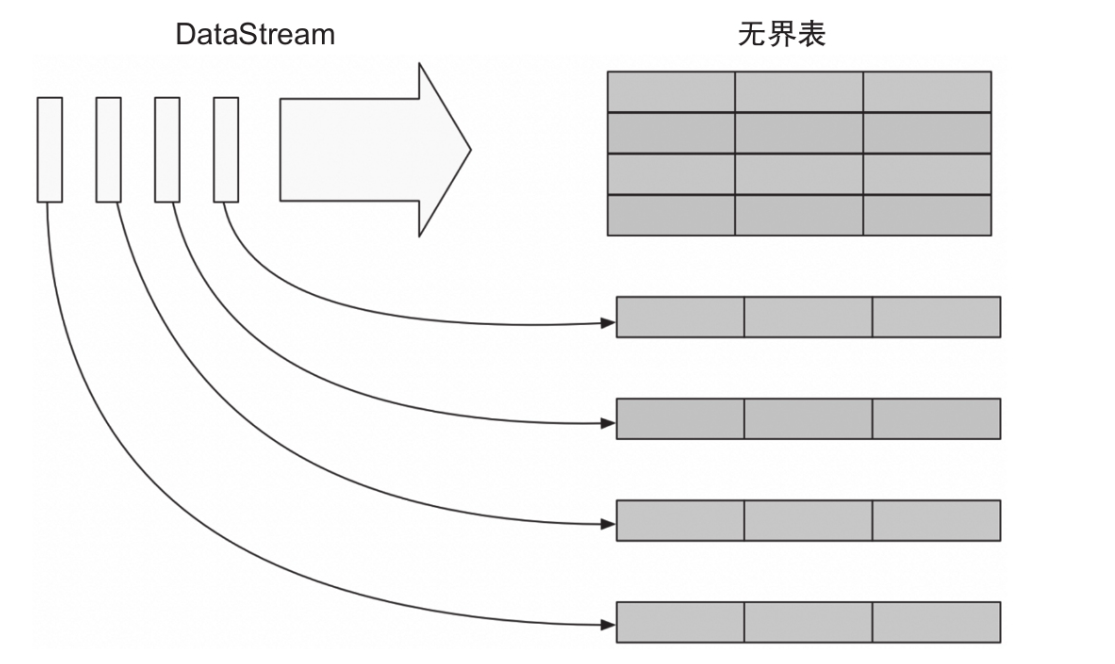
如图所示,Structured Streaming将流式的数据整体看成一张无界表,将每一条流入的数据看成无界的输入表,对输入进行处理会生成结果表。
生成结果表可以通过触发器来触发,目前支持的触发器都是定时触发的,整个处理类似Spark Streaming的微批处理;从Spark 2.3开始引入持续处理。
持续处理是一种新的、处于实验状态的流式处理模型,它在Structured Streaming的基础上支持持续触发来实现低延迟。
Flink
Flink是对有界数据和无界数据进行有状态计算的分布式引擎,它是纯流式处理模式。
流入Flink的数据会经过预定的DAG(Directed Acyclic Graph,有向无环图)节点,Flink会对这些数据进行有状态计算,整个计算过程类似于管道。
每个计算节点会有本地存储,用来存储计算状态,而计算节点中的状态会在一定时间内持久化到分布式存储,来保证流的容错
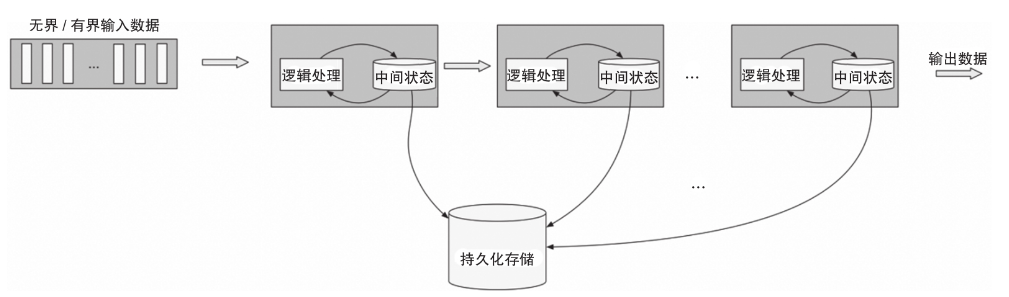
如图所示。这种纯流式模式保证了Flink的低延迟,使其在诸多的实时计算引擎竞争中具有优势。
Flink基本架构
分层架构
Flink是分层架构的分布式计算引擎,每层的实现依赖下层提供的服务,同时提供抽象的接口和服务供上层使用。
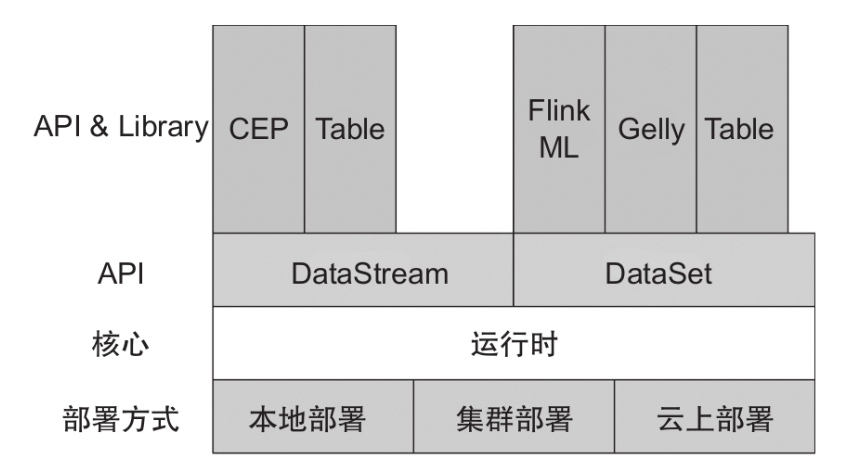
部署:Flink支持本地运行,支持Standalone集群以及YARN、Mesos、Kubernetes管理的集群,还支持在云上运行。(注:Flink部署模式会在第8章详细介绍。)
核心:Flink的运行时是整个引擎的核心,是分布式数据流的实现部分,实现了运行时组件之间的通信及组件的高可用等。
API:DataStream提供流式计算的API,DataSet提供批处理的API,Table和SQL API提供对Flink流式计算和批处理的SQL的支持。
Library:在Library层,Flink提供了复杂事件处理(CEP)、图计算(Gelly)及机器学习库。
运行时架构
Flink运行时架构经历过一次不小的演变。在Flink 1.5版本之前,运行时架构如图所示
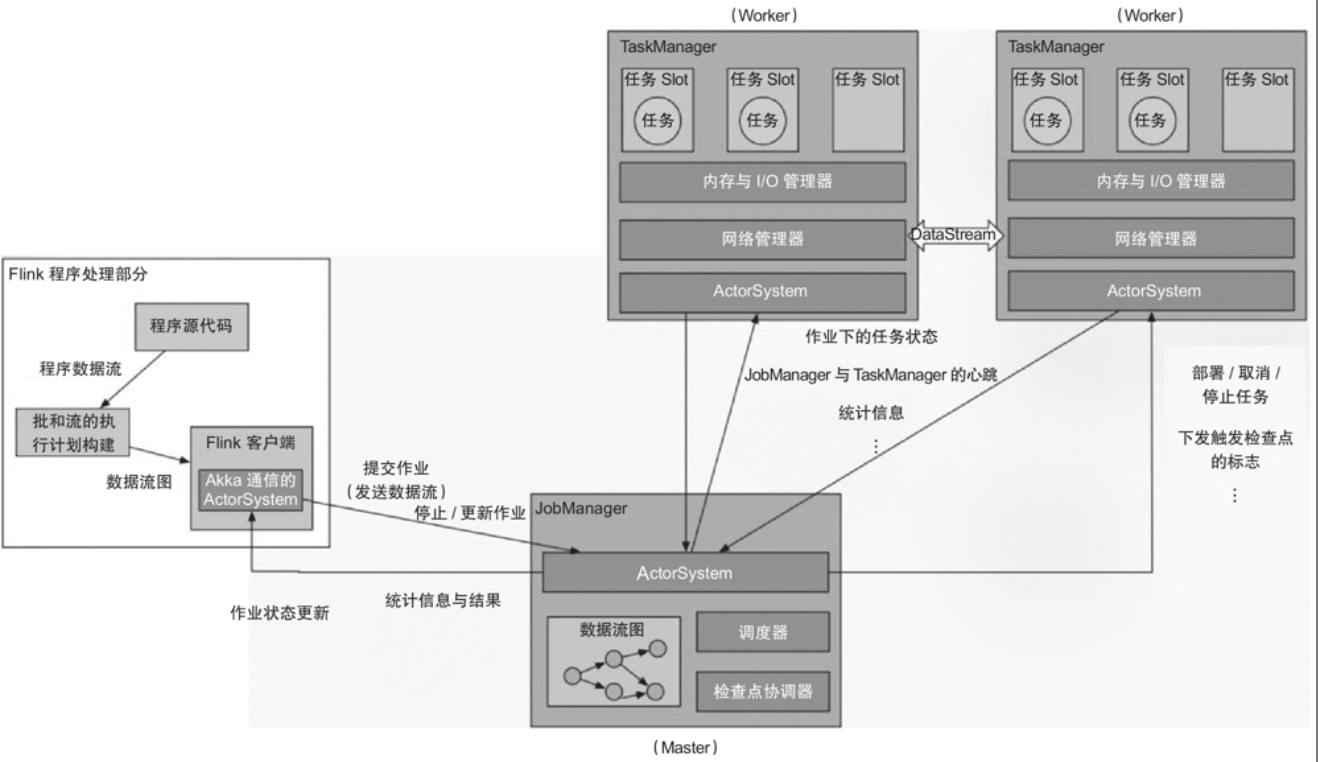
Client负责编译提交的作业,生成DAG,并向JobManager提交作业,往JobManager发送操作作业的命令。
JobManager作为Flink引擎的Master角色,主要有两个功能:作业调度和检查点协调。
TaskManager为Flink引擎的Worker角色,是作业实际执行的地方。TaskManager通过Slot对其资源进行逻辑分割,以确定TaskManager运行的任务数量。
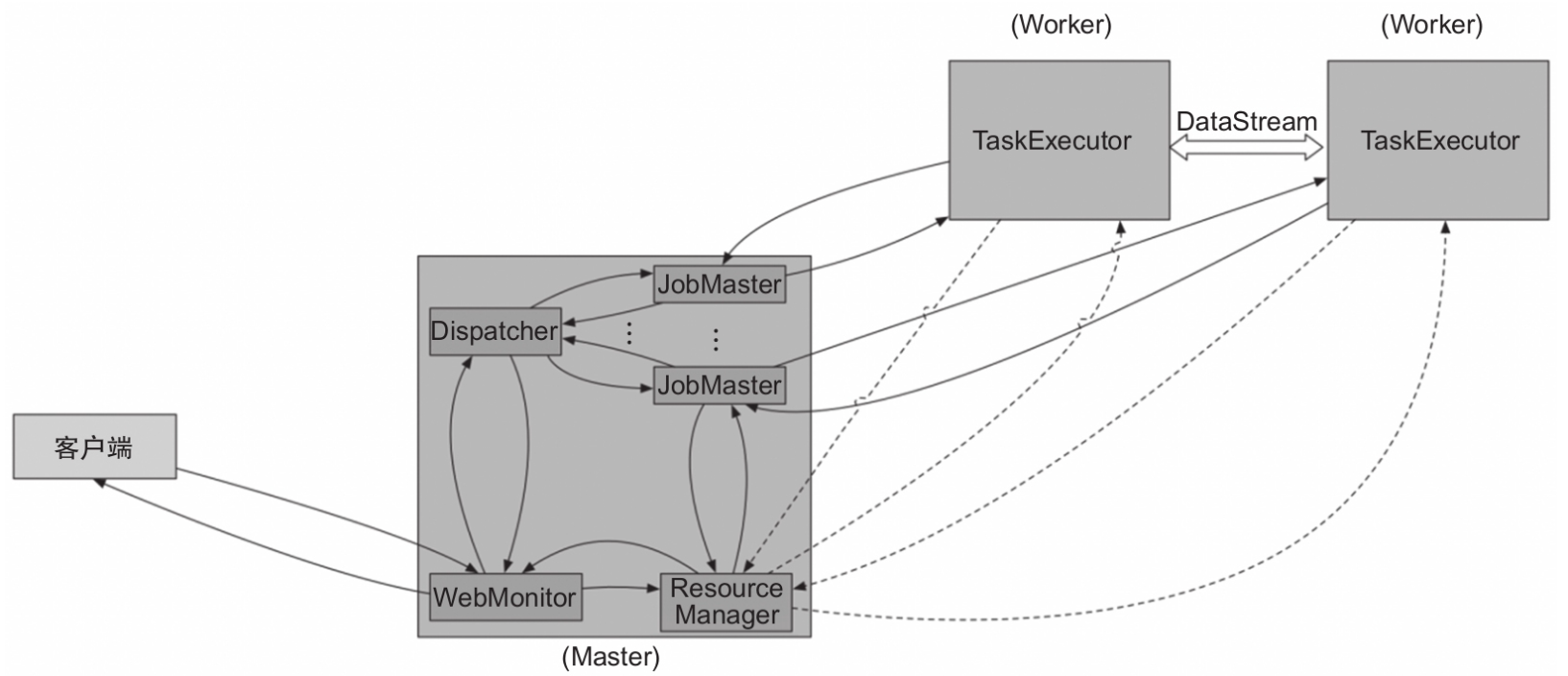
从Flink 1.5开始,Flink运行时有两种模式,分别是Session模式和Per-Job模式。
- Session模式:在Flink 1.5之前都是Session模式,1.5及之后的版本与之前不同的是引入了Dispatcher。Dispatcher负责接收作业提交和持久化,生成多个JobManager和维护Session的一些状态,如图所示。
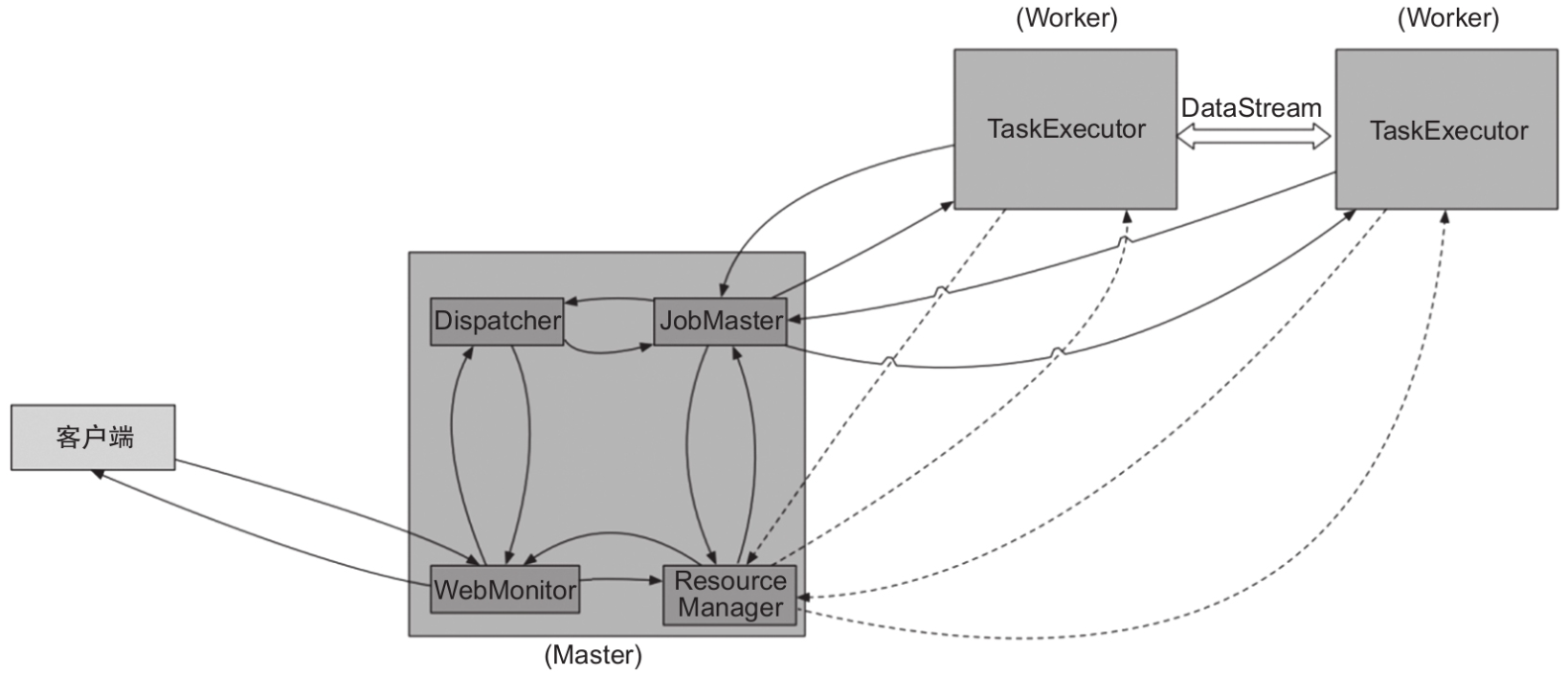
- Per-Job模式:该模式启动后只会运行一个作业,且集群的生命周期与作业的生命周期息息相关,而Session模式可以有多个作业运行、多个作业共享TaskManager资源,如图所示
编程模型与API
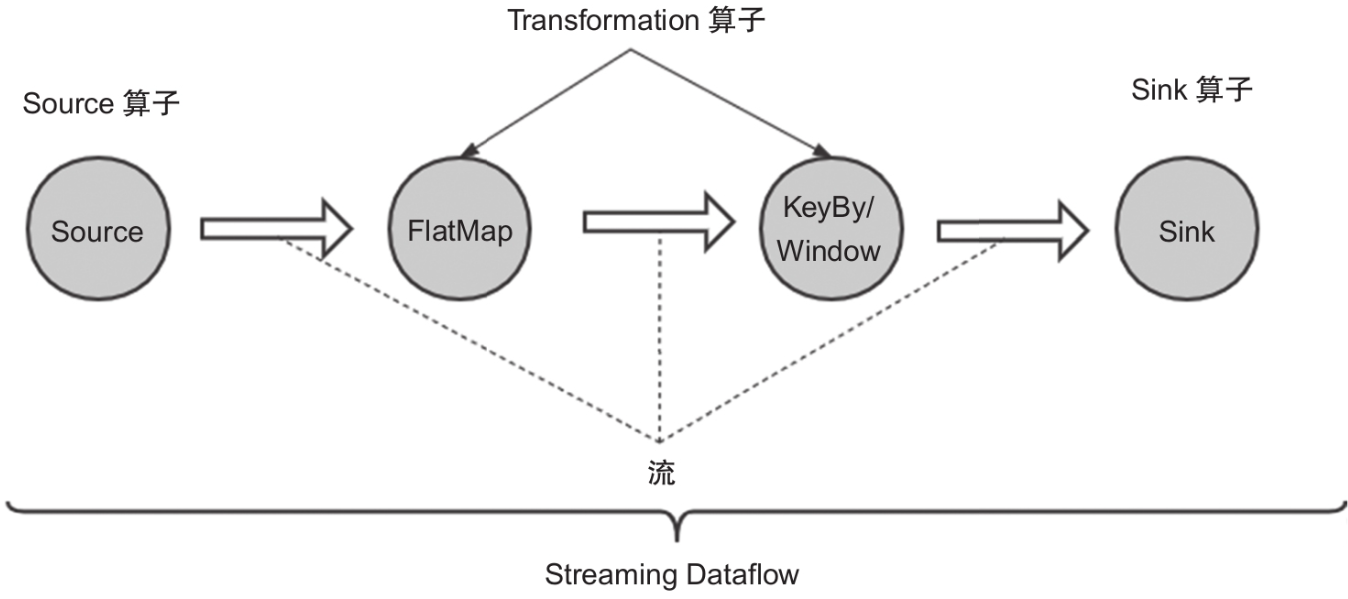
Flink中的主要概念和接口都是围绕DataStream展开
DataStream
在Flink中用DataSet和DataStream来表示数据集,DataSet表示有界的数据,DataStream表示无界的数据。
当然这只是概念层面的抽象,DataStream并没有真正的数据。DataStream通过初始化Source来构造,通过一系列的转换来表达计算过程,最后通过Sinker把结果输出到外部系统。
Flink内部集成了大量与外部系统交互的Source和Sink,这部分对应Flink中的Connectors模块;还有大量的Transformation,这部分对应Flink中的算子(Operator)。
1 | import org.apache.flink.api.common.functions.FlatMapFunction; |
在这个例子中,env.socketTextStream方法(从socket得到数据)得到DataStream,然后经过DataStream的各种转换,这里有flatMap、keyBy、window等转换,最后通过print把结果输出到标准输出。
上面的例子是通过socketTextStream从网络端口读取数据得到DataStream,还有一些其他方式
比如:通过读取文件,readFile (fileInputFormat, path);通过读取集合数据集,fromCollection (Collection)。
当然也可以通过方法StreamExecutionEnvironment.addSource (sourceFunction)来定制数据的读取,用户需要实现SourceFunction接口。
我们来看下这个方法是怎么得到DataStream的,关键代码如下:1
2
3
4
5
6
7public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function,
String sourceName, TypeInformation<OUT> typeInfo) {
// 此处省略不相关的代码
clean(function);
final StreamSource<OUT, ?> sourceOperator = new StreamSource<>(function);
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName);
}
可以看到该方法新建了一个DataStreamSource。
继续看DataStreamSource你会发现,它继承了SingleOutputStreamOperator(这个类从命名看不是很清楚,很容易让人把它误认为是个算子,但实际上它是个DataStream子类),这样我们就得到了一个DataStream。
DataStream之间是怎么相互转换的呢?来看DataStream的flatMap方法
1 | public <R> SingleOutputStreamOperator<R> flatMap(FlatMapFunction<T, R> flatMapper) { |
这里构造了一个StreamFlatMap类型的算子,然后继续调用transform方法。我们接着看transform方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public <R> SingleOutputStreamOperator<R> transform(String operatorName,
TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {
//构造Transformation
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operator,
outTypeInfo,
environment.getParallelism());
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(
environment, resultTransform);
// 把所有的Transformation都保存到StreamExecutionEnvironment中
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
可以看到其中最主要的工作是基于刚才的算子新建了一个OneInputTransformation,然后把该Transformation保存下来。
那么StreamExecutionEnvironment中保存的Transformation用来做什么呢?实际上Flink根据这些Transformation生成整个运行的拓扑,整个生成过程大致如下:
- 1)根据Transformation生成StreamGraph;
- 2)根据StreamGraph生成JobGraph;
- 3)根据JobGraph生成可以调度运行的ExecutionGraph。
这里用户的执行代码FlatMapFunction实际上是通过先传递给算子,然后由算子来调用执行的。
最后本例通过dataStream.print()将结果输出。
同样Flink提供了很多API来把结果写到外部系统,
- writeAsText():输出字符串到文件。
- writeAsCsv():输出CSV格式文本。
- print()/printToErr():标准输出/标准错误输出。
- writeToSocket():输出到socket。
- addSink():addSink与addSource一样,提供可以供用户扩展的输出方式,用户需要实现SinkFunction接口。
算子
DataStream的相互转换会生成算子,Flink中DataStream的转换有哪些,会生成哪些算子。这只选择一些有代表性的转换进行解释说明。
StreamFlatMap
flatMap作用:循环遍历Map中的元素并用相应的函数进行处理。该方法会生成算子StreamFlatMap。
1 | dataStream.flatMap(new FlatMapFunction<String, String>() { |
keyBy规则分区
keyBy作用:按一定规则分区,比如常用的根据某个字段进行keyBy操作,Flink会根据该字段值的hashCode进行分区。
1 | public static int computeOperatorIndexForKeyGroup(int maxParallelism, |
这里的keyGroupId就是根据字段的hashCode和Flink的最大并行度计算出来的。1
2dataStream.keyBy("someKey")
dataStream.keyBy(0)
该方法并不会生成一个算子,也就是说keyBy并没有生成运算拓扑的节点;
但是keyBy依然生成了Transformation,也就是说它规定了上下两个节点数据的分区方式。
Flink还有其他几种分区方式。
- rebalance:重新平衡分区,用于均衡数据,保证下游每个分区(在流系统中基本可以认为分区和并发是一个概念)的负载相同。
- broadcast:广播分区,将输出的每条数据都发送到下游所有分区。
- shuffle:随机分区,将输出的数据随机分发到下游分区。
- forward:本地分区,将输出的数据分发到本地分区。
- rescale:重新缩放分区,上下游根据分区数量分配对应的分配方式,然后循环发送。比如,如果上游分区为2,而下游分区为4,那么一个上游分区会把数据分发给两个下游分区,而另一个上游分区则把数据分发给其他两个下游分区,分区方式是循环分发。反之,如果下游操作的分区为2,而上游操作的分区为4,那么两个上游分区会把数据分发给一个下游分区,而另两个上游分区则把数据分发给另一个下游分区。
- global:全局分区,所有数据进入下游第一个分区。
在Flink实现中,StreamPartitioner是分区接口类,每种分区对应一个StreamPartitioner的实现类。
我们来看下rebalance对应的RebalancePartitioner。
1 | public DataStream<T> rebalance() { |
可以看到设置了分区方式,分区方式(要注意的是StreamPartitioner并不是算子)就是RebalancePartitioner。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class RebalancePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo;
public void setup(int numberOfChannels) {
super.setup(numberOfChannels);
nextChannelToSendTo = ThreadLocalRandom.current().nextInt(numberOfChannels);
}
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;
return nextChannelToSendTo;
}
}
主要方法selectChannel的源代码实现比较简单,就是随机选择下发的分区。
aggregation聚合计算
1 | keyedStream.sum(0); |
该方法会生成算子StreamGroupedReduce,包括fold、reduce及aggregation,只能作用于KeyedStream。
需要注意的一点是,这些聚合计算都是针对某个键(Key)的,如果要求全局的最大值、最小值,该方法是无法做到的。
window及window apply
根据窗口聚合计算数据
1 | dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))); |
该方法会生成窗口。
窗口分为Keyed Window和Non-Keyed Window(用WindowAll转换得到),二者的区别在于使用window转换之前是否进行keyBy操作。
窗口将会在后面详细介绍。
union
合并多个DataStream。1
dataStream.union(otherStream1, otherStream2, ...);
该方法有个有意思的使用方式是可以合并数据本身,这样就可以得到一个两倍数据的流。该方法同样不会产生算子。
window join
通过给定的键和窗口关联两个DataStream。
1 | dataStream.join(otherStream) |
这里我们通过一个例子来看下Flink中window join是怎么实现的。
假如我们有streamA(图中用深灰色元素表示)和streamB(图中用浅灰色元素表示)经过window join处理,伪代码如下(这段代码的主要内容就是两个流进行window join处理的用法示例):
1 | DataStream<Integer> streamA = ... |
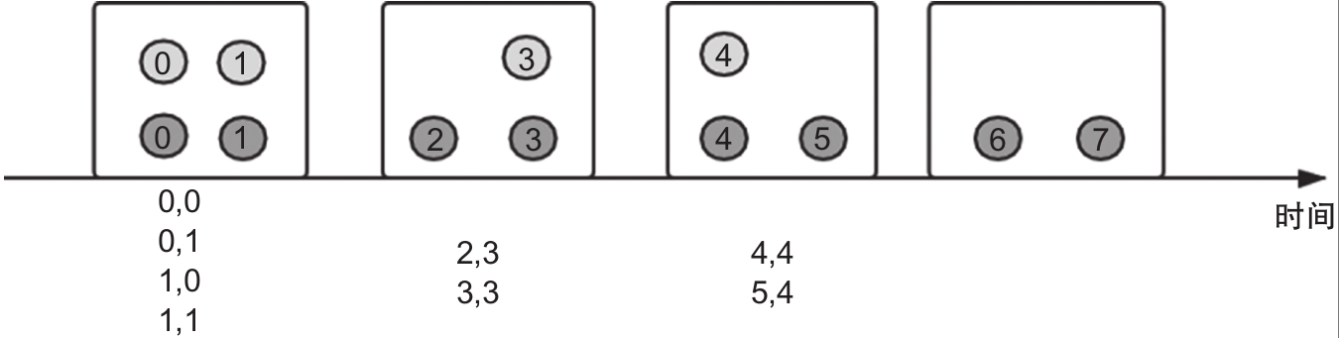
圆圈内的数字表示数据元素本身及事件时间,经过处理之后得到图下方给出的数字组合(这里假设图中给定的同一个窗口内数据的键是一样的,即每个窗口内的数据都满足join条件)。
可以看出这里join的行为和普通的inner join非常类似。
为了更好地理解join的结果,我们来看下其源代码实现。window join实现可以从JoinedStreams的apply方法着手。
1 | public <T> DataStream<T> apply(JoinFunction<T1, T2, T> function, |
这里可以看到window join是通过coGroup来实现的,生成一个CoGroupedStreams,然后应用JoinCoGroupFunction。
那么coGroup又是怎么实现window join的呢?
我们继续来看CoGroupedStreams的apply方法(略去了无关代码):
1 | public <T> DataStream<T> apply(CoGroupFunction<T1, T2, T> function, |
这部分代码非常清楚地展示了其实现过程:代码1调用union把两个DataStream联合在一起,代码2生成一个WindowedStream,代码3对WindowedStream执行窗口函数。
window join本质上还是通过union和window等更基础的算子实现的。
我们再来看一下这个过程中传入的JoinCoGroupFunction:1
2
3
4
5
6
7
8
9
10
11
12
13
14private static class JoinCoGroupFunction<T1, T2, T>
extends WrappingFunction<JoinFunction<T1, T2, T>>
implements CoGroupFunction<T1, T2, T> {
public void coGroup(Iterable<T1> first, Iterable<T2> second,
Collector<T> out) throws Exception {
for (T1 val1: first) {
for (T2 val2: second) {
out.collect(wrappedFunction.join(val1, val2));
}
}
}
}
这个函数就是图描述的不同数据相互连接配对的实现逻辑。
window join的窗口还可以是滑动窗口、会话窗口,这里不再详细讲解,实现原理基本一样。
interval join
通过给定的键和时间范围连接两个DataStream。假如有数据e1和e2分别来自两个DataStream,那么要让两个数据可以连接输出,需要
1 | e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound |
interval join只支持基于事件时间的范围。1
2
3
4
5keyedStream.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2)) // 下界和上界
.upperBoundExclusive(true) // 可选
.lowerBoundExclusive(true) // 可选
.process(new IntervalJoinFunction() {...});
Flink API中实现了两种join:一种是window join,另一种就是interval join。
两种join最大的不同在于join的数据分组不一样:window join是在同一个时间窗口内连接;interval join是每个数据元素根据自己的时间都有一个join取值范围,这个范围是由lowerBound和upperBound决定的。
我们通过一个例子来直观地看下interval join的过程,然后分析其实现。
如图所示,我们有两个流streamA和streamB,其数据分别用深灰色和浅灰色的圆圈表示,圆圈中的数字代表数据元素本身及事件时间。
interval join的伪代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14DataStream<Integer> streamA = ...
DataStream<Integer> streamB = ...
streamA.keyBy(<KeySelector>)
.intervalJoin(streamB.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx,
Collector<String> out) {
out.collect(first + "," + second);
}
});
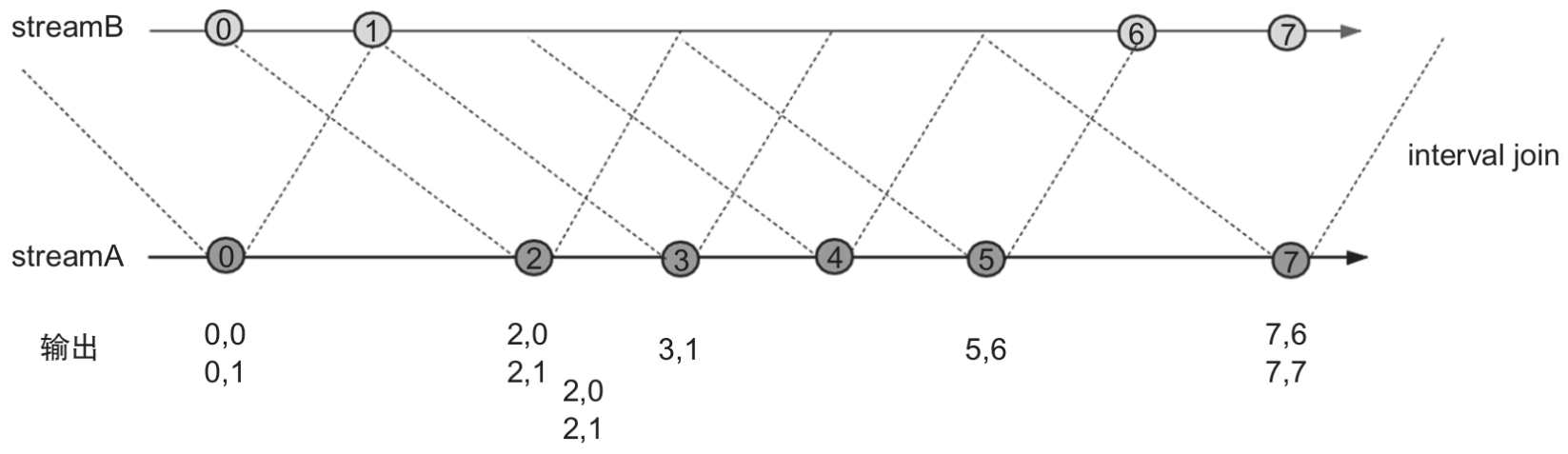
可以看到判断两个流的数据可以连接的依据是两个流的数据符合lowerBound和upperBound界定的范围,即1
streamA.data.ts + lowerBound <= streamB.data.ts.ts <= streamA.data.ts + upperBound
streamA的每个数据元素都可以根据lowerBound和upperBound在streamB上界定一个可以连接的范围,比如:当图中streamA的数据元素2被处理的时候,发现streamB的数据元素0和1满足界定范围,这时输出2,0和2,1
在图中streamB的数据元素1进入算子之后,也会根据范围界限找到符合范围条件的streamA的0数据元素,然后输出0,1。
我们接下来看下Flink中interval join是怎么实现的。
关键代码是IntervalJoinOperator中的processElement方法,实现过程与图给出的逻辑一致。
首先需要两个状态保存两个流的数据,这里用的是MapState;然后处理数据元素,遍历另一个流的数据,查询是否有满足界定范围的数据,如果有的话就将其发送出去;最后注册一个状态清理函数,用来清理掉永远无法连接上的过期数据。
这里只介绍了几个常用的Transformation和算子,像Connect、CoMap、Split、Select之类的操作和转换就不一一介绍了,有兴趣的可以通过官网和源代码学习了解。
窗口
窗口的基本概念
窗口是无边界流式系统中非常重要的概念,窗口把数据切分成一段段有限的数据集,然后进行计算。Flink中窗口按照是否并发执行,分为Keyed Window和Non-Keyed Window,它们的主要区别是有无keyBy动作。
Keyed Window可以按照指定的分区方式并发执行,所有相同的键会被分配到相同的任务上执行。
Non-Keyed Window会把所有数据放到一个任务上执行,并发度为1。
Keyed Window
1 | stream.keyBy(...) |
Non-Keyed Window
1 | stream.windowAll(...) // 接受WindowAssigner参数,用来分配窗口 |
因为实际生产中我们大多会使用Keyed Window,所以后续的解读都是针对Keyed Window展开的。
我们来看下上面提到的几个主要概念。
- WindowAssigner:窗口分配器。我们常说的滚动窗口、滑动窗口、会话窗口等就是由WindowAssigner决定的,比如TumblingEventTimeWindows可以产生基于事件时间的滚动窗口。
- Trigger:触发器。Flink根据WindowAssigner把数据分配到不同的窗口,还需要一个执行时机,Trigger就是用来判断执行时机的。Trigger类中定义了一些返回值类型,根据返回值类型来决定是否触发及触发什么动作。
- Evictor:驱逐器。在窗口触发之后,在调用窗口函数之前或者之后,Flink允许我们定制要处理的数据集合,Evictor就是用来驱逐或者过滤不需要的数据集的。
- Allowed Lateness:最大允许延迟。主要用在基于事件时间的窗口,表示在水位线到达之后的最长允许数据延迟时间。在最长允许延迟时间内,窗口都不会销毁。
- Window Function:窗口函数。用户代码执行函数,用来做真正的业务计算。
- Side Output:丢弃数据的集合。通过getSideOutput方法可以获取丢弃数据的DataStream,方便用户进行扩展。
窗口的执行流程
在深入介绍窗口之前,我们先从整体上看下窗口的执行过程,以便有个全局的概念。
从整体上介绍窗口的执行流程,如果其中有细节不清楚的地方,直接看后面几节,再回过头来看本节内容。
窗口本质上也是一个算子所以我们直接来看其实现类:EvictingWindowOperator和WindowOperator。
这两个类的区别是前者带驱逐器,后者不带。
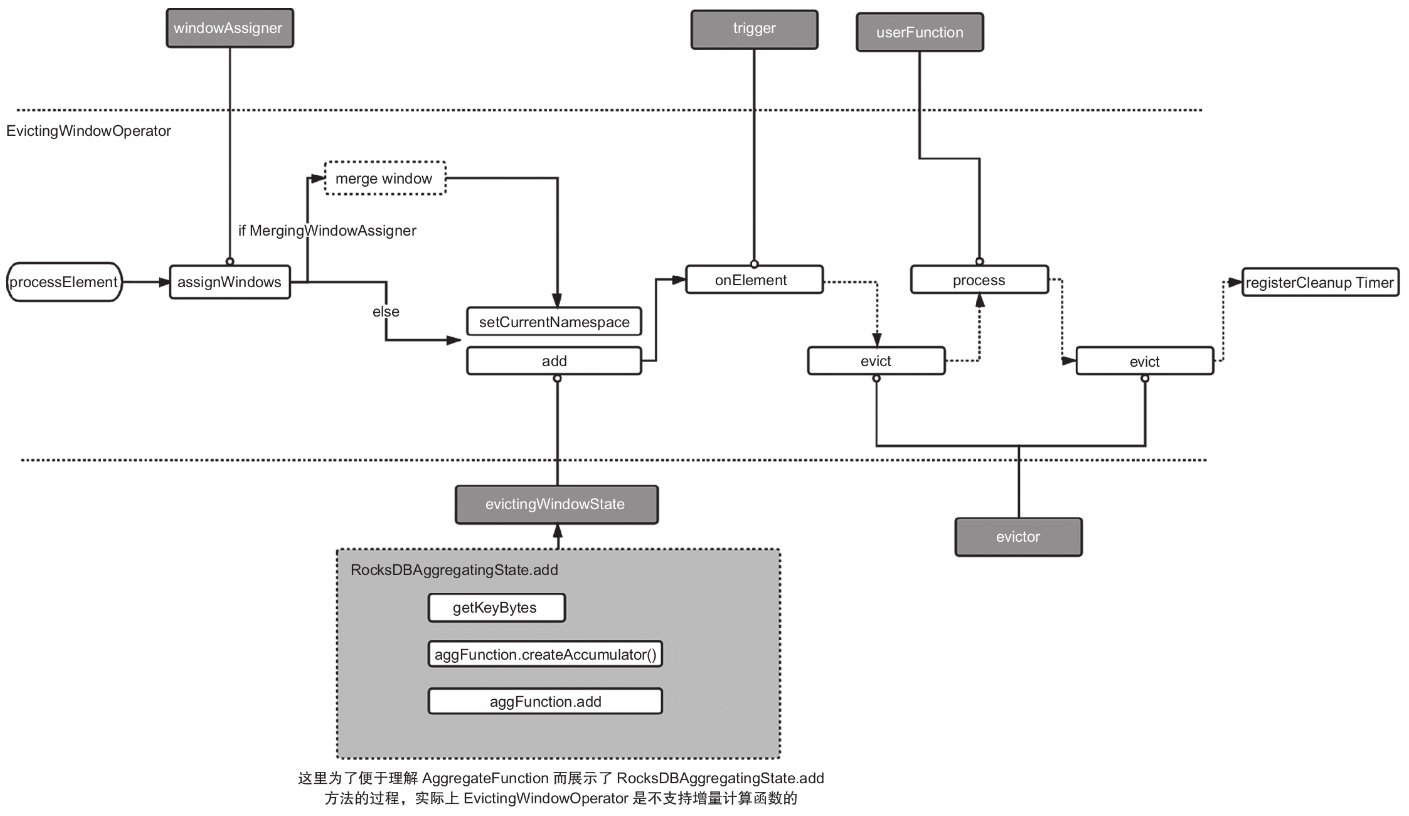
为了覆盖更多的场景,我们用EvictingWindowOperator来分析。 我们直接从算子最重要的方法processElement开始。
- 整个过程从分配窗口(WindowAssigner的主要作用)开始分配好窗口后,用当前窗口来设置窗口状态的命名空间;
- 之后把当前数据加入状态中(如果是聚合函数的话,还会有计算过程),并用当前数据去判断触发器是否触发,如果触发那就调用emitWindowContents方法处理数据,该方法的主要过程是调用驱逐器清除数据;
- 然后调用窗口函数计算结果;最后注册一个窗口本身的清除定时器。
1 | public void processElement(StreamRecord<IN> element) throws Exception { |
窗口分配器
主要介绍Flink中窗口分配器的作用及几种典型实现,这几种典型的实现实际上对应着几种典型的窗口。
熟悉流计算的读者可能知道,窗口(时间窗口)大致可以分为滑动窗口和滚动窗口。
那么这个分类是由什么决定的呢?
显然它是由数据分配到不同窗口的方式决定的。
在Flink中这个分配的动作就是由窗口分配器完成的。不同的窗口分配器实现类对应不同的窗口。
1 | public abstract class WindowAssigner<T, W extends Window> implements Serializable { |
其中最关键的是assignWindows方法,它用来分配窗口。我们来看几种常用的实现。
滚动窗口
Flink中有TumblingEventTimeWindows和TumblingProcessingTimeWindows两种滚动窗口(Tumbling Window),分别对应基于事件时间的滚动窗口和基于系统时间的滚动窗口。
这两种实现分配数据的策略实际上是一样的,只是基于的时间不同。
我们来看下TumblingEventTimeWindows的assignWindows方法:
1 | public Collection<TimeWindow> assignWindows(Object element, |
可以看到,其实现还是比较清楚的,根据窗口的大小(size)、偏移量(offset)、数据时间计算窗口的开始时间。
1 | public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) { |
返回一个TimeWindow。
滑动窗口
和滚动窗口一样,滑动窗口(Sliding Window)也有SlidingEventTimeWindows和Sliding-ProcessingTimeWindows两种实现,两种实现也基本是一样的。
我们来看SlidingProcessing-TimeWindows的assignWindows方法:
1 | public Collection<TimeWindow> assignWindows(Object element, long timestamp, |
首先我们看到一个最明显的区别是返回的TimeWindow个数不同,滚动窗口只返回一个,而滑动窗口返回多个,这也符合我们对滑动窗口的理解:滑动窗口是可以重叠的,一个数据可以落入多个窗口内(可以思考一下一个数据最多可以落入几个窗口内)。
与滚动窗口一样,计算最后一个窗口的开始时间,然后不断回溯(前一个窗口的开始时间减去滑动时间)寻找位于时间范围内的窗口,直到窗口的结束时间早于系统时间(或者事件时间)。
会话窗口
会话窗口(Session Window)是Flink中比较独特的窗口类型,其他流式系统不支持它,或支持得不够好。
会话窗口可以按照一个会话来分配数据,而会话的长度可以是固定的(EventTimeSessionWindows、ProcessingTimeSessionWindows),也可以是不断变化的(DynamicProcessingTimeSessionWindows、DynamicEventTimeSessionWindows)。
使用过会话的读者可能知道,只要不过期会话就可以一直存在,新的数据必然会加入某个会话,同时会导致会话的超时时间发生改变。
在Flink中,会话的不断变化就对应着会话窗口的不断合并。我们以EventTimeSessionWindows为例来看下会话窗口的实现,其中比较复杂的是窗口的合并。
会话窗口中数据的分配和滚动窗口很像,即返回一个计算好的窗口(TimeWindow)。1
2
3
4public Collection<TimeWindow> assignWindows(Object element, long timestamp,
WindowAssignerContext context) {
return Collections.singletonList(new TimeWindow(timestamp, timestamp + sessionTimeout));
}
窗口的分配过程结束后,会得到一个窗口。这个新分配的窗口属于哪个会话(真正的窗口)呢?
我们来看图中的例子(例子中sessionTimeout=3)。
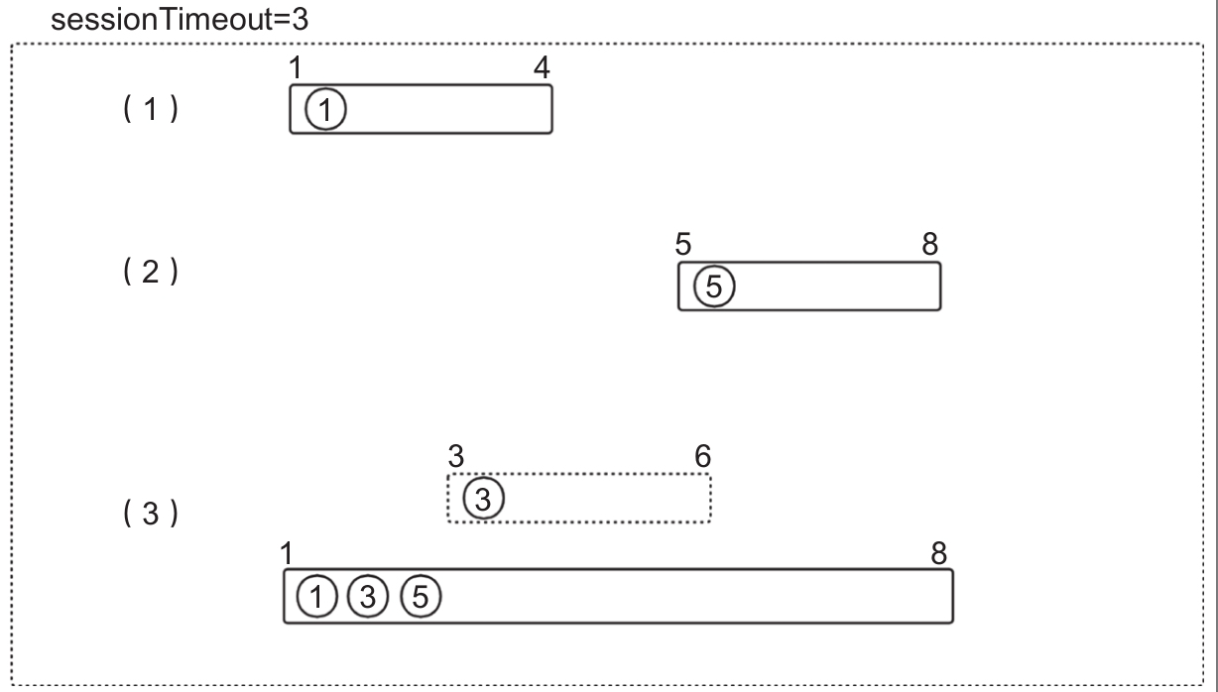
假如Flink接收到数据时间为1的数据(上图中的步骤1)(这里我们假设键相同或者是Non-Keyed Window),那么这个时候会生成TimeWindow(1,4),并处理数据时间为5的数据,生成TimeWindow(5,8);
然后继续处理时间为3的数据,这个时候应该生成TimeWindow(3,6)的窗口,但是由于TimeWindow(1,4)对应的会话还没有过期,应该把时间为3的数据归到这个会话中,所以Flink中进行TimeWindow的合并。
同理当TimeWindow(1,4)和TimeWindow(3,6)合并为TimeWindow(1,6)的时候,也应该将TimeWindow(5,8)同自己合并,这样最后合并为TimeWindow(1,8)。
当然不只是将TimeWindow合并,还需要将窗口对应的触发器、数据合并。
我们来看合并的关键代码,合并发生在数据被WindowOperator处理的过程中:
1 | W actualWindow = mergingWindows.addWindow(window, new MergingWindowSet.MergeFunction<W>() { |
其中关键的方法是MergingWindowSet的addWindow方法,其中TimeWindow合并的细节在其mergeWindows方法中,合并的规则就是我们上面介绍的。
合并的主要过程如下
- 找出合并之前的窗口集合和合并之后的窗口;
- 找出合并之后的窗口对应的状态窗口(方式是从合并窗口集合中挑选第一个窗口的状态窗口);
- 执行merge方法(合并窗口需要做的工作,也就是执行MergingWindowSet的addWindow方法)。
这里不好理解的是合并结果的窗口和结果对应的状态窗口(用来获取合并之后的数据),我们来看图
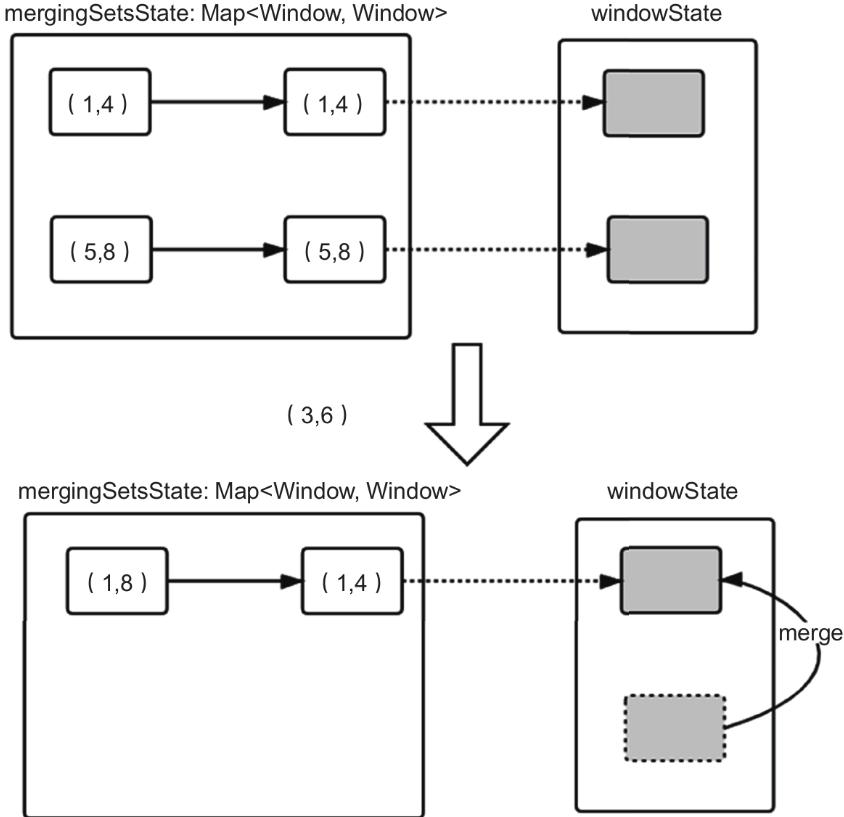
MergingWindowSet(窗口合并的工具类)中有个map,用来保存窗口和状态窗口的对应关系
那么怎么理解这个状态窗口呢?
如果我们在得到TimeWindow(1,4)时基于TimeWindow(1,4)在状态中保存了数据(数据A),也就是说状态的命名空间是TimeWindow(1,4),在得到TimeWindow(5,8)时基于TimeWindow(5,8)在状态中保存了数据(数据B),当第三个数据(数据C)来的时候,又经过合并窗口得到了TimeWindow(1,8)
那么怎么获取合并窗口的数据集AB呢?
显然我们还需要原来的TimeWindow(1,4)或者TimeWindow(5,8),原来的TimeWindow(1,4)在这里就是状态窗口。
这里窗口合并的同时会把窗口对应的状态所保存的数据合并到结果窗口对应的状态窗口对应的状态中。
这里有点绕,还是看图,最终合并窗口的结果窗口是TimeWindow(1,8)。
我们怎么获取TimeWindow(1,8)对应的数据集ABC呢?
这个时候可以通过MergingWindowSet中保存的TimeWindow(1,8)对应的状态窗口TimeWindow(1,4)来获取合并后的状态,即数据集ABC。
会话窗口的其他过程与滑动窗口及滚动窗口没有什么区别。
全局窗口
全局窗口(Global Window),顾名思义就是所有的元素都分配到同一个窗口中,我们常用的Count Window就是一种全局窗口。
其实现GlobalWindow的主要方法如下:
1 | public Collection<GlobalWindow> assignWindows(Object element, long timestamp, |
这里需要说明的是全局窗口和Non-Keyed Window是完全不同的概念:
- Non-Keyed Window是指并发为1的窗口,可以是滚动窗口或者滑动窗口;
- 而全局窗口既可以是Non-Keyed Window,也可以是Keyed Window。
触发器
触发器决定窗口函数什么时候执行以及执行的状态。
触发器通过返回值来决定什么时候执行,其返回值有如下几种类型。
- CONTINUE:什么也不做。
- FIRE:触发窗口的计算。
- PURGE:清除窗口中的数据。
- FIRE_AND_PURGE:触发计算并清除数据。
其接口定义如下(列出主要方法):
1 | public abstract class Trigger<T, W extends Window> implements Serializable { |
Flink实现了几种常用的触发器。
- EventTimeTrigger:当水位线大于窗口的结束时间时触发,一般用在事件时间的语义下。
- ProcessingTimeTrigger:当系统时间大于窗口结束时间时触发,一般用在系统时间的语义下。
- CountTrigger:当窗口中的数据量大于一定值时触发。
- DeltaTrigger:根据阈值函数计算出的阈值来判断窗口是否触发。
其中经常会用到的是根据系统时间和事件来判断窗口是否触发的触发器,我们来看下其实现过程。
我们先来看ProcessingTimeTrigger是怎么实现的。
1 |
|
在onElement方法中,调用triggerContext注册了窗户最大时间的定时器,tiggerContext中调用InternalTimerService来进行定时器注册。
InternalTimerService是Flink内部定时器的存储管理类。
整个调用及实现过程如图所示。
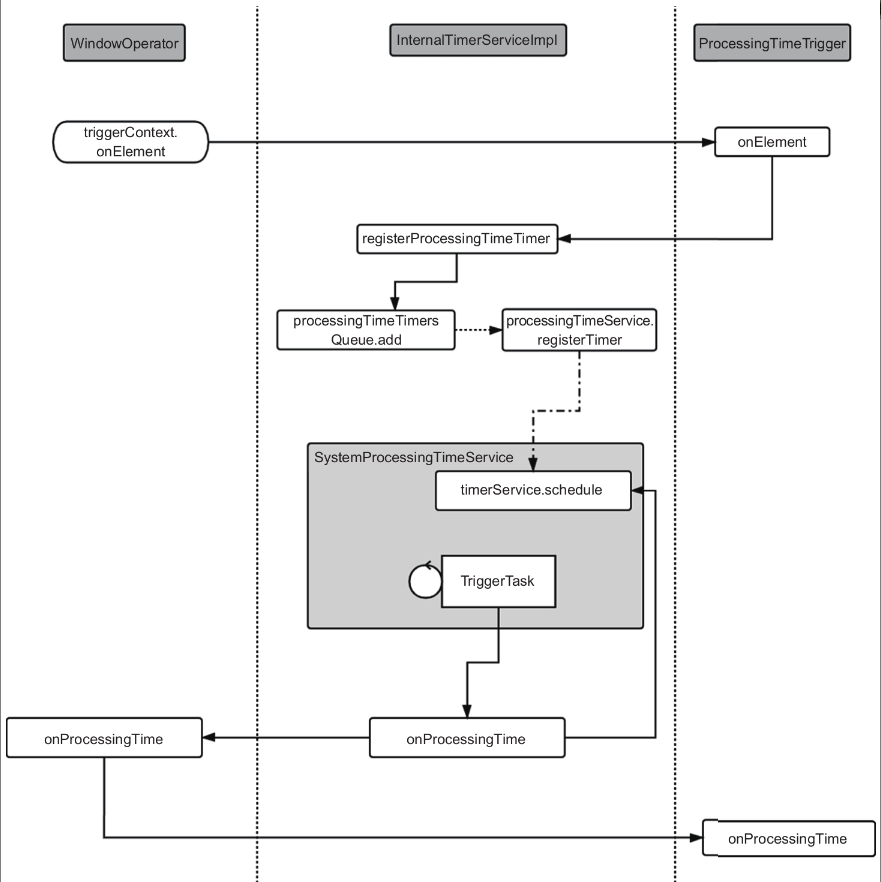
ProcessingTimeTriggerInternalTimerServiceImpl内部维护了一个有序的队列,用来存储定时器(TimerHeap-InternalTimer),并且利用ProcessingTimeService来延迟调度基于系统时间生成的Trigger-Task。
TriggerTask会调用InternalTimerServiceImpl的onProcessingTime方法,onProcessing-Time会调用真正的目标(WindowOperator)onProcessingTime方法,完成一次定时器的触发。
在InternalTimerServiceImpl调用onProcessingTime方法的过程中,会重设上下文(Context)的键,确保后续操作都是针对当前键对应的数据。
那么EventTimeTrigger和ProcessingTimeTrigger在实现上有什么不一样呢?
首先我们知道,基于事件时间的触发器必然与事件时间有关。而事件时间不是有序的,不能像系统时间那样,用延迟任务来触发。
么什么时候触发基于事件时间的定时器呢?
水位线(Watermark)在Flink中是用来推动基于事件时间的处理动作执行的,也就是说水位线代表了事件的最晚到达时间。
我们就可以采用水位线来触发基于事件时间的定时器,事实上Flink也是如此实现的,我们来看代码:
1 |
|
以上代码是EventTimeTrigger的onElement方法,与ProcessingTimeTrigger一样,如果条件不满足,那就调用TriggerContext来注册一个事件时间定时器,这里的依据是水位线是否大于窗口最大时间。
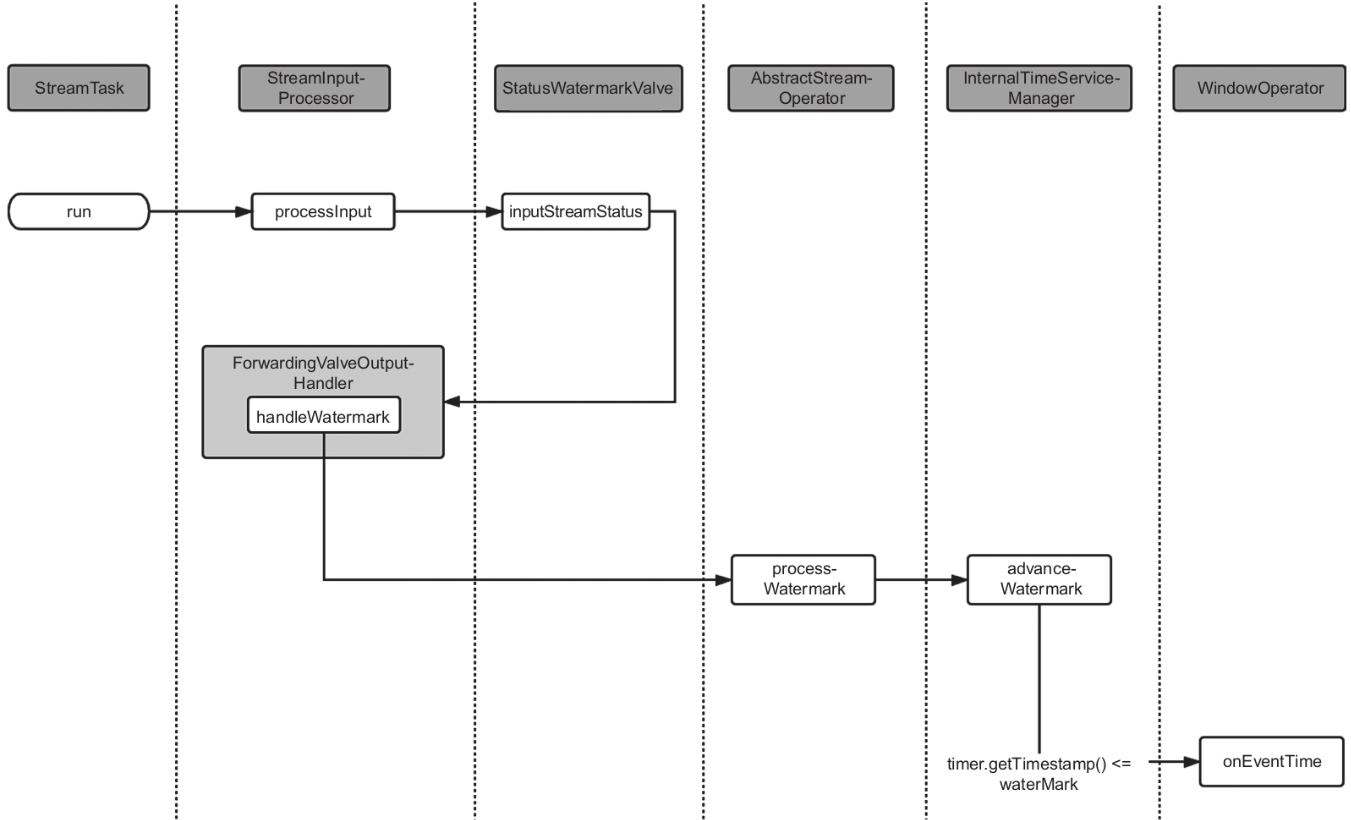
同样TriggerContext会调用InternalTimerServiceImpl的registerEventTimeTimer来真正注册定时器,InternalTimerServiceImpl注册的动作也就是把定时器(TimerHeapInternalTimer)放到一个有序队列中(eventTimeTimersQueue),之后就等水位线来触发。
如图所示整个触发过程是通过StreamTask处理水位线来驱动的,经过一系列的调用,由InternalTimeServiceManager完成触发器的触发,触发条件是水位线大于定时器的时间。
上面分析了EventTimeTrigger和ProcessingTimeTrigger的实现过程,其他触发器,如CountTrigger相对简单些,通过条件(数量是否大于阈值)就可以完成是否触发的判断,这里不再讨论。
窗口函数
当前介绍当窗口完成触发的时候,窗口函数怎么执行。
Flink中的窗口函数主要有ReduceFunction、AggregateFunction、ProcessWindow-Function三种(FoldFunction理论上可以通过AggregateFunction实现,并且Flink从1.8版本开始已经把该函数标记为Deprecated,因此该函数我们不再讨论)。
在实际使用中推荐使用前两种,因为它们是增量计算,每条数据都会触发计算,而且窗口状态中只保留计算结果。
而ProcessWindowFunction(或者使用了驱逐器之后)需要窗口把所有的数据保留下来,到窗口触发的时候,调用窗口函数计算,效率比较低,而且会造成大量状态缓存。
下面我们详细看下前两种窗户函数的实现。
ReduceFunction
ReduceFunction的接口定义如下
1 | public interface ReduceFunction<T> extends Function, Serializable { |
ReduceFunction是一个输入、输出类型一样的简单聚合函数,可以用来实现max()、min()、sum()等聚合函数。
在WindowOperator中并不直接使用ReduceFunction作为算子的userFunction,而要经过层层包装。主要包装类有两类。
- 一类是WindowFunction,用来指导具体的窗口函数怎么计算。比如PassThroughWindowFunction,它表示不调用用户的窗口函数,直接输出结果,用来包装ReduceFunction和AggregateFunction,因为这两个函数在窗口触发的时候已经计算好了结果,只需要发送结果即可。
- 另一类是InternalWindowFunction的实现类,主要用来封装窗口数据的类型,然后实际调用前面讲的第一类包装窗口类。
这么讲有点抽象,我们具体来看ReduceFunction函数在Flink中是怎么调用的。我们看在WindowStream中调用reduce方法之后会发生什么。
1 | public SingleOutputStreamOperator<T> reduce(ReduceFunction<T> function) { |
接着调用重载的reduce方法(下面只列出关键代码)
1 | public <R> SingleOutputStreamOperator<R> reduce( |
可以看到最终传给WindowOperartor的function是一个new InternalSingleValue-WindowFunction (new PassThroughWindowFunction())的实例对象。
PassThroughWindow-Function我们在前面讲过,该函数什么也不做只是把输出发送出去。
再看InternalSingle-ValueWindowFunction,它也是基本什么都不做(只是把单个input对象转为集合对象
这就是我们刚才说的该类包装类用来把输入转换为合适的类型),只是调用刚才传入它内部的PassThroughWindowFunction,WindowOperator最终拿到的窗口函数就是把结果发送出去,不进行任何计算。
那么我们传入的ReduceFunction怎么起作用?什么时候调用呢?
我们来看ReduceFunction传入WindowedStream之后用在了哪里,还是刚才的reduce方法:
1 | ReducingStateDescriptor<T> stateDesc = new ReducingStateDescriptor<>( |
由这样一段代码可以看到reduceFunction被放到了StateDescriptor中,用来生成我们需要的ReducingState,并且reduceFunction被传递给ReducingState,用来进行真正的计算。
我们来看ReducingState的实现类RocksDBReducingState的add方法:
1 | public void add(V value) throws Exception { |
AggregateFunction
AggregateFunction是对ReduceFunction的扩展,可以接受三种类型的参数——输出、计算和输出,它的适用范围比ReduceFunction更广。
其实现过程与ReduceFunction基本一致,这里不再赘述。
运行时组件与通信
Flink运行时作为Flink引擎的核心部分,支撑着Flink流作业和批作业的运行,同时保障作业的高可用和可扩展性等。
Flink运行时采用Master-Worker的架构,其中Flink的Master节点为JobManager,Worker节点为TaskManager。
本节结合运行时架构设计与源代码的实现来深入剖析运行时组件、组件间通信及运行时组件的高可用。
首先介绍运行时的主要组件REST、Dispatcher、JobMaster、Resource-Manager和TaskExecutor
然后对这些组件的通信架构和组件间的核心通信进行深入分析,最后对运行时组件的高可用的设计与实现进行剖析。
运行时组件
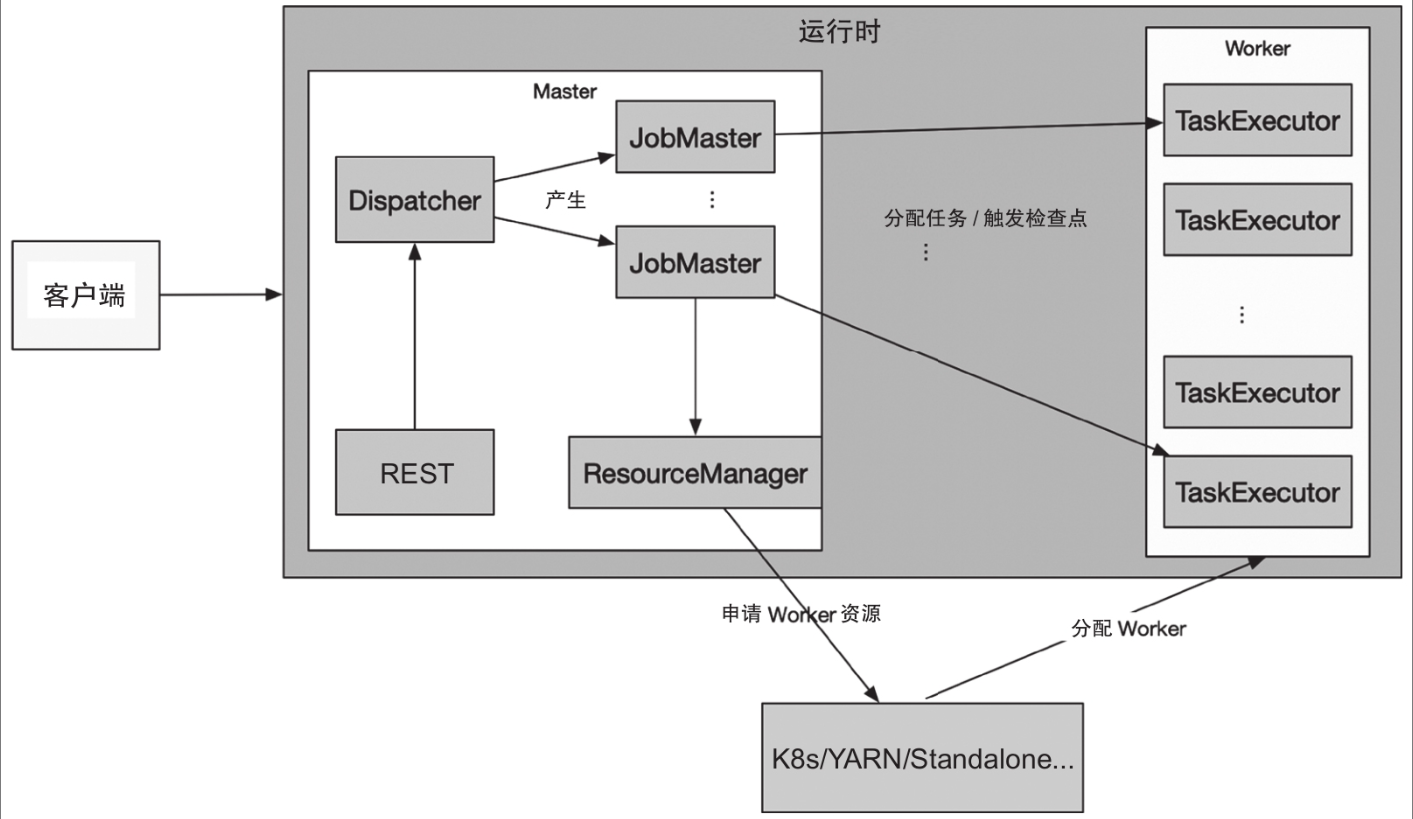
运行时组件的功能如下。
在运行时的架构里,JobManager(Master节点)包括REST、Dispatcher、Resource-Manager和JobMaster,而TaskManager(Worker节点)主要有TaskExecutor。
- REST的主体部分WebMonitorEndpoint接收客户端的HTTP请求,提供各种REST服务,如作业、集群的指标、各种作业信息的情况、操作作业等。
- Dispatcher的主要功能是接收REST转发的操作JobMaster请求,启动和管理JobMaster。
- JobMaster主要负责作业的运行调度和检查点的协调。
- ResourceManager在不同部署模式下对资源进行管理(主要包括申请、回收资源及资源状态管控)。
- TaskExecutor对资源(CPU、内存等)以逻辑的Slot进行划分,Slot供作业的Task调度到其上运行。
REST
REST是JobManager暴露给外部的服务,主要为客户端和前端提供HTTP服务。
REST部分源代码的核心是WebMonitorEndpoint类,WebMonitorEndpoint相关类的类图架构如图所示。
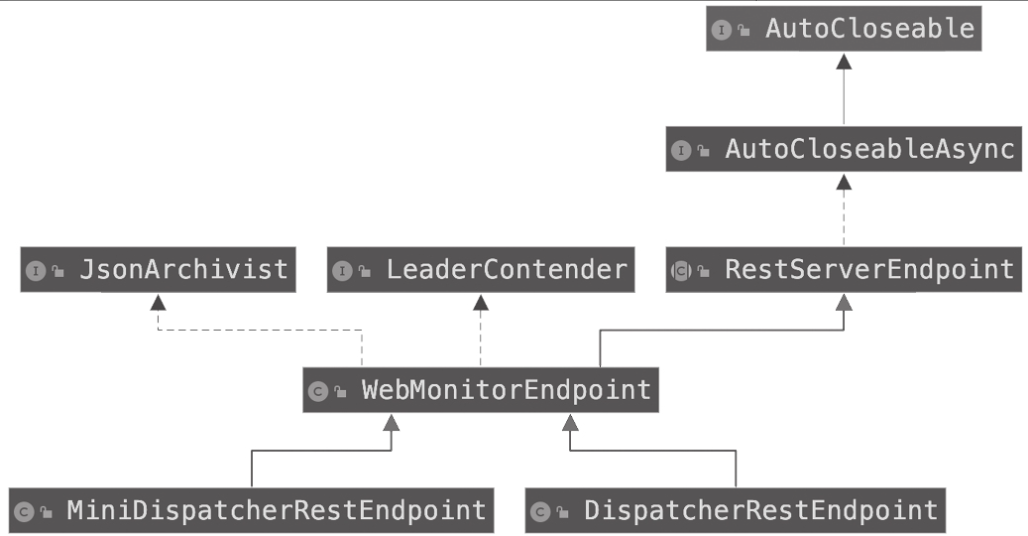
从REST的类图可以知道以下两点。
- WebMonitorEndpoint继承RestServerEndpoint类,实现JsonArchivist和Leader-Contender接口
其中:RestServerEndpoint是基于Netty实现的抽象类,是整个暴露REST服务的核心部分;JsonArchivist接口定义了基于ExecutionGraph(作业执行图)生成JSON的接口,供查询作业执行图信息的Handler(处理器)来实现;LeaderContender接口定义了WebMonitorEndpoint在首领(Leader)选举方面的处理方法。LeaderContender会在后面节详细介绍。 - MiniDispatcherRestEndpoint和DispatcherRestEndpoint作为WebMonitorEndpoint的子类实现。
两者的区别是MiniDispatcherRestEndpoint是作为Per-Job模式(一个作业对应一个集群的模式)的实现,而DispatcherRestEndpoint是作为Session模式的实现(一个集群可以有多个作业的模式)。
WebMonitorEndpoint的核心是启动过程,启动完成即可为外部提供REST服务。
WebMontiorEndpoint的启动过程如下
- 初始化处理外部请求的Handler;
- 将处理外部请求Handler注册到路由器(Router)
- 创建并启动NettyServer;
- 启动首领选举服务。
初始化所有Handler
在WebMonitorEndpoint的启动过程中,会调用父类RestServerEndpoint的start方法,而该方法执行流程的第一步是初始化Handler,如代码清单所示。
代码清单RestServerEndpoint启动过程中调用初始化的所有Handler部分
1 | public final void start() throws Exception { |
其中initializeHandlers方法在RestServerEndpoint类里是抽象的,具体实现在Web-MonitorEndpoint和DispatcherRestEndpoint类里。
DispatcherRestEndpoint与WebMonitor-Endpoint的initializeHandlers方法实现的不同之处在于
- DispatcherRestEndpoint作为Web-MonitorEndpoint的子类,会调用其initializeHandlers方法,同时多添加JobSubmitHandler,开启Web提交功能(默认是开启的),会添加WebSubmissionExtension类里对应的Handler
- 而WebSubmissionExtension里对应的Handler就是处理Flink UI中Submit New Job选项卡中相关的请求,包括上传Jar包、生成Jar列表、删除Jar、执行Jar、生成执行图。
WebMonitorEndpoint与DispatcherRestEndpoint的initializeHandlers方法分别如代码清单所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
protected List<Tuple2<RestHandlerSpecification, ChannelInboundHandler>>
initializeHandlers(final CompletableFuture<String> localAddressFuture) {
ArrayList<Tuple2<RestHandlerSpecification, ChannelInboundHandler>> handlers = new ArrayList<>(30);
final Time timeout = restConfiguration.getTimeout();
ClusterOverviewHandler clusterOverviewHandler = new ClusterOverviewHandler(
leaderRetriever,
timeout,
responseHeaders,
ClusterOverviewHeaders.getInstance());
...
handlers.add(Tuple2.of(clusterOverviewHandler.getMessageHeaders(), clusterOverviewHandler));
...
return handlers
}
protected List<Tuple2<RestHandlerSpecification, ChannelInboundHandler>>
initializeHandlers(final CompletableFuture<String> localAddressFuture) {
List<Tuple2<RestHandlerSpecification, ChannelInboundHandler>> handlers =
super.initializeHandlers(localAddressFuture);
final Time timeout = restConfiguration.getTimeout();
JobSubmitHandler jobSubmitHandler = new JobSubmitHandler(
leaderRetriever,
timeout,
responseHeaders,
executor,
clusterConfiguration);
if (restConfiguration.isWebSubmitEnabled()) {
try {
webSubmissionExtension = WebMonitorUtils.loadWebSubmissionExtension(
leaderRetriever,
timeout,
responseHeaders,
localAddressFuture,
uploadDir,
executor,
clusterConfiguration);
// 注册WebSubmissionExtension的Handler
handlers.addAll(webSubmissionExtension.getHandlers());
} catch (FlinkException e) {
if (log.isDebugEnabled()) {
log.debug("Failed to load web based job submission extension.", e);
} else {
log.info("Failed to load web based job submission extension. "
+ "Probable reason: flink-runtime-web is not in the classpath.");
}
}
} else {
log.info("Web-based job submission is not enabled.");
}
handlers.add(Tuple2.of(jobSubmitHandler.getMessageHeaders(), jobSubmitHandler));
return handlers;
所有的Handler都继承自AbstractHandler,而AbstractHandler类的架构如图所示。
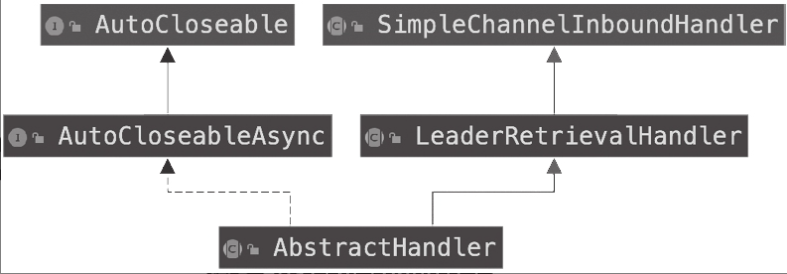
从图可知AbstractHandler会继承SimpleChannelInboundHandler,可以添加到ChannelPipeline,来处理Channel入站的数据以及各种状态变化。所有的Handler都有以下几个特点。
- 所有的Handler类在org.apache.flink.runtime.rest.handler包下面。
- 所有的Handler都有MessageHeaders的属性。MessageHeaders属性包含请求的URL、请求的参数类型、请求参数、响应的类型、响应返回码、HTTP请求类型和是否接收文件上传等。
- Handler会根据各自的需要,使用WebMonitor的LeaderRetriever和ResourceManager-Retriever字段分别对Dispatcher和ResourceManager进行访问,来获取与作业和资源相关的信息。
Handler注册Router
WebMonitorEndpoint的启动过程为:初始化所有的Handler,初始化后的Handler会注册到Router,方便后面的RouterHandler将请求路由到正确的Handler进行处理。
WebMonitorEndpoint的子类DispatcherRestEndpoint的启动过程为:初始化Handler,并将Handler注册到Router的列表中,如代码清单所示。
1 | public final void start() throws Exception { |
如代码清单所示,Handler注册到Router时(DispatcherRestEndpoint调用父类RestServerEnpoint类的registerHandler方法),DispatcherRestEndpoint会根据HttpMethod的请求,调用将Handler注册到Router中对应的HttpMethod的列表中。
1 | private static void registerHandler(Router router, String handlerURL, |
其中Router类的Handler的注册信息是一个嵌套的Map结构,Router的routers属性(Router类的Handler注册信息)是一个HttpMethod映射到MethodlessRouter的Map(Map<HttpMethod,MethodlessRouter>),而MethodlessRouter中的routes属性是一个PathPattern映射到Handler的Map,其中PathPattern由请求URL的path全路径和path基于path分隔符拆分成单词的数组属性组成。
Router的Handler注册信息的结构如图所示。
创建与启动NettyServer
在初始化所有Handler并将其注册到Router列表后,会创建和启动NettyServer,以暴露给外部REST服务。
创建与启动NettyServer有两部分:初始化处理Channel和绑定端口启动,如代码清单所示。
1 | public final void start() throws Exception { |
其中初始化Channel会创建ChannelPipeline。ChannelPipeline的结构如图所示,它包含六部分,各部分的功能如下

- HttpServerCodec:负责HTTP消息的解码与编码。FileUploadHandler:负责处理文件上传。
- FlinkHttpObjectAggragator:继承HttpObjectAggregator,负责将多个HTTP消息组装成一个完整的HTTP请求或者HTTP响应。
- ChunkedWriteHandler:负责大的数据流的处理,比如查看TaskManager/JobManager的日志和标准输出的Handler的处理。
- RouterHandler:REST服务暴露的核心,会根据URL路由到正确的Handler进行相应的逻辑处理。
- PipelineErrorHandler:负责记录异常日志,并返回HTTP异常响应。只有前面五部分因异常情况没有发送HTTP响应,才会执行到PipelineErrorHandler。
RouterHandler负责将HTTP请求路由到正确的Handler,分以下两个步骤。
- 通过初始化Handler注册到Router的注册信息,找到HTTP请求对应的路由结果,对于路由结果为空的,返回消息为Not Found、状态码为404的HTTP响应,如代码清单所示。
1 |
|
- 根据路由的结果,触发对应的Handler的消息处理,如代码清单所示。
1 | private void routed( |
启动Leader选举服务
在WebMonitorEndpoint的启动过程中,最后的部分启动首领选举服务,如代码清单所示。
首领选举服务会在后面节详细介绍。
1 | public final void start() throws Exception { |
Dispatcher
Dispatcher组件负责接收作业的提交、对作业进行持久化、产生新的JobMaster执行作业、在JobManager节点崩溃恢复时恢复所有作业的执行,以及管理作业对应JobMaster的状态。
Dispatcher组件的基础类为Dispatcher,Dispatcher组件相关的类图如图所示。
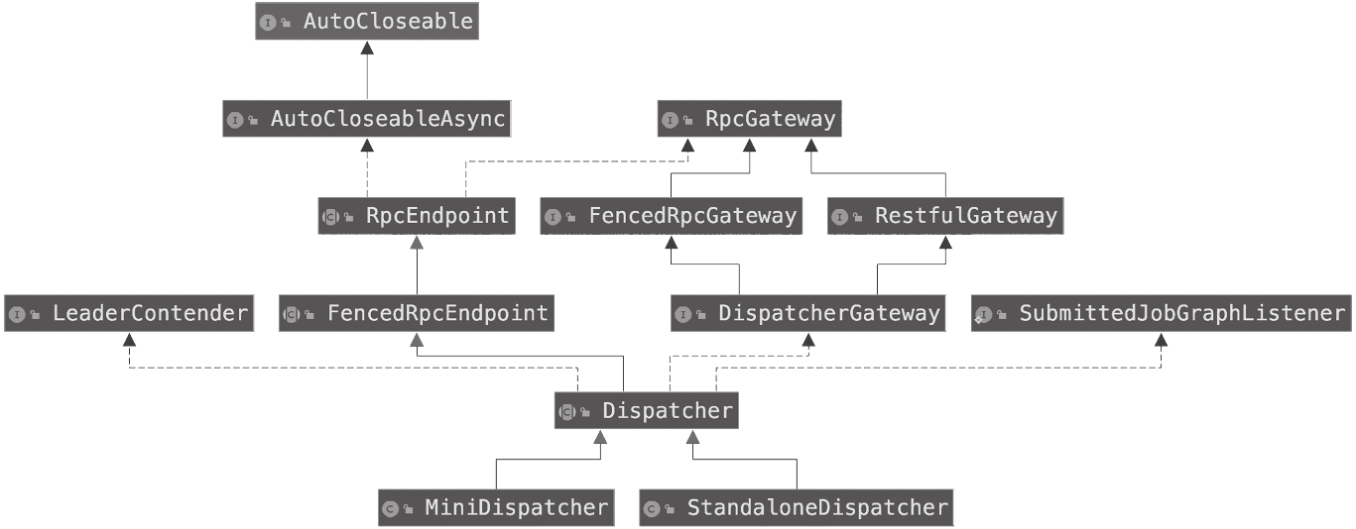
从上类图得知以下几点
- Dispatcher作为抽象类,继承FencedRpcEndpoint类,来对外部提供RPC(Remote Procedure Call,远程过程调用);Dispatcher实现LeaderContender接口,来处理首领选举;Dispatcher实现DispatcherGateway接口,提供给REST组件通过RPC调用的方法来暴露其服务;Dispatcher实现SubmittedJobGraphListener接口,来实现侦听持久化作业信息变更后的处理逻辑。
- MiniDispatcher类和StandaloneDispatcher类作为Dispatcher的子类实现。两者的不同是,MiniDispatcher类是作为Per-Job模式(一个作业对应一个集群的模式)的实现,而StandaloneDispatcher是作为Session模式(一个集群可以有多个作业的模式)的实现。
接下来重点看下Dispatcher接收到REST提交作业的消息后的处理过程
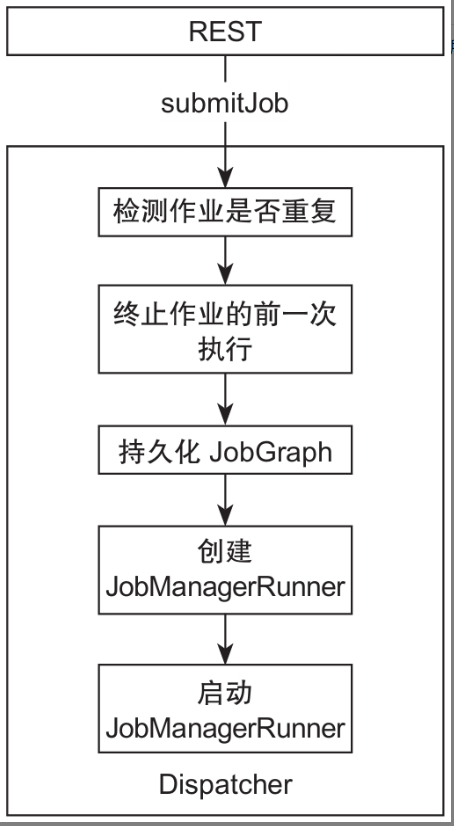
- 检查作业是否重复,防止一个作业在JobManager进程中被多次调度运行;
- 执行该作业前一次运行未完成的终止逻辑(同一个jobId的作业);
- 持久化作业的jobGraph;
- 创建JobManagerRunner;
- JobManagerRunner构建JobMaster用来负责作业的运行;
- 启动JobManagerRunner。
其中REST将作业提交到Dispatcher,是通过RPC调用Dispatcher实现DispatcherGateway的submitJob方法完成的。
该方法包括两部分:对提交的作业进行检查和执行提交作业逻辑,其中执行提交作业逻辑对应于上面处理过程的第2~6步。
Dispatcher处理作业提交方法
1 |
|
检查作业是否重复
处理作业的第一步是检查作业是否重复。
如代码清单所示,检查作业是否重复的逻辑就是判断作业是否执行过或者作业是否正在执行中。
其中jobManagerRunnerFutures属性在创建jobManagerRunner成功时会添加数据,而在创建或者启动JobManagerRunner失败以及移除作业时,会移除对应作业的数据。
1 | private boolean isDuplicateJob(JobID jobId) throws FlinkException { |
作业提交过程
如代码清单所示,提交作业的处理过程是先执行作业的前一次未完成的退出逻辑,再执行持久化和运行作业(上面提到的处理逻辑的第3~5步)。
1 | private CompletableFuture<Acknowledge> internalSubmitJob(JobGraph jobGraph) { |
其中执行作业前一次未完成的终止过程是先获取前一次未完成的终止逻辑,执行终止成功后再调用持久化运行作业方法,如代码清单所示。
1 | private CompletableFuture<Void> waitForTerminatingJobManager(JobID jobId, JobGraph jobGraph, FunctionWithException<JobGraph, CompletableFuture<Void>, ?> action) { |
代码如下所示获取作业前一次未完成的终止的处理逻辑方法。
如果该作业还在运行列表中,则返回作业还在运行中的异常;否则就从终止作业的进度列表中获取。
1 | CompletableFuture<Void> getJobTerminationFuture(JobID jobId) { |
如下代码所示,在处理完作业前一次未完成的终止的逻辑后,执行持久化与运行作业。
持久化作业是指SumittedJobGraphStore对作业的JobGraph信息进行持久化,其中持久化作业的JobGraph信息是为了在JobManager崩溃恢复时,JobManager可以对作业进行恢复。
1 | private CompletableFuture<Void> persistAndRunJob(JobGraph jobGraph) throws Exception { |
而运行作业的逻辑是,首先创建JobManagerRunner,将创建JobManagerRunner的进度记录到已在运行的作业列表中,表示该作业已在执行,再启动JobManagerRunner,如下代码清单所示。
1 | CompletableFuture<Void> runJob(JobGraph jobGraph) { |
其中启动JobManagerRunner的逻辑不单是处理JobManagerRunner的启动过程,还会通过JobManagerRunner调用getResultFuture方法,来对作业的执行情况进行侦听。
对于一直在正常运行的作业,getResultFuture是返回值,即不会执行handleAsync方法里的逻辑;
当作业运行状态变成终态(作业的终态有:CANCELED,作业被停止;FINISHED,作业已完成;FAILED,作业已不可恢复地异常失败)
以及JobManager启动或者运行出现异常时,会执行handleAsync方法里的逻辑,如下代码清单所示。
1 | private JobManagerRunner startJobManagerRunner(JobManagerRunner jobManagerRunner) throws Exception { |
在Dispatcher的重要逻辑中,除了提交作业,还有JobManager进程崩溃后在恢复时的恢复作业,恢复作业与HA中的首领选举有关,会在后面节详细展开。
在Dispatcher的代码里出现了getMainThreadExecutor方法和getRpcService().getExecutor()方法
这看起来有点让人迷惑,因为用getMainThreadExecutor这个方法处理不需要加锁来保证线程安全,而getRpcService().getExecutor()需要考虑线程安全。
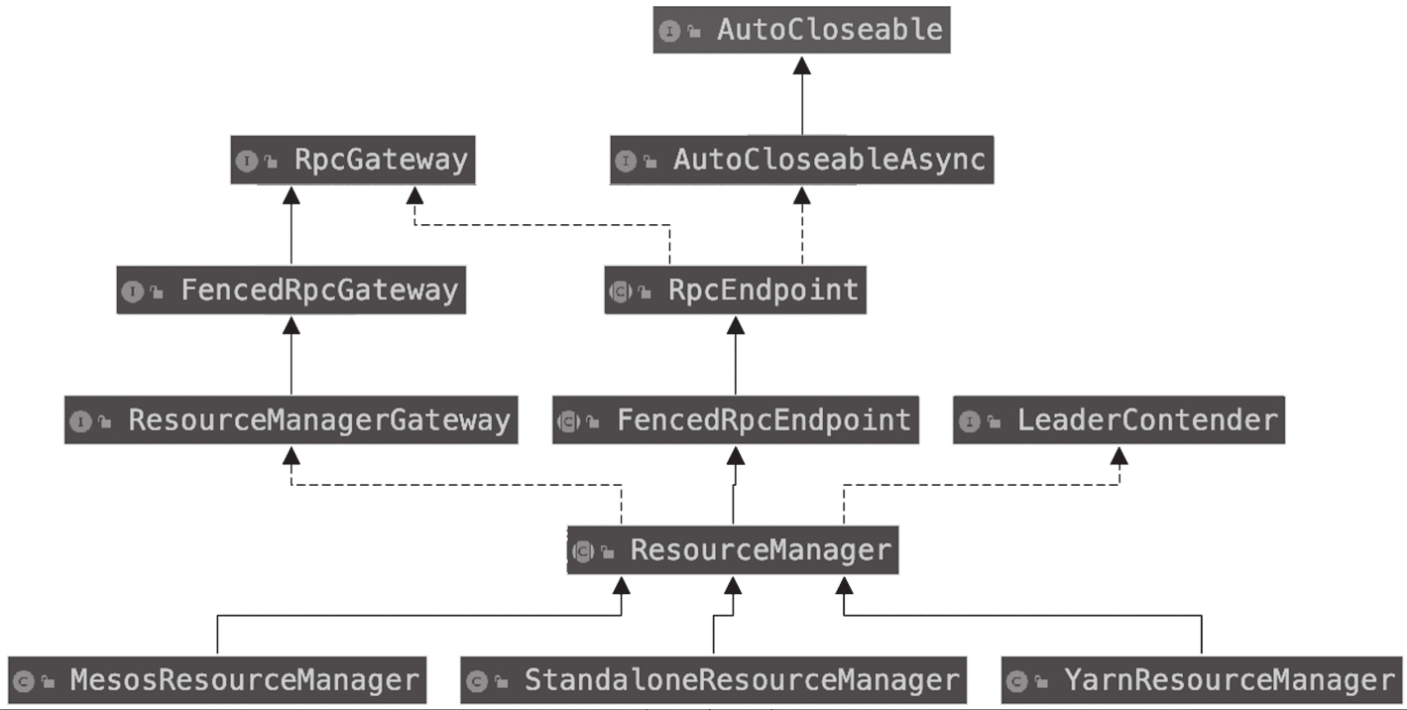
ResourceManager
ResourceManager组件负责资源的分配与释放,以及资源状态的管理。ResourceManager组件的基础类为ResourceManager,ResourceManager类的组织架构如图所示。
Resource-Manager类的实现接口和继承类整体与Dispatcher类类似,唯一不同的是Resource-Manager类实现的是ResourceManagerGateway接口,实现的方法供Dispatcher、REST、JobMaster组件调用。
ResourceManager的子类有StandaloneResourceManager、MesosResource-Manager、YarnResourceManager,作为不同部署模式的实现,实现在各种部署模式下与资源管控的交互。
ResourceManager与其他组件的通信主要有以下几种。
- REST组件通过Dispatcher透传或者直接与ResourceManager通信来获取TaskExecutor的详细信息、集群的资源情况、TaskExecutor Metric查询服务的信息、TaskExecutor的日志和标志输出。具体体现在Flink UI上。
- JobMaster与ResourceManager的交互主要体现在申请Slot、释放Slot、将JobMaster注册到ResourceManager,以及组件之间的心跳。
- TaskExecutor与ResourceManager的交互主要是将TaskExecutor注册到Resource-Manager、汇报TaskExecutor上Slot的情况,以及组件之间心跳通信。
对于资源Slot,在TaskExecutor上以Slot逻辑单元对TaskManager资源(资源CPU、内存等)进行划分,供作业的Task调度;
在JobMaster和ResourceManager上维护与Task-Executor的Slot的映射关系,JobManager通过SlotPool来管理运行作业的Slot,Resource-Manager通过SlotManager来管理TaskManager注册过来的Slot,供多个JobMaster的SlotPool来申请和分配。
接下来详细介绍ResourceManager、JobMaster与TaskExecutor之间的重要流程——申请资源Slot。
后面的JobMaster和TaskExecutor也会围绕申请资源Slot过程中的各个组件处理流程展开介绍。
整个申请资源Slot的流程如图所示。
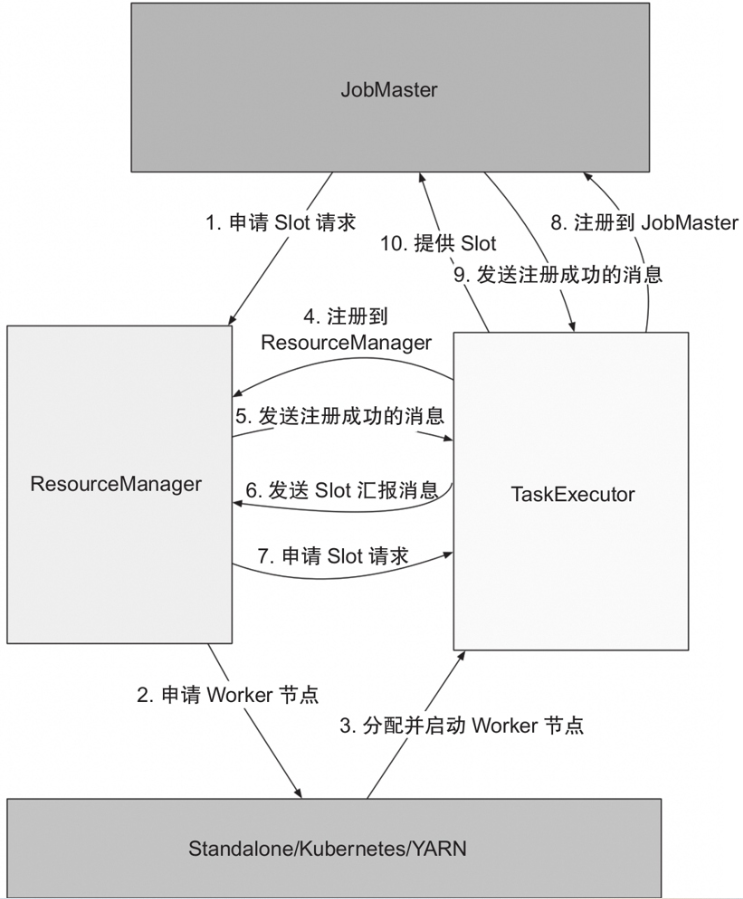
- JobMaster会根据Task的调度按需向ResourceManager发出申请Slot的请求。
- ResourceManager根据自身注册TaskManager的Slot空闲情况进行处理:TaskManager的空闲Slot资源足够时,就直接往对应的TaskManager发起申请占有Slot的请求;不够时则先会向各种部署模式(Standalone/Kubernetes/YARN)对应的资源管控中心申请TaskManager。
- 各种部署模式的资源管控中心根据ResourceManager申请TaskManager资源的规格,分配并启动TaskManager。
- 启动的TaskManager会注册到ResourceManager,注册成功后,TaskManager汇报自身的Slot情况(TaskManager汇报Slot过程)。
- ResourceManager根据TaskManager汇报的Slot情况向TaskManager申请占有Slot(ResourceManager的申请占有Slot过程)。
- TaskManager根据申请占有Slot信息中的作业信息注册对应的JobMaster,并将Slot提供给JobMaster调用分配Task(OfferSlot的过程)。
SlotManager
SlotManager作为ResourceManager的重要部分,维护和注册来自TaskManager的Slot,并处理来自JobMaster的Slot申请。
其中SlotManager服务的实现类为SlotManagerImpl。SlotManager处理来自所有JobManager的Slot申请,其处理过程分成两部分:申请资源Slot和处理TaskManager的注册Slot。
接下来以SlotManager处理来自JobMaster的Slot申请的过程和TaskManagerSlot的状态转换来展开介绍SlotManager。
申请Slot与分配
SlotManager在接收到JobMaster的Slot申请后,进行申请Slot过程,其过程主要有以下几部分:
- 检测Slot申请是否有效;
- 匹配SlotManager空闲的Slot(TaskManagerSlot)和待完成资源申请的Slot请求(PendingTaskManager),即Slot与待完成资源申请的Slot请求匹配过程;
- 申请TaskManager资源或者分配空闲的Slot(TaskManagerSlot)(申请资源与分配过程)。
如代码清单>所示,检测Slot申请是否有效,首先检查该Slot申请对应的JobMaster是否已注册,如果未注册则拒绝该Slot申请,反之执行后续的有效性检测。
1 |
|
如下代码清单所示,检测Slot申请的有效性,还会检测SlotManager是否已经启动(通过检查started属性)以及申请的Slot是否重复提交过。
其中申请的Slot是否重复提交过的检测方式是:检查待分配或者已经完成和活跃的Slot申请Map中是否存在该Slot的AllocationID。
申请Slot的AllocationID是在JobMaster组件中就产生的,是唯一确定的。
在检测完Slot申请的有效性后,会通过internalRequestSlot方法执行Slot和待分配请求匹配的逻辑。
SlotManager类的注册Slot申请请求方法
1 |
|
如下代码清单所示,内部申请Slot方法的处理流程为:先根据申请的Slot的资源规格匹配SlotManager的空闲Slot列表,匹配上空闲Slot,则完成该空闲Slot的分配过程,否则匹配待分配的申请请求和申请TaskManager。
SlotManager类内部申请Slot的方法
1 | private void internalRequestSlot(PendingSlotRequest pendingSlotRequest) throws ResourceManagerException { |
Slot匹配过程是根据Slot匹配策略(slotMatchingStrategy)从SlotManager注册的空闲TaskManagerSlot列表中挑选符合条件的TaskManagerSlot。
其Task-ManagerSlot记录Slot在TaskManager的地址,在TaskManager的SlotTable中的下标,Slot在TaskManager上的占用情况以及在ResourceManager的状态。
slotMatchingStrategy对应类的实现有两种,分别是Any-MatchingSlotMatchingStrategy和LeastUtilizationSlotMatchingStrategy。
- AnyMatchingSlot-MatchingStrategy的挑选策略是从空闲的TaskManagerSlot中任意挑选一个,这是默认的挑选策略;
- LeastUtilizationSlotMatchingStrategy是在空闲的TaskManagerSlot中挑选空闲Slot数量最多的TaskManager的TaskManagerSlot,该策略需要将参数cluster.evenly-spread-out-slots的值设置为true才会生效。
组件间通信
前面已经介绍了Flink的运行时基本组件REST、Dispatcher、JobMaster、Resource-Manager和TaskExecutor,接下来看看这些运行时组件间通信的设计与实现。
组件间的远程通信、组件内的本地通信以及组件内的状态在并发情况下的维护,都是基于Akka Actor来实现的。
在开始介绍组件间通信的设计和实现之前,先来看看组件实现的基础——消息传递模式(Akka)。
Akka与Actor模型
Akka是构建高并发、分布式、可扩展应用的框架。Akka让开发者只需要关注业务逻辑,不需要写底层代码来支持可靠性、容错和高性能。Akka带来了诸多好处,比如
- 提供新的多线程模型,不需要使用低级的锁和原子性的操作来解决内存可见性问题;
- 提供透明的远程通信,不再需要编写和维护复杂的网络代码;
- 提供集群式、高可用的架构,方便构建真正的响应式模式(Reactive)的应用。
Akka是基于Actor模型实现的,Actor模型类似于Erlang的并行模型,能使实现并发、并行和分布式应用更加简单。
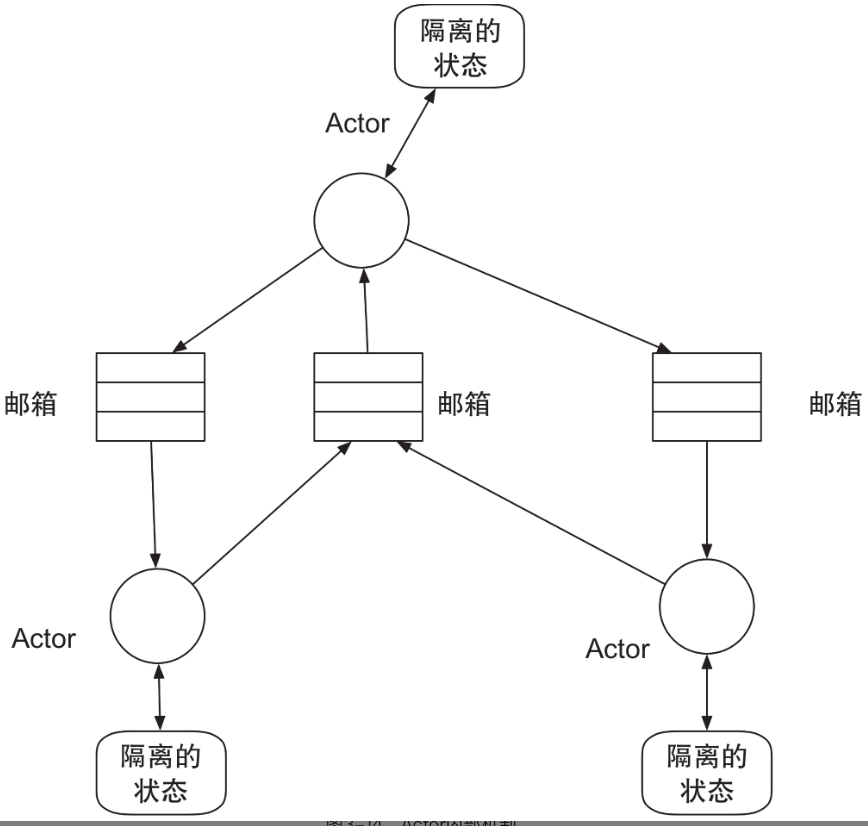
Actor是Actor模型中最重要的构成部分,作为最基本的计算单位,能接收消息并基于其执行计算。每个Actor都有自己的邮箱,用来存储接收到的消息。
每个Actor维持私有的状态,来实现Actor之间的隔离。
下图是各个Actor之间的通信示例情况。从图中可知,每个Actor都是由单个线程负责从各自的邮箱拉取消息,并连续处理接收到的消息。
对于接收到的消息,Actor可以更改其内部的状态,或者将其传给其他Actor,或者创建新的Actor。
下面通过一个实例来更好地了解Actor的创建、启动以及消息的发送。
RemoteServerActor的实现
实现AbstractActor的createReceive方法,来实现接收到消息的处理逻辑:接收到String的消息,将消息内容打印到控制台。
1 | public class RemoteServerActor extends AbstractActor { |
RemoteServerActorLauncher
启动Actor和发送消息
1 | public class RemoteServerActorLauncher { |
附带的配置
1 | akka { |
LocalClient
进行远程访问的LocalClient
1 | public class LocalClient { |
在上面的示例中,发送消息使用了tell模式。
Actor的发送消息模式有ask、tell和forward,三者的特点如下。
- ask模式:发送消息异步,并返回一个Future来代表可能的消息回应。
- tell模式:一种fire-and-forget(发后即忘)的方式,发送消息异步并立即返回,无返回信息。
- forward模式:类似邮件的转发,将收到的消息由一个Actor转发到另一个Actor。
至此与组件通信相关的Actor知识就介绍得差不多了,想要更深入地了解Akka Actor通信知识的读者可以查阅Akka官方网站(https://akka.io/)。
总结流程
- 创建远程的ActorSystem。
- 创建并启动RemoteServerActorLauncher实例,返回ActorRef,创建消息并通过ActorRef发送消息。
- ActorRef将消息委托给Dispatcher发送到Actor。
- Dispatcher把消息暂存在邮箱中,Dispatcher中封装了一个线程池,用于消息派发,实现异步消息发送的效果。
- 从邮箱中取出消息,委派给RemoteServerActorLauncher中通过createReceive方法创建的Receive实例来处理。
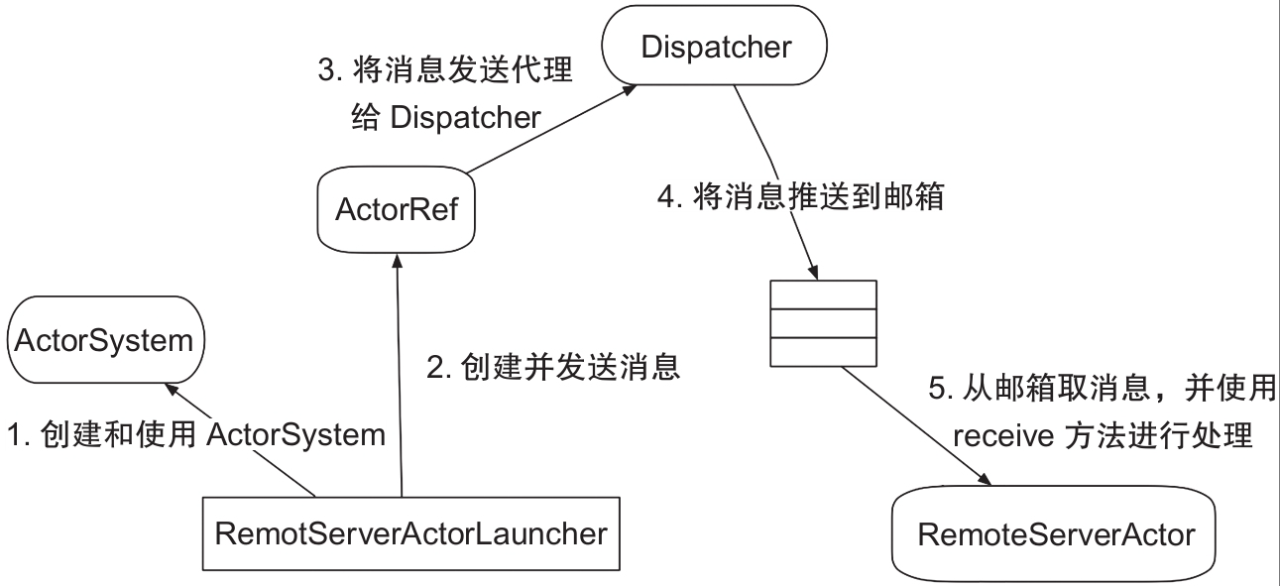
组件间通信实现
之前介绍了运行时的组件,对于这些组件内的多线程访问,没有锁和算子操作来保证状态,而主要通过runAsync方法、callAsync方法,以及通过getMainThreadExecutor调度来执行Future的回调方法,来实现对组件状态的安全操作。
组件间通过RpcGateway子类的方法实现远程的方法调用。
组件内部的安全状态操作是基于本地Actor实现的,而组件间的通信是通过远程Actor实现的。
至于组件内的本地通信与组件间通信的设计与实现,下面就来揭开其神秘的面纱。
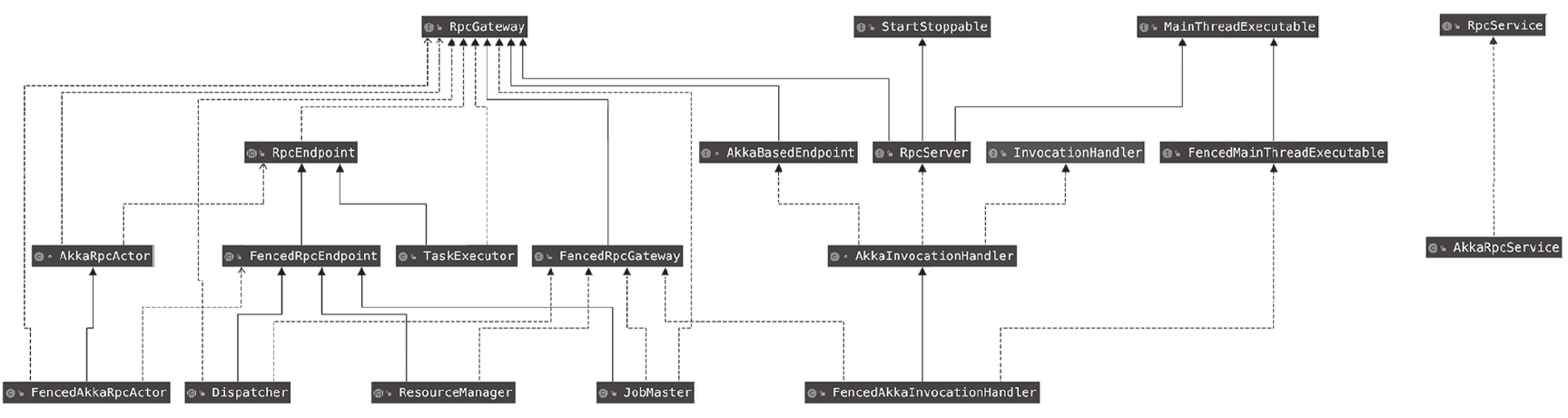
- RpcEndpoint:远程过程调用端点(rpc)基础类,提供远程过程调用的分布式组件需要继承这个基础类。前面提到的运行时组件Dispatcher、TaskExecutor、Resource-Manager和JobMaster组件都继承了RpcEndpoint。
- AkkaRpcActor:接收RpcInvocation、RunAsync、CallAsync和ControlMessages的消息来实现运行时组件中状态的安全操作。
- AkkaInvocationHandler:作为RpcAkka调用的Handler,AkkaRpcActor接收到的RunAsync、CallAsync和RpcInvocation消息都由AkkaInvocationHandler发送。
- AkkaRpcService:实现RpcService接口,负责启动AkkaRpcActor和连接到RpcEndpoint。连接到一个RpcEndpoint,会返回RpcGateway,供远程过程调用。
AkkaRpcActor
首先来看处理消息的AkkaRpcActor。除REST以外,其他运行时组件(Dispatcher、TaskExecutor、ResourceManager和JobMaster)都有一个AkkaRpcActor对象。AkkaRpc-Actor负责接收消息,并对消息进行处理,以操作RpcEndpoint(Dispatcher、TaskExecutor、
ResourceManager和JobMaster是RpcEnpoint类中的子类)的状态,实现对RpcEndpoint实现类对象的生命周期控制和状态操作。
AkkaRpcActor处理的消息分为远程握手消息(RemoteHandshakeMessage)、控制消息和普通消息。远程握手消息主要用于在RpcEndpoint之间的远程通信建立连接之前,检查RpcEndpoint之间版本是否兼容。
控制消息分START消息、STOP消息和TERMINATE消息。AkkaRpcActor接收到不同控制消息的场景与处理逻辑各不相同,具体如下。
- 当AkkaRpcActor接收到START消息时,只有AkkaRpcActor的状态设置为开始状态,才可以处理流入的普通消息。在AkkaRpcActor对应的RpcEndpoint启动时,会发送START消息给AkkaRpcActor。
- 当AkkaRpcActor接收到STOP消息时,AkkaRpcActor处于不再处理流入的普通消息且将接收到的普通消息丢弃的状态。此时只会发生JobMaster失去首领角色的情况。在这种情况下,JobMaster会将作业设置为暂停状态(Suspended),同时向与其对应的AkkaRpcActor发送STOP消息。
- 当AkkaRpcActor接收到TERMINATE消息时,会调用对应RpcEndpoint的退出(onStop方法)逻辑。只有在Master或Worker进程正常退出或者进程中的组件发生致命错误(Fatal Error)而退出时,才会接收到TERMINATE消息。
普通消息有RunAsync、CallAsync和RpcInvocation消息三种类型。普通消息在组件内部与组件间的使用场景各不相同,具体如下。
- RunAsync消息包含所需执行的Runnable和待执行的时间点,不需要返回执行结果。组件中的runAsync和scheduleRunAsync方法最终会将RunAsync消息发送给AkkaRpcActor,从而线程安全地执行Runnable的run方法,修改RpcEndpoint实现类对象的状态。
- CallAsync消息包含所需执行的Callable,需要返回执行结果。调用callAsync方法会触发客户端以ask模式将CallAsync消息发送给AkkaRpcActor。
- RpcInvocation消息分LocalRpcInvocation消息和RemoteRpcInvocation消息,二者的区别是:LocalRpcInvocation用于本地Actor之间的RPC,不需要消息的序列化和反序列化,用于Master上运行时组件间的通信(如ResourceManager与JobMaster的通信);RemoteRpcInvocation用于Actor远程通信中的RPC,需要序列化与反序列化,用于Master组件与Worker组件的远程通信(如JobMaster与TaskExecutor的通信)。
AkkaRpcService
接下来看下AkkaRpcActor的创建与启动过程。
AkkaRpcService负责创建和启动AkkaRpcActor,而这个过程是在AkkaRpcService的startServer方法中进行的。
如代码清单所示,AkkaRpcService中startServer方法的处理逻辑分成两部分
- 创建与启动AkkaRpcActor,用来接收和处理消息
- 构建RpcServer代理对象,使用发送消息给AkkaRpcActor的方式实现状态的线程安全操作。
1 |
|
在AkkaRpcService调用startServer方法、RpcEndpoint实现类对象获取到RpcServer代理对象、RpcServer代理对象调用start方法后,AkkaRpcActor即可处理普通消息。
至此FencedRpcEndpoint/RpcEndpoint中runAsync、callAsync和scheduleRunAsync方法的处理流程已十分清晰,如图所示,具体处理流程如下。
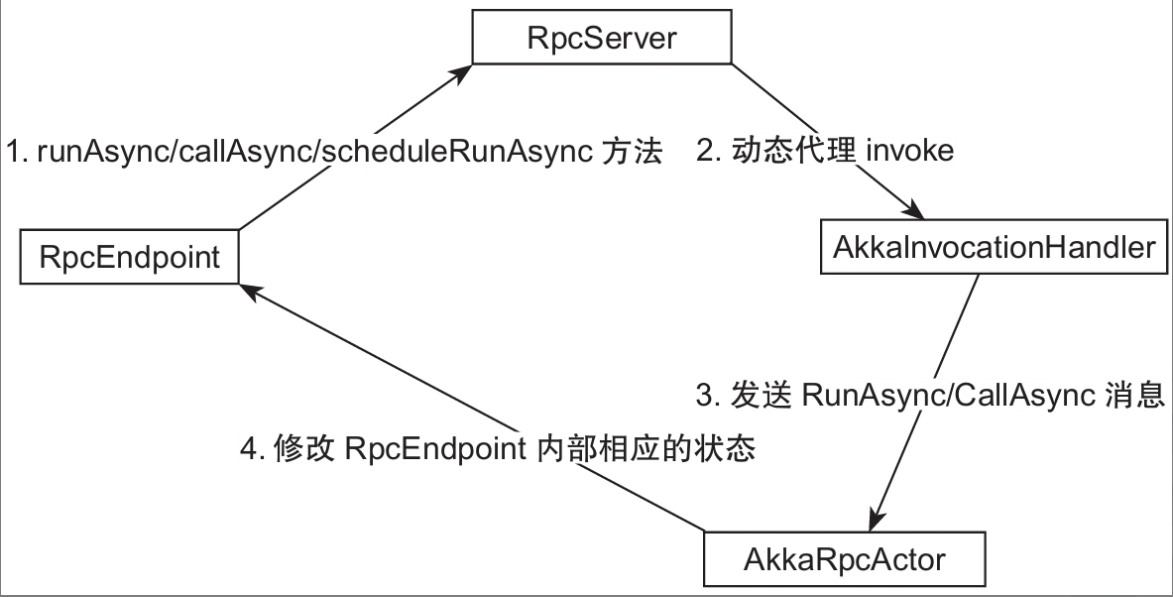
组件内runAsync、callAsync、scheduleRunAsync的处理流程
- FencedRpcEndpoint/RpcEndpoint实现类对象中调用runAsync、callAsync和schedule-RunAsync方法是通过RpcServer代理对象完成的。
- RpcServer代理对象调用runAsync、callAsync和scheduleRunAsync方法时会调用AkkaRpcInvocation的invoke方法,invoke方法会将这三种方法转换为RunAsync消息和CallAsync消息发送给AkkaRpcActor。
- AkkaRpcActor接收到RunAsync消息和CallAsync消息,进行FencedRpcEndpoint/RpcEndpoint实现类对象的线程安全的状态修改,或者将执行结果原路返回。
AkkaInvocationHandler
下面介绍RpcServer代理对象的InvocationHandler类AkkaInvocationHandler在组件内部与组件之间通信的作用。
作为RpcServer代理对象和创建远程连接的RpcGateway代理对象(后面会提到)的InvocationHandler,AkkaInvocationHandler能与本地AkkaRpcActor、远程AkkaRpcActor的消息交互。
之所以能够这样主要是因为AkkaInvocationHandler拥有ActorRef类型的对象rpcEndpoint(该rpcEndpoint与RpcEndpoint类无关),并且能够通过该对象直接与对应的Actor通信。
AkkaInvocationHandler类的所有逻辑的入口是实现InvocationHandler的invoke方法。如代码清单所示,当RpcServer代理对象或RpcGateway代理对象执行某个方法时,AkkaInvocationHandler的invoke方法会被调用。
而AkkaInvocationHandler的invoke方法的处理逻辑是,先获取调用方法的定义类,然后根据不同调用方法的定义类进行不同的处理。
对于不同调用方法的定义类,处理情况如下。
- 调用方法的定义类属于AkkaBasedEndpoint、Object、RpcGateway、StartStoppable、MainThreadExecutable和RpcServer,这是通过反射调用AkkaInvocationHandler的方法,这个场景用于RpcServer调用相应方法时(如调用runAsync、callAsync等方法)。
- 调用方法对应的定义类为FencedRpcGateway时,不支持,直接抛出异常,Fenced-RpcGateway接口定义的方法只有getFencingToken。
- 调用方法的定义类为其他时,调用invokeRpc来处理逻辑,这个场景用于继承RpcGateway接口的代理对象调用相应方法时。
1 |
|
RpcServer代理对象的方法调用是通过AkkaHandler的invoke调用来实现的(invoke调用的实现即通过反射调用其相应的方法,用于本地调用)。
RpcServer代理对象的调用方法有runAsync、scheduleRunAsync、callAsync、start和stop,这些方法的主要逻辑是通过ActorRef的rpcEndpoint属性往本地AkkaRpcActor发送RunAsync消息、CallAsync和控制消息。
AkkaInvocationHandler类往本地Actor发送消息的方法
1 |
|
AkkaInvocationHandler对于需要发送RpcInvocation的逻辑
1 | private Object invokeRpc(Method method, Object[] args) throws Exception { |
AkkaRpcService类中的connect方法
如代码清单所示,AkkaRpcService类中的内部connect方法的流程如下。
- 通过actorSelection的方式往Akka地址对应的Actor发送Identify消息。对应的Actor会返回ActorIdentity消息。
- 从ActorIdentity消息中提取ActorRef,再往ActorRef发送RemoteHandshakeMessage的消息,与对应Actor的组件握手建立联系。
1 |
|
状态管理与容错
提到实时计算引擎,人们自然而然地会将之与离线计算引擎分开讨论。对于离线计算引擎来说,由于需要计算的数据集是固定和有界的,当一个任务在提交执行过程中遇到不可预知的错误时,任务就会中断或失败。这个时候我们只需要找到问题的根源并进行修复,之后重新提交任务并运行即可。
在任务运行过程中无须太过关注中间状态的处理,只要任务逻辑与数据集是固定的,那么结果必然是相同的。
回到实时计算上来,与离线计算不同,实时计算的数据是无界的,任务触发执行后会永久运行下去,在执行过程中一旦有不可预知的错误(比如数据源出现脏数据)使得任务中断或失败,如果没有容错机制,那么实时计算会变得极不可靠。
Flink在容错方面的设计非常巧妙,通过引入状态的概念对数据处理时的快照进行管理,同时使用检查点机制定时将任务状态进行上报与存储,能够保证对数据的Exactly-once语义。
状态
状态在Flink中是特别重要的概念,如果对状态有很好的理解,我们就能更好地掌握Flink的特性。
接下来我们就对Flink的两大状态进行详细讲述。
状态的原理与实现
在Flink中,状态分为Keyed State和Operator State两种。
这两种状态又各自可以分为Raw State(原始状态)和Managed State(可管理状态)两种形式。
Managed State是官方推荐使用的状态形式,所有与DataStream相关的函数都可以使用它,我们在用Flink解决实际问题的时候,用得更多的也是Managed State。
接下来主要说明一下Managed Keyed State和Managed Operator State的实现原理。
Managed Keyed State介绍
顾名思义,Managed Keyed State只可以使用在KeyedStream上,具体可以分为ValueState、ListState、ReducingState、AggregatingState、FoldingState和MapState(在未来版本中FoldingState会被AggregatingState替代)。
如果想要使用这些状态,那么首先需要在代码中声明StateDescriptor,代码如下。
1 | public abstract class StateDescriptor<S extends State, T> implements Serializable |
StateDescriptor构造函数会声明状态的名称和数据类型,也会在类中给出各种方法供用户使用。
所有Managed Keyed StateDescriptor的父类均为StateDescriptor。
1 | protected StateDescriptor(String name, TypeSerializer<T> serializer, @Nullable T defaultValue) |
StateDescriptor提供了三个构造函数,从代码可以看出,这三个构造函数的不同之处在于第二个参数的设置。
- 第一个参数用来声明状态的名称,这个名称可以自定义。状态名称最好与状态的意义相关,且状态名称不可以重复。
- 第三个参数是默认值,如果状态没有被赋值,那么查询状态得到的返回值就是这个默认值。
- 第二个参数可以定义为TypeSerializer、TypeInformation和Class,分别对应状态数据类型的三种表达形式。
了解了StateDescriptor的构造后,我们下一步需要知道StateDescriptor在什么地方进行初始化操作。
在本节的开头我们说过,所有与DataStream相关的函数都可以使用Managed State。状态记录了每个函数中的状态,所以Managed Keyed State的声明是在函数中初始化的,具体来说是在函数类的open方法中完成的。
状态初始化完成,就表明状态可用,Flink通过RuntimeContext操作状态。
根据定义Managed Keyed State类型的不同,RuntimeContext提供了不同的getState方法,如ValueState。
getState方法的内容如下:1
2
3
4
5
6
public <T> ValueState<T> getState(ValueStateDescriptor<T> stateProperties) {
KeyedStateStore keyedStateStore = checkPreconditionsAndGetKeyedStateStore(stateProperties);
stateProperties.initializeSerializerUnlessSet(getExecutionConfig());
return keyedStateStore.getState(stateProperties);
}
getState方法主要做以下三件事情。
- 获取KeyedStateStore。KeyedStateStore是在StreamOperator中根据keyedStateBackend初始化得到的。KeyedStateStore是Keyed State存储的对象,每一次状态的变更都会同步到KeyedStateStore中去。
- 状态序列化方法初始化。提供一个序列化方法来指定声明状态序列化的方式,一个状态只会初始化一次,这是为了避免同一个状态被多种方式序列化。
- 从KeyedStateStore中得到状态的初始值。如果任务是第一次启动,那么会得到状态的默认值;如果任务是从检查点启动的,那么会获得从stateBackend中恢复的状态值。
Managed Operator State介绍
检查点
检查点(checkpoint)是Flink中一个很重要的名词。正是因为有了检查点机制,Flink在运行流式任务的时候才能保证系统内部的数据一致性
检查点机制原理
前面着重讲解了Flink的状态知识,从中可知Flink的函数和算子都是带状态的,这些状态根据流进的数据而不断被更新。
基于容错的考虑,我们需要不断收集和保存状态的快照,一旦任务失败,就可以直接从保存的状态中快速恢复到失败前的执行状态。
这就是检查点机制的大致原理。
具体展开介绍检查点之前,我们需要先了解一些知识。检查点机制的实现需要持久存储的支持,主要分下面两种
- 需要可根据时间进行回放的数据源存储,例如Kafka、RabbitMQ、Kinesis等;
- 需要持久存储来存放任务的状态,例如HDFS、S3、GFS等。
检查点机制会定时收集任务的状态并上传到持久存储中,当任务失败进行恢复时,需要从数据源中进行数据回放,并重新进行消费计算。
检查点执行过程
如果任务需要检查点机制的保障,则需要在代码中进行显式设置,因为默认是不开启检查点的。一旦开启了检查点,任务就会定时进行快照操作。下面我们就来仔细讲述检查点的完整执行过程。
- 在任务的初始化过程中,JobMaster会通过SchedulerNG完成各种调度操作。
SchedulerNG有个方法叫作startScheduling,在此方法中会调用ExecutionGraph的schedule-ForExecution方法进行作业的运行规划。 - 在scheduleForExecution方法中会首先判断作业的状态是否从created转换到running。
状态的转换是通过transitionState方法完成的,在转换的过程中会通知所有JobStatusListener状态变更信息。负责检查点的JobStatusListener名为CheckpointCoordinator-DeActivator,一旦此监听器监听到任务状态变为running,就会立即调用Checkpoint-Coordinator触发startCheckpointScheduler方法进行检查点的调度操作。 - 在startCheckpointScheduler方法中将会触发一个定时任务ScheduledTrigger,这个定时任务负责根据用户配置的时间间隔进行运行状态处理。
- ScheduledTrigger首先会拿到作业的所有Execution(单个ExecutionVertex的容器),然后判断所有要进行快照的任务是否都处于running状态。
如果所有任务都处于running状态,就会再判断操作是检查点还是保存点(savepoint)。最后轮询所有的Execution,触发triggerCheckpoint方法。 - Execution的triggerCheckpoint方法首先拿到运行Execution任务的LogicalSlot信息,再通过LogicalSlot得到此Slot所在TaskManager的TaskManagerGateway,并调用triggerCheckpoint方法。
- TaskManagerGateway的triggerCheckpoint方法本质上是执行TaskExecutorGateway的triggerCheckpoint方法,在这个方法里,通过executionAttemptID得到具体的任务,最后触发任务的triggerCheckpointBarrier方法,进而通过任务的AbstractInvokable类执行triggerCheckpoint方法。在流任务中,所有任务都继承自StreamTask,而StreamTask恰恰继承自AbstractInvokable
- 当StreamTask执行triggerCheckpoint方法时,会将运行在此任务中的所有Stream-Operator取出,并轮询执行snapshotState方法,SnapshotState根据用户配置的StateBackend进行状态的snapShot操作。任务在进行快照的时候,会将状态和相应的metainfo异步写入文件系统中,然后返回相应的statehandle对象用作恢复。
- 在所有的算子全部完成状态snapShot并告知JobManager后,就可以认为一次检查点执行过程全部完成。
任务容错
我们需要了解Flink的两个有关容错的概念:Restart Strategy和Failover Strategy。
- 前者决定了失败的任务是否应该重启,什么时候重启;
- 后者决定了哪些任务需要重启。
这两个概念的相关值都是通过参数配置的,具体可以参考Flink官方文档,这里不详细介绍,但无论是哪种配置,任务出错后进行恢复的本质是不变的——Task拿到最近一个检查点的状态进行恢复。
1 |
|
既然任务失败状态恢复的本质是相同的,那么我们就可以以一个典型的任务恢复过程FlinkKafkaConsumerBase为例来进行分析。
- 这个类继承自RichParallelSourceFunction并且使用了CheckpointedFunction接口。
根据之前介绍的状态相关内容,大家会立即想到这个类有两个重写方法——initializeState和snapshotState。前者在初始化或者恢复状态时调用,后者在检查点做快照时调用。当任务失败后重启时,首先会调用initializeState方法,这个方法包含以下三步。- 通过FunctionInitializationContext得到任务相应的OperatorStateStore
- 根据传入的相关参数从OperatorStateStore中拿出任务失败前最后一次成功检查点中的状态。相对于FlinkKafkaConsumerBase类来说,这一步拿出的是一个ListState类型,里面存储的是Tuple2<KafkaTopicPartition, Long>二元组数据结构。
- 根据FunctionInitializationContext判断这次initializeState的调用是否为任务重启恢复操作,如果是,则将上一步得到的ListState赋给全局变量restoredState,以供后面的open方法使用
- InitializeState方法执行完毕,紧接着会执行函数的open方法。
这个方法在任务初始化的时候只会执行一次,一般有关任务的配置或者加载操作都会在open中完成。由于上一步我们已经从检查点中将任务状态(restoredState)取出
因此在open中要做的就是将状态加载到任务中,让任务从状态断点处恢复运行。FlinkKafkaConsumerBase这个操作就是将Kafka相应的分区位移点(offset)信息从状态中恢复,继续从位移点消费数据。
任务失败恢复的过程大致可以总结为两步
- 首先算子从失败前任务状态存储中取出最后一次检查点中对应的状态;
- 然后算子加载对应的状态,从上次断点开始正常运行。不同算子恢复任务的不同之处只是在于从状态存储中恢复的状态类型不同,本质相同。
在这里我们需要对一个知识点进行引申:任务并行度改变后状态的恢复也就是我们常说的状态重分配;针对改变并行度的算子,状态的恢复当然会不同,具体的操作在CheckpointCoordinator中进行。
1 | // 重新分配任务状态 |
构建完StateAssignmentOperation对象后,就会调用assignStates方法,这个方法会进行以下操作。
- 判断并发度是否改变,如果没变,那么不重新分配,但如果任务状态的模式是广播类型,则会将此任务的状态广播给所有其他任务。
- 对于Operator State,会对每一个名称的状态计算出每个子任务中的元素个数之和(这就要求各个元素相互独立)并进行轮询调度(round robin)分配。
- 对于Keyed State的重新分配,首先根据新的并发度和最大并发度计算新的key-GroupRange,然后根据subtaskIndex获取keyGroupRange,最后获取到相应的keyStateHandle并完成状态的切分。
状态后端
状态后端(State Backend),顾名思义,是用来存放任务状态的地方。
在Flink中状态后端分为三类:FsStateBackend、MemoryStateBackend和RocksDBStateBackend。
这三种类型分别对应着不同的存储方式
- FsStateBackend先把任务状态存储在TaskManager的内存中,当作业开始做检查点的时候,将内存中的状态写到文件系统中;
- MemoryStateBackend也会将任务状态存储在TaskManager的内存中,但不同的是做检查点的时候,所有TaskManager会将内存中的状态上传至JobManager,存储在JobManager的内存中而不是可靠的外部存储中;
- RocksDBStateBackend会将状态存储在RocksDB中,做检查点的时候,再将状态上传至可靠的文件系统中。
任务提交与执行
主要介绍任务提交的整个过程和实现原理,包括其中的DAG转换、Slot分配、任务状态的变化等。任务的提交因部署模式而异,这里不一一介绍每种部署模式的提交过程,只重点讲解使用比较广泛的Flink on YARN模式
任务提交整体流程
由于整个流程比较复杂,我们省去了一些与任务提交相关度不太高的环节,比如Flink的JobManager是怎么与YARN的ResourceManager交互来申请资源的,或者YARN的NodeManager是怎么启动Flink的TaskManager的。
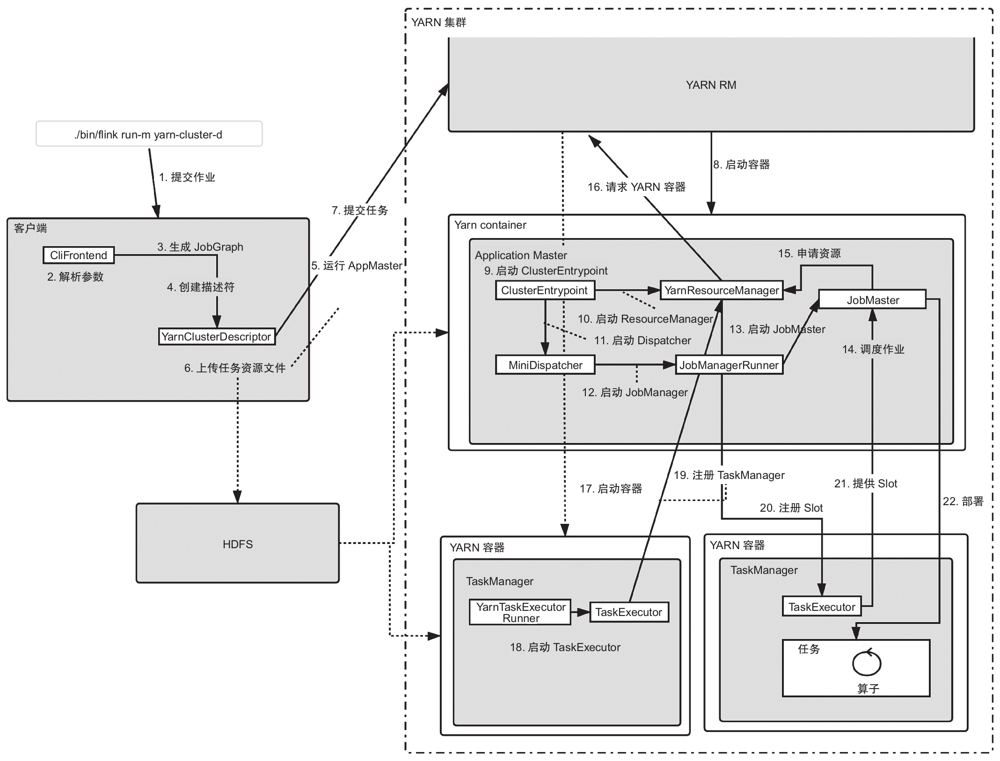
- 提交作业:执行./bin/flink run -m yarn-cluster -d来提交任务,这里我们按照yarn-cluster模式来提交任务,并且使用detached模式。
- 解析参数:命令行入口类CliFrontend会解析相关参数,根据不同的命令和参数执行不同的逻辑。
- 生成JobGraph:如果判断是通过Per-Job(用-m yarn-cluster指定,后续版本中可能没有Per-Job的概念,这里不用纠结具体的叫法)和detached模式提交的任务,会通过PackagedProgramUtils的createJobGraph方法来创建当前任务的JobGraph。
- 创建描述符:创建YarnClusterDescriptor来提交YARN作业。
- 运行AppMaster:这里是向YARN集群提交一个任务,与Spark及其他引擎往YARN上提交任务的过程是一样的。具体就是使用YarnClient接口的相关方法提交任务。
- 上传任务资源文件:提交任务的过程中需要把任务用到的文件或配置上传到文件系统中,以使任务在不同的节点启动之后都可以获取到需要的资源。
- 提交任务:把任务提交给YARN的ResourceManager(RM)。YARN的RM会启动一个容器来运行JobManager。具体过程如下:创建一个新的任务,判断资源情况,调度器(Scheduler)进行调度,随后YARN的RM通知NodeManager启动服务。
- 启动容器:YARN的NodeManager收到RM的通知,进行一系列校验和资源文件的准备,包括文件的下载和环境变量的设置,然后运行启动脚本(由ContainersLauncher根据AppMaster的启动命令生成)启动AppMaster。
- 启动ClusterEntrypoint:启动Flink的AppMaster,入口类是ClusterEntrypoint。10)启动ResourceManager:ClusterEntrypoint会依次启动JobManager中的各个服务,首先启动负责资源管理的YarnResourceManager,这是JobManager内部的服务,与YARN的RM是不同的服务。
- 启动ResourceManager:ClusterEntrypoint会依次启动JobManager中的各个服务,首先启动负责资源管理的YarnResourceManager,这是JobManager内部的服务,与YARN的RM是不同的服务。
- 启动Dispatcher:Dispatcher主要负责接收任务的提交,包括REST方式,为Flink提供一个任务提交管理中心化的角色。Dispatcher还可以用来对JobManager进行容错管理,在JobManager失败后做恢复工作。
- 启动JobManager:JobManager对应的实现类是JobManagerRunner,用来管理作业的调度和执行。
- 启动JobMaster:JobManager会把与作业相关的具体事情委托给JobMaster,自己则主要做一些高可用相关的工作。
- 调度作业:JobMaster会根据JobGraph构建ExecutionGraph,具体的执行过程后面会详细分析。ExecutionGraph经过Slot的分配之后就可以进行真正的部署了。这个时候如果还没有有效的Slot,会先申请Slot。
- 申请资源:JobMaster在调度任务的时候会通过SlotPool进行Slot的申请和分配。SlotPool是通过YarnResourceManager进行Slot的请求的,而YarnResourceManager内部通过SlotManager进行Slot管理。YarnResourceManager收到Slot请求之后会先判断是否有有效的Slot可供分配。如果有就直接分配;如果没有,则需要启动一个新的TaskManager提供新的Slot。
- 请求YARN容器,即Flink中的TaskManager。
- 启动容器:YARN的NodeManager收到命令之后,启动我们需要的容器。
- 启动TaskExecutor:TaskManager的入口类是YarnTaskExecutorRunner,该类会负责启动TaskExecutor。
- 注册TaskManager:TaskExecutor启动之后会向YarnResourceManager注册,成功后再向SlotManager汇报自己的资源情况,也就是Slot,同时会启动心跳等服务。
- 注册Slot:在TaskExecutor向YarnResourceManager注册之后,SlotManager就有了我们需要的Slot。SlotManager会从等待的请求队列里开始分配资源,向TaskManager请求Slot的分配。
- 提供Slot:TaskExecutor收到Slot请求后,进行一些检查和异常的判断,没有问题的话就会将Slot分配给JobMaster。到这里ExecutionGraph就得到了需要的物理资源Slot。
- 部署:Execution执行部署任务流程,向TaskExecutor提交任务,TaskExecutor启动新的线程执行任务。到这里整个任务提交的流程结束。后3节会分别介绍其中的关键过程:DAG转换、Slot分配和任务执行。
DAG转换
上一节介绍了任务提交的整体流程,这一节重点看下Flink中的用户代码是怎么转化为物理执行算子的,这也就是DAG的转换过程。
DAG的4层转换
用户代码到Fink任务物理执行会经过多次转换,从最初的program依次到StreamGraph、JobGraph、ExecutionGraph,ExecutionGraph中的ExecutionVertex经过Slot的分配最终部署到TaskManager,形成分布式执行的任务。
我们先通过图从整体上看一下这4层转换的大致过程,后面再以具体的例子WordCount来详细分析每个过程。
DAG的4层转换
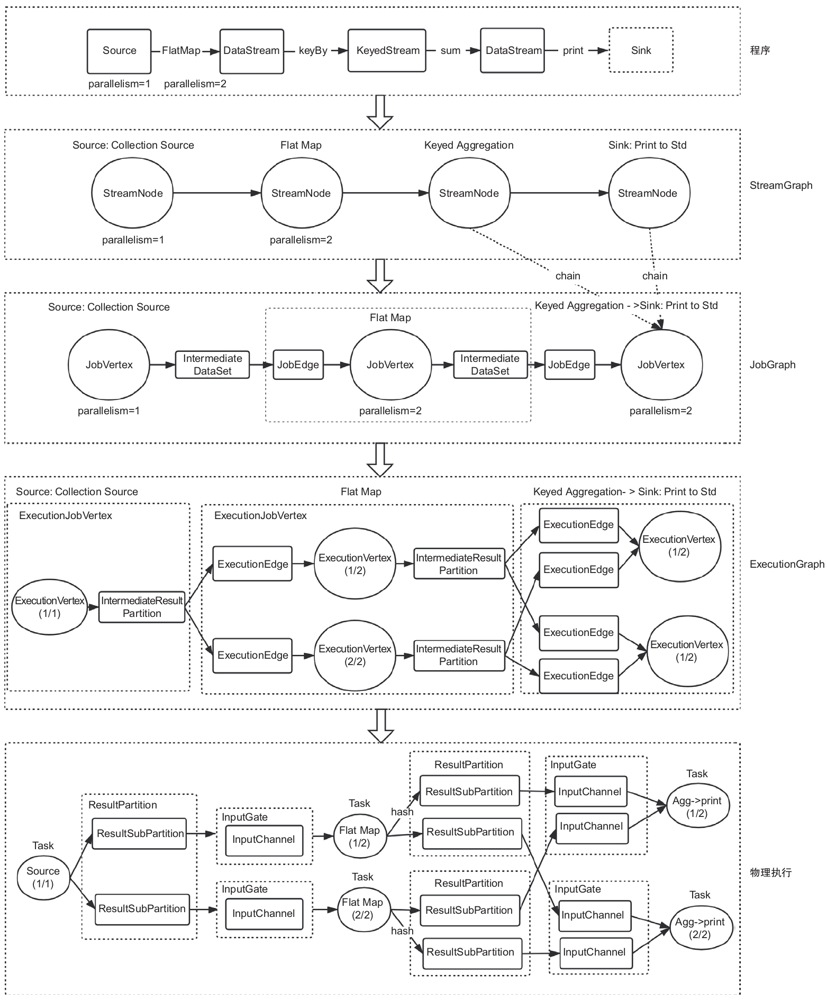
WordCount转换过程
下面以WordCount的例子来从源代码角度详细了解DAG的4层转换
1 | public class WordCount { |
算子到StreamGraph的转换
DataStream转换的过程会把算子(封装了用户的执行函数)封装成StreamTrans-formation,放到StreamExecutionEnvironment的变量Transformations中,StreamTransformation本身也持有前一个Transform的引用。
这样用户的转换逻辑就全部放到了Transformations中。
生成StreamGraph的过程就是把Transformations转换为StreamGraph的过程。
1 | protected final List<StreamTransformation<?>> transformations = new ArrayList<>(); |
StreamTransformation生成StreamGraph的过程其实就是构造StreamNode的过程,StreamNode包含当前算子及算子的上下游关系。
每个StreamTransformation包含的算子构造一个StreamNode,StreamTransformation包含的上下游关系构造StreamEdge,如图所示。
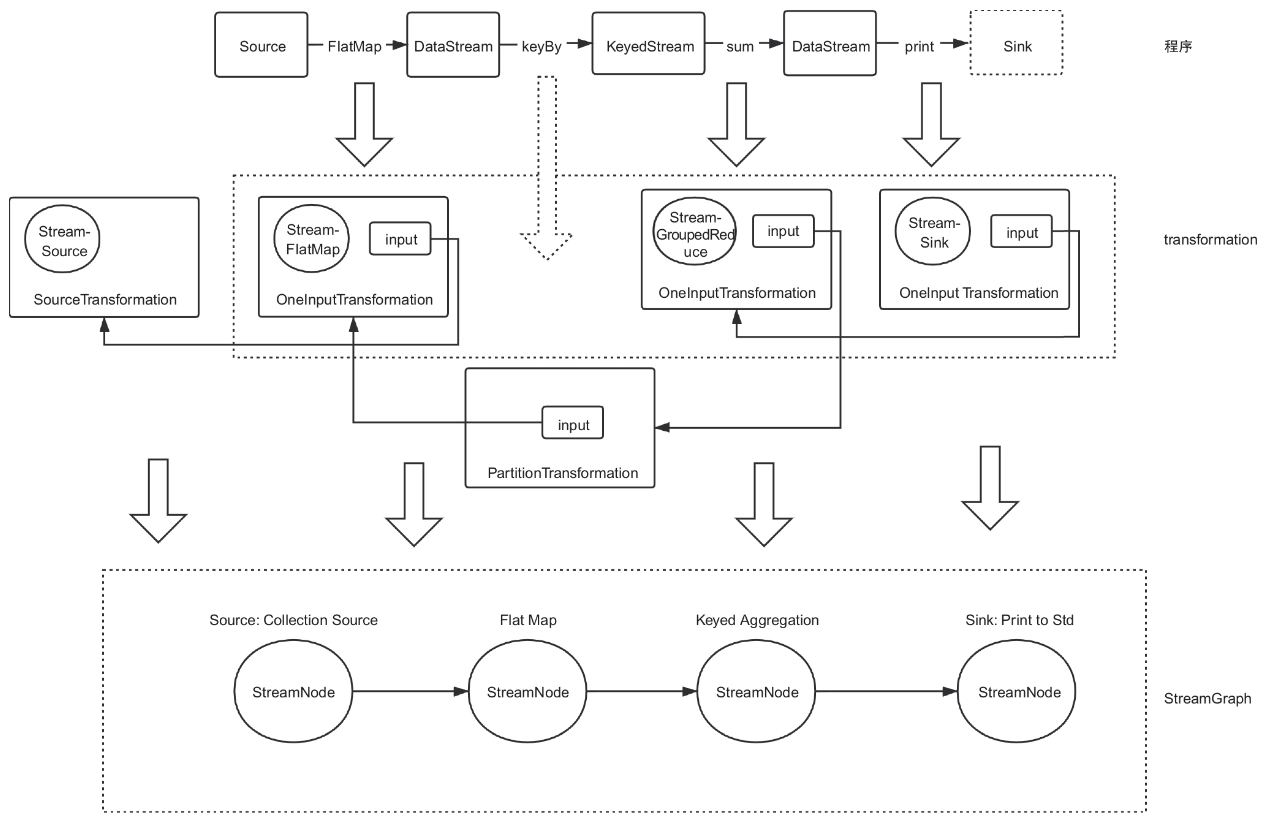
StreamGraph到JobGraph的转换
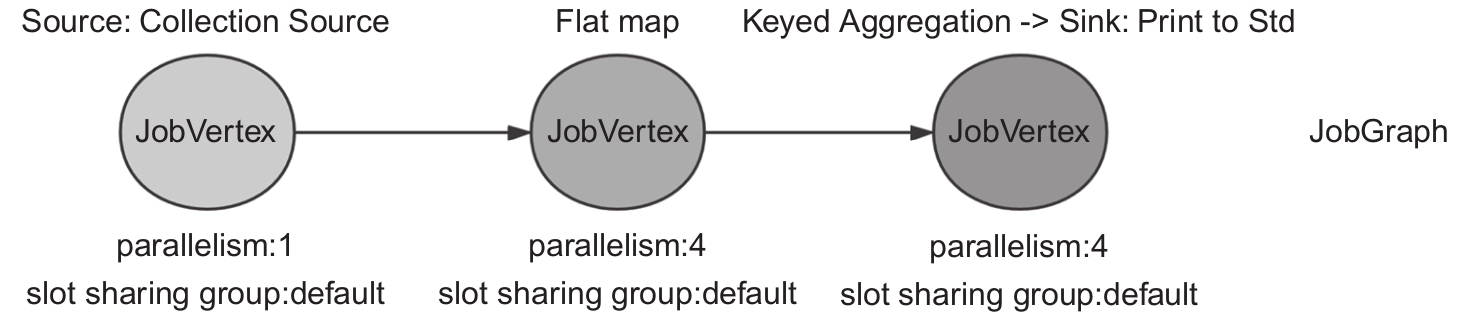
StreamGraph转换为JobGraph的过程就是构建JobVertex的过程,JobVertex也是后续Flink任务的最小调度单位。JobVertex可以包括多个算子,也就是把多个算子根据一定规则串联起来。
创建JobGraph主要是由StreamingJobGraphGenerator的createJobGraph方法完成的。
该方法的主要逻辑如下
- 遍历StreamGraph,为每个streamNode生成byte数组类型的哈希值并赋值给OperatorID,作为状态恢复的唯一标识。
- 利用StreamNode及其相关关系构造JobVertex。其主要逻辑实现在StreamingJob-GraphGenerator的createChain方法中。该方法的主要逻辑如下。
- 不能串联到一起的,单独生成JobVertex,并把算子中的用户函数(如WordCount的Tokenizer方法)及相关属性序列化到JobVertex的configuration中。
- 可以串联到一起的,选取串开头的StreamNode作为当前JobVertex的JobVertexID,将其他StreamNode都序列化到配置字段chainedTaskConfig_中。
当然序列化的对象也是存储了StreamNode相关信息的StreamConfig类。算子之间的关系生成了JobEdge和IntermediateDataSet类,放到JobVertex中。
- 设置Slot共享组及其他作业相关的属性,包括资源分配location属性、checkpoint等。
WordCount生成的JobGraph如图所示。
哪些算子可以串联呢?直接看以下源代码
1 | public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) { |
开发者关注的是否可以串联的是:上下游并发是否一样,是否包含keyBy或者Rebalance的动作。
算子串联的过程就是循环判断所有的StreamNode是否符合要求。
对于上面的WordCount的例子,我们稍微设置下并发:
1 | env.getConfig().setParallelism(2); |
生成的JobGraph就变成图这样了
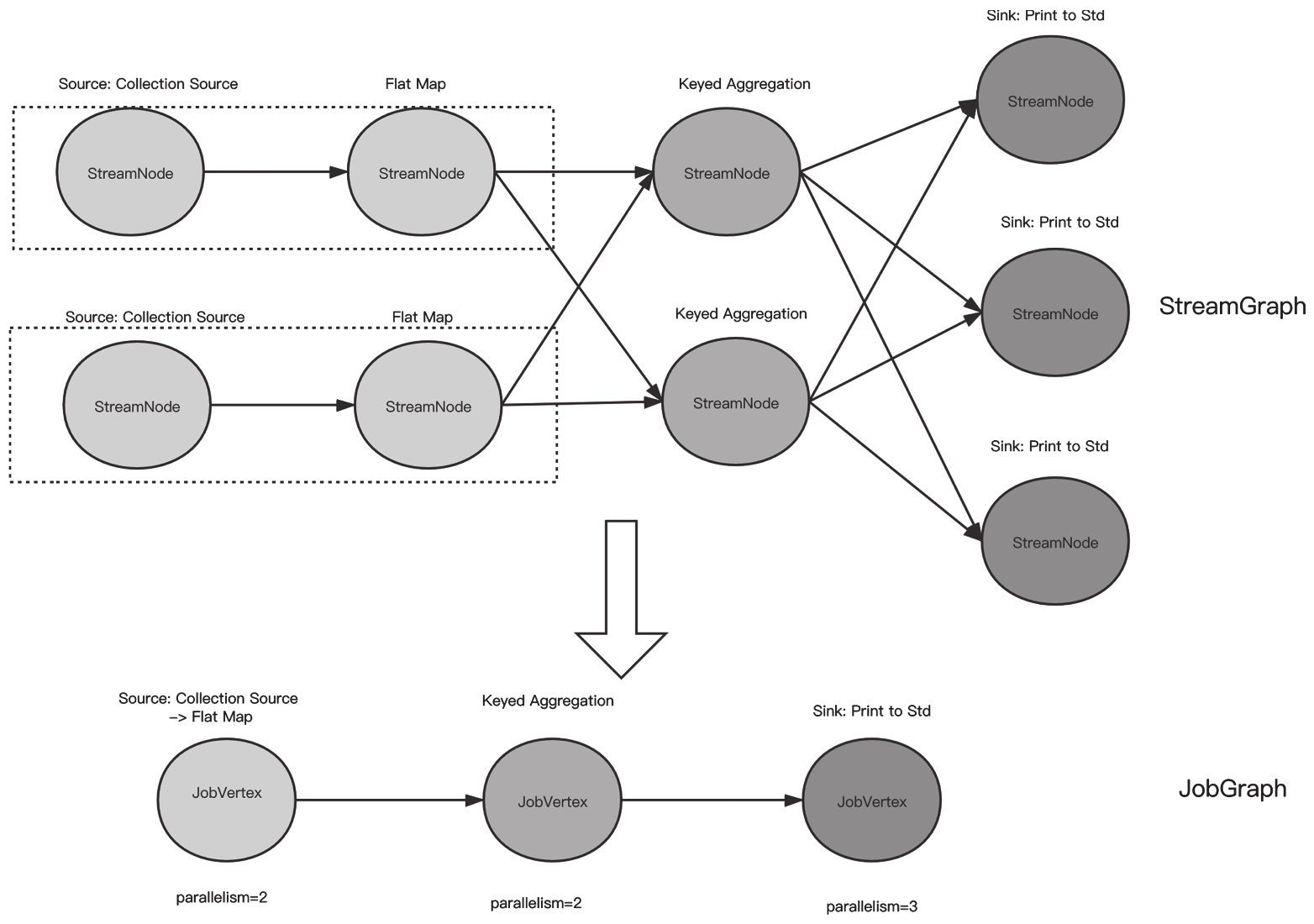
JobGraph到ExecutionGraph的转换
ExecutionGraph是JobGraph的并发版本,每个JobVertex对应ExecutionJobVertex,ExecutionJobVertex就是JobVertex增加一些执行信息的封装类。
一个有10个并发的算子会生成1个JobVertex、1个ExecutionJobVertex和10个ExecutionVertex。ExecutionVertex代表一个并发的子任务,可以被执行一次或者多次,内部Execution对象表示执行状态。
当然在ExecutionGraph内部也有JobStatus对象来记录整个作业的执行状态。
ExecutionVertex是通过IntermediateResultPartition来连接的。
接着看上面WordCount的例子,JobGraph转换为ExecutionGraph的过程如图所示。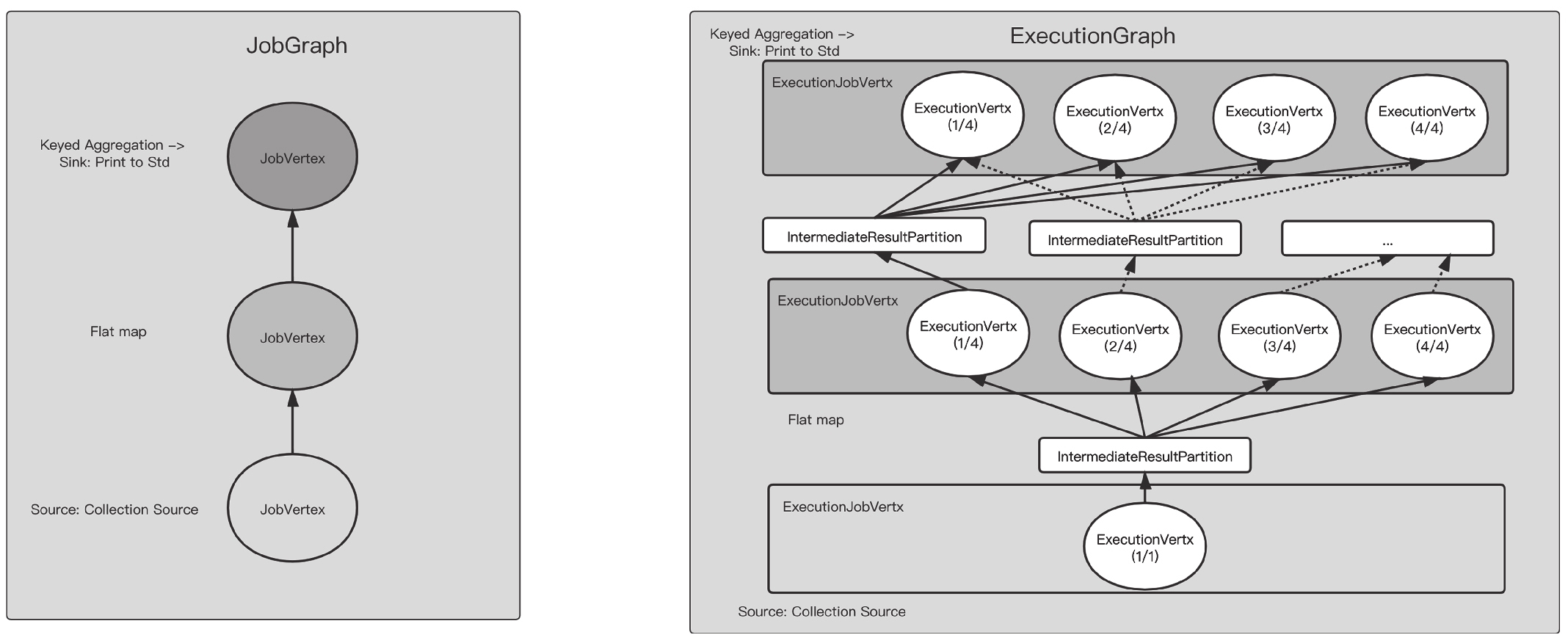
ExecutionGraph到Task的转换
ExecutionGraph到Task需要经过资源的分配即Slot的分配,然后部署。
Slot分配
本节重点介绍Slot的分配过程。
本节不涉及Slot在ResourceManager和TaskManager之间的申请过程,这里假设所有需要的Slot都已经在JobMaster的SlotPool中申请好。
相关概念和实现类
下面看几个重要的逻辑角色,它们一起配合管理Slot,而且相互之间有一些实现上的依赖或继承关系。
SlotManager和SlotPool
SlotManager是ResourceManager用来管理Slot的,它维护了所有已经注册的Slot的状态及使用情况。
而SlotPool是JobManager中用来服务Slot请求和分配的,当Slot不足时它会向ResourceManager请求更多的Slot。
SlotPool即使在ResourceManager服务无法响应的时候也可以单独提供服务。
它们之间的关系和交互如图所示。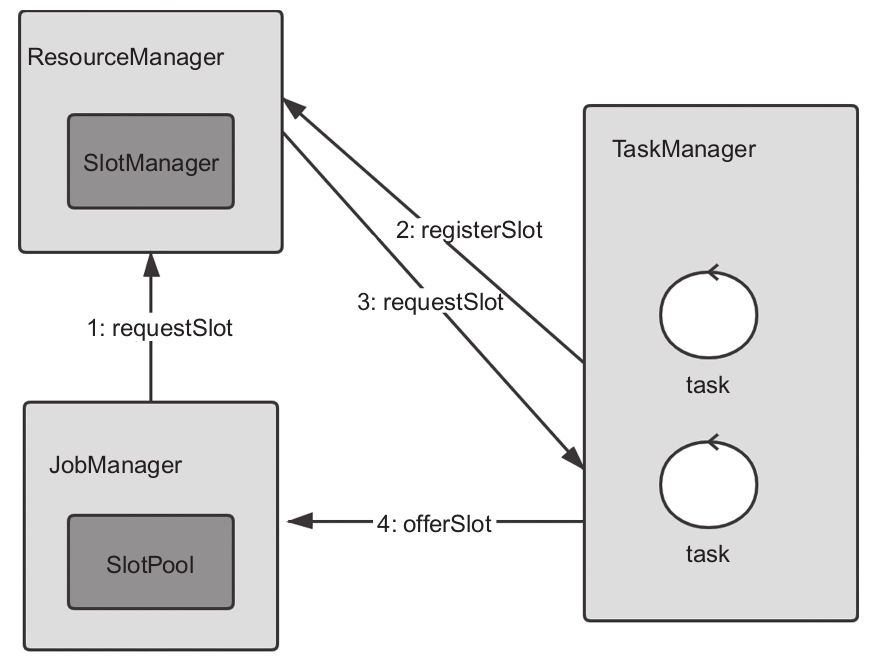
PhysicalSlot、LogicalSlot、MultiTaskSlot、SingleTaskSlot
PhysicalSlot和LogicalSlot是用来抽象Slot概念的,而MultiTaskSlot和SingleTaskSlot是用来辅助Slot的分配而用到的包装类,不对应任何概念,进一步说,TaskSlot的这两个实现类只是用来辅助共享Slot分配,如果没有设置Slot共享组,甚至不需要这两个类。
PhysicalSlot表示物理意义上的Slot,已经分配了唯一标识AllocationID,拥有TaskManagerGateway等属性,可以用来部署任务。
LogicalSlot(见图)表示逻辑意义上的Slot,一个LogicalSlot对应一个Execution-Vertex或任务,或者多个LogicalSlot对应一个PhysicalSlot,表示它们共用同一个Slot执行。
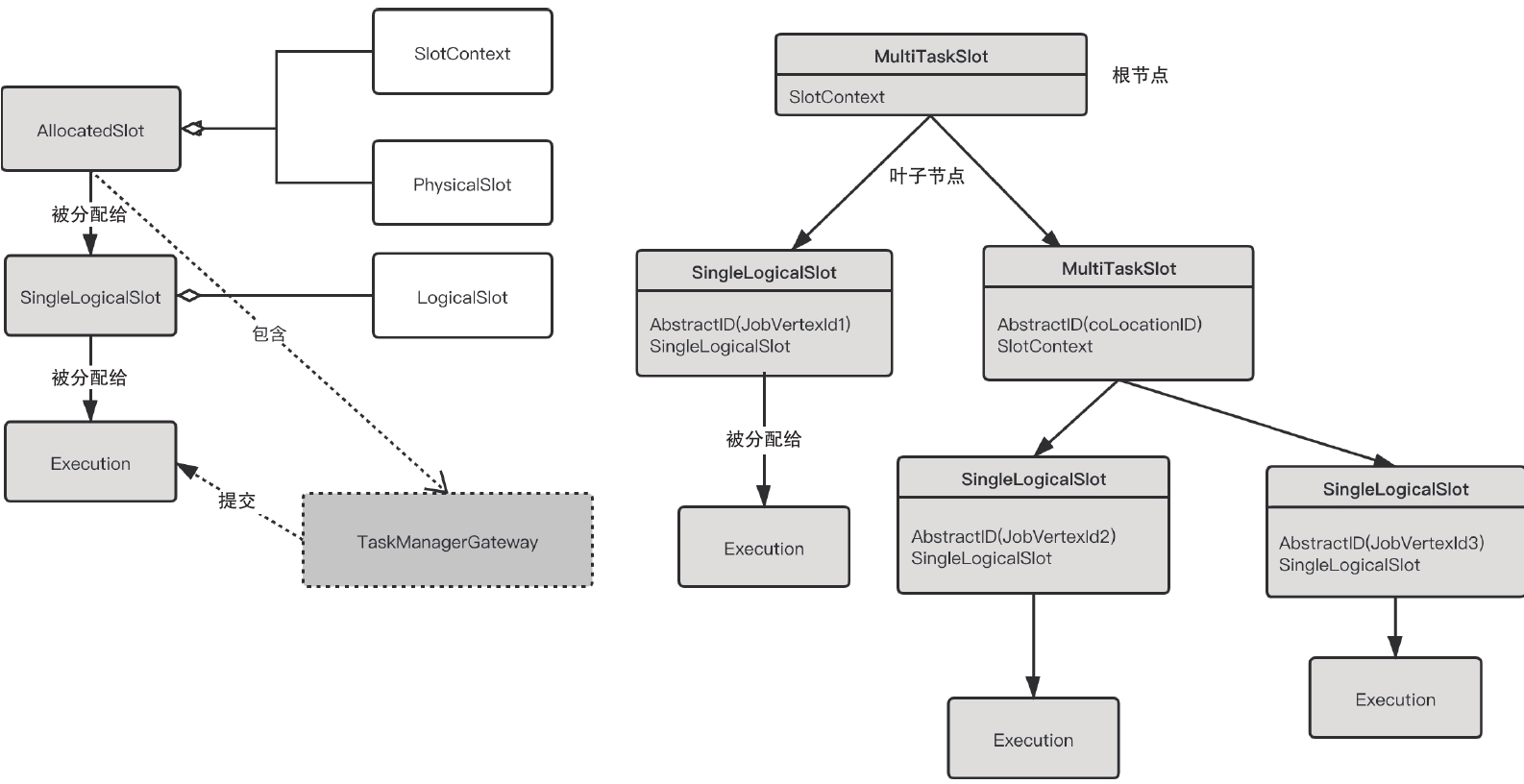
PhysicalSlot唯一的实现类是AllocatedSlot,LogicalSlot的主要实现类是SingleLogicalSlot,它们都实现了tryAssignPayload方法,也就是说AllocatedSlot可以装载一个SingleLogicalSlot,SingleLogicalSlot可以装载一个Execution(Execution表示ExecutionVertex的一次执行)。
这里payLoad表示“被分配给”的意思,也就是说Execution会拥有一个SingleLogicalSlot,而SingleLogicalSlot会拥有AllocatedSlot。AllocatedSlot包含Slot的物理信息,如Task-ManagerGateway,可以用来执行一次Execution。
MultiTaskSlot是为了完成多个LogicalSlot对一个PhysicalSlot的映射而用到的工具类。
MultiTaskSlot和SingleTaskSlot的接口都是TaskSlot。
MultiTaskSlot是一个树形结构,叶子节点就是SingleTaskSlot,非叶子节点还是MultiTaskSlot。
树的根节点是MultiTaskSlot,根节点会被分配一个SlotContext,SlotContext具体实现就是AllocatedSlot,也就是Physical-Slot。
树的所有叶子节点都会共享这个PhysicalSlot,而每个叶子节点SingleTaskSlot会对应一个SingleLogicalSlot,也就是LogicalSlot,这样就可以利用该树形结构表达多个LogicalSlot对一个PhysicalSlot的映射。
每个叶子节点都有唯一的AbstractID,这个就是JobVertexID,也就是说每个物理Slot节点上执行的任务都是不同的,不可能同一个任务的并发执行在相同的Slot上。
MultiTaskSlot表示的是同一个Slot共享组下的Slot分配,这个是通过SlotSharing-Manager来保证的,每个Slot共享组都会唯一对应一个SlotSharingManager。
Slot申请流程
之前JobMaster负责任务的调度和部署。入口方法是startScheduling方法,JobMaster会委托给LegacyScheduler执行。
LegacyScheduler是ExecutionGraph的一个门面类,具体的实现还是通过ExecutionGraph。
作业的调度和部署是以ExecutionVertex为单位进行的。
主要的方法是ExecutionGraph的scheduleForExecution。
下面先来看一下整个过程(见图),然后再对具体方法进行分析。
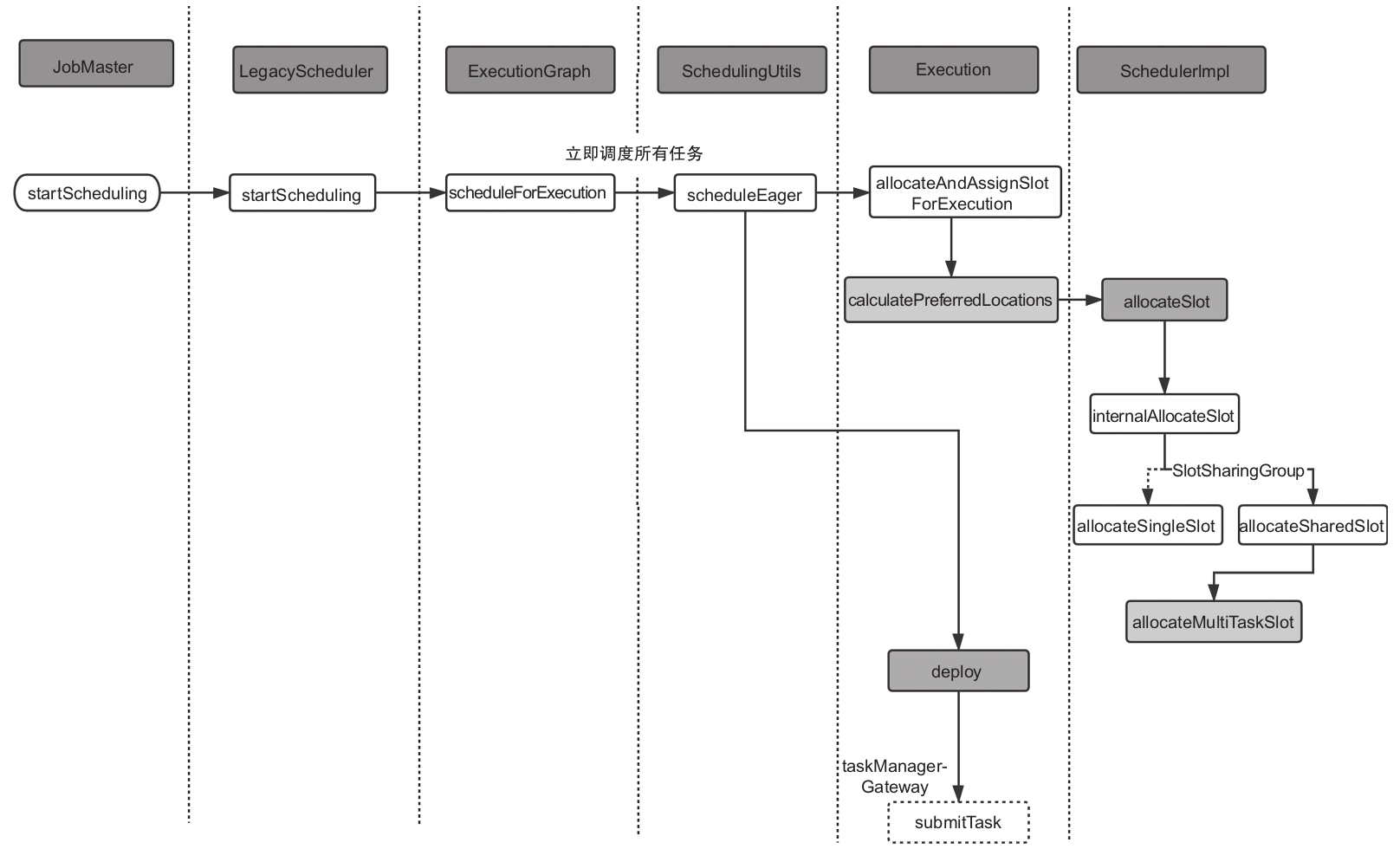
SchedulingUtils会根据ScheduleMode进入不同的方法,走不同的调度流程。Schedule-Mode主要有以下几种。
- LAZY_FROM_SOURCES:下游的任务需要在上游结果产生的前提下进行调度,一般用在离线的场景。
- LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST:与LAZY_FROM_SOURCES基本一致,不同的是这种模式支持在Slot资源不足的情况下执行作业,但用户需要确保作业中没有shuffle操作。
- EAGER:立刻调度所有的任务,流任务一般采用这种模式。
任务部署
经过上面的Slot申请之后,就可以进行部署工作了。
部署的主要逻辑在Execution的deploy方法中,实现如下:
1 | public void deploy() throws JobException { |
整个过程比较清楚,就是拿到分配的Slot构造TaskDeploymentDescriptor,然后通过TaskManagerGateway进行提交。
TaskDeploymentDescriptor包装了执行任务所需的大部分信息,其中的信息都经过了序列化。
下面就来具体分析提交之后的过程。
任务执行机制
任务执行过程
ExecutionVertex在经过Slot分配之后进行部署,TaskManager会收到submitTask的请求,启动并执行任务。
入口代码在TaskExecutor的submitTask方法中。我们根据图来看一下整个过程。
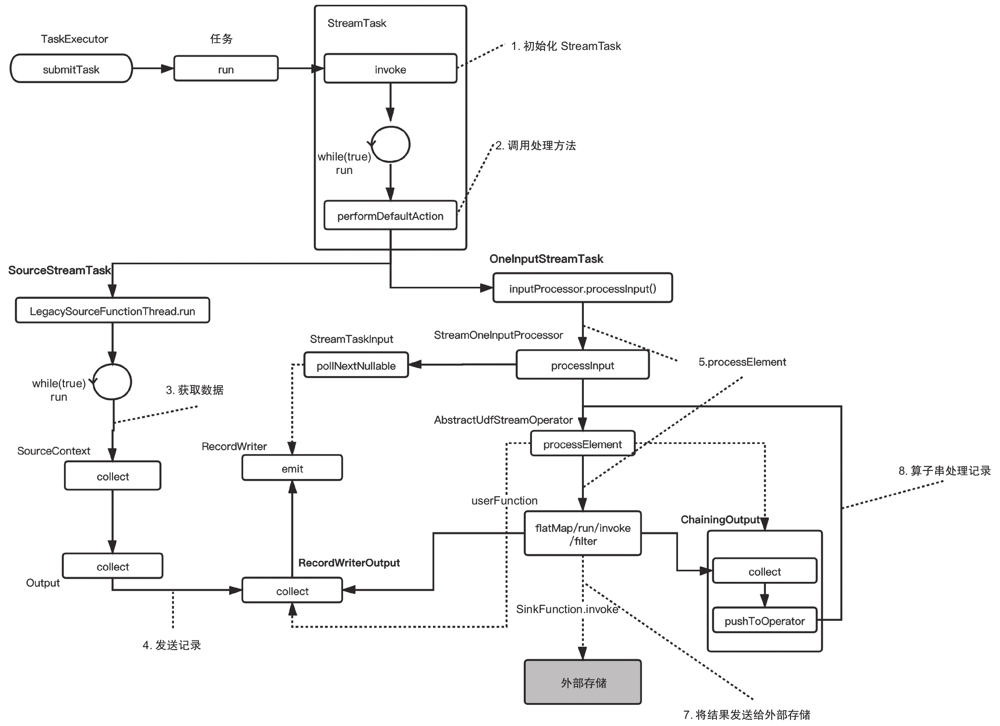
- 初始化StreamTask
在任务启动之后构造StreamTask,并调用其中的invoke方法。
StreamTask是流作业的执行基类,是调度和执行的基本单元和实现类。StreamTask会运行我们的算子,算子可能以算子串的形式存在。
StreamTask最重要的方法是invoke方法。invoke方法主要完成以下几项内容。- 初始化stateBackend,加载operatorChain。
- 执行init方法。
该方法是个抽象方法,每个具体的StreamTask类都有不同的实现。StreamTask的主要实现类有OneInputStreamTask(一个输入的任务)和SourceStreamTask(source处的任务)。对于OneInputStreamTask来说,init的主要工作是构建InputGate,用来消费分区的数据。 - 初始化算子的状态(从检查点恢复数据),然后打开所有的算子。
这里最终会调用ProcessFunction的open方法,也就是用户实现的函数的open方法。 - 开始运行算子,也就是图中的步骤2。在输入数据处理完成后,进入close流程。
- 关闭过程主要包括:timerService(用来注册Timer)停止服务;关闭所有的算子;清空所有缓存的数据;清理所有的算子。该方法是用来释放资源的,比如关闭stateBackend。
- 执行一个finally步骤,包括停止timerService,停止异步检查点进程,做些清理工作,以及关闭recordWriter。
- 执行处理方法
看过Flink早期版本代码的读者看到performDefaultAction方法可能会感到疑惑,怎么增加了这样一个方法?
Flink的早期版本(如1.4版本)中StreamTask的run方法是个抽象方法,不同的实现类有不同的实现;
而在我们分析的1.9版本中,run方法变成了具体方法,把performDefaultAction拿出来让各实现类实现。
简单看一下代码就会发现,1.9版本增加了一个mailbox变量,这就是稍后会讲到的Flink对线程模型的优化——MailBox线程模型。
这里performDefaultAction就是各个StreamTask要实现的具体方法,也就是算子的主要工作流程入口。 - 拉取数据
我们来看StreamTask的一个具体实现:SourceStreamTask。
SourceStreamTask的perform-DefaultAction(该方法也有一些与MailBox有关的逻辑,可以忽略,只需关注主要过程)经过一系列的调用最终会启动SourceFunction的run方法。
对于流任务的Source来说,SourceFunction是一个无限循环的函数,永不休止地进行数据的消费或者生产。 - 发送数据
数据在SourceFunction中产生之后,主线程会调用sourceContext进行收集,并经过Output接口实现类将其发送到网络端或下游算子。
在图中有两个Output的接口实现类,分别是RecordWriterOutput和ChainingOutput。- RecordWriterOutput:将数据通过RecordWriter发送出去。
- ChainingOutput:将数据推送到下一个算子,主要出现在算子串中。
- 处理数据我们来看StreamTask另一个经常使用的具体实现:OneInputStreamTask。
OneInput-StreamTask的performDefaultAction方法就是调用StreamOneInputProcessor的processInput,然后进一步调用算子的processElement。
图中给出的是我们比较常见的一个算子基础类AbstractUdfStreamOperator。
顾名思义这个类就是可以接受用户定义函数(UDF)的算子类。
AbstractUdfStreamOperator的processElement会调用userFunction的具体方法,也就是用户实现的方法。
这对于MapFunction来说,就是调用Map方法;对于FlatMap-Function来说,就是调用FlatMap方法;对于SinkFunction来说,就是调用invoke方法。 - 算子串处理数据
如果当前OneInputStreamTask的算子是一个算子串,那么经过第一个算子的process-Element方法之后,ChainingOutput会调用collect方法把数据推送到下一个算子,然后接着经过下一个算子的processElement方法。 - 将数据发送到外部
如果当前算子是StreamSink,那么userFunction就是SinkFunction,最终会调用Sink-Function的invoke方法,把数据发送到外部系统。
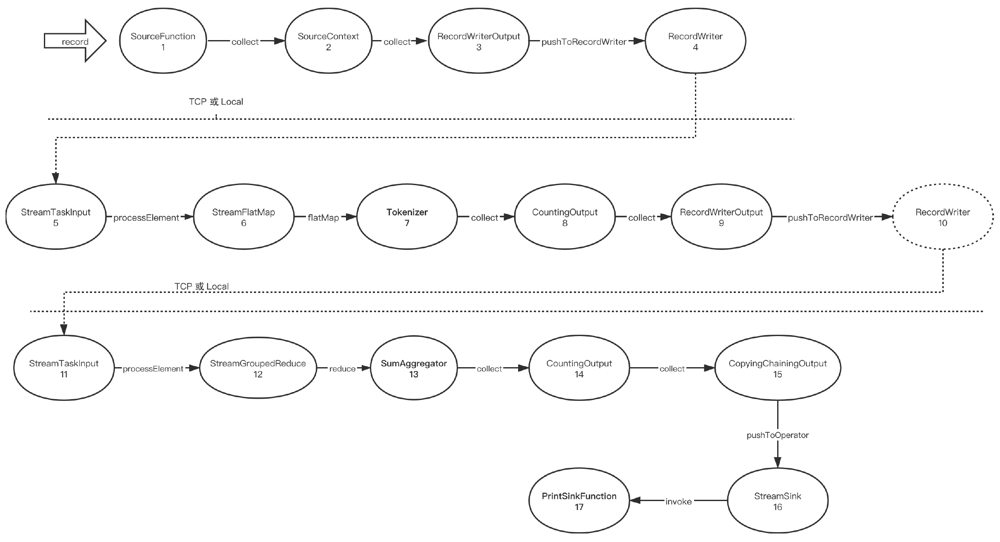
首先在SourceFunction处生成或者拉取数据,然后通过SourceContext将数据收集到Output中,这里的Output是RecordWriterOutput,这样数据会通过网络或者本地的方式被发送到一个任务中。
下一个任务,这里是FlatMap,通过StreamTaskInput获取到数据,数据经过算子调用map函数,也就是Tokenizer处理之后,被收集到CountingOutput(只起到计数的作用),接着CountingOutput转手把数据给了RecordWriterOutput,由RecordWriterOutput再把数据发送到网络或者通过本地内存传输。
经过网络传输(稍后介绍)和数据的重新分区,StreamGroupedReduce算子拿到了数据,进行求和计算,然后通过CopyingChainingOutput把数据推送到StreamSink算子,由StreamSink调用userFunction也就是PrintSinkFunction将数据打印到标准输出。
MailBox线程模型
MailBox线程模型是Flink 1.9版本引入的任务线程模型,它对早期版本中的简单线程模型进行了升级,优化了代码结构,提高了运行效率。
改进理由
为什么要对StreamTask的线程模型进行优化?Flink 1.9版本的代码已经经过部分的改造,不能很好地说明问题,下面以Flink 1.4版本代码为例来说明。
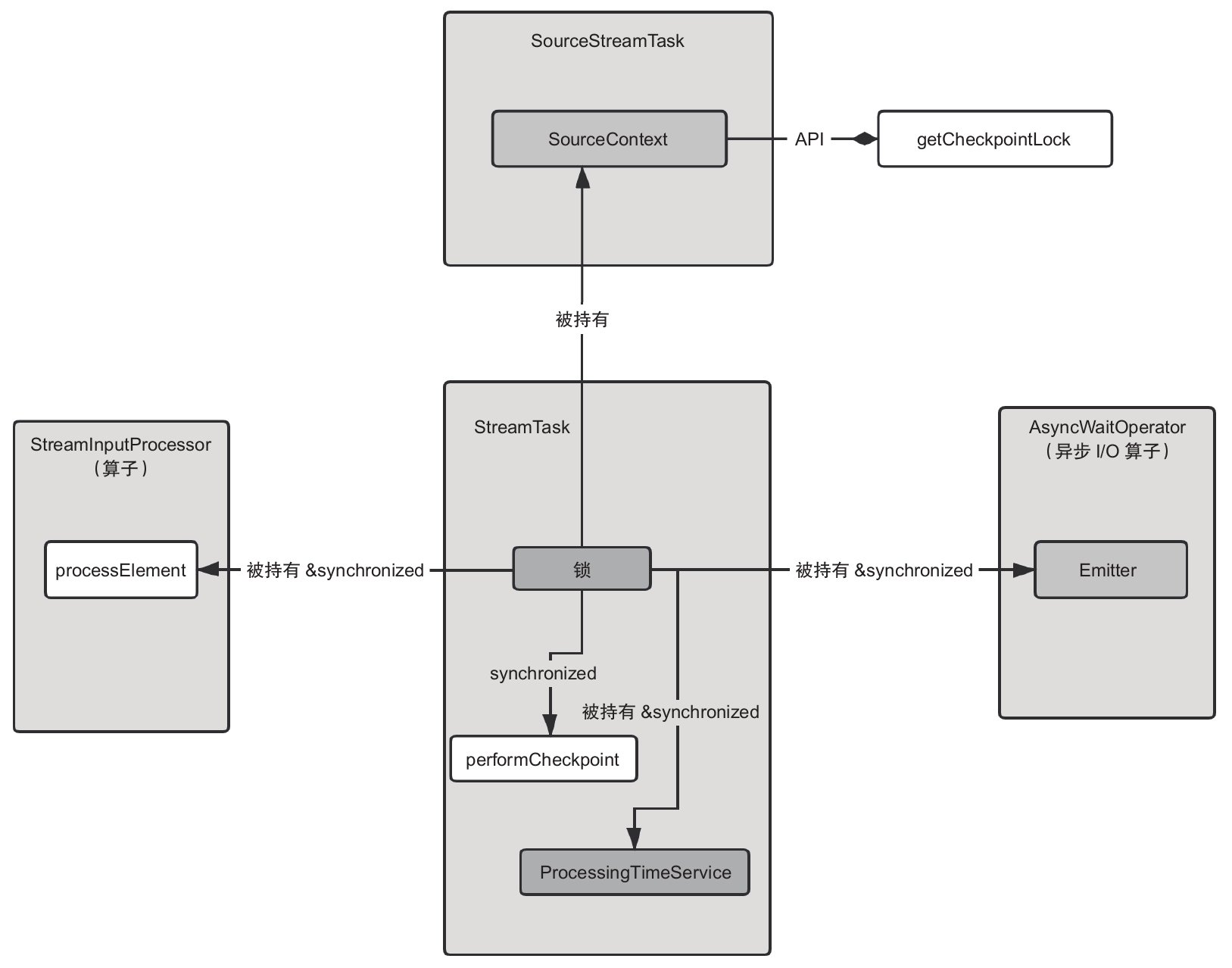
StreamTask内部有一个Object类型的锁变量lock,该变量会在多个地方用到,用来同步算子处理数据和检查点、定时器触发等操作。(为什么需要同步呢?读者可以自己思考下。)我们通过图来看看。
StreamTask的锁变量被多个地方引用和使用,而且还通过SourceContext的API暴露给了用户。
Flink 1.4及之前版本的实现有以下不足之处:锁对象在多个类中传递和使用,代码的可读性和后期的维护成本都是问题,而且后续开发的功能容易因锁的使用不当而出现问题。把框架内部的锁暴露给用户,这不是一个好的设计。
MailBox模型
MailBox模型借鉴Actor模型的设计理念,把需要同步的行为(action)放到一个队列或者消息容器里,然后单线程顺序获取行为,最后执行。
具体实现
对于具体实现,最简单的想法就是通过一个阻塞队列实现。
Flink 1.9版本是用一个ringBuffer的Runnable数组缓存行为,然后实现take或put相关方法。
这里我们看看Flink 1.10版本的实现(该版本在本书发售之前已经发布,并且这部分代码已经比较完善)。
国内查看评论需要代理~